
Как работает мультипроцессорная система с общей памятью кратко
Обновлено: 04.07.2024
Презентация на тему: " 1 Вычислительные системы Компьютерные с общей памятью ( мультипроцессорные системы) Компьютерные с распределенной памятью (мультикомпьютерные системы)" — Транскрипт:
1 1 Вычислительные системы Компьютерные с общей памятью ( мультипроцессорные системы) Компьютерные с распределенной памятью (мультикомпьютерные системы)
2 Мультипроцессорные системы Первый класс – это компьютеры с общей памятью. Системы, построенные по такому принципу, иногда называют мультипроцессорными "системами или просто мультипроцессорами. В системе присутствует несколько равноправных процессоров, имеющих одинаковый доступ к единой памяти. Все процессоры "разделяют" между собой общую память. Все процессоры работают с единым адресным пространством: если один процессор записал значение 79 в ячейку по адресу 1024, то другой процессор, прочитав содержимое ячейки, расположенное по адресу 1024, получит значение 79. 2
3 3 Параллельные компьютеры с общей памятью
4 Мультикомпьютерные системы Второй класс это компьютеры с распределенной памятью, которые по аналогии с предыдущим классом иногда называют мультикомпьютерными системами. Каждый вычислительный узел является полноценным компьютером со своим процессором, памятью, подсистемой ввода/вывода, операционной системой. В такой ситуации, если один процессор запишет значение 79 по адресу 1024, то это никак не повлияет на то, что по тому же адресу прочитает другой, поскольку каждый из них работает в своем адресном пространстве. 4
5 5 Параллельные компьютеры с распределенной памятью
6 Blue Gene/L 6 Расположение: Ливерморская национальная лаборатория имени Лоуренса Общее число процессоров штук Состоит из 64 стоек Производительность 280,6 терафлопс В штате лаборатории - порядка 8000 сотрудников, из которых - более 3500 ученых и инженеров. Машина построена по сотовой архитектуре, то есть, из однотипных блоков, что предотвращает появление "узких мест" при расширении системы. Стандартный модуль BlueGene/L - "compute card" - состоит из двух блоков-узлов (node), модули группируются в модульную карту по 16 штук, по 16 модульных карт устанавливаются на объединительной панели (midplane) размером 43,18 х 60,96 х 86,36 см, при этом каждая такая панель объединяет 512 узлов. Две объединительные панели монтируются в серверную стойку, в которой уже насчитывается 1024 базовых блоков-узлов. На каждом вычислительном блоке (compute card) установлено по два центральных процессора и по четыре мегабайта выделенной памяти Процессор PowerPC 440 способен выполнять за такт четыре операции с плавающей запятой, что для заданной тактовой частоты соответствует пиковой производительности в 1,4 терафлопс для одной объединительной панели (midplane), если считать, что на одном узле установлено по одному процессору. Однако на каждом блоке-узле имеется еще один процессор, идентичный первому, но он призван выполнять телекоммуникационные функции.
8 8 Организация мультипроцессорных систем (общая шина) Мультипроцессорная система с общей шиной Чтобы предотвратить одновременное обращение нескольких процессоров к памяти, используются схемы арбитража, гарантирующие монопольное владение шиной захватившим ее устройством. Недостаток: заключается в том, что даже небольшое увеличение числа устройств на шине (4-5) очень быстро делает ее узким местом, вызывающим значительные задержки при обменах с памятью и катастрофическое падение производительности системы в целом Достоинство: простота и дешевизна конструкции
9 9 Организация мультипроцессорных систем (матричный коммутатор) Матричный коммутатор позволяет разделить память на независимые модули и обеспечить возможность доступа разных процессоров к различным модулям одновременно. На пересечении линий располагаются элементарные точечные переключатели, разрешающие или запрещающие передачу информации между процессорами и модулями памяти. Недостаток: большой объем необходимого оборудования, поскольку для связи n процессоров с n модулями памяти требуется nxn элементарных переключателей Мультипроцессорная система с матричным коммутатором Преимущества: возможность одновременной работы процессоров с различными модулями памяти
10 10 Организация мультипроцессорных систем Мультипроцессорная система с омега-сетью Использование каскадных переключателей Каждый использованный коммутатор может соединить любой из двух своих входов с любым из двух своих выходов. Это свойство и использованная схема коммутации позволяют любому процессору вычислительной системы обращаться к любому модулю памяти. В общем случае для соединения n процессоров с n модулями памяти потребуется log 2 n каскадов по n/2 коммутаторов в каждом, т. е. всего (nlog 2 n)/2 коммутаторов. Проблема: задержки
11 11 Топологические связи модулей ВС Выбор той топологии связи процессоров в конкретной вычислительной системе может быть обусловлен самыми разными причинами. Это могут быть соображениями стоимости, технологической реализуемости, простоты сборки и программирования, надежности, минимальности средней длины пути между узлами, минимальности максимального расстояния между узлами и др.
12 12 Варианты топологий связи процессоров и ВМ NUMA Non Uniform Memory Access
13 Топология двоичного гиперкубы 13 В n-мерном пространстве в вершинах единичного n- мерного куба размещаются процессоры системы, т. е. точки (x 1, x 2, …, х n ), в которых все координаты х i могут быть равны либо 0, либо 1. Каждый процессор соединим с ближайшим непосредственным соседом вдоль каждого из n измерений. В результате получается n-мерный куб для системы из N = 2 n процессоров. Двумерный куб соответствует простому квадрату, а четырехмерный вариант условно изображен на рисунке. В гиперкубе каждый процессор связан лишь с log 2 N непосредственными соседями, а не с N, как в случае полной связности. Гиперкуб имеет массу полезных свойств. Например, для каждого процессора очень просто определить всех его соседей: они отличаются от него лишь значением какой-либо одной координаты х i. Каждая "грань" n-мерного гиперкуба является гиперкубом размерности n-1. Максимальное расстояние между вершинами n-мерного гиперкуба равно n. Гиперкуб симметричен относительно своих узлов: из каждого узла система выглядит одинаковой и не существует узлов, которым необходима специальная обработка.
14 Достоинства и недостатки компьютеров с общей и распределенной памятью Для компьютеров с общей памятью проще создавать параллельные программы, но их максимальная производительность сильно ограничивается небольшим числом процессоров. Для компьютеров с распределенной памятью все наоборот. Одним из возможных направлений объединения достоинств этих двух классов является проектирование компьютеров с архитектурой NUMA (Non Uniform Memory Access).
15 Данный компьютер состоит из набора кластеров, соединенных друг с другом через межкластерную шину. Каждый кластер объединяет процессор, контроллер памяти, модуль памяти и иногда некоторые устройства ввода/вывода, соединенные между собой посредством локальной шины. Когда процессору нужно выполнить операции чтения или записи, он посылает запрос с нужным адресом своему контроллеру памяти. Контроллер анализирует старшие разряды адреса, по которым и определяет, в каком модуле хранятся нужные данные. Если адрес локальный, то запрос выставляется на локальную шину, в противном случае запрос для удаленного кластера отправляется через межкластерную шину. В таком режиме программа, хранящаяся в одном модуле памяти, может выполняться любым процессором системы. Единственное различие заключается в скорости выполнения. Все локальные ссылки отрабатываются намного быстрее, чем удаленные. Поэтому и процессор того кластера, где хранится программа, выполнит ее на порядок быстрее, чем любой другой.
16 Простая конфигурация с архитектурой NUMA
17 NUMA - архитектура NUMA-компьютеры обладают серьезным недостатком, который выражается в наличии отдельной кэш-памяти у каждого процессорного элемента Кэш-память для многопроцессорных систем оказывается узким местом Объяснение: Если процессор Р1 сохранил значение X в ячейке q, а затем процессор Р2 хочет прочитать содержимое той же ячейки q. Процессор Р2 получит результат отличный от X, так как X попало в кэш процессора Р1. Эта проблема носит название проблемы согласования содержимого кэш-памяти Решение: Архитектура ccNUMA
18 Проблема неоднородности доступа Архитектура NUMA имеет неоднородную память (распределенность памяти между модулями), что в свою очередь требует от пользователя понимания неоднородности архитектуры. Если обращение к памяти другого узла требует на 5-10% больше времени, чем обращение к своей памяти, то это может и не вызвать никаких вопросов. Большинство пользователей будут относиться к такой системе, как к UMA (SMP), и практически все разработанные для SMP программы будут работать достаточно хорошо. Однако для современных NUMA систем это не так, и разница времени локального и удаленного доступа лежит в промежутке %.
20 20 Языки параллельного программирования Использование библиотек и интерфейсов, поддерживающих взаимодействие параллельных процессов: подготовка программного кода на любом доступном языке программирования, но с использованием интерфейса доступа к свойствам и методам, обеспечивающим параллельную обработку информации. Программист сам явно определяет какие параллельные процессы приложения в каком месте программы и с какими процессами должны либо обмениваться данными, либо синхронизировать свою работу. Такой идеологии следуют MPI и PVM Существует специализированная система Linda, добавляющая в любой последовательный язык лишь четыре дополнительные функции in, out, read и eval, что и позволяет создавать параллельные программы Использование подпрограмм и функций параллельных предметных библиотек в критических по времени счета фрагментах программы: использование дополнительных модулей, подключаемых к стандартному ЯП в процессе подготовки программного кода, позволяющие обеспечить параллельное функционирования программы только для некоторого набора алгоритмов. Весь параллелизм и вся оптимизация спрятаны в вызовах, а пользователю остается лишь написать внешнюю часть своей программы и грамотно воспользоваться стандартными блоками. Примеры библиотек: Lapack, Cray Scientific Library, HP Mathematical Library Использование специализированных пакетов и программных комплексов: применяются в основном для выполнения типовых задач и не требуют от пользователя каких-либо знаний программирования, либо архитектуры ВС. Основная задача это правильно указать все необходимые входные данные и правильно воспользоваться функциональностью пакета. Пример: пакет GAMESS для выполнения квантово-химических расчетов
21 21 Примеры языков программирования и надстроек 1.OpenMP 2.High Performance Fortran (HPF) 3.Occam, Sisal, Норма 4.Linda, Massage Passing Interface (MPI) 5.Lapack, 6.Gamess
25 Симметричное мультипроцессирование SMP часто применяется в науке, промышленности, бизнесе, где программное обеспечение специально разрабатывается для многопоточного выполнения. В то же время, большинство потребительских продуктов, таких как текстовые редакторы и компьютерные игры написаны так, что они не могут получить много пользы от SMP систем. Преимущества архитектуры Пограммы, запущенные на SMP системах, получают прирост производительности даже если они были написаны для однопроцессорных систем. Это связано с тем, что аппаратные прерывания, обычно приостанавливающие выполнение программы для их обработки ядром, могут обрабатываться на свободном процессоре. Эффект в большинстве приложений проявляется не столько в приросте производительности, сколько в ощущении, что программа выполняется более плавно. В некоторых приложениях, в частности программных компиляторах и некоторых проектах распределённых вычислений, повышение производительности будет почти прямо пропорционально числу дополнительных процессоров. Недостатки архитектуры Ограничение на количество процессоров При увеличении числа процессоров заметно увеличивается требование к полосе пропускания шины памяти. Это накладывает ограничение на количество процессоров в SMP архитектуре. Современные конструкции позволяют разместить до четырех процессоров на одной системной плате. Проблема когерентности кэша Возникает из-за того, что значение элемента данных в памяти, хранящееся в двух разных процессорах, доступно этим процессорам только через их индивидуальные кэши. Если процессор изменит значение элемента данных в своем кэше, то при попытке вывода данных из памяти, будет получено старое значение. Наоборот, если подсистема ввода/вывода вводит в ячейку основной памяти новое значение, в кэш памяти процессора по прежнему остается старо.
27 27 Архитектура Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. Примеры HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.).HP 9000 V-class Масштабируемость Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры.кластерные NUMA Операционная система Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel- платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка Модель программирования Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания.OpenMPавтоматического распараллеливания Основные классы современных параллельных компьютеров Симметричные мультипроцессорные системы (SMP)
28 28 Основные классы современных параллельных компьютеров Системы с неоднородным доступом к памяти (NUMA) Архитектура Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре c-NUMA (cache-coherent NUMA) Примеры HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600.HP 9000 V-classOrigin2000HPC NUMA-Q 2000RM600 Масштабируемость Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддержки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000). Операционная система Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000).SMP Модель программирования Аналогично SMP.SMP
29 29 Основные классы современных параллельных компьютеров Параллельные векторные системы (PVP) Архитектура Основным признаком PVP-систем является наличие специальных векторно- конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Примеры NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, серия Fujitsu VPP.SX-5T90CRAY SV1VPP Масштабируемость Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP).SMPMPP Модель программирования Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
31 31 Ссылки на литературу Анализ мультипроцессорных систем с иерархической памятью Языки параллельной обработки Архитектура и топология многопроцессорных вычислительных систем Эволюция языков программировния Специализирванные параллельные языки и расширения существующих языков Основные классы современных параллельных компьютеров Управление процессорами Мультипроцессорные системы Архитектура и топология многопроцессорных вычислительных систем Системы параллельной обработки данных
Аннотация: Архитектура ВС. Классификация вычислительных систем. Пути достижения параллелизма. Параллелизм на уровне команд, потоков, приложений. Анализ эффективности параллельных вычислений. Закон Амдала.
Мотивы параллелизма
- Параллельность повышает производительность системы из-за более эффективного расходования системных ресурсов. Например, во время ожидания появления данных по сети, вычислительная система может использоваться для решения локальных задач.
- Параллельность повышает отзывчивость приложения. Если один поток занят расчетом или выполнением каких-то запросов, то другой поток может реагировать на действия пользователя.
- Параллельность облегчает реализацию многих приложений. Множество приложений типа "клиент-сервер", "производитель-потребитель" обладают внутренним параллелизмом. Последовательная реализация таких приложений более трудоемка, чем описание функциональности каждого участника по отдельности.
Классификация вычислительных систем
Одной из наиболее распространенных классификаций вычислительных систем является классификация Флинна. Четыре класса вычислительных систем выделяются в соответствие с двумя измерениями – характеристиками систем: поток команд, которые данная архитектура способна выполнить в единицу времени (одиночный или множественный) и поток данных, которые могут быть обработаны в единицу времени (одиночный или множественный).
- SISD (Single Instruction, Single Data) – системы, в которых существует одиночный поток команд и одиночный поток данных. В каждый момент времени процессор обрабатывает одиночный поток команд над одиночным потоком данных. К данному типу систем относятся последовательные персональные компьютеры с одноядерными процессорами.
- SIMD (Single Instruction, Multiple Data) – системы с одиночным потоком команд и с множественным потоком данных; подобный класс составляют многопроцессорные системы, в которых в каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов. Такая архитектура позволяет выполнять одну арифметическую операцию над элементами вектора. Современные компьютеры реализуют некоторые команды типа SIMD (векторные команды), позволяющие обрабатывать несколько элементов данных за один такт.
- MISD (Multiple Instructions, Single Data) – системы, в которых существует множественный поток команд и одиночный поток данных; к данному классу относят систолические вычислительные системы и конвейерные системы;
- MIMD (Multiple Instructions, Multiple Data) – системы с множественным потоком команд и множественных потоком данных; к данному классу относится большинство параллельных вычислительных систем.
Классификация Флинна относит почти все параллельные вычислительные системы к одному классу – MIMD . Для выделения разных типов параллельных вычислительных систем применяется классификация Джонсона, в которой дальнейшее разделение многопроцессорных систем основывается на используемых способах организации оперативной памяти в этих системах. Данный подход позволяет различать два важных типа многопроцессорных систем: multiprocessors (мультипроцессорные или системы с общей разделяемой памятью) и multicomputers (мультикомпьютеры или системы с распределенной памятью).

Архитектура однопроцессорной машины
Современная однопроцессорная машина состоит из нескольких компонентов: центрального процессорного устройства (ЦПУ), первичной памяти, одного или нескольких уровней кэш -памяти ( кэш ), вторичной (дисковой) памяти и набора периферийных устройств ( дисплей , клавиатура, мышь , модем , CD, принтер и т.д.). Основными компонентами для выполнения программ являются ЦПУ, кэш и память .

Процессор выбирает инструкции из памяти, декодирует их и выполняет. Он содержит управляющее устройство (УУ), арифметико-логическое устройство ( АЛУ ) и регистры. УУ вырабатывает сигналы, управляющие действиями АЛУ , системой памяти и внешними устройствами. АЛУ выполняет арифметические и логические инструкции, определяемые набором инструкций процессора. В регистрах хранятся инструкции, данные и состояние машины (включая счетчик команд ).
Мультикомпьютеры с распределенной памятью

Мультикомпьютер (многомашинная система) – мультипроцессор с распределенной памятью, в котором процессоры и сеть расположены физически близко (в одном помещении). Также называют тесно связанной машинной. Она одновременно используется одним или небольшим числом приложений; каждое приложение задействует выделенный набор процессоров. Соединительная сеть с большой пропускной способностью предоставляет высокоскоростной путь связи между процессорами.
Мультипроцессор с разделяемой памятью
В мультипроцессоре и в многоядерной системе исполнительные устройства (процессоры и ядра процессоров) имеют доступ к разделяемой оперативной памяти. Процессоры совместно используют оперативную память .

У каждого процессора есть собственный кэш . Если два процессора ссылаются на разные области памяти, их содержимое можно безопасно поместить в кэш каждого из них. Проблема возникает, когда два процессора обращаются к одной области памяти. Если оба процессора только считывают данные, в кэш каждого из них можно поместить копию данных. Но если один из процессоров записывает в память , возникает проблема согласованности кэша: в кэш -памяти другого процессора теперь содержатся неверные данные. Необходимо либо обновить кэш другого процессора, либо признать содержимое кэша недействительным. Обеспечение однозначности кэшей реализуется на аппаратном уровне – для этого после изменения значения общей переменной все копии этой переменной в кэшах отмечаются как недействительные и последующий доступ к переменной потребует обязательного обращения к основной памяти. Необходимость обеспечения когерентности приводит к некоторому снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров.
Наличие общих данных при выполнении параллельных вычислений приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так, например, если изменение общих данных требует для своего выполнения некоторой последовательности действий, то необходимо обеспечить взаимоисключение с тем, чтобы эти изменения в любой момент времени мог выполнять только один командный поток . Задачи взаимоисключения и синхронизации относятся к числу классических проблем, и их рассмотрение при разработке параллельных программ является одним из основных вопросов параллельного программирования.
Режимы выполнения независимых частей программы
При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы выполнения независимых частей программы:
1) Режим разделения времени (многозадачный режим)
Режим разделения времени предполагает, что число подзадач (процессов или потоков одного процесса) больше, чем число исполнительных устройств. Данный режим является псевдопараллельным, когда активным (исполняемым) может быть одна единственнаяподзадача, а все остальные процессы (потоки) находятся в состоянии ожидания своей очереди на использование процессора; использование режима разделения времени может повысить эффективность организации вычислений (например, если один из процессов не может выполняться из-за ожидания вводимых данных, процессор может быть задействован для выполнения другого, готового к исполнению процесса), кроме того в данном режиме проявляются многие эффекты параллельных вычислений (необходимость взаимоисключения и синхронизации процессов и др.).
Многопоточность приложений в операционных системах с разделением времени применяется даже в однопроцессорных системах. Например, в Windows-приложениях многопоточность повышает отзывчивость приложения – если основной поток занят выполнением каких-то расчетов или запросов, другой поток позволяет реагировать на действия пользователя. Многопоточность упрощает разработку приложения. Каждый поток может планироваться и выполняться независимо. Например, когда пользователь нажимает кнопку мышки персонального компьютера, посылается сигнал процессу, управляющему окном, в котором в данный момент находится курсор мыши. Этот процесс ( поток ) может выполняться и отвечать на щелчок мыши. Приложения в других окнах могут продолжать при этом свое выполнение в фоновом режиме.
2) Распределенные вычисления
Такие системы пишутся для распределения обработки (как в файловых серверах), обеспечения доступа к удаленным данным (как в базах данных и в Web ), интеграции и управления данными, распределенными по своей сути (как в промышленных системах), или повышения надежности (как в отказоустойчивых системах). Многие распределенные системы организованы как системы типа клиент- сервер . Например, файловый сервер предоставляет файлы данных для процессов, выполняемых на клиентских машинах. Компоненты распределенных систем часто сами являются многопоточными.
3) Синхронные параллельные вычисления.
Их цель – быстро решать данную задачу или за то же время решить большую задачу. Примеры синхронных вычислений:
- научные вычисления, которые моделируют и имитируют такие явления, как глобальный климат, эволюция солнечной системы или результат действия нового лекарства;
- графика и обработка изображений, включая создание спецэффектов в кино;
- крупные комбинаторные или оптимизационные задачи, например, планирование авиаперелетов или экономическое моделирование.
Программы решения таких задач требуют эффективного использования доступных вычислительных ресурсов системы. Число подзадач должно быть оптимизировано с учетом числа исполнительных устройств в системе (процессоров, ядер процессоров).
Уровни параллелизма в многоядерных архитектурах
Параллелизм на уровне команд (InstructionLevelParallelism, ILP ) позволяет процессору выполнять несколько команд за один такт. Зависимости между командами ограничивают количество доступных для выполнения команд, снижая объем параллельных вычислений. Технология ILP позволяет процессору переупорядочить команды оптимальным образом с целью исключить остановки вычислительного конвейера и увеличить количество команд, выполняемых процессором за один такт. Современные процессоры поддерживают определенный набор команд, которые могут выполняться параллельно.
Параллелизм на уровне потоков процесса. Потоки позволяют выделить независимые потоки исполнения команд в рамках одного процесса. Потоки поддерживаются на уровне операционной системы. Операционная система распределяет потоки процессов по ядрам процессора с учетом приоритетов. С помощью потоков приложение может максимально задействовать свободные вычислительные ресурсы.
Параллелизм на уровне приложений.Одновременное выполнение нескольких программ осуществляется во всех операционных системах, поддерживающих режим разделения времени . Даже на однопроцессорной системе независимые программы выполняются одновременно. Параллельность достигается за счет выделение каждому приложению кванта процессорного времени.
Анализ эффективности параллельных вычислений
Анализ эффективности параллельных вычислений

Эффективность параллельного алгоритма определяется следующим образом:

Эффективность показывает, насколько задействованы вычислительные ресурсы системы; идеальное теоретическое значение эффективности равно единице.
Пределы параллелизма
Достижению максимального ускорения может препятствовать существование в выполняемых вычислениях последовательных расчетов, которые не могут быть распараллелены. Джин Амдал (GeneAmdahl)показал, что верхняя граница для ускорения определяется долей последовательных вычислений алгоритма:

– доля последовательных вычислений в применяемом алгоритме обработки данных, – число процессоров.
Например, если доля последовательных вычислений составляет 25%, то максимально достижимое ускорение для параллельного алгоритма равно:

В "законе Амдала"имеется несколько допущений, которые в реальных приложениях могут быть неверными. Одно из допущений заключается в том, что доля последовательных расчетов является постоянной величиной и не зависит от вычислительной сложности решаемой задачи. Однако, для большинства задач является убывающей функцией от , где –параметр сложности задачи.В этом случае ускорение может быть увеличено при увеличении вычислительной сложности задачи. Нарушение "закона Амдала" также может быть связано с архитектурными особенностями параллельной вычислительной системы. Например, параллельный алгоритм уменьшает объем данных, используемых каждым процессором, и повышает эффективность использования кэш -памяти каждого процессора. Оптимальная работа с кэш -памятью может сильно увеличить быстродействие алгоритма.
Параллельный алгоритм называется масштабируемым, если при росте числа процессоров он обеспечивает увеличение ускорения при сохранении постоянного уровня эффективности использования процессоров.
Параллельный компьютер, в котором все процессоры совместно используют общую физическую память, называется мультипроцессором , или системой с общей памятью (рис. а). Все процессы, работающие в мультипроцессоре совместно, могут иметь единое виртуальное адресное пространство, отображенное на общую память. Любой процесс с помощью команд LOAD и STORE может считать слово из памяти или записать слово в память. Больше ничего не требуется. Два процесса имеют возможность легко обмениваться информацией — для этого один из них просто записывает данные в общую память, а другой их считывает.

На рисунке (а) изображено мультипроцессор из 16 процессоров, имеющих общую память;
На рисунке (б) изображение, разделенное на 16 секций, каждую из которых анализирует отдельный процессор;
Благодаря возможности взаимодействия двух и более процессов мультипроцессоры весьма популярны. Данная модель понятна программистам и позволяет решать широкий круг задач. Для примера рассмотрим программу, которая анализирует битовое отображение и составляет список всех его объектов. Одна копия изображения хранится в памяти, как показано на (рис. б). Каждый из 16 процессоров запускает один процесс, призванный анализировать одну из 16 секций. Если процесс обнаруживает, что один из его объектов переходит через границу секции, этот процесс просто переходит вслед за объектом в следующую секцию, считывая слова этой секции. В нашем примере некоторые объекты обрабатываются несколькими процессами, поэтому в конце потребуется некоторая координация, чтобы определить количество домов, деревьев и самолетов.
Мультипроцессор, как и все компьютеры, должен содержать устройства ввода-вывода (диски, сетевые адаптеры и т. п.). В одних мультипроцессорных системах только определенные процессоры получают доступ к устройствам ввода-вывода и, следовательно, обладают специальными средствами ввода-вывода. В других мультипроцессорных системах каждый процессор может получить доступ к любому устройству ввода-вывода. Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода, и между процессорами возможна полная взаимозаменяемость, такой мультипроцессор называется симметричным (Symmetrie Multiprocessor, SMP).
Поскольку все процессоры в мультипроцессоре используют единое адресное пространство, функционирует только одна копия операционной системы. Соответственно, имеется только одна карта страниц памяти и одна таблица процессов. Когда процесс блокируется, его процессор сохраняет свое состояние в таблицах операционной системы, а затем просматривает эти таблицы в поисках другого процесса, который нужно запустить. Именно такая организация, в основе которой лежит единая система, и отличает мультипроцессор от мультикомпьютера.
Мы обсудим мультипроцессоры и мультикомпьютеры в этой главе.
Межпроцессорные системные соединения
Параллельная обработка требует использования эффективных системных соединений для быстрой связи между входом / выходом и периферийными устройствами, мультипроцессорами и общей памятью.
Иерархические шинные системы
Иерархическая система шин состоит из иерархии шин, соединяющих различные системы и подсистемы / компоненты в компьютере. Каждая шина состоит из нескольких сигнальных, управляющих и силовых линий. Различные шины, такие как местные шины, шины объединительной платы и шины ввода / вывода, используются для выполнения различных функций соединения.
Местные автобусы — это автобусы, установленные на печатных платах. Шина объединительной платы — это печатная плата, на которой используется множество разъемов для подключения функциональных плат. Шины, которые подключают устройства ввода-вывода к компьютерной системе, называются шинами ввода-вывода.
Перекладина и многопортовая память
Коммутируемые сети обеспечивают динамическое соединение между входами и выходами. В системах малого или среднего размера чаще всего используются перекрестные сети. Многоступенчатые сети могут быть расширены до более крупных систем, если проблема увеличенной задержки может быть решена.
Как кросс-коммутатор, так и многопортовая организация памяти являются одноступенчатой сетью. Хотя создание одноступенчатой сети обходится дешевле, но для установления определенных соединений может потребоваться несколько проходов. Многоступенчатая сеть имеет более одной ступени распределительных коробок. Эти сети должны иметь возможность подключать любой вход к любому выходу.
Многоступенчатые и объединяющие сети
Многоступенчатые сети или многоступенчатые сети присоединения представляют собой класс высокоскоростных компьютерных сетей, который в основном состоит из элементов обработки на одном конце сети и элементов памяти на другом конце, соединенных коммутационными элементами.
Эти сети применяются для создания больших многопроцессорных систем. Это включает в себя Omega Network, Butterfly Network и многое другое.
Мультикомпьютеры
Мультикомпьютеры — это MIMD-архитектуры с распределенной памятью. Следующая диаграмма показывает концептуальную модель мультикомпьютера —
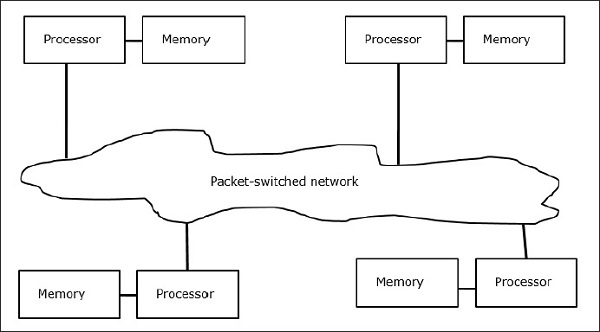
Отсутствие глобально доступной памяти является недостатком мультикомпьютеров. Это можно решить с помощью следующих двух схем —
Виртуальная общая память (VSM)
VSM — это аппаратная реализация. Таким образом, система виртуальной памяти операционной системы прозрачно реализована поверх VSM. Таким образом, операционная система считает, что она работает на машине с общей памятью.
Общая виртуальная память (SVM)
SVM — это программная реализация на уровне операционной системы с аппаратной поддержкой модуля управления памятью (MMU) процессора. Здесь единица обмена — страницы памяти операционной системы.
Если процессор обращается к определенной ячейке памяти, MMU определяет, находится ли страница памяти, связанная с доступом к памяти, в локальной памяти или нет. Если страница отсутствует в памяти, в обычной компьютерной системе она выгружается операционной системой с диска. Но в SVM операционная система выбирает страницу с удаленного узла, которому принадлежит эта конкретная страница.
Три поколения мультикомпьютеров
В этом разделе мы обсудим три поколения мультикомпьютеров.
Выбор дизайна в прошлом
Выбирая технологию процессора, проектировщик мультикомпьютера выбирает недорогие средние процессоры зерна как строительные блоки. Большинство параллельных компьютеров построены со стандартными готовыми микропроцессорами. Распределенная память была выбрана для нескольких компьютеров, а не для использования общей памяти, что ограничивало бы масштабируемость. Каждый процессор имеет свой собственный локальный блок памяти.
Настоящее и будущее развитие
Компьютеры следующего поколения превратились из мультикомпьютеров среднего и мелкого размера в глобальную виртуальную память. Мультикомпьютеры второго поколения все еще используются в настоящее время. Но с использованием более качественных процессоров, таких как i386, i860 и т. Д., Компьютеры второго поколения получили большое развитие.
Компьютеры третьего поколения — это компьютеры следующего поколения, где будут использоваться узлы, реализованные с помощью VLSI. Каждый узел может иметь процессор 14 MIPS, каналы маршрутизации 20 МБ / с и 16 КБ ОЗУ, интегрированные в один чип.
Система Intel Paragon
Ранее для создания мультикомпьютеров гиперкубов использовались однородные узлы, поскольку все функции были переданы хосту. Таким образом, это ограничило пропускную способность ввода / вывода. Таким образом, для эффективного решения крупномасштабных задач или с высокой пропускной способностью эти компьютеры нельзя было использовать. Система Intel Paragon была разработана для преодоления этой трудности. Он превратил мультикомпьютер в сервер приложений с многопользовательским доступом в сетевой среде.
В мультикомпьютере со схемой хранения и прямой маршрутизации пакеты являются наименьшей единицей передачи информации. В сетях, маршрутизируемых через червоточину, пакеты делятся на флиты. Длина пакета определяется схемой маршрутизации и реализацией сети, тогда как длина переброса зависит от размера сети.
При хранении и прямой маршрутизации пакеты являются основной единицей передачи информации. В этом случае каждый узел использует буфер пакетов. Пакет передается от исходного узла к узлу назначения через последовательность промежуточных узлов. Задержка прямо пропорциональна расстоянию между источником и пунктом назначения.
При маршрутизации по червоточине передача от исходного узла к узлу назначения осуществляется через последовательность маршрутизаторов. Все кадры одного и того же пакета передаются в неразделимой последовательности конвейерным способом. В этом случае только заголовок flit знает, куда идет пакет.
Тупик и виртуальные каналы
Виртуальный канал — это логическая связь между двумя узлами. Он образован буфером в исходном узле и узле приемника и физическим каналом между ними. Когда физический канал выделяется для пары, один исходный буфер соединяется с одним приемным буфером для формирования виртуального канала.
Читайте также:
- Как прогресс науки и техники влияет на образ жизни людей кратко
- Какое событие помогло герою раскрыть свой характер мцыри кратко
- Для чего проводят конкурсы в школе
- Подумайте почему религиозному образованию мусульман страны уделяется особое внимание кратко
- Что такое функциональная группа в химии кратко