
Критерий согласия хи квадрат кратко
Обновлено: 08.07.2024
Хи-квадрат Пирсона один из самых популярных статистических критериев для анализа качественных данных (номинальных, порядковых, ранговых), анализа частот. Однако, как и у каждого статистического критерия у хи-квадрата есть свои собственные правила применения метода, его интерпретации. Для того, чтобы Вы могли успешно овладеть этим ценнейшим статистическим инструментом сравнения статистических совокупностей по качественным данным предлагаем Вам ознакомиться с этой учебной статьей.
Как использовать хи-квадрат Пирсона?
Хи-квадрат используется прежде всего для анализа таблиц сопряженности (вид таблицы, которая учитывает совместное влияние фактора на исход, данные в таблице сопряженности должны быть представлены в виде частоты номинальных данных или интервалами, но не непрерывными количественными величинами). Стоит отметить, что при работе с сопряженными таблицами хи-квадрат часто является поддержкой для анализа влияния факторов риска с помощью расчета рисков (абсолютный и относительный риски) и отношение шансов.
Таблицы сопряженности могут принимать различные формы, простейшая таблица сопряженности выглядит следующим образом:
| Исход есть | Исхода нет | Всего | |
| Фактор риска есть | A | B | A+B |
| Фактора риска нет | C | D | C+D |
| Всего | A+C | B+D | A+B+C+D |
Как заполнить таблицу сопряженности? Обратимся к простому примеру:
Например, Вы хотите с помощью таблицы сопряженности и как следствия хи-квадрата Пирсона выяснить есть ли различия в частоте артериальной гипертонии в группах курящего и некурящего населения. Предполагается, что по остальным параметрам Ваши группы равномерны и превалирующим фактором риска развития артериальной гипертензии будет именно курение.
Для проведения исследования на основании ретроспективных данных (дизайн: случай-контроль) были отобраны две группы исследуемых — в первую вошли 70 человек, ежедневно выкуривающих не менее 1 пачки сигарет, во вторую группу вошли 80 некурящих такого же возраста, пола, и социального уровня (прочие систематически ошибки случайны).
Имея эти данные мы можем заполнить простейшую таблицу сопряженности:
АД- артериальное давление
Как видно из таблицы: каждая строка соответствует группе пациентов, которая подвергается влиянию фактора, каждый столбец, в свою очередь, обозначает частоту исходов в группе (к примеру: произошло/ не произошло, как в нашем примере).
Условия применения статистического критерия хи-квадрата Пирсона
- Тип данных: параметры должны быть качественными цельночисленными частотами, измеренными в номинальной шкале (Например, тип диагноза)
бинарными (пол: мужской/женский, наличие или отсутствие заболевания)
порядковыми (степень артериальной гипертензии),
- Желательно, чтобы общее количество наблюдений было более 20,
- Ожидаемая частота, соответствующая нулевой гипотезе должна быть более 5, если ожидаемое явление принимает значение менее 5, то необходимо использовать точный Критерий Фишера.
- Для четырехпольных таблиц (2х2): Если ожидаемое значение принимает значение менее 10 (а именно 5 2 /E
| Степень нарушения кровообращения | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | 49/13=3,77 | 16/12=1,33 | 9/5=1,80 |
| III | 81/34=2,38 | 144/32=4,50 | 9/14=0,64 |
| IV | 256/26=9,85 | 256/24=10,66 | 0/10*=0,10 |
| Всего | 16 | 16,49 | 2,54 |
как видно из данной таблицы одно из ожидаемых значений равно 0, в данном случае будет подставлена 1, корректнее применить точный критерий Фишера (см. Условия применения хи-квадрата Пирсона)
Четвертый этап

Необходимо соотнести полученное значение хи-квадрата с критическим значением хи-квадрата.Возникает вопрос, откуда брать критическое значение? Критическое значение хи-квадрата, как и для большинства, статистических критериев зависит от степени свободы и уровня достоверности (alpha), который Вы выбираете.В нашем случае, наше количество степеней свободы равно (3-1)*(3-1)=4, уровень значимости, который мы хотим соблюсти равен 0,05Обратимся к таблице критических значение хи-квадрата:
- Xи-квадрат (для d.f.=4 p=0.05) = 9.488
- Xи-квадрат (для d.f.=4 p=0.01) = 13.27735,03 > 13,277;
- p 2 =35,03, p 2 = (40х48 – 32х30)х150 / (70)(80)(72)(78) = (1920 – 960) 2 х150/31449600 = 138240000/31449600 = 4,395
- Сравним полученное значение хи-квадрата с критическим значением (для степени свободы 1, и уровнем значимости 3,841)
Правильная интерпретация: Курение оказывает влияние на формирование повышенного артериального давления df=1, x 2 = 4,395, p
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
До конца XIX века нормальное распределение считалась всеобщим законом вариации данных. Однако К. Пирсон заметил, что эмпирические частоты могут сильно отличаться от нормального распределения. Встал вопрос, как это доказать. Требовалось не только графическое сопоставление, которое имеет субъективный характер, но и строгое количественное обоснование.
Так был изобретен критерий χ 2 (хи квадрат), который проверяет значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Это произошло в далеком 1900 году, однако критерий и сегодня на ходу. Более того, его приспособили для решения широкого круга задач. Прежде всего, это анализ категориальных данных, т.е. таких, которые выражаются не количеством, а принадлежностью к какой-то категории. Например, класс автомобиля, пол участника эксперимента, вид растения и т.д. К таким данным нельзя применять математические операции вроде сложения и умножения, для них можно только подсчитать частоты.
Наблюдаемые частоты обозначим О (Observed), ожидаемые – E (Expected). В качестве примера возьмем результат 60-кратного бросания игральной кости. Если она симметрична и однородна, вероятность выпадения любой стороны равна 1/6 и, следовательно, ожидаемое количество выпадения каждой из сторон равна 10 (1/6∙60). Наблюдаемые и ожидаемые частоты запишем в таблицу и нарисуем гистограмму.

Нулевая гипотеза заключается в том, что частоты согласованы, то есть фактические данные не противоречат ожидаемым. Альтернативная гипотеза – отклонения в частотах выходят за рамки случайных колебаний, расхождения статистически значимы. Чтобы сделать строгий вывод, нам потребуется.
- Обобщающая мера расхождения между наблюдаемыми и ожидаемыми частотами.
- Распределение этой меры при справедливости гипотезы о том, что различий нет.
Начнем с расстояния между частотами. Если взять просто разницу О — E, то такая мера будет зависеть от масштаба данных (частот). Например, 20 — 5 =15 и 1020 – 1005 = 15. В обоих случаях разница составляет 15. Но в первом случае ожидаемые частоты в 3 раза меньше наблюдаемых, а во втором случае – лишь на 1,5%. Нужна относительная мера, не зависящая от масштаба.
Обратим внимание на следующие факты. В общем случае количество категорий, по которым измеряются частоты, может быть гораздо больше, поэтому вероятность того, что отдельно взятое наблюдение попадет в ту или иную категорию, довольно мала. Раз так, то, распределение такой случайной величины будет подчинятся закону редких событий, известному под названием закон Пуассона. В законе Пуассона, как известно, значение математического ожидания и дисперсии совпадают (параметр λ). Значит, ожидаемая частота для некоторой категории номинальной переменной Ei будет являться одновременное и ее дисперсией. Далее, закон Пуассона при большом количестве наблюдений стремится к нормальному. Соединяя эти два факта, получаем, что, если гипотеза о согласии наблюдаемых и ожидаемых частот верна, то, при большом количестве наблюдений, выражение
Важно помнить, что нормальность будет проявляться только при достаточно больших частотах. В статистике принято считать, что общее количество наблюдений (сумма частот) должна быть не менее 50 и ожидаемая частота в каждой группе должна быть не менее 5. Только в этом случае величина, показанная выше, имеет стандартное нормальное распределение. Предположим, что это условие выполнено.
У стандартного нормального распределения почти все значение находятся в пределах ±3 (правило трех сигм). Таким образом, мы получили относительную разность в частотах для одной группы. Нам нужна обобщающая мера. Просто сложить все отклонения нельзя – получим 0 (догадайтесь почему). Пирсон предложил сложить квадраты этих отклонений.
Это и есть статистика для критерия Хи-квадрат Пирсона. Если частоты действительно соответствуют ожидаемым, то значение статистики Хи-квадрат будет относительно не большим (отклонения находятся близко к нулю). Большое значение статистики свидетельствует в пользу существенных различий между частотами.
Как нетрудно заметить, величина хи-квадрат также зависит от количества слагаемых. Чем больше слагаемых, тем больше ожидается значение статистики, ведь каждое слагаемое вносит свой вклад в общую сумму. Следовательно, для каждого количества независимых слагаемых, будет собственное распределение. Получается, что χ 2 – это целое семейство распределений.
И здесь мы подошли к одному щекотливому моменту. Что такое число независимых слагаемых? Вроде как любое слагаемое (т.е. отклонение) независимо. К. Пирсон тоже так думал, но оказался неправ. На самом деле число независимых слагаемых будет на один меньше, чем количество групп номинальной переменной n. Почему? Потому что, если мы имеем выборку, по которой уже посчитана сумма частот, то одну из частот всегда можно определить, как разность общего количества и суммой всех остальных. Отсюда и вариация будет несколько меньше. Данный факт Рональд Фишер заметил лет через 20 после разработки Пирсоном своего критерия. Даже таблицы пришлось переделывать.
По этому поводу Фишер ввел в статистику новое понятие – степень свободы (degrees of freedom), которое и представляет собой количество независимых слагаемых в сумме. Понятие степеней свободы имеет математическое объяснение и проявляется только в распределениях, связанных с нормальным (Стьюдента, Фишера-Снедекора и сам Хи-квадрат).
Чтобы лучше уловить смысл степеней свободы, обратимся к физическому аналогу. Представим точку, свободно движущуюся в пространстве. Она имеет 3 степени свободы, т.к. может перемещаться в любом направлении трехмерного пространства. Если точка движется по какой-либо поверхности, то у нее уже две степени свободы (вперед-назад, вправо-влево), хотя и продолжает находиться в трехмерном пространстве. Точка, перемещающаяся по пружине, снова находится в трехмерном пространстве, но имеет лишь одну степень свободы, т.к. может двигаться либо вперед, либо назад. Как видно, пространство, где находится объект, не всегда соответствует реальной свободе перемещения.
Примерно также распределение статистики может зависеть от меньшего количества элементов, чем нужно слагаемых для его расчета. В общем случае количество степеней свободы меньше наблюдений на число имеющихся зависимостей.
Таким образом, распределение хи квадрат (χ 2 ) – это семейство распределений, каждое из которых зависит от параметра степеней свободы. Формальное определение следующее. Распределение χ 2 (хи-квадрат) с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Далее можно было бы перейти к самой формуле, по которой вычисляется функция распределения хи-квадрат, но, к счастью, все давно подсчитано за нас. Чтобы получить интересующую вероятность, можно воспользоваться либо соответствующей статистической таблицей, либо готовой функцией в Excel.
Интересно посмотреть, как меняется форма распределения хи-квадрат в зависимости от количества степеней свободы.
С увеличением степеней свободы распределение хи-квадрат стремится к нормальному. Это объясняется действием центральной предельной теоремы, согласно которой сумма большого количества независимых случайных величин имеет нормальное распределение. Про квадраты там ничего не сказано )).
Проверка гипотезы по критерию Хи квадрат Пирсона
Вот мы и подошли к проверке гипотез по методу хи-квадрат. В целом техника остается прежней. Выдвигается нулевая гипотеза о том, что наблюдаемые частоты соответствуют ожидаемым (т.е. между ними нет разницы, т.к. они взяты из той же генеральной совокупности). Если этот так, то разброс будет относительно небольшим, в пределах случайных колебаний. Меру разброса определяют по статистике Хи-квадрат. Далее либо полученную статистику сравнивают с критическим значением (для соответствующего уровня значимости и степеней свободы), либо, что более правильно, рассчитывают наблюдаемый p-value, т.е. вероятность получить такое или еще больше значение статистики при справедливости нулевой гипотезы.

Т.к. нас интересует согласие частот, то отклонение гипотезы произойдет, когда статистика окажется больше критического уровня. Т.е. критерий является односторонним. Однако иногда (иногда) требуется проверить левостороннюю гипотезу. Например, когда эмпирические данные уж оооочень сильно похожи на теоретические. Тогда критерий может попасть в маловероятную область, но уже слева. Дело в том, что в естественных условиях, маловероятно получить частоты, практически совпадающие с теоретическими. Всегда есть некоторая случайность, которая дает погрешность. А вот если такой погрешности нет, то, возможно, данные были сфальсифицированы. Но все же обычно проверяют правостороннюю гипотезу.
Вернемся к задаче с игральной костью. Рассчитаем по имеющимся данным значение статистики критерия хи-квадрат.
![]()
Теперь найдем критическое значение при 5-ти степенях свободы (k) и уровне значимости 0,05 (α) по таблице критических значений распределения хи квадрат.

То есть квантиль 0,05 хи квадрат распределения (правый хвост) с 5-ю степенями свободы χ 2 0,05; 5 = 11,1.
Сравним фактическое и табличное значение. 3,4 (χ 2 ) 2 0,05; 5). Расчетный значение оказалось меньшим, значит гипотеза о равенстве (согласии) частот не отклоняется. На рисунке ситуация выглядит вот так.

Если бы расчетное значение попало в критическую область, то нулевая гипотеза была бы отклонена.
Более правильным будет рассчитать еще и p-value. Для этого нужно в таблице найти ближайшее значение для заданного количества степеней свободы и посмотреть соответствующий ему уровень значимости. Но это прошлый век. Воспользуемся ЭВМ, в частности MS Excel. В эксель есть несколько функций, связанных с хи-квадрат.
Ниже их краткое описание.
ХИ2.ОБР – критическое значение Хи-квадрат при заданной вероятности слева (как в статистических таблицах)
ХИ2.ОБР.ПХ – критическое значение при заданной вероятности справа. Функция по сути дублирует предыдущую. Но здесь можно сразу указывать уровень α, а не вычитать его из 1. Это более удобно, т.к. в большинстве случаев нужен именно правый хвост распределения.
ХИ2.РАСП – p-value слева (можно рассчитать плотность).
ХИ2.РАСП.ПХ – p-value справа.
ХИ2.ТЕСТ – по двум диапазонам частот сразу проводит тест хи-квадрат. Количество степеней свободы берется на одну меньше, чем количество частот в столбце (так и должно быть), возвращая значение p-value.
Давайте пока рассчитаем для нашего эксперимента критическое (табличное) значение для 5-ти степеней свободы и альфа 0,05. Формула Excel будет выглядеть так:
Результат будет одинаковым – 11,0705. Именно это значение мы видим в таблице (округленное до 1 знака после запятой).
Рассчитаем, наконец, p-value для 5-ти степеней свободы критерия χ 2 = 3,4. Нужна вероятность справа, поэтому берем функцию с добавкой ПХ (правый хвост)
Значит, при 5-ти степенях свободы вероятность получить значение критерия χ 2 = 3,4 и больше равна почти 64%. Естественно, гипотеза не отклоняется (p-value больше 5%), частоты очень хорошо согласуются.
А теперь проверим гипотезу о согласии частот с помощью теста хи квадрат и функции Excel ХИ2.ТЕСТ.

Никаких таблиц, никаких громоздких расчетов. Указав в качестве аргументов функции столбцы с наблюдаемыми и ожидаемыми частотами, сразу получаем p-value. Красота.
Представим теперь, что вы играете в кости с подозрительным типом. Распределение очков от 1 до 5 остается прежним, но он выкидывает 26 шестерок (количество всех бросков становится 78).

p-value в этом случае оказывается 0,003, что гораздо меньше чем, 0,05. Есть серьезные основания сомневаться в правильности игральной кости. Вот, как выглядит эта вероятность на диаграмме распределения хи-квадрат.

Статистика критерия хи-квадрат здесь получается 17,8, что, естественно, больше табличного (11,1).
Надеюсь, мне удалось объяснить, что такое критерий согласия χ 2 (хи-квадрат) Пирсона и как с его помощью проверяются статистические гипотезы.
Напоследок еще раз о важном условии! Критерий хи-квадрат исправно работает только в случае, когда количество всех частот превышает 50, а минимальное ожидаемое значение для каждой группы не меньше 5. Если в какой-либо категории ожидаемая частота менее 5, но при этом сумма всех частот превышает 50, то такую категорию объединяют с ближайшей, чтобы их общая частота превысила 5. Если это сделать невозможно, или сумма частот меньше 50, то следует использовать более точные методы проверки гипотез. О них поговорим в другой раз.
Ниже находится видео ролик о том, как в Excel проверить гипотезу с помощью критерия хи-квадрат.
Итак, после разгрома двух десятков задач ставим вишенку на торт статистических гипотез, а именно разбираем важнейшую гипотезу о виде (законе) распределения и распространённые тематические примеры. Кино тоже будет.
Рассмотрим генеральную совокупность, распределение которой неизвестно. Однако есть основание полагать, что она распределена по некоторому закону (чаще всего, нормально). Это предположение может появиться как до, так и в результате статистического исследования, когда мы извлекли и изучили выборку объёма .
И нам требуется на уровне значимости проверить нулевую гипотезу – о том, что генеральная совокупность распределена по закону против конкурирующей гипотезы о том, что она по нему НЕ распределена.
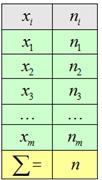
Как проверить эту гипотезу? Постараюсь объяснить кратко. Как вы знаете, выборочные данные группируются в дискретный или интервальный вариационный ряд с вариантами и соответствующими частотами
Поскольку эти данные взяты из практического опыта, то выборочный вариационный ряд называют эмпирическим рядом, а частоты – эмпирическими частотами.
Далее строятся графики, рассчитываются выборочные характеристики (выборочная средняя , выборочная дисперсия и другие), словом, выполняются все те хорошие дела, которыми мы занимались на протяжении многих уроков.
И возникает вопрос: значимо или незначимо различие между эмпирическими и соответствующими теоретическими частотами?
Для ответа на это вопрос рассматривают различные статистические критерии, которые называют критериями согласия, и наиболее популярный из них разработал Карл Пирсон:
При достаточно большом (объёме выборки) распределение этой случайной величины близкО к распределению хи-квадрат с количеством степеней свободы , где – количество оцениваемых параметров закона .
…всем понятно, почему величина случайная? – по той причине, что в разных выборках мы будем получать разные, заранее непредсказуемые эмпирические частоты.

Далее строится правосторонняя критическая область:
Критическое значение можно отыскать с помощью соответствующей таблицы или Экселя (Пункт 11б).
Наблюдаемое значение критерия рассчитывается по эмпирическим и найденным теоретическим частотам:
Если , то на уровне значимости нет оснований отвергать гипотезу о том, что генеральная совокупность распределена по закону . То есть, различие между эмпирическими и теоретическими частотами незначимо и обусловлено случайными факторами (случайностью самой выборки, способом группировки данных и т.д.)
Если , то нулевую гипотезу отвергаем, иными словами эмпирические и теоретические частоты отличаются значимо, и это различие вряд ли случайно.
Обратите внимание на формулировку, которую я выделил жирным цветом – такая формулировка напоминает нам о том, что принятие статистической гипотезы ещё не означает её истинность, поскольку существует -вероятность того, что мы приняли неправильную гипотезу (совершили ошибку второго рода).
И, наконец, бараны коровы, которые нас уже заждались. Реалистичность фактических данных оставлю на совести автора методички сельскохозяйственной академии:

По результатам выборочного исследования найдено распределение средних удоев молока в фермерском хозяйстве (литров) от одной коровы за день:
На уровне значимости 0,05 проверить гипотезу о том, что генеральная совокупность (средний удой коров всей фермы) распределена нормально. Построить эмпирическую гистограмму и теоретическую кривую.
…если не любите молоко, то пусть это будет чай, сок, пиво или какой-то другой напиток, который вам нравится :) Чтобы было интереснее исследовать эту волшебную ферму.
Решение: на уровне значимости проверим гипотезу о нормальном распределении генеральной совокупности против конкурирующей гипотезы о том, что она так НЕ распределена. Используем критерий согласия Пирсона .
Эмпирические частоты известны из предложенного интервального ряда, и осталось найти теоретические. Для этого нужно вычислить выборочную среднюю и выборочное стандартное отклонение .
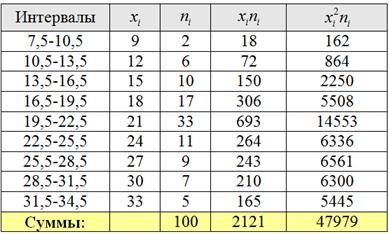
Выберем в качестве вариант середины частичных интервалов (длина каждого интервала ) и заполним расчётную таблицу:
Внимание! Если вы не понимаете, как заполнять эту таблицу, или не знаете, как это сделать быстро, то обязательно обратитесь к Примеру 16, там есть все объяснения и видео!
Вычислим выборочную среднюю:
литра
Выборочную дисперсию вычислим по формуле:
И выборочное стандартное отклонение:
литра.
По причине большого объёма выборки его исправлением можно пренебречь.
Теоретические частоты рассчитываются по формуле:
, где – знакомая функция Гаусса, а .
Все вычисления удобно проводить в Экселе и на всякий случай я распишу одну строчку:
– здесь выгодно использоваться встроенную экселевскую функцию =НОРМРАСП(-2,23; 0; 1; 0), первый аргумент которой равен текущему значению . За неимением Экселя и калькулятора пользуйтесь стандартной таблицей, которая есть практически в любой книге по терверу.
И, наконец, теоретическая частота:
, довольно часто её округляют до целого значения, но без округления результат всё же точнее.
Надеюсь, на данный момент уже все умеют протягивать (копировать) формулы по образцу, а если нет, то я всё равно научу :) Решил таки записать отдельный ролик, хотя особой технической новизны тут нет:

Как проверить гипотезу о норм. распределении генеральной совокупности? (Ютуб)
Дальнейшая задача состоит в том, чтобы оценить, насколько ЗНАЧИМО отличаются эмпирические частоты (ступеньки гистограммы) от соответствующих теоретических частот (уровень коричневых точек).
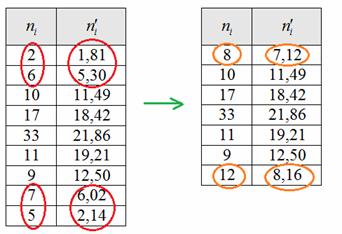
Но перед тем, как сравнивать теоретические и эмпирические частоты, следует объединить интервалы с малыми (меньше пяти) частотами. В данном случае объединяем два первых и два последних интервала, для этого суммируем частоты, обведённые красным цветом, и получаем оранжевые результаты:
Это нужно для того, чтобы сгладить неоправданно большое расхождением между малыми частотами по краям выборки. Действие не обязательное, но крайне желательное, ибо студентов на моей памяти часто заставляли переделывать задание.
Найдём критическое значение критерия согласия Пирсона. Количество степеней свободы определяется по формуле , где – количество интервалов, а – количество оцениваемых параметров рассматриваемого закона распределения.
Так как мы объединяли интервалы, то теперь их не девять, а .
У нормального закона мы оцениваем параметра.
Пояснение: – это оценка неизвестного генерального матоожидания, а – это оценка неизвестного генерального стандартного отклонения, итого два оцениваемых параметра.
Таким образом, и для уровня значимости :
Это значение можно найти по таблице критических значений распределения хи-квадрат или с помощью Калькулятора (Пункт 11б).
При нулевая гипотеза отвергается, а при таких оснований нет:
Вычислим наблюдаемое значение критерия (суть – сумму расхождений между частотами), и для этого удобно заполнить ещё одну расчётную табличку:
На всякий пожарный пример расчёта: .
В нижней строке таблицы у нас получилось готовое значение , поэтому на уровне значимости 0,05 гипотезу о нормальном распределении генеральной совокупности отвергаем.
Иными словами различие между эмпирическими и теоретическими частотами статистически значимо и вряд ли объяснимо случайными факторами. При этом с вероятностью 5% мы совершили ошибку 1-го рода (то есть, ген. совокупность на самом деле распределена нормально, но мы это отвергли).
Ответ: на уровне значимости 0,05 гипотезу о нормальном распределении отвергаем
В чём может быть причина? Ведь по теореме Ляпунова большинство коров не оказывает практически никакого влияния на удой других коров, и поэтому распределение ген. совокупности должно быть близкО к нормальному.
Причины могут быть разными. Например, неоднородный состав совокупности (коровы разной породы), или на ферме есть VIP-хлев, где коровы получают улучшенное питание :) А может быть, некоторые коровы больны и как раз оказывают существенное влияние на остальных, в связи с чем нарушается условие теоремы Ляпунова.
Интересно отметить, что при уменьшении уровня значимости до 0,01 критическое значение , и гипотеза о нормальном распределении уже принимается. Однако не нужно забывать, что здесь выросла -вероятность того, что мы приняли неправильную гипотезу. С оценкой этой вероятности можно ознакомиться в специализированной литературе по статистике.
И, конечно, в случае сомнений имеет смысл увеличить объём выборки, чтобы провести повторное исследование.
На основании исследования выборки выдвинуть гипотезу о законе распределения генеральной совокупности
То есть, здесь не говорится о том, что предполагаемый закон нормальный (или какой-то другой) – этот вопрос вам предлагается проанализировать самостоятельно.
Каким образом это можно сделать?
Во-первых, гипотезу можно выдвинуть априорно, даже не исследуя выборку, и зависеть она будет от содержания задачи. Так, для коров используем упомянутую выше теорему Ляпунова: если каждый объект совокупности оказывает несущественное влияние на всю совокупность, то её распределение близкО к нормальному. Если речь идёт о погрешностях округления, то распределены они обычно равномерно. Если распадаются радиоактивные изотопы, то, скорее всего, по экспоненциальному закону. И так далее.
Построенная гистограмма по форме напоминает колоколообразный график плотности нормального распределения, и это является веской причиной предположить, что генеральная совокупность распределена нормально. Да, здесь есть слишком высокий средний столбик, но, возможно, это просто случайность выборки.
Если столбики примерно одинаковы по высоте, то предполагаем, что генеральная совокупность распределена равномерно. Для показательного распределения тоже будет своя, характерная гистограмма.
В случае дискретных распределений тоже никаких проблем – строим полигон и смотрим, на что он похож.
Следующие признаки аналитические, приведу их для нормального распределения:
1) У нормального распределения математическое ожидание совпадает с модой и медианой. В нашем случае соответствующие выборочные показатели весьма близкИ друг к другу (матожидание оценивается выборочной средней):
Желающие могут рассчитать моду и медиану самостоятельно. Впрочем, желающими часто становятся поневоле, поскольку задача, которую мы рассматриваем, нередко идёт в комплексе со всеми этими заданиями.
– и в него действительно попадают все коровы!
3) Коэффициенты асимметрии и эксцесса нормального распределения равны нулю. В нашем случае эти характеристики не сказать что сильно, но довольно близкИ к нулю:
На практике в исследование желательно включить все пункты за исключением, возможно, третьего (т.к. асимметрию и эксцесс рассчитывают далеко не всегда).
Следует отметить, что перечисленные выше предпосылки ещё не означают, что соответствующая гипотеза будет принята, в чём мы недавно убедились. А если гипотеза и окажется принятой, то это всё равно на 100% не гарантирует нормальность генеральной совокупности (так как существует -вероятность совершить ошибку 2-го рода – принять неверную гипотезу).
Если вы не прорешали предыдущие пункты, то настоятельно рекомендую это сделать, ну или просто взять готовые числа из образца:
6) По найденным характеристикам сделать вывод о законе эмпирического ряда распределения.
7) Построить нормальную кривую по опытным данным на графике гистограммы.
8) Произвести оценку степени близости теоретического распределения эмпирическому ряду с помощью критерия согласия Пирсона на уровне значимости 0,05.
Как видите, Пункт 6 как раз на обоснование предполагаемого закона распределения. Краткое решение в конце этого урока.

В результате проверки 500 контейнеров со стеклянными изделиями установлено, что число повреждённых изделий имеет следующее эмпирическое распределение:
( – количество повреждённых изделий в контейнере, – количество контейнеров)
С помощью критерия согласия Пирсона на уровне значимости 0,05 проверить гипотезу о том, что случайная величина – число повреждённых изделий распределена по закону Пуассона.
…здесь тоже представьте изделия по своему интересу :)
Все числа уже забиты в макет, придерживайтесь следующего алгоритма:
2) Находим значения для . Вычисления можно проводить на обычном калькуляторе, но удобнее использовать экселевскую функцию =ПУАССОН, Калькулятор (Пункт 7) в помощь.
3) Находим теоретические частоты
5) Рассчитываем наблюдаемое значение критерия и делаем вывод.
Примерный образец чистового оформления задачи в конце урока.
Помимо разобранных примеров, в задачнике В. Е. Гмурмана можно найти аналогичные задачи для биномиального, равномерного и показательного распределения, но лично в моей практике они почти не встречались.
Ну а этот урок и тема подошли к концу, и я надеюсь, вам было хорошо. Но математическая статистика ни в коем случае не закончилась! – есть ещё порох, есть зажигательные разделы, о которых нужно непременно рассказать.
Желаю успехов и до скорых встреч!
Решения и ответы:
Пример 20. Решение (продолжение):
6) Проанализируем полученные результаты:
Форма гистограммы похожа на нормальную кривую.
Выборочная средняя, мода и медиана достаточно близкИ друг другу:
Построим интервал :
– в данный интервал попали все выборочные значения.
Асимметрия практически равна нулю , однако, эксцесс отличается значительно .
Перечисленные признаки позволяют предположить, что генеральная совокупность распределена нормально.
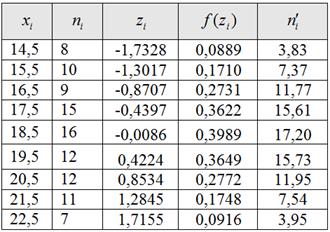
7) Найдём теоретические частоты:
, где , ,
в данной задаче :
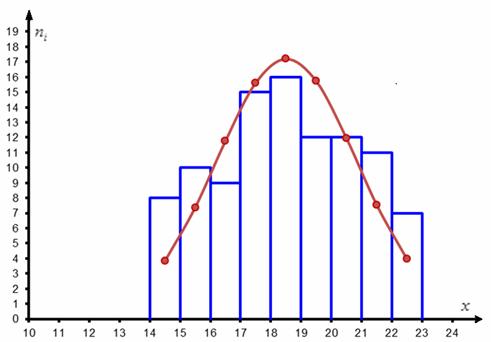
Построим эмпирическую гистограмму и теоретическую кривую:
8) Проверим гипотезу о том, что генеральная совокупность распределена нормально. Используем критерий согласия Пирсона. Для уровня значимости и количества степеней свободы по соответствующей таблице находим критическое значение:
При выдвинутую гипотезу отвергаем, а при нет оснований отвергать гипотезу.
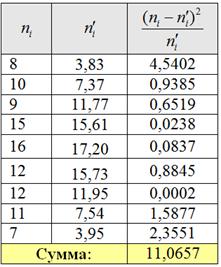
Вычислим наблюдаемое значение критерия . Заполним расчётную таблицу:
В результате: , поэтому на уровне значимости 0,05 нет оснований отвергать гипотезу о нормальном распределении генеральной совокупности.
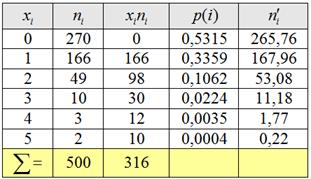
Пример 54. Решение: проверим гипотезу о том, что генеральная совокупность распределена по закону Пуассона. Используем критерий согласия Пирсона. Вычислим произведения , выборочную среднюю и теоретические частоты по формуле , где .
Вычисления сведём в таблицу:
Объединяем две последние варианты ввиду их малых частот и находим критическое значение для уровня значимости и количества степеней свободы :
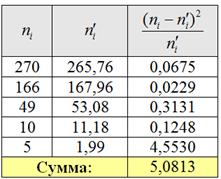
Вычислим наблюдаемое значение критерия :
Таким образом, , поэтому на уровне значимости нет оснований отвергать гипотезу о том, что генеральная совокупность распределена по закону Пуассона.
Автор: Емелин Александр
(Переход на главную страницу)
cкидкa 15% на первый зaкaз, при оформлении введите прoмoкoд: 5530-hihi5

Критерий хи-квадрат (χ 2 , критерий согласия Пирсона) – это метрика, которая измеряет, насколько Модель (Model) сопоставима с фактическими наблюдаемыми данными. Вычисляется с помощью формулы:
Данные, используемые при вычислении этой Статистики (Statistics), должны быть случайными, необработанными, взаимоисключающими, взятыми из независимых переменных и взятыми из достаточно большой Выборки (Sample). Например, результаты подбрасывания монеты соответствуют этим критериям.
При проверке гипотез часто используется критерий Хи-квадрат. Статистика сравнивает размер любых расхождений между ожидаемыми и фактическими результатами, учитывая размер выборки и количество переменных. Для этих тестов используются Степени свободы (Degrees of Freedom), чтобы определить, можно ли отклонить определенную Нулевую гипотезу (Null Hypothesis) на основе общего количества переменных и выборок в эксперименте. Как и в случае с любой другой статистикой, чем больше размер выборки, тем надежнее результаты.
Независимость
При изучении взаимосвязи между полом учащегося и выбранным курсом можно использовать критерий χ2 на независимость. Для проведения этого теста исследователь собирал данные по двум выбранным переменным (пол и выбранные курсы), а затем сравнивал частоту, с которой учащиеся мужского и женского пола выбирали среди предлагаемых классов, используя формулу, приведенную выше, и специальную статистическую таблицу.
Если нет взаимосвязи между полом и выбором курса (то есть, если они независимы), то следует ожидать, что фактическая частота, с которой студенты мужского и женского пола выбирают каждый предлагаемый курс, будет примерно равной. Число учащихся женского пола на любом выбранном курсе должно быть примерно равным доле студентов мужского в выборке. Тест на независимость может охарактеризовать разницу между фактическим наблюдением и теоретическим ожиданием.
Адекватность модели
Критерий Хи-квадрат предоставляет способ проверить, насколько хорошо выборка соответствует характеристикам Генеральной совокупности (Population). Мы не будем использовать выборку, если она не соответствует ожидаемым свойствам интересующей нас совокупности.
Пример. Рассмотрим воображаемую монету с вероятностью выпадения орла или решки ровно 50/50 и реальную монету, которую вы подбрасываете 100 раз. Если эта реальная монета имеет "справедливую" форму, то она также будет иметь равную вероятность приземления с обеих сторон, и ожидаемый результат подбрасывания монеты: орел выпадет 50 раз, и решка столько же. В этом случае критерий может сказать нам, насколько хорошо фактические результаты 100 подбрасываний монеты сравниваются с теоретической моделью, согласно которой честная монета даст результат 50/50. Фактический бросок может составить 50/50, 60/40 или даже 90/10. Чем дальше фактические результаты от 50/50, тем меньше соответствие этого набора бросков теоретическому ожиданию 50/50 и тем более вероятно, что эта монета на самом деле несправедлива.
Критерий Хи-квадрат и SciPy
Критерий можно вычислить с помощью функции SciPy. Для начала импортируем необходимые библиотеки:
Инициируем множества X и y , которые являются Предикторами (Predictor Variable) и Целевой переменной (Target Variable) соответственно:
Переформатируем целевую переменную с помощью метода vstack() ^ то есть превратим массивы 1-y и y в вертикальные массивы. Выполним Векторное перемножение (Dot Product) X и Y и посмотрим на результат:
Это наблюдаемые частоты признаков для каждого класса, то есть Таблица сопряжённости (Contingency Table):
Теперь вычислим ожидаемые значения:
Ожидаемые частоты выглядят так:
Наконец проведем тест Хи-квадрат, и для этого создадим два объекта score – результаты теста, и pval – P-значение (P-Value):
Реальные записи довольно плохо соответствуют ожидаемым, и это легко заметить по среднему низкому значению теста. Интересно, что создатели предполагают отображение 8 знаков после запятой, потому третий элемент ряда, "закончившийся" после третьего знака, так забавно выглядит:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Читайте также: