
В каком направлении развивается архитектура процессоров кратко
Обновлено: 06.07.2024
Несмотря на постоянные улучшения и стабильный прогресс с каждым новым поколением, каких-то фундаментальных сдвигов в индустрии процессоров не происходит уже давно. Переход от ламп к транзисторам был огромным шагом вперёд, также как переход от отдельных компонентов на интегральные схемы. Однако после этого ничего столь же революционного и масштабного не происходило.
Да, транзисторы стали меньше, чипы стали быстрее, а их производительность выросла в сотни раз, но мы начинаем наблюдать застой.
Это четвертая и последняя статья в нашей серии, посвященной разработке и изготовлению процессоров. Начав с высокоуровневого кода, мы узнали, как он компилируется в язык ассемблера и далее – в бинарные инструкции, с которыми работает процессор. Мы заглянули в архитектуру процессоров и поняли, как они обрабатывают инструкции. Затем мы внимательно рассмотрели различные отдельные составляющие процессора.
Мы увидели, как создаются все эти структуры, как обеспечивается согласованная работа миллиардов транзисторов и как из необработанного кремния физически производятся процессоры. Мы узнали об основных свойствах полупроводников и о том, как на самом деле выглядят внутренности чипа.
Перейдём к четвёртой части. Поскольку компании-производители не разглашают результаты исследований и подробности своих актуальных технологий, трудно с уверенностью сказать, что именно находится внутри вашего процессора. Однако мы можем проанализировать современные открытые исследования и понять, в каком направлении движется отрасль.
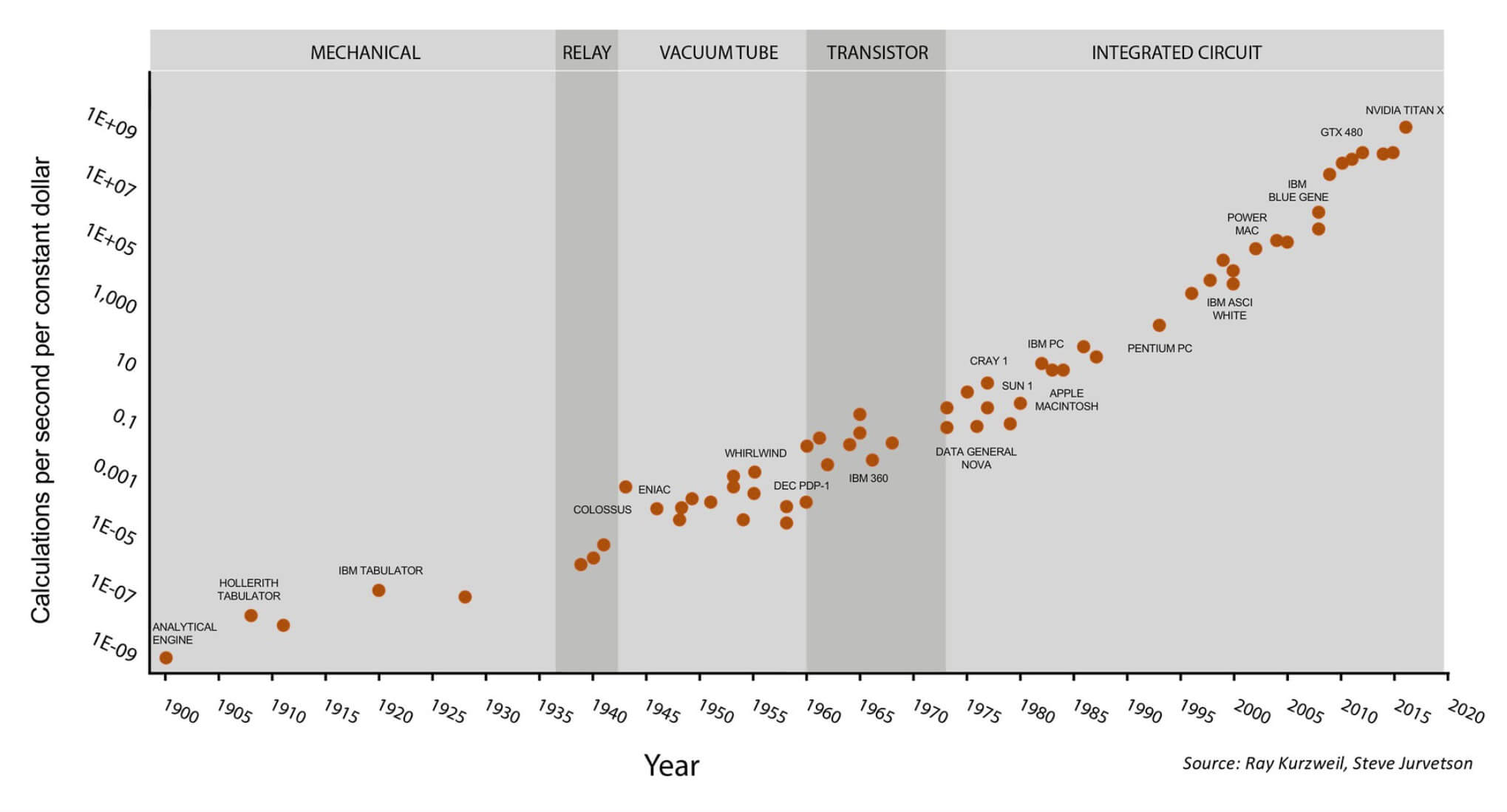
Одним из самых известных способов представления индустрии производства процессоров – это закон Мура, который гласит, что количество транзисторов в чипе удваивается примерно каждые полтора года. Долгое время этот закон оправдывал себя, но в последнее время рост стал замедляться. Транзисторы становятся настолько маленькими, что мы приближаемся к физическому пределу уменьшения размеров. Если не появится какой-либо прорывной технологии, нам придётся в будущем искать какие-то другие способы повышения производительности.
Закон Мура на протяжении последних 120 лет.
Этот график становится ещё интереснее, если обратить внимание на последние 7 точек – они относятся к GPU компании Nvidia, а не к процессорам общего назначения. Сверху: технологические периоды (механические устройства, реле, лампы, транзисторы, интегральные схемы); слева: стоимость вычислений в секунду (в "постоянных долларах"); снизу: годы. Иллюстрация Стива Джарветсона (Steve Jurvetson).
В то же время, очень многообещающе выглядит область квантовых вычислений. Я в этом не специалист, да почти и нет пока настоящих специалистов в этой области, поскольку технология лишь в процессе создания. Чтобы развеять мифы, скажу, что квантовые компьютеры не дадут вам 1000 кадров в секунду при рендеринге в реальном времени, например. Главное преимущество квантовых компьютеров на данный момент состоит в том, что они используют другие, более продвинутые и ранее недостижимые алгоритмы.

Один из прототипов квантового компьютера IBM.
В обычном компьютере транзистор либо включен, либо выключен, что соответствует 1 и 0. В квантовом компьютере возможна суперпозиция, когда бит может быть одновременно 0 и 1. Благодаря этой появившейся возможности ученые-кибернетики разрабатывают новые методы вычислений и могут решать задачи, неразрешимые с помощью существующих вычислительных мощностей. И дело не в том, что квантовые компьютеры быстрее, а в том, что они представляют собой принципиально новую модель вычислений, способную решать множество новых задач.
До массового внедрения этой технологии ещё 10-20 лет, так какие же тенденции наблюдаются сегодня в индустрии процессоров? Активно ведутся десятки исследований в разных областях, но я коснусь лишь нескольких, самых, на мой взгляд, значительных.
Растёт тенденция влияния гетерогенных вычислений. Это метод включения нескольких различных вычислительных элементов в одну систему. Большинству из нас знаком этот метод на примере отдельного GPU в компьютере. Центральный процессор очень гибок в настройке и может выполнять широкий спектр вычислений с адекватной скоростью. С другой стороны, GPU разработан специально для выполнения графических вычислений, таких как матричное перемножение. С подобными типами инструкции они справляются на порядки быстрее центрального процессора. Переложив некоторую часть нагрузки графическими вычислениями с CPU на GPU, мы можем ускорить выполнение расчетов. Любой программист легко оптимизирует своё ПО, нужным образом изменив алгоритм, а вот оптимизировать оборудование гораздо сложнее.
По мере того, как нагрузки становятся все более специализированными, разработчики оборудования включают в свои чипы все больше акселераторов. Провайдеры облачных сервисов, такие как AWS, начали предоставлять разработчикам карты FPGA для ускорения их вычислений в облаке. В отличие от обычных вычислительных элементов, таких как ЦП и GPU, имеющих жёсткую внутреннюю архитектуру, архитектура FPGA гибкая. Это практически программируемое оборудование, которое можно настроить в соответствии с нуждами пользователя.

Взглянув на снимки кристаллов относительно современных процессоров, мы видим, что бо́льшую часть площади ЦП на самом деле занимает не само ядро. Всё бо́льшую долю занимают разного рода ускорители. Это позволило ускорить выполнение очень специализированных вычислений, а также значительно снизить энергопотребление.
Раньше при необходимости добавления в систему обработки видео, разработчики просто добавляли в систему новый чип. Однако это крайне неэффективный подход. Каждый раз, когда сигналу нужно пройти по физическому проводнику от одного чипа к другому, требуется огромное количество энергии на бит. Сама по себе крошечная доля джоуля не кажется особо значительной, но при передаче данных внутри, а не снаружи чипа, она используется на 3-4 порядка эффективнее. Благодаря интеграции таких акселераторов с ЦП, мы наблюдали рост количества чипов со сверхнизким энергопотреблением.
И всё же ускорители не идеальны. Чем больше мы добавляем их в схемы, тем менее гибким становится чип, и мы начинаем жертвовать общей производительностью ради пиковой производительности специализированных видов вычислений. На каком-то этапе весь чип просто превращается в набор акселераторов и перестаёт быть ЦП как таковым. Баланс между производительностью специализированных вычислений и общей производительностью всегда очень тщательно настраивается. Это разногласие между оборудованием общего назначения и специализированными нагрузками называется разрывом специализации (specialization gap).
Если некоторым кажется, что возможности GPU/Machine Learning уже достигли своего апогея, мы можем ожидать, что всё больший объём вычислений будет передаваться специализированным ускорителям. Облачные вычисления и ИИ продолжают развиваться, поэтому GPU выглядят лучшим решением для достижения требуемого уровня объёма вычислений.
Новаторская идея, которую сейчас активно исследуют — это метод под названием Near-Memory Computing (NMC, “околопамятные вычисления”). Вместо того, чтобы извлекать небольшие фрагменты данных из памяти и вычислять их быстрым процессором, исследователи делают наоборот. Они экспериментируют с созданием небольших процессоров непосредственно в контроллерах памяти ОЗУ или SSD. Разместив вычисления ближе к памяти, мы можем получить огромную экономию энергии и времени, ведь теперь нет нужды гонять данные столь много и долго. Вычислительные модули имеют прямой доступ к нужным им данным, поскольку находятся непосредственно в памяти. Эта идея всё ещё находится в зачаточном состоянии, но результаты выглядят многообещающе.
Одно из препятствий, стоящих на пути реализации near-memory computing — это ограничения, накладываемые процессом изготовления чипа. Как говорилось в третьей части, процесс кремниевого производства очень сложен и состоит из десятков этапов. Эти процессы обычно специализированы для изготовления либо быстрых логических элементов, либо элементов памяти. Если попытаться создать чип памяти с помощью процесса, оптимизированного для вычислительных элементов, то получится чип с чрезвычайно низкой плотностью элементов. Если же попробовать создать процессор с помощью процесса, предназначенного для модулей памяти, то получим очень низкую производительность и большие тайминги.
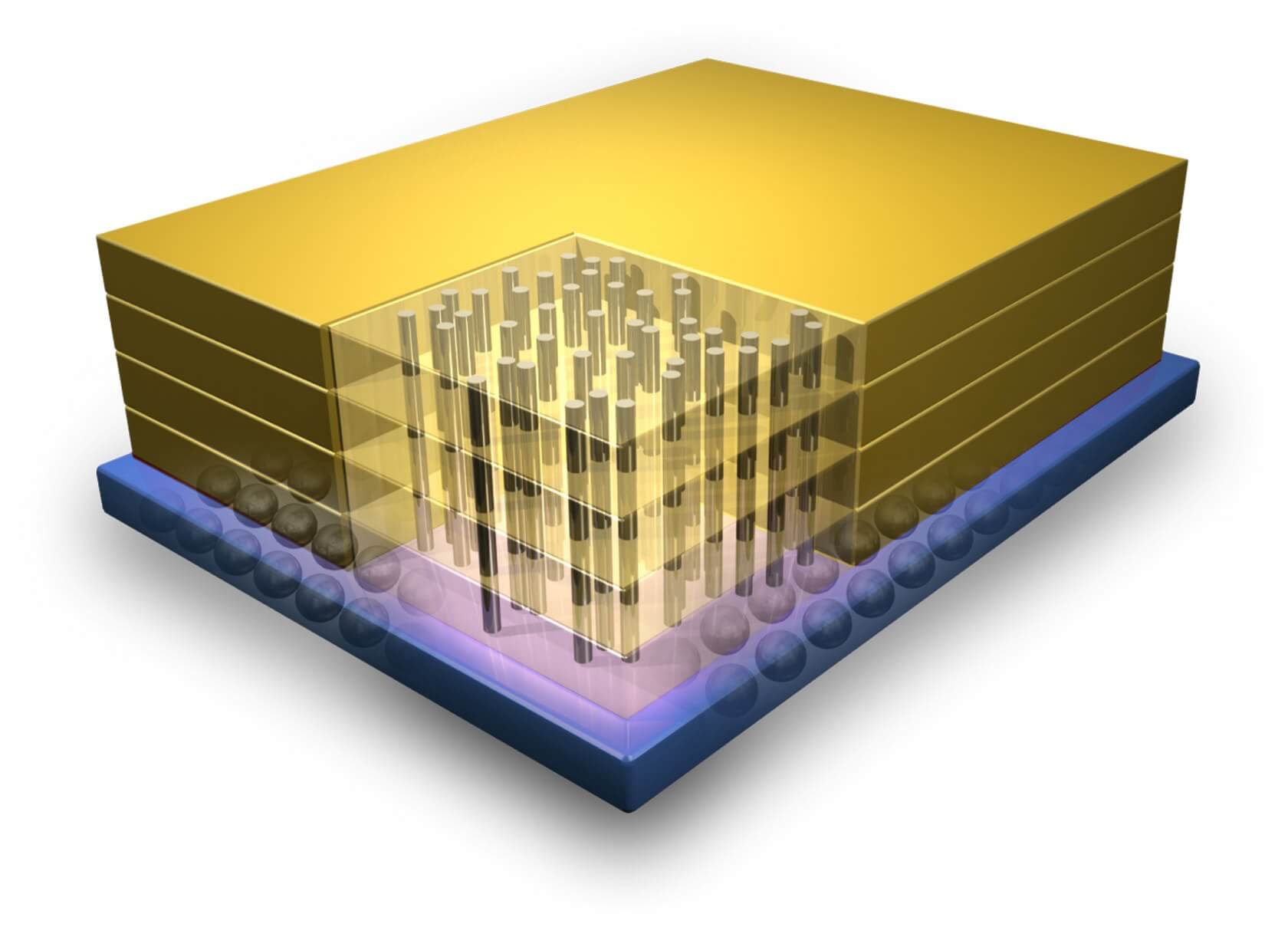
Пример 3D-интеграции, демонстрирующий вертикальные соединения между слоями транзисторов.
Одним из возможных решений этой проблемы является трёхмерная интеграция (3D Integration). Традиционные процессоры обладают одним очень широким слоем транзисторов, и это имеет свои ограничения. Как видно из названия, 3D-интеграция — это процесс расположения нескольких слоёв транзисторов друг над другом для повышения плотности и снижения задержек. Вертикальные проводники, производимые на разных процессах изготовления, используются для соединений между слоями. Эта идея была предложена уже давно, но индустрия отказалась от неё из-за серьёзных сложностей в её реализации. В последнее время мы наблюдаем возникновение технологии накопителей 3D NAND и возрождение этой области исследований.
Уязвимости Spectre и Meltdown — это, вероятно, самые известные примеры того, как проектировщики добавляют функции, значительно ускоряющие процессор, не в полной мере осознавая связанные с этим угрозы. При разработке же современных процессоров гораздо большее внимание уделяется безопасности как ключевой части архитектуры. При её повышении часто страдает производительность, но учитывая ущерб, который компании могут понести из-за появления серьёзных уязвимостей, очевидно, что безопасностью пренебрегать не стоит в той же мере, как производительностью.
В предыдущих частях нашей серии мы коснулись таких техник, как высокоуровневый синтез, позволяющий проектировщикам сначала описать структуру на языке высокого уровня, а затем позволить сложным алгоритмам определить оптимальную для выполнения функции аппаратную конфигурацию. С каждым поколением этапы проектирования становятся всё более дорогостоящими, поэтому инженеры ищут способы ускорения разработки. Следует ожидать, что в дальнейшем и эта тенденция проектирования оборудования при помощи ПО будет только усиливаться.
Будущее предсказать невозможно, но рассмотренные нами в статье инновационные идеи и области исследований могут служить своего рода дорожной картой наших ожиданий в сфере проектирования процессоров будущего. Что с уверенностью можно сказать, так это то, что мы близимся к концу типичных усовершенствований процесса производства. Чтобы и дальше продолжать увеличивать производительность в каждом поколении, разработчикам придётся искать ещё более сложные решения.
Надеемся, что наша серия из четырёх статей пробудила ваш интерес к тому, как проектируются и производятся процессоры, как контролируется их качество и многому другому. Существует бесконечное количество материалов по этой теме, и если бы мы попытались раскрыть их все, то каждая из статей заняла бы целый университетский курс. Хочется надеяться, вы узнали для себя что-то новое и теперь лучше понимаете, насколько сложны компьютеры на каждом из уровней. Если у вас есть предложения, какую тему нам стоит рассмотреть поглубже, мы всегда готовы выслушать их.
От простого к сложному
от медленного к быстрому
к уменьшение энергопотребления и уменьшения размеров кристаллов.
к замене кремния в транзисторах на более производительные вещества.
1) Переводим в двоичную систему счисления, деля число целочисленно на 2 до тех пор, пока не получится 0.
Записываем остатки от деления в обратном порядке.
2)Разбиваем двоичное число на тройки, начиная с младшего разряда: [001][100][000][110][011]
Каждую тройку переводим в восьмиричную систему счисления и записываем "как есть": [1][4][0][6][3].
3)Разбиваем двоичное число на четверки, начиная с младшего разряда: [0001][1000][0011][0011]
Переводим каждую четверку в шестнадцатиричную сисиему счисления и записываем "как есть": [1][8][3][3].
ЭВМ-ЭЛЕКТРОННО ВЫЧИСЛИТЕЛЬНАЯ МАШИНА.
ЭВМ МОЖНО ВНЕДРИТЬ ПОЧТИ ВО ВСЕ ОТРАСЛИ,ТАК КАК ЭТО УЛУЧШАЕТ СКОРОСТЬ И КАЧЕСТВО РАБОТЫ В РАЗЫ.
ПОДУМАЙ ГДЕ ТОЛЬКО НЕТ КОМПЬЮТЕРОВ ЧЕРЕЗ КОТОРЫЕ МОЖНО КОНТРОЛИРОВАТЬ РАБОТУ ИЛИ ПРОСТО ЭКОНОМИТЬ ВРЕМЯ.
ПОКОЛЕНИЕ ЭВМ-ПОКОЛЕНИЕ КОМПЬЮТЕРИЗАЦИИ.
ЭВМ И КИБЕРНЕТИКА СВЯЗАНЫ ПОТОМУ ЧТО 1)КОНТРОЛЬ НАД ВНЕДРЕННЫМ ЧЕМ УГОДНО ОСУЩЕСТВЛЯЕТСЯ ЧЕРЕЗ КОМПЬЮТЕР,2)ПОДДЕРЖАНИЕ РАБОТЫ И ОБЕСПЕЧЕНИЕ ЭТО ВСЕ ТЕЖЕ МОЖЕТ ДРУГИЕ СХЕМЫ КАК В ЭВМ.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
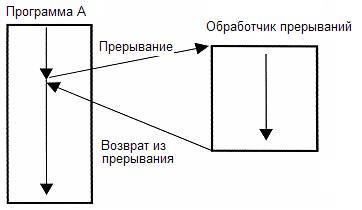
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Прежде чем рассмотреть основные виды архитектур процессоров, необходимо понять, что это такое. Под архитектурой процессора обычно понимают две совершенно разные сущности.
С программной точки зрения архитектура процессора — это совместимость с определённым набором команд (Intel x86), их структуры (система адресации, набор регистров) и способа исполнения (счётчик команд).
Говоря простым языком, это способность программы, собранной для архитектуры x86, работать практически на любой x86-совместимой системе. При этом такая программа не будет работать, например, на ARM системе.
С аппаратной точки зрения архитектура процессора — это некий набор свойств и качеств, присущий целому семейству процессоров (Skylake – процессоры Intel Core 5 и 6 поколений).
Если тема кажется сложной, можно начать со статьи о том, чем CPU отличается от GPU.
Виды архитектур
В этой статье мы рассмотрим самые распространенные и актуальные архитектуры с программной точки зрения, кроме узкоспециализированных (графических, математических, тензорных).
Самый яркий пример CISC архитектуры — это x86 (он же IA-32) и x86_64 (он же AMD64).
В CISC процессорах одна команда может быть заменена ей аналогичной, либо группой команд, выполняющих ту же функцию. Отсюда вытекают плюсы и минусы архитектуры: высокая производительность благодаря тому, что несколько команд могут быть заменены одной аналогичной, но большая цена по сравнению с RISC процессорами из-за более сложной архитектуры, в которой многие команды сложнее раскодировать.
По сравнению с CISC эта архитектура имеет константную длину команды, а также меньшее количество схожих инструкций, позволяя уменьшить итоговую цену процессора и энергопотребление, что критично для мобильного сегмента. У RISC также большее количество регистров.
Примеры RISC-архитектур: PowerPC, серия архитектур ARM (ARM7, ARM9, ARM11, Cortex).
В общем случае RISC быстрее CISC. Даже если системе RISC приходится выполнять 4 или 5 команд вместо одной, которую выполняет CISC, RISC все равно выигрывает в скорости, так как RISC-команды выполняются в 10 раз быстрее.
Отсюда возникает закономерный вопрос: почему многие всё ещё используют CISC, когда есть RISC? Всё дело в совместимости. x86_64 всё ещё лидер в desktop-сегменте только по историческим причинам. Так как старые программы работают только на x86, то и новые desktop-системы должны быть x86(_64), чтобы все старые программы и игры могли работать на новой машине.
Для Open Source это по большей части не является проблемой, так как пользователь может найти в интернете версию программы под другую архитектуру. Сделать же версию проприетарной программы под другую архитектуру может только владелец исходного кода программы.
Ещё более простая архитектура, используемая в первую очередь для ещё большего уменьшения итоговой цены и энергопотребления процессора. Используется в IoT-сегменте и недорогих компьютерах, например, роутерах.
Для увеличения производительности во всех вышеперечисленных архитектурах может использоваться “спекулятивное исполнение команд”. Это выполнение команды до того, как станет известно, понадобится эта команда или нет.
Примеры архитектуры: Intel Itanium, Эльбрус-3.
Виртуальные архитектуры
Из минусов виртуальных архитектур можно выделить меньшую производительность по сравнению с реальными архитектурами. Этот минус нивелируется с помощью JIT- и AOT-компиляции. Однако большим плюсом будет кроссплатформенность.
Дальнейшим развитием этих архитектур стали гибридные архитектуры. Например современные x86_64 процессоры хотя и CISC-совместимы, но являются процессорами с RISC-ядром. В таких гибридных CISC-процессорах CISC-инструкции преобразовываются в набор внутренних RISC-команд. Какое дальнейшее развитие получат архитектуры процессора, покажет только время.
Читайте также: