
Реферат на тему суперскалярные микропроцессоры
Обновлено: 04.07.2024
Инструкции могут быть зависимыми по данным и по управляющей логике программы. ( Data dependence and control flow dependence ).
Эффективность суперскалярных и конвейерных механизмов во многом ограничивается различными условными переходами внутри программы.
Существует специальный механизм предсказания переходов ( branch prediction ).
МПП выбирает один из возможных путей и продолжает выбирать инструкции и нагружать конвейеры МП работой. В момент, когда условие перехода вычислено, определяется, не ошибся ли предсказатель.
Ошибка предсказателя (branch misprediction ) - все уже выполненные или еще находящиеся в обработке инструкции удаляются, и МП заново заполняет конвейеры.
Можно выделить статический и динамический предсказатель.
Динамический предсказатель отличается тем, что собирает статистику на каждое ветвление и делает предсказание на основании собранной статистики.
Тривиальное предсказание – переход не будет выполнен в случае если осуществляется переход вперед и будет выполнен – если происходит переход назад.
Существует также механизм предсказания цели ветвления (branch target prediction ), который предсказывает безусловные переходы.
Качество предсказания переходов.
В программе есть некая управляющая логика, и эта логика включает в себя различные переходы внутри кода. Если встречаются if ’ы и на основании вычисления какого-то условия принимается решение, какую выполнять инструкцию дальше? Как быть с загрузкой конвейера, в случае если встречается зависимость по управляющей логике? Можно остановить конвейер и ждать, пока вычислится условие перехода и после этого определить, какую инструкцию выполнять дальше и загружать ее на конвейер. Понятно, что в этом случае произойдет замедление работы конвейера, поэтому выбран другой метод. Процессор пытается предсказать по какому-то пути будет передаваться управление и продолжает выполнять инструкции с этого направления. Причем пока процессор не убедится, что выполняются правильные инструкции, они недействительны . Как только процессор убеждается, что путь угадан верно, все инструкции признаются правильными. Если предсказатель ошибся и реальное управление пошло по другому пути, недействительные инструкции удаляются из буферов, где они ожидали своей судьбы. Это приводит к некой задержке, приходится тратить время на то, чтобы инструкции удалять и загружать правильные инструкции на конвейер. Ошибка предсказателя ( branch misprediction ) вызывает замедление работы конвейера.
В процессоре есть статический и динамический предсказатель.
Статический предсказатель действует по простым правилам и принимает решения для тех переходов для которых нет собранной статистики.
Если встречается условный переход вперед, то статический предсказатель считает, что перехода не будет (в случае с оператором if управление пойдет по ветке if а не else ).
В том случае, если у нас будет переход назад, то этот переход будет выполнен. Это сделано для лучшей обработки циклов. Обычно циклы имеют более двух итераций, и эта схема лучше работает.
При выполнении перехода накапливается статистика , которую при последующих исполнениях данного перехода будет использовать динамический предсказатель.
Если у вас внутри цикла постоянно встречается if (и этот if хорошо предсказуемый), то начиная со второй-третьей итерации процессор будет четко угадывать правильное направление и задержки мы не получим. Если переход плохо предсказуемый, то будет много неугадываний и производительность цикла понизится.
Одна из целей vtun ’а — это определение таких событий, как неверное угадывание перехода, например. Вы можете этим устройством проанализировать ваше приложение и увидеть, что в определенном месте вашего кода есть плохо предсказуемый переход или цепочка переходов влияющих на производительность . Зачастую такие проблемы могут быть решены творческим модифицированием кода .
Существуют разные проблемы. Проблема с КЭШем, например. Если у вас идет неугадывание по КЭШу, и вы не можете вовремя получить из памяти какие-то адреса, то эта проблема заслонит ту проблему, что вы не можете правильно определить цель ветвления, потому что процессор будет простаивать много времени по другой причине.
Суперскалярность
Суперскалярный процессор – процессор, способный выполнять несколько операций за один такт.
Как следствие, для такого типа процессора обязательно наличие нескольких исполнительных блоков ( execution unit ).
Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств.
Pentium - первый суперскалярный процессор архитектуры x86.
Выигрыш от суперскалярности определяется уровнем параллелизма инструкций.
"Разнообразие" поступающих на конвейер инструкций позволяет более полно нагружать исполняемые устройства.
Суперскалярность.
Теперь обсудим суперскалярность . Мы рассуждали о командном управляющем устройстве и об арифметико-логических устройствах. Суперскалярность — это процессор , который имеет несколько исполняющих устройств, то есть одновременно он может выполнять несколько арифметических и логических операций. Мы обсуждали конвейер, где обрабатывались инструкции, и была часть конвейера, которая выполняла операцию и называлась " исполняющее устройство ", где непосредственно делалась основная работа, для которой эта инструкция была написана. Суперскалярность означает, что построен конвейер имеющий несколько исполняющих устройств и одновременно может исполняться несколько различных команд. Исполняющие устройства специфицированы, они не могут исполнить любую инструкцию, у них у каждого своя должность (один выполняет одни виды команд, другой – другие и так далее). То есть у нас появилась возможность выполнять одновременно несколько инструкций на этих исполняющих устройствах. Например до 6 инструкций на микропроцессорах семейства IA32 последних моделей.
Первым суперскалярным процессором интеловской архитектуры был Pentium, и в нем было реализовано исполняемое устройство U и исполняемое устройство V. Одно умело делать все операции , а второе — самые простенькие, например, инкрементирование.
Разнообразие поступающих на конвейер инструкций позволяет процессору полнее загружать работой конвейер. Если у вас все инструкции однотипные, то спектр всех этих исполняющих устройств не будет задействован и они будут простаивать.
Упрощенная модель процессора
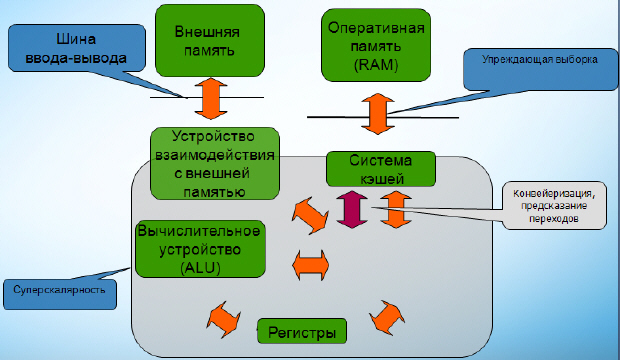
Теперь мы берем и изменяем несколько упрощенную модель нашего микропроцессора, чтобы схематично отобразить на ней те свойства, которые мы только что обсуждали. На системной шине работает упреждающая выборка , которая из памяти подгружает данные в систему КЭШа, базируясь на логике железного предсказателя. Отображаем систему КЭШей. В микропроцессоре будет работать конвейер и предсказатель переходов, то есть управляющее устройство будет брать не только те инструкции, которые оно в данный момент собирается выполнять, а также те, которые ему рекомендует брать предсказатель переходов (чтобы конвейер более плотно нагружать). Регистров увеличенное количество, ну и суперскалярность , которую мы можем отобразить как наличие нескольких вычислительно-логических устройств.
Использование векторных инструкций, векторизация
Типичная векторная инструкция выполняет элементарную операцию над двумя векторными последовательностями в памяти или векторными регистрами фиксированной длины.

Векторизация – процесс конвертации компьютерной программы из скалярного представления, в котором одна операция выполняется над парой операндов, в векторное представление, в котором одна операция выполняется над парой векторных операндов.
Конвейеризация, суперскалярность — это некие варианты параллелизации. Они несколько разные по их специфике, но в целом приводят к тому, что мы одновременно работаем с несколькими инструкциями.
Третий вариант параллелизации — параллелизация по данным, векторизация. Типичная векторная инструкция выполняет элементарную операцию над двумя векторными последовательностями в памяти или векторными регистрами фиксированной длины. Ее можно трактовать двояко, с одной стороны это поддержка на уровне микропроцессора векторных регистров и операций с ними, с другой стороны это некая оптимизация , позволяющая обычный скалярный код преобразовывать в векторный код. Т.е. в отличии от обсуждаемых ранее особенностей микропроцессора, эта технология не будет работать по умолчанию, если не будут предприняты какие-либо действия разработчиками запускаемого приложения. Сам микропроцессор на данном этапе векторизовать код не умеет.
Векторизация — это некая технология, когда вы можете ваш скалярный код (то есть код, который работает с какими-то скалярными элементами, допустим, элементами массива) превратить в векторный код, который будет оперировать уже не элементами массива, а секциями массива, будет делать операции не над одним элементом из массива а, соответственно, над вектором элементов. Вы можете делать векторизацию либо руками, либо поручить эту работу компилятору, и он вашу скалярную программу преобразует в векторный вид. В данной лекции, перечисляя факторы влияющие на производительность , я просто хочу подчеркнуть, что использование при рассчетах векторных инструкций способно серьезно ускорить работу микропроцессора.
Процессор поддерживает разные наборы векторных инструкций: SSE2 , SSE3 и так далее. Обсуждая полноту набора инструкций мы уже затронули вопрос, что приложение будет работать оптимальнее на архитектуре, если при создании приложения вы будете специально создавать его для работы на данной архитектуре. Это верно и в случае с векторными инструкциями.
Опережающий просмотр потока инструкций
Для того, чтобы эффективно использовать несколько АЛУ и конвейер, современные микропроцессоры используют опережающий просмотр потока инструкций . Это позволяет определить те инструкции, которые могут вычисляться параллельно.
Также возможно исполнение с изменением последовательности операций (out-of- order execution ).
Но технологии опережающего просмотра инструкций ( lookahead ) не могут решить проблему простоя АЛУ и конвейера в случае низкого уровня инструкционного параллелизма.
Out-of- order execution – одно из определяющих свойств архитектуры x86 . Реализация этого механизма усложняет процессор . В качестве противоположного примера от Интел можно упомянуть архитектуры Itanium и Atom . На этих архитектурах инструкции выполняются в порядке, заданном приложением.
Т.е. в микроархитектурах семейства IA32 реализовано исполнение с изменением последовательности операций (out-of-order- execution ). То есть программисты написали какие-то инструкции, подали их на процессор , а он сам выбрал, в каком порядке их выполнять. В данном случае важная часть работы – планирование инструкций выполняется непосредственно микропроцессором.
Это не единственный возможный вариант работы микропроцессора. Есть микропроцессор Intel Atom , предназначенный для различных планшетных устройств, который последовательно выполняет получаемые микроинструкции, или например, процессор Itanium , в котором в процессор поступают инструкции уже объединенные в группы. То есть работа по определению того, какие инструкции независимы и в каком порядке их подавать процессору переложена на компилятор . В этом случае работа по определению оптимального порядка инструкций выполняется один раз — во время компиляции . Это должно быть выгодно с точки зрения энергопотребления.
Если кто-то хочет более подробно с этим всем ознакомиться, я отсылаю к инструкциям, к документации от Интел. Вы можете скачать документацию и после этого сидеть и перед сном ее почитывать. Документация содержит много схем, объясняющих более подробно работу микропроцессора и взаимодействия между различными компонентами процессора. Пример, который показывает спецификацию исполняемых устройств. То есть существует внутри конвейера некий распределитель, который поступающие инструкции распределяет на то или иное подходящее исполняющее устройство .
Основная идея, определяющая развитие суперскалярных микропроцессоров, состоит в построении возможно большего количества параллельных структур при сохранении традиционных последовательных программ. Это означает, что компиляторы и аппаратура микро-процессора сами, без вмешательства программиста, обеспечивают загрузку параллельно работающих функциональных устройств микропроцессора.
В соответствии с моделью последовательного программирования программы пишутся в предположении, что команды будут выполнены в том же порядке, в каком они представлены в программе. Однако с целью достижения большей эффективности современные процессоры пытаются выполнять несколько команд одновременно и в некоторых случаях в порядке, отличном от их исходной последовательности в программе. Это переупорядочение может быть выполнено в трансляторе и (или) в аппаратных средствах во время выполнения. Суперскалярные и VLIW-про-цессоры принадлежат классу архитектур, которые используют параллельность уровня команды (ILP).
ILP-процессоры и компиляторы обычно преобразуют полностью упорядоченное множество команд исходной программы в частично упорядоченное множество, структурированное зависимостями по данным и управлению. Зависимости по управлению (которые проявляются как переходы по условию) представляют главное препятствие высокопараллельному выполнению потому, что эти зависимости должны быть установлены прежде, чем будут выполнены все последующие команды.
Текст последовательной программы, представленной на языке высокого уровня, компилируется в машинный код, отражающий статическую структуру программы, т.е. упорядоченное множество команд (инструкций) в памяти компьютера. Процесс выполнения программы с конкретными наборами входных данных может быть представлен динамической структурой программы, т.е. множеством последовательностей инструкций в порядке их исполнения.
Повысить степень параллелизма программы можно, изменяя соответствующим образом ее статическую или динамическую структуру. Поскольку статическая структура программы однозначно соответствует ее исходному тексту (в предположении неизменности компилятора), то изменение статической структуры сводится к изменению исходного кода, что, в общем случае, не всегда возможно. Динамическая же структура программы может быть изменена при неизменной статической структуре. И главной целью такого изменения должно быть повышение степени параллельного исполнения команд.
Допустимые границы преобразования динамической структуры программы задают существующие на множестве инструкций отношения: зависимость по управлению и зависимость по данным. При описании архитектур суперскалярных процессоров часто используется модель окна исполнения. При исполнении программы микропроцессор как бы продвигает по статической структуре программы окно исполнения. Команды в окне могут исполняться параллельно, если между ними нет зависимости.
Для устранения зависимостей, вызванных командами переходов, используется метод предсказания, позволяющий извлекать и условно исполнять команды предсказанного перехода. Если позднее обнаруживается, что предсказание было сделано верно, то результаты условно исполненных команд принимаются. Если предсказание было ошибочным, состояние процессора восстанавливается на момент принятия решения о выполнении перехода.
Команды, помещенные в окно исполнения, могут быть зависимы по данным. Эти зависимости обусловлены использованием одних и тех же ресурсов памяти (регистров, ячеек памяти) в разных командах. Поэтому для правильного исполнения программы необходимо использование этих ресурсов в предписываемом программой порядке.
Все виды зависимостей по данным могут быть классифицированы по типу ассоциаций: RAR – "чтение после чтения", WAR – "запись после чтения", WAW – "запись после записи", RAW – "чтение после записи".
Пример различных зависимостей команд по данным показан на рис. 1.3.
Рис. 1.3. Зависимость команд по данным
Некоторые из зависимостей по данным могут быть устранены. RAR, по сути дела, соответствует отсутствию зависимостей, поскольку в данном случае порядок выполнения команд не имеет значения. Действительной зависимостью является только "чтение после записи" (RAW), так как необходимо прочитать предварительно записанные новые данные, а не старые.
Лишние зависимости по данным появляются в результате "записи после чтения" (WAR) и "записи после записи" (WAW). Зависимость WAR состоит в том, что команда должна записать новое значение в ячейку памяти или регистр, из которых должно быть произведено чтение. Лишние зависимости появляются по нескольким причинам: не оптимизированный программный код, ограничение количества регистров, стремление к экономии памяти, наличие программных циклов. Важно отметить, что запись может быть произведена в любой свободный ресурс, а не только тот, который указан в программе.
После удаления лишних зависимостей по управлению и данным команды могут исполняться параллельно. Формирование расписания параллельного выполнения команд возлагается на аппаратные средства микропроцессора. Это расписание учитывает существующие зависимости между командами и имеющиеся функциональные модули процессора.
В современных микропроцессорах широко используется принцип конвейерного выполнения отдельных элементарных операций. Конвейеризация внутренних процессов позволяет выполнять команду за каждый процессорный цикл.
Дальнейшее внедрение принципов конвейеризации привело к появлению класса суперскалярных микропроцессоров. Суперскалярные микропроцессоры – микропроцессоры, способные выполнять нескольких команд за один процессорный цикл. Такой режим выполнения программы стал возможным благодаря наличию в процессорах нескольких исполнительных устройств.
Типовая архитектура суперскалярного микропроцессора представлена на рис. 1.4.

Рис. 1.4. Архитектура суперскалярного микропроцессора
В число основных блоков суперскалярного микропроцессора входят: блок выборки команд и предсказания переходов, блок декодирования команд, анализа зависимостей между командами, переименования и диспетчеризации, блоки регистров и обрабатывающих устройств с плавающей и фиксированной точками, блок управления памятью, а также блок упорядочения выполненных команд.
Ниже рассмотрены основные приемы повышения быстродействия в суперскалярных микропроцессорах.
![Микропроцессоры и их характеристики [06.09.13]](https://studrb.ru/files/works_screen/1/48/36.jpg)
1.Теоретическая часть. Микропроцессоры и их характеристика.
1.1.Основные понятия 6
1.2.Классификация микропроцессоров 10
1.3 Структура и основные характеристики микропроцессоров 12
2. Практическая часть 19
2.1 Общая характеристика задачи 19
2.2 Описание алгоритма решения задачи 22
Список литературы 27
Введение
Важнейший компонент любого персонального компьютера - это микропроцессор, который управляет работой компьютера и выполняет большую часть обработки информации.
В современном мире трудно найти область техники, где не применялись бы микропроцессоры.
Актуальность этой темы состоит в том, что микропроцессор компьютера является основой современной компьютерной техники. Компьютерная техника лежит в основе современного прогресса. Она обеспечивает работу современных станков, контроль технологических процессов на производстве, связь на всех уровнях (от межгосударственного до бытового). С помощью нее проводятся сложные и трудоемкие расчеты, что значительно ускоряет процессы конструирования, разработки, фундаментальные исследования, то есть задает темпы прогресса. И в зависимости от того, как будет в будущем меняться мощность этой маленькой детали, будет зависеть производительность всей компьютерной техники в целом.
В микропроцессорах - наиболее сложных микроэлектронных устройствах - воплощены самые передовые достижения инженерной мысли. В условиях свойственной данной отрасли производства жесткой конкуренции и огромных капиталовложений выпуск каждой новой модели микропроцессора, так или иначе, связан с очередным научным, конструкторским, технологическим прорывом.
В микропроцессорах нашли отражение высокие научно-технические достижения в области физики твердого тела, кристаллографии, радиотехники и электроники, математики и автоматизации, кибернетики и электроники. Известны различные применения микропроцессоров. Важнейшими из них являются: автоматизация электротехнического оборудования, управление производством, физическое и математическое моделирование, обработка результатов экспериментов, управление приборами и искусственными органами в медицине, обеспечение безопасности движения на транспорте и т.д.
Цель данной курсовой работы: рассмотреть классификацию, структуру и основные характеристики микропроцессоров ПК.
Для достижения поставленной цели необходимо решить следующие задачи:
- раскрыть основные понятия темы;
- дать общую схему классификации микропроцессоров;
- рассмотреть структуру и основные характеристики микропроцессоров ПК.
Данная курсовая работа выполнена на компьютере Intel Pentium IV c программным обеспечением Windows XP и Microsoft Office 2003.
1.Теоретическая часть. Микропроцессоры и их характеристика.
Введение
Актуальность темы состоит в том, что микропроцессор компьютера является основой современной компьютерной техники. Компьютерная техника лежит в основе современного прогресса. Она обеспечивает работу современных станков, контроль технологических процессов на производстве, связь на всех уровнях (от межгосударственного до бытового). С помощью нее проводятся сложные и трудоемкие расчеты, что значительно ускоряет процессы конструирования, разработки, фундаментальные исследования, то есть задает темпы прогресса. И в зависимости от того, как будет в будущем меняться мощность этой маленькой детали, будет зависеть производительность всей компьютерной техники в целом. Полученные в ходе написания работы знания могут пригодиться и в обыденной жизни, например при приобретении персонального компьютера.
Для раскрытия выбранной темы необходимо рассмотреть ряд таких вопросов, как: структура микропроцессор, его характеристики, а так же классификацию микропроцессоров персонального компьютера.
1.1 Основные понятия
Процессор - это не просто скопище транзисторов, а целая система множества важных устройств. На любом процессорном кристалле находятся:
Собственно процессор, главное вычислительное устройство, состоящее из миллионов логических элементов -транзисторов.
Кэш-память первого уровня - небольшая (несколько десятков килобайт) сверхбыстрая память, предназначенная для хранения промежуточных результатов вычислений.
Кэш-память второго уровня - эта память чуть помедленнее, зато больше - от 128 килобайт до 2 Мб.
Все эти устройства размещаются на кристалле площадью не более 4-6 квадратных сантиметров.
Арифметико-логическое устройство - часть процессора, которая выполняет команды.
Устройство управления - часть процессора, выполняющая функции управления устройствами.
Тактовая частота. Самый важный показатель, определяющий скорость работы процессора. Тактовая частота, измеряемая в мегагерцах (МГц) и гигагерцах (ГГц), обозначает лишь то количество циклов, которые совершает работающий процессор за единицу времени (секунду).
Размер кэш-памяти. В эту встроенную память процессор помещает все часто используемые данные, чтобы не обращаться каждый раз - к более медленной оперативной памяти и жесткому диску.
Кэш-память в процессоре имеется двух видов. Самая быстрая - кэш-память первого уровня (32 кб у процессоров Intel и до 128 кб - в последних моделях AMD).
Частота системной шины. Шиной называется та аппаратная магистраль, по которой перемещаются от устройства к устройству данные. Чем выше частота шины, тем больше данных поступает за единицу времени к процессору.
1.2 Классификация микропроцессоров
По числу больших интегральных схем (БИС) в микропроцессорном комплекте различают микропроцессоры однокристальные, многокристальные и многокристальные секционные.
Однокристальные микропроцессоры получаются при реализации всех аппаратных средств процессора в виде одной БИС или СБИС (сверхбольшой интегральной схемы). По мере увеличения степени интеграции элементов в кристалле и числа выводов корпуса параметры однокристальных микропроцессоров улучшаются. Однако возможности однокристальных микропроцессоров ограничены аппаратными ресурсами кристалла и корпуса. Для получения многокристального микропроцессора необходимо провести разбиение его логической структуры на функционально законченные части и реализовать их в виде БИС (СБИС). Функциональная законченность БИС многокристального микропроцессора означает, что его части выполняют заранее определенные функции и могут работать автономно.
Многокристальные секционные микропроцессоры получаются в том случае, когда в виде БИС реализуются части (секции) логической структуры процессора при функциональном разбиении ее вертикальными плоскостями.
По назначению различают универсальные и специализированные микропроцессоры.
Универсальные микропроцессоры могут быть применены для решения широкого круга разнообразных задач. При этом их эффективная производительность слабо зависит от проблемной специфики решаемых задач. Специализация МП, т.е. его проблемная ориентация на ускоренное выполнение определенных функций позволяет резко увеличить эффективную производительность при решении только определенных задач.
Среди специализированных микропроцессоров можно выделить различные микроконтроллеры, ориентированные на выполнение сложных последовательностей логических операций, математические МП, предназначенные для повышения производительности при выполнении арифметических операций за счет, например, матричных методов их выполнения, МП для обработки данных в различных областях применений и т. д.
По виду обрабатываемых входных сигналов различают цифровые и аналоговые микропроцессоры. Сами микропроцессоры - цифровые устройства, однако могут иметь встроенные аналого-цифровые и цифро-аналоговые преобразователи. Поэтому входные аналоговые сигналы передаются в МП через преобразователь в цифровой форме, обрабатываются и после обратного преобразования в аналоговую форму поступают на выход. С архитектурной точки зрения такие микропроцессоры представляют собой аналоговые функциональные преобразователи сигналов и называются аналоговыми микропроцессорами. Отличительная черта аналоговых микропроцессоров способность к переработке большого объема числовых данных, т. е. к выполнению операций сложения и умножения с большой скоростью при необходимости даже за счет отказа от операций прерываний и переходов.
По характеру временной организации работы микропроцессоры делят на синхронные и асинхронные.
Синхронные микропроцессоры - микропроцессоры, в которых начало и конец выполнения операций задаются устройством управления (время выполнения операций в этом случае не зависит от вида выполняемых команд и величин операндов).
Асинхронные микропроцессоры позволяют начало выполнения каждой следующей операции определить по сигналу фактического окончания выполнения предыдущей операции.
По организации структуры микропроцессорных систем различают микроЭВМ одно- и многомагистральные.
В одномагистральных микроЭВМ все устройства имеют одинаковый интерфейс и подключены к единой информационной магистрали, по которой передаются коды данных, адресов и управляющих сигналов.
В многомагистральных микроЭВМ устройства группами подключаются к своей информационной магистрали. Это позволяет осуществить одновременную передачу информационных сигналов по нескольким (или всем) магистралям. Такая организация систем усложняет их конструкцию, однако увеличивает производительность.
По количеству выполняемых программ различают одно- и многопрограммные микропроцессоры.
В однопрограммных микропроцессорах выполняется только одна программа. Переход к выполнению другой программы происходит после завершения текущей программы.
В много- или мультипрограммных микропроцессорах одновременно выполняется несколько (обычно несколько десятков) программ.
1.3 Структура и основные характеристики микропроцессоров
Процессор — основная микросхема компьютера, в которой и производятся все вычисления [3, с.80]. Собственно говоря, процессор в компьютере не один — их может быть целый десяток! Собственным процессором снабжена видеоплата, звуковая плата, множество внешних устройств (например, принтер). И часто по производительности эти микросхемы могут поспорить с главным, Центральным Процессором. Но в отличие от него, все они являются узкими специалистами — один отвечает за обработку звука, другой — за создание трехмерного изображения.
Основное и главное отличие центрального процессора — это его универсальность. При желании центральный процессор может взять на себя любую работу, в то время как процессор видеоплаты при всем желании не сможет раскодировать, скажем, музыкальный файл.
Однако процессор — это не просто скопище транзисторов, а целая система множества важных устройств [4, с.38]. В состав микропроцессора входят следующие устройства.
1. Арифметико-логическое устройство предназначено для выполнения всех арифметических и логических операций над числовой и символьной информацией.
2. Устройство управления координирует взаимодействие различных частей компьютера. Выполняет следующие основные функции:
• формирует и подает во все блоки машины в нужные моменты времени определенные сигналы управления (управляющие импульсы), обусловленные спецификой выполнения различных операций;
• формирует адреса ячеек памяти, используемых выполняемой операцией, и передает эти адреса в соответствующие блоки компьютера;
• получает от генератора тактовых импульсов обратную последовательность импульсов.
3. Микропроцессорная память предназначена для кратковременного хранения, записи и выдачи информации, используемой в вычислениях непосредственно в ближайшие такты работы машины. Микропроцессорная память строится на регистрах и используется для обеспечения высокого быстродействия компьютера, так как основная память не всегда обеспечивает скорость записи, поиска и считывания информации, необходимую для эффективной работы быстродействующего микропроцессора [5]. Важно также отметить, что данные, попавшие в некоторые регистры, рассматриваются не как данные, а как команды, управляющие обработкой данных в других регистрах [3, с.80].
4. Кэш-память. Буферная память — своеобразный накопитель для данных. В современных процессорах используется два типа кэш-памяти: первого уровня — небольшая (несколько десятков килобайт) сверхбыстрая память, и второго уровня — чуть помедленнее, зато больше — от 128 килобайт до 2 Мб [4, с.38].
5. Процессор связан несколькими группами проводников называемых шинами. С остальными устройствами компьютера, и в первую очередь с оперативной памятью. Основных шин три: шина данных, адресная шина и командная шина.
1. Адресная шина. Шина или часть шины, предназначенная для передачи адреса, а именно используется ЦП для выбора требуемой ячейки памяти или устройства ввода-вывода путем установки на шине конкретного адреса, соответствующего одной из ячеек памяти или одного из элементов ввода-вывода, входящих в систему.
2. Шина команд. По ней передаются управляющие сигналы, предназначенные памяти и устройствам ввода-вывода. Эти сигналы указывают направление передачи данных (в процессор или из него).
3. Шина данных — информационная магистраль, благодаря которой процессор может обмениваться данными с другими устройствами компьютера [3, с.80].
Микропроцессоры отличаются друг от друга двумя главными характеристиками: типом (моделью) и тактовой частотой. Одинаковые модели микропроцессоров могут иметь разную тактовую частоту - чем выше тактовая частота, тем выше производительность и цена микропроцессора. Тактовая частота указывает, сколько элементарных операций (тактов) микропроцессор выполняет в одну секунду. Тактовая частота измеряется в мегагерцах (МГц). Следует заметить, что разные модели микропроцессоров выполняют одни и те же операции за разное число тактов. Чем выше модель микропроцессора, тем меньше тактов требуется для выполнения одних и тех же операций.
Рассмотрим характеристики процессоров более подробно.
1. Тип микpопpоцессоpа.
Тип установленного в компьютеpе микpопpоцессоpа является главным фактоpом, опpеделяющим облик ПК. Именно от него зависят вычислительные возможности компьютеpа. В зависимости от типа используемого микpопpоцессоpа и опpеделенных им аpхитектуpных особенностей компьютеpа pазличают пять классов ПК:
- компьютеры класса XT;компьютеpы класса AT;компьютеpы класса 386;компьютеpы класса 486;компьютеpы класса Pentium.
2. Тактовая частота микpопpоцессоpа - указывает, сколько элементарных операций (тактов) микропроцессор выполняет за одну секунду.
Генератор тактовых импульсов генерирует последовательность электрических импульсов. Частота генерируемых импульсов определяет тактовую частоту машины. Промежуток времени между соседними импульсами определяет время одного такта работы машины, или просто, такт работы машины.
Частота генератора тактовых импульсов является одной из основных характеристик персонального компьютера и во многом определяет скорость его работы, ибо каждая операция в машине выполняется за определенное количество тактов.
3. Быстpодействие микpопpоцессоpа - это число элементаpных опеpаций, выполняемых микpопpоцессоpом в единицу вpемени (опеpации/секунда).
4. Разpядность пpоцессоpа - максимальное количество pазpядов двоичного кода, котоpые могут обpабатываться или пеpедаваться одновpеменно.
5. Аpхитектуpа микpопpоцессоpа.
Понятие архитектуры микропроцессора включает в себя систему команд и способы адресации, возможность совмещения выполнения команд во времени, наличие дополнительных устройств в составе микропроцессора, принципы и режимы его работы.
В соответствии с аpхитектуpными особенностями, опpеделяющими свойства системы команд, pазличают:
- микропроцессоры типа CISC с полным набором системы команд;
- микропроцессоры типа RISC с усеченным набором системы команд;
- микропроцессоры типа VLIW со сверхбольшим командным словом;
- микропроцессоры типа MISC с минимальным набором системы команд и весьма высоким быстродействием и др.
Заключение
Микропроцессор представляет собой компьютер в миниатюре. Кроме обрабатывающего блока, он содержит блок управления, и даже память (внутренние ячейки памяти). Это значит, что микропроцессор способен автономно выполнять все необходимые действия с информацией. Многие компоненты современного персонального компьютера содержат внутри себя миниатюрный компьютер. Массовое распространение микропроцессоры получили и в производстве, там, где управление может быть сведено к отдаче ограниченной последовательности команд.
Микропроцессоры незаменимы в современной технике. Например, управление современным двигателем - обеспечение экономии расхода топлива, ограничение максимальной скорости движения, контроль исправности и т. д. - немыслимо без использования микропроцессоров. Еще одной перспективной сферой их использования является бытовая техника - применение микропроцессоров придает ей новые потребительские качества.
Вскоре на рынке появится новый микропроцессор, который в перспективе способен расширить выбор элементной базы для недорогих ПК. Микросхема называется IDT-C6 и представляет собой микропроцессор класса Pentium, изготовление которого компания Integrated Device Technology Inc. планирует начать осенью этого года. Компания, расположенная в Санта-Кларе (шт. Калифорния), намеревается выпускать микропроцессоры с внутренней тактовой частотой 150, 180 и 200 МГц и средствами MMX, сообщил Гленн Хенри, президент компании IDT, разработавшего эту микросхему.
Это все говорит о том, что производство и усовершенствование микропроцессоров не стоит на месте. Современные технологии с каждым днем упрощают работу человека с компьютером, давая ему больше возможностей для работы.
2. Практическая часть
2.1 Общая характеристика задачи
Наименование экономической задачи: составление реестра договоров по филиалам страховой компании. Цель решения задачи – определение отчислений для их уплаты.
Компания имеет свои филиалы в нескольких городах (рисунок 2) и поощряет развитие каждого филиала, предоставляя определенный дисконт. Дисконт пересматривается ежемесячно по итогам общих сумм договоров по филиалам.
В конце каждого месяца составляется общий реестр договоров по всем филиалам (рисунок 3).

Суперскалярность — архитектура вычислительного ядра, использующая несколько декодеров команд, которые могут загружать работой множество исполнительных блоков. Планирование исполнения потока команд является динамическим и осуществляется самим вычислительным ядром.
Если в процессе работы команды, обрабатываемые конвейером, не противоречат друг другу, и одна не зависит от результата другой, то такое устройство (ядро) может осуществить параллельное выполнение команд. В суперскалярных системах решение о запуске инструкции на исполнение принимает сам вычислительный модуль, что требует много ресурсов. В более поздних системах, таких как Эльбрус-3 и Itanium, используется статпланирование, то есть параллельные инструкции объединяются компилятором в длинную команду, в которой все инструкции заведомо параллельные (архитектура VLIW).
Содержание
Реализации
| Архитектура | Первая реализация | Год | Разработчик | Другие разработчики суперскалярных ЭВМ на данной архитектуре | Примечание |
|---|---|---|---|---|---|
| CDC 6600 | CDC 6600 | 1964 | Control Data Corporation | Конвейер исполнения команд, несколько исполнительных устройств (но не конвейеризованных). | |
| CDC 7600 [источник не указан 914 дней] | CDC 7600 | 1969 | Control Data Corporation | Полная конвейеризация — и исполнения команд, и самих исполнительных устройств. | |
| IBM 360/91 [источник не указан 914 дней] | IBM 360/91 | 1967 | IBM | Полная конвейеризация с динамическим переименованием регистров, исполнением команд не в очередности их поступления и предсказанием переходов | |
| Эльбрус | Эльбрус-1 | 1979 | ИТМиВТ | ||
| I960 | I960 | 1988 | Intel | ||
| SPARC | SuperSPARC | 1992 | Sun Microsystems | Fujitsu, МЦСТ | |
| x86 | Pentium | 1993 | Intel | AMD, VIA | |
| MIPS | R8000 | 1994 | MIPS Technologies | Toshiba | |
| ARM | Cortex A8 | ARM |
Ускорение вычислений
В суперскалярных вычислительных машинах используется ряд методов для ускорения вычислений, характерных прежде всего для них, однако такие методики могут использоваться и в других типах архитектур:
Также используются общие методики увеличения производительности, применяемые и в других типах вычислительных машин:
Читайте также: