
Коды рида соломона реферат
Обновлено: 03.07.2024
Понятие кодов Рида-Соломона как недвоичных циклических кодов, позволяющих исправлять ошибки в блоках данных. Основные правила декодирования произвольного текста, используя программу RSCODEC. Процесс несистематического кодирования информационного слова.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 09.01.2014 |
| Размер файла | 3,4 M |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Коды Рида -- Соломона (Reed-Solomon codes) -- недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида -- Соломона, работающие с байтами (октетами).
Код Рида -- Соломона является частным случаем БЧХ-кода.
В настоящее время широко используется в системах восстановления данных с компакт-дисков, при создании архивов с информацией для восстановления в случае повреждений, в помехоустойчивом кодировании.
Коды Рида -- Соломона являются важным частным случаем БЧХ-кода, корни порождающего полинома которого лежат в том же поле, над которым строится код (). Пусть -- элемент поля порядка . Если -- примитивный элемент, то его порядок равен , то есть . Тогда нормированный полином минимальной степени над полем , корнями которого являются подряд идущих степеней элемента , является порождающим полиномом кода Рида -- Соломона над полем :
где -- некоторое целое число (в том числе 0 и 1), с помощью которого иногда удается упростить кодер. Обычно полагается . Степень многочлена равна .
Длина полученного кода , минимальное расстояние (минимальное расстояние d линейного кода является минимальным из всех расстояний Хемминга всех пар кодовых слов, см. Линейный код). Код содержит проверочных символов, где обозначает степень полинома; число информационных символов . Таким образом и код Рида -- Соломона является разделимым кодом с максимальным расстоянием (является оптимальным в смысле границы Синглтона).
Кодовый полином может быть получен из информационного полинома , , путем перемножения и :
рид соломон декодирование
Код Рида -- Соломона над , исправляющий ошибок, требует проверочных символов и с его помощью исправляются произвольные пакеты ошибок длиной и меньше. Согласно теореме о границе Рейгера, коды Рида -- Соломона являются оптимальными с точки зрения соотношения длины пакета и возможности исправления ошибок -- используя дополнительных проверочных символов исправляется ошибок (и менее).
Теорема (граница Рейгера). Каждый линейный блоковый код, исправляющий все пакеты длиной и менее, должен содержать, по меньшей мере, проверочных символов.
Код, двойственный коду Рида -- Соломона, есть также код Рида-Соломона. Двойственным кодом для циклического кода называется код, порожденный его проверочным многочленом.
Матрица порождает код Рида -- Соломона тогда и только тогда когда любой минор матрицы отличен от нуля.
При выкалывании или укорочении кода Рида-Соломона снова получается код Рида -- Соломона. Выкалывание -- операция, состоящая в удалении одного проверочного символа. Длина кода уменьшается на единицу, размерность сохраняется. Расстояние кода должно уменьшиться на единицу, ибо в противном случае удаленный символ был бы бесполезен. Укорочение - фиксируем произвольный столбец кода и выбираем только те векторы, которые в данном столбце содержат 0. Это множество векторов образует подпространство.
Код Рида -- Соломона является одним из наиболее мощных кодов, исправляющих многократные пакеты ошибок. Применяется в каналах, где пакеты ошибок могут образовываться столь часто, что их уже нельзя исправлять с помощью кодов, исправляющих одиночные ошибки.
Кодирование с помощью кода Рида -- Соломона может быть реализовано двумя способами: систематическим и несистематическим.
При несистематическом кодировании информационное слово умножается на некий неприводимый полином в поле Галуа. Полученное закодированное слово полностью отличается от исходного и для извлечения информационного слова нужно выполнить операцию декодирования и уже потом можно проверить данные на содержание ошибок. Такое кодирование требует большие затраты ресурсов только на извлечение информационных данных, при этом они могут быть без ошибок.
При систематическом кодировании к информационному блоку из символов приписываются проверочных символов, при вычислении каждого проверочного символа используются все символов исходного блока. В этом случае нет затрат ресурсов при извлечении исходного блока, если информационное слово не содержит ошибок, но кодировщик/декодировщик должен выполнить операций сложения и умножения для генерации проверочных символов. Кроме того, так как все операции проводятся в поле Галуа, то сами операции кодирования/декодирования требуют много ресурсов и времени. Быстрый алгоритм декодирования, основанный на быстром преобразовании Фурье, выполняется за время порядка .
При операции кодирования информационный полином умножается на порождающий многочлен. Умножение исходного слова длины на неприводимый полином при систематическом кодировании можно выполнить следующим образом:
К исходному слову приписываются нулей, получается полином .
Этот полином делится на порождающий полином , находится остаток
Этот остаток и будет корректирующим кодом Рида -- Соломона, он приписывается к исходному блоку символов. Полученное кодовое слово
Кодировщик строится из сдвиговых регистров, сумматоров и умножителей. Сдвиговый регистр состоит из ячеек памяти, в каждой из которых находится один элемент поля Галуа.
Существует и другая процедура кодирования (более практичная и простая). Положим - примитивный элемент поля , и пусть - вектор информационных символов, а значит - информационный многочлен. Тогда вектор есть вектор кода Рида - Соломона, соответствующий информационному вектору . Этот способ кодирования показывает , что для кода РС вообще не нужно знать порождающего многочлена и порождающей матрицы коды, достаточно знать разложение поля по примитивному элементу и размерность кода (длина кода в этом случае определяется как ). Все дело в том, что за разностью полностью скрывается порождающий многочлен и кодовое расстояние.
Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия:
Вычисляет синдром ошибки
Строит полином ошибки
Находит корни данного полинома
Определяет характер ошибки
Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое слово на порождающий многочлен. Если при делении возникает остаток, то в слове есть ошибка. Остаток от деления является синдромом ошибки.
По синдрому ошибки и найденным корням полинома с помощью алгоритма Форни определяется характер ошибки и строится маска искаженных символов. Однако для кодов РС существует более простой способ отыскания характера ошибок. Для кодов РС с произвольным множеством последовательных нулей
где формальная производная по многочлена локаторов ошибок ,а
Далее после того как маска найдена, она накладывается на кодовое слово с помощью операции XOR и искаженные символы восстанавливаются. После этого отбрасываются проверочные символы и получается восстановленное информационное слово.
Сразу после появления (60-е годы 20-го века) коды Рида - Соломона стали применяться в качестве внешних кодов в каскадных конструкциях, использующихся в спутниковой связи. В подобных конструкциях - ые символы РС (их может быть несколько) кодируются внутренними сверточными кодами. На приемном конце эти символы декодируются мягким алгоритмом Витерби (эффективный в каналах с АБГШ). Такой декодер будет исправлять одиночные ошибки в q - ичных символах, когда же возникнут пакетные ошибки и некоторые пакеты q - ичных символов будут декодированы неправильно, тогда внешний декодер Рида - Соломона исправит пакеты этих ошибок. Таким образом будет достигнута требуемая надежность передачи информации.
В настоящий момент коды Рида -- Соломона имеют очень широкую область применения благодаря их способности находить и исправлять многократные пакеты ошибок.
Код Рида -- Соломона используется при записи и чтении в контроллерах оперативной памяти, при архивировании данных, записи информации на жесткие диски (ECC), записи на CD/DVD диски. Даже если поврежден значительный объем информации, испорчено несколько секторов дискового носителя, то коды Рида -- Соломона позволяют восстановить большую часть потерянной информации. Также используется при записи на такие носители, как магнитные ленты и штрих коды.
Возможные ошибки при чтении с диска появляются уже на этапе производства диска, так как сделать идеальный диск при современных технологиях невозможно. Также ошибки могут быть вызваны царапинами на поверхности диска, пылью и т. д. Поэтому при изготовлении читаемого компакт-диска используется система коррекции CIRC (Cross Interleaved Reed Solomon Code). Эта коррекция реализована во всех устройствах, позволяющих считывать данные с CD дисков, в виде чипа с прошивкой firmware. Нахождение и коррекция ошибок основана на избыточности и перемежении (redundancy & interleaving). Избыточность примерно 25 % от исходной информации.
При записи на аудиокомпакт - диски используется стандарт Red Book. Коррекция ошибок происходит на двух уровнях C1 и C2. При кодировании на первом этапе происходит добавление проверочных символов к исходным данным, на втором этапе информация снова кодируется. Кроме кодирования осуществляется также перемешивание (перемежение) байтов, чтобы при коррекции блоки ошибок распались на отдельные биты, которые легче исправляются. На первом уровне обнаруживаются и исправляются ошибочные блоки длиной один и два байта (один и два ошибочных символа соответственно). Ошибочные блоки длиной три байта обнаруживаются и передаются на следующий уровень. На втором уровне обнаруживаются и исправляются ошибочные блоки, возникшие в C2, длиной 1 и 2 байта. Обнаружение трех ошибочных символов является фатальной ошибкой и не может быть исправлено.
Выберем количество контрольных байтов, равное 20. Соответственно, мы сможем гарантированно исправлять искажения кратностью вплоть до 10 байтов.
Декодер сообщает, что синдром ошибок для принятого кадра равен нулю.
Используем генератор искажений. Для начала введем количество байтов, которые будут случайным образом искажены. Выберем количество искажаемых байтов 13:
Кроме того, также имеем информационный блок кадра в искаженном виде:
Кроме того, для детального анализа всех этапов декодирования кадра, в секции дополнительных функций мы можем запустить окна для отображения вычисленного синдрома ошибок, найденного полинома локаторов ошибок, найденных локаторов ошибок, вычисленных полиномов величин ошибок и формальной производной, вычисленных величин ошибок, а также сформированного полинома ошибок.
Имеем синдром ошибок и видим, что он не равен нулю, что говорит о том, что принятый кадр содержит ошибки (подвергнут искажениям):
Также имеем найденный декодером полином локаторов ошибок:
Имеем вычисленные локаторы ошибок, заметим, что декодер сделал правильное предположение о количестве искаженных байтов (2):
Также имеем вычисленные полиномы величин ошибок и формальной производной:
Также имеем вычисленные величины ошибок:
Наконец, имеем сформированный полином ошибок
Скриншоты программы, полученные при искажении 26 информационных байтов
В результате искаженный кадр принимает следующий вид:
Информационный блок кадра в искаженном виде:
Предполагаемый вектор искажений вида:
Имеем синдром ошибок и видим, что он не равен нулю, что говорит о том, что принятый кадр содержит ошибки (подвергнут искажениям):
Полином локаторов ошибок:
Имеем вычисленные локаторы ошибок, заметим, что декодер сделал правильное предположение о количестве искаженных байтов (13):
Также имеем вычисленные полиномы величин ошибок и формальной производной:
Также имеем вычисленные величины ошибок:
Сформированный полином ошибок:
Скриншоты программы, полученные при искажении 28 информационных байтов
В результате искаженный кадр принимает следующий вид:
Информационный блок кадра в искаженном виде:
Предполагаемый вектор искажений вида:
Имеем синдром ошибок и видим, что он не равен нулю, что говорит о том, что принятый кадр содержит ошибки (подвергнут искажениям):
Полином локаторов ошибок:
Также имеем вычисленные полиномы величин ошибок и формальной производной:
Также имеем вычисленные величины ошибок:
Сформированный полином ошибок:
Скриншоты программы, полученные при искажении 30 информационных байтов
В результате искаженный кадр принимает следующий вид:
Информационный блок кадра в искаженном виде:
Предполагаемый вектор искажений вида:
Имеем синдром ошибок и видим, что он не равен нулю, что говорит о том, что принятый кадр содержит ошибки (подвергнут искажениям):
Полином локаторов ошибок:
Имеем вычисленные локаторы ошибок, заметим, что декодер сделал правильное предположение о количестве искаженных байтов (13):
Также имеем вычисленные полиномы величин ошибок и формальной производной:
Также имеем вычисленные величины ошибок:
Сформированный полином ошибок:
Скриншоты программы, полученные при искажении 32 информационных байтов
В результате искаженный кадр принимает следующий вид:
Информационный блок кадра в искаженном виде:
Предполагаемый вектор искажений вида:
Имеем синдром ошибок и видим, что он не равен нулю, что говорит о том, что принятый кадр содержит ошибки (подвергнут искажениям):
Полином локаторов ошибок:
Имеем вычисленные локаторы ошибок, заметим, что декодер сделал правильное предположение о количестве искаженных байтов (13):
Также имеем вычисленные полиномы величин ошибок и формальной производной:
Также имеем вычисленные величины ошибок:
Сформированный полином ошибок:
Вывод. Ознакомились с принципами кодирования/декодирования информации при помощи кодов Рида-Соломона. Получили практические навыки работы в программе RSCODEC, которая осуществляет кодирование текстовой информации при помощи кодов Рида-Соломона.
Подобные документы
Разработка алгоритма и программы кодирования и декодирования данных кодом Рида-Малера. Понятие избыточных кодов, их применение. Корелляционный код. Особенности построения простых помехоустойчивых кодов Рида-Маллера. Рассмотрение частных случаев.
курсовая работа [31,9 K], добавлен 09.03.2009
Коды Боуза-Чоудхури-Хоквингема (БЧХ) – класс циклических кодов, исправляющих многократные ошибки. Отличие методики построения кодов БЧХ от обычных циклических. Конкретные примеры процедуры кодирования, декодирования, обнаружения и исправления ошибок.
реферат [158,2 K], добавлен 16.07.2009
Циклические коды как подкласс (подмножество) линейных кодов, пошаговый алгоритм и варианты их кодирования и декодирования. Методика построения интерфейса отладочного модуля. Элементарный план и элементы отладки декодирующего модуля циклических кодов.
лабораторная работа [133,8 K], добавлен 06.07.2009
Определение понятий кода, кодирования и декодирования, виды, правила и задачи кодирования. Применение теорем Шеннона в теории связи. Классификация, параметры и построение помехоустойчивых кодов. Методы передачи кодов. Пример построения кода Шеннона.
курсовая работа [212,6 K], добавлен 25.02.2009
Изучение сущности циклических кодов - семейства помехоустойчивых кодов, включающих в себя одну из разновидностей кодов Хэмминга. Основные понятия и определения. Методы построения порождающей матрицы циклического кода. Понятие открытой системы. Модель OSI.
- устройствах памяти (включая магнитные ленты, CD, DVD, штриховые коды, и т.д.);
- беспроводных или мобильных коммуникациях (включая сотовые телефоны, микроволновые каналы и т.д.);
- спутниковых коммуникациях;
- цифровом телевидении / DVB (digital video broadcast );
- скоростных модемах, таких как ADSL , xDSL и т.д.
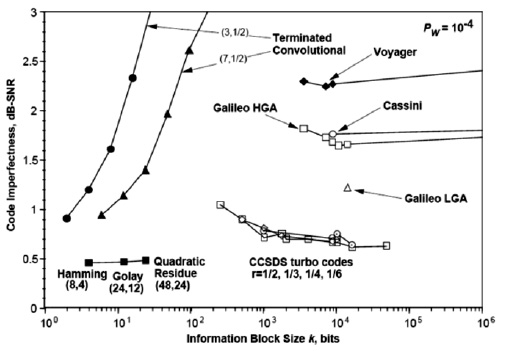
Рис. 4.3. Несовершенство кода, как функция размера информационного блока для разных задач и алгоритмов

Свойства кодов Рида-Соломона
Коды Рида-Соломона являются субнабором кодов BCH и представляют собой линейные блочные коды. Код Рида-Соломона специфицируются как RS(n,k) s -битных символов.
Это означает, что кодировщик воспринимает k информационных символов по s битов каждый и добавляет символы четности для формирования n символьного кодового слова. Имеется nk символов четности по s битов каждый. Декодер Рида-Соломона может корректировать до t символов, которые содержат ошибки в кодовом слове, где 2t = n–k .
Диаграмма, представленная ниже, показывает типовое кодовое слово Рида-Соломона:
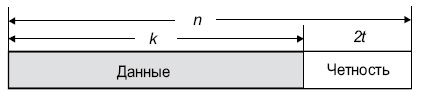
n = 255, k = 223, s = 8
При размере символа s , максимальная длина кодового слова ( n ) для кода Рида-Соломона равна n = 2 s – 1 .
Коды Рида-Соломона могут быть в принципе укорочены путем обнуления некоторого числа информационных символов на входе кодировщика (передавать их в этом случае не нужно). При передаче данных декодеру эти нули снова вводятся в массив.
Пример. Код (255, 223), описанный выше, может быть укорочен до (200, 168). Кодировщик будет работать с блоком данных 168 байт, добавит 55 нулевых байт, сформирует кодовое слово (255, 223) и передаст только 168 информационных байт и 32 байта четности .
Объем вычислительной мощности, необходимой для кодирования и декодирования кодов Рида-Соломона, зависит от числа символов четности . Большое значение t означает, что большее число ошибок может быть исправлено, но это потребует большей вычислительной мощности по сравнению с вариантом при меньшем t .
Ошибки в символах
Одна ошибка в символе происходит, когда 1 бит символа оказывается неверным или когда все биты неверны.
Коды Рида-Соломона особенно хорошо подходят для корректировки кластеров ошибок (когда неверными оказываются большие группы бит кодового слова, следующие подряд).
Декодирование
Когда кодовое слово декодируется, возможны три варианта.
- Если 2s + r ( s ошибок, r потерь), тогда исходное переданное кодовое слово всегда будет восстановлено. В противном случае
- Декодер детектирует ситуацию, когда он не может восстановить исходное кодовое слово. или
- Декодер некорректно декодирует и неверно восстановит кодовое слово без какого-либо указания на этот факт.
Вероятность каждого из этих вариантов зависит от типа используемого кода Рида-Соломона, а также от числа и распределения ошибок.
Объяснение кода Рида-Соломона, написанного для программистов

Аннотация:Недавно я увидел код RS и нашел его довольно интересным. Я нашел некоторые материалы для изучения и обнаружил, что программистам будет легче начать с этой статьи. Прочитав его, я захотел перевести его и посмотреть, насколько я понял, поэтому я придумал эту статью. Есть некоторые ошибки в этой статье и некоторые опечатки. Если вам интересно, лучше прочитать оригинальный текст :)
Коды коррекции ошибок Рида-Соломона (далее называемые кодами RS) широко используются в хранилищах данных (таких как CD) и в приложениях передачи. Однако в этих приложениях кодовые слова скрыты в электронном устройстве, поэтому невозможно понять, как они выглядят и насколько они эффективны. Некоторые сложные конструкции штрих-кодов также используют коды RS, которые могут раскрыть все детали.Это очень интересный способ для энтузиастов, которые хотят получить информацию из первых рук о том, как эта технология работает.
В этой статье я пытаюсь представить основные принципы кодов RS с точки зрения программиста (не математика). Я буду использовать популярный QR-код в качестве примера, чтобы представить. Я выбрал Python (в основном потому, что написанный мною код выглядит аккуратно и красиво), но я также представлю некоторые менее очевидные возможности Python, чтобы те, кто не знаком с Python, могли его понять. Используемая в нем математика предъявляет определенные требования к читателям и обычно преподается в университетах, но ее должны понимать люди, хорошо разбирающиеся в алгебре средней школы.
1. Структура QR-кода

1.1 Маска
Причина необходимости обработки маски состоит в том, чтобы избегать таких фигур, как локаторные узоры или большие пустые области в области данных, которые могут запутать сканер. Процесс маскирования инвертирует некоторые модули (белый становится черным, а черный становится белым), оставляя другие модули без изменений.
Обратитесь к рисунку ниже, красная область кодируется с помощью шаблона фиксированной маски, и информация о формате маски области данных (черно-белая часть) сохраняется. Когда QR-код создан, кодировщик пытается выбрать шаблон маски, который минимизирует нежелательные функции. Информация о выбранном режиме маски будет сохранена в информации о формате (красная область), чтобы декодер знал, какой из них использовать. Светло-серая область - это фиксированный шаблон, который не содержит никакой информации. Кроме того, в режиме локатора он также содержит линейку (timing patterns Справочное объяснение)。Исходное изображение

1.2 Формат информации
Существует еще одна распознаваемая копия информации о формате, поэтому, даже если один из них будет уничтожен, все равно есть шанс быть распознанным. Копия делится на две части, размещается сбоку от двух других локаторов, а также читается против часовой стрелки (вверх по левому нижнему локатору, а затем по верхнему правому краю локатора слева направо).
Первые 2 формата информацииbitsПриведен уровень исправления ошибок, используемый для данных. QR-код этого размера содержит 26 байт (bytes,1 byte = 8 bits) Информация, некоторые из которых используются для хранения исходных данных, а некоторые используются для хранения контрольных кодов, как показано в следующей таблице. Первый столбец слева - это просто простое имя для уровня исправления ошибок.
| Уровень исправления ошибок | Индикатор уровня | Коды исправления ошибок | Количество оригинальных байтов данных |
|---|---|---|---|
| L | 01 | 7 | 19 |
| M | 00 | 10 | 16 |
| Q | 11 | 13 | 13 |
| H | 10 | 17 | 9 |
Следующие 3 в формате информацииbitsИспользуется для указания шаблона маски, используемого для области данных. Образец определен способом пения 6x6, повторяемым по мере необходимости, чтобы покрыть всю область. Шаблон показан ниже, включая соответствующую математическую формулу, чтобы указать, является ли каждый модуль (в маске) черным (i и j - числа, начинающиеся с 0 в строках и столбцах, считая от верхнего левого угла)Исходное изображение

Остальные 10 в формате информацииbitsОн используется для проверки ошибки самой информации о формате, что будет объяснено в последующих главах.
1.3 Данные
На следующем рисунке показан увеличенный рисунок после операции обратной маски. Различаются разные области, в том числе края области данных.Исходное изображение

Биты данных начинаются с правого нижнего угла и поднимаются зигзагообразно вдоль двух крайних правых столбцов. Первые три байта: 01000000 11010010 01110101 (Примечание: см. Небольшую стрелку в правом нижнем углу рисунка). Следующие два столбца читаются сверху вниз, поэтому следующий байт - 01000111. Прочитав до конца, прочитайте следующие два столбца снизу вверх . таким образом, прочитайте до самого левого столбца (если необходимо, пропустите схему синхронизации). Ниже приводится полное шестнадцатеричное представление данных:
Первоначальная информация: 40 d2 75 47 76 17 32 06 27 26 96 c6 c6 96 70 ec
Исправление ошибок: bc 2a 90 13 6b af ef fd 4b e0
1.4 Декодирование
| Название проекта | Индикатор режима | Длина в байтах | Количество байтов данных |
|---|---|---|---|
| цифровой | 0001 | 10 | 10 bits per 3 digits |
| буква и цифра | 0010 | 9 | 11 bits per 2 characters |
| байт | 0100 | 8 | 8 bits per character |
| китайский символ | 1000 | 8 | 13 bits per character |
Длина байтов действительна только для маленьких QR-кодов
2. Код БЧХ
2.1 Обнаружение ошибок МПБ
Следующая функция Python реализует этот процесс
4.2.2 Обработка ошибок (так же, как python, опущено)
4.2.3 Генератор РС полином
Код RS использует аналогичный код BCH Генератор полинома , Умножить (x-α ^ n). Например:
g(x) = (x - α^0) (x - α^1) (x - α^2) (x - α^3) = 01 x^4 + 0f x^3 + 36 x^2 + 78 x^1 + 40
Следующая функция вычисляет генераторный полином, необходимый для заданного количества символов проверки кода RS:
Эта функция не очень эффективна, потому что она последовательно выделяет больший массив для g в каждом цикле, но это не является узким местом в практических приложениях. Если вы заинтересованы в читателях оптимизации, вы можете переписать его и позволить выделять только для g один раз.
4.2.4. Полиномиальное деление
Среди существующих алгоритмов полиномиального деления самым простым является алгоритм, аналогичный целочисленному делению. В следующем примере показано, как кодируются данные 12 34 56 (примечание: это выражается в шестнадцатеричном формате):
Соедините остаток и исходные данные, чтобы получить закодированные данные 12 34 56 37 e6 78 d9. Этот вид целочисленного деления неэффективен из-за множества циклов соглашения, необходимых в реализации алгоритма.Синтетическое подразделение (синтетическое подразделение)Это более эффективный алгоритм. Следующий код представляет собой расширенную реализацию алгоритма до полинома GF (2 ^ p):
4.2.5 Функция кодирования
4.3.2 Расчет синдрома
Продолжая приведенный выше пример, мы видим, что синдромы (закодированных) данных действительно равны 0, и после внесения ошибки мы получим ненулевые синдромы.
Следующий код используется для автоматической проверки правильности информации:
=== Начало аннотации ===
Полученные данные r (x) получают путем объединения кодированных данных (кодовое слово кода RS) c (x) и ошибки e (x):
r(x) = c(x) + e(x)
Помните v = nsym, потому что c (x) является корнем полинома генератора в α ^ 0, α ^ 1, α ^ 2, . α ^ (v-1) (см. Определение генератора полинома, чтобы увидеть, Обратите внимание, что + на самом деле -), и c (x) может быть выражено как q (x) * g (x) (если вы не понимаете, пожалуйста, обратитесь к аннотациям в разделе 2.1), поэтому результат оценки c (x) здесь должен быть Это 0.
Если значение r (x) равно 0, это означает, что e (x) также равно 0, что указывает на то, что оно либо в порядке, либо ошибочно, что его вообще нельзя найти (это другое кодовое слово). Если r (x) не равно 0, то синдром S является точно значением всех e (x):
S[0] = e(1), S[1] = e(α^1), S[2] = e(α^2), . S[v-1] = e(α^(v-1))
Если количество неправильных кодовых слов не превышает v / 2, информация может быть восстановлена через S.
=== Конец аннотации ===
4.3.3 Устранение (стирание) исправление
Затем вычислите дискриминант ошибок (полином для оценки стирания / ошибки), который достигается полиномиальным умножением и затем полиномиальным делением:
Наконец, алгоритм Форни реализует шаг 4. Следующая функция содержит алгоритм для достижения исправления и исключения:
Python отмечает:Эта функция использует [:: - 1] для изменения порядка элементов списка.
Тест кода выглядит следующим образом:
4.3.4 Исправление ошибок
Более вероятные случаи - это ошибки в неизвестных местах, поэтому первым делом нужно их найти. Алгоритм Берлекампа-Масси (обычно называемый алгоритмом BM) используется для вычисления полинома ошибки. Тогда нам нужно только вычислить нулевую точку этого (местоположения ошибки) полинома (аннотация: должна ссылаться на корень полинома), который отмечает позицию ошибки.
Далее мы используем простой и прямой метод тестирования, чтобы найти 0 в полиноме через эту формулу позиционирования, а затем найти неправильную позицию. код шоу, как показано ниже:
Аннотация: я не рассматривал этот алгоритм более подробно: в общем, он использует тождество Ньютона (составленное в соответствии с 4.3.3), чтобы сгенерировать полином местоположения ошибки, а затем оценить его, чтобы получить местоположение ошибки. Для более подробной информации, пожалуйста, обратитесь кAN2407.pdf
Этот метод неэффективен, и поиск Chien является более эффективным алгоритмом.
4.3.5 Устранение и исправление ошибок
Синдром Форнея может быть использован для замены синдрома при обычном поиске местоположения ошибки.
Следующая функция rs_correct_errata дает полный процесс, используя -1 в позиции, где исключается msg_in.
Замечание по Python: два массива erase_pos и err_pos связаны операцией +.
Это последний сегмент, необходимый для реализации полнофункционального декодера RS исправления ошибок / устранения ошибок. Если вы хотите пойти глубже, оригинальный автор рекомендует книгу "Algebraic Codes for Data Transmission》
5 Упакуйте экземпляр
В следующем примере показано, как использовать код выше для кодирования и декодирования:

ГОСТ
Кодирование Рида-Соломона
Кодирование Рида-Соломона – это помехоустойчивое кодирование цифровых сигналов и данных, применяемое для защиты передаваемой или хранимой информации от ошибок. Коды Рида-Соломона относятся к классу линейных блочных циклических кодов.
Как и у всех помехоустойчивых кодов, исправляющая способность кода Рида-Соломона основана на добавлении избыточности в информационные данные. Коды были разработаны в 1960 году в Массачусетском технологическом институте Ирвином Ридом и Густавом Соломоном и являются частным случаем БЧХ-кодов (кодов Боуза-Чоудхури-Хоквингема).
Добавление избыточных (проверочных) символов к передаваемой информации приводит к уменьшению скорости передачи информации, добавляя большее количество избыточных символов, которые улучшают исправляющую способность кода, но уменьшают скорость передачи информации. Поэтому всегда нужен баланс между двумя этими характеристиками кода. Для блоковых кодов американский инженер и математик Клод Шеннон доказал свою теорему для каналов с шумами, которая утверждает, что “при помощи подходящих кодов можно передавать информацию с любой скоростью, не превосходящей пропускной способности канала, так, чтобы вероятность ошибки после декодирования была произвольно малой”.
Коды Рида-Соломона используются в следующих современных системах цифровой передачи и хранения информации:
- спутниковая связь;
- мобильная связь;
- цифровое DVB-телевидение;
- модемы передачи данных;
- запись и хранение данных на CD и DVD дисках;
- штрих-коды и QR-коды.
При передаче информации в каналах связи возникают помехи, при хранении информации на DVD дисках могут появиться царапины, QR-код может нечётко пропечататься, и всё это приводит к ошибкам в первоначальной информации. Искажения информации для двоичных сигналов выражаются в замене битов “0” на “1” и наоборот, битов “1” на “0”. Использование кода Рида-Соломона позволяет не только обнаружить факт искажения первоначальной информации, но и локализовать искажённую позицию, а для двоичной информации это равносильно исправлению ошибки. На практике впервые коды Рида-Соломона были применены при записи информации на лазерные компакт-диски.
Готовые работы на аналогичную тему
В блочных кодах каждый блок кодируется и декодируется отдельно, независимо от других блоков. Кодер блочного кода можно условно представить некоторой функцией, на вход которой поступают k символов, а на выходе образуется n символов. Декодер представляет функцию, на вход которой поступают n символов, а на выходе образуется k символов. Блочный код можно задать несколькими способами – с помощью кодовой таблицы, порождающей матрицы или порождающего полинома.
Реализация кодера и декодера на С++
Также надо обратить внимание на то, что существуют две разновидности кодов Рида-Соломона – систематический и несистематический. При систематическом кодировании исходные $k$ информационных символов остаются неизменными, а проверочные $m$ символов добавляются в конце информационного слова. Поэтому при декодировании такого кода, в случае если ошибки в текущем блоке не обнаруживаются, то просто отбрасываются проверочные символы, а остаются чистые информационные символы. Если ошибки были обнаружены, то они исправляются в информационном блоке, а затем также отбрасывается проверочный блок.
При несистематическом кодировании исходный информационный блок умножается на порождающий полином кода, в результате чего генерируются проверочные $m$ символов и добавляются к исходным $k$ символам, но позиции информационных и проверочных символов в результирующем блоке перемешаны. При декодировании такого кода, даже если ошибки в текущем блоке не обнаружены, необходима обратная операция деления на порождающий полином кода, для выделения информационных символов.
Программно кодер систематического кода Рида-Соломона можно представить в виде регистра сдвига (последовательность ячеек памяти), в который посимвольно поступают из массива данных информационные символы, в отдельном регистре хранится порождающий полином кода и на каждом шаге производится поразрядное умножение содержимого регистра на порождающий полином.
Читайте также: