
Оптимальный код сжатие информации кратко
Обновлено: 03.07.2024
Аннотация: В лекции рассматриваются основные понятия и алгоритмы сжатия данных, приводятся примеры программной реализации алгоритма Хаффмана через префиксные коды и на основе кодовых деревьев.
Цель лекции: изучить основные виды и алгоритмы сжатия данных и научиться решать задачи сжатия данных по методу Хаффмана и с помощью кодовых деревьев.
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и насколько та или иная информация при этом сожмется. Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Шенон предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0,6 – 1,3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение .
Сжатие данных – это процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Сжатие данных можно разделить на два основных типа:
- Сжатие без потерь (полностью обратимое) – это метод сжатия данных, при котором ранее закодированная порция данных восстанавливается после их распаковки полностью без внесения изменений. Для каждого типа данных, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
- Сжатие с потерями – это метод сжатия данных, при котором для обеспечения максимальной степени сжатия исходного массива данных часть содержащихся в нем данных отбрасывается. Для текстовых, числовых и табличных данных использование программ, реализующих подобные методы сжатия, является неприемлемыми. В основном такие алгоритмы применяются для сжатия аудио- и видеоданных, статических изображений.
Алгоритм сжатия данных (алгоритм архивации) – это алгоритм , который устраняет избыточность записи данных.
Введем ряд определений, которые будут использоваться далее в изложении материала.
Алфавит кода – множество всех символов входного потока. При сжатии англоязычных текстов обычно используют множество из 128 ASCII кодов. При сжатии изображений множество значений пиксела может содержать 2, 16, 256 или другое количество элементов.
Кодовый символ – наименьшая единица данных, подлежащая сжатию. Обычно символ – это 1 байт , но он может быть битом, тритом , или чем-либо еще.
Кодовое слово – это последовательность кодовых символов из алфавита кода. Если все слова имеют одинаковую длину (число символов), то такой код называется равномерным (фиксированной длины), а если же допускаются слова разной длины, то – неравномерным (переменной длины).
Код – полное множество слов.
Токен – единица данных, записываемая в сжатый поток некоторым алгоритмом сжатия. Токен состоит из нескольких полей фиксированной или переменной длины.
Фраза – фрагмент данных, помещаемый в словарь для дальнейшего использования в сжатии.
Кодирование – процесс сжатия данных.
Декодирование – обратный кодированию процесс, при котором осуществляется восстановление данных.
Отношение сжатия – одна из наиболее часто используемых величин для обозначения эффективности метода сжатия.

Значение 0,6 означает, что данные занимают 60% от первоначального объема. Значения больше 1 означают, что выходной поток больше входного (отрицательное сжатие, или расширение).
Коэффициент сжатия – величина, обратная отношению сжатия.

Средняя длина кодового слова – это величина, которая вычисляется как взвешенная вероятностями сумма длин всех кодовых слов.
где – вероятности кодовых слов;
Существуют два основных способа проведения сжатия.
Статистические методы – методы сжатия, присваивающие коды переменной длины символам входного потока, причем более короткие коды присваиваются символам или группам символам, имеющим большую вероятность появления во входном потоке. Лучшие статистические методы применяют кодирование Хаффмана.
Словарное сжатие – это методы сжатия, хранящие фрагменты данных в "словаре" (некоторая структура данных ). Если строка новых данных, поступающих на вход, идентична какому-либо фрагменту, уже находящемуся в словаре, в выходной поток помещается указатель на этот фрагмент. Лучшие словарные методы применяют метод Зива-Лемпела.
Рассмотрим несколько известных алгоритмов сжатия данных более подробно.
Метод Хаффмана
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Хаффмановское кодирование (сжатие) – это широко используемый метод сжатия, присваивающий символам алфавита коды переменной длины, основываясь на вероятностях появления этих символов.
Идея алгоритма состоит в следующем: зная вероятности вхождения символов в исходный текст, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Таким образом, в этом методе при сжатии данных каждому символу присваивается оптимальный префиксный код , основанный на вероятности его появления в тексте.
Префиксный код – это код, в котором никакое кодовое слово не является префиксом любого другого кодового слова. Эти коды имеют переменную длину.
Оптимальный префиксный код – это префиксный код , имеющий минимальную среднюю длину.
Алгоритм Хаффмана можно разделить на два этапа.
- Определение вероятности появления символов в исходном тексте.
Первоначально необходимо прочитать исходный текст полностью и подсчитать вероятности появления символов в нем (иногда подсчитывают, сколько раз встречается каждый символ). Если при этом учитываются все 256 символов, то не будет разницы в сжатии текстового или файла иного формата.
Далее находятся два символа a и b с наименьшими вероятностями появления и заменяются одним фиктивным символом x , который имеет вероятность появления, равную сумме вероятностей появления символов a и b . Затем, используя эту процедуру рекурсивно, находится оптимальный префиксный код для меньшего множества символов (где символы a и b заменены одним символом x ). Код для исходного множества символов получается из кодов замещающих символов путем добавления 0 или 1 перед кодом замещающего символа, и эти два новых кода принимаются как коды заменяемых символов. Например, код символа a будет соответствовать коду x с добавленным нулем перед этим кодом, а для символа b перед кодом символа x будет добавлена единица.
Коды Хаффмана имеют уникальный префикс , что и позволяет однозначно их декодировать, несмотря на их переменную длину.
Пример 1. Программная реализация метода Хаффмана.
Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранения словаря). В настоящее время данный метод практически не применяется в чистом виде, обычно используется как один из этапов сжатия в более сложных схемах. Это единственный алгоритм , который не увеличивает размер исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
Вопрос 1. Основные положения, термины и определения. Классификация кодов
Формально-математическое определение кодирования:
Тогда: отображение Т: Х → Y называется кодированием, если для ∀ y ∈ Y
∃ Т -1 (у) = х.
Множество кодовых букв (символов) называется кодовым алфавитом, а их количество - объемом алфавита или основанием кода. Количество букв в кодовом слове называется длиной кодового слова или значностью кода.
Классификация кодов
1. По наличию избыточности:
2. По значности (длине кодового слова):
3. По типу оператора кодирования:
Классификация избыточных кодов:
1. По возможностям коррекции ошибок:
2. По количеству кодируемых символов:
- непрерывные (древовидные, рекуррентные сверточные, цепные);
2. По возможности разделения информационных и проверочных символов:
Вопрос 2. Оптимальное кодирование
Естественно полагать оптимальным такое правило кодирования (критерий), при котором:
–во-первых, кодовые слова могут быть декодированы в исходную последовательность букв источника;
–во-вторых, число кодовых букв, затрачиваемых на одну букву источника, в среднем минимально.
Первое требование определяет обратимость операции кодирования – однозначность декодирования, а второе - экономность кодирования или быстродействие кодера.
Среднее число кодовых букв на одну букву источника можно определить по формуле

, (2.1)
где ni – число кодовых букв, кодирующих слово xi источника,
P(xi) – вероятность появления буквы xi на выходе дискретного источника.
Нижним теоретическим пределом для Nср является энтропия Шеннона

В оптимальном коде избыточность, связанная с неравномерностью появления символов полностью исключается.
Введение
Вопрос 1. Основные положения, термины и определения. Классификация кодов

Формально-математическое определение кодирования:
Тогда: отображение Т: Х → Y называется кодированием, если для ∀ y ∈ Y
∃ Т -1 (у) = х.
Множество кодовых букв (символов) называется кодовым алфавитом, а их количество - объемом алфавита или основанием кода. Количество букв в кодовом слове называется длиной кодового слова или значностью кода.
Классификация кодов
1. По наличию избыточности:
2. По значности (длине кодового слова):
3. По типу оператора кодирования:
Классификация избыточных кодов:
1. По возможностям коррекции ошибок:
2. По количеству кодируемых символов:
- непрерывные (древовидные, рекуррентные сверточные, цепные);
2. По возможности разделения информационных и проверочных символов:
Вопрос 2. Оптимальное кодирование
Естественно полагать оптимальным такое правило кодирования (критерий), при котором:
–во-первых, кодовые слова могут быть декодированы в исходную последовательность букв источника;
–во-вторых, число кодовых букв, затрачиваемых на одну букву источника, в среднем минимально.
Первое требование определяет обратимость операции кодирования – однозначность декодирования, а второе - экономность кодирования или быстродействие кодера.
Среднее число кодовых букв на одну букву источника можно определить по формуле
, (2.1)
где ni – число кодовых букв, кодирующих слово xi источника,
P(xi) – вероятность появления буквы xi на выходе дискретного источника.
Нижним теоретическим пределом для Nср является энтропия Шеннона
В оптимальном коде избыточность, связанная с неравномерностью появления символов полностью исключается.
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики

Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F =
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.

Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.

Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.

Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 B1
a2 B2
…
an Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:

Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Кодирование информации – процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения.
p, blockquote 1,0,0,0,0 -->

p, blockquote 2,0,0,0,0 -->
Три типа кодирования которые применяются в радиотехнических системах (РТС):
- эффективное кодирование (сжатие информации) – направленное на уменьшение избыточности информации;
- помехоустойчивое кодирование (канальное кодирование для РТС) – направленное на повышение устойчивости к частичной потери информации вследствие воздействия помех;
- криптография (кодирование с засекречиванием информации) – направленное на защиту информации от несанкционированного доступа.
Структура РТСПИ с учетом кодирования
p, blockquote 4,0,0,0,0 -->

p, blockquote 5,0,0,0,0 -->
Эффективное кодирование – процесс уменьшения избыточности информации (сжатие информации).
p, blockquote 7,0,0,0,0 -->
Если не применять сжатие, тогда понадобится гораздо большая пропускная способность канала связи.
p, blockquote 9,0,0,0,0 -->
p, blockquote 10,0,0,0,0 -->
Приемное устройство состоит из демодулятора, помехоустойчивого декодера, криптографического декодера, эффективного декодера. Сначала устраняем ошибки, затем дешифруем и разжимаем информацию, чтобы можно было воспринимать информацию.
p, blockquote 11,0,0,0,0 -->
Эффективное кодирование
Пропускная способность это ширина спектра, чем больше пропускная способность, тем быстрее передается информация и тем шире становится спектр, чем шире спектр становится, тем меньше каналов в эфире можно расположить.
p, blockquote 12,0,0,0,0 -->
Эффективное кодирование бывает:
- сжатие без потери информации — наиболее применим для сжатия текста, файлов и т.п, где потеря информации недопустима;
- сжатие с потерей – наиболее применима для сжатия аудио, речи, изображения, видео и т.п.
Если при передаче информации, мы не можем позволить себе потерять даже один бит, тогда, нужно сжимать и разжимать таким образом, чтобы разжатый файл полностью повторял то, что сжали.
p, blockquote 14,0,0,0,0 -->
Если работать с той информацией, которую можно немного исказить, то будет достигнуто лучшее сжатие. Такое сжатие применимо в аудио, сжатии речи, изображение, видео. Идет размен между степенью сжатия и качеством, но по прежнему, например картинка или звук сохранили свою информативность.
p, blockquote 15,0,0,0,0 -->
Рассмотрим пример 1 :
p, blockquote 16,1,0,0,0 -->
Есть несжатая звуковая информация разрядностью 16 бит, и частотой дискретизации 44100Гц имеет скорость 705 кБит/с. Для речи достаточно частоты дискретизации 8кГц, 16бит≈128кБит/с.
p, blockquote 17,0,0,0,0 -->
В таблице представлены скорости, которые обеспечивают речевые кодеки.
p, blockquote 18,0,0,0,0 -->

p, blockquote 19,0,0,0,0 -->
Можно битовую скорость уменьшить на несколько порядков. Это сжатие с частичной потерей информации, разборчивость плохая, но она все же будет.
p, blockquote 20,0,0,0,0 -->
Пример 2 :
p, blockquote 21,0,0,0,0 -->
Формат передачи видео PAL и SECAM без сжатия потребовал бы информационной скорости ≈ 249 МБит/с (720×576× (3×8) × 25). Со сжатием MPEG-2 информационная скорость составляет порядка 15 Мбит/с.
p, blockquote 22,0,0,0,0 -->
Сжатие без потери информации
p, blockquote 23,0,0,0,0 -->
Рассмотрим на примере алфавита. Чем буква встречается чаще, тем меньше информации она в себе несет и наоборот.
p, blockquote 24,0,0,1,0 -->
Суть сжатия без потерь заключается в том, чтобы тем символом который встречается часто присваивать короткие кодовые слова. Но тем, которые встречаются редко, можно присвоить и по длиннее кодовые слова.
p, blockquote 25,0,0,0,0 -->
Например, кодируем русский алфавит, кириллицу. Объединим буквы е и ё, тогда 32 буквы. Потребуется 5 бит, чтобы закодировать 32 различных символа. 2^5=32. Сжимаем на основании того, что какие-то буквы встречаются редко, а какие-то часто.
p, blockquote 26,0,0,0,0 -->
Оптимальный код сжатия должен учитывать вероятность появления символа, буквы. Таковым кодом является код Хаффмана .
Каким-то буквам поставим 3 бита, которые часто встречаются, Буквы, которые редко встречаются, им можно поставить 9 бит. Но нас интересует не одна буква, а текст. Для примера посмотрите табличку.
p, blockquote 28,0,0,0,0 -->
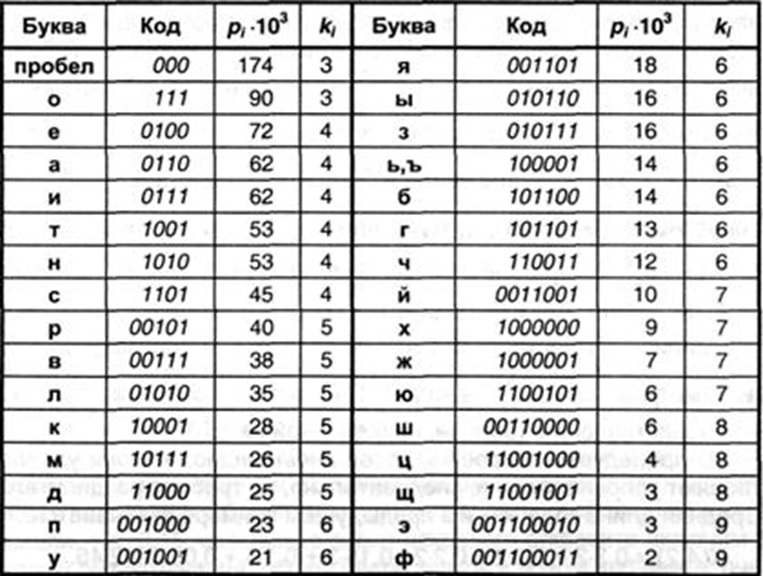
p, blockquote 29,0,0,0,0 -->
Чем больше вероятность, тем чаще буква встречается. Тем меньше кодовое слово. Несмотря на то, что часть символов имеют длину кодового слова больше, чем если кодировать напрямую, все равно, за счет тех символов, которые встречаются в среднем объем информации станет меньше.
p, blockquote 30,0,0,0,0 -->
Код Хаффмана применяется в любом сжатии, изображения, звук, только там в качестве символов не буквы, как мы рассмотрели пример, а паттерны.
p, blockquote 31,0,0,0,0 --> p, blockquote 32,0,0,0,1 -->
ИТОГ: Сжатие без потери информации осуществляется за счет того что, те символы, которые применяются часто, им ставятся короткие кодовые слова, а которые редко, там можно ставить длинные кодовые слова.
Важнейшей задачей современной информатики является кодирование информации наиболее оптимальным способом.
Один из подходов к решению проблемы сжатия информации заключался в отказе от одинаковой длины кодовых слов: часто встречающиеся символы кодировать более короткими кодовыми словами по сравнению с реже встречающимися символами.
Префиксные коды
Теоретические исследования К. Шеннона и Р. Фано показали, что можно построить эффективный неравномерный код без использования разделителя. Для этого он должен удовлетворять условию Фано: ни одно кодовое слово не является началом другого кодового слова . Коды, удовлетворяющие условию Фано называются префиксными.
Префиксный код — это код, в котором ни одно кодовое слово не является началом другого кодового слова.
Шеннон и Фано предложили алгоритм построения эффективных сжимающих кодов переменной длины (алгоритм Шеннона – Фано). Однако, в некоторых случаях алгоритм давал неоптимальное решение.
Код Хаффмана
В 1952 году Дэвид Хаффман, ученик Фано, предложил новый алгоритм кодирования и доказал оптимальность своего способа. Улучшение степени сжатия Хаффман достиг за счет кодирования часто встречающихся символов короткими кодами, реже встречающихся – длинными.

Для получения кода каждого символа движемся от корня дерева до данного символа, выписывая по ходу нули и единицы. В нашем примере символы имеют следующие коды:
Читайте также: