
Кратко сущность это бд
Обновлено: 02.07.2024
База данных (БД) — это программа, которая позволяет хранить и обрабатывать информацию в структурированном виде.
БД это отдельная независимая программа, которая не входит в состав языка программирования. В базе данных можно сохранять любую информацию, чтобы позже получать к ней доступ.
Пример использования
Базы данных нужны для хранения информации. Чтобы получить полное понимание необходимости использования БД в современном веб-программировании, необходимо ответить на три вопроса:
- Какую информацию и зачем мы храним?
- В каком виде и как надо хранить эту информацию?
- Как и каким способом можно получить доступ к этой информации?
Предположим, вы решили сделать сайт, где каждый пользователь может вести личный дневник наблюдения за погодой в своем городе.
Такой сайт должен иметь как минимум одну форму ввода со следующими полями: город, дата, температура, облачность, погодное явление, и так далее.
Каждый день наблюдатель записывает показания погоды в эту форму, чтобы когда-нибудь в будущем вернуться на сайт и посмотреть, какая была погода месяц или даже год назад.
Из этого примера следует, что программист каким-то образом должен сохранять данные из формы для дальнейшего использования.
Кроме обычного просмотра дневника погоды за месяц в виде таблицы, можно сделать и более сложный проект.
Например, чтобы электронный дневник чем-то качественно отличался от своего бумажного аналога, будет неплохо добавить туда возможности для простого анализа: показать какой день был самым холодным в ноябре или какой продолжительности была самая длинная серия пасмурных дней.
Получается, что данные надо не просто как-то хранить, но и иметь возможность их обрабатывать и анализировать.
Именно для этих целей и существуют базы данных.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Достоинствами данной модели являются
· Использование естественного языка.
Сущность XE "Сущность" это собирательное понятие, некоторая абстракция реально существующего объекта, процесса, явления или некоторого представления об объекте, информацию о котором требуется хранить в базе данных.
Выделяют три вида сущностей: стержневая, ассоциативная (ассоциация) и характеристическая (характеристика). Кроме этого во множестве ассоциативных сущностей также определяют подмножество обозначений. Дадим теперь определение видам сущностей.
Стержневая сущность XE "Стержневая сущность" .
Стержневая (сильная) XE "Сильная сущность" сущность – независящая от других сущность. Стержневая сущность не может быть ассоциацией, характеристикой или обозначением (см. ниже).
Любой фрагмент предметной области может быть представлен некоторым набором сущностей и связями между ними. Например, рассматривая предметную область ФАКУЛЬТЕТ можно выделить следующие основные сущности: СТУДЕНТ, КАФЕДРА, СПЕЦИАЛЬНОСТЬ, ДЕКАНАТ, ГРУППА, ПРЕПОДАВАТЕЛЬ, ЭКЗАМЕН . На первом этапе создания ER -модели данных следует выделить все сущности, которые предполагается описывать исходя из постановки задачи. Лишний раз подчеркнем, что сущностью может быть не только некоторый материальный объект, но и некоторый процесс, например ЭКЗАМЕН, ЛЕКЦИЯ . Сущностью может быть и некоторая количественная и качественные характеристики объекта: УЧЕНОЕ ЗВАНИЕ, СТАЖ и др. Все в действительности зависит от постановки задачи и от нашего анализа предметной области.
Основные понятия
Рассмотрим другие важные понятия, используемые при построении ER -модели. Мы ввели уже понятие сущности. Остановимся на трех других Понятиях: атрибут сущности, ключ, связь.
Система диаграмм
Таблица 1.6. Обозначения для ER- модели
Так на диаграмме изображается сильная сущность [1] .
Так на диаграмме изображается сущность, отличная от сильной сущности, без уточнения ее типа.
Атрибут сущности, являющийся первичным ключом.
Обозначает связь, между двумя сущностями.
Прямая линия указывает на связь между сущностями, либо соединяет сущность и атрибут. Линия со стрелкой указывает направленную связь.
Правила порождения
И так ER -диаграммы построены. Следующий этап проектирования – перенести диаграммы на язык таблиц конкретной СУБД. Можно сказать, что ER -диаграммы порождают реляционную базу данных. Оказывается процесс порождения можно легко формализовать, довести до автоматизма. Прежде всего, заметим, что почти всегда есть взаимнооднозначное соответствие между сущностью и таблицей. При этом атрибуты сущности переходят в атрибуты (столбцы) таблицы, а первичный ключ сущности переходит в первичный ключ таблицы. В Таблице 1.7 представлены правила соответствия бинарных связей сущностей и соответствующих элементов реляционной базы данных.
Таблица 1.7.Правила соответствия
Тип бинарной связи
Элементы реляционной базы данных
Строится одна таблица, структура которой состоит из атрибутов обеих сущностей. В качестве первичного ключа берется ключ одной из сущностей.
При построении связи на основе двух таблиц мы вынуждены допустить, что значение внешнего ключа может быть равно NULL . Если исключить эту возможность, то такую связь следует строить на основе трех таблиц. Одна таблица является таблицей – посредником. Она содержит первичные ключи двух других таблиц.
Обычно такой тип связи строится на основе трех таблиц (пар. 2, Один ко многим). Таблица посредник содержит внешний ключ, соответствующий первичному ключу первой таблицы и внешний ключ, соответствующий первичному ключу второй таблицы.
Любая связь такого типа строится на основе трех таблиц (см. пар. 2, Многие ко многим).
Правила порождения позволят легко перейти от логической модели данных к физической модели.
Заканчивая рассматривать ER -модель, заметим, что при тщательном анализе предметной области, на предмет выявления сущностей, при переходе к реляционной базе данных дополнительная нормализация таблиц, скорее всего не понадобится. Зависимости внутри таблицы часто означают, что мы в одной таблице пытаемся вместить несколько сущностей.
О диаграммных техниках, используемых при построении информационных систем
Функциональные диаграммы
Функциональное моделирование основывается на техниках SADT XE " SADT " и IDEF XE " IDEF " . SADT была предложена Дугласом Россом в середине 1960-х годов. Военно-воздушные силы США использовали методику SADT в своей программе ICAM XE " ICAM " ( Integrated Computer Aided Manufacturing – интеграция компьютерных и промышленных технологий) и назвали ее IDEF В рамках технологии SADT было разработано несколько графических языков моделирования:
■ IDEF 0 – для документирования процессов производства и отображения информации об использовании ресурсов на каждом из этапов проектирования систем.
■ IDEF 1 – для документирования информации о производственном окружении систем.
■ IDEF 2 – для отображения поведения систем во времени.
■ IDEF 3 – для моделирования бизнес процессов.
■ IDEF4 – объектно-ориентированное моделирование.
■ IDEF 5 – моделирование наиболее общих (онтологических) закономерностей системы.
Методология IDEF - SADT представляет собой совокупность методов, правил и процедур, предназначенных для построения функциональной модели какой-либо предметной области. Центральным понятием этой методологии является понятие функции XE "Функция" . Иногда используют и другие термины: деятельность или процесс. Под функцией понимается некоторое действие или набор действий, которые имеют определенную цель и приводят к конкретным результатам. Определенная функция на диаграмме обозначается прямоугольником. На диаграмме используются также стрелки, которые обеспечивают связь между различными функциями (обеспечивают интерфейсы), связывая их в конечном итоге в единую систему, моделирующую предметную область. В диаграммах используются стрелки четырех видов, их называют интерфейсными дугами:
■ I ( Input ) – вход, т.е. все что является исходным материалом для данной функции. Стрелка входит слева в прямоугольник, обозначающий данную деятельность.
■ O ( Output ) – результат выполнения функции. Стрелка выходит справа из прямоугольника, обозначающего функцию.
■ C ( Control ) – ограничения данной функции (все, что ограничивает функцию). Стрелка входит в прямоугольник сверху.
■ M ( Mechanism ) – механизм, используемый в данной функции. Стрелка входит снизу в прямоугольник - функцию.
На Рис. 1.15 представлен общий вид фрагмента диаграммы, изображенной по методологии SADT .
Рис. 1.15. Общий вид функциональной диаграммы
Рис. 1.18. Диаграмма SADT , полученная из общей диаграммы (см. Рис. 1.17) посредством детализации
Как видно, в частности, на диаграмме (Рис. 1.18), функции связываются друг с другом при помощи интерфейсных дуг. Вообще в технологии SADT выделяют семь видов связывания:
■ Логическая связность. Обусловлена тем, что функции или данные относятся к одному классу.
■ Временная связность. Такой тип связности возникает, когда функции выполняются параллельно в одно и тоже время.
■ Процедурная связность. Тип связности возникает, когда функции выполняются в одной и той же части процесса.
■ Коммуникационная связность. Возникает, когда блоки (функции) используют одни и те же данные.
■ Последовательная связность. Возникает, когда выход (выходная дуга) одной функции является одновременно входными данными для другой функции.
■ Функциональная связность. Связность возникает, когда одна функция воздействует на другую через интерфейсные дуги управления (на Рис. 1.18 блок 1 воздействует на остальные блоки как раз через дуги управления).
Диаграммы потоков данных
В основе данной методологии лежит метод диаграмм потоков данных ( DFD XE " DFD " - Data Flow Diagram ). Данные диаграммы призваны описывать процессы преобразования информации от ее ввода в систему до выдачи пользователю. Как и для диаграмм SADT здесь мы также имеем дело с целой иерархией диаграмм, в которой диаграммы нижнего уровня детализируют диаграммы верхнего уровня. Диаграммы верхнего уровня определяют основные процессы и подсистемы информационной системы с внешними входами и выходами. Далее путем декомпозиции диаграммы детализируются. В результате возникает иерархия диаграмм, на самом нижнем уровне которой описаны элементарные процессы. Основными компонентами диаграмм DFD являются:
■ Системы и подсистемы.
Рис. 1.19. Внешняя сущность в потоковых диаграммах
Внешняя сущность представляет собой физическое лицо или предмет являющийся источником или приемником информации. Объект, который мы обозначаем как внешняя сущность, является внешним по отношению к анализируемой предметной области и анализу не подвергается. Это может быть клиент какой-либо службы (если анализируется вся службы) и оператор, работающий с информационной системой (если анализу подвергается только функционирование ИС). Внешняя сущность обознается квадратом (см. Рис. 1.19), несколько приподнятым над плоскостью диаграммы.
Рис. 1.20. Обозначение подсистемы в потоковой диаграмме
На самом верхнем уровне анализируемая предметная область может быть представлена как некоторая система. В свою очередь система может быть представлена как совокупность (декомпозиция) нескольких подсистем. Каждая подсистема получает свой номер. На диаграмме она изображается в виде прямоугольника с округленными углами (см. Рис. 1.20). Здесь же указывается номер подсистемы, имя подсистемы в виде развернутого предложения и имя проектировщика данной подсистемы.
Рис. 1.21. Обозначение процесса в потоковой диаграмме
Процесс в модели DFD представляет собой некоторое преобразование входного потока данных в выходной. Под процессом можно понимать и оператора ЭВМ и программу, и работу целого отдела. На диаграмме процесс изображается как подсистема в виде прямоугольника (см. Рис. 1.21). Номер процесса является его идентификатором и состоит из номера процесса или подсистемы верхнего уровня и собственно номера процесса. Имя процесса должно содержать глагол в неопределенной форме и четко определять, что данный процесс делает. Наконец в имени процесса должен быть обозначен объект, который и реализует данный процесс.
Рис. 1.22. Накопитель в потоковой диаграмме
Под накопителем понимается некоторое устройство, используемое для хранения информации. Способы помещения и извлечения данных из накопителя могут самые разные. Накопитель данных на диаграмме изображается в виде прямоугольника (см. Рис. 1.22), разделенного на два отсека. В первом отсеке должен стоять номер накопителя, начинающийся с буквы D , во втором его имя. Имя накопителя должно быть достаточно информативным для использования его в дальнейших разработках. Разумеется при разработке информационной системы в конечном итоге под накопителем, понимается конкретная база данных.
Кроме перечисленных элементов в диаграммах DFD имеются также потоки данных, которые определяют информацию, передаваемую от источника к приемнику. Поток данных на диаграммах изображается линией, заканчивающейся стрелкой. Стрелка указывает на направление передачи информации. Кроме этого для каждого потока должно быть указано имя, которое должно определять его содержание.
UML диаграммы
Как и другие языки моделирования сложных систем, язык UML зиждется на трех принципах:
■ Абстрагирование – отбрасывание тех элементов системы, которые не существенны с точки зрения рассматриваемой модели.
■ Многомодельность – любая достаточно сложная система не может быть полностью описана только одной моделью.
■ Иерархичность – при описании данной системы используются различные уровни абстрагирования и детализации. На самой вершине иерархии расположена модель, представляющая систему в наиболее полном виде.
Всего в языке UML существует одиннадцать типов диаграмм. Каждая из диаграмм призвана конкретизировать различные представления о рассматриваемой системе. Перечислим типы диаграмм:
■ Диаграммы вариантов использования.
Остановимся только на одном типе диаграммы – диаграмме классов, который непосредственно можно применить при разработке структуры баз данных. Данный вид диаграмм должен содержать набор классов, анализируемой предметной области, связи между ними, а также возможные ограничения и комментарии.
Классом XE "Класс" в языке UML будем называть именованное описание множества однородных объектов, имеющие одинаковые атрибуты, операции XE "Операции" , отношения с другими объектами и семантику.
Атрибут класса XE "Атрибут класса" - именованное свойство класса, описывающее множество значений, которые принимают экземпляры этого свойства.
Операцией класса XE "Операция класса" будем называть именованную услугу, которую можно запросить у любого экземпляра данного класса.
Между классами в диаграмме могут существовать связи трех типов: зависимости, обобщения и ассоциации.
Определение зависимости XE "Зависимости" .
Связь между двумя классами называю зависимостью, если изменение в спецификации одного класса может повлиять на поведение другого класса.
Определение обобщения XE "Обобщения" .
Обобщением называется связь между классами, когда один из классов является частным случаем второго.
Общий класс при наследовании называется родителем, предком или суперклассом XE "Суперкласс" , а частный класс – потомком. Например, при анализе такой системы как школа, можно выделить суперкласс Человек, в который будут входить такие классы – потомки, как учителя, административные работники школы, ученики, родители учеников. В дальнейшем класс учителей можно рассматривать как суперкласс по отношению к обычным учителям и классным руководителям.
Определение ассоциации XE "Ассоциации" .
Ассоциация показывает, что между объектами одного класса существует некоторая связь с объектами другого класса. Допускается, что класс может быть связан сам с собой. Кроме этого в связи могут участвовать более двух классов.
Ассоциативная связь может характеристики:
■ Роли связи XE "Роли связи" . Для каждого класса, участвующего в ассоциативной связи могут быть указаны роли. Например, для связи между классами Учителя и Ученики можно указать роли: обучающий и обучаемый.
■ Кратность связи XE "Кратность связи" . Кратность определяет, сколько объектов данного класса может или должно участвовать в данной связи. Например, кратность 0..1 говорит, что не все экземпляры класса могут участвовать в данной связи, но в каждом экземпляре связи может участвовать только один объект класса.
В диаграммах классов могут также указываться ограничения, которые затем должны поддерживаться в базах данных. Ограничения могут выражаться предложениями на естественном языке, но могут записываться на специальном языке OCL XE " OCL " ( Object Constraint Language – язык объектных ограничений). Язык OCL является подмножеством языка UML . Это формальный язык, который позволяет выразить логику ограничений, накладываемых на отдельные элементы диаграмм.
Рис. 1.24. пример простейшей UML -диаграммы
На Рис. 1.24 представлена простейшая UML -диаграмма, на которой изображено три класса: Студенты, Оценки, Предметы. Связь между всеми тремя между всеми тремя классами носит ассоциативную природу. Обратите внимание на значок . Он означает, что налицо агрегатной связи – оценка ставится конкретному студенту и неотъемлемо принадлежит ему. Более того, данный тип агрегации, несомненно, является композитной (закрашенный ромб), так как оценки не могут существовать без конкретного студента. У каждой связи указывается его имя, но роли связи я не указываю, так в данном случае это не добавляет ясности в диаграмму, а скорее затруднит ее чтение. Обратим внимание, что у каждого класса указываются не только атрибуты, но операции (или методы). Разумеется, диаграмма может не вместить все атрибуты и операции.
[1] Разумеется, читатель должен понимать, что речь идет о классе (наборе) сущностей.
При проектировании базы данных и разработке программного продукта наиболее важной проблемой есть проблема взаимодействия разработчика с заказчиком. Задача разработчика – наиболее точно воссоздать пожелания заказчика при разработке программного продукта управления базой данных. Основная проблема, которую нужно решить разработчику – правильное построение базы данных, а точнее схемы (структуры) базы данных.
Кроме того, разработчик дополнительно встречается с другими трудностями, к которым можно отнести:
- поиск эффективных алгоритмов;
- подбор надлежащих структур данных;
- отладка и тестирование сложного кода;
- дизайн и удобство интерфейса приложения.
В процессе разработки программного обеспечения, управляющего базой данных, разработчик должен подробно выучить требования заказчика. База данных должна быть разработана таким образом, чтобы она была понятной, наиболее точно отображала решаемую проблему и не содержала избыточности в данных.
Чтобы облегчить процесс разработки (проектирования) базы данных, используются так называемые семантические модели данных. Для разных видов баз данных наиболее известной есть ER-модель данных (Entity-Relationship model).
2. Что такое ER-модель (Entity-relationship model)? Для чего нужно разрабатывать ER-модель?
Для больших баз данных построение ER-модели позволяет избежать ошибок проектирования, которые чрезвычайно сложно исправлять, в особенности, если база данных уже эксплуатируется или на стадии тестирования. Ошибки в разработке структуры базы данных могут привести к переделке кода программного обеспечения управляющего этой базой данных. В результате время, средства и человеческие ресурсы будут использованы неэффективно.
ER-модель – это только концептуальный уровень моделирования. ER-модель не содержит деталей реализации. Для той же самой ER-модели детали ее реализации могут отличаться.
3. Что такое сущность в базе данных? Примеры
Сущность в базе данных – это любой объект в базе данных, который можно выделить исходя из сути предметной области для которой разрабатывается эта база данных. Разработчик базы данных должен уметь правильно определять сущности.
Пример 1. В базе данных книжного магазина можно выделить следующие сущности:
- книга;
- поставщик;
- размещение в магазине.
Пример 2. В базе данных учета учебного процесса некоторого учебного заведения можно выделить следующие сущности:
- студенты (ученики);
- преподаватели;
- группы;
- дисциплины, которые изучаются.
4. Какие существуют разновидности типов сущностей? Обозначение типов сущностей в ER-модели
- слабый тип. Этот тип сущности есть зависимым от сильной сущности;
- сильный тип. Это самостоятельный тип сущности, который ни от кого не зависит.
На рисунке 1 изображены обозначения слабого и сильного типа сущности в ER-модели.

Рис. 1. Обозначение сильного и слабого типов сущности
5. Для чего предназначены атрибуты? Виды атрибутов. Обозначение атрибутов на ER-модели
Каждый тип сущности имеет определенный набор атрибутов. Атрибуты предназначены для описания конкретной сущности.
Различают следующие виды атрибутов:
На ER-диаграмме атрибуты обозначаются так, как изображено на рисунке 2. Как видно из рисунка, любой атрибут обозначается в виде эллипса с названием внутри эллипса. Если атрибут есть первичным ключом, то его название подчеркивают.
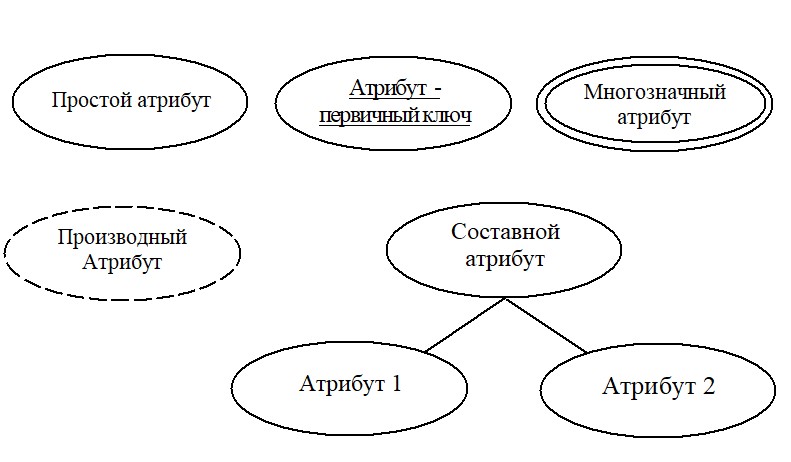
Рисунок 2. Представление атрибутов на диаграммах ER-модели
6. Как типы сущностей и атрибуты ER-модели реализуются в реальных базах данных и управляемых ими программах?
При разработке программ управления базами данных, типы сущностей и их атрибуты можно представлять по разному при этом придерживаясь нескольких подходов:
- выбрать в качестве источника данных известную технологию (например Microsoft SQL Server, Oracle Database, Microsoft Access, Microsoft ODBC Data Source и т.п.), которая уже исследована, протестирована, стандартизирована и имеет огромный набор средств управления базой данных;
- разработать собственный формат базы данных и реализовать методы ее обработки, а взаимодействие с известными источниками данных реализовать в виде специальных команд наподобие Импорт/Экспорт. В этом случае придется собственноручно программировать всю рутинную работу по ведению и обеспечению надежной работы базы данных;
- реализовать объединение двух вышеприведенных подходов. Современные средства разработки программного обеспечения имеют мощный набор библиотек для обработки сложных наборов и визуализации данных в них (коллекции, массивы, компоненты визуализации и т.п.).
Если база данных реализуется в известных реляционных СУБД (например Microsoft Access, Microsoft SQL Server и т.п.), то типы сущностей представляются таблицами. Атрибуты из ER-модели соответствуют полям таблицы. Одна запись в таблице базы данных представляет один экземпляр сущности.
Каждый вид атрибута реализуется следующим образом:
- простой атрибут или однозначный атрибут может быть представлен доступным набором базовых типов, которые есть в любом языке программирования. Например, целочисленные атрибуты представляются типом int , integer , uint и т.д.; атрибуты содержащие дробную часть могут быть представлены типом float , double ; строчные атрибуты типом string и т.д.;
- составной атрибут – это объект, который включает в себя несколько вложенных простых атрибутов. Например, в СУБД Microsoft Access составной атрибут некоторой таблицы может формироваться на основе набора простых типов (полей). В языках программирования объединение полей реализуется структурами или классами;
- многозначный атрибут может быть реализован массивом или коллекцией простых или составных атрибутов;
- произвольный атрибут реализуется дополнительным полем, которое вычисляется при обращении к таблице. Такое поле называется вычислительным полем (calculated field) и формируется на основе других полей таблицы;
- атрибут, который есть первичным ключом может быть целочисленным, строчным или иного порядкового типа. В этом случае, значение каждой ячейки таблицы, которая соответствует первичному ключу, есть уникальным. Наиболее часто, в качестве первичного ключа выступает целый тип ( int , integer ).
Если база данных реализована в уникальном формате, то типы сущностей удобнее всего представлять в виде классов или структур. Атрибуты сущности реализуются в виде полей (внутренних данных) класса. Методы класса реализуют необходимую обработку полей класса (атрибутов). Взаимодействие (связь) между классами реализуется с помощью специально разработанных интерфейсов с использованием известных шаблонов проектирования.
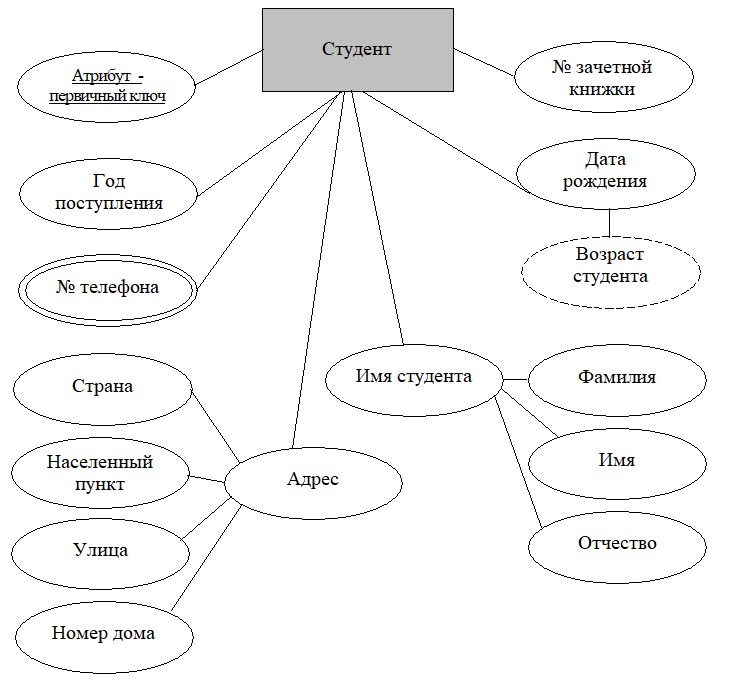
На вышеприведенном рисунке объявляются следующие атрибуты, которые в СУБД (программе) могут иметь следующие типы:
Аннотация: В лекции рассматривается общий смысл понятий базы данных (БД) и системы управления базами данных (СУБД). Даются основные понятия, относящиеся к базе данных такие, как алгоритм, кортеж, объект, сущность. Основные требования, предъявляемые к банку данных. Определения БД и СУБД.
Цель лекции: Уяснить разницу между базой данных и системой управления базой данных. Ознакомиться с основными требованиями, которые предъявляются к банку данных и основными определениями, относящимися к БД и СУБД.
Рассмотрим общий смысл понятий базы данных (БД) и системы управления базами данных (СУБД).
С самого начала развития вычислительной техники образовались два основных направления использования ее.
Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление, это использование средств вычислительной техники в автоматических или автоматизированных информационных системах . В самом широком смысле информационная система представляет собой программный комплекс, функции которого состоят в поддержке надежного хранения информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы , системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т.д.
На самом деле, второе направление возникло несколько позже первого. Это связано с тем, что на заре вычислительной техники компьютеры обладали ограниченными возможностями в части памяти. Понятно, что можно говорить о надежном и долговременном хранении информации только при наличии запоминающих устройств, сохраняющих информацию после выключения электрического питания. Оперативная память этим свойством обычно не обладает. В начале, использовались два вида устройств внешней памяти: магнитные ленты и барабаны. При этом емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они больше всего похожи на современные магнитные диски с фиксированными головками) давали возможность произвольного доступа к данным, но были ограниченного размера.
Легко видеть, что указанные ограничения не очень существенны для чисто численных расчетов. Даже если программа должна обработать (или произвести) большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти, чтобы программа работала как можно быстрее.
С другой стороны, для информационных систем, в которых потребность в текущих данных определяется пользователем, наличие только магнитных лент и барабанов неудовлетворительно. Представьте себе покупателя билета, который стоя у кассы должен дождаться полной перемотки магнитной ленты. Одним из естественных требований к таким системам является средняя быстрота выполнения операций.
Именно требования к вычислительной технике со стороны не численных приложений вызвали появление съемных магнитных дисков с подвижными головками , что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной и внешней памятью с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.
Историческим шагом стал переход к использованию систем управления файлами. С точки зрения прикладной программы файл - это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса внешней памяти и обеспечение доступа к данным.
Любая задача обработки информации и принятия решений может быть представлена в виде схемы, показанной на рис. 1.1.
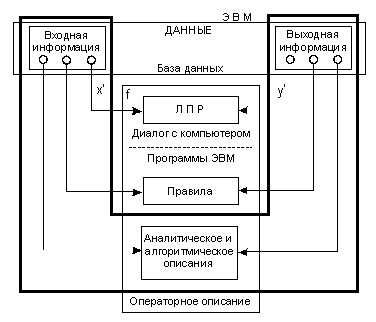
Рис. 1.1. Схема решения задач обработки информации и принятия решений: x-штрих, y-штрих - входная и выходная информация; f - внутреннее операторное описание
Определение основных терминов
Дадим определения основных терминов. В качестве составных частей схемы выделяются информация (входная и выходная) и правила ее преобразования.
Правила могут быть в виде алгоритмов, процедур и эвристических последовательностей.
Последовательность операций обработки данных называют информационной технологией (ИТ). В силу значительного количества информации в современных задачах она должна быть упорядочена. Существует два подхода к упорядочению.
- Данные связаны с конкретной задачей (технология массивов) - упорядочение по использованию. Вместе с тем алгоритмы более подвижны (могут чаще меняться), чем данные. Это вызывает необходимость переупорядочения данных, которые к тому же могут повторяться в различных задачах.
- В связи с этим предложена другая, широко используемая технология баз данных, представляющая собой упорядочение по хранению.
Под базой данных (БД) понимают совокупность хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений. Целью создания баз данных , как разновидности информационной технологии и формы хранения данных, является построение системы данных, не зависящих от принятых алгоритмов (программного обеспечения), применяемых технических средств и физического расположения данных в ЭВМ; обеспечивающих непротиворечивую и целостную информацию при нерегламентируемых запросах. БД предполагает многоцелевое ее использование (несколько пользователей, множество форм документов и запросов одного пользователя).
База знаний (БЗ) представляет собой совокупность БД и используемых правил, полученных от лиц, принимающих решения ( ЛПР ).
Наряду с понятием "база данных" существует термин " банк данных ", который имеет две трактовки.
- В настоящее время данные обрабатываются децентрализовано (на рабочих местах) с помощью персональных компьютеров (ПК). Первоначально же использовалась централизованная обработка на больших ЭВМ. В силу централизации базу данных называли банком данных и потому часто не делают различия между базами и банками данных.
- Банк данных - база данных и система управления ею (СУБД). СУБД (например, FoxPro) представляет собой приложение для создания баз данных как совокупности двумерных таблиц.
Иногда в составе банка данных выделяют архивы. Основанием для этого является особый режим использования данных, когда только часть данных находится под оперативным управлением СУБД. Все остальные данные обычно располагаются на носителях, оперативно не управляемых СУБД. Одни и те же данные в разные моменты времени могут входить как в базы данных, так и в архивы. Банки данных могут не иметь архивов, но если они есть, то в состав банка данных может входить и система управления архивами.
Эффективное управление внешней памятью являются основной функцией СУБД . Эти обычно специализированные средства настолько важны с точки зрения эффективности, что при их отсутствии система просто не сможет выполнять некоторые задачи уже по тому, что их выполнение будет занимать слишком много времени. При этом ни одна из таких специализированных функций не является видимой для пользователя. Они обеспечивают независимость между логическим и физическим уровнями системы: прикладной программист не должен писать программы индексирования, распределять память на диске и т. д.
Основные требования, предъявляемые к банкам данных
Развитие теории и практики создания информационных систем, основанных на концепции баз данных, создание унифицированных методов и средств организации и поиска данных позволяют хранить и обрабатывать информацию о все более сложных объектах и их взаимосвязях, обеспечивая многоаспектные информационные потребности разных пользователей. Основные требования, предъявляемые к банкам данных, можно сформулировать так:
- Многократное использование данных: пользователи должны иметь возможность использовать данные различным образом.
- Простота: пользователи должны иметь возможность легко узнать и понять, какие данные имеются в их распоряжении.
- Легкость использования: пользователи должны иметь возможность осуществлять (процедурно) простой доступ к данным, при этом все сложности доступа к данным должны быть скрыты в самой системе управления базами данных.
- Гибкость использования: обращение к данным или их поиск должны осуществляться с помощью различных методов доступа.
- Быстрая обработка запросов на данные: запросы на данные должны обрабатываться с помощью высокоуровневого языка запросов , а не только прикладными программами, написанными с целью обработки конкретных запросов.
- Язык взаимодействия конечных пользователей с системой должен обеспечивать конечным пользователям возможность получения данных без использования прикладных программ.
База данных - это основа для будущего наращивания прикладных программ: базы данных должны обеспечивать возможность быстрой и дешевой разработки новых приложений.
- Сохранение затрат умственного труда: существующие программы и логические структуры данных не должны переделываться при внесении изменений в базу данных.
- Наличие интерфейса прикладного программирования: прикладные программы должны иметь возможность просто и эффективно выполнять запросы на данные; программы должны быть изолированными от расположения файлов и способов адресации данных.
- Распределенная обработка данных: система должна функционировать в условиях вычислительных сетей и обеспечивать эффективный доступ пользователей к любым данным распределенной БД, размещенным в любой точке сети.
- Адаптивность и расширяемость: база данных должна быть настраиваемой, причем настройка не должна вызывать перезаписи прикладных программ. Кроме того, поставляемый с СУБД набор предопределенных типов данных должен быть расширяемым - в системе должны иметься средства для определения новых типов и не должно быть различий в использовании системных и определенных пользователем типов.
- Контроль целостности данных: система должна осуществлять контроль ошибок в данных и выполнять проверку взаимного логического соответствия данных.
- Восстановление данных после сбоев: автоматическое восстановление без потери данных транзакции. В случае аппаратных или программных сбоев система должна возвращаться к некоторому согласованному состоянию данных.
- Вспомогательные средства должны позволять разработчику или администратору базы данных предсказать и оптимизировать производительность системы.
- Автоматическая реорганизация и перемещение: система должна обеспечивать возможность перемещения данных или автоматическую реорганизацию физической структуры .
Компоненты банка данных
Определение банка данных предполагает, что с функционально-организационной точки зрения банк данных является сложной человеко-машинной системой, включающей в себя все подсистемы, необходимые для надежного, эффективного и продолжительного во времени функционирования.
В структуре банка данных выделяют следующие компоненты:
- Информационная база;
- Лингвистические средства;
- Программные средства;
- Технические средства;
- Организационно-административные подсистемы и нормативно-методическое обеспечение.
Организационно-методические средства - это совокупность инструкций, методических и регламентирующих материалов, описаний структуры и процедуры работы пользователя с СУБД и БД.
Пользователи БД и СУБД
Пользователей (СУБД) можно разделить на две основные категории: конечные пользователи; администраторы баз данных.
Особо следует поговорить об администраторе базы данных (АБД). Естественно, что база данных строится для конечного пользователя (КП). Однако первоначально предполагалось, что КП не смогут работать без специалиста-программиста, которого назвали администратором базы данных. С появлением СУБД они взяли на себя значительную часть функций АБД, особенно для БД с небольшим объемом данных. Однако для крупных централизованных и распределенных баз данных потребность в АБД сохранилась. В широком плане под АБД понимают системных аналитиков, проектировщиков структур данных и информационного обеспечения, проектировщиков технологии процессов обработки, системных и прикладных программистов, операторов, специалистов в предметной области и по техническому обслуживанию. Иными словами, в крупных базах данных это могут быть коллективы специалистов. В обязанности АБД входит:
- анализ предметной области, статуса информации и пользователей;
- проектирование структуры и модификация данных;
- задание и обеспечение целостности;
- загрузка и ведение БД;
- защита данных;
- обеспечение восстановления БД;
- сбор и статистическая обработка обращений к БД, анализ эффективности функционирования БД;
- работа с пользователем.
Краткие итоги
Базы данных (БД) - это именованная совокупность данных, отображающая состояние объектов и их отношения в рассматриваемой предметной области.
Система управления базами данных (СУБД) - это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Основные требования, предъявляемые к банкам данных: многократное использование данных, простота, легкость использования, гибкость использования, быстрая обработка запросов на данные, язык взаимодействия.
Пользователей (СУБД) можно разделить на две основные категории: конечные пользователи; администраторы баз данных.
Читайте также: