
Иерархия это в информатике кратко
Обновлено: 02.07.2024
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
Информатика. 7 класса. Босова Л.Л. Оглавление
Логические имена устройств внешней памяти компьютера
К каждому компьютеру может быть подключено несколько устройств внешней памяти. Основным устройством внешней памяти ПК является жёсткий диск. Если жёсткий диск имеет достаточно большую ёмкость, то его можно разделить на несколько логических разделов.
Наличие нескольких логических разделов на одном жёстком диске обеспечивает пользователю следующие преимущества:
- можно хранить операционную систему в одном логическом разделе, а данные — в другом, что позволит переустанавливать операционную систему, не затрагивая данные;
- на одном жёстком диске в различные логические разделы можно установить разные операционные системы;
- обслуживание одного логического раздела не затрагивает другие разделы.
Каждое подключаемое к компьютеру устройство внешней памяти, а также каждый логический раздел жёсткого диска имеет логическое имя.
В операционной системе Windows приняты логические имена устройств внешней памяти, состоящие из одной латинской буквы и знака двоеточия:
- для дисководов гибких дисков (дискет) — А: и В:;
- для жёстких дисков и их логических разделов — С:, D:, Е: и т. д.;
- для оптических дисководов — имена, следующие по алфавиту после имени последнего имеющегося на компьютере жёсткого диска или раздела жёсткого диска (например, F:);
- для подключаемой к компьютеру флеш-памяти — имя, следующее за последним именем оптического дисковода (например, G:).
В операционной системе Linux приняты другие правила именования дисков и их разделов. Например:
- логические разделы, принадлежащие первому жёсткому диску, получают имена hdal, hda2 и т. д.;
- логические разделы, принадлежащие второму жёсткому диску, получают имена hdbl, hdb2 и т. д.
Файл
Все программы и данные хранятся во внешней памяти компьютера в виде файлов.
Файл — это поименованная область внешней памяти.
Файловая система — это часть ОС, определяющая способ организации, хранения и именования файлов на носителях информации.
Файл характеризуется набором параметров (имя, размер, дата создания, дата последней модификации) и атрибутами, используемыми операционной системой для его обработки (архивный, системный, скрытый, только для чтения). Размер файла выражается в байтах.
Файлы, содержащие данные — графические, текстовые (рисунки, тексты), называют документами, а файлы, содержащие прикладные программы, — файлами-приложениями. Файлы-документы создаются и обрабатываются с помощью файлов-приложений.
Имя файла, как правило, состоит из двух частей, разделенных точкой: собственно имени файла и расширения. Собственно имя файлу даёт пользователь. Делать это рекомендуется осмысленно, отражая в имени содержание файла. Расширение имени обычно задаётся программой автоматически при создании файла. Расширения не обязательны, но они широко используются. Расширение позволяет пользователю, не открывая файла, определить его тип — какого вида информация (программа, текст, рисунок и т. д.) в нём содержится. Расширение позволяет операционной системе автоматически открывать файл.
В современных операционных системах имя файла может включать до 255 символов, причём в нём можно использовать буквы национальных алфавитов и пробелы. Расширение имени файла записывается после точки и обычно содержит 3-4 символа.
В ОС Windows в имени файла запрещено использование следующих символов: \, /. *, ?, «, , |. В Linux эти символы, кроме /, допустимы, хотя использовать их следует с осторожностью, так как некоторые из них могут иметь специальный смысл, а также из соображений совместимости с другими ОС.
Операционная система Linux, в отличие от Windows, различает строчные и прописные буквы в имени файла: например, FILE.txt, file.txt и FiLe.txt — это в Linux три разных файла.
В таблице приведены наиболее распространённые типы файлов и их расширения:

В ОС Linux выделяют следующие типы файлов:
- обычные файлы — файлы с программами и данными;
- каталоги — файлы, содержащие информацию о каталогах;
- ссылки — файлы, содержащие ссылки на другие файлы;
- специальные файлы устройств — файлы, используемые для представления физических устройств компьютера (жёстких и оптических дисководов, принтера, звуковых колонок и т. д.).
Каталоги
На каждом компьютерном носителе информации (жёстком, оптическом диске или флеш-памяти) может храниться большое количество файлов. Для удобства поиска информации файлы по определённым признакам объединяют в группы, называемые каталогами или папками.
Каталог также получает собственное имя. Он сам может входить в состав другого, внешнего по отношению к нему каталога. Каждый каталог может содержать множество файлов и вложенных каталогов.
Каталог — это поименованная совокупность файлов и подкаталогов (вложенных каталогов).
Каталог самого верхнего уровня называется корневым каталогом.
Файловая структура диска
Файловая структура диска — это совокупность файлов на диске и взаимосвязей между ними.
Файловые структуры бывают простыми и многоуровневыми (иерархическими).
Простые файловые структуры могут использоваться для дисков с небольшим (до нескольких десятков) количеством файлов. В этом случае оглавление диска представляет собой линейную последовательность имён файлов (рис. 2.8). Его можно сравнить с оглавлением детской книжки, которое содержит названия входящих в неё рассказов и номера страниц.

Иерархические файловые структуры используются для хранения большого (сотни и тысячи) количества файлов. Иерархия — это расположение частей (элементов) целого в порядке от высшего к низшим. Начальный (корневой) каталог содержит файлы и вложенные каталоги первого уровня. Каждый из каталогов первого уровня может содержать файлы и вложенные каталоги второго уровня и т. д. (рис. 2.9). В этом случае оглавление диска можно сравнить с оглавлением нашего учебника: в нём выделены главы, состоящие из параграфов, которые, в свою очередь, разбиты на отдельные пункты и т. д.

Пользователь, объединяя по собственному усмотрению файлы в каталоги, получает возможность создать удобную для себя систему хранения информации. Например, можно создать отдельные каталоги для хранения текстовых документов, цифровых фотографий, мелодий ит. д.; в каталоге для фотографий объединить фотографии по годам, событиям, принадлежности и т. д. Знание того, какому каталогу принадлежит файл, значительно ускоряет его поиск.
Графическое изображение иерархической файловой структуры называется деревом. В Windows каталоги на разных дисках могут образовывать несколько отдельных деревьев; в Linux каталоги объединяются в одно дерево, общее для всех дисков (рис. 2.10). Древовидные иерархические структуры можно изображать вертикально и горизонтально.

Полное имя файла
Чтобы обратиться к нужному файлу, хранящемуся на некотором диске, можно указать путь к файлу — имена всех каталогов от корневого до того, в котором непосредственно находится файл.
В операционной системе Windows путь к файлу начинается с логического имени устройства внешней памяти; после имени каждого подкаталога ставится обратный слэш. В операционной системе Linux путь к файлу начинается с имени единого корневого каталога; после имени каждого подкаталога ставится прямой слэш.
Последовательно записанные путь к файлу и имя файла составляют полное имя файла. Не может быть двух файлов, имеющих одинаковые полные имена.
Пример полного имени файла в ОС Windows:
Пример полного имени файла в ОС Linux:
Задача 1. Пользователь работал с каталогом С:\Физика\Задачи\Кинематика. Сначала он поднялся на один уровень вверх, затем ещё раз поднялся на один уровень вверх и после этого спустился в каталог Экзамен, в котором находится файл Информатика.dос. Каков путь к этому файлу?
Решение. Пользователь работал с каталогом С:\Физика\Задачи\Кинематика. Поднявшись на один уровень вверх, пользователь оказался в каталоге С:\Физика\Задачи. Поднявшись ещё на один уровень вверх, пользователь оказался в каталоге СДФизика. После этого пользователь спустился в каталог Экзамен, где находится файл. Полный путь к файлу имеет вид: С:\Физика\Экзамен.
Задача 2. Учитель работал в каталоге D:\Уроки\7 класс\Практические работы. Затем перешёл в дереве каталогов на уровень выше, спустился в подкаталог Презентации и удалил из него файл Введение, ppt. Каково полное имя файла, который удалил учитель?
Решение. Учитель работал с каталогом D:\Уроки\7 класс\Практические работы. Поднявшись на один уровень вверх, он оказался в каталоге D:\Уроки\8 класс. После этого учитель спустился в каталог Презентации, путь к файлам которого имеет вид: D:\Уроки\ 7 класс\Презентации. В этом каталоге он удалил файл Введение.ppt, полное имя которого D:\Уроки\8 класс\ Презентации \Введение.ррt.
Работа с файлами
Создаются файлы с помощью систем программирования и прикладного программного обеспечения.
В процессе работы на компьютере над файлами наиболее часто проводятся следующие операции:
- копирование (создаётся копия файла в другом каталоге или на другом носителе);
- перемещение (производится перенос файла в другой каталог или на другой носитель, исходный файл уничтожается);
- переименование (производится переименование собственно имени файла);
- удаление (в исходном каталоге объект уничтожается).
Вопросы
1. Ознакомьтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Дополняет ли презентация информацию, содержащуюся в тексте параграфа?
Что такое файловая структура диска
- Ствол – корень ФС.
- Ветви – каталоги разного уровня, один может располагаться в другом.
- Листья – файлы.
Графическое изображение иерархической файловой структуры выглядит следующим образом.


Система управления документами выполняет ряд функций:
- связывает обрабатываемые операционной системой и программами данные;
- занимается централизованным распределением пространства для хранения информации;
- позволяет приложениям и пользователю выполнять операции над файлами и накопителями;
- предотвращает несанкционированный доступ к документам.
Разновидности
- Физическая – её задачи: управление пространством накопителя, размещение и предоставление доступа к файлам, формирование их структуры на дисках.
- Логическая – это пространство имён или адресное пространство.
Поясним. Физически все файлы расположены на одном жёстком диске или в флеш-памяти. Для обращения к ним используется адресное пространство – указывается путь. Представим, что все документы находятся на одном диске C:\.
Для обращения к документам в одноуровневых ФС вводят название раздела, далее – его имя, например, C:\file.docx.
Логически эти файлы располагаются в различных каталогах (папках, директориях) – абстрактные структуры, логические контейнеры, применяемые для упорядочивания, структурирования и группировки документов.
Например: C:\документы\file.docx, C:\видео\сериалы\8сезон\серия5.mp4. После названия папки ставится разделитель – обратная косая черта, после имени документа – точка, затем – его расширение, обычно состоящее из трёх букв.
При описанной организации ФС документы имеют два имени:
- Короткое – название и расширение, указанное через точку.
- Длинное – начинается с метки логического раздела или физического накопителя, включает названия всех каталогов в иерархической последовательности – от наивысшего до самого низшего, и заканчивается коротким именем.

Описанная ФС ускоряет поиск нужных файлов, позволяет:
- Хранить на одном разделе множество документов с одинаковыми короткими названиями, если те расположены в разных папках – имеют различные адреса.
- Группировать документы по общим признакам.
- Держать на компьютере несколько копий одного документа.
Порядок подчинения или древовидная структура файлов формируется пользователем на всех разделах, кроме системного, где всё делают программы установки ОС и приложений. Человеку в иерархию каталогов на разделе C:\ вмешиваться не стоит.
Ныне практически каждая файловая система многоуровневая или древовидная – это рассмотренный выше метод организации хранения данных. Одноуровневая файловая структура – это устаревшая, практически не использующаяся ФС. Пример: когда в корне диска – съёмного накопителя – размещены десятки файлов без каталогов.

Особенности обращения к файлам
Для выполнения операций с файлом указывается его полное имя от дисковой метки до расширения. Бывают ситуации, когда для идентификации объекта достаточно использовать его краткое имя – название с расширением через точку. Для пользователя, работающего с ФС, один каталог всегда активный, например, открытый в Проводнике. Файловый обозреватель фиксирует, запоминает путь к текущей директории и использует его как относительное имя, автоматически добавляя его перед кратким.
Монтирование
Организовать хранение содержимого внешних накопителей (флешек, компакт-дисков) на одном устройстве можно путём размещения отдельной автономной файловой структуры на внутреннем носителе. Её принято называть образом – это отдельный файл, в котором хранится точная цифровая копия содержимого флешки, логического или физического раздела. Создав такую копию, её монтируют в виртуальный дисковод и работают как с физическим носителем в режиме чтения. Изменять содержимое образа привычным способом нельзя.

Диск D:\ – образ, точная цифровая копия флешки.
Есть варианты объединения файловых структур разных логических либо физических накопителей в одну. После монтирования разницы между корневой и смонтированной ФС нет.
Иерархическая база данных. Иерархическая модель данных
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.

Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
Еще записи о создании сайтов и их продвижении, базах данных, IT-технология и сетевых протоколах
Возможно, эти записи вам покажутся интересными
Выберете удобный для себя способ, чтобы оставить комментарий
This article has 6 comments
Привет! Спасибо, очень интересно! А не знаешь, пример иерархической базы данных это какая СУБД? И где можно скачать иерархическую СУБД?
Привет! Где скачать иерархическую СУБД или сетевую СУБД я не знаю, возможно есть где-нибудь на торрентах, возможно на оффициальных сайтах той или иной иерархической или сетевой СУБД. В качестве примера иерархической системы управления базами данных (пример иерархической СУБД, иерархической модели данных) можно привести СУБД от IBM — ISM (Information Managment System) примерно такой же вопрос был в публикации виды и типы баз данных.
Как ни странно, иерархические базы данных до сих пор используются, даже в повседневной жизни любого компьютерного юзвера, который даже об этом не подозревает. Мне, например, по работе частенько приходится работать с такими базами данных, к сожалению, именно по этому типу БД информации крайне мало сейчас, в основном, в довольно специализированной литературе и с использование через чур умных терминов.
Пожлуйста, не отправляйте в Google, я там уже искала и ничего не нашла! Как можно преобразовать данные из иерархической базы данных в представление сетевых баз данных? И наоборот: данные сетевой модели данных в иерархическую модель данных?
Для начала было бы неплохо узнать какая у вас иерархическая СУБД и какую используете сетевую СУБД, чтобы дать какой-то совет. Уверен, что уже готовые решения есть. В самом простом случае можно записывать данные в файл, которые берутся из иерархической базы данных, а затем из этого файла записывать данные в сетевую базу данных, конечно, с использованием какого-нибудь языка программирования.
Не все связи между элементами информации можно отразить с использованием линейных списков и таблиц. Приведем пример иерархии фирмы: во главе - директор, которому подчиняются главный инженер и главный бухгалтер, у каждого из них есть свои подчиненные. Схема управления этой фирмы - многоуровневая.

Несколько деревьев образуют лес.
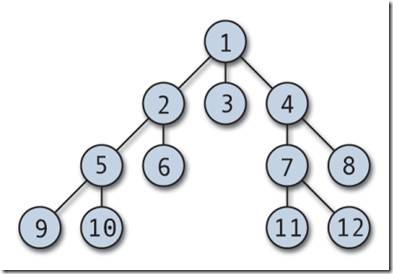
Дерево состоит из узлов и связей между ними (они называются дугами). Первый узел, расположенный на верхнем уровне (в него не входит ни одна стрелка‐дуга) – это корень дерева. Узлы, из которых не выходит ни одна дуга, называются листьями и они называются конечными узлами. Все остальные узлы, кроме корня и листьев – это промежуточные узлы.

Готовые работы на аналогичную тему
В дереве на рисунке справа родитель узла $E$ – это узел $B$, а предки узла $E$ – это узлы $A$ и $B$, для которых узел $E$ – потомок. Потомками узла $A$ (корня) являются все остальные узлы.
Типичными примерами иерархии могут быть различные классификации (растений, животных, минералов, химических соединений). Пример деления отряда Хищные приведен на рисунке $3$.

Рисунок 3. Отряд Хищные
В текстах иерархию часто оформляют в виде многоуровневого списка. Например, оглавление книги о хищниках может выглядеть так:


Рисунок 5. Иерархия папок на компьютере
Алгоритм вычисления алгебрайческого выражения $(a+3)\cdot 5-2\cdot b$ может быть представлен в виде дерева:

Рисунок 6. Дерево алгоритма вычисления выражения $(a+3)\cdot 5-2\cdot b$
Главное,что скобки здесь не обязательны; если их убрать, то выражение все равно может быть однозначно вычислено:
Такая запись называется префиксной (операция записывается перед данными), просматривается с конца. Логика записи следующая: как только встретится знак операции, то эта операция выполняется с двумя значениями, записанными справа. В рассмотренном выражении сначала выполняется умножение:
и еще одно умножение
и, наконец, вычитание: $(a+3)\cdot 5-(2\cdot b).$
Для вычисления такого выражения скобки не нужны, и это очень удобно для автоматических расчетов. Когда программа на языке программирования высокого уровня переводится в машинные коды, все выражения записываются в бесскобочной постфиксной форме и именно так и вычисляются.
Информация играет главенствующую роль в обществе и в процессе управления. Информационный поток управления охватывает: экономику, социальную сферу, производство, научные эксперименты, образование и др.
Можно выделить следующие виды иерархии информации: временная, пространственная, функциональная, ситуационная и информационная. Приведенное деление не может быть однозначным.
Временная иерархия. Информация делится по времени поступления, обработки или отправки.
Пространственная иерархия. Информация делится по пространственному признаку, а именно к какому узлу она относится.
Функциональная иерархия. В ее основе лежит функциональная зависимость (подчиненность) элементов системы.
Ситуационная иерархия. Информация делится в зависимости от ситуации, например все данные об каком-то одном объекте.
Читайте также: