
Современные способы кодирования информации в вычислительной технике доклад
Обновлено: 04.07.2024
Работа содержит 1 файл
Введение.docx
Аналогичным образом на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Способы кодирования информации.
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована. Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита. Кодирование символьной (текстовой) информации. Основная операция, производимая над отдельными символами текста - сравнение символов. При сравнении символов наиболее важными аспектами являются уникальность кода для каждого символа и длина этого кода, а сам выбор принципа кодирования практически не имеет значения. Для кодирования текстов используются различные таблицы перекодировки. Важно, чтобы при кодировании и декодировании одного и того же текста использовалась одна и та же таблица. Таблица перекодировки - таблица, содержащая упорядоченный некоторым образом перечень кодируемых символов, в соответствии с которой происходит преобразование символа в его двоичный код и обратно. Наиболее популярные таблицы перекодировки: ДКОИ-8, ASCII, CP1251, Unicode.Исторически сложилось, что в качестве длины кода для кодирования символов было выбрано 8 бит или 1 байт. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти. Различных комбинаций из 0 и 1 при длине кода 8 бит может быть 28 = 256, поэтому с помощью одной таблицы перекодировки можно закодировать не более 256 символов. При длине кода в 2 байта (16 бит) можно закодировать 65536 символов.
Кодирование числовой информации.
Сходство в кодировании числовой и текстовой информации состоит в следующем: чтобы можно было сравнивать данные этого типа, у разных чисел (как и у разных символов) должен быть различный код. Основное отличие числовых данных от символьных заключается в том, что над числами кроме операции сравнения производятся разнообразные математические операции: сложение, умножение, извлечение корня, вычисление логарифма и пр. Правила выполнения этих операций в математике подробно разработаны для чисел, представленных в позиционной системе счисления. Основной системой счисления для представления чисел в компьютере является двоичная позиционная система счисления.
Кодирование текстовой информации
В настоящее время, большая часть пользователей, при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др. Подсчитаем, сколько всего символов и какое количество бит нам нужно.10 цифр, 12 знаков препинания, 15 знаков арифметических действий, буквы русского и латинского алфавита, ВСЕГО: 155 символов, что соответствует 8 бит информации.
Единицы измерения информации.
1 Кбайт = 1024 байтам
1 Мбайт = 1024 Кбайтам
1 Гбайт = 1024 Мбайтам
1 Тбайт = 1024 Гбайтам
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой.
Основным отображением кодирования символов является код ASCII - American Standard Code for Information Interchange- американский стандартный код обмена информацией, который представляет из себя таблицу 16 на 16, где символы закодированы в шестнадцатеричной системе счисления.
Кодирование графической информации.
Важным этапом кодирования графического изображения является разбиение его на дискретные элементы (дискретизация). Основными способами представления графики для ее хранения и обработки с помощью компьютера являются растровые и векторные изображения. Векторное изображение представляет собой графический объект, состоящий из элементарных геометрических фигур (чаще всего отрезков и дуг). Положение этих элементарных отрезков определяется координатами точек и величиной радиуса. Для каждой линии указывается двоичные коды типа линии (сплошная, пунктирная, штрихпунктирная), толщины и цвета. Растровое изображение представляет собой совокупность точек (пикселей), полученных в результате дискретизации изображения в соответствии с матричным принципом. Матричный принцип кодирования графических изображений заключается в том, что изображение разбивается на заданное количество строк и столбцов. Затем каждый элемент полученной сетки кодируется по выбранному правилу.
Pixel (picture element - элемент рисунка) - минимальная единица изображения, цвет и яркость которой можно задать независимо от остального изображения. В соответствии с матричным принципом строятся изображения, выводимые на принтер, отображаемые на экране дисплея, получаемые с помощью сканера. Качество изображения будет тем выше, чем "плотнее" расположены пиксели, то есть чем больше разрешающая способность устройства, и чем точнее закодирован цвет каждого из них.
Для черно-белого изображения код цвета каждого пикселя задается одним битом. Если рисунок цветной, то для каждой точки задается двоичный код ее цвета. Поскольку и цвета кодируются в двоичном коде, то если, например, вы хотите использовать 16-цветный рисунок, то для кодирования каждого пикселя вам потребуется 4 бита (16=24), а если есть возможность использовать 16 бит (2 байта) для кодирования цвета одного пикселя, то вы можете передать тогда 216 = 65536 различных цветов.
Использование трех байтов (24 битов) для кодирования цвета одной точки позволяет отразить 16777216 (или около 17 миллионов) различных оттенков цвета - так называемый режим “истинного цвета” (True Color). Заметим, что это используемые в настоящее время, но далеко не предельные возможности современных компьютеров.
Кодирование звуковой информации.
Из курса физики вам известно, что звук - это колебания воздуха. По своей природе звук является непрерывным сигналом. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки аналоговый сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел, а для этого его необходимо дискретизировать и оцифровать.
Кодирование информации. В процессе преобразования информации из одной формы представления (знаковой системы) в другую осуществляется кодирование. Средством кодирования служит таблица соответствия, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем.
В процессе обмена информацией часто приходится производить операции кодирования и декодирования информации. При вводе знака алфавита в компьютер путем нажатия соответствующей клавиши на клавиатуре выполняется его кодирование, т. е. преобразование в компьютерный код. При выводе знака на экран монитора или принтер происходит обратный процесс — декодирование, когда из компьютерного кода знак преобразуется в графическое изображение.
Кодирование изображений и звука. Информация, в том числе графическая и звуковая, может быть представлена в аналоговой или дискретной форме. При аналоговом представлении физическая величина принимает бесконечное множество значений, причем ее значения изменяются непрерывно. При дискретном представлении физическая величина принимает конечное множество значений, причем ее величина изменяется скачкообразно.

ГОСТ
Современные способы кодирования информации в вычислительной технике — это методы, позволяющие преобразовать информационные данные одного типа в данные другого типа.
Введение
Современное компьютерное оборудование способно перерабатывать различные виды информации, такие как, текст, графика, звук и изображение в видео формате. Данные виды представляются в компьютере в бинарной системе кодирования, то есть при помощи алфавита, имеющего всего два символа, а именно нуль и единица. Это обстоятельство объясняется тем, что представление данных в формате набора электронных импульсных сигналов является очень удобным. Причём отсутствие импульса означает символ нуль, а наличие импульса означает символ единица. Такую систему кодирования называют бинарной или двоичной, а логический набор нулей и единиц является машинным языком. Любая цифра бинарного машинного кода обладает количеством информационных данных, которое равняется одному биту.
Кодирование текстовой информации
Сегодня большинство компьютерных пользователей работает с текстовой информацией, состоящей из символов, то есть буквенной, цифровой, знаковой и другой информации. Обычно для кодирования одного символа используется информационное количество, которое равно одному байту, то есть восьми битам. С помощью формулы, связывающей число допустимых событий К, и информационный объём I, можно определить количество символов, которое возможно закодировать, предполагая, что допустимые события это символы:
То есть, чтобы представить текстовую информацию, можно применить алфавит, размером 256 знаков.
Смысл кодировки состоит в том, что всем символам ставится в соответствие бинарный код от 00000000 до 11111111, или десятичный код, который ему соответствует, от нуля до 256.
На текущий момент для кодирования русского алфавита могут использоваться пять разных таблиц кодирования (КОИ - 8, СР1251, СР866, Мас, ISO).
Следует отметить, что если текст закодирован с помощью одной из таблиц, то в других системах кодирования он будет отображён неправильно. Но, как правило, перекодировкой текстовых документов занимается не сам пользователь, а специализированные программы, называемые конверторами, встраиваемые в программные приложения.
Готовые работы на аналогичную тему
С начала 1997-го года все версии Microsoft Windows&Office стали поддерживать новый формат кодирования Unicode, в котором на кодирование каждого символа отводится по два байта, что позволяет кодировать не 256 символов, а уже 65536 разных знаков. Для определения числового кода символа, можно использовать кодовую таблицу.
Кодирование графической информации
Графическая информация может быть представлена в двух форматах:
- Аналоговый формат
- Дискретный или числовой формат.
Живописная картина, в которой цвет меняется плавно и непрерывно, является примером аналогового формата изображения, а графика, распечатанная на струйном принтере и состоящая из набора точек разных цветов, является примером дискретного формата.
За счёт разделения графики, то есть её дискретизации, можно преобразовать графическую информацию из аналогового формата в дискретный. При этом выполняется кодировка, то есть назначение всем компонентам конкретной величины в кодовом формате. При кодировке изображения выполняется его дискретизация в пространстве. Аналогом этого процесса является формирование изображения из большого числа мелких цветных элементов, то есть мозаичный метод. Всё графическое изображение подразделяется на набор отдельных точек, где каждой точке присваивается код её цветовой окраски. Следует заметить, что качество кодировки зависит от следующих характеристик:
- Размер точек, на которые разбивается изображение.
- Число применяемых градаций цвета.
Чем более маленький используется размер точки, тем точнее будет передача изображения, то есть повышается качество кодировки. А также, чем больше применяется цветовых оттенков, то есть разных цветов отдельной точки, тем более информативной является каждая точка, что также повышает качество кодировки.
Формирование и сохранение информационных объектов графики может быть выполнено в следующих форматах:
- Векторный формат.
- Фрактальный или растровый формат.
Отдельно стоит трёхмерная или 3D графика, где соединяются оба метода реализации графики. Она занимается изучением методик и способов формирования объёмных моделей объектов в виртуальных режимах отображения.
Для каждого типа формирования графических изображений применяются свои методы кодировки графической информации.
Растровый формат изображения предполагает его разбиение на набор точек. Качество формирования рисунка напрямую связано с количеством точек и их габаритами. После окончания разделения рисунка на точки, начинается кодирование цвета всех точек в направлении с левого верхнего угла построчно слева направо. Каждая точка из набора разбиения изображения называется пикселем. Занимаемый в памяти объём растрового изображения вычисляется путём умножения числа пикселей на объём информации, связанный с одной точкой, который в свою очередь имеет зависимость от цветопередачи. Качество графического изображения зависит также от разрешающей способности монитора. Чем эта способность выше, то есть, чем больше число строчек в растре и точек в строке, тем более качественным будет изображение.
Векторным изображением является графический объект, который состоит из маленьких элементарных отрезков прямых и различных дуг. Основным компонентом изображения считается линия. Как и все объекты, она имеет определённые свойства, такие как форма (прямая, кривая), толщина, цвет, начертание (пунктир, сплошная линия). Если линия замкнута, то она имеет свойство заполнения, то есть или определённым цветом, или другими объектами. Все другие объекты векторной графики формируются из линейного набора. Информационные данные, которые содержат векторное изображение, подвергаются кодированию, аналогично обычным символам.
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
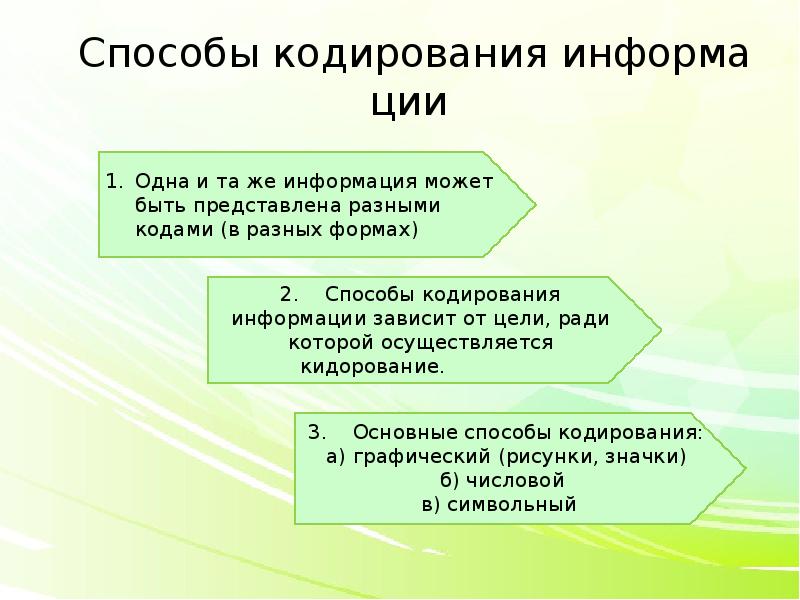
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
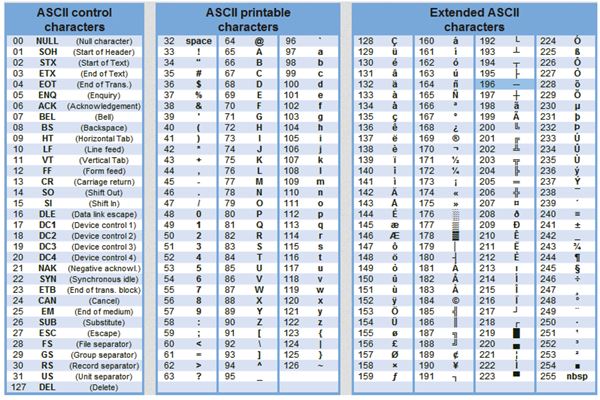
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.
Вы можете изучить и скачать доклад-презентацию на тему Современные способы кодирования информации в вычислительной технике. Презентация на заданную тему содержит 10 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас - поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!









Цели кодирования Повышение эффективности передачи данных, за счет достижения максимальной скорост и передачи данных. Повышение помехоустойчив ости при передаче данных.В соответствии с этими целями теория кодирования развивается в двух основных направлениях: 1. Теория экономичного (эффективного, оптимального) кодирования занимается поиском кодов, позволяющих в каналах без помех повысить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи данных с пропускной способностью канала связи. 2. Теория помехоустойчивого кодирования занимается поиском кодов, повышающих достоверность передачи информации в каналах с помехами. 3. Способы представления кодов. 4.В зависимости от применяемых методов кодирования, используют различные математические модели кодов, при этом наиболее часто применяется предст авление кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д.
Кодирование графической информации Кодирование графической информации основано на том, что изображение состоит из мельчайших точек, образующих характерный узор, называемый растром. Каждая точка имеет свои линейные координаты и свойства (яркость), следовательно, их можно выразить с помощью целых чисел – растровое кодирование позволяет использовать двоичный код для представления графической информации. Черно-белые иллюстрации представляются в компьютере в виде комбинаций точек с 256 градациями серого цвета – для кодирования яркости любой точки достаточно восьмиразрядного двоичного числа.
Кодирование текстовой информации Для кодирования текстовых данных используются специально разработанные таблицы кодировки, основанные на сопоставлении каждого символа алфавита с определенным целым числом. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы.
Кодирование звуковой информации Приемы и методы кодирования звуковой информации пришли в вычислительную технику наиболее поздно и до сих пор далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, хотя можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармоничных сигналов разной частоты, каждый из которых представляет правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП). Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармоничных сигналов разной частоты, каждый из которых представляет правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП).
Кодирование и декодирование Процесс представления информации в определенной стандартной форме и обратный процесс восстановления информации по ее такому представлению. В математич. литературе кодированием наз. отображение произвольного множества Ав множество конечных последовательностей (слов) в нек-ром алфавите В, а декодированием - обратное отображение.

Код - это комплект условных обозначений (либо сигналов) с целью записи (либо передачи) предварительно определенных конкретных понятий.
Как правило любой образ при кодировании представляется отдельным символом.
Символ - это компонент конечного множества непохожих друг на друга компонентов.
Пк способен подвергать обработке лишь данные, представленные в числовой форме. Вся иная информация (к примеру, звуки, изображения и т. д.) для обработки в пк должна быть преобразована в числовую форму. К примеру, для того чтобы перевести в числовую форму музыкальный звук, необходимо через незначительные интервалы времени определять интенсивность звука на определенных частотах, представляя итоги каждого измерения в числовой форме. С помощью программ для пк возможно осуществить преобразования полученной данных, к примеру "наложить" друг на друга звуки с разных источников.
Подобным способом в пк возможно подвергать обработке текстовую информацию. При вводе в пк каждая буква кодируется конкретным числом, а при выводе на внешние устройства с целью восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как мы знаем все без исключения числа в пк представляются с помощью нулей и единиц. Другими словами, пк как правило функционируют в двоичной системе счисления, так как при этом устройства для их обработки получаются наиболее элементарными. Ввод чисел в пк, а также вывод их с целью чтения человеком способен реализоваться в обычной десятичной форме, а все без исключения требуемые преобразования осуществляют программы, действующие в пк.
Двоичный код – это метод представления данных с помощью 2-ух знаков - $0$ также $1$.
Длина кода – число знаков, применяемых для представления кодируемой информации.
Бит - это одна двоичная цифра $0$ либо $1$. Одним битом возможно закодировать 2 значения: $1$ либо $0$. Двумя битами возможно закодировать 4 значения: $00$, $01$, $10$, $11$. Тремя битами кодируются $8$ различных значений. Добавление 1-го бита удваивает число значений, которое возможно закодировать.
Виды кодирования информации
Различают кодирование информации следующих видов:
кодирование текстовой информации;
кодирование графической информации;
кодирование числовой информации;
кодирование звуковой информации;
Кодирование текстовой информации.
Каждый текст состоит из последовательности знаков. Знаками могут являться буквы, цифры, знаки препинания, знаки математических операций, круглые и квадратные скобки и т.д.
Текстовая информация, равно как также каждая иная, находится в памяти пк в двоичном виде. Для этого любому устанавливается в соответствии некоторое неотрицательное число, именуемое кодом знака, и это число вносится в память ЭВМ в двоичном виде. Конкретное соотношение между знаками и их кодами именуется системой кодировки. В пк как правило применяется система кодировки ASCII (American Standard Code for Informational Interchange – Американский стандартный код для информационного обмена).
Создатели программного обеспечения сформировали личные $8$-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ знаков. Чтобы не было путаницы, первые $128$ знаков в таких кодировках, как правило, отвечают стандарту ASCII. Остальные $128$ - реализуют региональные языковые характерные черты.
Восьмибитными кодировками, популярными в нашей стране, считаются KOI8, UTF8, Windows-1251 и некоторые прочие.
Больше всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные методы кодирования текстовой информации
Имеется ряд ключевых методов кодирования текстовых данных:
графический, в котором текстовая информация кодируется путем применения специальных рисунков либо символов;
символьный, в котором тексты кодируются с применением знаков того же алфавита, на котором написан исходник;
числовой, в котором текстовая информация кодируется с помощью чисел.
Процедура чтения текста представляет собой процесс, обратный его написанию, в результате которого рукописный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
Стенография
Стенография — это один из методов кодирования текстовой информации с помощью специальных символов. Она представляет собой быстрый метод записи устной речи. Навыками стенографии могут обладать далеко не все, а только немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст одновременно с речью выступающего лица, что, на наш взгляд, достаточно трудно. Но для них это не проблема, так как в стенограмме целое слово либо совокупность букв могут обозначаться одним символом. Скорость стенографического письма превышает скорость обыкновенного в $4-7$ раз. Расшифровать стенограмму способен только сам стенографист.
Стенография дает возможность не только осуществлять синхронную запись устной речи, но и рационализировать технику письма.
Криптография
Шифрование представляет собой процедура превращения открытого текста в зашифрованный, а дешифрование — процедура противоположного преобразования, при котором восстанавливается первоначальный текст.
Шифрование — это тоже кодирование, но с засекреченным способом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Числовое кодирование текстовой информации
В любом национальном языке существует свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих собственный порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно данный код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Кроме кодов самих символов в памяти пк находится также сведения о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти пк.
Используя соответствия букв алфавита с их числовыми кодами, возможно сформировать специальные таблицы кодирования. Иначе можно отметить, что символы конкретного алфавита имеют свои числовые коды в соответствии с конкретной таблицей кодирования.
Кодирование цвета
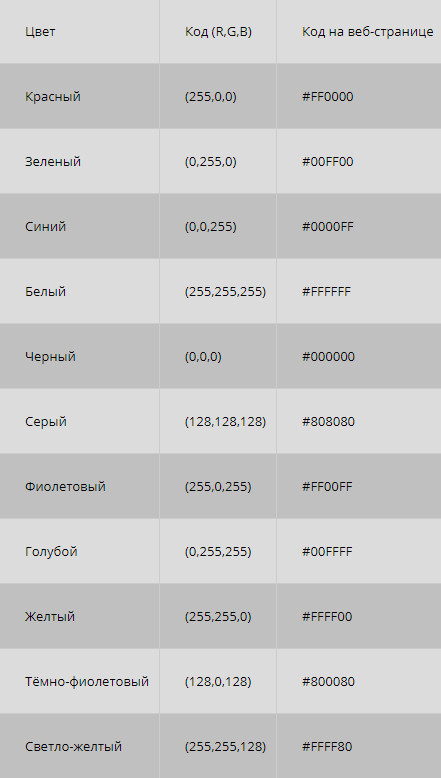
Чтобы сохранить в двоичном коде фотографию, ее сперва условно делят на множество небольших цветных точек, именуемых пикселями. После разбивки на точки цвет каждого пикселя кодируется в бинарный код и записывается на запоминающем устройстве.
Но качество кодирования фото в бинарный код зависит не только от количества пикселей, но также и от их цветового многообразия. Алгоритмов записи цвета в двоичном коде имеется несколько. Наиболее популярным из них считается RGB. Эта аббревиатура – первые буквы названий 3-х ключевых цветов: красного – англ.Red, зеленого – англ. Green, синего – англ. Blue. Перемешивая эти 3 тона в разных пропорциях, можно получить любой иной цвет либо оттенок.
На этом и построен алгоритм RGB. Каждый пиксель записывается в двоичном коде путем указания количества красного, зеленого и синего цвета, участвующего в его создании. Чем больше битов выделяется для кодирования пикселя, тем больше вариантов смешивания этих 3-х каналов можно использовать и тем значительнее будет цветовая насыщенность изображения.
Цветовое разнообразие пикселей, из которых состоит изображение, именуется глубиной цвета
Кодирование графической информации
Считается, что глаз человека может отличать приблизительно $16$ миллионов оттенков цвета. Для формального описания цвета создали ряд цветовых моделей и соответствующих им методов кодирования.
Цветовая модель RGB
Название этой модели происходит от названий 3-х базовых цветов, применяемых в модели — Red, Green, Blue, а конкретнее их первых букв. Данная цветовая модель представляет метод получения цвета на экране монитора либо тв, т.е. устройства, содержащего электронно-лучевую трубку. Модель аддитивная (цвет получается при сложении точек 3-х базовых цветов, каждая своей яркости). Причем яркость любого базового цвета может принимать значения от $0$ до $255$, таким образом, модель дает возможность кодировать $2563$ либо $16,7$ млн. цветов. Эти тройки базовых цветов находятся весьма близко друг к другу, так, когда мы посмотрим на эти триады из светящихся точек, то любая тройка объединяется для нас в большую точку определенного цвета. Чем больше яркость цветной точки, тем большее количество данного цвета добавится к результирующей точке
Устройства ввода графических данных такие, как сканер, цифровая камера и пр. функционируют в данной модели. RGB-кодирование лучше всего может помочь описать цвет, излучаемый определенным устройством, к примеру, монитором. Если же мы посмотрим на изображение, отпечатанное на бумаге, ситуация абсолютно другая. Мы улавливаем не прямые лучи источника, которые попадают нам в глаза, а лучи, отраженные с поверхности. Белый свет, испускаемый некоторым источником и включающий волны всего видимого диапазона, поступает на бумагу с нанесенной на нее краской. Краска впитывает долю лучей, а остальные воспринимают наши глаза, это и есть тот цвет, что мы видим.
Описанная выше техника формирования изображений из мелких точек считается более популярной и именуется растровой. Однако помимо растровой графики, в пк применяется еще и векторная графика.
Векторные изображения формируются только при поддержке пк и создаются не из пикселей, а из графических примитивов.
Кодирование числовой информации
При кодировании чисел учитывается цель, с которой цифра была введена в систему. Любые сведения, кодируемые в двоичной системе, шифруются с помощью единиц и нолей. Данные символы еще именуют битами. Этот способ кодировки считается более распространенным, так как его проще организовать в технологическом плане: наличие сигнала – $1$, отсутствие – $0$. У двоичного шифрования имеется только единственный минус – длина комбинаций из символов. С технической точки зрения легче действовать с множеством обычных, однотипных компонентов, нежели с небольшим количеством более сложных.
Целые числа кодируются переводом чисел с одной системы счисления в иную. Для кодирования реальных чисел применяют $80$-разрядное кодирование.
Список использованных источников
Простейшие методы шифрования текста/ Д.М. Златопольский. – М.: Чистые пруды, 2007 – 32 с.
Информатика. Задачник-практикум в 2 т. / Под ред. И. Г. Семакина, Е. К. Хеннера: Том 1. – М.: Лаборатория Базовых Знаний, 2000. – 304 с.: ил.
Читайте также: