
Графовые базы данных доклад
Обновлено: 02.07.2024
DATABASE / DATA STRUCTURE / GRAPH DATA MODEL / SQL / NOSQL / INDEXING / DATA ANALYSIS / DATA SCHEME / GRAPH REPRESENTATION / БАЗА ДАННЫХ / СТРУКТУРА ДАННЫХ / ГРАФ / МОДЕЛЬ ДАННЫХ / ИНДЕКСАЦИЯ / АНАЛИЗ ДАННЫХ / СХЕМА ДАННЫХ / ПРЕДСТАВЛЕНИЕ ГРАФОВ
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Засядко Г.Е., Карпов А.В.
В статье рассматриваются проблемы разработки графовых баз данных в условиях быстро растущего объема генерируемых и обрабатываемых данных. Целью статьи является анализ особенностей графовых моделей данных , демонстрация их преимуществ перед остальными, а так же постановка задачи о разработке нового способа представления графов в памяти компьютера.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Засядко Г.Е., Карпов А.В.
Нахождение подобия между неструктурированными объектами данных на основе метода сингулярного разложения спектра графа
Сравнительный анализ использования реляционных и графовых баз данных в разработке цифровых образовательных систем
Абстракции и базовые операции специализированного языка описания алгоритмов решения задач структурного анализа и синтеза
Применение теории графов в интеллектуальной методике анализа социальных медиа для мониторинга популярности кандидатов в период предвыборной кампании
Problems in the development of graph databases
The article discusses the development of graph databases in the rapidly growing volume of generated and processed data. The purpose of this paper is to analyze graph data models, demonstrate their advantages over the others, as well as the formulation of the problem of the development of a new method of representing graphs in computer memory.
Проблемы разработки графовых баз данных
Г.Е. Засядко, А.В. Карпов Московский политехнический университет
Аннотация: В статье рассматриваются проблемы разработки графовых баз данных в условиях быстро растущего объема генерируемых и обрабатываемых данных. Целью статьи является анализ особенностей графовых моделей данных, демонстрация их преимуществ перед остальными, а так же постановка задачи о разработке нового способа представления графов в памяти компьютера.
Ключевые слова: база данных, структура данных, граф, модель данных, SQL, NoSQL, индексация, анализ данных, схема данных, представление графов.
• резкий рост объемов обрабатываемых и хранимых данных [2];
• сложная и изменчивая структура данных;
• высокие требования к возможности распределенного хранения данных [3];
• нестандартные методы обработки данных.
Одним из самых перспективных направлений развития NoSQL -решений являются графовые базы данных [4]. Преимущества данных решений:
• разработка без задания схемы данных;
• широкие возможности по описанию сложных данных;
• описание данных с большим количеством связей.
Таким образом, при решении определенного круга задач, например, таких как всевозможные научные исследования, описание и отслеживание бизнес-логики и бизнес-процессов, существует острая потребность в некотором хранилище, которое позволяло бы при помощи него осуществлять полный цикл сбора, хранения, обработки данных в единой адаптирующейся модели. Это могло бы дать значительный выигрыш не только в скорости доступа к данным и их обработке, но и в удобстве использования, упрощении и ускорении процесса разработки и интеграции, снижении избыточности данных и количестве применяемых инструментов, а соответственно и затрат на поддержку информационной системы в будущем.
Подобные многоцелевые решения пригодятся в первую очередь в сфере анализа данных, динамически изменяющихся в процессе работы с ними. Это те случаи, где можно столкнуться с ограничениями и неудобствами условно стандартных и распространенных средств хранения, таких как реляционные базы данных или многие NoSQL-решения, предоставляющие в большинстве случаев лишь широкие возможности по хранению и быстрому доступу к данным на физическом уровне.
Проблема заключается не только в скорости доступа к хранимым данным, но так же и в правильной их логической организации с минимизацией стоимости каждой операции, совершаемой над данными.
Одним из центральных методов представления данных об окружающем мире в информационных системах, является метод, основанный на выделении из доступного объема информации метаданных и непосредственно самих данных [5].
Суть данного подхода состоит в некотором анализе всего множества описываемых объектов, выделении на его основе некоторого количества различных классов и описании реальных объектов при помощи них. Каждый выделенный класс обладает определенным набором свойств, присущих ему.
В реальном же мире зачастую невозможно сразу определить класс объекта, либо объекты, отнесенные к одному классу, будут обладать различным набором свойств. Нет ничего идеального и поддающегося строгому описанию. Такой подход применим лишь для определенного круга задач, и способен отражать суть только статически описываемых объектов.
Перспективной моделью данных, подходящей под вышеперечисленные критерии и лишенной необходимости предварительной классификации описываемых объектов, является графовая модель данных, достаточно гибкая для описания данных любого рода и сложности, в силу своих структурных особенностей. Графы одинаково хорошо подходят для представления как слабо, так и для сложно структурированных объектов и систем [6, 7].
Для наглядной оценки в таблице №1 приведены результаты проведенного сравнения на соответствие основным критериям наиболее распространенных моделей баз данных.
Таблица №1. Сравнительные критерии для различных моделей баз данных
Key-Value модель данных Реляционная модель данных (РМД) Объектно-ориентированная модель данных Документ-ориентированная модель RDF (Resource Description Framework) модель данных Мультиграфовая модель (Property graph)
Разработка без задания схемы данных - - - + + +
Удобство описания объектов - + + + - +
Удобство оперирования большими объемами данных + - - + + +
Удобство оперирования большим количеством связей - - - - + +
Наглядность представления данных и их связей - - - - + +
Возможность использования в децентрализованных системах + - + + + +
Помимо всего прочего графовую модель данных возможно представить как некоторый рекурсивный тип данных [8], что дает широкие возможности по применению различных способов его хранения и обработки. Здесь открывается целый спектр методов и алгоритмов для работы как с самой структурой графа и его логической организацией [9], так и непосредственно с данными, хранящимися в нем.
Области применения графовых моделей и методы работы с ними активно изучаются, ведется множество исследований, направленных на
унификацию языков запросов к базам данных, выбор канонических моделей и моделей ресурсов [10]. Такие исследования, безусловно, необходимы и играют одну из ключевых ролей.
Неотъемлемой частью успешной обработки данных на графовых моделях являются способы хранения и методы доступа к данным внутри используемых структур. Обычно способы хранения графов в памяти обладают высокой избыточностью и лишены возможности быстрого обхода и поиска, что приводит к сильному снижению скорости обработки. Таким образом, сейчас перед нами стоит задача по пересмотру и анализу существующих способов представления и хранения графовых моделей в памяти компьютера, выявление их особенностей, преимуществ и недостатков. Необходимо сконцентрировать силы на поиске нового, гибкого, легко адаптируемого под поставленные задачи способа представления графов. Искомая структура данных, должна будет способствовать оптимизации используемой памяти и логической организации, тем самым позволив снизить избыточность, ускорить процесс индексации и поиска хранимых данных, понизив алгоритмическую сложность обработки.
1. Tony Hey, Stewart Tansley, Kristin Tolle, The Fourth Paradigm: DataIntensive Scientific Discovery. Redmond: Microsoft Research, 2009. p. 4.
2. Jeffry Ullman, Database systems - the complete book. Pearson, 2009. p. 4.
3. Andrew S. Tanenbaum, Distributed Systems: Principles and Paradigms. Maarten van Steen, 2016. pp. 34 - 49.
4. Ian Robinson, Jim Webber, Graph Databases. O'Reilly, 2015. pp. 8 - 10.
5. Gavin Powell, Beginning Database Design. Wrox, 2006. p. 219.
8. Niklaus Wirth, Algorithms and Data Structures. Prentice-Hall, Inc, 1986. pp. 109-111.
9. Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein, Introduction to Algorithms, Third Edition. The MIT Press, 2010. pp 587 - 768.
1. Tony Hey, Stewart Tansley, Kristin Tolle, The Fourth Paradigm: DataIntensive Scientific Discovery. Redmond: Microsoft Research, 2009. p. 4.
2. Jeffry Ullman, Database systems - the complete book. Pearson, 2009. p. 4.
3. Andrew S. Tanenbaum, Distributed Systems: Principles and Paradigms. Maarten van Steen, 2016. pp. 34 - 49.
4. Ian Robinson, Jim Webber, Graph Databases. O'Reilly, 2015. pp. 8 - 10.
5. Gavin Powell, Beginning Database Design. Wrox, 2006. p. 219.
8. Niklaus Wirth, Algorithms and Data Structures. Prentice-Hall, Inc, 1986. pp 109-111.
9. Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein, Introduction to Algorithms, Third Edition. The MIT Press, 2010. pp. 587 - 768.


Система управления графовыми базами данных (далее графовые базы данных) поддерживает методы создания ( Create ), чтения ( Read ), изменения ( Update ) и удаления ( Delete ) (CRUD), основанные на графовой модели данных. Графовые базы данных, как правило, поддерживают систему транзакций реального времени (OLTP). Соответственно, они оптимизированы для выполнения транзакций и спроектированы с учетом транзакционной целостности и оперативности.
Имеются две особенности графовых баз данных, которые необходимо учитывать при рассмотрении применяемой ими технологии:
- принцип хранения. Некоторые графовые базы данных используют специализированные хранилища графов, предназначенные и оптимизированные для хранения и обработки именно графов. Но такую технологию хранения используют не все графовые базы данных. Некоторые сериализуют графы и размещают их в реляционной, объектно-ориентированной или какой-то другой базе данных или хранилище;
- порядок обработки. Некоторые определения требуют, чтобы графовая база данных использовала смежность без индесов (index-free adjacency), т. е. физическое соединение
Важно отметить, что принципы специализированного хранения графов и специализированной обработки графов не хороши и не плохи - они просто являются классическими инженерными компромиссами. Преимущество специализированного хранения графов - в том, что оно предусматривает стек, специально разработанный для повышения производительности и масштабируемости. Преимуществом неспециализированного хранения графов является использование зрелых неграфовых интерфейсов (например, MySQL), особенности которых хорошо знакомы разработчикам. Специализированная обработка графов (смежность без индексов) демонстрирует лучшую производительность обхода, но некоторые запросы приводят к использованию больших объемов памяти.
Взаимосвязи в графовой модели данных являются гражданами первого сорта. Здесь к ним относятся не так, как в других системах управления базами данных, где для отображения взаимосвязей применяются такие механизмы, как внешние ключи или внешние операции, например MapReduce. Собирая абстракции узлов и взаимосвязей в связанные структуры, графовая база данных позволяет строить модели любой сложности, лучше всего отражающие предметную область. Полученные модели проще и в то же время нагляднее, чем те, что создаются с помощью традиционных реляционных баз данных или других NOSQL-хранилищ.
На рис. 1 приведен графический обзор некоторых графовых баз данных из представленных сегодня на рынке, основанных на разных моделях хранения и обработки.
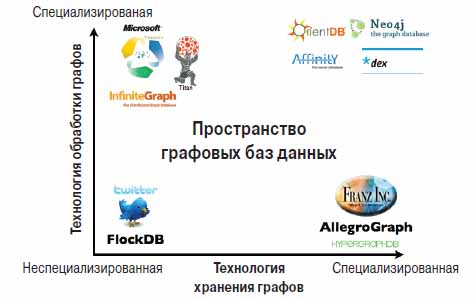
Рис. 1. Обзор графовых баз данных
Механизмы вычисления графов
Из-за своей направленности на глобальные запросы механизмы вычисления графов, как правило, оптимизированы для сканирования и пакетной обработки больших объемов информации, и в этом отношении они похожи на другие технологии пакетного анализа, такие как интеллектуальный анализ данных (data mining) или аналитическая обработка в реальном времени (OLAP), используемые в реляционном мире. Некоторые механизмы вычисления включают в себя и средства хранения графов, а другие (большинство) заботятся только об обработке данных, получаемых из внешнего источника, а затем возвращают результаты для сохранения в другом месте.
Рисунок 2 иллюстрирует типовую архитектуру развертывания механизмов вычисления графов. Она включает в себя систему записи (System of Record, SOR) базы данных со свойствами OLTP (например, MySQL, Oracle или Neo4j), которая обслуживает запросы и отвечает на запросы, поступающие от приложений (и в конечном счете от пользователей). Периодически задания на извлечение, преобразование и загрузку данных (Extract, Transform, Load, ETL) перемещают данные из системы записи базы данных в механизм вычисления графов для выполнения автономных запросов и анализа.
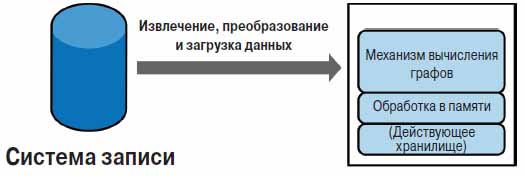
Рис. 2. Укрупненная схема типичной среды движков расчетов графов
Преимущества графовых баз данных
Несмотря на то что практически все можно представить в виде графа, мы живем в прагматичном мире бюджетов, проектов с жесткими графиками, корпоративных стандартов и коммерческих правил. Предоставляемый графовыми базами данных новый мощный метод моделирования данных сам по себе не является достаточным основанием для замены устоявшихся и понятных платформ обработки данных - от этого должна быть незамедлительная и весьма значительная практическая польза. Для графовых баз данных такой мотивацией может послужить применение ее в тех случаях и к таким моделям данных, когда при переходе на графовую модель будет достигнуто увеличение производительности на один и более порядков. Вместе с выигрышем в производительности графовые базы данных предоставляют чрезвычайно гибкую модель данных и способ развертывания, соответствующий современным способам развертывания программного обеспечения.
Производительность
Одной из веских причин выбора графовой базы данных является большой прирост производительности при работе со взаимосвязанными данными, по сравнению с реляционными базами данных и NOSQL-хранилищами. В отличие от реляционных баз данных, где учет взаимосвязей интенсивно ухудшает производительность запросов на больших наборах данных, производительность графовых баз данных остается неизменной с увеличением объема хранимых данных. Это связано с тем, что запросы локализуются в определенной части графа. В результате время выполнения каждого запроса зависит от размера части графа, которую требуется обойти для удовлетворения запроса, а не от общего размера графа.
Гибкость
Разработчикам и проектировщикам необходимо организовать взаимосвязи между данными, согласно требованиям области применения, структура данных должна соответствовать изменяющимся потребностям, а не навязываться заранее и оставаться неизменной. В графовых базах данных эта задача легко решается. Как мы увидим в главе 3, графовая модель данных отражает и охватывает потребности бизнеса таким образом, что может изменяться со скоростью изменения самого бизнеса.
Присущая графам возможность расширения означает, что можно добавлять новые виды взаимосвязей, новые узлы, новые метки и новые подграфы в существующую структуру, не нарушив при этом существующих запросов и функционала приложения. Это положительно влияет на производительность разработки и снижает риски для проекта. Благодаря гибкости графовой модели не требуется предварительно моделировать задачу в мельчайших подробностях, что очень неудобно из-за быстро меняющихся бизнес-требований. Способность графов к расширению также позволяет уменьшить количество миграций, что снижает нагрузку при обслуживании данных и уменьшает риск потери данных.
Оперативность
Модель данных должна не отставать от прочих составных частей приложения и использовать технологии, соответствующие современным итерационным методам развертывания программного обеспечения. Современные графовые базы данных оснащены всем необходимым для разработки и системного обслуживания. В частности, встроенная графовая модель данных, лишенная схем, в сочетании со встроенным программным интерфейсом (API) и языком запросов позволяет эффективно вести разработку приложений.
В то же время благодаря отсутствию схемы графовые базы данных не предполагают наличия ориентированных на схемы механизмов контроля данных, которые широко применяются в реляционном мире. Но в этом нет ничего страшного, здесь они заменены гораздо более удобными и действенными видами контроля. Как мы увидим в главе 4, контроль выполняется в программной форме, с помощью тестов для моделей данных и запросов, а также с помощью определения бизнесправил, основанных на графе. Сейчас такая методика уже не вызывает сомнений: разработка с помощью графовых баз данных полностью соответствует современным методикам гибкой и надежной разработки программного обеспечения, что позволяет разработке приложений с использованием графовых баз данных не отставать от бизнес-среды.
Итоги
В этой главе мы рассмотрели графовую модель со свойствами, представляющую собой простой, но удобный инструмент для работы со взаимосвязанными данными. Графовая модель со свойствами хорошо моделирует области ее применения, а графовые базы данных облегчают разработку приложений, которые реализуют графовые модели.
В следующем моем блоге мы сравним несколько различных технологий обработки взаимосвязанных данных, начнем с реляционных баз данных, затем перейдем к агрегированным NOSQL-хранилищам и закончим графовыми базами данных. Обсудив их, мы узнаем, почему графы и графовые базы данных являются лучшим средством для моделирования, хранения и выборки взаимосвязанных данных. Затем, в последующих главах, будут описаны проектирование и реализация решений, основывающихся на графовых базах данных.
Что такое информационные технологии? В первую очередь их можно подразделить на технологии обработки, технологии передачи и технологии хранения информации. Ниже речь пойдет о центральном понятии технологий хранения — базах данных.
Прообразы того, что сейчас называется базами данных, существовали и в докомпьютерную эпоху. Ими были библиотечные каталоги, телефонные и бухгалтерские книги и т. д. C появлением компьютеров все эти данные стали переносить в них, так появились первые компьютерные базы данных. Поначалу это были просто файлы, но со временем выяснилось, что с ростом объема данных, разнообразия и сложности задач становится необходимой специальная организация данных. Например, требуются индексы – специальные структуры, позволяющие в большой базе быстро находить нужные записи.
Базы данных в современном понимании появились в середине 60-х годов. В настоящее время их так или иначе используют практически все программные системы. Например, база данных системы управления предприятием может хранить сведения о следующих взаимосвязанных объектах:
Из приведенного примера понятно, насколько важны при хранении сведений об объектах связи между ними. Поэтому неудивительно, что первыми моделями данных (и, соответственно, базами данных) были следующие.
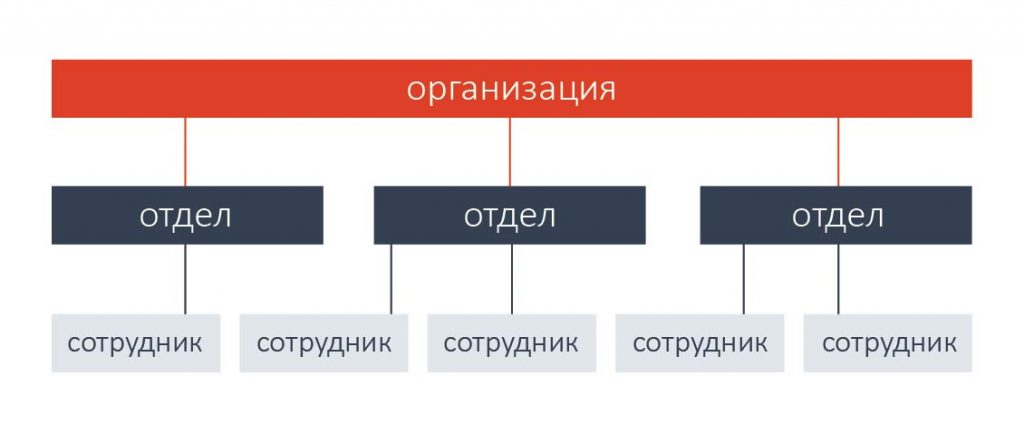
Иерархическая. Это наиболее естественная модель для отражения взаимосвязей в организациях и других иерархически организованных структурах.
Сетевая. Для ряда задач иерархическая модель слишком жестка, необходимо ее расширение. Например, если одна и та же деталь входит в несколько узлов, в иерархической модели данных это отражено быть не может.
База данных (БД) – это собственно данные в удобном для их хранения и обработки формате;
Система управления базами данных (СУБД) – это программа, которая умеет, с одной стороны, получать от пользователя или пользовательского приложения запросы на добавление, поиск и модификацию данных, с другой стороны, по запросам пользователя эти данные в базах искать, добавлять, извлекать, удалять, модифицировать.
Одна СУБД может управлять несколькими базами данных, и можно сказать, что у каждой СУБД свой формат баз данных.
Функциями СУБД являются также создание индексов, поддержка транзакций, обеспечение целостности данных, резервное копирование и восстановление, защита от сбоев и пр.
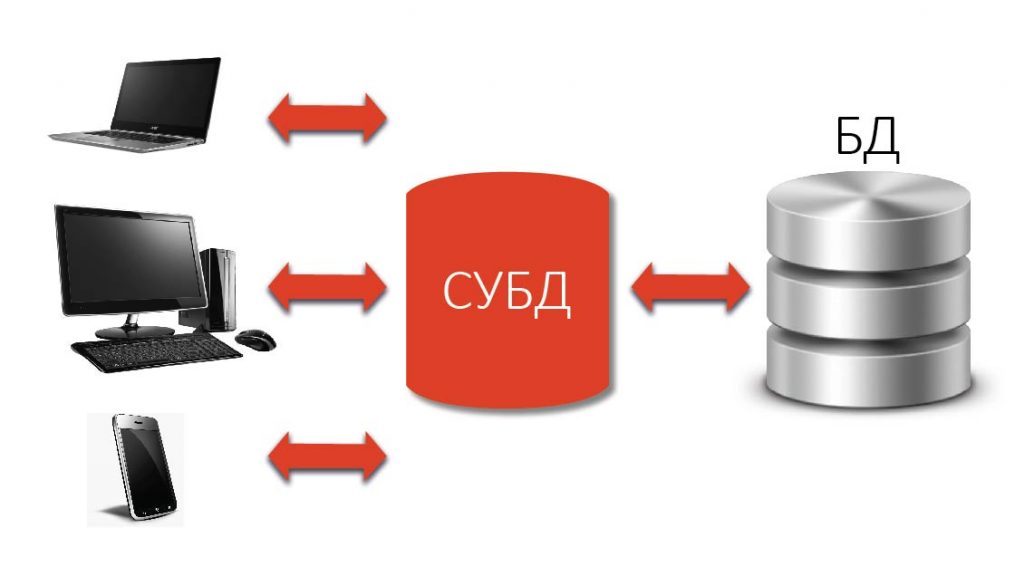
Как видно из рисунка, любая база данных управляется СУБД, доступна через СУБД, и только через СУБД. То есть, база данных и СУБД – это единый организм, одно без другого не существует.
Реляционная модель
В числе первых моделей данных, описанных выше, отсутствует самая, возможно, простая и базовая модель, возникшая даже раньше других, но долго не имевшая общепринятого названия. Иногда ее называли линейной, иногда табличной. Суть ее заключается в простом последовательном расположении сведений об объектах. Например, на рисунке ниже каждая строка представляет собой запись сведений об одном объекте, и эти записи расположены последовательно (линейно).
Такую модель можно рассматривать как вырожденную иерархическую или сетевую. Однако именно она впоследствии развилась в ставшую широко известной реляционную модель Кодда. В начале 70-х Эдгар Кодд [1] строго описал реляционную модель на основе разработанных им реляционной алгебры и реляционного исчисления.
Реляционная модель быстро завоевала популярность и стала использоваться повсеместно, отчасти в связи с тем, что в то время большая часть данных была слабо связанной и для большинства приложений было достаточно отдельных таблиц.
Однако иногда необходимо было связывать данные. В рамках реляционной модели это делалось довольно неудобным способом, и, что хуже, поиск по таким связям (операции соединения таблиц, JOIN), был очень медленным.
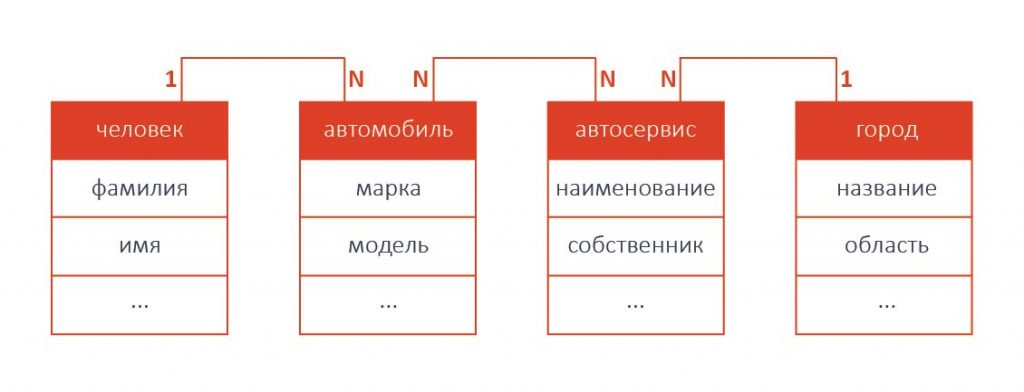
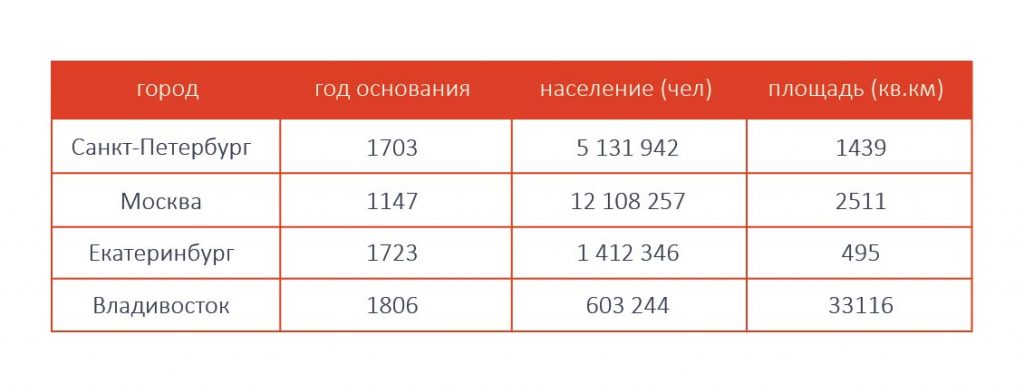
Производительность деградировала тем быстрее, чем больше соединяемых таблиц было задействовано в одном запросе. Например, если из базы данных, схема которой представлена на рисунке выше, требуется получить информацию о всех людях, имеющих автомобиль марки Toyota (одна операция JOIN), поиск будет достаточно быстрым. Однако если требуется получить информацию о всех людях, имеющих автомобили марки Toyota, ремонтировавшиеся в фирменных автосервисах, находящихся в определенном городе (четыре операции JOIN), скорость поиска будет намного ниже.
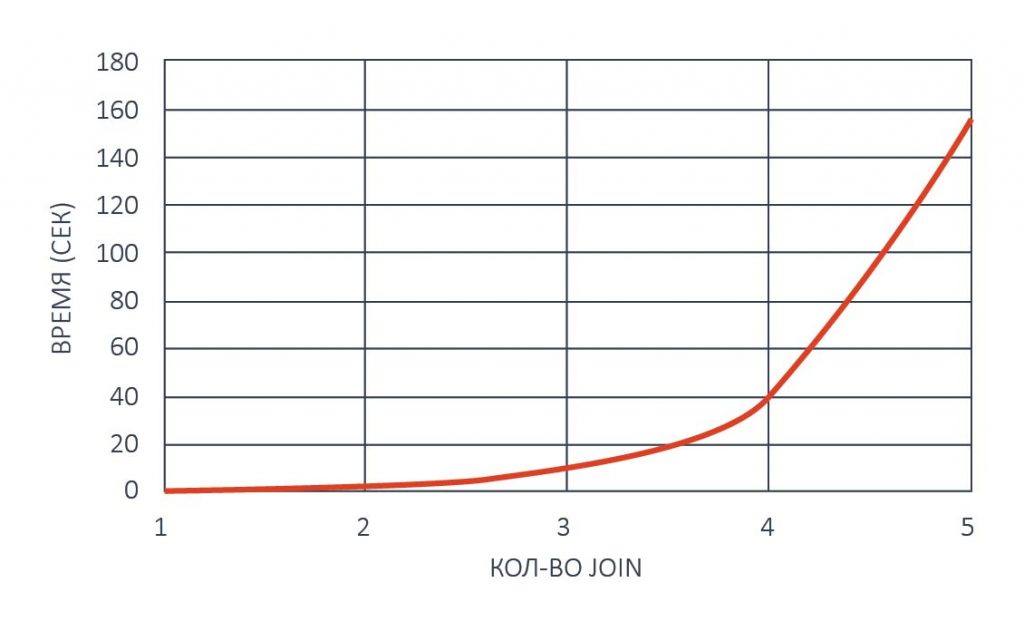
На рисунке выше видно, что рост времени поиска данных в реляционных базах данных в зависимости от количества операций JOIN может быть экспоненциальным.
Стандартизация реляционной модели, SQL
Большим достижением создателей реляционной модели явилась её стандартизация.
Были стандартизованы основные понятия и терминология, был разработан мощный язык запросов – Structured Query Language (SQL), на котором можно было выразить практически любое действие над базой данных. Поэтому реляционные СУБД часто называют SQL СУБД.
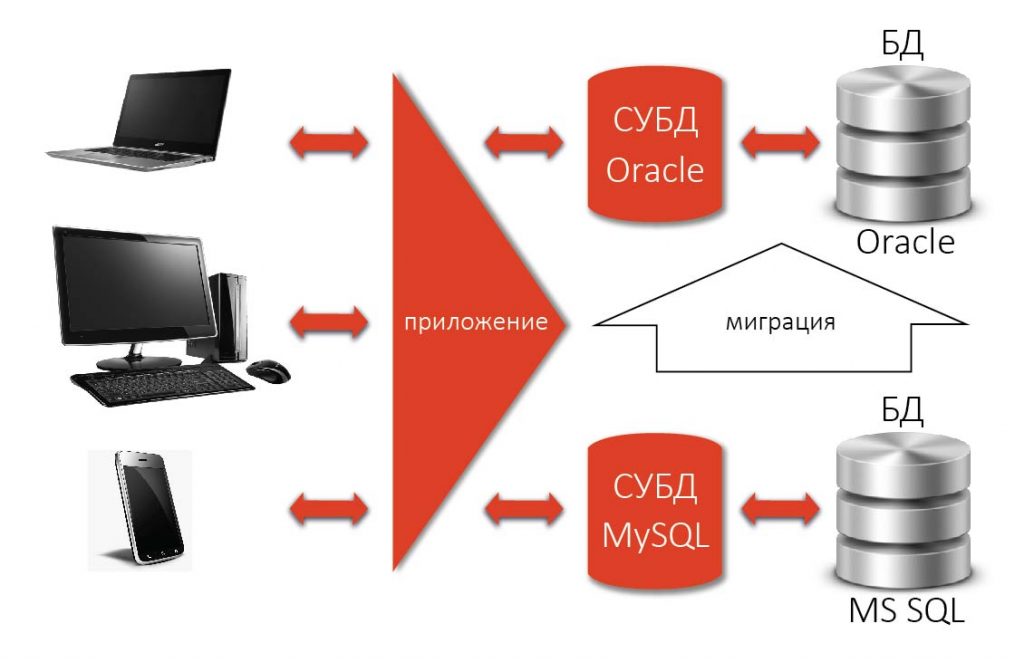
Стандартизация позволила в идеале безболезненно переходить (мигрировать) с одной реляционной СУБД на другую, не меняя разработанного приложения. На практике, конечно, такая миграция никогда не проходит гладко, но в целом это было большим шагом вперед по сравнению с практически полной несовместимостью существовавших тогда нереляционных СУБД.
По-видимому, именно эта стандартизованность явилась основным конкурентным преимущество реляционных СУБД. Для сравнения, объектным СУБД, развивавшимся в то же время, и обладавшим рядом архитектурных преимуществ, но так и оставшимся проприетарными в части, например, языков запросов, так и не удалось занять сколь-нибудь значительную долю рынка.
NoSQL, графовые базы данных
Реляционные базы данных доминируют и поныне, но к началу 2000-х появились тенденции, ставящие под сомнение дальнейшее их господство.
Развитие бизнеса в эпоху Internet привело не только к значительному увеличению объемов данных, но и существенному их усложнению. Можно сказать, что реляционные СУБД просто перестали справляться. Разочарование в реляционной модели привело к появлению альтернативных моделей, учитывающих новые реалии. Стали появляться и активно развиваться СУБД, основанные на модели ключ-значение, документные, колоночные и, наконец, графовые. Эти модели получили общее название NoSQL.
Среди всех NoSQL-моделей, по нашему мнению, наибольший интерес сегодня представляет графовая модель данных. Почему?
Во-первых, графовая модель сама по себе является наиболее естественным подходом к моделированию. Недаром сетевая модель данных, структурно близкая к графовой, являлась одной из первых моделей данных.
Во-вторых, наше время характеризуется ростом связности данных.
В-третьих, в начале XXI века Internet сообщество взяло курс на построение Semantic Web (Web 3.0) [2]. Напомним вкратце, что
Модели графовых СУБД. RDF, SPARQL
Существует две основных разновидности графовой модели данных: Property Graph и RDF-граф (RDF — Resource Description Framework).
Наиболее известной СУБД, работающей с моделью Property Graph, является Neo4j. В основном, СУБД, работающие с Property Graph, имеют проприетарные интерфейсы и несовместимы друг с другом.
Модель данных RDF еще раньше развивалась в недрах науки искусственного интеллекта (ИИ) как один из способов представления знаний. После 2001 года, когда в журнале Scientific American была опубликована статья [2] знаменитого Тима Бернерса Ли (автора идеи всемирной паутины – World Wide Web), в Internet сообществе стал лавинообразно нарастать интерес к графовым базам, в частности, RDF. В 2004 г. RDF принят как стандарт комитета W3C (World Wide Web Consortium).
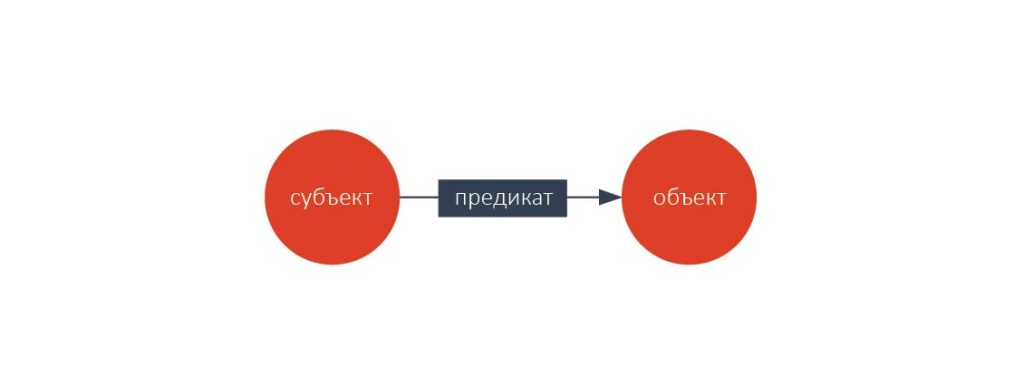
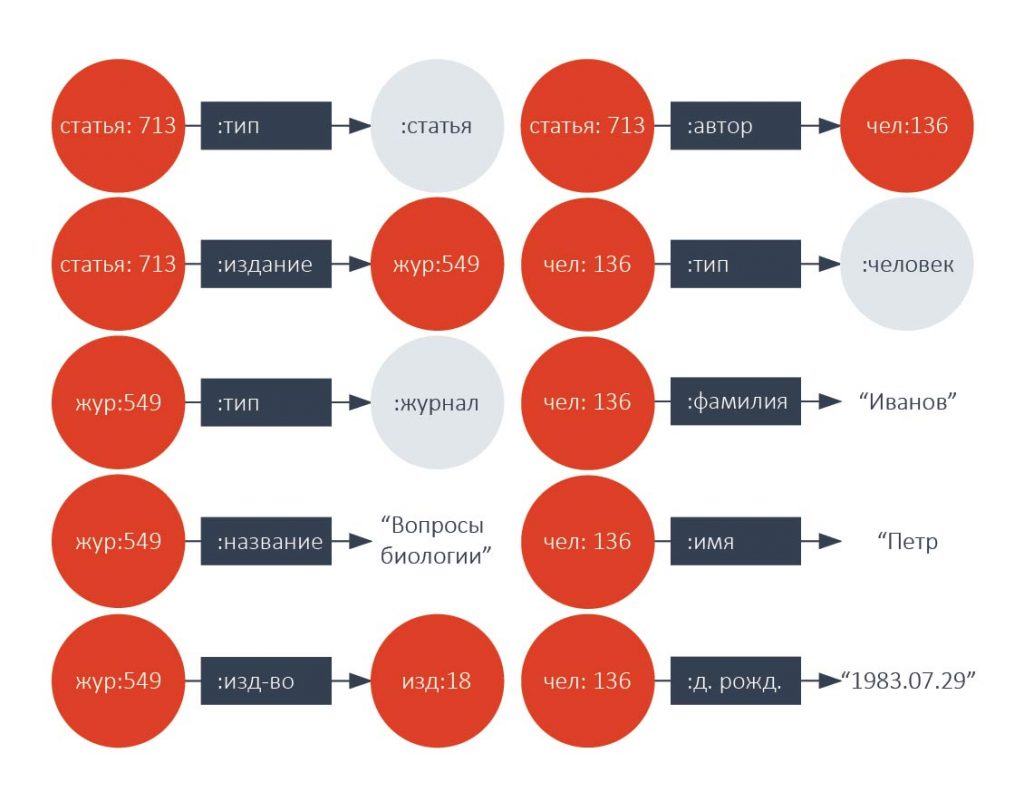
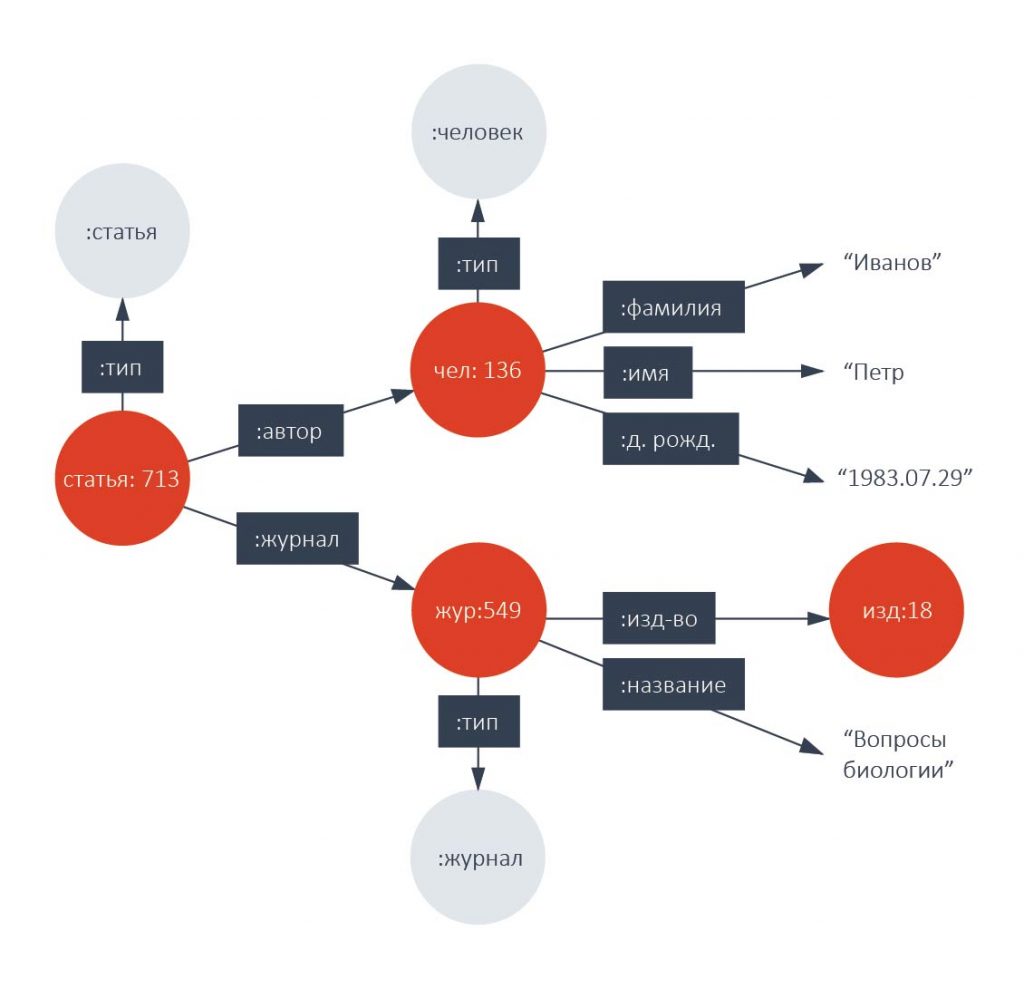
На графе, заданном таким образом, можно делать запросы с помощью специальных языков. Наиболее известный из них — язык, принятый в качестве стандарта W3C –SPARQL. Его синтаксис похож на SQL, язык SPARQL, как и SQL, имеет декларативную основу.
Что особенно важно, графовая RDF база данных гораздо легче проектируется, управляется и модифицируется, чем аналогичная реляционная база. Поиск сложных связей на этой модели также происходит с гораздо большей эффективностью, поскольку (при правильной архитектуре СУБД) все связи прямые, нет необходимости проводить операцию JOIN через внешние ключи.
Стандартизация RDF
Поскольку RDF вышел из ИИ, то он приспособлен для задач обработки знаний. Хотя, строго говоря, RDF – это информационная модель, она не достаточна для построения семантических систем. Зато модель RDF легкая и стройная, и пригодна для решения широкого круга задач, не только в рамках Semantic Web, но и в других прикладных областях. Для семантической обработки имеются стандартные расширения, совместимые с RDF, также принятые консорциумом W3C.
Благодаря усилиям консорциума W3C модель RDF удалось сделать гораздо более стандартизованной, чем это было достигнуто для реляционной модели.
Переход от SQL баз данных к RDF системам обещает такой же технологический скачок, как переход от самых первых СУБД к SQL.
Применения графовых СУБД
Можно выделить несколько направлений, в которых применение графовых СУБД наиболее эффективно.
Государственный сектор
Управление процессами, документооборот, аналитика, социологические исследования, и т.д. Клиентами могут быть федеральные и региональные министерства, исследовательские организации, и т.д.
Жизненный цикл предприятий
Интеграция и управление жизненным циклом предприятий в системах автоматизации предприятий. Применение графовых технологий дает возможность единообразно хранить и обрабатывать очень разнородную информацию, включая данные систем ERP, EAM, PLM, САПР и т.д. Клиенты – компании, переходящие на ISO 15926 и другие стандарты на основе RDF, например, Bentley, Siemens, OAK, OCK, Росатом, Роснефть, РАО ЕЭС и т.д.
Маркетинг, реклама, PR
Сбор и анализ разнородной информации из блогов, соц. сетей и т.д. для выявления источников информации, предпочтений пользователей; программы лояльности; SEO и т. д.
Оборона
АСУ вооруженными силами; системы распределения военной информации; системы планирования войсковых операций; системы анализа и поддержки принятия решений на ТВД; средства автоматизации процессов боевого информационного обеспечения и управления войсками; тренажерные системы; и т.д.
Безопасность
Анализ логов, электронной почты, интернет трафика; финансовый анализ; анализ информации о людях из разных источников, включая данные о работе, собственности, доходах; анализ информации о связях и интересах из социальных сетей; поиск связей по аффилированности и т.д. Возможные клиенты – службы безопасности банков и предприятий, холдингов, корпораций и т.д.
Бизнес-аналитика
Построение аналитических систем нового поколения; построение систем Semantic Data Warehouse — нового класса хранилищ, использующего взаимосвязи данных для повышения качества принятия решений. Клиенты – государственный сектор, банки, предприятия, корпорации, страховые компании и т.д.
Управление сетями и дата-центрами
Управление жизненным циклом вычислительных комплексов, дата-центров, компьютерных и телекоммуникационных сетей и т.д.; моделирование и оптимизация взаимодействия физического, сетевого и других. уровней. Возможные клиенты – дата-центры, Internet провайдеры, службы коммуникаций и кибербезопасности.
Социальные приложения, рекомендационные сервисы и коммерция
Построение и анализ социальных графов. Применение графовых подходов позволяет выявлять модели аналогичного поведения, групп влияния, неявных групп, и т.д. Возможные клиенты: Компании-разработчики Web-сервисов для более тонкого учета предпочтений клиентов; разработчики приложений для мобильных устройств, Интернет-торговли, форумов и социальных сетей.
Образование
Построение графа взаимосвязей между терминами, понятиями, программами обучения, задачами, тестами, знаниями учащегося и т.д. для построения адаптивных обучающих систем. Клиенты – учебные заведения, провайдеры систем дистанционного обучения.
Геосервисы, геоприложения
Построение взаимосвязей разнородных данных на карте, связанной с людьми, местами и событиями, компаниями, предприятиями и т.д.; решение задач логистики, маршрутизации и т.д. Возможные клиенты –Министерство обороны, МЧС, другие министерства, разработчики социальных приложений и т.д.
Проблемы графовых СУБД
Графовые СУБД в силу своей гибкости и универсальности завоевывает все большее место на рынке. Но широкому их распространению по-прежнему мешает проблема их сравнительно низкой производительности на простых запросах, а именно:
- С одной стороны, графовые базы деградируют гораздо медленнее, чем реляционные при увеличении кол-ва – связей.
- С другой стороны, они (имеющиеся на рынке реализации) изначально более медленные.
Таким образом, получается, что графовые СУБД проявляют свои преимущества только при большом количестве связей. Но для типовых современных приложений характерно кол-во связей (операций JOIN в терминах SQL баз) от 2 до 5. То есть, применение графовых СУБД в настоящее время ограничено только сильно связанными данными.
Решение — Графовая СУБД NitrosBase
Графовая СУБД NitrosBase RDF Storage целиком основана на технологии NitrosBase, которая создавалась и оттачивалась более 20 лет. Технологические новации NitrosBase занимают лидирующие позиции по производительности, что неоднократно было отмечено наградами на отраслевых выставках и конференциях.
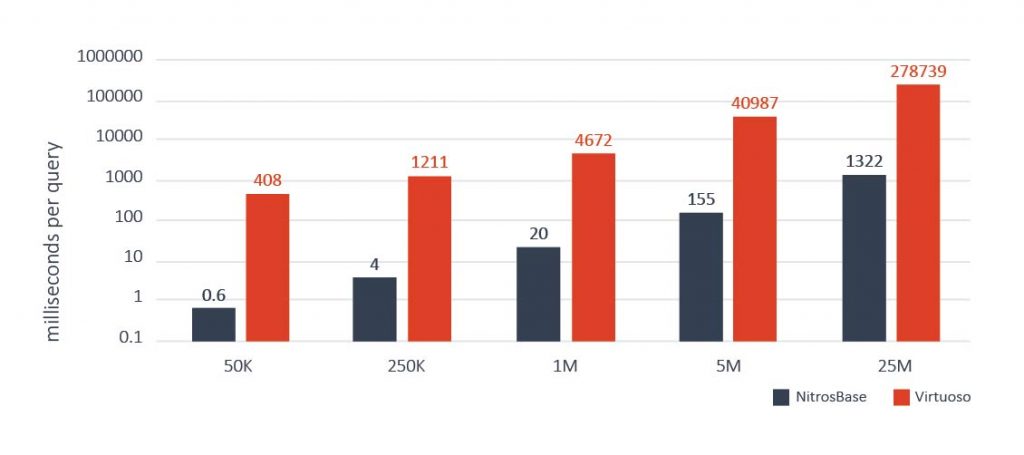
Проведенные нами сравнительные тесты широко известного набора SP2Bench показали значительное превосходство в производительности NitrosBase Storage над конкурентами. Например, на рисунке ниже показаны сравнительные результаты запроса 6 из набора SP2Bench. Запрос состоял в том, чтобы получить множество публикаций, авторы которых не публиковались ранее. Результаты показывают превосходство NitrosBase по сравнению с одной из наиболее производительных RDF СУБД более чем в 200 раз.
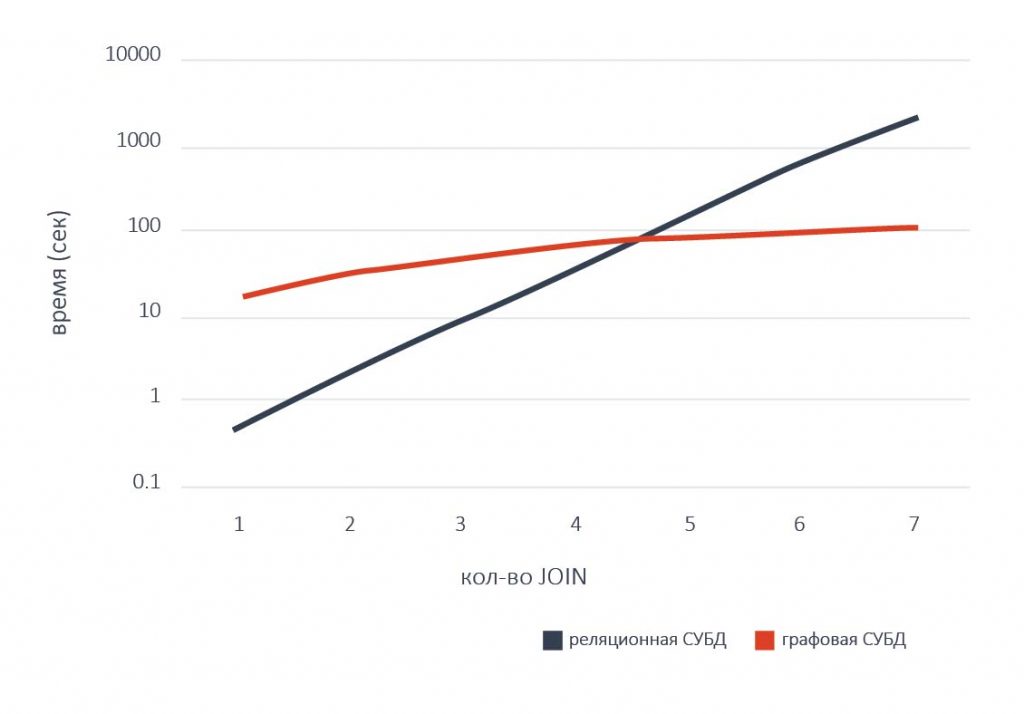
NitrosBase RDF Storage проявляет свои преимущества не только при большом количестве связей, она быстрее всех известных на рынке реляционных СУБД даже при небольшом количестве связей, характерном для типовых современных приложений.
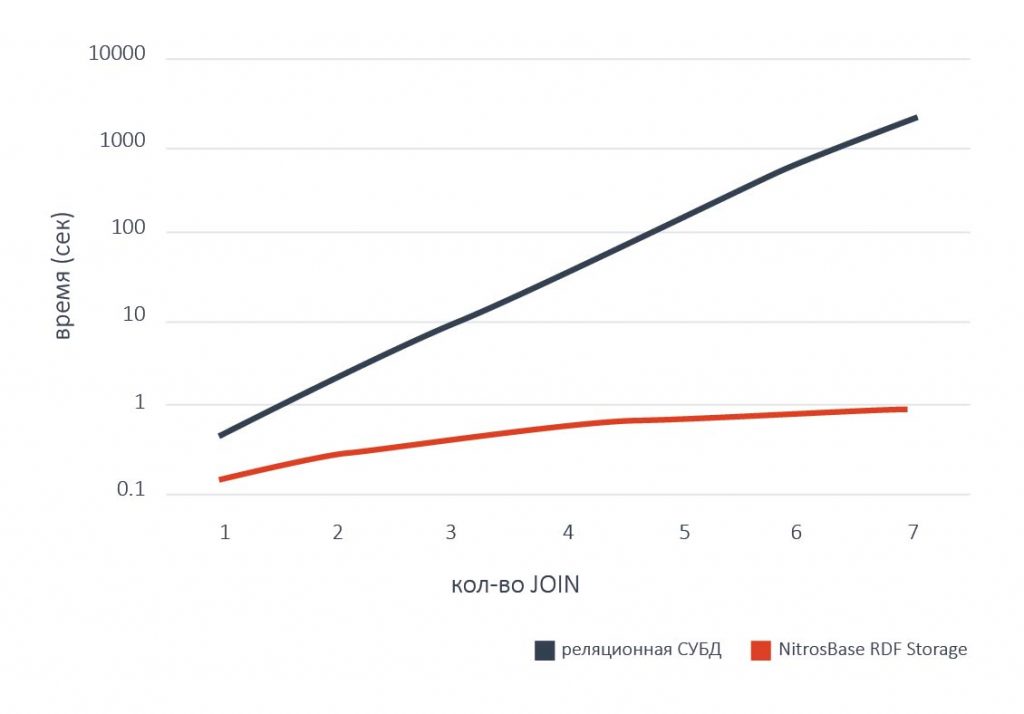
С помощью NitrosBase можно уже сейчас начать широкое распространение графовых СУБД для всех имеющихся на рынке ниш обработки данных.
Любые данные где-то хранятся. Будь это интернет вещей или пароли в *nix. Показываем схемы основных типов баз данных, чтобы наглядно представить различия между ними.

Типы баз данных, называемых также моделями БД или семействами БД, представляют собой шаблоны и структуры, используемые для организации данных в системе управления базами данных (СУБД). Выбор типа повлияет на то, какие операции сможет выполнять приложение, как будут представлены данные, на функции СУБД для разработки и рантайма.
Начнём с трёх типов БД, которые всё ещё могут встречаться в специализированных средах, но в основном заменены надежными и производительными альтернативами.
1. Простые структуры данных
Первый и простейший способ хранения данных – текстовые файлы. Метод применяется и сегодня для работы с небольшими объёмами информации. Для разделения полей используется специальный символ: запятая или точка с запятой в csv-файлах датасетов, двоеточие или пробел в *nix-подобных системах:
/etc/passwd в *nix системе
- ограничен тип и уровень сложности хранимой информации;
- трудно установить связи между компонентами данных;
- отсутствие функций параллелизма;
- практичны только для систем с небольшими требованиями к чтению и записи;
- используются для хранения конфигурационных данных;
- нет необходимости в стороннем программном обеспечении.
- /etc/passwd и /etc/fstab в *nix-системах
- csv-файлы
2. Иерархические базы данных

Пример построения иерархических связей
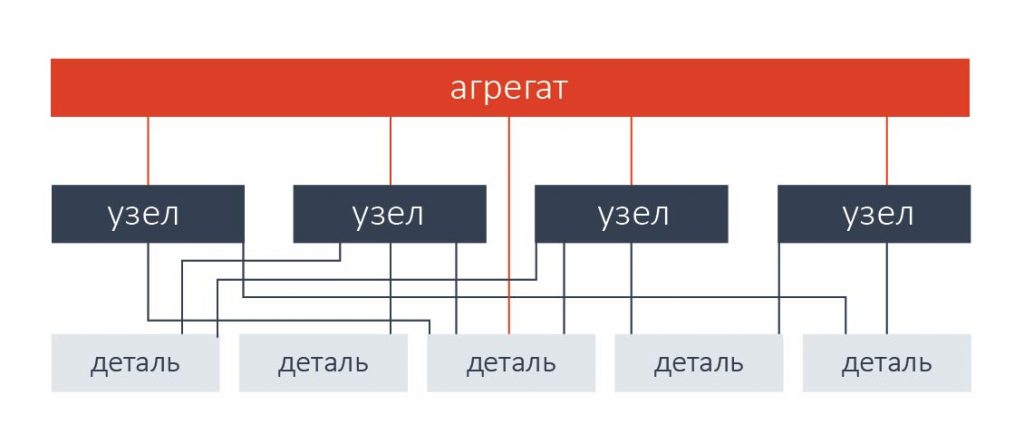
3. Сетевые базы данных
Сетевые базы данных расширяют функциональность иерархических: записи могут иметь более одного родителя. А значит, можно моделировать сложные отношения.

Пример связей в сетевой базе данных
- сетевые базы данных представляются не деревом, а общим графом
- ограничены теми же шаблонами доступа, что иерархические БД
4. SQL базы данных
Реляционные базы данных – старейший тип до сих пор широко используемых БД общего назначения. Данные и связи между данными организованы с помощью таблиц. Каждый столбец в таблице имеет имя и тип. Каждая строка представляет отдельную запись или элемент данных в таблице, который содержит значения для каждого из столбцов.

- поле в таблице, называемое внешним ключом, может содержать ссылки на столбцы в других таблицах, что позволяет их соединять;
- высокоорганизованная структура и гибкость делает реляционные БД мощными и адаптируемыми ко различным типам данных;
- для доступа к данным используется язык структурированных запросов (SQL);
- надёжный выбор для многих приложений.

- хранилища обеспечивают быстрый и малозатратный доступ;
- часто хранят данные конфигураций и информацию о состоянии данных, представленных словарями или хэшем;
- нет жёсткой схемы отношения между данными, поэтому в таких БД часто хранят одновременно различные типы данных;
- разработчик отвечает за определение схемы именования ключей и за то, чтобы значение имело соответствующий тип/формат.
6. Документная база данных

- база данных не предписывает опредёленный формат или схему;
- каждый документ может иметь свою внутреннюю структуру;
- документные БД являются хорошим выбором для быстрой разработки;
- в любой момент можно менять свойства данных, не изменяя структуру или сами данные.
7. Графовая база данных
Вместо сопоставления связей с таблицами и внешними ключами, графовые базы данных устанавливают связи, используя узлы, рёбра и свойства.

Графовые базы представляют данные в виде отдельных узлов, которые могут иметь любое количество связанных с ними свойств.
- выглядят аналогично сетевым;
- фокусируются на связях между элементами;
- явно отображает связи между типами данных;
- не требуют пошагового обхода для перемещения между элементами;
- нет ограничений в типах представляемых связей.
8. Колоночные базы данных
Колоночные базы данных (также нереляционные колоночные хранилища или базы данных с широкими столбцами) принадлежат к семейству NoSQL БД, но внешне похож на реляционные БД. Как и реляционные, колоночные БД хранят данные, используя строки и столбцы, но с иной связью между элементами.

- БД удобны при работе с приложениями, требующими высокой производительности;
- данные и метаданные записи доступны по одному идентификатору;
- гарантировано размещение всех данных из строки в одном кластере, что упрощает сегментацию и масштабирование данных.
9. Базы данных временных рядов
Базы данных временны́х рядов созданы для сбора и управления элементами, меняющимися с течением времени. Большинство таких БД организованы в структуры, которые записывают значения для одного элемента. Например, можно создать таблицу для отслеживания температуры процессора. Внутри каждое значение будет состоять из временной метки и показателя температуры. В таблице может быть несколько метрик.

- ориентированы на запись;
- предназначены для обработки постоянного потока входных данных;
- производительность зависит от количества отслеживаемых элементов, интервала опроса между записью новых значений и фактической полезной нагрузки данных.
NewSQL и многомодельные БД являются разными типами баз данных, но решают одну группу проблем, вызванных полярными подходами SQL или NoSQL-стратегии. Почему бы не объединить преимущества обеих групп?
10. NewSQL базы данных
NewSQL базы данных наследуют реляционную структуру и семантику, но построены с использованием более современных, масштабируемых конструкций. Цель – обеспечить большую масштабируемость, нежели реляционные БД, и более высокие гарантии согласованности, чем в NoSQL. Компромисс между согласованностью и доступностью является фундаментальной проблемой распределённых баз данных, описываемой теоремой CAP.
- возможность горизонтального масштабирования;
- высокая доступность;
- большая производительность и репликация;
- небольшой функционал и гибкость;
- немалое потребление ресурсов и необходимость специализированных знаний для работы с базой данных.
11. Многомодельные базы данных
Многомодельные базы данных – базы, объединяющие функциональные возможности нескольких видов БД. Преимущества такого подхода очевидны – одна и та же система может использовать различные представления для разных типов данных.
Совместное размещение данных из нескольких типов БД в одной системе позволяет выполнять новые операции, которые в противном случае были бы затруднены или невозможны. Например, многомодельные базы могут позволить юзерам получить доступ к данным, хранящимся в разных типах БД, и управлять ими в рамках одного запроса, а также поддерживают согласованность данных при выполнении операций, изменяющих информацию сразу в нескольких системах.
- помогают уменьшить нагрузку на СУБД;
- позволяют расширяться до новых моделей по мере изменения потребностей без внесения изменений в базовую инфраструктуру;
- обеспечивают непрерывный доступ и простое распределение данных;
- имеют линейную масштабируемость и просты для разработки.
Заключение
Изменение типов хранимых данных, требования к скорости и производительности привели и к продолжающемуся расширению типов баз данных. При этом каждый из них продолжает быть нужным в своей нише, где взаимосвязи между данными ассоциируются с определенной схемой строения базы данных.
В последние несколько лет произошел взрыв новых парадигм в базах данных. Ранее система управления реляционными базами данных (RDBMS), воплощенная подобными Microsoft SQLServer или Oracle MySQL, быладе-фактомаршрут для тех, кто ищет базу данных. Я затронул причины этого и посмотрел на некоторые из более новых или вновь открытых альтернатив в одном из моихранние произведения; в этой статье я собираюсь углубиться в одну из них, базу данных графиков, чтобы изучить, что они могут сделать, и показать некоторые варианты использования, где они сияют.
Что такое график?
Граф Базы данных, как следует из названия, организуют данные в виде графика, основанного на математическом принципетеория графов, По сути, мы можем рассматривать граф как совокупность узлов и ребер. Узлы обычно представляют объекты, ребра используются для представления отношений между этими объектами. Что делает это полезным для нас с точки зрения баз данных, так это то, что узлы могут содержать данные, описывающие сущность, но ребра также могут содержать данные, описывающие природу и детализацию этих отношений. Эти данные могут быть такими же простыми, как тип отношений, или гораздо более подробными.
Давайте посмотрим на примерный график и посмотрим, как это выглядит.

Один из замечательных аспектов графиков заключается в том, что они изначально слабо схематичны или не содержат схем. Это означает, что с течением времени, и мы хотим расширить граф для хранения различных типов сущностей и данных, мы можем просто создавать узлы, которые описывают их, не нарушая то, что у нас уже есть, или не делая сложных изменений схемы в базе данных.

Построение нашего примера MCU в Neo4j
Во-первых, если у вас естьNeo4j работаетили вы используетеонлайн песочницаони предоставляют нам нужно создать наш график. У нас есть несколько вариантов для этого, мы могли бы создать данные, используя серию отдельных операций Cypher (зеркальное отображение того, как приложение будет создавать данные в базе данных), мы можем использовать Cypher для загрузки данных из файла, такого как CSV или JSON, или мы можем использовать встроенную функцию ETL Neo4j для загрузки данных из RDBMS, подключенной к JDBC.
Давайте быстро рассмотрим пару, начнем с использования импорта файлов для создания данных, показанных в первом примере, который мы рассмотрели.
Во-первых, нам понадобятся данные для нашего графика в файлах CSV, которые мы можем импортировать, вы можете найти набор для использования в моемGitHub, Мы можем использовать их напрямую из GitHub, используя следующий Cypher, чтобы импортировать их и построить наш начальный график. Обратите внимание, что вам нужно запускать каждую команду отдельно.
Разбивая это, сначала мы создаем узлы для людей и фильмы на основе файлов CSV для каждого типа. Затем мы загружаем CSV, которые определяют отношения, и, сопоставляя узлы, создают подходящие отношения Наконец, как id Поле было необходимо только для построения отношений из нереляционных файлов, мы удаляем его из узлов. Это ключевой момент, а не в графических базах данных - поскольку отношения являются первоклассным гражданином, нам больше не нужно беспокоиться об идентификаторах для создания внешних ключей (да!).
Теперь у нас есть исходные данные, давайте запустим несколько операций Cypher, чтобы расширить их до полного графика, показанного во втором из наших примеров. Сначала мы можем запустить следующее, чтобы создать наш первый персонаж
И тогда мы можем связать его в графе с помощью пары отношений:
MATCH (person:Person ), (character:Character ) CREATE (person)-[:played]->(character)
MATCH (character:Character ), (movie:Movie ) CREATE (character)-[:appeared_in]->(movie)
Сделав это, мы можем использовать встроенный браузер Neo4j для запроса графика и проверить, что у нас есть.

Выполнение некоторых запросов
Теперь мы построили наш график, давайте рассмотрим некоторые из запросов, которые мы можем создать с помощью Cypher, чтобы изучить его. Вы можете запустить их прямо в браузере, который предоставляет Neo4j, чтобы увидеть результаты.
Во-первых, давайте посмотрим, что мы можем узнать о финале Avengers
Теперь давайте посмотрим на что-то более сложное, давайте найдем все фильмы, снятые Джозефом Руссо
Этот запрос вернет и Captain America Winter Soldier, и Мстителей Engame. Опять же, мы могли бы смоделировать это в СУБД, используя три таблицы с внешними ключами, а затем создать оператор Select, чтобы объединить их. Однако эти типы запросов - то, где Neo4j сияет с точки зрения производительности по реляционной базе данных; поскольку в Neo4j отношения хранятся эффективно, поскольку указатели, следующие за ними, являются тривиальной операцией по сравнению с алгоритмами соединения, используемыми СУБД. Синтаксис также обычно более очевиден, чем операторы SQL, состоящие из нескольких типов соединений, и нам не нужно беспокоиться о внешних ключах
Давайте использовать эту теорию, чтобы выполнить более сложный запрос, более глубоко изучая отношения между людьми и фильмами. Следующий Cypher возвращает выдержку из нашего графика, показывающего фильмы, снятые Джозефом Руссо, и с участием Роберта Дауни-младшего как актера
MATCH m=(director:Person )-[r.Directed]->(movie:Movie)
Как вы можете видеть, мы сейчас создаем довольно сложные запросы, основанные на отношениях, и опять-таки никаких сложных объединений или внешних ключей не видно.
Если мы хотим выполнить агрегирование, например, чтобы найти общий бюджет возвращенных выше фильмов, мы немного изменим запрос, как показано ниже.
MATCH m=(director:Person )-[r.Directed]->(movie:Movie)
Более сложные отношения
До сих пор мы рассматривали довольно простые отношения, которые только определяют характер отношений. Neo4j позволяет нам пойти дальше и добавить данные в отношения; мы построим новый график для сопоставления боев в MCU, чтобы увидеть, как это работает.

Во-первых, давайте использовать эти дополнительные данные, чтобы найти имя каждого, кто сражался с Таносом в Войне Бесконечности Мстителей
MATCH (hero:Character)-[:fought ]->(villain:Character ) RETURN hero.name
Если мы запустим это, нам вернутся четыре имени: Железный Человек, Капитан Америка, Видение и Черная Вдова. Давайте теперь выясним, кто сражался с Таносом в Engame, но не в Infinity Wars
Match (hero:Character)-[:fought ]->(villain:Character ), (hero2:Character)-[:fought (villain:Character ) WITH COLLECT (distinct hero.name) AS AIWheros, COLLECT (distinct hero2.name) as AEheros RETURN [x in AEheros WHERE NOT (x in AIWheros)]
Добавляя метаданные к нашим отношениям, мы можем использовать Chypher, чтобы начать понимать очень сложные графы.
Мы начали с небольшого взгляда на теорию графов и на то, как она поддерживает класс баз данных NoSQL, которые мы можем использовать в наших решениях.
Затем мы взглянули на Neo4j, как мы можем использовать его для создания графиков данных, а затем строить запросы для получения информации и значения из данных и особенно отношений.
Мы видели, как графические базы данных являются невероятно мощным инструментом для определенных классов проблем, и что, хотя мы можем решать их с помощью более традиционных механизмов баз данных, графические базы данных обеспечивают гораздо более оптимизированное решение.
Читайте также: