
Чем отличается стандарт unicode от кодировки ascii кратко
Обновлено: 02.07.2024
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
Разница между Unicode и ASCII: Unicode и ASCII являются стандартами кодирования текстов, используемыми во всем мире. Эти коды предоставляют уникальный номер для каждого символа независимо от того, какой язык или программа используется.

Кодировка символов и чисел с помощью ASCII и Unicode немного отличается. Unicode и ASCII - это стандарты того, как представлять разные символы в двоичный так что они могут быть записаны, сохранены, переданы и прочитаны в цифровые СМИ.
Юникод и ASCII
ASCII сокращается от Американский стандартный код Для обмена информацией. Это символ, который используется в стандарте кодирования для связь через электронику.
Одна из основных причин, почему Unicode был проблемой, возникла из-за множества нестандартных расширенных программ ASCII. Если вы не используете распространенную страницу, которая используется Microsoft и большинство других софтверные компании, то вы, вероятно, столкнетесь с проблемами, когда ваши персонажи будут отображаться в виде прямоугольников.
Что такое ASCII?
Любая электронная устройство связи считывает данные как электрические импульсы, как включенные, так и выключенные. Это включение и выключение представлено в цифровом виде как 1 и 0 соответственно.
Представление данных в виде единиц и нулей называется двоичное представление. Все, что вы вводите на компьютере, сохраняется только в виде этих двух чисел.
В первые годы развития вычислительной техники единственный язык, известный программисты был английским (поскольку компьютеры и все, что с этим связано, было изобретено в США).
Следовательно, для компьютерные кодеры, всего 127–128 символов было более чем достаточно для представления всего, что было на клавиатуре.
Компьютерные кодеры, разработанные ASCII - Американский стандартный код для обмена информациейстандарт кодирования. Этот стандарт использовался для кодирования определенного количества символов, точнее 127.
Эти 127 символов включают: AZ, az, 0-9, знаки препинания, символы новой строки и так далее.

Что такое Юникод?
Краткая форма Американский стандартный код для обмена информацией - ASCII. Кодировка этой системы основана на упорядочивании английского алфавита. Все современные машины кодирования данных поддерживают ASCII, а также другие. ASCII был впервые использован службой данных Bell в качестве семибитного телепринтера.
Использование двоичных систем привело к огромным изменениям в наших персональных вычислениях. Личное Компьютер как мы видим сейчас, преимущество использования двоичный язык который использовался в качестве основных вещей для кодирования и декодирования. На нем основаны различные языки, созданные и принятые позже.
Как двоичная система делает ПК более удобным и удобным для всех, аналогично ASCII используется для облегчения общения. 33 символа не печатаются, 94 символа печатаются, а всего пробел составляет 128 символов, которые используются ASCII.

Заметные различия между Unicode и ASCII
1. ASCII - это американская система кодирования, в то время как Unicode - это международная система кодирования компьютеров и других электронных устройств.
3. Юникод стандартизирован, а ASCII - нет.
4. Unicode представляет большинство письменных языков в мире, а ASCII - нет.
5. Американский стандартный код для обмена информацией имеет свой эквивалент в Юникоде.
6. ASCII обычно представляет строчные и прописные буквы, цифры и Символы а с другой стороны, Unicode представляет все буквы арабского, английского и других языков.
7. ASCII представляет собой небольшой диапазон чисел и символов, в то время как, с другой стороны, Unicode представляет математические символы, скрипты, эмодзи и широкий диапазон символов по сравнению с ASCII.
Если вам понравилась эта статья, подпишитесь на вашу электронную почту для связанных материалов. Благодарю.
CSN Team.
=> ПОСЛЕДУЮЩИЕ США НА INSTAGRAM | FACEBOOK & TWITTER ДЛЯ ПОСЛЕДНЕГО ОБНОВЛЕНИЯ
могу ли я знать точную разницу между Unicode и ASCII?
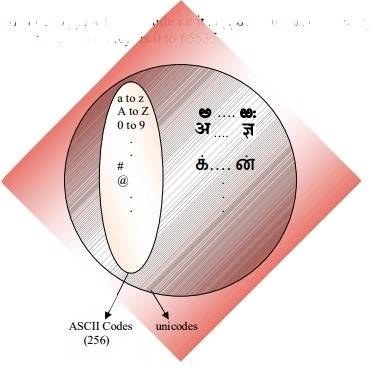
ASCII имеет в общей сложности 128 символов (256 в расширенном наборе).
есть ли спецификация размера для символов Unicode?
ASCII определяет 128 символов, которые сопоставляются с числами 0-127. Unicode определяет (меньше) 2 21 символы, которые аналогично сопоставляются с числами 0-2 21 (хотя не все номера в настоящее время назначены, а некоторые зарезервированы).
Unicode является надмножеством ASCII, и числа 0-128 имеют то же значение в ASCII, что и в Unicode. Например, число 65 означает "Латинская столица "а"".
понимание почему ASCII и Unicode были созданы в первую очередь помогли мне понять как они на самом деле работают.
ASCII, Origins
как указано в других ответах, ASCII использует 7 бит для представления символа. Используя 7 бит, мы можем иметь максимум 2^7 (= 128) различных комбинаций * . Это означает, что мы можем представить 128 символов.
большинство символов ASCII являются печатными символами алфавита, такими как abc, ABC, 123,?&!, п. Остальные символы например возврата каретки, перевода строки, tab, etc.
смотрите ниже двоичное представление нескольких символов в ASCII:
см. полную таблицу ASCII здесь.
ASCII предназначался только для английского языка.
что? Почему только английский? Так много языков!
потому что центр компьютерной индустрии был в США в это время. Как следствие, им не нужно было поддерживать акценты или другие знаки, такие как á, ü, ç, ñ, и т. д. (также известный как диакритические знаки).
ASCII Extended
Unicode, The Rise
ASCII Extended решает проблема для языков, которые основаны на латинском алфавите. а как насчет других, которым нужен совершенно другой алфавит? Греческий? Русский? Китайский и тому подобное?
нам нужен совершенно новый набор символов. это рациональная основа Unicode. Unicode не содержит каждый символ из каждого языка, но он уверен, что содержит гигантское количество символов (посмотреть в этой таблице).
вы не можете сохранить текст на жесткий диск как "Unicode". Unicode-это абстрактное представление текста. Вам нужно "закодировать" это абстрактное представление. Вот где кодирование вступает в игру.
кодировки: UTF-8 vs UTF-16 vs UTF-32
ответ делает довольно хорошую работу по объяснению основ:
- UTF-8 и UTF-16 кодировки переменной длины.
- в UTF-8 символ может занимать не менее 8 бит.
- In UTF-16, длина символа начинается с 16 бит.
- UTF-32-кодировка фиксированной длины в 32 бита.
UTF-8 использует набор ASCII для первых 128 символов. Это удобно, потому что это означает, что текст ASCII также действителен в UTF-8.
почему 2^7?
Это очевидно для некоторых, но на всякий случай. У нас есть семь слотов, заполненных либо 0, либо 1 (Двоичный Код). Каждый может иметь две комбинации. Если у нас есть семь мест, мы 2 * 2 * 2 * 2 * 2 * 2 * 2 = 2^7 = 128 комбинаций. Подумайте об этом как о кодовом замке с семью колесами, каждое колесо имеет два номера только.
Unicode пришел, чтобы решить эту катастрофу. Версия 1 начиналась с 65536 кодовых точек, обычно закодированных в 16 битах. Later extended в версии 2 до 1,1 млн. кодовых точек. Текущая версия 6.3, используя 110,187 из доступных 1,1 миллиона кодовых точек. Это больше не вписывается в 16 бит.
Кодирование в 16-битах было распространено, когда v2 появился, например, в операционных системах Microsoft и Apple. И языковые среды, такие как Java. Спецификация v2 придумала способ сопоставить эти 1,1 миллиона кодовых точек в 16 бит. Кодировка называется UTF-16, кодировка переменной длины, где одна кодовая точка может принимать 2 или 4 байта. Исходные кодовые точки v1 занимают 2 байта, добавленные-4.
другое кодирование переменной длины, которое очень распространено, используется в операционных системах *nix и инструментах UTF-8, кодовая точка может принимать от 1 до 4 байтов, исходные коды ASCII занимают 1 байт, остальные занимают больше. Единственная кодировка без переменной длины-UTF-32, занимает 4 байта для кодовой точки. Не часто используется, так как это довольно расточительно. Другие одни, как UTF-1 и UTF-7, широко игнорируемый.
проблема с кодировками UTF-16/32 заключается в том, что порядок байтов будет зависеть от конечности машины, которая создала текстовый поток. Поэтому добавьте в микс UTF-16BE, UTF-16LE, UTF-32BE и UTF-32LE.
наличие этих различных вариантов кодирования возвращает катастрофу кодовой страницы в некоторой степени, наряду с горячими дебатами среди программистов, выбор UTF является "лучшим". Их связь с операционной системой по умолчанию в значительной степени рисует линии. Один counter-measure-это определение спецификации, метка порядка байтов, специальная кодовая точка (U+FEFF, пространство нулевой ширины) в начале текстового потока, которая указывает, как кодируется остальная часть потока. Он указывает как кодировку UTF, так и endianess и нейтрален к движку рендеринга текста. К сожалению, это необязательно, и многие программисты заявляют о своем праве опустить его, поэтому несчастные случаи все еще довольно распространены.
ASCII имеет 128 позиций кода, выделенных графическим символам и управляющим символам (управляющим кодам).
Unicode имеет 1,114,112 кодовых позиций. Около 100 000 из них в настоящее время были выделены символам, и многие кодовые точки были сделаны постоянно нехарактерными (т. е. никогда не использовались для кодирования какого-либо символа), и большинство кодовых точек еще не назначены.
единственное, что ASCII и Unicode имеют в общей являются: 1) Они характер коды. 2) 128 первых кодовых позиций Юникода были определены, чтобы иметь те же значения, что и в ASCII, за исключением того, что кодовые позиции символов управления ASCII просто определены как обозначающие символы управления, с именами, соответствующими их именам ASCII, но их значения не определены в Юникоде.
Иногда, однако, Unicode характеризуется (даже в стандарте Unicode!) как "широкий ASCII". Это слоган, который в основном пытается передать идею, что Unicode предназначен для будь универсальная символьный код так же, как когда-то ASCII (хотя репертуар символов ASCII был безнадежно недостаточен для универсального использования), в отличие от использования разных кодов в разных системах и приложениях и для разных языков.
Unicode как таковой определяет только "логический размер" символов: каждый символ имеет кодовый номер в определенном диапазоне. Эти кодовые номера можно представить используя различные кодировки передачи, и внутренне, внутри память, символы Юникода обычно представлены с использованием одного или двух 16-разрядных величин на символ, в зависимости от диапазона символов, иногда с использованием одного 32-разрядного количества на символ.
java обеспечивает поддержку Unicode i.e он поддерживает все Всемирные алфавиты. Следовательно, размер char в java составляет 2 байта. И диапазон от 0 до 65535.
одна из основных причин, почему Unicode была проблемой, возникла из-за многих нестандартных расширенных Программы в ASCII. Если вы не используете распространенную страницу, которая используется Microsoft и большинством других программных компаний, вы, скорее всего, столкнетесь с проблемами с вашими персонажами, появляющимися в виде ящиков. Unicode практически устраняет эту проблему, поскольку все кодовые точки символов были стандартизированы.
еще одно важное преимущество Unicode заключается в том, что на максимуме он может вместить огромное количество символов. Из-за этого Unicode в настоящее время содержит большинство письменных языков и все еще есть место и для большего. Это включает в себя типичные слева направо скрипты, такие как английский и даже справа налево скрипты, такие как арабский. Китайский, японский, и многие другие варианты также представлены в Юникоде. Таким образом, Unicode не будет заменен в ближайшее время.
для поддержания совместимости со старым ASCII, который уже широко использовался в то время, Unicode был разработан таким образом, что первые восемь битов соответствовали наиболее популярной странице ASCII. Поэтому, если вы откроете ASCII кодированный файл с Unicode, вы все равно получите правильные символы, закодированные в файле. Это облегчило принятие Юникода, поскольку уменьшило влияние принятия нового стандарта кодирования для тех, кто уже использовал ASCII.

Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
- прогноза погоды;
- вычислений экспериментальной и теоретической физики;
- расчета заработной платы сотрудников (например, компьютер LEO применялся для нужд компании, владеющей сетью чайных магазинов);
- прогнозирование результатов выборов президента США (1952 год, компьютер UNIVAC).
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
- Число из десятичной системы счисления переводится в двоичную, т.е. набор нулей и единиц. Например, 3 в двоичной системе счисления можно записать в виде 11, а 9 как 1001. Подробнее о системах счисления читайте в соответствующем гайде.
- Полученный набор нулей и единиц хранится в ячейках памяти компьютера. Например, наличие тока на элементе памяти означает единицу, его отсутствие — ноль.

В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).

Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
- Компьютеры должны стать универсальными. Это означало переход от производства узкоспециализированных компьютеров к машинам, которые могут решать разные задачи.
- Компьютеры должны стать совместимыми друг с другом, то есть должна быть возможность использовать данные с одного компьютера на другом.
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).

Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
- символ Ø можно было получить так: печатаем O, затем с помощью управляющего кода BS (BackSpace) передвигаем печатную головку на один символ назад и печатаем символ /,
- символ à получался как a BS `
- символ Ç получался как C BS ,
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.

Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Читайте также:
- Почему появление позвоночника и черепа у животных имеет большое приспособительное значение кратко
- С творчеством каких русских писателей связаны города золотого кольца россии кратко
- Как екатерина 2 взошла на престол кратко
- План работы с детьми не посещающими детский сад
- План урока по чеченской литературе 4 класс къоьллел хьекъал тоьлла