
Сообщение в информатике это буква
Обновлено: 18.05.2024
Единицей измерения количества информации является бит – это наименьшаяединица.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i .
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2 i .
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
16 = 2 i , 2 4 = 2 i , т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Математически это произведение записывается так: I = К · i.
32 = 2 i , 2 5 = 2 i , т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
I = 23 · 8 = 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Разбор решения заданий тренировочного модуля
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2 i .
В информатике алфавит — это множество (как правило конечное) символов или букв, например латинских букв и цифр. Примером распространённого алфавита является двоичный алфавит . Конечная строка — это конечная последовательность букв алфавита. Например, двоичная строка — это строка из символов алфавита . Также возможно построение бесконечных последовательностей из букв алфавита.
Пусть дан алфавит . Тогда обозначает множество всевозможных строк из символов алфавита . Здесь ^*" width="" height="" />
обозначен оператор звезда Клини. Запись (или иногда или ) обозначает множество всех бесконечных последовательностей символов из алфавита .
Например, для алфавита строки составляют его замыкание Клини (где ε обозначает пустую строку).
Алфавиты играют важную роль в теории формальных языков, автоматов и полуавтоматов. В большинстве случаев для определения сущности автоматов, таких как детерминированный конечный автомат (ДКА), требуется задать алфавит, из которого составляются входные строки для автомата.
Понятие "информация" имеет различные трактовки в разных предметных областях. Например, информация может пониматься как:
- абстракция, абстрактная модель рассматриваемой системы (в математике);
- сигналы для управления, приспособления рассматриваемой системы (в кибернетике);
- мера хаоса в рассматриваемой системе (в термодинамике);
- вероятность выбора в рассматриваемой системе (в теории вероятностей);
- мера разнообразия в рассматриваемой системе (в биологии) и др.
Рассмотрим это фундаментальное понятие информатики на основе понятия "алфавит" ("алфавитный", формальный подход). Дадим формальное определение алфавита .
Алфавит – конечное множество различных знаков, символов, для которых определена операция конкатенации (приписывания, присоединения символа к символу или цепочке символов); с ее помощью по определенным правилам соединения символов и слов можно получать слова (цепочки знаков) и словосочетания (цепочки слов ) в этом алфавите (над этим алфавитом ).

Буквой или знаком называется любой элемент x алфавита X , где . Понятие знака неразрывно связано с тем, что им обозначается ("со смыслом"), они вместе могут рассматриваться как пара элементов (x, y) , где x – сам знак, а y – обозначаемое этим знаком.
Пример. Примеры алфавитов : множество из десяти цифр, множество из знаков русского языка, точка и тире в азбуке Морзе и др. В алфавите цифр знак 5 связан с понятием "быть в количестве пяти элементов".
Конечная последовательность букв алфавита называется словом в алфавите (или над алфавитом ).
Длиной |p| некоторого слова p над алфавитом Х называется число составляющих его букв .
Слово (обозначаемое символом ) имеющее нулевую длину , называется пустым словом : | | = 0.
Множество различных слов над алфавитом X обозначим через S(X) и назовем словарным запасом (словарем) алфавита (над алфавитом ) X .
В отличие от конечного алфавита , словарный запас может быть и бесконечным.
В алфавите должен быть определен порядок следования букв (порядок типа "предыдущий элемент – последующий элемент"), то есть любой алфавит имеет упорядоченный вид X = 1, x2, …, xn> .
Таким образом, алфавит должен позволять решать задачу лексикографического (алфавитного) упорядочивания, или задачу расположения слов над этим алфавитом , в соответствии с порядком, определенным в алфавите (то есть по символам алфавита ).
Информация по отношению к источнику или приемнику бывает трех типов: входная, выходная и внутренняя.
Информация по отношению к конечному результату бывает исходная, промежуточная и результирующая.
Информация по ее изменчивости бывает постоянная, переменная и смешанная.
Информация по стадии ее использования бывает первичная и вторичная.
Информация по ее полноте бывает избыточная, достаточная и недостаточная.
Информация по доступу к ней бывает открытая и закрытая.
Есть и другие типы классификации информации .
Пример. В философском аспекте информация делится на мировоззренческую, эстетическую, религиозную, научную, бытовую, техническую, экономическую, технологическую.

ГОСТ
Общее понятие кодирования информации
Познание окружающего мира начинается с восприятия его человеком с помощью органов чувств. Зрение, вкус, слух, обоняние, осязание доводят до нашего сознания информацию о самых разнообразных свойствах предметов, а также явлениях и процессах, происходящих вокруг нас. Эта информация поступает к нам в виде набора символов или сигналов. Однако если эти символы или сигналы никому не ясны, то информация будет бесполезной. Поэтому требуется язык общения, который будет понятен всем.
Естественные и формальные языки представления информации
Язык — это знаковая система для представления и передачи информации.
- естественные (например, мимика и жесты, музыка, живопись, речь человека);
- формальные (например, математическая символика, чертежи и схемы, нотная грамота, языки программирования).
Естественный язык можно формализовать. Так для формализации музыки изобрели нотную грамоту, для формализации речи создали национальные алфавиты (например, латинский ($26$ символов), русский ($33$ символа)), кроме этого арабские цифры, азбуку Морзе и т.д.
Естественные языки развивались веками и служили для общения людей между собой. Формальные языки разрабатываются для специальных применений.
Коммуникативный язык несет в себе логическую информацию, именно с помощью него человек преобразует получаемую информацию в знания и передает эти знания другим людям.
Алфавиты представления информации
Первобытные люди для обозначения каждого нового предмета придумывали новые имена. Для получения необходимого разнообразия имен, названий они стали комбинировать звуки таким образом, чтобы получить в результате слова. Так в ходе эволюции человека появилась идея создания конечного алфавита, т.е. некоторого фиксированного набора знаков, из которого можно составить как угодно много слов. Комбинация знаков алфавита называется словом. Из слов можно составлять фразы, которые будут нести определенную смысловую нагрузку.
Готовые работы на аналогичную тему
Таким образом, алфавит – это упорядоченный набор символов или сигналов, который составляет основу языка.
Мощность алфавита - это количество составляющих его символов.
Человек в своей практике общения использует самые разнообразные языки (например, дорожная грамота, включающая в себя знаки дорожного движения и разметки). Прежде всего, это, конечно же, языки устной и письменной речи, в том числе и иностранные.
Кроме того, человек использует ряд языков профессионального назначения. К ним относятся языки математических и химических формул, обозначений электроники (например, схема электрической цепи), языки программирования. При этом каждый язык имеет свой алфавит.
С развитием технических средств передачи информации появилась необходимость использования помимо речевых алфавитов многих других. Одним из примеров первых алфавитов, используемых в технике, является азбука Морзе, в которой каждому знаку обычного алфавита соответствует набор точек и тире.
Общее понятие кодирования информации
Воспринимая информацию, человек стал стремиться зафиксировать ее таким образом, чтобы она стала понятной для других, представляя ее в той или иной форме.
Музыкальную тему композитор может наиграть на пианино, а затем записать с помощью нот. Образы, навеянные все той же мелодией, поэт может воплотить в виде стихотворения, хореограф выразить танцем, а художник — в картине.
Люди сохраняют свои знания, записывая их на различных носителях. Благодаря чему эти знания передаются не только в пространстве, но и во времени — от одного поколения к другому.
До наших дней дошли послания предков, которые с помощью различных символов пытались изобразить себя и свои поступки в памятниках и надписях. Примером могут служить наскальные рисунки (петроглифы), которые по сей день представляют загадку для ученых. Вероятнее всего, таким образом древние люди пытались вступить в контакт с будущими поколениями и сообщить о событиях их жизни.
Каждый народ имеет свой язык, состоящий из набора символов (букв): русский, английский, японский и многие другие. Об этом уже упоминалось ранее.
Представление информации с помощью какого-либо языка часто называют кодированием.
Код — это набор символов либо условных обозначений, используемый для представления информации.
Алфавит кодирования содержит полный набор кодов.
Кодирование — это процесс представления информации с помощью кода.
Так водитель пытается передать сигнал с помощью гудка или мигания фар. В данном случае гудок (его наличие или отсутствие) – это код, а в случае световой сигнализации кодом будет являться мигание фар или его отсутствие. Пешеход встречается с кодированием информации при переходе дороги по сигналу светофора. Код определяет цвет светофора — красный, желтый, зеленый.
Естественный язык, на котором мы общаемся, тоже представляет собой код, называемый алфавитом. Во время устной речи этот код передается звуками, при письменной — буквами. Причем одну и ту же информацию можно представить различными способами. К примеру, запись разговора можно закодировать на бумажном носителе двумя способами: с помощью букв или специальных стенографических знаков.
В более узком смысле под кодированием часто понимают переход от одной формы представления информации к другой, которая более удобна при хранении, передаче или обработке.
В процессе развития технических средств появлялись новые способы кодирования информации. Так во второй половине XIX века американский изобретатель Сэмюэль Морзе придумал удивительно простой код, который применяется до сих пор. Используя этот код, информацию можно представить в виде: длинного сигнала (тире), короткого сигнала (точки) и отсутствия сигнала (паузы) для разделения букв. Таким образом, принцип кодирования сводился к использованию набора символов, расположенных в строго определенном порядке.

Знаменитый немецкий ученый Готфрид Вильгельм Лейбниц предложил еще в XVII веке уникальную по своей простоте систему представления чисел, основанную на использовании вычислений с помощью двоек.
В настоящее время этот способ представления информации с помощью языка, в состав которого входит всего два символа: $0$ и $1$, называется двоичным кодированием информации и широко используется в технических устройствах, в том числе и в компьютере. Эти два символа $0$ и $1$ принято называть двоичными цифрами или битами (от англ. bit — Binary Digit - двоичный знак).
Каждому человеку ежедневно в бытовых условиях приходится сталкиваться с устройствами, которые могут находиться только в двух устойчивых состояниях: включено или выключено. И это хорошо известные всем выключатели. Однако изобрести выключатель, который был бы способен устойчиво и быстро переключаться в любое из $10$ состояний, оказалось невозможно. В итоге после ряда неудачных попыток разработчики сделали вывод о невозможности создания компьютера на основе десятичной системы счисления. Поэтому представление чисел в компьютере осуществляется с помощью двоичной системы счисления.
Способ кодирования информации зависит от цели, которая при этом должна быть достигнута. Целью может являться сокращение записи, засекречивание (шифровка) информации, или, напротив, достижение взаимопонимания. Например, система дорожных знаков, флажковая азбука на флоте, специальные научные языки и символы ― химические, математические, медицинские и др., предназначены для того, чтобы люди могли общаться и понимать друг друга. От того, как представлена информация, зависит способ ее обработки, хранения, передачи и т.д.
К категории символов относятся строчные и прописные буквы, знаки препинания, цифры, пробел, разнообразные специальные знаки.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
Представление символов в вычислительных машинах
В вычислительных машинах символы представлены в виде последовательностей бит. Возможность их передачи и корректного отображения на разных устройствах обеспечена уникальной последовательностью единиц и нулей, характерной для определенного знака.
Бит — это двоичный знак двоичной системы, обозначающий минимальный элемент информации для вычислительной машины.
Символы бывают печатными и непечатными. Печатные — это те, что мы видим на экране компьютера. Непечатные лишены изображения, но тоже обладают уникальным кодом. При их пересылке машина выполняет закодированную операцию, но не отображает ее результат на мониторе.
Простыми примерами непечатных знаков являются команды перемещения в следующую строку, возврата в начало строки.
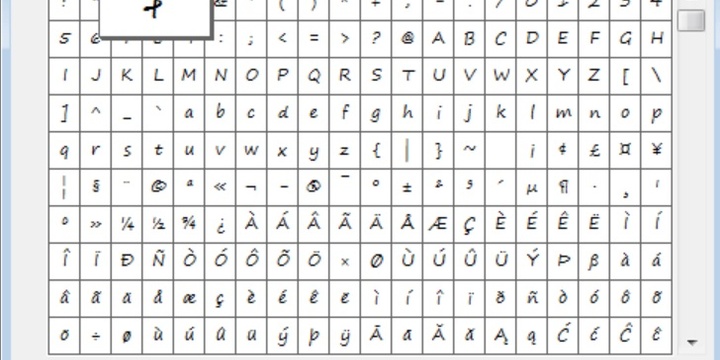
Кодировки символов, какие бывают, таблица
Для того чтобы закодированная информация могла без искажения передаваться между устройствами, необходима некая единая система. Считается, что первой такой системой стала таблица ASCII 7. В нее вошли 128 символов.
Второй стала ее усовершенствованная версия — ASCII 8, сделавшая допустимым хранение 256 знаков.
ASCII 8 содержала набор из управляющих символов, прописных и строчных букв английского алфавита, знаков препинания и арабских цифр. Однако для многих языков этого было недостаточно: графика арабского, китайского и японского не укладывалась в 256 знаков. Поэтому разработка продолжилась и привела к возникновению стандарта Unicode.

Этот стандарт содержит 109000 разнообразных символьных обозначений и пока удовлетворяет потребности даже самых сложных с графической точки зрения языков.
Специальные символы по информатике
В информатике, математике и других точных науках существует множество специальных символов, обозначающих математические действия, значения, меры. Уместить их все на клавиатуру невозможно. Поэтому для их введения разработали специальные таблицы.
Читайте также: