
Как положить сообщение в очередь
Обновлено: 04.07.2024
Почему RabbitMQ?
Причин несколько, но одна из основных — реализация приложения на платформе Erlang/OTP, гарантирующая максимальную стабильность и масштабируемость очереди, как ключевого узла всей системы. Другая причина — полная открытость приложения, распространяющегося по лицензии Mozilla Public License и реализация открытого протокола AMQP, библиотеки для которого существуют во всех основных языках и платформах программирования. В том числе и для Node.js
Основные понятия
Брокер
Очередь
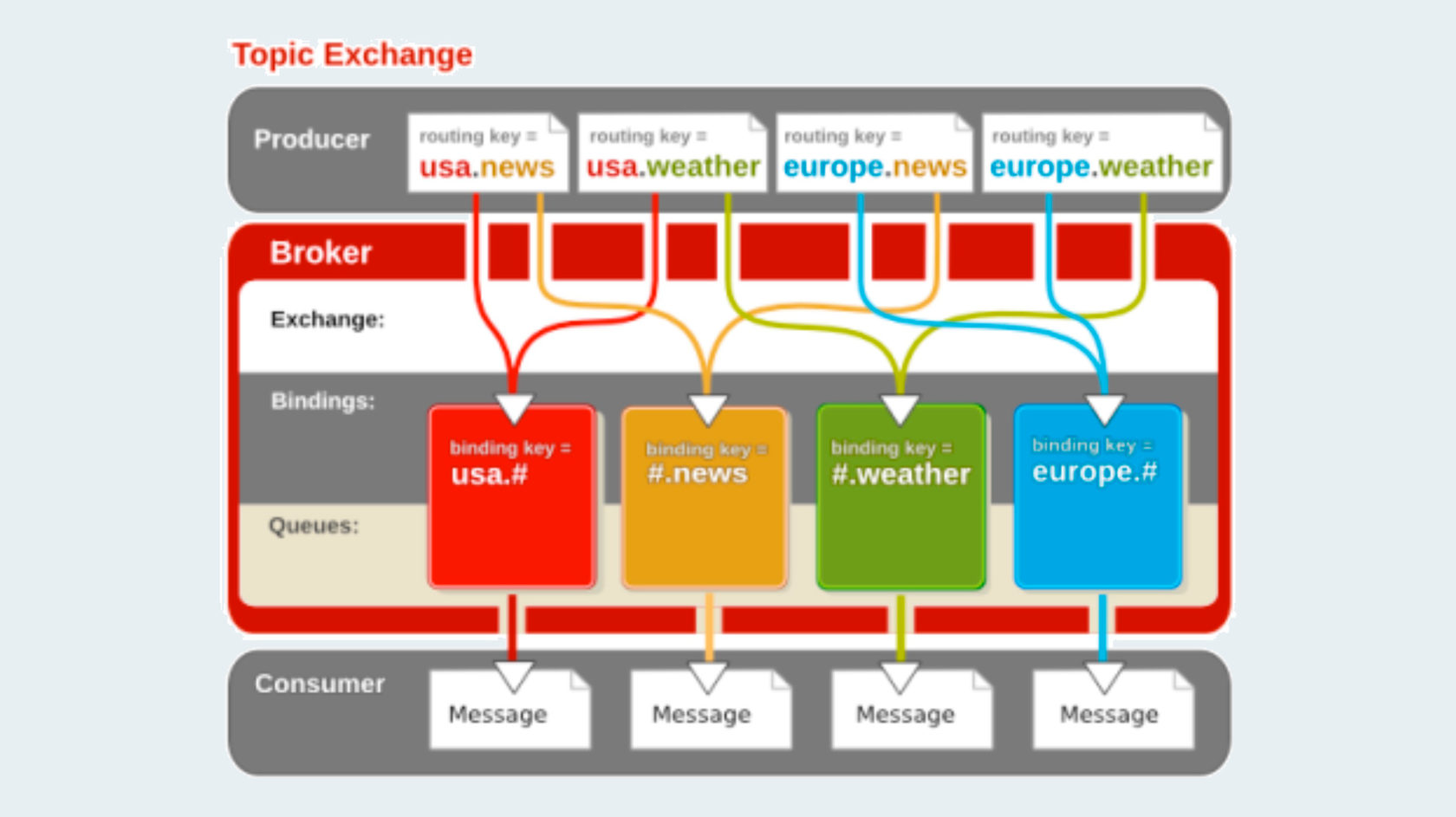
Биржа
Обратите внимание: брокер по-умолчанию сам распределяет нагрузку между клиентами, вам ничего не нужно для этого делать. Один у вас клиент, или пятьдесят — брокеру всё равно.
Publish-Subscribe (он же Broadcast)
Всего одно маленькое дополнение — и совершенно изменившийся алгоритм работы. Как видите, для того, чтобы менять поведение брокера, вовсе не нужно лезть в глубокие настройки сервера. Достаточно слегка поменять код.
Маршрутизация по шаблону
Существует два особых знака, которые используются в routingKey при привязке очереди к бирже по метке (и только тогда, но не при отправке!):
Remote Procedure Call
Клиент
На клиенте всё очень просто: в вызов publish добавляется специальная опция replyTo, значением которой является имя очереди, в которой клиент будет ожидать ответ. Обратите внимание, что в данном случае клиент обращается к серверу именно через publish, поскольку он хочет вызвать удалённую процедуру, находящуюся на сервере. В данном сценарии отправителем будет являться клиент, а потребителем — сервер. Затем их роли поменяются местами, когда сервер отправит клиенту ответ.
Варианты работы
Прямая передача
Для работы с RabbitMQ в Node.js лучше всего использовать библиотеку amqplib , реализующую соответствующий протокол. В этом случае вы можете использовать любой брокер, который соответствует этому протоколу.
Связь с брокером и создание канала
Рассмотрим по порядку, что происходит после установления связи с брокером и создания канала.
Клиент для тестирования отправителя
Однако в этом случае возникает вопрос: как отделить ответ на один вызов от другого? Для этой ситуации предназначен ещё один параметр вызова publish : correlationId . Он принимает строковое значение и возвращается в ответе от сервера, чтобы клиент мог на его основе определить, результат какого вызова он получил только что. Его можно генерировать случайным образом. Если же клиенту приходит ответ с неизвестным correlationId , то его можно смело игнорировать. Такое может случиться из-за рассинхронизации сервера и брокера, например, в случае падения сервера.
Общий алгоритм работы

Я Артём Лисовский, head of learning в IT-компании kt.team. Статья составлена на базе выступления для команды kt.team и может быть полезна и интересна всем разработчикам, которые пишут сервисы с высокими требованиями к отказоустойчивости и масштабируемости.
Содержание
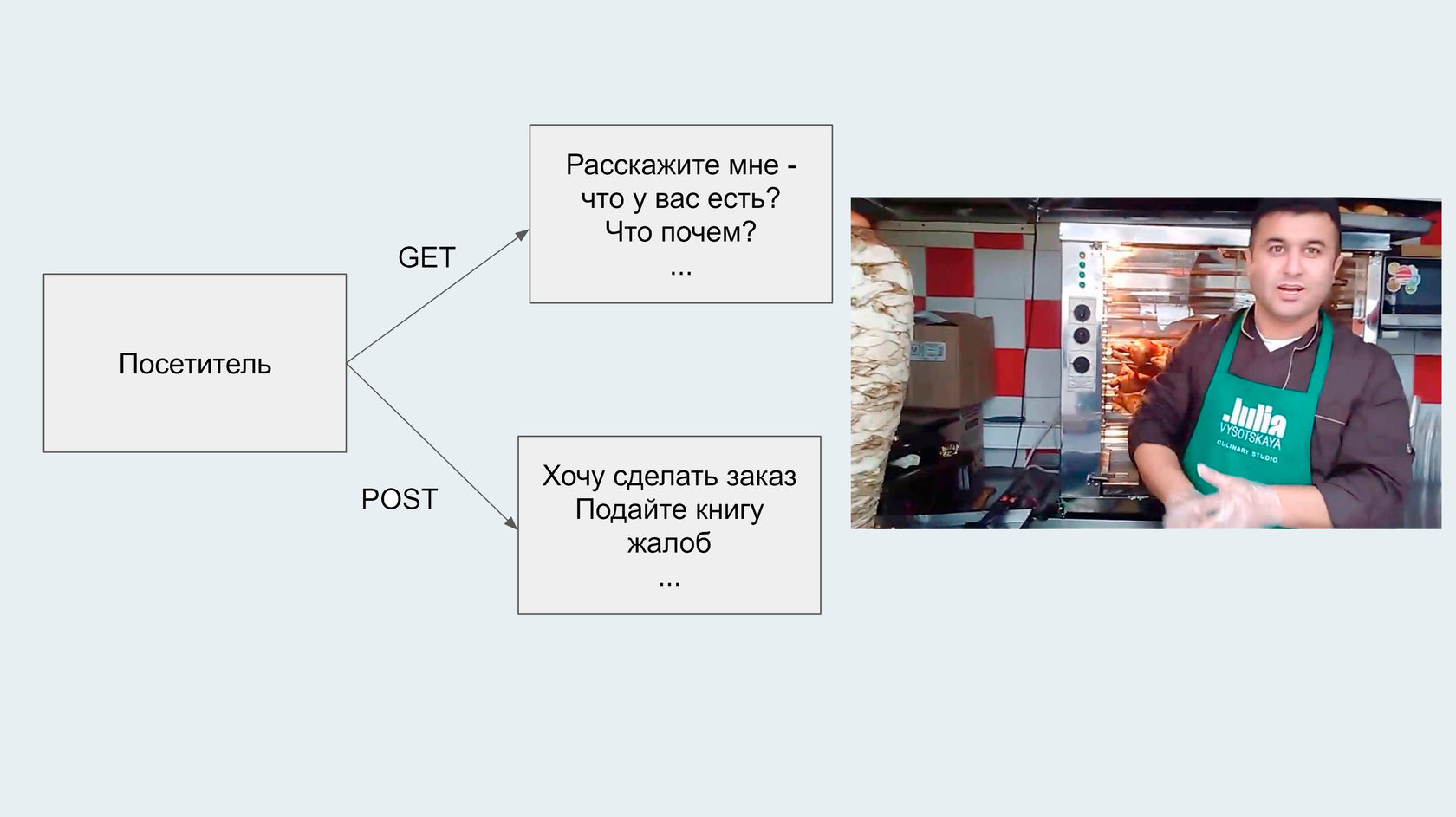
Работа ларька шаурмы очень похожа на работу web-сайта, потому что и там и там посетители выполняют похожие действия:


А POST-запросы состоят из желания сделать заказ, просьбы дать книгу жалоб и так далее; всё, что мы можем запросить у продавца.


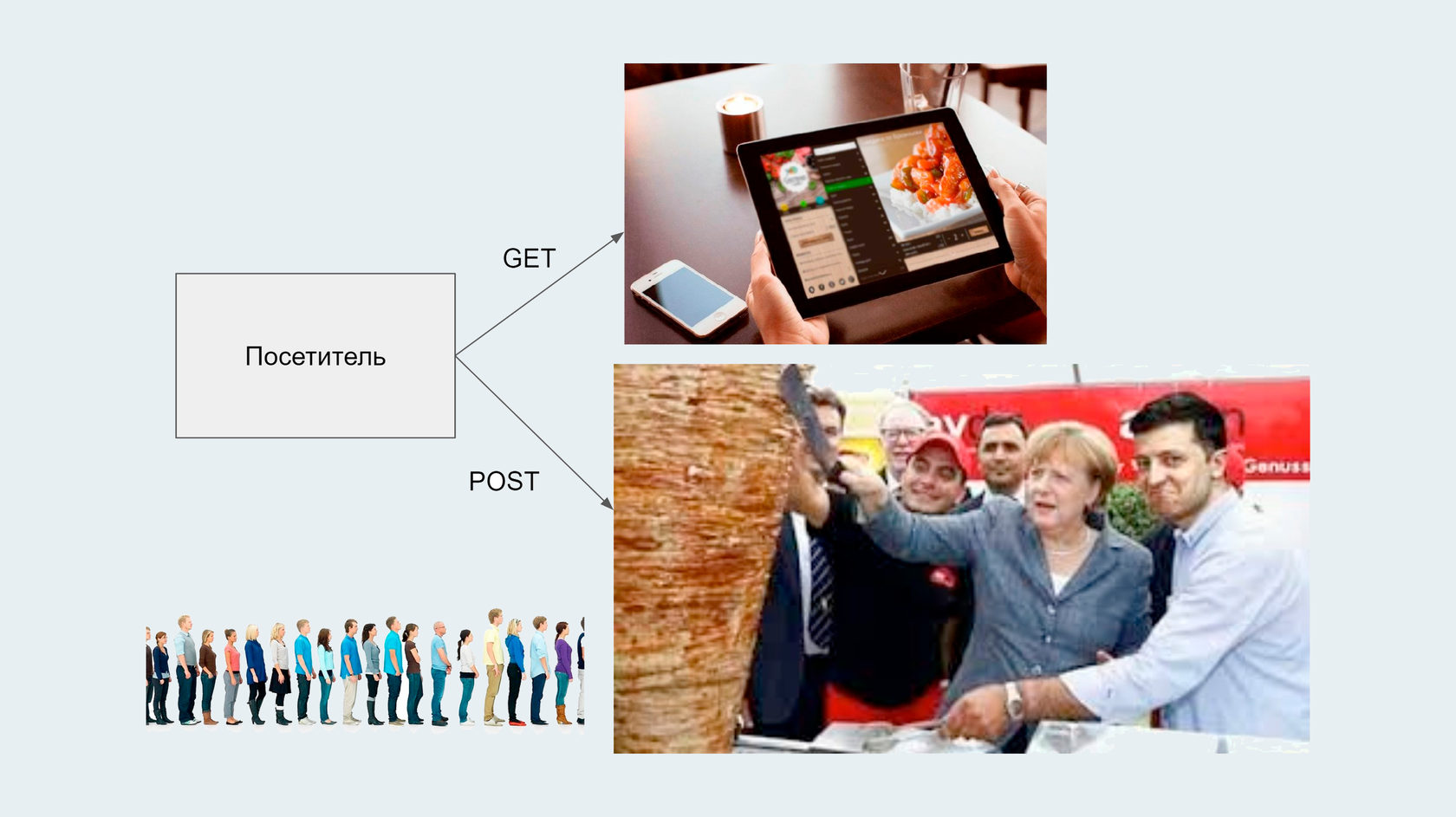
Другой способ: пригласить друзей и начать готовить шаурму вместе, но тогда у нас возникают новые проблемы. Всё потому, что очередью никто не управляет.
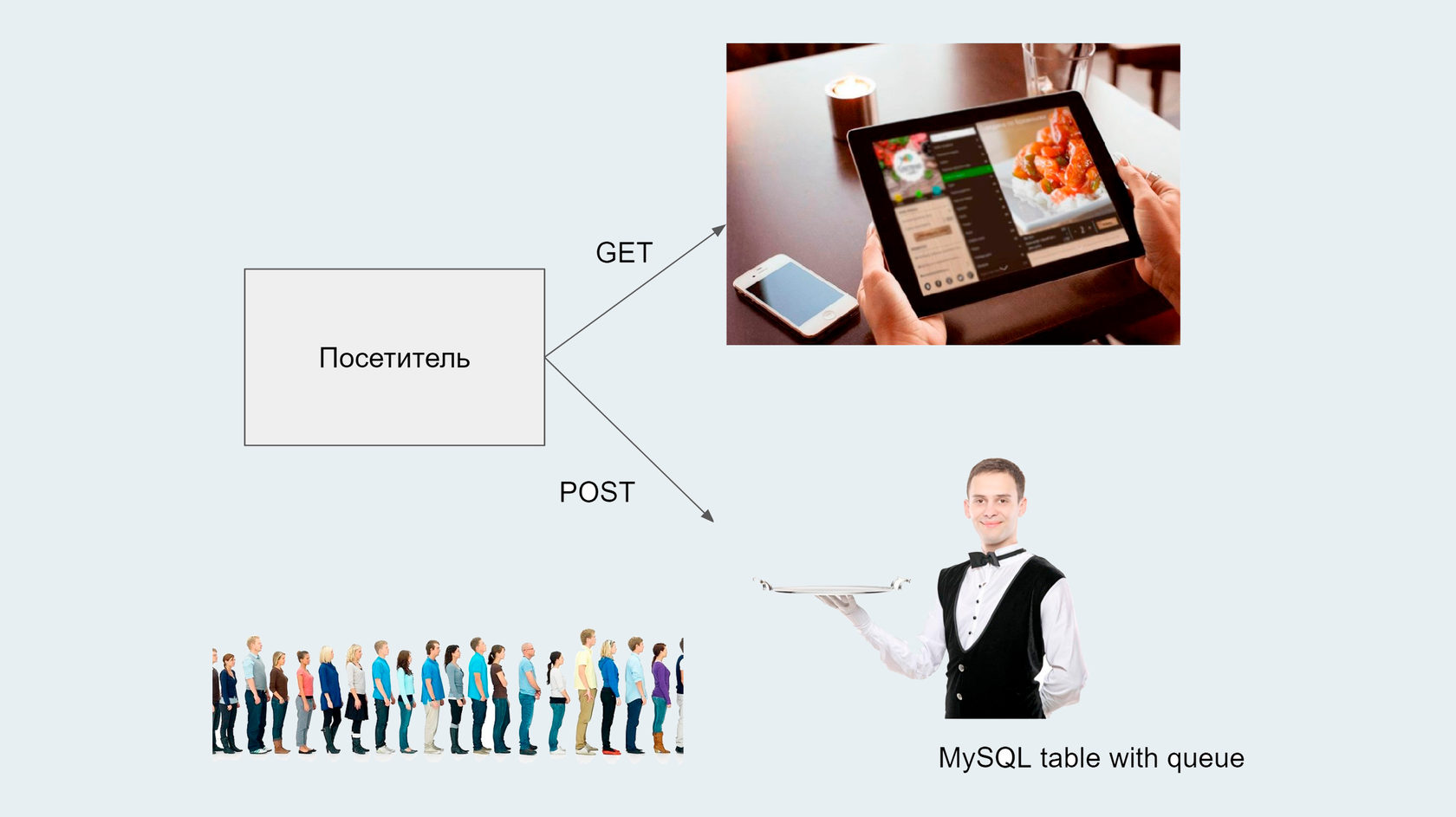
Когда к нам поступает много параллельных заказов и мы не знаем, кто за какой заказ будет отвечать, нам нужен менеджер, который эту очередь заказов распределит по исполнителям.
Если этого не сделать, у нас появляются следующие риски:
- потерять заказ;
- взяться за один заказ нескольким людям одновременно или, наоборот, не взяться вообще;
- заказчик уйдёт, а мы продолжим делать шаурму, за которую никто не заплатит;
- если один и тот же исполнитель и готовит, и принимает оплату, ему придётся слишком часто снимать перчатки, из-за чего будет тратиться слишком много времени, и так далее.
Самое простое — поставить над всеми исполнителями старшего официанта, менеджера, кипера, который будет распределять заказы. Если так сделать, то до поры до времени всё будет идти вполне неплохо.
очевидно, что мы не блокируем содержимое, т. е. несколько работников (исполнителей) могут взяться за один и тот же заказ;
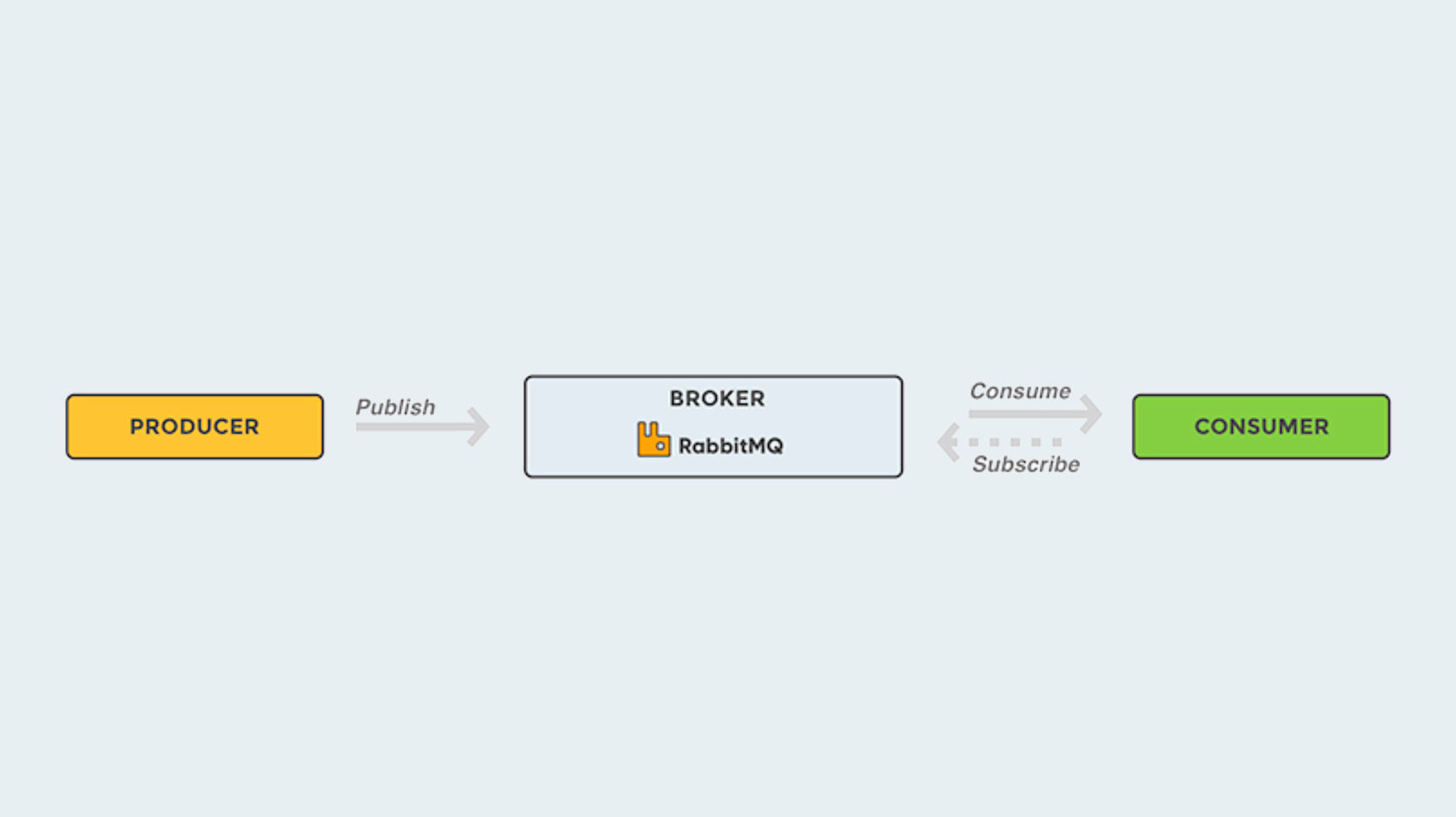
Посмотрим, что предлагается в коробке большинства брокеров (и в RabbitMQ тоже), на примере решаемой задачи.
Если повар, скажем, отошёл или сломал руку, заказ остаётся в очереди. Этот повар может взять заказ позже, или его может взять другой повар.
Реализация брокера очередей в виде RabbitMQ
Плавно переходим к реализации брокера очередей в виде RabbitMQ. Это гибридный брокер, он поддерживает несколько протоколов.
Сегодня наиболее распространённый протокол — это AMQP. О нём по большей части и будем вести речь.

Если смотреть принципиально (сверху), то AMQP-протокол вообще и RabbitMQ в частности представляют собой следующую модель.
Самый банальный пример такой модели — создание PDF.

direct — полное совпадение ключа. Мы можем создать очередь для одного ключа, очередь для другого; у очереди может быть несколько ключей — всё как в обычном STP-роутинге;
headers — мы имеем возможность указать какой-то тип прямо в message и роутиться по нему (используется, когда нет отдельного ключа).

Какие фишки подразумеваются в очереди и уже реализованы в Rabbit'е

Есть несколько режимов создания дампов.
Кейс: актуальные варианты использования ACK.
В общем и целом это работает примерно таким образом.

У нас есть exchanges разных типов. Ниже представлены примеры, в каких случаях они могут быть использованы.
Чтобы начать работать с Rabbit, нам не нужно никаких суперприблуд, нужен банальный composer. Пуллим из Docker образ и запускаем его. Советую пуллить по тегу 3-management. По этому тегу будет доступен крайний стабильный релиз RabbitMQ; приписка management означает, что он будет поставлен вместе с панелью администрирования в виде Web UI (пользовательский интерфейс, представленный в виде сайта, который запускается в web-браузере).


Это очень удобно, примерно как MySQL сразу с phpMyAdmin. Соответственно, здесь мы можем увидеть сразу все наши очереди (queues), все наши соединения с RabbitMQ (connections), каналы (channels), обменники (exchanges) — в общем, всю информацию подробно.

В PHP всё подключается довольно просто. При создании соединения мы всегда должны указывать параметры, поэтому держать отдельный instance, который будет задавать параметры конфига в Rabbit, нет смысла. Если такой очереди, или такого обменника, или чего-то ещё не было раньше, мы всегда создаём их заново, а RabbitMQ у нас крутится постоянно, т. е. он работает персистентно. У нас есть название exchange, название очереди, мы создаём коннект на наш хост, порт, используем данные авторизации — и открывается канал для работы по этому соединению.
Чтобы создать новую очередь, есть простейшая функция queue_declare, где мы указываем:
passive: true или false (обычно false; true используется, если нужно обратиться к очереди, не изменяя её состояния, т. е., например, просто проверить, что она существует);
durable: true или false (будет ли данный юнит выживать при рестарте сервера, хранится ли он на диске или нет — the queue will survive server restarts);
exclusive: true или false (может ли быть доступна очередь из других каналов — мы можем ограничить очередь в рамках одного соединения, но это очень редко используемый кейс, обычно exclusive: false);
Вот и все настройки очереди.
После настройки очереди нам необходимо сделать собственно exchange (точку роутинга) и привязать его к какой-то из очередей (сделать binding).

- type (всего четыре типа, о которых мы уже говорили ранее);
- passive;
- durable (будем ли хранить юнит при рестарте);
- auto_delete (очищается ли очередь, когда соединение закрывается).


Первый параметр — очередь.

Здесь register_shutdown_function — стандартная функция PHP, в которой мы можем обозначить callback-функцию (например shutdown), которая будет выполнена по окончании работы скрипта. Когда скрипт заканчивает работу, нам всегда лучше закрывать соединения. Соответственно, мы регистрируем функцию, которая будет выполняться при завершении скрипта — в нашем примере это функция shutdown с аргументами channel и connection.


Но бывает, что вернуть ответ клиентскому приложению сразу невозможно. Например, когда сервер обрабатывает видео — это может занять минуты и даже часы. На время обработки большого объема данных вычислительные ресурсы сервера загружены и его способность обрабатывать входящие запросы падает.
Допустим, серверное приложение получило тяжелый запрос. Оно передает его другим приложениям дальше по цепочке, а само продолжает общение с клиентом.
Когда в вашем бэкенд-приложении задействованы очереди, обработка видео выглядит так:
FIFO и LIFO (ФИФО и ЛИФО) — что это такое
Для серверных приложений наиболее востребованы очереди (метод FIFO), но большинство сервисов для организации очередей могут работать и в режиме стека (LIFO).
RabbitMQ
Apache Kafka
Redis
Redis создавалась как система хранения данных в оперативной памяти. Изначальное предназначение — ускорение доступа к востребованной информации и построение систем кеширования.
Но бывает, что вернуть ответ клиентскому приложению сразу невозможно. Например, когда сервер обрабатывает видео — это может занять минуты и даже часы. На время обработки большого объема данных вычислительные ресурсы сервера загружены и его способность обрабатывать входящие запросы падает.
Допустим, серверное приложение получило тяжелый запрос. Оно передает его другим приложениям дальше по цепочке, а само продолжает общение с клиентом.
Когда в вашем бэкенд-приложении задействованы очереди, обработка видео выглядит так:
FIFO и LIFO (ФИФО и ЛИФО) — что это такое
Для серверных приложений наиболее востребованы очереди (метод FIFO), но большинство сервисов для организации очередей могут работать и в режиме стека (LIFO).
RabbitMQ
Apache Kafka
Redis
Redis создавалась как система хранения данных в оперативной памяти. Изначальное предназначение — ускорение доступа к востребованной информации и построение систем кеширования.
Внедрение сервисов очередей положительно влияет на скорость, масштабируемость и отказоустойчивость систем. Без таких решений невозможно построить надежную распределенную архитектуру.
Читайте также: