
Есть сообщение с заданным распределением частот таблица закодировать по коду фано
Обновлено: 19.05.2024
Построение кодов Хаффмана для последовательности символов.
В принципе уже есть калькулятор Код Хаффмана, который рассчитывает коды Хаффмана для заданной вероятности символов, однако, как показала практика, студентам задания формируют в виде
Дана строка:beadbdddbaddaecbde. Определить коды встречающихся букв (код Хаффмана). Закодировать исходную строку построенным кодом.
В принципе, всё, что нужно для использования калькулятора по ссылке выше, это по строке составить таблицу встречаемости символов, и внести эту таблицу в калькулятор. Ну то есть, если взять процитированный пример, надо посчитать банально, сколько раз встречается символ b, символ e, символ a, символ d и символ c. Однако мне не жалко, я могу и код написать, который это сделает за студента. Ну в самом деле, вдруг человек ошибется, не так посчитает, или там пропустит пару букв.
В общем, в калькулятор ниже вводите свою строку - получаете ту же строку, но закодированную кодом Хаффмана и таблицу символов: сколько раз встретился символ в строке, какую частоту это дает в процентах от общего количества символов и код Хаффмана для каждого символа.
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем.
Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий.
Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
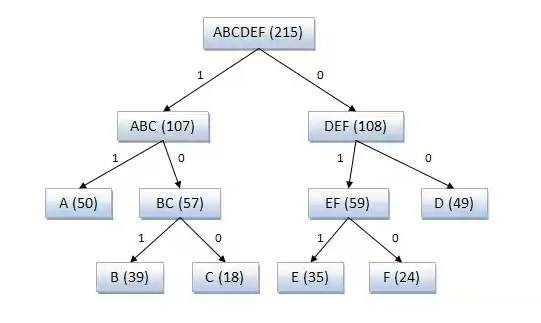
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона-Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Пример 1. Закодируем буквы алфавита в коде Шеннона-Фано.
Пусть имеется случайная величина X (x1, x2, x3, x4, x5, x6, x7, x8), имеющая восемь состояний с распределением вероятностей
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
Определив избыточность L по формуле L=1-H/H0=1-2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
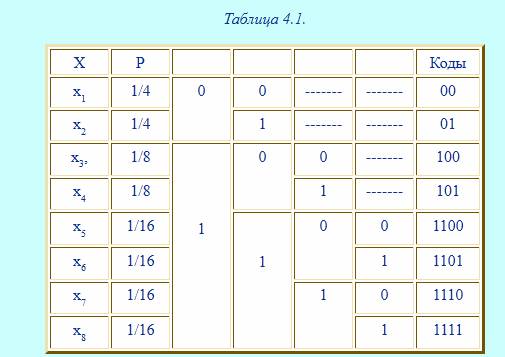
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
| X | P | Коды | |
| x1 | 1/4 | ------- | ------- |
| x2 | 1/4 | ------- | ------- |
| x3, | 1/8 | ------- | |
| x4 | 1/8 | ------- | |
| x5 | 1/16 | ||
| x6 | 1/16 | ||
| x7 | 1/16 | ||
| x8 | 1/16 |
Средняя длина полученного кода будет равна
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице
| Буква | Рi | Код | ||
| ? | 0.145 | - | ||
| о | 0.095 | - | ||
| е | 0.074 | |||
| а | 0.064 | |||
| и | 0.064 | |||
| н | 0.056 | |||
| т | 0.056 | … | … | - |
| с | 0.047 | … | … | |
| . | … | |||
| ф | 0.03 |
Средняя длина данного кода будет равна, бит/букву;
Энтропия H=4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины , то эффективность была бы значительно ниже.

Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем.
Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий.
Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона-Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Пример 1. Закодируем буквы алфавита в коде Шеннона-Фано.
Пусть имеется случайная величина X (x1, x2, x3, x4, x5, x6, x7, x8), имеющая восемь состояний с распределением вероятностей
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
Определив избыточность L по формуле L=1-H/H0=1-2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
| X | P | Коды | |
| x1 | 1/4 | ------- | ------- |
| x2 | 1/4 | ------- | ------- |
| x3, | 1/8 | ------- | |
| x4 | 1/8 | ------- | |
| x5 | 1/16 | ||
| x6 | 1/16 | ||
| x7 | 1/16 | ||
| x8 | 1/16 |
Средняя длина полученного кода будет равна
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице
| Буква | Рi | Код | ||
| ? | 0.145 | - | ||
| о | 0.095 | - | ||
| е | 0.074 | |||
| а | 0.064 | |||
| и | 0.064 | |||
| н | 0.056 | |||
| т | 0.056 | … | … | - |
| с | 0.047 | … | … | |
| . | … | |||
| ф | 0.03 |
Средняя длина данного кода будет равна, бит/букву;
Энтропия H=4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины , то эффективность была бы значительно ниже.
Вы вероятно слышали о Дэвиде Хаффмане и его популярном алгоритме сжатия. Если нет, то поищите информацию в интернете — в этой статье я не буду вас грузить историей или математикой. Сегодня я хочу просто попытаться показать вам практический пример применения алгоритма к символьной строке.
Примечание переводчика: под символом автор подразумевает некий повторяющийся элемент исходной строки — это может быть как печатный знак (character), так и любая битовая последовательность. Под кодом подразумевается не ASCII или UTF-8 код символа, а кодирующая последовательность битов.
К статье прикреплён исходный код, который наглядно демонстрирует, как работает алгоритм Хаффмана — он предназначен для людей, которые плохо понимают математику процесса. В будущем (я надеюсь) я напишу статью, в которой мы поговорим о применении алгоритма к любым файлам для их сжатия (то есть, сделаем простой архиватор типа WinRAR или WinZIP).
Идея, положенная в основу кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код. Это нужно, так как мы хотим, чтобы, когда мы обработали весь ввод, самые частотные символы заняли меньше всего места (и меньше, чем они занимали в оригинале), а самые редкие — побольше (но так как они редкие, это не имеет значения). Для нашей программы я решил, что символ будет иметь длину 8 бит, то есть, будет соответствовать печатному знаку.
Мы могли бы с той же простотой взять символ длиной в 16 бит (то есть, состоящий из двух печатных знаков), равно как и 10 бит, 20 и так далее. Размер символа выбирается, исходя из строки ввода, которую мы ожидаем встретить. Например, если бы я собрался кодировать сырые видеофайлы, я бы приравнял размер символа к размеру пикселя. Помните, что при уменьшении или увеличении размера символа меняется и размер кода для каждого символа, потому что чем больше размер, тем больше символов можно закодировать этим размером кода. Комбинаций нулей и единичек, подходящих для восьми бит, меньше, чем для шестнадцати. Поэтому вы должны подобрать размер символа, исходя из того по какому принципу данные повторяются в вашей последовательности.
Для этого алгоритма вам потребуется минимальное понимание устройства бинарного дерева и очереди с приоритетами. В исходном коде я использовал код очереди с приоритетами из моей предыдущей статьи.
Чтобы построить дерево, мы воспользуемся слегка модифицированной очередью с приоритетами — первыми из неё будут извлекаться элементы с наименьшим приоритетом, а не наибольшим. Это нужно, чтобы строить дерево от листьев к корню.
Для начала посчитаем частоты всех символов:
| Символ | Частота |
|---|---|
| 'b' | 3 |
| 'e' | 4 |
| 'p' | 2 |
| ' ' | 2 |
| 'o' | 2 |
| 'r' | 1 |
| '!' | 1 |

После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета:
Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.
Повторим те же шаги и получим последовательно:

Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево:

Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:
Если мы так сделаем, то получим следующие коды для символов:
| Символ | Код |
|---|---|
| 'b' | 00 |
| 'e' | 11 |
| 'p' | 101 |
| ' ' | 011 |
| 'o' | 010 |
| 'r' | 1000 |
| '!' | 1001 |
Важно иметь в виду, что каждый код не является префиксом для кода другого символа. В нашем примере, если 00 — это код для 'b', то 000 не может оказаться чьим-либо кодом, потому что иначе мы получим конфликт. Мы никогда не достигли бы этого символа в дереве, так как останавливались бы ещё на 'b'.
На практике, при реализации данного алгоритма сразу после построения дерева строится таблица Хаффмана. Данная таблица — это по сути связный список или массив, который содержит каждый символ и его код, потому что это делает кодирование более эффективным. Довольно затратно каждый раз искать символ и одновременно вычислять его код, так как мы не знаем, где он находится, и придётся обходить всё дерево целиком. Как правило, для кодирования используется таблица Хаффмана, а для декодирования — дерево Хаффмана.
Приложенный исходный код работает по тому же принципу, что и описан выше. В коде можно найти больше деталей и комментариев.
Все исходники были откомпилированы и проверены с использованием стандарта C99. Удачного программирования!
Оптимальное кодирование
Пусть имеется случайная величина X ( x 1 , x 2 , x 3 , x 4 , x 5 , x 6 , x 7 , x 8 ), имеющая восемь состояний с распределением вероятностей
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
Определив избыточность L по формуле L =1- H / H 0 =1 - 2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
Возникает вопрос: возможно ли составить код, в котором на одну букву будет, в среднем приходится меньше элементарных символов.
Такие коды существуют. Это коды Шеннона - Фано и Хаффмана.
Принцип построения оптимальных кодов:
1. Каждый элементарный символ должен переносить максимальное количество информации, для этого необходимо, чтобы элементарные символы (0 и 1) в закодированном тексте встречались в среднем одинаково часто. Энтропия в этом случае будет максимальной.
2. Необходимо буквам первичного алфавита, имеющим большую вероятность, присваивать более короткие кодовые слова вторичного алфавита.
Код Шеннона-Фано
Пример 2 . Закодируем буквы алфавита из примера 1 в коде Шеннона - Фано.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
Средняя длина полученного кода будет равна
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице 4.2.

Средняя длина данного кода будет равна, бит/букву;
Энтропия H =4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины , то эффективность была бы значительно ниже.
Читайте также: