
Языки искусственного интеллекта реферат
Обновлено: 07.07.2024
Тема языковой проблемы искусственного интеллекта широко раскрывается в статье Уилла Найта, главного редактора AI MIT Technology Review, которую специалисты PayOnline, системы автоматизации приема онлайн-платежей, старательно перевели для пользователей Хабрахабра. Ниже представляем сам перевод.
Примерно в середине крайне напряженной игры в Го, проходившей в южнокорейском Сеуле, участниками которой были один из лучших игроков всех времен Ли Седоль и созданный Google искусственный интеллект под названием AlphaGo, программа сделала загадочный шаг, продемонстрировавший пугающее преимущество над своим человеческим оппонентом.
На 37 шаге AlphaGo решила поставить черный камень в нелепое, на первый взгляд, положение. Казалось, что этот ход, больше похожий на характерную ошибку новичка, наверняка приведет к сдаче существенной части игрового поля, тогд как суть игры, напротив, заключается в контроле игрового пространства. Телевизионные комментаторы гадали в чем же дело: то ли это они не поняли хода машины, то ли у нее произошел какой-то сбой. На самом деле, вопреки всеобщему представлению, ход номер 37 позволил AlphaGo создать сильную позицию в центре доски. Программа Google одержала убедительную победу, совершив ход, который, на ее месте не сделал бы ни один человек.
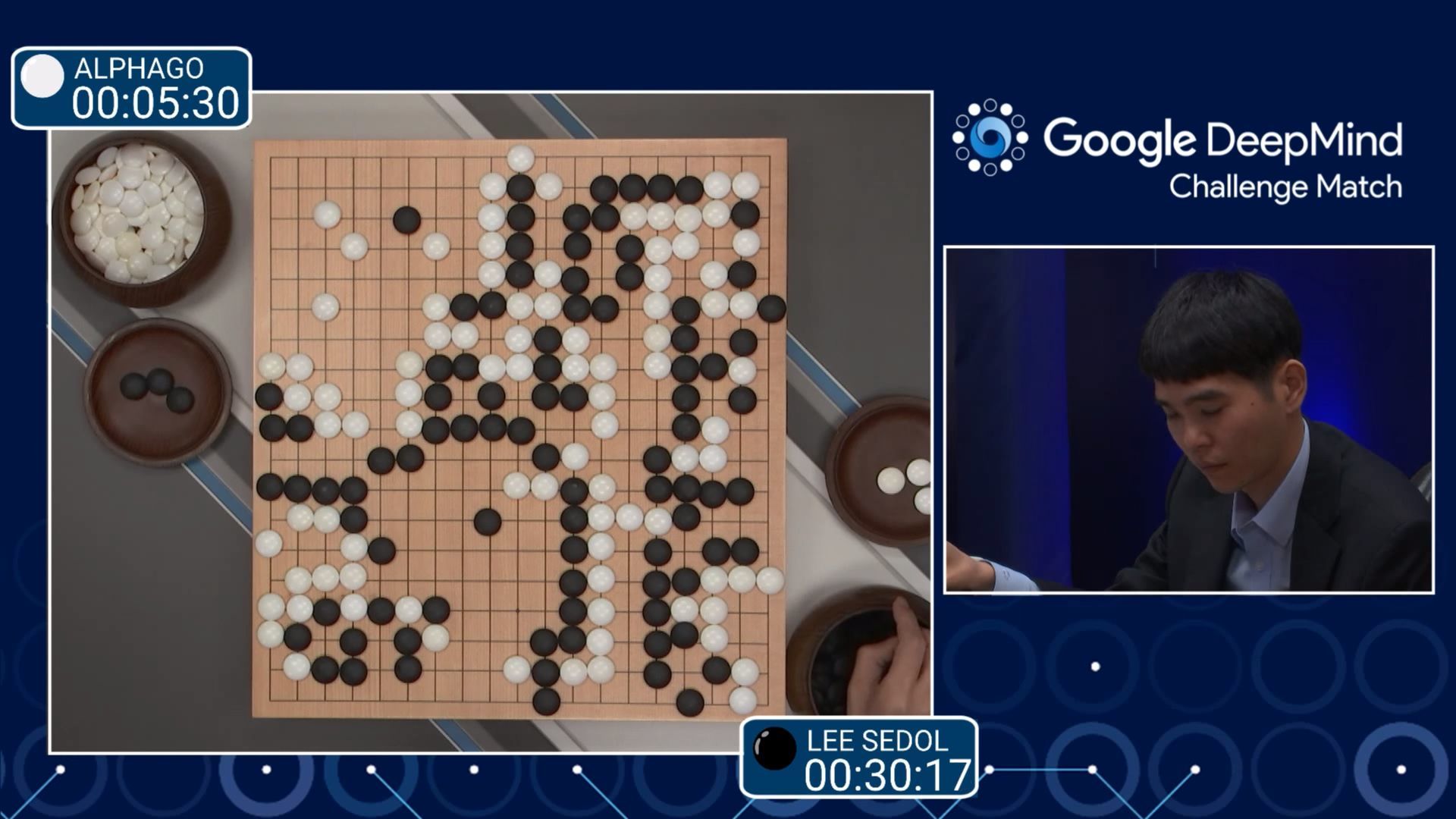
Победа AlphaGo выглядит особенно впечатляюще, поскольку многие считают древнюю игру в Го хорошей проверкой на развитость интуитивного интеллекта. Ее правила крайне просты: два игрока по очереди расставляют черные и белые камни на пересечениях вертикальных и горизонтальных линий доски, пытаясь окружить камни оппонента и тем самым исключить их из игры. Несмотря на эту простоту, хорошая игра в Го требует немалых умственных усилий.

A Rubber Ball Thrown on the Sea — Лоуренс Вайнер, 1970 / 2014
Одна из причин, по которым понимание языка так трудно дается компьютерам и программам искусственного интеллекта заключается в том, что значения слов часто зависят от контекста и даже внешнего вида отдельных букв и слов. Эта статья сопровождается серией изображений, авторы которых продемонстрировали примеры использования различных визуальных образов, общий смысл которых выходит далеко за рамки значения использованных в них букв.
Но несмотря на этот впечатляющий прогресс, существует одна фундаментальная область знаний, судьба которой в контексте ИИ остается неясной: языковое знание. Системы вроде Siri или IBM Watson могут следовать простым воспроизведенным вслух или на письме командам и отвечать на элементарные вопросы, однако они не способны поддерживать беседу и не понимают реального смысла слов, которые используют. Если мы хотим по-настоящему ощутить на себе весь преобразовательный потенциал ИИ, ситуация в этой области должна измениться.
Несмотря на то, что AlphaGo не умеет разговаривать, он содержит в себе технологию, которая может вывести машинное понимание языка на более высокий уровень. В стенах таких компаний, как Google, Facebook и Amazon, а также лидирующих академических лабораториях по изучению ИИ, исследователи предпринимают попытки полноценного решения задачи, которая кажется неразрешимой. Среди применяемых ими разработок есть глубинное обучение и некоторые другие ИИ-инструменты, обеспечившие успех AlphaGo и общее возрождение интереса к ИИ. Успешность их работы позволит осознать масштаб и характер явления, определяемого как революция искусственного интеллекта. От результатов их деятельности также будет зависеть и то, насколько коммуникабельными будут машины будущего и смогут ли они стать близкими друзьями людей в их повседневной жизни, или так и останутся загадочными черными ящиками, стремящимися к еще большей автономности.
Возможно, те же методы, которые позволили AlphaGo завоевать первенство в Го однажды позволят компьютерам овладеть языком, а может быть, для этого потребуется нечто большее. В любом случае, если программы искусственного интеллекта не научатся понимать язык, воздействие, которое ИИ окажет на общество, будет иным. Конечно, у нас в распоряжении по-прежнему будут невероятно мощные и умные программы, такие как AlphaGo. Однако наши отношения с ИИ, вероятно, будут характеризоваться гораздо меньшей степенью сотрудничества и дружественности.
Заклинатели машин
Через несколько месяцев после триумфа AlphaGo я отправился в Кремниевую долину — самое сердце последнего бума в сфере искусственного интеллекта. Мне хотелось нанести визит исследователям, добившимся заметного прогресса в области практического применения ИИ и прямо сейчас пытающимся вывести машины на более высокий уровень понимания языка.
Я начал с Винограда, который живет в окрестностях Пало-Альто, прямо у южной части стэндфордского кампуса, неподалеку от штаб-квартиры Google, Facebook и Apple. Кучерявые белые волосы и густые усы делают его еще более похожим на авторитетного академика, излучающего к тому же заразительный энтузиазм.
В далекий 1968 год Виноград предпринял одну из самых первых попыток научить машину разумному разговору. Будучи одаренным математиком и очарованным языкознаниями ученым, он оказался в новой лаборатории MIT по изучению искусственного интеллекта с целью написания докторской работы и решил разработать программу, способную вести текстовые беседы с людьми на языке повседневного общения. В то время эта задача не казалась чересчур амбициозной. Область ИИ развивалась семимильными шагами, а другие сотрудники MIT работали над созданием сложных систем машинного зрения и футуристическими роботизированными манипуляторами.

Four Colors Four Words — Джозеф Кошут, 1966
И все же далеко не все были убеждены в том, что освоение языка — простая задача. Некоторые критики, включая влиятельного лингвиста и профессора MIT Ноама Чомски, полагали, что в своих попытках научить машины понимать человеческий язык исследователи ИИ неизбежно столкнутся с проблемами, просто потому, что механика человеческого языка тогда была изучена слабо. Виноград вспоминает даже, как однажды на вечеринке один из студентов Чомски прекратил с ним общение, едва услышав, что тот работает в лаборатории ИИ.
SHRDLU всюду демонстрировали как один из символов фундаментального прогресса в области ИИ. Но это была только иллюзия. Когда Виноград попытался расширить блочный мир программы, то правила, необходимые для учета используемых слов и грамматических связей, стали слишком громоздкими и неуправляемыми. Несколькими годами позже он прекратил работу над программой и, в конечном счете, бросил и работу с ИИ для того, чтобы сосредоточиться на других областях исследований.

Pure Beauty — Джон Балдессари, 1966-68
Но даже в то время, пока Дрейфус развивал свою теорию, группа исследователей работала над подходом, который, в конечном счете, должен был наделить машины как раз таким типом мышления. Почерпнув немного вдохновения из открытий нейронауки, они экспериментировали с искусственными нейронными сетями — слоями математически симулированных нейронов, которые можно было приучить к активации в ответ на определенные входящие данные. Первые подобные системы были ужасно медленными, и от подхода отказались в силу непрактичности его логического аппарата. Крайне важно, однако, отметить, что нейронные сети могли обучаться такому поведению, запрограммировать которое заранее было невозможно, и позже этот навык оказался очень полезен для решения простых задач, таких, как распознание рукописных символов. Работа в этом направлении приобрела коммерческий характер в 90-х, когда стала использоваться для чтения цифр на чеках. Сторонники подхода были убеждены, что нейронные сети, в конечном счете, позволят машинам показывать гораздо более значимые результаты, чем то, что они могли в те годы. В один прекрасный день, заявляли они, технологии смогут даже понимать язык.
На протяжении последних нескольких лет нейронные сети стали во много раз сложнее и эффективнее. Подход был усилен благодаря успехам в области математики и, что важно, появлению более быстрого компьютерного оборудования и доступности огромного количества данных. К 2009 году исследователи из Университета Торонто показали, что многослойная сеть глубинного обучения способна распознавать речь с рекордной точностью. А в 2012 году эта же группа ученых выиграла конкурс по машинному зрению, представив невероятно точный алгоритм глубинного обучения.
Попытки применить глубинное обучение к языкам сталкиваются с очевидной проблемой, суть которой заключается в том, что слова — это условные символы и в этом отношении они принципиально отличаются от художественных образов. Два слова, например, могут быть похожи по значению и состоять при этом из совершенно разных букв, а одно и то же слово в разных контекстах может обозначать совершенно разные вещи.
Совместное применение двух таких сетей делает возможным высококачественный перевод между двумя языками, а объединение этого типа сети с другим, способным распознавать объекты изображений, позволяет составлять на удивление правдоподобные сопроводительные подписи к ним.
Смысл жизни
Сидя в конференц-зале, расположенном в самом сердце гудящей как улей штаб-квартиры Google в калифорнийском Маунтин-Вью, Квок Ли, один из исследователей компании, участвовавший в разработке ее новейших ИИ-решений, рассуждает над идеей машины, способной поддерживать настоящую беседу. Амбиции Ли направлены на получение полезных результатов, которые можно будеет использовать в разработке разговаривающих машин.

The Answer/Wasn’t Here II — Тауба Ауербах, 2008
По любопытному стечению обстоятельств, ближайший сосед Терри Винограда в Пало-Альто оказался человеком, который также может помочь компьютерам получить более глубокое понимание истинного значения слов. В момент моего визита Фей-фей Ли, директор стэндфордской лаборатории искусственного интеллекта, была в декретном отпуске, однако она пригласила меня к себе домой и с гордостью представила своей очаровательной трехмесячной малышке по имени Феникс.
Этот подход близок к тому, как познают окружающий мир дети, постоянно ассоциирующие слова с объектами, отношениями и действиями. Однако на этом аналогия с человеческим обучением заканчивается. Маленьким детям не нужно видеть собаку верхом на скейтборде, чтобы представить ее в уме или описать при помощи слов. Фей-фей Ли считает, что современного машинного обучения и ИИ-инструментов недостаточно, чтобы воплотить в жизнь мечту о настоящем ИИ. По мнению ученой, исследователям ИИ также придется подумать над учетом таких аспектов, как эмоциональный интеллект и навыки социального общения.
Никто не знает, как дать машинам эти человеческие навыки, если, конечно, это вообще возможно. Быть может, в этих качествах есть нечто, присущее только людям, что делает их недосягаемыми для ИИ?
Современные ученые-когнитивисты, такие как Таненбаум из MIT, в своих теориях высказывают идею о том, что всем современным нейронным сетям, сколь большими и сложными они ни были, не хватает многих других важных компонентов разума. Люди обладают способностью обучаться очень быстро на основе относительно небольшого количества данных и имеют встроенную способность эффективно создавать в уме трехмерную модель мира.
Если он прав, то создать языковое понимание в машинах и ИИ без попытки воспроизвести человеческое обучение, способы восприятия окружающего мира и психологии будет невозможно.
Объясни, что ты имеешь в виду
Офис Ноя Гудмана на стэндфордской кафедре психологии практически пуст, не считая пары абстрактных картин, прислоненных к одной из стен и нескольких заросших растений. Когда я приехал, Гудман увлеченно печатал что-то, сидя за своим ноутбуком и положив голые ноги на стол. Мы прогулялись через залитый солнцем кампус.
И все же, несмотря на сложность и многомерность этой задачи, начальный успех исследователей в использовании техник глубинного обучения для распознания изображений и обучении машин играм, таким как Го, по крайней мере дает надежу на то, что мы, возможно, стоим на пороге прорыва и в области языков. Если это так, эти успехи пришлись как нельзя кстати.
Если ИИ и суждено стать вездесущим инструментом, который люди будут использовать для преобразования собственного интеллекта, и которому они будут доверять решение задач в рамках тесного сотрудничества, язык должен стать ключом для этих взаимоотношений. Особую актуальность эта потребность приобретает в свете того, что глубинное обучение и другие техники, в сущности, позволяют программам искусственного интеллекта программировать самих себя.
Toyota, изучающая широкий спектр технологий автоматизированного вождения, инициировала исследовательский проект в MIT под руководством Джеральда Сассмана, эксперта по искусственному интеллекту и языковому программированию. Цель проекта — разработка автоматизированной системы вождения, способной объяснить, почему она совершила то или иное действие. Вполне очевидный способ объяснения в данном контексте — разговор робота с водителем.
Поэтому машина в некотором роде знала, что Седоль будет совершенно ошеломлен таким ходом.
По словам Сильвера, Google рассматривает некоторые варианты коммерческого применения технологии, включая разработку интеллектуального помощника и инструмента для сферы здравоохранения. После конференции я спросил его о важности общения с ИИ, лежащего в основе этих систем.
Продолжайте следить за обновлениями блога международной процессинговой компании PayOnline и первыми читайте переводы самых интересных материалов зарубежных изданий о технологиях.
Вы можете изучить и скачать доклад-презентацию на тему Языки искусственного интеллекта. Презентация на заданную тему содержит 13 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас - поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!












Алан Тьюринг , основатель информатики, был одним из первых, кто принимал развитие искусственного интеллекта (ИИ) всерьез и знал, что в один прекрасный день машины смогут думать так же, как люди. Он предложил простой тест: если человек во время беседы не сможет отличить машину от человека, значит, машина достигла уровня интеллекта человека. Другими словами, если она может думать, как человек, значит, она может обрабатывать язык, как человек. Алан Тьюринг , основатель информатики, был одним из первых, кто принимал развитие искусственного интеллекта (ИИ) всерьез и знал, что в один прекрасный день машины смогут думать так же, как люди. Он предложил простой тест: если человек во время беседы не сможет отличить машину от человека, значит, машина достигла уровня интеллекта человека. Другими словами, если она может думать, как человек, значит, она может обрабатывать язык, как человек.
С появлением Siri компании Google и Cortana надеялись, что эра, о которой говорил Тьюринг, наступила, но пока обе программы способны распознавать и отвечать лишь на простые вопросы С появлением Siri компании Google и Cortana надеялись, что эра, о которой говорил Тьюринг, наступила, но пока обе программы способны распознавать и отвечать лишь на простые вопросы
Главными проблемами, решаемыми в рамках ИИ, являются: Главными проблемами, решаемыми в рамках ИИ, являются: построение экспертных систем, решение задач поиска, в которых полный перебор вариантов теоретически невозможен (в том числе - программирование игр), моделирование биологических форм, распознавание образов
Типы ии Искусственный интеллект узкой направленности Общий искусственный интеллект Искусственный суперинтеллект
Одним из самых ярких примеров обработки естественного языка является функция спонтанного перевода, запущенная Microsoft в Skype Одним из самых ярких примеров обработки естественного языка является функция спонтанного перевода, запущенная Microsoft в Skype
Языки программирования ии В начале семидесятых годов были созданы два специфических языка программирования – Пролог (Prolog) и Лисп (LISP).
Язык программирования LISP LISP был придуман Джоном Маккарти в 1958 году для решения задач нечислового характера. Долгое время LISP использовался исключительно узким кругом специалистов по искусственному интеллекту. Но, начиная с 80-х годов прошлого века, LISP начал набирать обороты и сейчас активно используется, например, в AutoCad и Emacs.
Пример программы на LISP Давайте напишем программу сложения: 2 + 3 Исходный код: (+ 2 3) После нажатия Enter выведется ответ: 5. Или пример посложнее: (2 + 2) * (11 - 1) Код: ( * ( + 2 2) ( - 11 1)) Вывод: 40
Язык программирования Пролог Этот язык логического программирования предназначен для представления и использования знаний о некоторой предметной области. Программы на этом языке состоят из некоторого множества отношений, а ее выполнение сводится к выводу нового отношения на основе заданных. В Прологе реализован декларативный подход, при котором достаточно описать задачу с помощью правил и утверждений относительно заданных объектов. Если это описание является достаточно точным, то ЭВМ может самостоятельно найти требуемое решение.
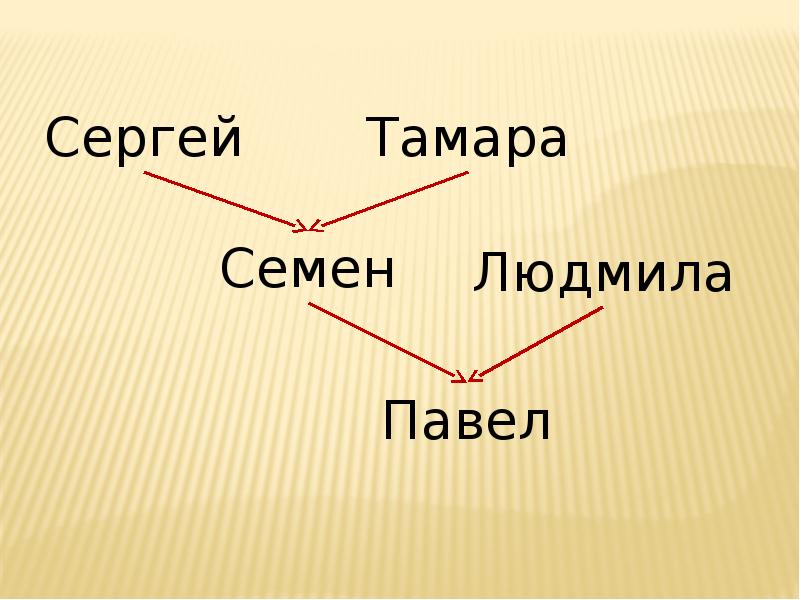
Пример программы на Prolog В качестве исходных выберем отношение родитель(X,Y), обозначающее, что X является родителем Y, и отношения мужчина(X) и женщина (X), обозначающие принадлежность лица к одному из полов. Тогда исходные данные для программы могут выглядеть примерно так. мужчина(Сергей). женщина(Тамара). мужчина(Семен). женщина (Людмила). мужчина(Павел). родитель(Сергей, Семен). родитель(Тамара, Семен). родитель(Семен, Павел). родитель(Людмила, Павел)
Теперь введем выражение дед(X,Y), обозначающее, является ли X дедом Y. Мы используем два Прологовских символа – запятая в следующей записи обозначает логическое И, а символ :- обозначает ЕСЛИ. Теперь введем выражение дед(X,Y), обозначающее, является ли X дедом Y. Мы используем два Прологовских символа – запятая в следующей записи обозначает логическое И, а символ :- обозначает ЕСЛИ. дед(X,Y):- родитель(X,Z),родитель(Z,Y),мужчина(X). После запуска ее на выполнение Пролог-система выдаст запрос на ввод вопроса. Для начала введем дед(X,Павел) (по-русски этот вопрос звучит так: "Кто дед Павла?"), система выдаст X=Сергей. Теперь спросим дед(Тамара, Павел) ("Является ли Тамара дедом Павла?"). Получим ответ no (нет).
Это прежде всего Лисп (LISP) и Пролог (Prolog) [8] – наиболее распространенные языки, предназначенные для решения задач искусственного интеллекта. Есть и менее распространенные языки искусственного интеллекта, например РЕФАЛ, разработанный в России. Универсальность этих языков меньшая, нежели традиционных языков, но ее потерю языки искусственного интеллекта компенсируют богатыми возможностями по работе с символьными и логическими данными, что крайне важно для задач искусственного интеллекта. На основе языков искусственного интеллекта создаются специализированные компьютеры (например, Лисп-машины), предназначенные для решения задач искусственного интеллекта. Недостаток этих языков – неприменимость для создания гибридных экспертных систем.
Специальный программный инструментарий
В эту группу программных средств искусственного интеллекта входят специальные инструментарии общего назначения. Как правило, это библиотеки и надстройки над языком искусственного интеллекта Лисп: КЕЕ (Knowledge Engineering Environment), FRL (Frame Representation Language), KRL (Knowledge Represantation Language), ARTS и др. [1,4,7,8,10], позволяющие пользователям работать с заготовками экспертных систем на более высоком уровне, нежели это возможно в обычных языках искусственного интеллекта.
"Оболочки"
Под "оболочками" (shells) понимают "пустые" версии существующих экспертных систем, т.е. готовые экспертные системы без базы знаний. Примером такой оболочки может служить EMYCIN (Empty MYCIN – пустой MYCIN) [8], которая представляет собой незаполненную экспертную систему MYCIN. Достоинство оболочек в том, что они вообще не требуют работы программистов для создания готовой экспертной системы. Требуется только специалист(ы) в предметной области для заполнения базы знаний. Однако если некоторая предметная область плохо укладывается в модель, используемую в некоторой оболочке, заполнить базу знаний в этом случае весьма не просто.
ТЕХНОЛОГИЯ РАЗРАБОТКИ ЭКСПЕРТНЫХ СИСТЕМ
1. Этапы разработки
2. Этап 1: выбор подходящей проблемы
3. Этап 2: разработка прототипной системы
4. Этап 3: развитие прототипа до промышленной ЭС
5. Этап 4: оценка системы
6. Этап 5: стыковка системы
7. Этап 6: поддержка системы
ЭТАПЫ РАЗРАБОТКИ
Разработка программных комплексов экспертных систем как за рубежом, так и в нашей стране находится на уровне скорее искусства, чем науки. Это связано с тем, что долгое время системы искусственного интеллекта внедрялись в основном во время фазы проектирования, а чаще всего разрабатывалось несколько прототипных версий программ, прежде чем был получен конечный продукт. Такой подход действует хорошо в исследовательских условиях, однако в коммерческих условиях он является слишком дорогим, чтобы оправдать коммерчески жизненный продукт.
Процесс разработки промышленной экспертной системы, опираясь на традиционные технологии [4,8,10], можно разделить на шесть более или менее независимых этапов (рис. 16.7), практически не зависимых от предметной области.
Рис. 16.7.Этапы разработки ЭС
Последовательность этапов дана для общего представления о создании идеального проекта. Конечно, последовательность эта не вполне фиксированная. В действительности каждый последующий этап разработки ЭС приносит новые идеи, которые могут повлиять на предыдущие решения и даже привести к их переработке. Именно поэтому многие специалисты по информатике весьма критично относятся к методологии экспертных систем. Они считают, что расходы на разработку таких систем очень большие, время разработки слишком длительное, а полученные в результате программы ложатся тяжелым бременем на вычислительные ресурсы.
В целом за разработку экспертных систем целесообразно браться организации, где накоплен опыт по автоматизации рутинных процедур обработки информации, например:
1. информационный поиск;
2. сложные расчеты;
4. обработка текстов.
Решение таких задач, во-первых, подготавливает высококвалифицированных специалистов по информатике, необходимых для создания интеллектуальных систем, во-вторых, позволяет отделить от экспертных систем неэкспертные задачи.
ЭТАП 1: ВЫБОР ПОДХОДЯЩЕЙ ПРОБЛЕМЫ
Этот этап включает деятельность, предшествующую решению начать разрабатывать конкретную ЭС. Он включает:
1. определение проблемной области и задачи;
2. нахождение эксперта, желающего сотрудничать при решении проблемы, и назначение коллектива разработчиков;
3. определение предварительного подхода к решению проблемы;
4. анализ расходов и прибыли от разработки;
5. подготовку подробного плана разработки.
Правильный выбор проблемы представляет, наверное, самую критическую часть разработки в целом. Если выбрать неподходящую проблему, можно очень быстро увязнуть в "болоте" проектирования задач, которые никто не знает, как решать. Неподходящая проблема может также привести к созданию экспертной системы, которая стоит намного больше, чем экономит. Дело будет обстоять еще хуже, если разработать систему, которая работает, но не приемлема для пользователей. Даже если разработка выполняется самой организацией для собственных целей, эта фаза является подходящим моментом для получения рекомендаций извне, чтобы гарантировать удачно выбранный и осуществимый с технической точки зрения первоначальный проект.

При выборе области применения следует учитывать, что если знание, необходимое для решения задач, постоянное, четко формулируемое и связано с вычислительной обработкой, то обычные алгоритмические программы, по всей вероятности, будут самым целесообразным способом решения проблем в этой области.
Экспертная система ни в коем случае не устранит потребность в реляционных базах данных, статистическом программном обеспечении, электронных таблицах и системах текстовой обработки. Но если результативность задачи зависит от знания, которое является субъективным, изменяющимся, символьным или вытекающим частично из соображений здравого смысла, тогда область может обоснованно выступать претендентом на экспертную систему.
Приведем некоторые факты, свидетельствующие о необходимости разработки и внедрения экспертных систем:
1. нехватка специалистов, расходующих значительное время для оказания помощи другим;
2. потребность в многочисленном коллективе специалистов, поскольку ни один из них не обладает достаточным знанием;
3. сниженная производительность, поскольку задача требует полного анализа сложного набора условий, а обычный специалист не в состоянии просмотреть (за отведенное время) все эти условия;
4. большое расхождение между решениями самых хороших и самых плохих исполнителей;
5. наличие конкурентов, имеющих преимущество в том, что они лучше справляются с поставленной задачей.
Подходящие задачи имеют следующие характеристики:
1. являются узкоспециализированными;
2. не зависят в значительной степени от общечеловеческих знаний или соображений здравого смысла;
3. не являются для эксперта ни слишком легкими, ни слишком сложными (время, необходимое эксперту для решения проблемы, может составлять от трех часов до трех недель);
4. условия исполнения задачи определяются самим пользователем системы;
5. имеет результаты, которые можно оценить.
Обычно экспертные системы разрабатываются путем получения специфических знаний от эксперта и ввода их в систему. Некоторые системы могут содержать стратегии одного индивида. Следовательно, найти подходящего эксперта – это ключевой шаг в создании экспертных систем.
В процессе разработки и последующего расширения системы инженер по знаниям и эксперт обычно работают вместе. Инженер по знаниям помогает эксперту структурировать знания, определять и формализовать понятия и правила, необходимые для решения проблемы.
Во время первоначальных бесед они решают, будет ли их сотрудничество успешным. Это немаловажно, поскольку обе стороны будут работать вместе по меньшей мере в течение одного года. Кроме них в коллектив разработчиков целесообразно включить потенциальных пользователей и профессиональных программистов.
Предварительный подход к программной реализации задачи определяется исходя из характеристик задачи и ресурсов, выделенных на ее решение. Инженер по знаниям выдвигает обычно несколько вариантов, связанных с использованием имеющихся на рынке программных средств. Окончательный выбор возможен лишь на этапе разработки прототипа.
После того как задача определена, необходимо подсчитать расходы и прибыли от разработки экспертной системы. В расходы включаются затраты на оплату труда коллектива разработчиков. В дополнительные расходы включают стоимость приобретаемого программного инструментария, с помощью которого разрабатывается экспертная система.
Прибыль возможна за счет снижения цены продукции, повышения производительности труда, расширения номенклатуры продукции или услуг или даже разработки новых видов продукции или услуг в этой области. Соответствующие расходы и прибыли от системы определяются относительно времени, в течение которого возвращаются средства, вложенные в разработку. На современном этапе большая часть фирм, развивающих крупные экспертные системы, предпочли разрабатывать дорогостоящие проекты, приносящие значительные прибыли.
Наметились тенденции разработки менее дорогостоящих систем, хотя и с более длительным сроком возвращаемости вложенных в них средств, так как программные средства разработки экспертных систем непрерывно совершенствуются.
После того как инженер по знаниям убедился, что:
1. данная задача может быть решена с помощью экспертной системы;
2. экспертную систему можно создать предлагаемыми на рынке средствами;
3. имеется подходящий эксперт;
4. предложенные критерии производительности являются разумными;
5. затраты и срок их возвращаемости приемлемы для заказчика, он составляет план разработки.
План определяет шаги процесса разработки и необходимые затраты, а также ожидаемые результаты.
ЭТАП 2: РАЗРАБОТКА ПРОТОТИПНОЙ СИСТЕМЫ
Понятие прототипной системы
Прототипная система является усеченной версией экспертной системы, спроектированной для проверки правильности кодирования фактов, связей и стратегий рассуждения эксперта. Она также дает возможность инженеру по знаниям привлечь эксперта к активному участию в разработке экспертной системы и, следовательно, к принятию им обязательства приложить все усилия для создания системы в полном объеме.
Объем прототипа – несколько десятков правил, фреймов или примеров. На рис. 16.8 изображены шесть стадий разработки прототипа и минимальный коллектив разработчиков, занятых на каждой из стадий (пять стадий заимствованы из [10]). Приведем краткую характеристику каждой из стадий, хотя эта схема представляет грубое приближение к сложному итеративному процессу.
Рис. 16.8.Стадии разработки прототипа ЭС
Хотя любое теоретическое разделение бывает часто условным, осознание коллективом разработчиков четких задач каждой стадии представляется целесообразным. Роли разработчиков (эксперт, программист, пользователь и аналитик) являются постоянными на протяжении всей разработки. Совмещение ролей нежелательно.
Сроки приведены условно, так как зависят от квалификации специалистов и особенностей задачи.
Идентификация проблемы
Уточняется задача, планируется ход разработки прототипа экспертной системы, определяются:
1. необходимые ресурсы (время, люди, ЭВМ и т.д.);
2. источники знаний (книги, дополнительные эксперты, методики);
3. имеющиеся аналогичные экспертные системы;
4. цели (распространение опыта, автоматизация рутинных действий и др.);
5. классы решаемых задач и т.д.
Идентификация проблемы– знакомство и обучение коллектива разработчиков, а также создание неформальной формулировки проблемы.
Средняя продолжительность 1 - 2 недели.
Извлечение знаний
Происходит перенос компетентности экспертов на инженеров по знаниям с использованием различных методов:
1. анализ текстов;
3. экспертные игры;
7. наблюдение и другие.
Извлечение знаний– получение инженером по знаниям наиболее полного представления о предметной области и способах принятия решения в ней.

Но если многие предсказания и идеи, выдвинутые в научной фантастике, стали реальностью, то искусственному интеллекту до этого, вероятно, очень далеко. Мы и близко не подошли к созданию настоящего искусственного интеллекта упомянутых персонажей.
Порой кажется, что ждем мы уже целую вечность. Мы можем задать простые вопросы Siri, Google или Cortana, и они ответят, но все, кто использовал такую технологию, рано или поздно разочаровывались. Когда Siri только появилась, мы думали, что это и есть будущее, но сейчас большинство из нас обращаются к ней разве что для поиска в Google и дают предельно простые задания вроде установки таймера.
Причина того, что эти программные продукты так далеки от идеала, заключается в языке. Вот здесь и должна сыграть свою роль обработка естественного языка (natural language processing, NLP). ИИ может уловить смысл простых языковых образований и даже ответить, но он ограничен буквальностью собственной интерпретации вопросов. Компьютер может знать определение слов, но он не понимает их значения в более широком контексте.

Если вы интересуетесь технологиями или увлекаетесь научной фантастикой, вы, вероятно, слышали о тесте Тьюринга. Алан Тьюринг был одним их первых, кто всерьез задумался о потенциале ИИ, он верил, что однажды интеллект машин сможет сравняться с человеческим. Он выдвинул идею простого теста: если в ходе беседы человек не может отличить машину от другого человека, значит, машина достигла уровня человеческого интеллекта.
Тест Тьюринга на самом деле несколько сложнее, но его концепция до сих пор применима в качестве целевого ориентира обработки естественного языка. Иными словами, если машина может думать, как человек, она умеет и обрабатывать язык, как человек (учитывая сложность нашего мозга, способность машины думать наравне с человеком — огромное достижение).
Нужны ли нам андроиды, декламирующие стихи?
Эта цитата стала известной благодаря своей красоте и человечности. Мы хотим создать поэтичных андроидов? Они нужны нам? Это тема для научно-фантастической сюжета, но факт остается фактом: Рой отлично знает язык и понимает эмоции, которые вызывает его речь.
ИИ подобного рода присутствует в произведениях фантастики уже не один десяток лет. Но нам так и не удалось воплотить эти идеи в жизнь. Чем больше информации мы получали о том, как создать настоящий ИИ, и о программе NLP, тем отчетливее понимали, что знания наши близки к нулю. И вопрос здесь нужно ставить шире, ведь мы практически ничего не знаем и о человеческом мозге. Мы не сумели создать ничего, что думало бы, как человек, потому что мы понятия не имеем, как думает человеческий мозг.
На данном этапе мы выделяем три уровня ИИ. Я не опишу их точнее, чем Тим на ресурсе Wait But Why, так что лучше процитирую:

ИИ 1-й ступени. Узкий искусственный интеллект (УИИ), иногда еще называется слабым ИИ. Это ИИ со специализацией в одной области. Есть ИИ, которые способны только обыграть чемпиона мира по шахматам, и больше ничего. Спросите такую машину, как лучше хранить данные на жестком диске, — и наткнетесь на отсутствующий взгляд.

ИИ 2-й ступени. Общий искусственный интеллект (ОИИ), также называется сильным ИИ или ИИ человеческого уровня. Термином ОИИ обозначается компьютер, который в целом умен, как человек. Это машина, способная выполнять любые интеллектуальные задания, доступные человеческому существу. Создать ОИИ гораздо сложнее, чем УИИ, и нам это только предстоит.

Недавно я услышал то, что прочно засело у меня в голове: оказывается, люди в состоянии производить физические и тригонометрические вычисления буквально с ходу. Когда футбольный мяч взлетает вверх, мы можем сказать, когда и где он приземлится. Это знают и квотербеки, бросающие мяч. Они выполняют сложные вычисления и вкладывают их в свои физические действия. Невероятно, если вдуматься! Но ведь мы и представления не имеем, как нам это удается.
Как разработать ИИ, способный делать вещи, которых мы даже не понимаем?
Так как же разработать ИИ, способный делать вещи, которых мы сами не понимаем? Над этим продолжают работать и гиганты вроде Google и Palantir, и многие стартапы, включая X.ai, MetaMind, Feedzai, Signal N, Lilt, и множество других компаний.
Мы испробовали несколько путей преодоления этих препятствий.
Имитация эволюции
Хотя мы многого не знаем о том, как работает человеческий мозг, мы знаем чуть больше о том, как он пришел к этому состоянию, то есть о естественном отборе. Поэтому некоторые пробуют искусственно применить принцип естественного отбора к машинам, с той разницей, что на это уйдут не миллионы лет, поскольку элемент случайности здесь менее выражен.
Этот подход называется эволюционным моделированием или генетическими алгоритмами. Машины выполняют определенные задания, и, когда одна из них проходит испытания с допустимым количеством ошибок, она комбинируется с другими машинами, так же успешно прошедшими испытания. Однако это итеративный процесс, который представляет проблему: мы не знаем, сколько времени понадобится на создание интеллекта, равного нашему.
На данный момент этот метод признан неудачным, и он практически заброшен в 1990-х годах.

Вдохновение от природы
Наш мозг — это биологическая нейронная сеть, поэтому компании и строят искусственные нейронные сети. Методом проб и ошибок они пытаются воспроизвести способы обработки мозгом информации и нейронные маршруты, которые ведут к правильному ответу. На самом деле искусственные нейронные сети имеют гораздо меньше общего с биологическим мозгом, чем отражает их название. Искусственные нейронные сети — это грубая математическая модель, схема, созданная на основе наших скудных знаний о мозге.
Потенциал ИИ сделает доступным преодоление языкового барьера.
Энди использовал электронную библиотеку по машинному обучению TensorFlow от Google (открытый источник) для создания потрясающего и очень значимого генератора скриптов. Google встроил ее во многие свои продукты — от Photos до Search и Gmail — и, разумеется, в Google Now — приложение, которое, в сущности, берет все, что Google знает о вас и использует для выдачи полезной и актуальной информации. Его также можно считать Google-версией Siri.
Глубинное обучение имеет огромный потенциал совершить революцию в области ИИ и помочь нам сделать следующий шаг. Но есть и другие решения, над которыми работают люди.

кадр из фильма Entertainment
Пусть машины проектируют себя сами
В начале фильма Тео нужно многому ее научить, а в конце ее интеллект намного превосходит его собственный. Это экспоненциальный процесс. Выражаясь доступным языком, чем больше она узнает, тем больше способна узнать. Возможно, это приведет нас к кардинально новым типам интеллекта, создаваемого скорее машинами, чем людьми.
Это приводит нас к мысли, что на искусственный интеллект распространяется закон Мура, который гласит, что вычислительная мощность удваивается каждые два года. Речь идет об увеличении мощности в геометрической прогрессии. И хотя темпы начинают замедляться, рост по-прежнему экспоненциальный. Это уже заметно. Глубинное обучение было известно еще в 1970-х годах, но экспоненциальный рост вычислительной мощности и объема данных в значительной мере обеспечил прорывы, которые мы наблюдаем сейчас.
Это большое событие для международной коммерческой среды, да и для общества в целом. Представьте, насколько выше была бы наша продуктивность без языковых барьеров, у скольких людей мы могли бы учиться, со сколькими разговаривать, хотя раньше это было нам недоступно, насколько успешнее стал бы международный бизнес, например, для небольших компаний, которые не могут позволить себе содержать штат переводчиков.
Нам еще долго идти к тому, чтобы компьютеры начали понимать язык. Каждый язык — сложная система, включающая разнообразные тонкости, диалекты, сленг, смыслы, эмоции, интонации, нарратив и контекст. И все это машинам трудно понять. Такие программы, как TensorFlow и CNDK, — большой шаг вперед, но, чтобы попасть туда, куда нам нужно, требуется взаимодействие с человеком.
(1 голосов, оценка: 5,00 из 5)
Загрузка.
Читайте также: