
Структурированные типы данных реферат
Обновлено: 05.07.2024
Описанные выше типы данных называют простыми. Основной признак, по которому можно определить величину простого типа, таков: одно имя — одно значение.
Значительно большие возможности заключают в себе структурированные данные, определяемые разработчиком программы (в пределах возможностей используемого им языка программирования), К структурированию данных разработчика программы толкает как логика прикладной задачи, так и чисто утилитарное соображение: при наличии в задаче большого количества входных и выходных данных отдельное именование каждого из них может оказаться практически невозможным.
Разумеется, действия разработчика алгоритма и программы ограничены возможностями того языка программирования, на который он ориентируется. В разных языках возможности структуризации переменных на уровне сложных структур не совпадают, но многие структуры давно стали традиционными и реализованы в большинстве практически используемых языков программирования.
Структурированные типы данных классифицируют по следующим основным признакам: однородная — неоднородная, упорядоченная — неупорядоченная, прямой доступ — последовательный доступ, статическая — динамическая. Эти признаки противостоят друг другу лишь внутри пары, а вне этого могут сочетаться.
Структуру называютупорядоченной, если, между ее элементами определен порядок следования. Примером упорядоченной математической структуры служит числовая последовательность, в которой у каждого элемента (кроме первого) есть предыдущий и последующий. Наличие индекса в записи элементов структуры уже указывает на ее упорядоченность (хотя индекс для этого не является обязательным признаком).
По способу доступа упорядоченные структуры бывают прямого и последовательного доступа. При прямом доступе каждый элемент структуры доступен пользователю в любой момент независимо от других элементов. Глядя на линейную таблицу чисел мы можем списать или заменить сразу, допустим, десятый элемент. Однако, если эта таблица не на бумаге, а, скажем, каким-то образом записана на магнитофонную ленту, то сразу десятое число нам недоступно — надо сначала извлечь девять предшествующих. В последнем случае мы имеем дело с последовательным доступом.
Самым традиционным и широко известным из структурированных типов данных являетсямассив (иначе называемый регулярным типом) — однородная упорядоченная статическая структура прямого доступа.
Массивом называют однородный набор величин одного и того же типа, называемых компонентами массива, объединенных одним общим именем (идентификатором) и идентифицируемых (адресуемых) вычисляемыминдексом. Это определение подчеркивает, что все однотипные компоненты массива имеют одно и то же имя, но различаются по индексам, которые могут иметь характер целых чисел из некоторого диапазона, литер, перечисленных констант. Индексы позволяют адресовать компоненты массива, т.е. получить доступ в произвольный момент времени к любой из них как к одиночной переменной (рис. 1.32). Обычный прием работы с массивом — выборочное изменение отдельных его компоневт.
Вычисляемые индексы позволяют использовать единое обозначение элементов массива для описания массовых однотипных операций в циклических конструкциях программ. Важной особенностью массива является его статичность. Массив должен быть описан в программе (т.е. определены тип и число компонент) и его характеристики не могут быть изменены в ходе выполнения программы.
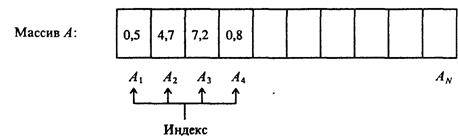
Рис. 1.32. Одномерный массив — набор элементов (компонентов)
Компонентами массива могут быть не только простейшие данные, но и структурные, в том числе массивы. В этом случае мы получаем массив массивов — многомерныймассив. Для индексации элементарных компонент в этом случае может потребоваться два, три и более индексов.
В некоторых системах программирования существуют специальные виды массивов. Например, массив литер (символов) определяется как строка.
Данные, хранящиеся в массивах, находятся в оперативной памяти компьютера. Это, с одной стороны, ускоряет доступ к ним в ходе решения задачи, а с другой -налагает ограничения на объем возможной информации, организованной в виде массивов. Не следует поэтому, без крайней необходимости, создавать новые массивы для перемещения данных из уже существующих массивов.
Существует огромное число методов сортировки массивов. Рассмотрим один из самых простых (но не самых быстрых) — метод выбора.
В начале процесса имеем заполненный числами массив (неотсортированный). Процесс сортировки строится по индукции. Допустим, мы уже отсортировали часть массива и имеем упорядоченную последовательность
и оставшуюся неотсортированной последовательность
При каждом шаге, начиная с i = 1, из неотсортированной части последовательности извлекается наименьший элемент х = ai, и меняется местами с i-м элементом. Затем этот процесс повторяется для i = 2, i = 3 и т.д., до тех пор пока не останется один, самый большой элемент.
1) фиксируется в качестве значения вспомогательной переменной т первый слева элемент массива: т = аi (в конце процесса т будет иметь значение наименьшего элемента);
2) выполняется сравнение т с элементом массива aj, (начиная с номера j = i + 1) и, если ajт, то т заменяется на аj;
3) далее выполняется сравнение т с очередным элементом массива, т.е. j увеличивается на единицу и шаги 2, 3 выполняются снова, до тех пор пока у не достигнет максимального значения индекса элемента массива.
После выполнения этих предписаний переменная т будет соответствовать наименьшему элементу массива.
Двумерный массив визуально представляется плоской таблицей, табл. 1.10. При наличии одного имени (идентификатора) для всех компонентов каждый из них фиксируется значениями двух индексов, указывающих номер строки и номер столбца, на пересечении которых находится эта компонента.
Таблица 1.10 Графический образ двумерного массива
| i j | … | ||||
| a11 | a12 | a13 | a14 | … | |
| a21 | a22 | a23 | a24 | … | |
| a31 | a32 | a33 | a34 | … | |
| a41 | a42 | a43 | a44 | … | |
| … | … | … | … | … | … |
Пусть в таблице п строк и т столбцов. Вспомогательным алгоритмом в данной задаче может быть алгоритм поиска нужных узлов в одной строке. Пусть эта строка имеет номер k. Алгоритмы записаны без комментариев для самостоятельного разбора.
Вспомогательный алгоритм (k):
1) положить j = 1;
2) если tk,jTtk.j+1, то см. п. 2;
3) увеличить j на 1,
4) если jm, то вернуться к п. 2;
5) задача решена, ответ: (k,j), (k,j + 1);
2) выполнить вспомогательный алгоритм (K);
3) увеличить k на 1;
4) если kn, то вернуться к п.2;
Записи, множества, файлы
Обобщением массива является комбинированный тип данных — запись, являющаяся неоднородной упорядоченной статической структурой прямого доступа. Запись есть набор именованных компонент — полей (часто разного типа), объединенных одним общим именем и идентифицируемых (адресуемых) с помощью как имени записи, так и имен полей, рис. 1.33.
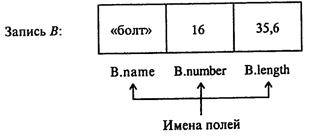
Для облегчения работы с полями в различных языках программирования существуют средства, облегчающие их адресацию.
И записи, и массивы обладают одним общим свойством — произвольным доступом к компонентам. Записи более универсальны в том смысле, что для них не требуется идентичности типов их компонент. Массивы обеспечивают большую гибкость -индексы их компонент можно вычислять в отличие от имен полей записей.
Существенно иные возможности дает структура данных, моделирующая свойстваматематического объекта — множества.
Над множеством могут быть выполнены следующие операции:
1) объединение множеств (операция сложения ‘+’);
2) пересечение множеств (операция умножения ‘*’);
3) теоретико-множественная разность (вычитание множеств ‘-‘);
4) проверка принадлежности элемента множеству.
Различия между множеством и массивом очень существенны: размер множества заранее не оговаривается (хотя и ограничен компьютерной реализацией, например, 255), не существует иного способа доступа к элементам множества, кроме как проверкой принадлежности множеству.
Более сложной, чем рассмотренные выше из предусмотренных в современных системах программирования структур данных, является очередь (файл).
Очередь есть линейно упорядоченный набор следующих друг за другом компонент, доступ к которым происходит по следующим правилам:
1) новые компоненты могут добавляться лишь в хвост очереди;
2) значения компонент могут читаться (извлекаться) лишь в порядке следования компонент от головы к хвосту очереди.
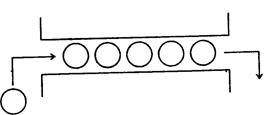
В языках программирования существуют и такие разновидности файлов, которые не подчиняются условию последовательности доступа к его компонентам (так называемые, файлы прямого доступа). Они уже не являются очередями.
Статьи к прочтению:
Работа с множествами. Структурированные типы данных. Урок 16
Похожие статьи:
Для повышения производительности и качества работы необходимо иметь данные, максимально приближенные к реальным аналогам. Тип данных, позволяющий хранить…
Изображения представляются двумя способами. 1. Графические объекты создаются как совокупности линий, векторов – называется векторной графикой. 2….
Любой из структуированных типов данных характеризуется множественностью образующих этот тип элементов. Переменная или константа структуированного типа всегда имеет несколько компонент. Каждая из этих компонент, в свою очередь, может принадлежать структуированному типу, что позволяет говорить о возможной вложенности типов.
В Турбо Паскале пять структуированных типов:
- массивы;
- строки;
- множества;
- записи;
- файлы;
Однако, прежде чем приступить к их изучению, нам надо рассмотреть еще два типа данных — перечисляемый и интервальный, которые относятся к порядковым типам, нами ранее не рассматривались, но потребуются при изучении нового материала.
Массивы — это совокупности однотипных элементов. Характеризуются они следующим:
- каждый компонент массива может быть явно обозначен и к нему имеется прямой доступ;
- число компонент массива определяется при его описании и в дальнейшем не меняется.
Для обозначения компонент массива используется имя переменной-массива и так называемые индексы, которые обычно указывают желаемый элемент. Тип индекса может быть только порядковым (кроме longint). Чаще всего используется интервальный тип (диапазон).
Описание типа массива задается следующим образом:
имя типа = array[ список индексов ] of тип
Здесь имя типа — правильный идентификатор; список индексов — список одного или нескольких индексных типов, разделенных запятыми; тип — любой тип данных.
Вводить и выводить массивы можно только поэлементно.
Пример 1. Ввод и вывод одномерного массива.
mas = array[1..n] of integer;
writeln('введите элементы массива');
for i:=1 to n do readln(a[i]);
writeln('вывод элементов массива:');
for i:=1 to n do write(a[i]:5);
Определить переменную как массив можно и непосредственно при ее описании, без предварительного описания типа массива, например:
var a,b,c: array[1..10] of integer;
Если массивы a и b описаны как:
a = array[1..5] of integer;
b = array[1..5] of integer;
то переменные a и b считаются разных типов. Для обеспечения совместимости применяйте описание переменных через предварительное описание типа.
Если типы массивов идентичны, то в программе один массив может быть присвоен другому. В этом случае значения всех переменных одного массива будет присвоены соответствующим элементам второго массива.
Вместе с тем, над массивами не определены операции отношения. Сравнивать два массива можно только поэлементно.
Так как тип, идущий за ключевым словом of в описании массива, — любой тип Турбо Паскаль, то он может быть и другим массивом. Например:
mas = array[1..5] of array[1..10] of integer;
Такую запись можно заменить более компактной:
mas = array[1..5, 1..10] of integer;
Таким образом возникает понятие многомерного массива. Глубина вложенности массивов произвольная, поэтому количество элементов в списке индексных типов (размерность массива) не ограничена, однако не может быть более 65520 байт.
Работа с многомерными массивами почти всегда связана с организацией вложенных циклов. Так, чтобы заполнить двумерный массив (матрицу) случайными числами, используют конструкцию вида:
Динамический массив представляет собой массив, для которого при объявлении указывается только тип его элементов, а размер массива определяете при выполнении программы. Формат описания типа динамического массива:
Type = Аггау of ;
Задание размера динамического массива во время выполнения программы производится процедурой SetLength (var S; NewLength:integer), которая для динамического массива Sустанавливает новый размер, равный NewLength. Выполнять операции с динамическим массивом и его элементами можно только после задания размеров этого массива.
После задания размера динамического массива для определения его длины, минимального и максимального номеров элементов используются функции Length( ), Low( )и High( )соответственно. Нумерация элементов динамического массива начинается с нуля, в связи с этим функция Low( )для него всегда возвращает значение ноль.
m: array of real;
for n:=0 to 99 do m[n]:=n;
SetLength (m , 200);
После описания динамического массива, состоящего из вещественных чисел, определяется размер этого массива, равный 100 элементам. Каждому элементу присваивается значение, равное его номеру в массиве. Так как нумерация элементов массива начинается с нуля, то номер последнего из них равен не 100, а 99. После цикла размер массива увеличивается до двухсот.
Для описания типа многомерного динамического массива(к примеру, двумерного) используется конструкция:
Type = Аггау of Аггау of ;
Действия над массивом обычно выполняются поэлементно, в т.ч. операции ввода и вывода. Поэлементная обработка массивов производится, как правило, с использованием циклов. Массив в целом (как единый объект) может участвовать только в операциях отношения и в операторе присваивания, при этом массивы должны быть полностью идентичными по структуре, то есть иметь индексы одинаковых типов и элементы одинаковых типов .
Множества: множество представляет собой совокупность элементов, выбранных из предопределенного набора значений. Все элементы множества имеют порядковый тип; количество элементов множества не может превышать 256. Формат, описания множественного типа:
Type = Set of ;
Переменная множественного типа может содержать от нуля до максимального числа элементов своего множества. Значения множественного типа заключаются в квадратные скобки. Пустое множество обозначается [ ]. Операции, допустимые над множествами, приведены в таблице.

Вместе с тем, имеется операция in(проверка членства), которая определяет принадлежность выражения порядкового типа (первого операнда) множеству (второму операнду). Результат операции будет типа booleanи иметь значение Trueв случае соблюдения принадлежности значения множеству.
Записи: записи объединяют фиксированное число элементов данных других типов. Отдельные элементы записи имеют имена и называютсяполями. Имя поля должно быть уникальным в пределах записи. Различают фиксированные и вариантные записи. Фиксированная запись состоит из конечного числа полей, ее объявление имеет следующий формат:
Type = record;
end ;
Вариантная запись, так же как и фиксированная, имеет конечное число полей, однако предоставляет возможность по-разному интерпретировать области памяти, занимаемые полями. Все варианты записи располагаются в одном месте памяти и позволяют обращаться к ним по различным именам. Отметим, что термин ʼʼвариантная записьʼʼ не имеет ничего общего с термином ʼʼвариантный типʼʼ (variant). Формат объявления вариантной записи:
Type = record;
Case : of;
end ;
Для обращения к конкретному полю крайне важно указывать имя записи и имя поля, разделенные точкой. Τᴀᴋᴎᴍ ᴏϬᴩᴀᴈᴏᴍ, имя поля является составным. С полем можно выполнять те же операции, что и с переменной этого типа.
Переменная Man — фиксированная запись, которая содержит поля имени ( Name ), оклада ( Salary ) и примечания ( Note ), причем каждое поле имеет свой тип.
Файлы: Файл представляет собой имеющую имя последовательность однотипных элементов, размещенных на внешнем устройстве, чаще всего, на диске. Файл имеет много общего с одномерным динамическим массивом, но размещается не в оперативной, а во внешней памяти, и не требует предварительного указания размера.
Для выполнения операций с конкретным файлом, размещенным на диске, в программе обычно используется так называемая файловая переменная (логический файл). Файловая переменная после ее описания связывается с некоторым файлом, благодаря чему операции, выполняемые над ней, приводят к соответствующим изменениям в данном файле. После завершения всех операций связь между файловой переменной и файлом разрывается. Теперь файловую переменную можно связать с другим файлом этого же типа.
Учитывая зависимость оттипа элементов различают текстовые, типизированные и нетипизированные файлы. Текстовый файл содержит строки символов переменной длины, типизированный файл составляют элементы указанного типа (кроме файлового), внетипизированном файле находятся элементы, тип которых не указан. Описание файловой переменной, предназначенной для работы с файлом, должно соответствовать типу элементов файла.
f2: File of integer;
f3: File of real;
здесь переменная f1 предназначена для работы с текстовыми файлами, переменные f2 и f3 – с типизированными файлами, содержащими целые и вещественные числа, соответственно, а переменная f4 – с нетипизированными файлами.
Структурированные типы данных - понятие и виды. Классификация и особенности категории "Структурированные типы данных" 2017, 2018.
Массив Массив — последовательность элементов одного типа, называемого базовым. На абстрактном уровне массив представляет собой линейную структуру. На физическом уровне массив реализован последовательной (прямоугольной) схемой хранения. Располагаться он может в. [читать подробнее].
Простые типы данных Типы данных Любые данные, используемые в программировании, имеют свои типы данных. Важно! Реляционная модель требует, чтобы типы используемых данных были простыми (скаляры). Для уточнения этого утверждения рассмотрим, какие вообще типы. [читать подробнее].
Массив (ARRAY) объединяет элементы одного типа данных. Более формально массив можно определить как одномерную (последовательную) упорядоченную совокупность элементов некоторого типа, которые адресуются с помощью индекса. В качестве иллюстрации можно представить себе шкаф. [читать подробнее].

ГОСТ
Метод структурной алгоритмизации является одним из системных методов разработки алгоритмов. Он основан на визуальном представлении алгоритмов в виде последовательностей управляющих структурных фрагментов.
Каждый алгоритм состоит из элементарных шагов, которые можно объединить в определенные алгоритмические конструкции: линейную (последовательную), разветвляющуюся, циклическую .
Линейной называется конструкция алгоритма, реализованная в виде последовательности действий (шагов), причем каждое действие (шаг) выполняется только 1 раз, после каждого действия (шага) выполняется увеличение действия (шага) на 1 до тех пор, пока значение не станет больше конечного параметра алгоритма.
С помощью линейных алгоритмов представляют линейные процессы. Алгоритмы этого типа используют при описании обобщенного решения задач в виде последовательностей модулей.
Разветвляющейся (ветвящейся) называют алгоритмическую конструкцию, обеспечивающую выбор между 2 вариантами решений в зависимости от значений входных данных.
Готовые работы на аналогичную тему
Ниже приведены блок-схемы разветвляющихся алгоритмов.
Циклической (или циклом) называется конструкция алгоритма, в которой некоторая группа идущих подряд действий (шагов) выполняется несколько раз в зависимости от условия задачи и входных данных.
Такую группу повторяющихся действий на каждом шагу цикла называют телом цикла.
В любой циклической конструкции содержатся элементы ветвящейся конструкции алгоритма.
Различают 3 типа циклических алгоритмов:
- цикл с параметром (арифметический цикл);
- цикл с предусловием;
- цикл с постусловием (последние два называют итерационными).
Арифметический цикл
В цикле данного типа число шагов однозначно определено правилом изменения параметра, задаваемом с помощью его начальных и конечных значений, а также шага его изменения. Т.е., на каждом шаге цикла значение параметра изменяется согласно шагу цикла, пока не достигнет значения, равного конечному значению параметра.
Цикл с предусловием
В данном цикле количество шагов заранее не определяется, оно зависит от входных данных. В этой циклической структуре сначала происходит проверка значения условного выражения (условия), стоящего перед выполнением очередного шага цикла. При истинном значении условного выражения будет исполняться тело цикла. После чего снова будет выполняться проверка условия. Эти действия будут повторяться до тех пор, пока значение условного выражения не станет ложным, тогда цикл завершится.
Особенностью данного типа цикла является то, что при изначальной ложности значения условного выражения тело цикла не будет выполняться совсем.
Цикл с постусловием
В данной циклической конструкции, как и в предыдущей, заранее не определяется число повторений тела цикла, оно будет зависеть от входных параметров. Отличительной чертой цикла с предусловием является то, что тело цикла с постусловием в любом случае будет выполнено хотя бы 1 раз и только после этого проверится условие. В данной конструкции тело цикла выполняется до тех пор, пока значение условного выражения будет ложным. Как только оно станет истинным, выполнение команд прекратится.
В реальных задачах, как правило, присутствует любое количество циклов.
Ниже приведены блок-схемы циклических алгоритмов.
Типы данных: простые и структурированные
К реальным данным, которые обрабатываются программой, относят целые и вещественные числа, логические величины и символы. Они относятся к простым типам данных и называются базовыми. Все обрабатываемые компьютером данные хранятся в его ячейках памяти, каждая из которых имеет свой адрес. В языках программирования существуют переменные, позволяющие не обращать внимание на адреса ячеек памяти и обращаться к ним с помощью имени (идентификатора).
Переменная представляет собой именованный объект (ячейку памяти), изменяющий свое значение.
Имя переменной указывает на значение, а адрес и способ ее хранения остаются скрытыми от про¬граммиста. Помимо имени и значения переменные имеют свой тип, помогающий опре¬делить какого типа информация находится в памяти.
Типом переменной задается:
- используемый способ записи информации в ячейки памяти;
- необходимый объем памяти для ее хранения.
Для каждого типа объем памяти определяется так, чтобы в него можно было поместить любое значение из допустимо¬го диапазона значений для данного типа.
Переменные, которые присутствуют в программе на протяжении всего периода ее работы, называются статическими.
Переменные, которые создаются и уничтожаются на разных этапах выполнения про¬граммы, называются динамическими.
Остальные данные, значения которых не изменяются на протяжении всего выполнения программы, называются константами или постоянными.
Константы также имеют тип. Их возможно ука¬зывать явно или с помощью идентификаторов.
Чтобы повысить производительность и качество работы нужно иметь данные, которые будут максимально приближены к реальным аналогам.
Тип данных, который позволяет хранить вместе под одним именем несколько переменных, называется структурированным.
Любой язык программирования имеет свои структурированные типы. Рассмотрим одну из таких структур - массив.
Массивом называют упорядоченную совокупность однотипных величин, которые имеют общее имя, порядковые номера у элементов (индексы).
Элементы массива хранятся в памяти компьютера по соседству в отличие от одиночных элементов. Массивы различают по количеству индексов элементов.
Одномерный массив характеризуется наличием у каждого элемента лишь одного индекса. Примерами одномерных массивов являются геометрическая и арифметическая последовательности, которые определяют конечные ряды чисел.
Количество элементов массива называется размерностью.
У одномерного массива его размерность записывают рядом с именем в круглых скобках.
Элементы одномерного массива вводятся поэлемен¬тно, в порядке, необходимом для решения конкретной задачи. При необходимости ввода всего массива элементы вводятся в порядке возрастания индексов.
Читайте также: