
Символы и алфавиты для кодирования информации реферат
Обновлено: 30.06.2024
Представленная работа посвящена теме "Кодирование информации".
Человек воспринимает окружающий мир, своего рода, получает информацию с помощью органов чувств: зрение, слух, обоняние, осязание, вкус. Для того чтобы правильно ориентироваться в мире, он запоминает полученные сведения, то есть хранит информацию. В процессе достижения каких-либо целей человек принимает решения - обрабатывает информацию. В процессе общения с другими людьми человек передает и принимает информацию. Человек живет в мире информации.
Море информации, которое получает человек, необходимо как-то запомнить или сохранить. На помощь приходит персональный компьютер. Никто не задумывается о том, как информация помещается на маленьких и удобных флэш-картах, и, конечно же, на жестком диске компьютера. Поэтому я считаю данную тему, для нашего современного мира – мира информационных технологий, актуальной.
I.История кодирования информации
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли:
- криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для непосвященных лиц;

- азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);

-сурдожесты – язык жестов, используемый людьми с нарушениями слуха.
Один из самых первых известных методов шифрования носит имя римского императора Юлия Цезаря (I век до н.э.). Этот метод основан на замене
каждой буквы шифруемого текста, на другую, путем смещения в алфавите от
исходной буквы на фиксированное количество символов, причем алфавит
II.Кодирование информации
Код – это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Обычно каждый образ при кодировании (иногда говорят – шифровке) представлении отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.

Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной для нас десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Цели кодирования информации:
1) повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
2) представление информации и данных в наиболее удобном для ЭВМ виде
3) снижение требований к скорости передачи за счёт сокращения избыточности информации
4) сокращение объёма памяти занимаемой файлами
5) Повышение помехоустойчивости при передаче данных.
Аналоговой
Дискретной.
Живописное полотно, цвет которого изменяется непрерывно - это пример
аналогового представления, а изображение, напечатанное при помощи струйного принтера и состоящее из отдельных точек разного цвета - это дискретное представление. Путем разбиения графического изображения (дискретизации) происходит преобразование графической информации из аналоговой формы в дискретную. При этом производится кодирование - присвоение каждому элементу конкретного значения в форме кода. При кодировании изображения происходит его пространственная дискретизация. Все изображение разбивается на отдельные точки, каждому элементу ставится в соответствие код его цвета. При этом качество кодирования будет зависеть от следующих параметров: размера точки и количества используемых цветов. Чем меньше размер точки, а, значит, изображение составляется из большего количества точек, тем выше качество кодирования. Чем большее количество цветов используется (т. е. точка изображения может принимать больше возможных состояний), тем больше информации несет каждая точка, а, значит, увеличивается качество кодирования. Создание и хранение графических объектов возможно в нескольких видах - в виде векторного, фрактального или растрового изображения.
Существует несколько способов кодирования графической информации.
Растровое изображение: при помощи увеличительного стекла можно увидеть, что черно-белое графическое изображение, например из газеты, состоит из мельчайших точек, составляющих определенный узор - растр. Во Франции в 19 веке возникло новое направление в живописи - пуантилизм. Его техника заключалась в том, что на холст рисунок наносился кистью в виде разноцветных точек. Также этот метод издавна применяется в полиграфии для кодирования графической информации. Точность передачи рисунка зависит от количества точек и их размера. После разбиения рисунка на точки, начиная с левого угла, двигаясь по строкам слева направо, можно кодировать цвет каждой точки. В современных ПК в основном используют следующие разрешающие способности экрана: 640 на 480, 800 на 600, 1024 на 768 и 1280 на 1024 точки. Так как яркость каждой точки и ее линейные координаты можно выразить с помощью целых чисел, то можно сказать, что этот метод кодирования позволяет использовать двоичный код для того чтобы обрабатывать графические данные.
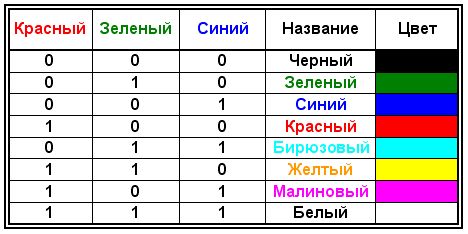
Если говорить о черно-белых иллюстрациях, то, если не использовать полутона, то пиксель будет принимать одно из двух состояний: светится (белый) и не светится (черный). А так как информация о цвете пикселя называется кодом пикселя, то для его кодирования достаточно одного бита памяти: 0 - черный, 1 - белый. Если же рассматриваются иллюстрации в виде комбинации точек с 256 градациями серого цвета (а именно такие в настоящее время общеприняты), то достаточно восьмиразрядного двоичного числа для того чтобы закодировать яркость любой точки. В компьютерной графике чрезвычайно важен цвет. Он выступает как средство усиления зрительного впечатления и повышения информационной насыщенности изображения.
Цветовые модели: если говорить о кодировании цветных графических
изображений, то нужно рассмотреть принцип декомпозиции произвольного цвета на основные составляющие. Применяют несколько систем кодирования: HSB, RGB и CMYK. Первая цветовая модель проста и интуитивно понятна, т. е. удобна для человека, вторая наиболее удобна для компьютера, а последняя модель CMYK-для типографий. Использование этих цветовых моделей связано с тем, что световой поток может формироваться излучениями, представляющими собой комбинацию " чистых" спектральных цветов: красного, зеленого, синего или их производных.
Заключение
Таким образом, можно сделать вывод, что кодирование информации в компьютере - это очень важный процесс.
В сегодняшнем XXI веке немыслимо представить человека, который бы не пользовался компьютером и другими современными технологиями.
Школа гуманитарных наук
Кафедра социальных наук
РЕФЕРАТ НА ТЕМУ:
| Выполнила студентка 1 курса гр. Б4112 Храмова Анна |
| . |
Содержание
I.История кодирования информации………………………………. 4
III. Способы кодирования информации……………………………. 6
- Кодирование символьной (текстовой) информации…………….6-8
- Кодирование числовой информации………………………………..8
- Кодирование звуковой информации………………………………10
Список используемых источников………………………………….12
Введение
Представленная работа посвящена теме "Кодирование информации".
Человек воспринимает окружающий мир, своего рода, получает информацию с помощью органов чувств: зрение, слух, обоняние, осязание, вкус. Для того чтобы правильно ориентироваться в мире, он запоминает полученные сведения, то есть хранит информацию. В процессе достижения каких-либо целей человек принимает решения - обрабатывает информацию. В процессе общения с другими людьми человек передает и принимает информацию. Человек живет в мире информации.
Море информации, которое получает человек, необходимо как-то запомнить или сохранить. На помощь приходит персональный компьютер. Никто не задумывается о том, как информация помещается на маленьких и удобных флэш-картах, и, конечно же, на жестком диске компьютера. Поэтому я считаю данную тему, для нашего современного мира – мира информационных технологий, актуальной.
I.История кодирования информации
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли:
- криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для непосвященных лиц;
- азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
-сурдожесты – язык жестов, используемый людьми с нарушениями слуха.
Один из самых первых известных методов шифрования носит имя римского императора Юлия Цезаря (I век до н.э.). Этот метод основан на замене
каждой буквы шифруемого текста, на другую, путем смещения в алфавите от
исходной буквы на фиксированное количество символов, причем алфавит
II.Кодирование информации
Код – это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Обычно каждый образ при кодировании (иногда говорят – шифровке) представлении отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной для нас десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Цели кодирования информации:
1) повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
2) представление информации и данных в наиболее удобном для ЭВМ виде
3) снижение требований к скорости передачи за счёт сокращения избыточности информации
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли:
криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для непосвященных лиц;
азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
с урдожесты – язык жестов, используемый людьми с нарушениями слуха.
II. Кодирование информации
Код – это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Обычно каждый образ при кодировании (иногда говорят – шифровке) представлении отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
III. Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами.
Т радиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события): К = 2 I = 2 8 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
IV . Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).

ГОСТ
Общее понятие кодирования информации
Познание окружающего мира начинается с восприятия его человеком с помощью органов чувств. Зрение, вкус, слух, обоняние, осязание доводят до нашего сознания информацию о самых разнообразных свойствах предметов, а также явлениях и процессах, происходящих вокруг нас. Эта информация поступает к нам в виде набора символов или сигналов. Однако если эти символы или сигналы никому не ясны, то информация будет бесполезной. Поэтому требуется язык общения, который будет понятен всем.
Естественные и формальные языки представления информации
Язык — это знаковая система для представления и передачи информации.
- естественные (например, мимика и жесты, музыка, живопись, речь человека);
- формальные (например, математическая символика, чертежи и схемы, нотная грамота, языки программирования).
Естественный язык можно формализовать. Так для формализации музыки изобрели нотную грамоту, для формализации речи создали национальные алфавиты (например, латинский ($26$ символов), русский ($33$ символа)), кроме этого арабские цифры, азбуку Морзе и т.д.
Естественные языки развивались веками и служили для общения людей между собой. Формальные языки разрабатываются для специальных применений.
Коммуникативный язык несет в себе логическую информацию, именно с помощью него человек преобразует получаемую информацию в знания и передает эти знания другим людям.
Алфавиты представления информации
Первобытные люди для обозначения каждого нового предмета придумывали новые имена. Для получения необходимого разнообразия имен, названий они стали комбинировать звуки таким образом, чтобы получить в результате слова. Так в ходе эволюции человека появилась идея создания конечного алфавита, т.е. некоторого фиксированного набора знаков, из которого можно составить как угодно много слов. Комбинация знаков алфавита называется словом. Из слов можно составлять фразы, которые будут нести определенную смысловую нагрузку.
Готовые работы на аналогичную тему
Таким образом, алфавит – это упорядоченный набор символов или сигналов, который составляет основу языка.
Мощность алфавита - это количество составляющих его символов.
Человек в своей практике общения использует самые разнообразные языки (например, дорожная грамота, включающая в себя знаки дорожного движения и разметки). Прежде всего, это, конечно же, языки устной и письменной речи, в том числе и иностранные.
Кроме того, человек использует ряд языков профессионального назначения. К ним относятся языки математических и химических формул, обозначений электроники (например, схема электрической цепи), языки программирования. При этом каждый язык имеет свой алфавит.
С развитием технических средств передачи информации появилась необходимость использования помимо речевых алфавитов многих других. Одним из примеров первых алфавитов, используемых в технике, является азбука Морзе, в которой каждому знаку обычного алфавита соответствует набор точек и тире.
Общее понятие кодирования информации
Воспринимая информацию, человек стал стремиться зафиксировать ее таким образом, чтобы она стала понятной для других, представляя ее в той или иной форме.
Музыкальную тему композитор может наиграть на пианино, а затем записать с помощью нот. Образы, навеянные все той же мелодией, поэт может воплотить в виде стихотворения, хореограф выразить танцем, а художник — в картине.
Люди сохраняют свои знания, записывая их на различных носителях. Благодаря чему эти знания передаются не только в пространстве, но и во времени — от одного поколения к другому.
До наших дней дошли послания предков, которые с помощью различных символов пытались изобразить себя и свои поступки в памятниках и надписях. Примером могут служить наскальные рисунки (петроглифы), которые по сей день представляют загадку для ученых. Вероятнее всего, таким образом древние люди пытались вступить в контакт с будущими поколениями и сообщить о событиях их жизни.
Каждый народ имеет свой язык, состоящий из набора символов (букв): русский, английский, японский и многие другие. Об этом уже упоминалось ранее.
Представление информации с помощью какого-либо языка часто называют кодированием.
Код — это набор символов либо условных обозначений, используемый для представления информации.
Алфавит кодирования содержит полный набор кодов.
Кодирование — это процесс представления информации с помощью кода.
Так водитель пытается передать сигнал с помощью гудка или мигания фар. В данном случае гудок (его наличие или отсутствие) – это код, а в случае световой сигнализации кодом будет являться мигание фар или его отсутствие. Пешеход встречается с кодированием информации при переходе дороги по сигналу светофора. Код определяет цвет светофора — красный, желтый, зеленый.
Естественный язык, на котором мы общаемся, тоже представляет собой код, называемый алфавитом. Во время устной речи этот код передается звуками, при письменной — буквами. Причем одну и ту же информацию можно представить различными способами. К примеру, запись разговора можно закодировать на бумажном носителе двумя способами: с помощью букв или специальных стенографических знаков.
В более узком смысле под кодированием часто понимают переход от одной формы представления информации к другой, которая более удобна при хранении, передаче или обработке.
В процессе развития технических средств появлялись новые способы кодирования информации. Так во второй половине XIX века американский изобретатель Сэмюэль Морзе придумал удивительно простой код, который применяется до сих пор. Используя этот код, информацию можно представить в виде: длинного сигнала (тире), короткого сигнала (точки) и отсутствия сигнала (паузы) для разделения букв. Таким образом, принцип кодирования сводился к использованию набора символов, расположенных в строго определенном порядке.

Знаменитый немецкий ученый Готфрид Вильгельм Лейбниц предложил еще в XVII веке уникальную по своей простоте систему представления чисел, основанную на использовании вычислений с помощью двоек.
В настоящее время этот способ представления информации с помощью языка, в состав которого входит всего два символа: $0$ и $1$, называется двоичным кодированием информации и широко используется в технических устройствах, в том числе и в компьютере. Эти два символа $0$ и $1$ принято называть двоичными цифрами или битами (от англ. bit — Binary Digit - двоичный знак).
Каждому человеку ежедневно в бытовых условиях приходится сталкиваться с устройствами, которые могут находиться только в двух устойчивых состояниях: включено или выключено. И это хорошо известные всем выключатели. Однако изобрести выключатель, который был бы способен устойчиво и быстро переключаться в любое из $10$ состояний, оказалось невозможно. В итоге после ряда неудачных попыток разработчики сделали вывод о невозможности создания компьютера на основе десятичной системы счисления. Поэтому представление чисел в компьютере осуществляется с помощью двоичной системы счисления.
Способ кодирования информации зависит от цели, которая при этом должна быть достигнута. Целью может являться сокращение записи, засекречивание (шифровка) информации, или, напротив, достижение взаимопонимания. Например, система дорожных знаков, флажковая азбука на флоте, специальные научные языки и символы ― химические, математические, медицинские и др., предназначены для того, чтобы люди могли общаться и понимать друг друга. От того, как представлена информация, зависит способ ее обработки, хранения, передачи и т.д.
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
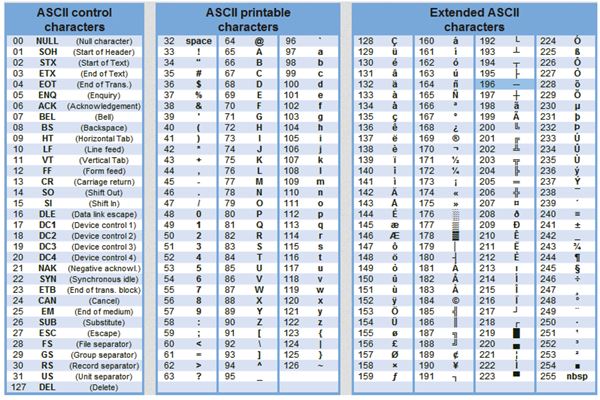
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
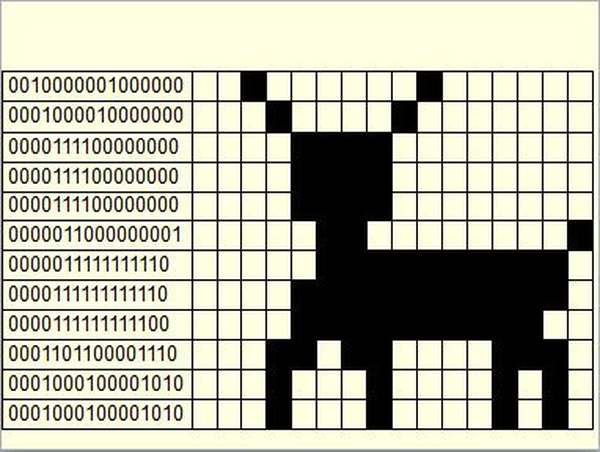
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
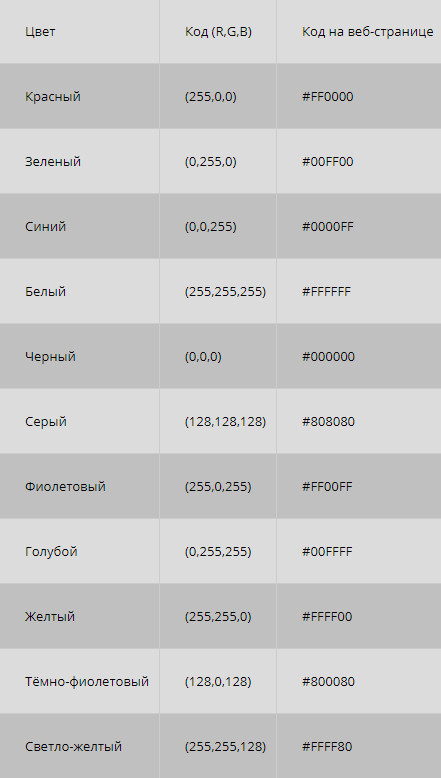
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.
Читайте также: