
Реферат на тему извлечение информации
Обновлено: 05.07.2024
Поиск информации или информационный поиск представляет один из основных информационных процессов. Цели, возможности и характер поиска всегда зависели от наличия, информации, её важности и доступности, а также средств организации поиска.
Интернет-технологии и программно-технические средства, доступные большинству людей, позволяют осуществлять данный процесс в любое время, практически в любом месте по любым запросам.
Поиск - процесс, в ходе которого в той или иной последовательности производится соотнесение отыскиваемого с каждым объектом, хранящимся в массиве. Цель любого поиска заключается в потребности, необходимости или желании находить различные виды информации, способствующие получению лицом, осуществляющим поиск, нужных ему сведений, знаний и т.д. для повышения собственного профессионального, культурного и любого иного уровня; создания новой информации и формирования новых знаний; принятия управленческих решений и т.п.
Термин информационный поиск (англ. information retrieval) ввёл американский математик К. Муэрс. Он заметил, что побудительной причиной такого поиска является информационная потребность, выраженная в форме информационного запроса. К объектам информационного поиска К. Муэрс отнес документы, сведения об их наличии и (или) местонахождении, фактографическую информацию.
Решать проблемы фактографического поиска первыми стали представители библиотек. Они разработали средства информационного поиска, получившие название "справочно-поисковый аппарат" (каталоги, библиографические указатели и др.). В профессиональной отечественной печати данный термин используется с 1970-х годов. Библиотекари определяют "информационный поиск" как нахождение в информационном массиве документов, соответствующих информационному запросу пользователей.
С точки зрения использования компьютерной техники "информационный поиск" - совокупность логических и технических операций, имеющих конечной целью нахождение документов, сведений о них, фактов, данных, релевантных запросу потребителя.
1 Информационный поиск: виды, этапы поиска
Побудительная причина информационного поиска - информационная потребность, выраженная в форме информационного запроса. Объектами информационного поиска могут быть документы, сведения о их наличии и (или) местонахождении, фактографическая информация.
Условно информационный поиск делится на четыре основных вида: библиографический, документальный, фактографический и аналитический. Например, чтобы найти информационный источник (документ или издание), надо знать определенную совокупность библиографических данных (фактов), характеризующих его, отличающих от многих других: хотя бы от написанных тем же автором, на одну и ту же тему и т. д. Следовательно, нужно сначала осуществить библиографический поиск. И, наоборот, чтобы провести фактографический поиск в какой-либо отрасли знаний или практики, требуется сначала найти те литературные источники (документы, издания), в которых могут быть интересующие нас факты. Поэтому сначала надо провести библиографический и документальный поиск.
Этапы информационного поиска:
1. Уточнение информационной потребности и формулировка запроса.
2. Выбор источников информации, соответствующих запросу пользователя.
3. Извлечение информации из информационных массивов
4. Оценка результатов поиска.
Уточнение информационной потребности.
Информационная потребность – это тема, о которой пользователь хочет знать больше. Ее следует отличать от запроса, т.е. оттого, что пользователь вводить в строку поиска. Информационная потребность должна быть выражена средствами, которые "понимает" ИПС.
Нередко человек, осуществляющий поиск, имеет самое приблизительное представление об интересующей его тематике, либо он ищет документ, который сам собирается написать. Пользователю обычно требуется найти не какой-то конкретный, заранее известный документ, а некие сведения (факты), знание которых необходимо для решения поставленной задачи.
Формулировка запроса по теме должна быть оформлена в виде ключевых слов или словосочетаний. Ключевые слова – это набор слов или словосочетаний, отражающих основную тему документа и описывающих информационную потребность.
Точность и полнота поиска зависят не только от характеристик самой ИПС, но и от того, как создается запрос. Современные системы еще не обладают искусственным
интеллектом и не могут задать вам уточняющие вопросы, поэтому удовлетворяющий вашу информационную потребность ответ может быть получен только на очень точно сформулированный запрос, но далеко не всегда пользователь может четко и однозначно сформулировать именно тот набор ключевых слов, который и приведет его к искомому результату. Основные проблемы связаны с неудачным выбором ключевых слов и просмотром ненужных документов, полученных в списке результатов запроса.
И поэтому, поиск по возможности лучше вести по нескольким словам, их сочетаниям, а иногда и по конкретным фразам. Все служебные слова (предлоги, союзы, частицы и т.п.) следует считать не ключевыми, термины, частота встречаемости которых мала не следует включать в поиск, часто встречающиеся (Москва) – надо употреблять в сочетании с другими словами сужающими их значение.
Выбор источников информации, соответствующих запросу пользователя включает определение, какой тип информационного источника в каждой конкретной ситуации будет соответствовать ИП: источник на традиционных носителях или доступ к информации в режиме онлайн, в т.ч. и подписные БД.
Извлечение информации из информационных массивов.
После четкого определения границ запроса и выбора источника информации следующим этапом справочного процесса является выбор модели поиска для извлечения информации . Исторически первой моделью информационного поиска является булева модель .
Основным достоинством ее является простота, способность работать с большими объемами информации и высокая скорость выполнения поисковых запросов. По этой причине на основе булевой модели было построено большое количество поисковых систем.
Оценка результатов поиска.
Два основных понятия, в которых дается оценка эффективности поиска, определены в ГОСТ 7.73-96. Релевантными (
В автоматизированных системах поиск основан на формальной релевантности. Если поисковый запрос сформулирован точно, подробно, то релевантный ответ, скорее всего будет пертинентным. Идеальная ИПС должна выдавать документы, содержательно релевантные запросу, и ничего кроме них. Однако на практике это обычно не достигается, наблюдаются молчание ИПС (невыдача некоторого количества релевантных документов) и шум (выдача лишних документов).
Качество поиска в информационно-поисковых системах обычно характеризуется двумя критериями – полнотой и точностью. Полнота поиска определяется общим количеством найденных документов, а точность – соотношением между найденными релевантными и не релевантными документами.
Важно иметь ввиду, что информация, содержащаяся в научных документах, объективно подчиняется законам рассеяния. Данные характеристики зависят друг от друга, при увеличении полноты, как правило, снижается точность и наоборот.
В реальных системах коэффициент полноты достигает 70%, а коэффициент точности поиска колеблется в очень широких пределах, иногда снижаясь до 10%. Величины этих коэффициентов зависят от целого ряда факторов: как внутренних свойств собственно поисковой системы (объема и характеристик информационного массива, информационно-поискового языка, критерия выдачи), так и от многих "внешних" условий: степени специфичности информационных запросов, способности пользователя правильно сформулировать свои информационные потребности на естественном языке, правильности построения конкретного запроса, а также от субъективного представления пользователя о том, что такое нужная ему информация. Из-за ошибок и неточностей, возникающих на каждом из этапов работы, как пользователя, так и системы, результаты могут сильно отличаться от того, что хотел получить пользователь, обращаясь к ИПС.
Важно иметь ввиду, что информация, содержащаяся в научных документах, объективно подчиняется законам рассеяния.
Данные характеристики зависят друг от друга, при увеличении полноты, как правило, снижается точность и наоборот.
В реальных системах коэффициент полноты достигает 70%, а коэффициент точности поиска колеблется в очень широких пределах, иногда снижаясь до 10%. Величины этих коэффициентов зависят от целого ряда факторов: как внутренних свойств собственно поисковой системы (объема и характеристик информационного массива, информационно-поискового языка, критерия выдачи), так и от многих "внешних" условий: степени специфичности информационных запросов, способности пользователя правильно сформулировать свои информационные потребности на естественном языке, правильности построения конкретного запроса, а также от субъективного представления пользователя о том, что такое нужная ему информация. Из-за ошибок и неточностей, возникающих на каждом из этапов работы, как пользователя, так и системы, результаты могут сильно отличаться от того, что хотел получить пользователь, обращаясь к ИПС.
Согласно четвертой парадигме, сформулированной Джимом Греем в 2007 году, данные, полученные в результате наблюдений, деятельности людей в промышленности, социальной сфере, экономике и т.д., а также в ходе измерений высокотехнологичными инструментами формируются в процессе интенсивного анализа данных. Увеличение объема и разнообразия данных в различных областях и интенсивное использование данных приводит к разработке методов и инструментов для анализа данных.
Поиск информации — это процесс извлечения структурированных данных из неструктурированных или плохо структурированных документов. Извлечение информации — это разновидность информационного поиска. Изучение структурных данных и комплексных исследований является результатом исследований и применения различных методов и средств. Целевая схема представляет собой схему структуры данных, которая предоставляет информацию, необходимую для решения определенных проблем, извлеченную из различных разнородных информационных ресурсов.
Извлечение информации в основном связано с идентификацией сущностей и отношений. Это один из ключевых этапов предварительной обработки текста, необходимый для реализации более сложных моделей и программ. Сущности должны быть отнесены к некоторым категориям. Особое место в извлечении сущностей занимают проблемы идентификации именованных сущностей и кореференции (разрешение анафорических связей). [1, c 77].
Процесс извлечения информации из разноструктурированных данных и ее приведения к целевой схеме
На рис 1. Изображены основные этапы процесса извлечения сущностей из исходных разноструктурированных коллекций данных, их интеграции для последующего анализа полученной информации для анализа при решении прикладной задачи (класса задач).
Процесс начинается с поиска информационных ресурсов, релевантных задаче, и извлечения из них исходных коллекций данных. Информационные ресурсы могут содержать структурированные данные (базы данных, представленные в различных моделях), слабоструктурированные данные (например, данные из социальных сетей), неструктурированные данные (текст).
На следующем этапе неструктурированные данные (тексты) пропускаются через средства анализа текста, например, Pullenti, Метафраз, AQL, SystemT. В то же время из текстов извлекаются сущности, например, люди, организации, территориальные образования и т.д. Сущности, извлекаемые из текста одним определенным инструментальным средством, всегда соответствуют одной и той же структуре, определенной форматом вывода средства анализа текста. Эта структура называется исходной схемой данных.
Следующим шагом является интеграция собранных структурированных коллекций и сущностей, извлеченных из текстов, в общую интегрированную коллекцию. Интеграция информации включает в себя несколько второстепенных этапов.
Сравнение элементов схем источника и целевой схемы может производиться с использованием различных методов и средств автоматизации. На основании сравнения между элементов схем создаются правила преобразования данных из исходных схем в целевую. Эти правила затем применяются для трансформации данных. Чтобы установить отношения между сущностями из разных коллекций, используются методы разрешения сущностей, то есть установления сходства сущностей. Слияние данных — это формирование интегрированного представления информации об одной сущности реального мира, получаемой из различных источников данных.
Нужна помощь в написании статьи?
Мы - биржа профессиональных авторов (преподавателей и доцентов вузов). Пишем статьи РИНЦ, ВАК, Scopus. Помогаем в публикации. Правки вносим бесплатно.
Наконец, последний этап процесса — это анализ и визуализация информации из интегрированной коллекции с использованием существующих средств анализа данных.
Чтобы обеспечить масштабирование процесса с точки зрения объема извлеченных и интегрированных данных, необходимо реализовать его на основе платформы распределенного хранения и обработки больших объемов данных. [2, c 391]
В данной работе в качестве такой платформы рассмотрим Apache Hadoop. Hadoop включает, в частности, распределенную файловую систему HDFS и менеджер ресурсов YARN. В различных дистрибутивах Hadoop встроены некоторые средства анализа текстов. Так, например, в дистрибутив IBM BigInsights встроен язык разработки экстракторов текстовой аналитики AQL. Для обеспечения реализации методов интеграции данных над Hadoop (включая разрешение и слияние сущностей) может использоваться декларативный язык HIL, ориентированный на разрешение и слияние сущностей в Hadoop-инфраструктуре HIL может использоваться для спецификации правил трансформации данных из исходных схем в целевую, с дальнейшим выполнением этих трансформаций в среде Hadoop. HIL компилируется в язык Jaql, который в свою очередь, автоматически переписывается в MapReduce-программы.
В задачах обработки текста на естественном языке выделяют четыре типа функций потерь, характеризующих потери при неправильном принятии решений на основе наблюдаемых данных:
1) функции потерь, реально существующие в мире, например, потеря денег, времени и т.д. (обычно они не известны);
2) функции экспертной оценки (адекватность оценки, релевантность и т.д.);
3) автоматические методы оценки на основе корреляции (например, BLEU – Bilingual Evaluation Understudy, ROUGE – RecallOriented Understudy For Gisting Evaluation, WER – Word Error Rate, mAP – Mean Average Precision). Эти методы предполагают сравнение с более высокими результатами. В начале работы алгоритмов требуется участие экспертов;
Заключение
Таким образом, извлечение информации является ключевым этапом в построении сложных систем информационного поиска, в том числе вопросно-ответных системах. Несмотря на разнообразие существующих методов извлечения информации из неструктурированных данных, а именно текстовых корпусов, до сих пор не решены ключевые проблемы информационного поиска, связанные с автоматическим построением баз знаний.
Список литературы:
Л. М. Ермакова. Методы извлечения информации из текста Л. Пермский государственный национальный исследовательский университет, Россия, Пермь, 2012.
Брюхов Д.О., Скворцов Н. А. Извлечение информации из коллекций русскоязычных текстовых документов в среде Hadoop, Россия, Пермь 2014.
Нужна помощь в написании статьи?
Мы - биржа профессиональных авторов (преподавателей и доцентов вузов). Пишем статьи РИНЦ, ВАК, Scopus. Помогаем в публикации. Правки вносим бесплатно.
Сбор и регистрация информации происходят по-разному в различных объектах. Наиболее сложна эта процедура в автоматизированных управленческих процессах промышленных предприятий, фирм и т.п., где производятся сбор и регистрация первичной учетной информации, отражающей производственно-хозяйственную деятельность объекта. Не менее сложна эта процедура и в финансовых органах, где происходит оформление движения денежных ресурсов.
Особое значение при этом придается достоверности, полноте и своевременности первичной информации. На предприятии сбор и регистрация информации происходят при выполнении различных хозяйственных операций (прием готовой продукции, получение и отпуск материалов и т.п.), в банках – при совершении финансово-кредитных операций с юридическими и физическими лицами. Учетные данные могут возникать на рабочих местах в результате подсчета количества обработанных деталей, прошедших сборку узлов, изделий, выявления брака и т.д.
В процессе сбора фактической информации производятся измерение, подсчет, взвешивание материальных объектов, подсчет денежных купюр, получение временных и количественных характеристик работы отдельных исполнителей. Сбор информации, как правило, регистрируется, т.е. информация фиксируется на материальном носителе (документе, машинном носителе) вводом в ПЭВМ. Запись в первичные документы в основном осуществляется вручную, поэтому процедуры сбора и регистрации остаются пока наиболее трудоемкими, а процесс автоматизации документооборота – по-прежнему актуальным.
В условиях автоматизации управления предприятием особое внимание придается использованию технических средств сбора и регистрации информации, совмещающих операции количественного измерения, регистрации, накопления и передачи информации по каналам связи, ввод ее непосредственно в ЭВМ для формирования нужных документов или накопления полученных данных в системе.
ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ
При извлечении информации важное место занимают различные формы и методы исследования данных:
• поиск ассоциаций, связанных с привязкой к какому-либо событию;
• обнаружение последовательностей событий во времени;
• выявление скрытых закономерностей по наборам данных, путем определения причинно-следственных связей между значениями определенных косвенных параметров исследуемого объекта (ситуации, процесса);
• оценка важности (влияния) параметров на развитие ситуации;
• классифицирование (распознавание), осуществляемое путем поиска критериев, по которым можно было бы относить объект (события, ситуации, процессы) к той или иной категории;
• кластеризация, основанная на группировании объектов по каким-либо признакам;
• прогнозирование событий и ситуаций.
Следует упомянуть неоднородность (разнородность) информационных ресурсов, характерную для многих предметных областей. Одним из путей решения данной проблемы является объектно-ориентированный подход, наиболее распространенный в настоящее время. Кратко рассмотрим его основные положения.
Декомпозиция на основе объектно-ориентированного подхода основана на выделении следующих основных понятий: объект, класс, экземпляр.
Объект — это абстракция множества предметов реального мира, обладающих одинаковыми характеристиками и законами поведения. Объект характеризует собой типичный неопределенный элемент такого множества. Основной характеристикой объекта является состав его атрибутов (свойств).
Атрибуты — это специальные объекты, посредствомкоторыхможно задать правила описания свойств других объектов.
Экземпляр объекта — это конкретный элемент множества. Например, объектом может являться государственный номер автомобиля, а экземпляром этого объекта — конкретный номер К 173 ПА.
Класс — это множество предметов реального мира, связанных общностью структуры и поведением.Элемент класса — это конкретный элемент данного множества. Например, класс регистрационных номеров автомобиля.
Важная особенность объектно-ориентированного подхода связана с понятием инкапсуляции, обозначающим сокрытие данных и методов (действий с объектом) в качестве собственных ресурсов объекта.
Понятия полиморфизма и наследования определяют эволюцию объектно-ориентированной системы, что подразумевает определение новых классов объектов на основе базовых.
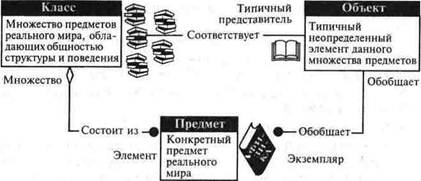
Т и с. 4.2. Отношения между классами, объектами и предметами реального мира
Полиморфизм интерпретируется как способность объекта принадлежать более чем одному типу.
Наследование выражает возможность определения новых классов на основе существующих с возможностью добавления или переопределения данных и методов.
- Извлечение информации (англ. information extraction) — это задача автоматического извлечения (построения) структурированных данных из неструктурированных или слабоструктурированных машиночитаемых документов.
* MUC-1 (1987), MUC-2 (1989): Военно-морские операции.
* MUC-3 (1991), MUC-4 (1992): Терроризм в латиноамериканских странах.
* MUC-5 (1993): Венчурные операции в области микроэлектроники.
* MUC-6 (1995): Новостные статьи об изменениях в управляющих процессах.
MUC-7 (1998): Отчёты о запусках спутников.Тексты на естественном языке могут потребовать некоего предварительного преобразования на язык (например, RDF — Resource Description Framework), понятный для компьютера.
Типичные подзадачи извлечения информации:
* Распознавание именованных элементов (сущностей), например: имён людей, названий организаций, географических названий, событий, временны́х и денежных обозначений и пр.
* Разрешение анафоры и кореференций : поиск связей, относящихся к одному и тому же объекту. Типичный случай таких ссылок — местоименная анафора.
* Выделение терминологии: нахождение для данного текста ключевых слов и словосочетаний (коллокаций).
Связанные понятия
Распределённая система — система, для которой отношения местоположений элементов (или групп элементов) играют существенную роль с точки зрения функционирования системы, а, следовательно, и с точки зрения анализа и синтеза системы.
Обработка естественного языка (Natural Language Processing, NLP) — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез — генерацию грамотного текста. Решение этих проблем будет означать создание более удобной формы взаимодействия компьютера и человека.
База знаний (БЗ; англ. knowledge base, KB) — база данных, содержащая правила вывода и информацию о человеческом опыте и знаниях в некоторой предметной области (ISO/IEC/IEEE 24765-2010, ISO/IEC 2382-1:1993). В самообучающихся системах база знаний также содержит информацию, являющуюся результатом решения предыдущих задач.
Визуализация данных — это представление данных в виде, который обеспечивает наиболее эффективную работу человека по их изучению. Визуализация данных находит широкое применение в научных и статистических исследованиях (в частности, в прогнозировании, интеллектуальном анализе данных, бизнес-анализе), в педагогическом дизайне для обучения и тестирования, в новостных сводках и аналитических обзорах. Визуализация данных связана с визуализацией информации, инфографикой, визуализацией научных данных, разведочным.
Исчисление процессов или алгебра процессов — семейство связанных подходов к формальному моделированию параллельных систем.
Упоминания в литературе
На уровне общества и государства информационная безопасность характеризуется степенью их защищенности и, следовательно, устойчивостью основных сфер жизнедеятельности (экономики, науки, техносферы, сферы управления, военного дела, общественного сознания и т. д.) по отношению к опасным, дестабилизирующим, деструктивным, ущемляющим интересы страны информационным воздействиям на этапах как внедрения, так и извлечения информации . Состояние информационной безопасности определяется способностью нейтрализовать такие воздействия. Становление информационного общества происходит в результате воздействия информационных и телекоммуникационных технологий на экономику, социальную структуру, право, культуру, государство. Современные компьютеры, глобальные информационные сети и сетевые технологии сильно изменили нашу жизнь, но вместе с новыми возможностями у нас появились и новые риски. В условиях продолжающейся научно-технической революции в области вычислительной техники и телекоммуникаций, глобализации процессов экономического и политического развития человеческого общества проблемы безопасности развития личности, функционирования общественных структур и органов государства в информационной сфере становятся все более актуальными, затрагивая все более широкий круг субъектов информационных отношений[84].
Связанные понятия (продолжение)
Модель данных — это абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь. Эти объекты позволяют моделировать структуру данных, а операторы — поведение данных.
Схема базы данных включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных.
Представление знаний — вопрос, возникающий в когнитологии (науке о мышлении), в информатике и в исследованиях искусственного интеллекта.
Язы́к запро́сов — это искусственный язык, на котором делаются запросы к базам данных и другим информационным системам, особенно к информационно-поисковым системам.
Выделение признаков — это процесс снижения размерности, в котором исходный набор сырых переменных сокращается до более управляемых групп (признаков) для дальнейшей обработки, оставаясь при этом достаточным набором для точного и полного описания исходного набора данных.
Конте́йнер в программировании — тип, позволяющий инкапсулировать в себе объекты других типов. Контейнеры, в отличие от коллекций, реализуют конкретную структуру данных.
Информацио́нный по́иск (англ. information retrieval) — процесс поиска неструктурированной документальной информации, удовлетворяющей информационные потребности, и наука об этом поиске.
Предме́тная о́бласть — множество всех предметов, свойства которых и отношения между которыми рассматриваются в научной теории. В логике — подразумеваемая область возможных значений предметных переменных логического языка.
Формальная верификация или формальное доказательство — формальное доказательство соответствия или несоответствия формального предмета верификации его формальному описанию. Предметом выступают алгоритмы, программы и другие доказательства.
Документа́ция на программное обеспечение — печатные руководства пользователя, диалоговая (оперативная) документация и справочный текст, описывающие, как пользоваться программным продуктом.
Анализ данных — область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений. Анализ данных имеет множество аспектов и подходов, охватывает разные методы в различных областях науки и деятельности.
Вопросно-ответная система (QA-система; от англ. QA — англ. Question-answering system) — информационная система, способная принимать вопросы и отвечать на них на естественном языке, другими словами, это система с естественно-языковым интерфейсом.
Семанти́ческая паути́на (англ. semantic web) — это общедоступная глобальная семантическая сеть, формируемая на базе Всемирной паутины путём стандартизации представления информации в виде, пригодном для машинной обработки.
Скрытая марковская модель (СММ) — статистическая модель, имитирующая работу процесса, похожего на марковский процесс с неизвестными параметрами, и задачей ставится разгадывание неизвестных параметров на основе наблюдаемых. Полученные параметры могут быть использованы в дальнейшем анализе, например, для распознавания образов. СММ может быть рассмотрена как простейшая байесовская сеть доверия.
Храни́лище да́нных (англ. Data Warehouse) — предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Строится на базе систем управления базами данных и систем поддержки принятия решений. Данные, поступающие в хранилище данных, как правило, доступны только для чтения.
Формальные методы занимаются приложением довольно широкого класса фундаментальных техник теоретической информатики: разные исчисления логики, формальных языков, теории автоматов, формальной семантики, систем типов и алгебраических типов данных.
Требования к программному обеспечению — совокупность утверждений относительно атрибутов, свойств или качеств программной системы, подлежащей реализации. Создаются в процессе разработки требований к программному обеспечению, в результате анализа требований.
Аспе́ктно-ориенти́рованное программи́рование (АОП) — парадигма программирования, основанная на идее разделения функциональности для улучшения разбиения программы на модули.
Полнотекстовый поиск (англ. Full text searching, фр. Recherche en texte integral) — автоматизированный поиск документов, при котором поиск ведётся не по именам документов, а по их содержимому, всему или существенной части.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка.
Проектирование программного обеспечения — процесс создания проекта программного обеспечения (ПО), а также дисциплина, изучающая методы проектирования.
Ка́чество програ́ммного обеспечения — способность программного продукта при заданных условиях удовлетворять установленным или предполагаемым потребностям (ISO/IEC 25000:2014).
Ассоциативная память (АП) или ассоциативное запоминающее устройство (АЗУ) является особым видом машинной памяти, используемой в приложениях очень быстрого поиска. Известна также как память, адресуемая по содержимому, ассоциативное запоминающее устройство, контентно-адресуемая память или ассоциативный массив, хотя последний термин чаще используется в программировании для обозначения структуры данных (Hannum и др., 2004).
Архитектура программного обеспечения (англ. software architecture) — совокупность важнейших решений об организации программной системы. Архитектура включает.
Сема́нтика в программировании — дисциплина, изучающая формализации значений конструкций языков программирования посредством построения их формальных математических моделей. В качестве инструментов построения таких моделей могут использоваться различные средства, например, математическая логика, λ-исчисление, теория множеств, теория категорий, теория моделей, универсальная алгебра. Формализация семантики языка программирования может использоваться как для описания языка, определения свойств языка.
По́ле кла́сса или атрибу́т (переменная-член, data member, class field, instance variable) в объектно-ориентированном программировании — переменная, связанная с классом или объектом. Все данные объекта хранятся в его полях. Доступ к полям осуществляется по их имени. Обычно тип данных каждого поля задаётся в описании класса, членом которого является поле.
Фолксоно́мия (англ. folksonomy, от folk — народный + taxonomy таксономия, от гр. расположение по порядку + закон) — народная классификация, практика совместной категоризации информации (текстов, ссылок, фото, видеоклипов и т. п.) посредством произвольно выбираемых меток, называемых тегами.
Примитивный (встроенный, базовый) тип — тип данных, предоставляемый языком программирования как базовая встроенная единица языка.
Паке́т прикладны́х програ́мм (аббр. ППП, англ. application package) или паке́т програ́мм — набор взаимосвязанных модулей, предназначенных для решения задач определённого класса некоторой предметной области. По смыслу ППП было бы правильнее назвать пакетом модулей вместо устоявшегося термина пакет программ. Отличается от библиотеки тем, что создание библиотеки не ставит целью полностью покрыть нужды предметной области, так как приложение может использовать модули нескольких библиотек. Требования же.
Логический синтез в электронике — процесс получения списка соединений логических вентилей из абстрактной модели поведения логической схемы (например, на уровне регистровых передач). Наиболее распространенный пример этого процесса — синтез спецификаций, написанных на языках описания аппаратуры. Синтез выполняют программы-синтезаторы, способные оптимизировать проект согласно различным особенностям устройства, таким как временные ограничения, площадь и используемые компоненты. Такие программы обычно.
Диагра́мма свя́зей, известная также как интелле́кт-ка́рта, ка́рта мыслей (англ. Mind map) или ассоциати́вная ка́рта — метод структуризации концепций с использованием графической записи в виде диаграммы.
Процесс разработки программного обеспечения (англ. software development process, software process) — структура, согласно которой построена разработка программного обеспечения (ПО).
Методология разработки программного обеспечения — совокупность методов, применяемых на различных стадиях жизненного цикла программного обеспечения и имеющих общий философский подход.
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Машинное обучение (англ. machine learning, ML) — класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение в процессе применения решений множества сходных задач. Для построения таких методов используются средства математической статистики, численных методов, методов оптимизации, теории вероятностей, теории графов, различные техники работы с данными в цифровой форме.
В информатике параллели́зм — это свойство систем, при котором несколько вычислений выполняются одновременно, и при этом, возможно, взаимодействуют друг с другом. Вычисления могут выполняться на нескольких ядрах одного чипа с вытесняющим разделением времени потоков на одном процессоре, либо выполняться на физически отдельных процессорах. Для выполнения параллельных вычислений разработаны ряд математических моделей, в том числе сети Петри, исчисление процессов, модели параллельных случайных доступов.
Обфуска́ция (от лат. obfuscare — затенять, затемнять; и англ. obfuscate — делать неочевидным, запутанным, сбивать с толку) или запутывание кода — приведение исходного текста или исполняемого кода программы к виду, сохраняющему её функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции.
Читайте также: