
Реферат многомерные базы данных
Обновлено: 07.07.2024
Сегодня все большее число организаций приходит к пониманиютого, что без наличия своевременной и объективной информации о состоянии рынка,прогнозирования его перспектив, постоянной оценки эффективностифункционирования собственных структур и анализа взаимоотношений с бизнес-партнерами и конкурентами их дальнейшее развитиестановится практически невозможным. Поэтому не удивительно то внимание, котороесегодня уделяется средствам реализации и концепциям построения информационныхсистем, ориентированных на аналитическую обработку данных. И в первую очередьэто касается систем управления базами данных, основанными на многомерномподходе — МСУБД.
Следует заметить, что МСУБД не являются изобретениемдевяностых годов, а сам многомерный подход возник практически одновременно ипараллельно с реляционным. Однако, только начиная с середины девяностых годов,а точнее с 1993 г., интерес к МСУБД начал приобретать всеобщий характер. Именнов этом году появилась новая программная статья одного из основоположниковреляционного подхода Э. Кодда [1], в которой он сформулировал 12 основныхтребований к средствам реализации OLAP (табл. 1) и произвел анализ некоторыхкак субъективных, так и вполне объективных недостатков реляционного подхода,затрудняющих его использование в задачах, требующих сложной аналитическойобработки данных.
Многомерное представление данных
Средства должны поддерживать многомерный на концептуальном уровне взгляд на данные.
Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда они берутся.
Средства должны сами выбирать и связываться с наилучшим для формирования ответа на данный запрос источником данных. Средства должны обеспечивать автоматическое отображение их собственной логической схемы в различные гетерогенные источники данных.
Производительность практически не должна зависеть от количества Измерений в запросе.
Поддержка архитектуры клиент-сервер
Средства должны работать в архитектуре клиент-сервер.
Равноправность всех измерений
Ни одно из измерений не должно быть базовым, все они должны быть равноправными (симметричными).
Динамическая обработка разреженных матриц
Неопределенные значения должны храниться и обрабатываться наиболее эффективным способом.
Поддержка многопользовательского режима работы с данными
Средства должны обеспечивать возможность работать более чем одному пользователю.
Поддержка операций на основе различных измерений
Все многомерные операции (например Агрегация) должны единообразно и согласованно применяться к любому числу любых измерений.
Простота манипулирования данными
Средства должны иметь максимально удобный, естественный и комфортный пользовательский интерфейс.
Развитые средства представления данных
Средства должны поддерживать различные способы визуализации (представления) данных.
Неограниченное число измерений и уровней агрегации данных
Не должно быть ограничений на число поддерживаемых Измерений.
Таблица1. (12 правил оценки средств для OLAP).
Набор этих требований, послуживших де-факто определениемOLAP, достаточно часто вызывает различные нарекания, так как здесь смешаны:
Многомерное представление данных и OLAP уже стали сегодняодними из наиболее широко распространенных концепций построения аналитическихсистем.
Требования к средствамреализации систем оперативной и аналитической обработки данных
При первом знакомстве с многомерным подходом к организацииданных достаточно часто возникают два противоречивых вопроса.
Для чего собственнонужны МСУБД и нужно ли тратить время и средства на их освоение и приобретение,если все те же задачи можно решить и средствами традиционных РСУБД?
Почему МСУБДограничивают себя исключительно приложениями, ориентированными на анализ данныхи почему бы на их основе не реализовывать традиционные системы оперативнойобработки данных?
Другим неотъемлемым свойством Исторических данных являетсяобязательная спецификация Времени, которому эти данные соответствуют. ПричемВремя является не только наиболее часто используемым критерием выборки, но иодним из основных критериев, по которому данные упорядочиваются в процессеобработки и представления пользователю. А это накладывает соответствующиетребования как на используемые механизмы хранения и доступа:
для уменьшения времени обработки запросов желательно, чтобыуже в БД данные хранились (были предварительно отсортированы) в том порядке, вкотором они наиболее часто запрашиваются;
так и на языки описания и манипулирования данными, например:
во многих организациях используются как общепринятые, так исобственные календарные циклы (финансовый год может начинаться не в январе каккалендарный, а, например, в июне);
время является стандартным параметром практически любойаналитической, статистической или финансовой функции (прогноз, нарастающийитог, переходящий запас, скользящее среднее и т.д.).
Прогнозируемые данные.Когда говорится о неизменности и статичности данных в аналитических системах,имеется в виду неизменность исключительно Исторических данных (данных,описывающих уже произошедшие события). Такое предположение ни в коем случае нераспространяется на Прогнозируемые данные (данные о событии, которое еще непроисходило). И этот момент является весьма существенным.
потребуется не только вычислить новое, еще не существующеезначение Объема Продаж, для еще не наступившего июня 1997 г., но и предварительновычислить гипотетическое значение Объема продаж, за уже прошедший июнь 1996 г.
В свою очередь, к оперативным данным, отражающим состояниенекоторой предметной области в данный текущий момент времени, не применимытакие понятия, как прошлое или будущее. Для них существует единственное понятие- сейчас, а их основное назначение — адекватное детализированное отображениетекущих событий (изменений), происходящих в реальном мире. Например:
менеджера Петроваперевели из Восточного филиала фирмы в Западный.
Вместе с тем изменчивость Оперативных данных ни в коемслучае не подразумевает их близость по свойствам к Прогнозируемым данным. Междуними существует коренное различие. Оперативным данным, в отличие отПрогнозируемых, присуще свойство общезначимости, иобычно все пользователи работают с одним и тем же экземпляром данных. Послетого как в оперативную систему заведены данные о том, что Петров продал ещеодин автомобиль, эта информация сразу же должна стать доступной всемзаинтересованным в ней пользователям. Причем до тех пор, пока это изменение незафиксировано, ни какой другой пользователь не имеет права изменять строку синформацией о продажах Петрова.
Существенно иная ситуация с Прогнозируемыми данными. Ониносят, скорее, личностный (индивидуальный) характер. Вполне реальна ситуация,когда коммерческий директор фирмы и управляющий региональным отделениемодновременно решили получить прогноз возможного объема продаж на 1997 г. дляПетрова. Однако каждый из них делает собственный прогноз. Каждый из них можетиспользовать свои функции прогнозирования, и, даже если применяется один и тотже метод (или функция), прогноз может основываться на различных историческихинтервалах, и результаты, по всей вероятности, будут различны. Поэтому каждыйиз них работает с собственным экземпляром Прогнозируемых данных (хотя этиданные и относятся формально к одной и той же личности, виду деятельности ивремени), и эти данные не должны смешиваться. Конечно, вполне вероятно, чтоодин из этих вариантов будет принят в качестве плановых показателей дляПетрова. Но после того, как Прогноз утвержден в качестве Плана, данные простоперейдут в другую категорию и станут Историческими.
Следует заметить, что в области информационных технологийвсегда существовало два взаимодополняющих друг друга направления развития:
транзакционную или операционную) обработку данных;
И практически до настоящего времени, когда говорилось остремительном росте числа реализаций информационных систем, прежде всегоимелись в виду системы, предназначенные исключительно для оперативной обработкиданных. Именно для этого изначально и создавались и на это были ориентированыРСУБД, которые сегодня стали основным средством построения информационныхсистем самого различного масштаба и назначения. Но, являясь высокоэффективнымсредством реализации систем оперативной обработки данных, РСУБД оказались менееэффективными в задачах аналитической обработки.
Конечно, средствами традиционных РСУБД и на основанииданных, хранящихся в реляционной БД, можно построить заранее регламентированныйаналитический отчет (табл. 2) и даже Прогноз об ожидаемом объеме продажавтомобилей на следующий год.
Сколько? Как? Когда?
Почему? Что будет если?
Регламентированный отчет, диаграмма
Последовательность интерактивных отчетов, диаграмм, экранных форм; динамическое изменение уровней агрегации и срезов данных
Уровень аналитических требований
Тип экранных форм
В основном определенный заранее, регламентированный
Уровень агрегации данных
Детализированные и суммарные
В основном суммарные
Исторические и текущие
Исторические, текущие и прогнозируемые
В основном предсказуемые
Непредсказуемые, от случаю к случаю
Работа с историческими и текущими данными, регламентированная аналитическая обработка и построение прогнозов
Работа с историческими, текущими и прогнозируемыми данными. Многопроходный анализ, моделирование
Таблица2. (Сравнение характеристик статического (регламентированного) идинамического анализа).
Но, как правило, после просмотра такого отчета упользователя (аналитика) появится не готовый ответ, а новая серия вопросов.Однако, если бы ему захотелось получить ответ на новый вопрос, он может ждатьего часы, а иногда и дни. Обычно каждый новый непредусмотренный заранее запросдолжен быть сначала формально описан, передан программисту, запрограммирован и,наконец, выполнен. Но после того, как аналитик получит долгожданный ответ,достаточно часто оказывается, что решение не могло ждать и оно уже принято, иличто случается еще чаще, произошло взаимное непонимание и получен ответ на несовсем тот вопрос. Впрочем, не намного меньшее время затрачивается и наполучение ответа и на заранее описанный и запрограммированный запрос.
Более того, для решения большинства аналитических задач,скорее всего, потребуется использование внешних по отношению к РСУБД,специализированных инструментальных средств. Выполнение большинствааналитических функций (например построение прогноза) невозможно безпредположения об упорядоченности данных. Но в РСУБД предполагается, что данныев БД не упорядочены (или, более точно, упорядочены случайным образом).Естественно, здесь имеется возможность после выборки данных из БД выполнить ихсортировку и затем аналитическую функцию. Но это потребует дополнительныхзатрат времени на сортировку. Сортировка должна будет проводиться каждый разпри обращении к этой функции, и, самое главное, такая функция может бытьопределена и использована только во внешнем по отношению к РСУБДпользовательском приложении и не может быть встроенной функцией языка SQL.
Не менее важно и то, что многие критически необходимые дляоперативных систем функциональные возможности, реализуемые в РСУБД, являютсяизбыточными для аналитических задач. Например, в аналитических системах (табл.3) данные обычно загружаются достаточно большими порциями из различных внешнихисточников (оперативных БД, заранее подготовленных плоских файлов, электронныхтаблиц). И, как правило, время и последовательность работ по загрузке,резервированию и обновлению данных могут быть спланированы заранее. Поэтому втаких системах обычно не требуются и, соответственно, не предусматриваются,например, развитые средства обеспечения целостности, восстановления иустранения взаимных блокировок и т.д. А это не только существенно облегчает иупрощает сами средства реализации, но и значительно снижает внутренниенакладные расходы и, следовательно, повышает производительность при выполненииих основной целевой функции — поиске и выборке данных.
Высокая частота, маленькими порциями
Малая частота, большими порциями
В основном внутренние
В основном внешние (по отношению к аналитической системе)
Текущие (за период от нескольких месяцев до одного года)
В основном исторические (за период в несколько лет, десятки лет) и прогнозируемые
Уровень агрегации данных
В основном агрегированные данные
Фиксация, оперативный поиск и обработка данных
Работа с историческими данными, аналитическая обработка, прогнозирование и моделирование
Таблица3. (Характеристики данных в системах, ориентированных на оперативную ианалитическую обработку данных).
Многомерная модель данных
На самом деле все сказанное в этом утверждении — чистаяправда, и пользователю, занимающемуся анализом, действительно присуща многомерность мышления. Весь вопрос в том, что понимать подИзмерением.
Двухмерноепредставление данных конечному пользователю
Достаточно очевидно, что даже при небольших объемах данныхотчет, представленный в виде двухмерной таблицы (Модели автомобиля по оси Y иВремя по оси X), нагляднее и информативнее отчета с реляционной построчнойформой организации (рис. 1).
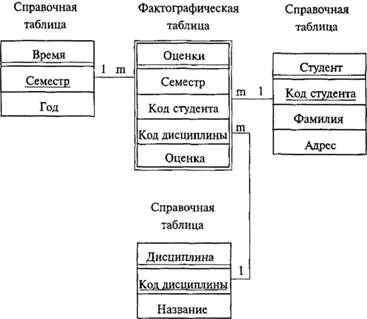
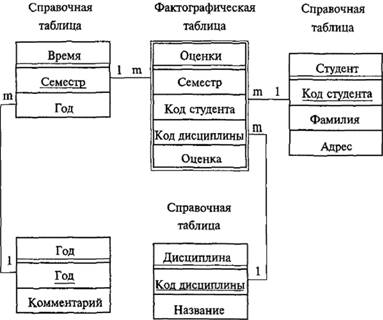
Хранимые классы объектов наследуются от системного класса % Library. Persistent и способны длительно храниться в памяти объекта. Экземпляры таких классов обладают однозначными объектными идентификаторами OID. Хранимый объект может использоваться и как свойство класса (столбец таблицы) другого объекта. Иными словами, возможна ссылка на этот объект, что соответствует связи I: М двух таблиц… Читать ещё >
Многомерная модель данных ( реферат , курсовая , диплом , контрольная )
Вообще говоря, ММД может взаимодействовать и с реляционной БД, потому данный параграф уместен и в гл. 5. Однако взаимодействие с объектно-ориентированной моделью предпочтительнее, и потому рассмотрим ММД здесь.
Многомерная модель используется, как отмечалось ранее, в хранилищах данных. Имеются три разновидности ММД: MOLAP, ROLAP, HOLAP.
MOLAP предполагает формирование так называемого многомерного куба (гиперкуба). Трехмерный куб показан на рис. 7.4.
Каждая из координат куба называется измерением. Измерения реализуются с помощью индексов, которые, как известно, позволяют резко увеличить скорость доступа к данным. По разным оценкам, эта скорость в 10−100 раз выше, чем в реляционных моделях данных. Значение результата в многомерной модели помещается на пересечении (в ячейке) соответствующих значений измерений.

За увеличенную скорость доступа приходится платить увеличенным объемом памяти. Соотношение между полезным и потребным объемами памяти в многомерной модели данных в 5−10 раз больше, чем в реляционной модели данных. Кроме того, в ММД много пустых ячеек, и требуются специальные эффективные программы хранения значения NULL. Желательно удаление пустых ячеек. В многомерной модели выполняются четыре основные операции: агрегация (свертка) данных; дезагрегация (детализация) данных; сечение (при фиксированных значениях одного или нескольких измерений); вращение (для двумерного случая это аналог транспонирования матрицы).
ROLAP позволяет дать характеристику размерности хранилища данных (табл. 7.3).
Размерность хранилища данных
Предельный объем, Гбайт.
Число строк н фактологической таблице, млн.
Сравнение MOLAP и ROLAP дает следующие результаты:
- • MOLAP обладает высоким быстродействием, но возникают проблемы с хранением больших объемов данных;
- • ROLAP не имеет ограничений на объем данных, однако обладает гораздо меньшим быстродействием.
Отсюда возникает идея построения HOLAP, совмещающего достоинства MOLAP и ROLAP.
HOLAP. Дело в том, что все данные ХД одновременно никогда не требуются. Каждый раз используется лишь их часть. В связи с этим целесообразно данные разделить на предметные подобласти, которые называют киосками (магазинами, витринами) данных. Киоск данных [17] - специализированное тематическое хранилище, обслуживающее одно из направлений деятельности фирмы.
В этом случае центральное хранилище может быть реализовано с использованием реляционной БД, а основные данные хранятся в многочисленных киосках.
CACHE как система управления объектно-ориентированной базой данных
Покажем некоторые особенности построения объектно-ориентированной базы данных на примере СУБД CACHE.
Прежде всего обратим внимание на объектно-ориентированное (объектное) построение собственно БД в рамках СУБД CACHE, поскольку объектное построение интерфейса пользователя и алгоритма приложения подробно обсуждалось в гл. 1.
Чтобы было ясно, о чем идет речь, сведем эту терминологию в таблицу (табл. 7.4), из которой видны особенности структуры ООБД (ООСУБД).
- 1. Ячейки таблиц, как и в расширенных ОРБД, неатомарны. В качестве ячеек могут выступать коллекции (списки, массивы), что соответствует спискам (List) и многомерным наборам (MULTISET) в расширенной объектно-реляционной БД.
- 2. Связи между классами устанавливаются через указатели (OID, OREF).
- 3. Общие подтаблицы нескольких таблиц формируются как встраиваемые объекты (аналог абстрактных классов ROW, и прежде всего — ROW TYPE объектно-реляционных БД).
- 4. Предусмотрена возможность хранения больших объектов.
Сравнительная терминология
Экземпляр класса (объект).
Ссылка на хранимый объект.
Повторяющиеся поля, используемые в нескольких таблицах.
Столбец с ячейкойсписком.
Хранимая процедура или вид.
Рассмотрим построение собственно базы данных.
Классы типов данных (в том числе созданных пользователями) приписываются атрибутам (полям, свойствам) объектов (таблиц), получающим данные того или иного типа в качестве значений. Эти классы не могут содержать свойств и образовывать экземпляры, не имеют собственной идентификации (для ссылок), однако обладают методами. Каждый тип данных представляет собой класс. Классы типов данных могут создаваться и пользователями.
Имеются три формата типов данных: хранения в БД (storage), логический (logical) в памяти компьютера, отображения (display) на экране монитора. Форматы могут быть преобразованы друг в друга.
Объектом называют экземпляр класса (строку) в отличие от реализации компонента в соответствующем контейнере (как, например, в программном продукте Delphi).
Класс объектов определяет структуру данных и поведение объектов одного типа. Класс объектов характеризуется именем класса, свойствами, методами.
Хранимые классы объектов наследуются от системного класса % Library. Persistent и способны длительно храниться в памяти объекта. Экземпляры таких классов обладают однозначными объектными идентификаторами OID. Хранимый объект может использоваться и как свойство класса (столбец таблицы) другого объекта. Иными словами, возможна ссылка на этот объект, что соответствует связи I: М двух таблиц реляционной БД.
Встраиваемые классы объектов наследуют свое поведение от системного класса % Library. SerialObject и могут быть сохранены только в составе соответствующих хранимых объектов. Встроенный объект в памяти характеризуется объектной ссылкой, в базе данных хранится в последовательной форме (разновидность коллекции-массива) как часть хранимого объекта, при этом идентификатор OID отсутствует.
Построение классов объектов возможно в режиме диалога или с помощью языков программирования (командная строка, программа). В диалоговом режиме возможно использовать визуальный язык (аналог языка QBE для запросов) или сопровождающий его язык определения классов (CACHE Definition Language — CDL) — аналог языка SQL в реляционных БД.
В качестве свойств (рис. 7.8) выступают константы (независимо от класса типа), встроенные объекты, ссылки на объекты, потоки данных BLOB, коллекции, многомерные переменные, двунаправленные связи между хранимыми объектами.
Потоки данных BLOB имеют две разновидности для символьных (CHARACTERSTREAM) и двоичных (BINARYSTREAM) данных (аналогично CLOB и BLOB для гибридных ОРБД).
Коллекции могут быть списком (List Collection) и массивом (Array Collection). В их состав могут входить константы, встроенные объекты и ссылки, которые задаются соответственно % Library. ListOfDataTypes, %Library.ListOfObjects, %Library.ArrayOfDataTypes, %Library.ArrayOf Objects.

Рис. 7.8. Типы свойств В коллекции-массиве упорядочение ведется по полю, принятому в качестве ключа.
В коллекции-списке в качестве ключа выступает позиция элемента в списке.
Связь является двунаправленной — взаимные ссылки между таблицами. Они гарантируют ссылочную целостность.
Имеются временные (буферная память) и вычисляемые свойства.
Методы, как уже отмечалось, связаны с типом данных. По умолчанию принимается тип данных String.
Аргументы метода по умолчанию передаются по значению, а для передачи по ссылке аргументу должен предшествовать символ &. Методы, как и свойства, могут быть определены как public или private.
В объектной модели выделяют:
Свойства характеризуются именем класса, именем свойства, типом данных, ключевыми словами, параметрами для типов данных. Свойства могут быть открытыми (public) и закрытыми (private).
Свойство связано с набором методов, который имеет два источника:
- 1) класс свойств (методы доступа Get () и Set ());
- 2) тип данных.
Параметры класса используются при компиляции.
Запрос — операции с множествами экземпляров классов. Результат запроса доступен через специальный интерфейс обработки результатов запросов ResultSet. Запросы могут иметь форму хранимых процедур.
Индекс — путь доступа к экземпляру класса. Он используется для повышения скорости выполнения запросов. Индекс создается на основе одного или нескольких свойств (полей).
Взаимодействие описанных составных частей СУБД (БД) обеспечивается языками программирования.
В CACHE существует три вида доступа (рис. 7.9).
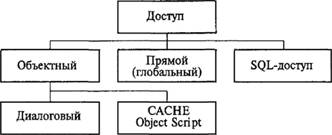
Рис. 7.9. Виды доступа в СУБД CACHE.
Объектный доступ осуществляется в диалоге или с помощью языка программирования CACHE ObjectScript.
В прямом доступе используется многомерная модель данных (ММД). Именно в многомерной структуре ядра БД хранятся данные.
Суть ММД фактически заключается в задании значений некоторой функции от множества координат.
В рамках СУБД CACHE этот факт записывается в виде A(i, j, k, l) = Аijkl.
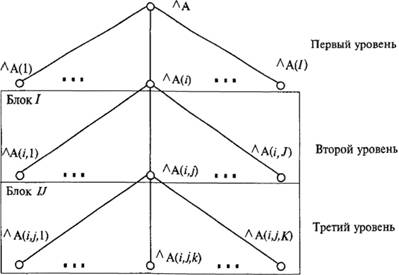
ММД не рассматривается как инструмент реализации приложений, а служит основой хранения данных и используется при построении хранилищ данных (систем OLAP).
К тому же необходимо реализовать процедуры наследования.
Таким образом, следует трансформировать язык SQL2, чтобы стало возможно оперировать с неатомарными ячейками и обеспечить процедуру наследования.
Именно по этому пути (а не по пути создания нового языка SQL3) пошли создатели СУБД CACHE.
Прежде всего следует отметить, что в рамках единой архитектуры CACHE каждый класс объектного представления является таблицей с тем же именем, а каждая таблица реляционной парадигмы — объектом. Соотношение объектов и реляционных аналогов приведено в табл. 7.4.
Заметим, что в реляционной БД нет точных аналогов методов и параметров классов и экземпляров классов, временных свойств. С другой стороны, в реляционном представлении имеют место триггеры, которые не нужны в объектной среде.
Наследование в объектном представлении трансформируется в набор исходной и наследуемой таблиц.
По умолчанию имена объектного свойства и реляционного поля одинаковы. Переименование возможно с помощью ключевого слова SQLFIELDNAME в определении объектного свойства.
Объектные свойства-константы (атомарные ячейки) могут быть временными, многомерными и вычисляемыми. Вычисляемые свойства автоматически в таблицах не отображаются. В реляционной трактовке для этого следует предусмотреть вычисляемые поля. Последние могут быть трансформированы в вычисляемые свойства.
Удобнее вычисления размещать в методах класса, которые могут вызываться и из методов вычисления свойств, и как вычисляемые поля.
Ссылки на хранимые объекты осуществляются внешним ключом.
Встроенные объекты характеризуются составным именем поля с использованием символа подчеркивания (_), т. e. Addres_Ulica.
Коллекция-список отображается в виде отдельного поля, содержащего список значений.
Коллекция-массив представляется в виде отдельной подтаблицы, связанной с основной таблицей через внешний ключ. Имя подтаблицы то же составное: _.
Объектным запросам соответствуют хранимые процедуры и виды (View). Ключевые слова — SQLPROC, SQLVIEW, SQLVIEWNAME.
Методы класса могут быть отображены в коде в виде вычисляемых полей или в виде хранимых процедур. Могут использоваться и триггеры, определяемые в объектном представлении на языке CDL или в рамках CACHE Object Architect.
Выделяют вложенный и встроенный языки SQL. Структура языка SQL2 (интерфейсного и вложенного) отображена во многих источниках.
В связи с этим акцентируем внимание на отличиях языка SQL в СУБД CACHE (CACHE SQL) от языка SQL2. Расширение вложенного языка SQL2 имеет место в следующих направлениях:
- 1) дополнительные операторы;
- 2) объект CURSOR;
- 3) поля-списки;
- 4) соединения (ссылки, отношения зависимости).
- 1. Дополнительными операторами являются:
- ? — оператор проверки по шаблону;
- (- оператор вхождения;
] - оператор следования за.
Возможно использование как одинарных, так и двойных кавычек; приставки not перед логическими операторами (not =, not).
2. В дополнение к таким объектам, как таблицы, виды, хранимые процедуры, индексы, ограничения, генераторы, триггеры, в рамках CACHE используют объект SQL2, получивший название CURSOR.
CURSOR — некоторый набор данных, формируемый чаще всего оператором select. Он содержит несколько записей и отличается от хранимых процедур, которые только вычисляют набор данных, и вида, вычисляемого каждый раз при запросе к нему. CURSOR вычисляется один раз и существует до момента его уничтожения.
Покажем процедуру создания курсора, снабдив ее соответствующими комментариями ["https://referat.bookap.info", 26].
DECLARE PersCur CURSOR.
FOR SELECT Familia, DateRogd.
/*для объявленного курсора возможно использовать предложения OPEN, FETCH, CLOSE*/.
/'считывание содержимого полей в локальные переменные, как в хранимых процедурах */.
FETCH PersCur INTO: Familia, :DateRogd.
/*следует отметить, что локальные переменные могли быть заданы и при определении курсора */.
DECLARE PersCur CURSOR.
FOR SELECT Familia, DateRogd INTO: Familia, :DateRogd.
/*в этом случае оператор извлечения данных меняется */ FETCH PersCur.
/*не используемый курсор закрывается */.
Результаты запроса могут считываться и в индексированные переменные.
FETCH PersCur INTO: а ('Результат запроса Т) в данном случае — в трехуровневую переменную; в объекты, например объект с OREF=provider.
FETCH PersCur INTO: Familia.
Set provider. Familia=Familia.
Данные могут быть вставлены в курсор (запрос оператором INSERT) из переменных и индексированных переменных (как параметров).
- 1. Обращение к полям-спискам рассматривалось ранее.
- 2. Соединения могут быть внешними и неявными.
Во внешнем соединении CACHE в предложении WHERE вместо символа = применяется символ =*.
Неявное соединение определяется не запросом пользователя, а поддерживается БД. В неявных соединениях выделяют ссылки и отношения зависимости.
В ссылке поле ссылающейся таблицы содержит первичный ключ ID записи таблицы (указатель), на которую она ссылается.
SELECT Name, Manufacturer -> Surname FROM Tovar.
SELECT Tovar.Name, Manufacturer. Surname FROM Tovar, Manufacturer.
Отношение зависимости — отношение 1: M от родительской к дочерней таблице. Каждая строка дочерней таблицы ссылается на какую-либо строку родительской таблицы (вариант внутреннего соединения). Это чаще всего относится к встроенным объектам: пусть родительская таблица имеет имя Invoice, дочерняя — Position, а ссылка на нее — Invoice Position.
Выделяют два типа зависимостей: от дочерней таблицы к родительской и от родительской к дочерней.
В первом случае оператор
WHERE Price > 100 000.
FROM lnvoice_Position, Invoice.
WHERE Price >100 000.
Во втором случае оператору.
SELECT 1nvoice_Position -> Price.
FROM Invoice WHERE Price > 100 000.
AND lnvoiceNumber= 1 003 274.
FROM Invoice, lnvoice_Position.
WHERE Invoice. lnvoiceNumber=1 003 274.
&sql (SELECT ID INTO: ID.
В качестве SQL-оператора могут выступать операторы обновления, создания объекта (CREATE) и описанный ранее CURSOR.
SQL-данные могут иметь следующие форматы: Logical (по умолчанию), ODBC, Display (не относится к свойствам-константам и значениям переменных).
&sql (SELECT $$$FIELDS.
С другой стороны, макроопределение может применяться для добавления &sql:
FOR $$$GETNEXT Quit: SQLCODE=100 Do abc,.
FOR &sql (FETCH xcur INTO: a).
Quit :SQLCODE=100 Do abc.
Здесь SQLCODE — переменная, характеризующая выполнение &sql: 0 — успешно завершено; 100 — успешно завершено, но не найдено для заданных условий ни одной записи; менее нуля — имеется ошибка.
В заключение отметим, что наиболее удобно осуществлять SQL-доступ из внешних систем, что позволяет использовать такие реляционные объекты, как отчеты. Этот внешний реляционный доступ обеспечивается сервером CACHE SQL и интерфейсом ODBC.
Перспективы развития ООБД
По сравнению с реляционными БД ООБД обладают следующими преимуществами.
- 1. Лучшие возможности моделирования систем из блоков, обладающих произвольными связями.
- 2. Легкая расширяемость структуры за счет создания новых типов данных (свойств), наследования, установления новых связей и корректировки методов.
- 3. Возможность использования рекурсивных методов при навигационном методе доступа к большим объемам данных.
- 4. Повышение производительности в 10−30 раз.
- 5. Более широкая сфера применения (например, использование в мультимедийных системах).
Преимущества ООБД [3] приведут, видимо, к очень широкому их распространению. Однако прежде следует решить ряд задач по устранению недостатков ООБД: создать гибкую структуру БД; построить четкий язык программирования; отработать синтаксис разбора запросов, в том числе — вложенных; определить несколько методов доступа к данным; отработать вопросы одновременного доступа (разрешение конфликтов при множественном наследии); определить сложный перебор данных; отработать защиту и восстановление данных; уточнить семантику (действия) операторов при динамических изменениях; встроить изменение атрибутов дочерних объектов.
Однако и после устранения названных недостатков переход к ООБД будет носить, видимо, эволюционный характер, поскольку сразу отказаться от значительного количества действующих реляционных БД будет нельзя. Такой безболезненный переход будет возможен, если первоначально в ООСУБД будет присутствовать не только объектная, но и реляционная составляющая. Более того, в ООСУБД следует ввести и многомерную модель для формирования хранилищ данных, парадигма которых хорошо согласуется с парадигмой ООБД. Именно такой подход использован в ООСУБД CACHE [38, 40].
Многомерные базы данных — технология, которая длительное время воспринималась как новинка, — сегодня является решением, которое предлагает не только высокую производительность и простоту использования, но и обеспечивает возможности, необходимые для разработки, расширения и быстрого развертывания бизнес-приложений при сокращении ИТ-затрат. Системы на основе многомерных баз данных идеально подходят для потребностей как для рынков среднего и малого бизнеса (SMB), так и крупных предприятий.
Многомерные базы данных отличаются от реляционных прежде всего трехмерностью — поддержкой неограниченного числа значений в поле, и находят свое применение там, где необходима эффективная и простая работа с большими массивами символьной информации. В многомерных СУБД данные организованы в виде упорядоченных многомерных массивов, удовлетворяющих требованиям защиты от несанкционированного доступа в организации. Они обеспечивают более быструю реакцию на запросы данных за счет того, что обращения поступают к относительно небольшим блокам данных, необходимых для конкретной группы пользователей. Для достижения сравнимой производительности реляционные системы требуют тщательной проработки схемы базы данных, определения способов индексации и специальной настройки. Ограничения SQL остаются реальностью, что не позволяет реализовать в реляционных СУБД многие встроенные функции, легко обеспечиваемые в системах основанных на многомерном представлении данных.
Основные преимущества многомерных СУБД
· Общая простота системы, что позволяет осуществлять быстрое встраивание технологий многомерных СУБД в приложения. Системы на основе многомерных баз данных требуют меньше специальных навыков по разработке и администрированию;
· Относительно низкая общая стоимость владения, а также быстрый возврат инвестиций;
· В случае использования многомерных СУБД поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных, так как многомерная база данных обеспечивает оптимизированный доступ к запрашиваемым ячейкам;
· Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным.
Наиболее коммерчески успешными из известных программных продуктов, основанных на многомерных технологиях, являются СУБД UniVerse компании Rocket Software и СУБД jBASEодноименной компании jBASE International.
Специалисты компании ГазИнтех предлагают надежные и недорогие решения, которые позволяют перейти на использование современных открытых технологий. В том числе нами разработаны уникальные решения, позволяющие использовать преимущества стразу нескольких программных продуктов многомерных СУБД. Мы оказываем услуги по настройке, системной интеграции, администрированию и поддержке, а также разработке приложений различного масштаба на платформах многомерных СУБД UniVerse и jBASE.
9. Общая характеристика и виды документальных информационных систем
Напомним, что в фактографических информационных системах единичным элементом данных, имеющим отдельное смысловое значение, является запись, образуемая конечной совокупностью полей-атрибутов. Иначе говоря, информация о предметной области представлена набором одного или нескольких типов структурированных на отдельные поля записей.
В отличие от фактографических информационных систем, единичным элементом данных в документальных информационных системах является неструктурированный на более мелкие элементы документ. В качестве неструктурированных документов в подавляющем большинстве случаев выступают, прежде всего, текстовые документы, представленные в виде текстовых файлов, хотя к классу неструктурированных документированных данных могут также относиться звуковые и графические файлы.
Основной задачей документальных информационных систем является накопление и предоставление пользователю документов, содержание, тематика, реквизиты и т. п. которых адекватны его информационным потребностям. Поэтому можно дать следующее определение документальной информационной системы — единое хранилище документов с инструментарием поиска и отбора необходимых документов. Поисковый характер документальных информационных систем исторически определил еще одно их название — информационно-поисковые системы (ИПС), хотя этот термин не совсем полно отражает специфику документальных ИС.* Соответствие найденных документов информационным потребностям пользователя называется пертинентностью. В силу теоретических и практических сложностей с формализацией смыслового содержания документов пертинентность относится скорее к качественным понятиям, хотя, как будет рассмотрено ниже, может выражаться определенными количественными показателями.
* Поиск информации (данных) осуществляется и в фактографических ИС. Таким образом термин ИПС определяет функциональное назначение ИС, но не отражает специфики представления и обработки данных. Специфика документальных ИПС заключается в том, что они удовлетворяют информационные потребности пользователя, предоставляя ему документы, в которых содержится интересующая пользователя информация.
В зависимости от особенностей реализации хранилища документов и механизмов поиска документальные ИПС можно разделить на две группы:
• системы на основе индексирования;
В семантически-навигационных системах документы, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую* (смысловую) сеть в базе документов. Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС.
В системах на основе индексирования исходные документы помещаются в базу без какого-либо дополнительного преобразования,* но при этом смысловое содержание каждого документа отображается в некоторое поисковое пространство. Процесс отображения документа в поисковое пространство называется индексированием и заключается в присвоении каждому документу некоторого индекса-координаты в поисковом пространстве. Формализованное представление (описание) индекса документа называется поисковым образом документа (ПОД). Пользователь выражает свои информационные потребности средствами и языком поискового пространства, формируя поисковый образ запроса (ПОЗ) к базе документов. Система на основе определенных критериев и способов ищет документы, поисковые образы которых соответствуют или близки поисковым образам запроса пользователя, и выдает соответствующие документы. Соответствие найденных документов запросу пользователя называется релевантностью.** Схематично общий принцип устройства и функционирования документальных ИПС на основе индексирования иллюстрируется на рис. 6.1.
* За исключением возможного сжатия (архивирования).
** На практике термин релевантность часто отождествляют с термином пертинентность, хотя в строгом отношении они различны.
Рис. 6.1. Общий принцип устройства и функционирования документальных ИПС на основе индексирования
Особенностью документальных ИПС является также то, что в их функции, как правило, включаются и задачи информационного оповещения пользователей по всем новым поступающим в систему документам, соответствующим заранее определенным информационным потребностям пользователя.* Принцип решения задач информационного оповещения в документальных ИПС на основе индексирования аналогичен принципу решения задач поиска документов по запросам и основан на отображении в поисковое пространство информационных потребностей пользователя в виде так называемых поисковых профилей пользователей (ППП). Информационно-поисковая система по мере поступления и индексирования новых документов сравнивает их образы с поисковыми профилями пользователей и принимает решение о соответствующем оповещении. Принцип решения задач информационного оповещения схематично иллюстрируется на рис. 6.2.
* Задачи информационного оповещения основаны на идеологии т.н. избирательного распространения информации (ИРИ), наработанной в библиотечном деле.
Рис. 6.2. Принцип решения задач информационного оповещения в документальных ИПС на основе индексирования
Поисковое пространство, отображающее поисковые образы документов и реализующее механизмы информационного поиска документов так же, как и в СУБД фактографических систем, строится на основе языков документальных баз данных, называемых информационно-поисковыми языками (ИПЯ). Информационно-поисковый язык представляет собой некоторую формализованную семантическую систему, предназначенную для выражения содержания документа и запросов по поиску необходимых документов. По аналогии с языками баз данных фактографических систем ИПЯ можно разделить на структурную и манипуляционную составляющие.
Структурная составляющая ИПЯ (поискового пространства) документальных ИПС на основе индексирования реализуется индексными указателями в форме информационно-поисковых каталогов, тезаурусов и генеральных указателей.

ГОСТ
Многомерный подход к представлению данных в базах был разработан практически в одно время с реляционным, но многомерных СУБД (МСУБД), которые бы реально работали, долгое время было очень мало. Только с середины 1990-х гг. к ним стал возникать массовый интерес.
Толчком к тому была статья, которую написал в 1993 г. один из основоположников реляционного подхода Э. Кодд. В статье он сформулировал основные требования к системам оперативной аналитической обработки, самые важные из которых относились к возможностям концептуального представления и обработки многомерных данных. Многомерные системы предоставляют возможность оперативной обработки информации для проведения анализа и принятия решения.
Информационные системы (ИС) развивались в двух направлениях:
- системы аналитической обработки (системы поддержки принятия решений);
- системы оперативной (транзакционной) обработки.
В системах аналитической обработки реляционные СУБД были недостаточно гибкими. Они были предназначены для информационных систем оперативной обработки информации и являлись в этой области достаточно эффективными.
Более эффективными в системах аналитической обработки оказались многомерные системы управления БД.
Многомерные СУБД – это узкоспециализированные СУБД, которые предназначены для интерактивной аналитической обработки информации.
Основные понятия
Основными понятиями, которые используются в МСУБД, являются агрегируемость, историчность и прогнозируемость данных. Рассмотрим эти понятия.
Под агрегируемостъю данных подразумевается ознакомление с информацией на разных уровнях ее обобщения.
В ИС степень детальности представления данных зависит от уровня пользователя: руководитель, управляющий, оператор, аналитик.
Готовые работы на аналогичную тему
Историчность данных подразумевает обеспечение высокого уровня неизменности (статичности) самих данных и их взаимосвязей с обязательной привязкой данных ко времени.
Статичность данных предоставляет возможность использования при их обработке специализированных методов загрузки, индексации, хранения и выборки.
Привязка данных ко времени нужна для частого выполнения запросов, которые имеют значения дата/время в выборке. Необходимость упорядочивания данных по временному показателю при обработке и представлении данных пользователю приводит к необходимости соответствия определенным требованиям к механизмам хранения и доступа к информации. Например, чтобы уменьшить время обработки запросов нужно, чтобы данные были постоянно отсортированы в том порядке, в каком они наиболее часто запрашиваются.
Под прогнозируемостью данных понимают использование функций прогнозирования для разных временных интервалов.
Многомерность модели данных позволяет многомерно представлять логическую структуру информации при ее описании и при выполнении операций манипулирования данными.
В сравнении с реляционной, многомерная модель имеет более высокую наглядность и информативность. На рисунке 1 представлены реляционная (а) и многомерная (б) модель представления одинаковых данных об объемах продаж автомобилей.
В многомерных моделях данных используются следующие основные понятия:
Измерение – множество однотипных данных, которые образуют одну грань гиперкуба.
Чаще всего используются:
- временные измерения: Год, Квартал, Месяц, День;
- географические измерения: Город, Район, Регион, Страна и т.д.
Измерения в многомерной модели данных выступают в роли индексов, которые служат для идентификации конкретных значений в ячейках гиперкуба.
Ячейка – поле, которое содержит значение, однозначно определяющееся фиксированным набором измерений.
Поле чаще всего имеет цифровой тип. Ячейки в качестве значений могут содержать переменные (значения могут изменяться и их можно загрузить из внешнего источника данных или сформировать программно) или формулы (значения, которые вычисляются согласно заданным формулам).
На рисунке 1 каждая ячейка Объем продаж однозначно определена комбинацией измерений Месяц и Модель. В практическом применении часто необходимо большее число измерений. На рисунке 2 представлен пример трехмерной модели данных.
Измерения:
Время (год) – 2014, 2015, 2016
Менеджер – Иванов, Петров, Сидоров
Модель – Honda, Volvo, Audi
Показатель: Объем продаж
Схемы организации данных
В МСУБД существует 2 основные схемы организации данных: гиперкубическая и поликубическая.
Гиперкубическая схема предполагает использование показателей, все из которых определены одним и тем же набором измерений.
Другими словами, если БД содержит несколько гиперкубов, то все они одинаковой размерности и с совпадающими измерениями. Очевидным является то, что в некоторых случаях БД может содержать избыточную информацию (в случае обязательного заполнения ячеек).
Поликубическая схема предполагает наличие в БД нескольких гиперкубов с разной размерностью и разными измерениями в качестве граней.
Сервер Oracle Express Server является системой, которая поддерживает поликубическую схему БД.
Преимущества и недостатки многомерной модели
Основное преимущество использования многомерной модели данных состоит в удобстве и эффективности аналитической обработки больших объемов данных, которые связаны со временем.
Среди недостатков многомерной модели данных выделяют ее громоздкость для решения простейших задач обычной оперативной обработки информации.
Системы, которые поддерживают многомерные модели данных: Cache, Oracle Express Server, Media Multi-matrix и Essbase.
Получи деньги за свои студенческие работы
Курсовые, рефераты или другие работы
Автор этой статьи Дата написания статьи: 28 07 2016
Юлия Александровна Чистоедова
Автор24 - это сообщество учителей и преподавателей, к которым можно обратиться за помощью с выполнением учебных работ.
Читайте также: