
Многомерный анализ данных реферат
Обновлено: 04.07.2024
Тема данного, сделанного мной реферата интересна тем, что методов многомерного анализа данных много, но они разрозненные и, как правило, несводимые в единое целое. Многообразие этих методов обусловлено объективным многообразием изучаемых явлений, которые данные методы призваны отображать и измерять. В реферате рассмотрены различные методы, приведены их особенности. В заключительной части реферата я выскажу свою точку зрения по данной теме. Ведь если рассматривать пристально, то и ценность многомерных методов анализа определяется тем, насколько каждый из них и все они адекватны изучаемым предметам, полно и достоверно выявляют и объясняют скрытые причинно-следственные связи признаков, которые не могут быть установлены и предъявлены с помощью плоских одномерных расчетов и примитивных цифровых иллюстраций.
Многомерные методы предоставляют вычислительные и графические средства для исследования сходства, близости и группировки данных. Данные могут быть представлены и в виде множества переменных, значения которых характеризуют некоторое число систем, объектов, или субъектов, или один объект, или субъект в разные моменты времени.
Большинство методов решают задачу уменьшения количества переменных, необходимых для описания исследуемого явления, объекта, системы и выделения в этом пространстве наиболее важных характеристик или скрытых факторов.
Методы многомерного анализа позволяют анализировать количественные зависимости отдельных сторон исследуемого объекта от множества его признаков. К ним, в частности, всегда относят:
- кластерный (таксономический) анализ - классификация признаков и объектов при отсутствии предварительных или экспертных данных о группировке информации.
- логлинейный анализ - поиск и оценка взаимосвязей в таблице, сжатое описание табличных данных
- корреляционный анализ - метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными.
Метод кластерного анализа позволяет строить классификацию элементов посредством объединения их в группы - кластеры на основе критерия минимума расстояния в пространстве показателей, описывающих эти элементы, позволяет построить классификацию их на заданное число групп - кластеров. Вероятностное обоснование результатов кластеризации можно поучить методом дискриминантного анализа.
Дивизивная стратегия динамических сгущений позволяет сгруппировать объекты в заданное число кластеров. В случае дивизионом стратегии кластеризации необходимо задать число кластеров, окончательное количество кластеров может оказаться меньше. Промежуточным результатом анализа являются среднее внутрикластерное расстояние, по которому можно сравнивать различные варианты кластеризации, и кластеры с указанием элементов, включенных в них. При этом можно получить проекции на плоскость каждой пары показателей центров кластеров и объектов, или субъектов каждого кластера, соединенных линиями с центрами. Часто используют следующие варианты этой стратегии:
- стратегия ближайшего соседа очень сильно сжимает пространство исходных переменных и позволяет получить минимальное дерево групповой классификации;
- стратегия дальнего соседа сильно растягивает пространство;
- стратегия группового соседа сохраняет метрику пространства;
- гибкая стратегия универсальна
В результате получают матрицы расстояний между элементами, последовательности кластеров возрастающей общности и расстояния, а так же- дендрограмму - дерево объединения кластеров. При выполнении анализа расстояния оценивают с использованием следующих различных метрик:
евклидова метрика, которая применима для переменных, измеренных в одних единицах;
- нормализованная евклидова метрика подходит для переменных, измеренных в различных единицах;
- метрику суммы квадратов можно использовать, чтобы расстояние между кластерами было равно сумме расстояний между их компонентами;
- если переменные имеют различную значимость, то используют взвешенное суммирование квадратов, при этом матрица данных должна содержать веса показателей;
- манхеттеновскую метрику применяют для ранговых переменных;
Дискриминантный анализ позволяет проверить гипотезу о возможности классификации заданного множества объектов, характеризуемых некоторым числом переменных показателей, на некоторое число классов или кластеров, дать классификации вероятностную оценку.
Факторный анализ. Переменные, значения которых представляют данные статистики, или которые можно получить в опросе, или эксперименте, имеют для исследуемого объекта или явления нередко достаточно условный характер. Они могут лишь опосредовано отражать его внутреннюю структуру, движущие силы или факторы. Исследователь рынка, аналитик органа планирования ограничен набором показателей, традиционно используемых в официальной статистике, в анкетах для опросов. Когда неизвестный фактор проявляется и в изменении нескольких переменных, в процессе анализа можно наблюдать существенную корреляцию, или связь между переменными. Тем самым число независимых, скрытых факторов может быть существенно меньше, чем число традиционно используемых показателей, которые выбирают достаточно субъективно. Степень влияния фактора на некоторый показатель статистически характеризуется величиной дисперсии, т.е. разбросом значении этого показателя при изменении значений фактора. Если расположить оси исходных переменных ортогонально друг к другу, то можно обнаружить, что в этом пространстве объекты группируются своим расположением, определенным координатами точек, в виде некоторого облака или эллипса рассеяния, более вытянутого в одних направлениях и почти плоского в других. При этом обычно оказывается, что толщина такого облака рассеяния по некоторым осям настолько мала, что эти оси можно в дальнейшем совсем не рассматривать. Метод факторного анализа первоначально был разработан в психологии. Его цель — выделить отдельные компоненты человеческого интеллекта из многомерных данных по измерению различных проявлений умственных способностей. Однако очень быстро этот метод стал популярен в экономических исследованиях. Наиболее широко используется метод главных компонент.
Метод главных компонент. Как правило, основной задачей факторного анализа является нахождение сокращенной системы существенных факторов в пространстве регистрируемых переменных, что включает следующие этапы:
1) выделение первоначальных факторов; этот этап включает вычисление главных компонент и выбор в качестве факторов тех компонент, которые отвечают за большую часть дисперсии, рассеяния данных наблюдения;
2) вращение выделенных факторов в целях облегчения их интерпретации в терминах исходных переменных.
Содержательная интерпретация новых факторов является творческой задачей исследователя, выходящей за рамки формального метода, однако она может принести много полезного для дальнейшего понимания объекта исследования.
Использование ковариационной матрицы сравнительно менее употребительно и позволяет в вычислениях учитывать не только степень взаимосвязанности, коррелированности переменных, но и абсолютную величину ковариаций.
Производится выделение главных компонент, для каждого компонента находят:
- собственное значение, пропорциональное части общей дисперсии экспериментальных данных, приходящейся на данный фактор, то есть объясняемой им;
- процент полной дисперсии, приходящейся на каждый фактор;
- процент накопленной дисперсии.
Для облегчения интерпретации факторов можно произвести вращение факторов в пространстве переменных. Вращение позволяет получить более простую структуру системы факторов, при которой каждый фактор имеет большие нагрузки на малое число переменных и малые нагрузки на остальные переменные. Используют различные методы вращения. Перед вращением желательно выполнить нормализацию факторных нагрузок, чтобы исключить влияние на результат переменных с большой общностью. По окончании вращения поверить общность и специфичность каждого фактора и оценить новые факторные нагрузки. Изменение второго фактора по годам было почти монотонно с небольшим отступлением от монотонности в 2004 г., когда значение фактора упало до уровня 2001 г. Изменение третьего фактора оказалось почти монотонным с 1995 по 2000 г., за исключением 1998 г., когда значение фактора резко упало; с 2000 по 2004 г. тенденция изменилась, значение фактора стало падать. Изменение значений четвертого главного фактора оказалось монотонным до 2004 г., когда значение фактора резко упало. Изучение полученных результатов позволило выдвинуть гипотезы о возможности идентификации главных факторов следующим образом. Первый главный фактор может быть фактором индустриального развития. Второй главный фактор может быть фактором развития рынка. Третий главный фактор может быть фактором постиндустриального развития, тогда как четвертый главный фактор может быть фактором доиндустриального развития. Если эти гипотезы верны, то в рассматриваемый период экономическое развитие было противоречивым. Если в развитых странах преобладают тенденции постиндустриального развития, то возможно, что основная тенденция развития российской экономики - индустриальное развитие.
Факторный анализ - многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки. Факторный анализ впервые возник в психометрике и в настоящее время широко используется не только в психологии, но и в нейрофизиологии, социологии, политологии, в экономике, статистике и других науках. Основные идеи факторного анализа были заложены английским психологом и антропологом, основателем евгеники Гальтоном, внесшим также большой вклад в исследование индивидуальных различий. В разработку факторного анализа внесли вклад также Спирмен 1904, 1927, 1946, Тёрстоун 1935, 1947, 1951, Кеттел 1946, 1947, 1951, Пирсон, Айзенк. Математический аппарат факторного анализа разрабатывался Хотеллингом, Харманом, Кайзером, Тёрстоуном, Такером. Во второй половине XX века факторный анализ включён во все основные пакеты статистической обработки данных, в том числе в R, SAS, SPSS, Statistica, Stata.
Факторный анализ позволяет решить две важные проблемы исследователя: описать объект измерения всесторонне и в то же время компактно. С помощью факторного анализа возможно выявление скрытых переменных факторов, отвечающих за наличие линейных статистических корреляций между наблюдаемым и переменными. Две основные цели факторного анализа:
определение взаимосвязей между переменными, классификация переменных, то есть "объективная R-классификация"; сокращение числа переменных необходимых для описания данных. При анализе в один фактор объединяются сильно коррелирующие между собой переменные, как следствие происходит перераспределение дисперсии между компонентами и получается максимально простая и наглядная структура факторов. После объединения коррелированность компонент внутри каждого фактора между собой будет выше, чем их коррелированность с компонентами из других факторов. Эта процедура также позволяет выделить латентные переменные, что бывает особенно важно при анализе социальных представлений и ценностей. Например, анализируя оценки, полученные по нескольким шкалам, исследователь замечает, что они сходны между собой и имеют высокий коэффициент корреляции, он может предположить, что существует некоторая латентная переменная, с помощью которой можно объяснить наблюдаемое сходство полученных оценок. Такую латентную переменную называют фактором. Данный фактор влияет на многочисленные показатели других переменных, что приводит нас к возможности и необходимости выделить его как наиболее общий, более высокого порядка. Для выявления наиболее значимых факторов и, как следствие, факторной структуры, наиболее оправданно применять метод главных компонент МГК. Суть данного метода состоит в замене коррелированных компонентов некоррелированными факторами. Другой важной характеристикой метода является возможность ограничиться наиболее информативными главными компонентами и исключить остальные из анализа, что упрощает интерпретацию результатов. Достоинство МГК также в том, что он - единственный математически обоснованный метод факторного анализа. По утверждению ряда исследователей МГК не является методом факторного анализа, поскольку не расщепляет дисперсию индикаторов на общую и уникальную. Основной смысл факторного анализа заключается в выделении из всей совокупности переменных только небольшого числа латентных независимых друг от друга группировок, внутри которых переменные связаны сильнее, чем переменные, относящиеся к разным группировкам. Факторный анализ может быть: разведочным - он осуществляется при исследовании скрытой факторной структуры без предположения о числе факторов и их нагрузках;
конфирматорным подтверждающим, предназначенным для проверки гипотез о числе факторов и их нагрузках.
Практическое выполнение факторного анализа начинается с проверки его условий. В обязательные условия факторного анализа входят:
факторный анализ осуществляется по коррелирующим переменным. выборка должна быть однородна; все признаки должны быть количественными; число наблюдений должно быть не менее чем в два раза больше числа переменных; исходные переменные должны быть распределены симметрично;
При числе общих факторов больше четырёх в каждой паре столбцов должно быть некоторое количество нулевых нагрузок в одних и тех же строках. Данное предположение дает возможность разделить наблюдаемые переменные на отдельные скопления, в каждой строке матрицы вторичной структуры V должен быть хотя бы один нулевой элемент. Для каждой пары столбцов матрицы V должно быть, как можно меньше значительных по величине нагрузок, соответствующих одним и тем же строкам. Это требование обеспечивает минимизацию сложности переменных. У одного из столбцов каждой пары столбцов матрицы V должно быть несколько нулевых коэффициентов нагрузок в тех позициях, где для другого столбца они ненулевые. Это предположение гарантирует различимость вторичных осей и соответствующих им подпространств размерности r - 1 в пространстве общих факторов. Для каждого столбца k матрицы вторичной структуры V должно существовать подмножество из r линейно-независимых наблюдаемых переменных, корреляции которых с k-м вторичным фактором - нулевые. Данный критерий сводится к тому, что каждый столбец матрицы должен содержать не менее r нулей. При первом виде вращения каждый последующий фактор определяется так, чтобы максимизировать изменчивость, оставшуюся от предыдущих, поэтому факторы оказываются независимыми, некоррелированными друг от друга к этому типу относится МГК. Второй вид - это преобразование, при котором факторы коррелируют друг с другом. Преимущество косоугольного вращения состоит в следующем: когда в результате его выполнения получаются ортогональные факторы, можно быть уверенным, что эта ортогональность действительно им свойственна, а не привнесена искусственно. Существует около 13 методов вращения в обоих видах, в статистической программе SPSS 10 доступны пять: три ортогональных, один косоугольный и один комбинированный, однако из всех наиболее употребителен ортогональный метод "варимакс". Метод "варимакс" максимизирует разброс квадратов нагрузок для каждого фактора, что приводит к увеличению больших и уменьшению малых значений факторных нагрузок. В результате простая структура получается для каждого фактора в отдельности.
Главной проблемой факторного анализа является выделение и интерпретация главных факторов. При отборе компонент исследователь обычно сталкивается с существенными трудностями, так как не существует однозначного критерия выделения факторов, и потому здесь неизбежен субъективизм интерпретаций результатов. Существует несколько часто употребляемых критериев определения числа факторов. Некоторые из них являются альтернативными по отношению к другим, а часть этих критериев можно использовать вместе, чтобы один дополнял другой: Критерий доли воспроизводимой дисперсии. Факторы ранжируются по доле детерминируемой дисперсии, когда процент дисперсии оказывается несущественным, выделение следует остановить. Желательно, чтобы выделенные факторы объясняли более 80 % разброса. Недостатки критерия: во-первых, субъективность выделения, во-вторых, специфика данных может быть такова, что все главные факторы не смогут совокупно объяснить желательного процента разброса. Поэтому главные факторы должны вместе объяснять не меньше 50.1 % дисперсии. Критерий интерпретируемости и инвариантности. Данный критерий сочетает статистическую точность с субъективными интересами. Согласно ему, главные факторы можно выделять до тех пор, пока будет возможна их ясная интерпретация. Она, в свою очередь, зависит от величины факторных нагрузок, то есть если в факторе есть хотя бы одна сильная нагрузка, он может быть интерпретирован. Возможен и обратный вариант - если сильные нагрузки имеются, однако интерпретация затруднительна, от этой компоненты предпочтительно отказаться. Критерий Кайзера или критерий собственных чисел. Этот критерий предложен Кайзером, и является, вероятно, наиболее широко используемым. Отбираются только факторы с собственными значениями равными или большими 1. Это означает, что если фактор не выделяет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, то он опускается. Критерий значимости. Он особенно эффективен, когда модель генеральной совокупности известна и отсутствуют второстепенные факторы. Но критерий непригоден для поиска изменений в модели и реализуем только в факторном анализе по методу наименьших квадратов или максимального правдоподобия. Критерий каменистой осыпи или критерий отсеивания. Он является графическим методом, впервые предложенным психологом Кэттелом. Собственные значения возможно изобразить в виде простого графика. Кэттел предложил найти такое место на графике, где убывание собственных значений слева направо максимально замедляется. Предполагается, что справа от этой точки находится только "факториальная осыпь" - "осыпь" является геологическим термином, обозначающим обломки горных пород, скапливающиеся в нижней части скалистого склона. Однако этот критерий отличается высокой субъективностью и, в отличие от предыдущего критерия, статистически не обоснован. Недостатки обоих критериев заключаются в том, что первый иногда сохраняет слишком много факторов, в то время как второй, напротив, может сохранить слишком мало факторов; однако оба критерия вполне хороши при нормальных условиях, когда имеется относительно небольшое число факторов и много переменных. На практике возникает важный вопрос: когда полученное решение может быть содержательно интерпретировано. В этой связи предлагается использовать ещё несколько критериев.
И так, изучение методов многомерного анализа данных, несмотря на сложные процедуры их приложения, целесообразность их широкого практического применения необходима. В отличие от простых одномерных методов, оперирующих ограниченными и, как правило, однородными наборами объектов наблюдения и очевидными взаимосвязями между их признаками, многомерные методы имеют дело с неограниченными и разрозненными наборами наблюдаемых объектов и неочевидными и, как правило, многообразными и по преимуществу разнонаправленными взаимосвязями между их признаками. Возникает объективная необходимость обращения к методам многомерного анализа данных, успех в применении которых определяется знанием природы изучаемых объектов, их размерности и многообразных форм многомерных взаимосвязей. На практике, несмотря на существующее множество методов многомерного анализа данных, есть необходимость использовать только те, которые адекватно приемлемы в статистической работе.
Список используемой литературы:
Выполнили:
Проверил:
Минск2013
Цель работы
1. Изучение аппроксимации функции одной переменной отрезками ряда Тейлора и исследование ее точности.
2. Изучение аппроксимации функции многих переменных отрезками ряда Тейлора спомощью классического подхода и исследование ее точности.
Ход работы
Таблица 1. Варианты заданий для функций одной переменной
Номер варианта Функция
1б
Таблица 2. Варианты заданий для функций двухпеременных
Номер варианта Функция
1б
Представление функции одной переменной рядом Тейлора.
Получим для функции y(x) отрезок ряда Тейлора в окрестности некоторой точки а до 4-й степени независимойпеременной включительно.
Напишем m-файл-сценарий для аппроксимации функции одной переменной, приведенной в таблице 1, отрезками ряда Тейлора в окрестности точки 3 от нулевой до 4-й степени независимойпеременной включительно. C помощью программы plot выведем в одно графическое окно графики функции и аппроксимирующих полиномов.
m-файл-функция будет иметь следующий вид:
clcclear
syms x a
y = x^4-5*x+1;x1 = 0:0.1:4;
y1 = subs(y, x, x1);
y_taylor0 = taylor(y, 3, 1)
taylor0 = subs(y_taylor0, x, x1);
hold on
plot(x1,y1,'k-o');
for i=2:1:5
y_taylor = taylor(y, 3, i)
y_taylor1 =subs(y_taylor, x, x1);
if (i==2) color='r--*';
elseif (i==3) color='g-.s';
elseif (i==4) color='m--d';
elseif (i==5) color='c:o';
end
plot(x1, y_taylor1,color);
endplot(x1, taylor0,'b:+');
legend('Function itself', 'Taylor of 1st order'.
'Taylor of 2nd order','Taylor of 3rd order', 'Taylor of 4th order'.
'Taylor of zero order'.
Чтобы читать весь документ, зарегистрируйся.
Связанные рефераты
С помощью многомерного сравнительного анализа пр
. С помощью многомерного сравнительного анализа проводится сопоставление.
Многомерный регриссионный анализ
. Регрессио́нный анализ — статистический метод исследования влияния одной или нескольких.
2 Стр. 15 Просмотры
Анализ данных
. уравнения[+]y=0.5 + 2.3*x; А=3,48%; r=0,71 Главная цель анализа временных рядов.
9 Стр. 83 Просмотры
Анализ Данных
Анализ данных
. Анализируя данные за 1 квартал 2016 и 2017 годов количество проб воды из водных объектов.
Тема данного, сделанного мной реферата интересна тем, что методов многомерного анализа данных много, но они разрозненные и, как правило, несводимые в единое целое. Многообразие этих методов обусловлено объективным многообразием изучаемых явлений, которые данные методы призваны отображать и измерять. В реферате рассмотрены различные методы, приведены их особенности. В заключительной части реферата я выскажу свою точку зрения по данной теме. Ведь если рассматривать пристально, то и ценность многомерных методов анализа определяется тем, насколько каждый из них и все они адекватны изучаемым предметам, полно и достоверно выявляют и объясняют скрытые причинно-следственные связи признаков, которые не могут быть установлены и предъявлены с помощью плоских одномерных расчетов и примитивных цифровых иллюстраций.
Многомерные методы предоставляют вычислительные и графические средства для исследования сходства, близости и группировки данных. Данные могут быть представлены и в виде множества переменных, значения которых характеризуют некоторое число систем, объектов, или субъектов, или один объект, или субъект в разные моменты времени.
Большинство методов решают задачу уменьшения количества переменных, необходимых для описания исследуемого явления, объекта, системы и выделения в этом пространстве наиболее важных характеристик или скрытых факторов.
Методы многомерного анализа позволяют анализировать количественные зависимости отдельных сторон исследуемого объекта от множества его признаков. К ним, в частности, всегда относят:
- кластерный (таксономический) анализ - классификация признаков и объектов при отсутствии предварительных или экспертных данных о группировке информации.
- логлинейный анализ - поиск и оценка взаимосвязей в таблице, сжатое описание табличных данных
- корреляционный анализ - метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными.
Метод кластерного анализа позволяет строить классификацию элементов посредством объединения их в группы - кластеры на основе критерия минимума расстояния в пространстве показателей, описывающих эти элементы, позволяет построить классификацию их на заданное число групп - кластеров. Вероятностное обоснование результатов кластеризации можно поучить методом дискриминантного анализа.
Дивизивная стратегия динамических сгущений позволяет сгруппировать объекты в заданное число кластеров. В случае дивизионом стратегии кластеризации необходимо задать число кластеров, окончательное количество кластеров может оказаться меньше. Промежуточным результатом анализа являются среднее внутрикластерное расстояние, по которому можно сравнивать различные варианты кластеризации, и кластеры с указанием элементов, включенных в них. При этом можно получить проекции на плоскость каждой пары показателей центров кластеров и объектов, или субъектов каждого кластера, соединенных линиями с центрами. Часто используют следующие варианты этой стратегии:
- стратегия ближайшего соседа очень сильно сжимает пространство исходных переменных и позволяет получить минимальное дерево групповой классификации;
- стратегия дальнего соседа сильно растягивает пространство;
- стратегия группового соседа сохраняет метрику пространства;
- гибкая стратегия универсальна
В результате получают матрицы расстояний между элементами, последовательности кластеров возрастающей общности и расстояния, а так же- дендрограмму - дерево объединения кластеров. При выполнении анализа расстояния оценивают с использованием следующих различных метрик:
евклидова метрика, которая применима для переменных, измеренных в одних единицах;
- нормализованная евклидова метрика подходит для переменных, измеренных в различных единицах;
- метрику суммы квадратов можно использовать, чтобы расстояние между кластерами было равно сумме расстояний между их компонентами;
- если переменные имеют различную значимость, то используют взвешенное суммирование квадратов, при этом матрица данных должна содержать веса показателей;
- манхеттеновскую метрику применяют для ранговых переменных;
Дискриминантный анализ позволяет проверить гипотезу о возможности классификации заданного множества объектов, характеризуемых некоторым числом переменных показателей, на некоторое число классов или кластеров, дать классификации вероятностную оценку.
Факторный анализ. Переменные, значения которых представляют данные статистики, или которые можно получить в опросе, или эксперименте, имеют для исследуемого объекта или явления нередко достаточно условный характер. Они могут лишь опосредовано отражать его внутреннюю структуру, движущие силы или факторы. Исследователь рынка, аналитик органа планирования ограничен набором показателей, традиционно используемых в официальной статистике, в анкетах для опросов. Когда неизвестный фактор проявляется и в изменении нескольких переменных, в процессе анализа можно наблюдать существенную корреляцию, или связь между переменными. Тем самым число независимых, скрытых факторов может быть существенно меньше, чем число традиционно используемых показателей, которые выбирают достаточно субъективно. Степень влияния фактора на некоторый показатель статистически характеризуется величиной дисперсии, т.е. разбросом значении этого показателя при изменении значений фактора. Если расположить оси исходных переменных ортогонально друг к другу, то можно обнаружить, что в этом пространстве объекты группируются своим расположением, определенным координатами точек, в виде некоторого облака или эллипса рассеяния, более вытянутого в одних направлениях и почти плоского в других. При этом обычно оказывается, что толщина такого облака рассеяния по некоторым осям настолько мала, что эти оси можно в дальнейшем совсем не рассматривать. Метод факторного анализа первоначально был разработан в психологии. Его цель — выделить отдельные компоненты человеческого интеллекта из многомерных данных по измерению различных проявлений умственных способностей. Однако очень быстро этот метод стал популярен в экономических исследованиях. Наиболее широко используется метод главных компонент.
Метод главных компонент. Как правило, основной задачей факторного анализа является нахождение сокращенной системы существенных факторов в пространстве регистрируемых переменных, что включает следующие этапы:
1) выделение первоначальных факторов; этот этап включает вычисление главных компонент и выбор в качестве факторов тех компонент, которые отвечают за большую часть дисперсии, рассеяния данных наблюдения;
2) вращение выделенных факторов в целях облегчения их интерпретации в терминах исходных переменных.
Содержательная интерпретация новых факторов является творческой задачей исследователя, выходящей за рамки формального метода, однако она может принести много полезного для дальнейшего понимания объекта исследования.
Использование ковариационной матрицы сравнительно менее употребительно и позволяет в вычислениях учитывать не только степень взаимосвязанности, коррелированности переменных, но и абсолютную величину ковариаций.
Производится выделение главных компонент, для каждого компонента находят:
- собственное значение, пропорциональное части общей дисперсии экспериментальных данных, приходящейся на данный фактор, то есть объясняемой им;
- процент полной дисперсии, приходящейся на каждый фактор;
- процент накопленной дисперсии.
Для облегчения интерпретации факторов можно произвести вращение факторов в пространстве переменных. Вращение позволяет получить более простую структуру системы факторов, при которой каждый фактор имеет большие нагрузки на малое число переменных и малые нагрузки на остальные переменные. Используют различные методы вращения. Перед вращением желательно выполнить нормализацию факторных нагрузок, чтобы исключить влияние на результат переменных с большой общностью. По окончании вращения поверить общность и специфичность каждого фактора и оценить новые факторные нагрузки. Изменение второго фактора по годам было почти монотонно с небольшим отступлением от монотонности в 2004 г., когда значение фактора упало до уровня 2001 г. Изменение третьего фактора оказалось почти монотонным с 1995 по 2000 г., за исключением 1998 г., когда значение фактора резко упало; с 2000 по 2004 г. тенденция изменилась, значение фактора стало падать. Изменение значений четвертого главного фактора оказалось монотонным до 2004 г., когда значение фактора резко упало. Изучение полученных результатов позволило выдвинуть гипотезы о возможности идентификации главных факторов следующим образом. Первый главный фактор может быть фактором индустриального развития. Второй главный фактор может быть фактором развития рынка. Третий главный фактор может быть фактором постиндустриального развития, тогда как четвертый главный фактор может быть фактором доиндустриального развития. Если эти гипотезы верны, то в рассматриваемый период экономическое развитие было противоречивым. Если в развитых странах преобладают тенденции постиндустриального развития, то возможно, что основная тенденция развития российской экономики - индустриальное развитие.
Факторный анализ - многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки. Факторный анализ впервые возник в психометрике и в настоящее время широко используется не только в психологии, но и в нейрофизиологии, социологии, политологии, в экономике, статистике и других науках. Основные идеи факторного анализа были заложены английским психологом и антропологом, основателем евгеники Гальтоном, внесшим также большой вклад в исследование индивидуальных различий. В разработку факторного анализа внесли вклад также Спирмен 1904, 1927, 1946, Тёрстоун 1935, 1947, 1951, Кеттел 1946, 1947, 1951, Пирсон, Айзенк. Математический аппарат факторного анализа разрабатывался Хотеллингом, Харманом, Кайзером, Тёрстоуном, Такером. Во второй половине XX века факторный анализ включён во все основные пакеты статистической обработки данных, в том числе в R, SAS, SPSS, Statistica, Stata.
Факторный анализ позволяет решить две важные проблемы исследователя: описать объект измерения всесторонне и в то же время компактно. С помощью факторного анализа возможно выявление скрытых переменных факторов, отвечающих за наличие линейных статистических корреляций между наблюдаемым и переменными. Две основные цели факторного анализа:
определение взаимосвязей между переменными, классификация переменных, то есть "объективная R-классификация"; сокращение числа переменных необходимых для описания данных. При анализе в один фактор объединяются сильно коррелирующие между собой переменные, как следствие происходит перераспределение дисперсии между компонентами и получается максимально простая и наглядная структура факторов. После объединения коррелированность компонент внутри каждого фактора между собой будет выше, чем их коррелированность с компонентами из других факторов. Эта процедура также позволяет выделить латентные переменные, что бывает особенно важно при анализе социальных представлений и ценностей. Например, анализируя оценки, полученные по нескольким шкалам, исследователь замечает, что они сходны между собой и имеют высокий коэффициент корреляции, он может предположить, что существует некоторая латентная переменная, с помощью которой можно объяснить наблюдаемое сходство полученных оценок. Такую латентную переменную называют фактором. Данный фактор влияет на многочисленные показатели других переменных, что приводит нас к возможности и необходимости выделить его как наиболее общий, более высокого порядка. Для выявления наиболее значимых факторов и, как следствие, факторной структуры, наиболее оправданно применять метод главных компонент МГК. Суть данного метода состоит в замене коррелированных компонентов некоррелированными факторами. Другой важной характеристикой метода является возможность ограничиться наиболее информативными главными компонентами и исключить остальные из анализа, что упрощает интерпретацию результатов. Достоинство МГК также в том, что он - единственный математически обоснованный метод факторного анализа. По утверждению ряда исследователей МГК не является методом факторного анализа, поскольку не расщепляет дисперсию индикаторов на общую и уникальную. Основной смысл факторного анализа заключается в выделении из всей совокупности переменных только небольшого числа латентных независимых друг от друга группировок, внутри которых переменные связаны сильнее, чем переменные, относящиеся к разным группировкам. Факторный анализ может быть: разведочным - он осуществляется при исследовании скрытой факторной структуры без предположения о числе факторов и их нагрузках;
конфирматорным подтверждающим, предназначенным для проверки гипотез о числе факторов и их нагрузках.
Практическое выполнение факторного анализа начинается с проверки его условий. В обязательные условия факторного анализа входят:
факторный анализ осуществляется по коррелирующим переменным. выборка должна быть однородна; все признаки должны быть количественными; число наблюдений должно быть не менее чем в два раза больше числа переменных; исходные переменные должны быть распределены симметрично;
При числе общих факторов больше четырёх в каждой паре столбцов должно быть некоторое количество нулевых нагрузок в одних и тех же строках. Данное предположение дает возможность разделить наблюдаемые переменные на отдельные скопления, в каждой строке матрицы вторичной структуры V должен быть хотя бы один нулевой элемент. Для каждой пары столбцов матрицы V должно быть, как можно меньше значительных по величине нагрузок, соответствующих одним и тем же строкам. Это требование обеспечивает минимизацию сложности переменных. У одного из столбцов каждой пары столбцов матрицы V должно быть несколько нулевых коэффициентов нагрузок в тех позициях, где для другого столбца они ненулевые. Это предположение гарантирует различимость вторичных осей и соответствующих им подпространств размерности r - 1 в пространстве общих факторов. Для каждого столбца k матрицы вторичной структуры V должно существовать подмножество из r линейно-независимых наблюдаемых переменных, корреляции которых с k-м вторичным фактором - нулевые. Данный критерий сводится к тому, что каждый столбец матрицы должен содержать не менее r нулей. При первом виде вращения каждый последующий фактор определяется так, чтобы максимизировать изменчивость, оставшуюся от предыдущих, поэтому факторы оказываются независимыми, некоррелированными друг от друга к этому типу относится МГК. Второй вид - это преобразование, при котором факторы коррелируют друг с другом. Преимущество косоугольного вращения состоит в следующем: когда в результате его выполнения получаются ортогональные факторы, можно быть уверенным, что эта ортогональность действительно им свойственна, а не привнесена искусственно. Существует около 13 методов вращения в обоих видах, в статистической программе SPSS 10 доступны пять: три ортогональных, один косоугольный и один комбинированный, однако из всех наиболее употребителен ортогональный метод "варимакс". Метод "варимакс" максимизирует разброс квадратов нагрузок для каждого фактора, что приводит к увеличению больших и уменьшению малых значений факторных нагрузок. В результате простая структура получается для каждого фактора в отдельности.
Главной проблемой факторного анализа является выделение и интерпретация главных факторов. При отборе компонент исследователь обычно сталкивается с существенными трудностями, так как не существует однозначного критерия выделения факторов, и потому здесь неизбежен субъективизм интерпретаций результатов. Существует несколько часто употребляемых критериев определения числа факторов. Некоторые из них являются альтернативными по отношению к другим, а часть этих критериев можно использовать вместе, чтобы один дополнял другой: Критерий доли воспроизводимой дисперсии. Факторы ранжируются по доле детерминируемой дисперсии, когда процент дисперсии оказывается несущественным, выделение следует остановить. Желательно, чтобы выделенные факторы объясняли более 80 % разброса. Недостатки критерия: во-первых, субъективность выделения, во-вторых, специфика данных может быть такова, что все главные факторы не смогут совокупно объяснить желательного процента разброса. Поэтому главные факторы должны вместе объяснять не меньше 50.1 % дисперсии. Критерий интерпретируемости и инвариантности. Данный критерий сочетает статистическую точность с субъективными интересами. Согласно ему, главные факторы можно выделять до тех пор, пока будет возможна их ясная интерпретация. Она, в свою очередь, зависит от величины факторных нагрузок, то есть если в факторе есть хотя бы одна сильная нагрузка, он может быть интерпретирован. Возможен и обратный вариант - если сильные нагрузки имеются, однако интерпретация затруднительна, от этой компоненты предпочтительно отказаться. Критерий Кайзера или критерий собственных чисел. Этот критерий предложен Кайзером, и является, вероятно, наиболее широко используемым. Отбираются только факторы с собственными значениями равными или большими 1. Это означает, что если фактор не выделяет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, то он опускается. Критерий значимости. Он особенно эффективен, когда модель генеральной совокупности известна и отсутствуют второстепенные факторы. Но критерий непригоден для поиска изменений в модели и реализуем только в факторном анализе по методу наименьших квадратов или максимального правдоподобия. Критерий каменистой осыпи или критерий отсеивания. Он является графическим методом, впервые предложенным психологом Кэттелом. Собственные значения возможно изобразить в виде простого графика. Кэттел предложил найти такое место на графике, где убывание собственных значений слева направо максимально замедляется. Предполагается, что справа от этой точки находится только "факториальная осыпь" - "осыпь" является геологическим термином, обозначающим обломки горных пород, скапливающиеся в нижней части скалистого склона. Однако этот критерий отличается высокой субъективностью и, в отличие от предыдущего критерия, статистически не обоснован. Недостатки обоих критериев заключаются в том, что первый иногда сохраняет слишком много факторов, в то время как второй, напротив, может сохранить слишком мало факторов; однако оба критерия вполне хороши при нормальных условиях, когда имеется относительно небольшое число факторов и много переменных. На практике возникает важный вопрос: когда полученное решение может быть содержательно интерпретировано. В этой связи предлагается использовать ещё несколько критериев.
И так, изучение методов многомерного анализа данных, несмотря на сложные процедуры их приложения, целесообразность их широкого практического применения необходима. В отличие от простых одномерных методов, оперирующих ограниченными и, как правило, однородными наборами объектов наблюдения и очевидными взаимосвязями между их признаками, многомерные методы имеют дело с неограниченными и разрозненными наборами наблюдаемых объектов и неочевидными и, как правило, многообразными и по преимуществу разнонаправленными взаимосвязями между их признаками. Возникает объективная необходимость обращения к методам многомерного анализа данных, успех в применении которых определяется знанием природы изучаемых объектов, их размерности и многообразных форм многомерных взаимосвязей. На практике, несмотря на существующее множество методов многомерного анализа данных, есть необходимость использовать только те, которые адекватно приемлемы в статистической работе.
Список используемой литературы:
Фундамент статистики как науки составляют эмпирические наблюдения за окружающим нас миром.
Одномерный статистический анализ представляет частный случай многомерного.
Практически все задачи одномерного анализа ставятся и решаются в предположении того, что в природе существует так называемый гауссовский закон распределения данных.
Регрессионный анализ
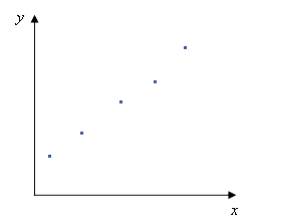
Рис. 1. График зависимости рентабельности от доли рынка
Невооруженным взглядом видно, что это прямая, однако точные ее пара- метры помогает установить регрессионный анализ. Регрессионный анализ широко используется в офисном пакете Excel, который предоставляет возможность исследовать не только линейные, но и другие, более сложные зависимости (в Excel это называется построением линий трендов).
Регрессионный анализ – метод установления аналитического выражениястохастической зависимости между исследуемыми признаками. Уравнение регрессии показывает, как в среднем изменяется y при изменении любого из xi, и имеет вид: y=f(x1, x2,…,xn), где y – зависимая переменная (всегда одна); xi – независимые переменные (факторы) (их может быть несколько).
В ходе регрессионного анализа решаются две основные задачи: построение уравнения регрессии, т.е. нахождение вида зависимости между результатным показателем и независимыми факторами x1, x2,…, xn; оценка значимости полученного уравнения, т.е. определение того, насколько выбранные факторные признаки объясняют вариацию признака y.
Применяется регрессионный анализ главным образом для планирования, а также для разработки нормативной базы. В отличие от корреляционного анализа, который только отвечает на вопрос, существует ли связь между анализируемыми признаками, регрессионный анализ дает и ее формализованное выражение.
Кроме того, если корреляционный анализ изучает любую взаимосвязь факторов, то регрессионный – одностороннюю зависимость, т.е. связь, показывающую, каким образом изменение факторных признаков влияет на признак результативный.
Задача на использование методов корреляционного и регрессионного анализа.
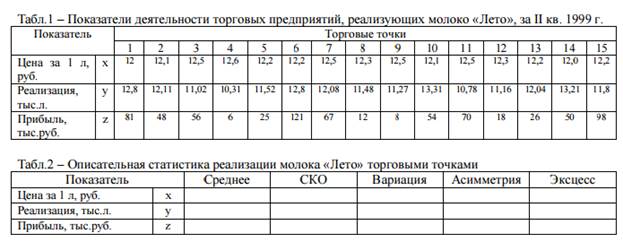
Корреляционный анализ
Корреляционный анализ позволяет судить о том, насколько похоже ведут себя разные переменные. В самом общем виде принятие гипотезы о наличии корреляции означает, что изменение значения переменной А произойдет одновременно с пропорциональным изменением значения Б: если обе переменные растут, то корреляция положительная; если одна переменная растет, а вторая уменьшается – корреляция отрицательная. При изучении корреляций стараются установить, существует ли какая- то связь между двумя показателями в одной выборке (например, между ростом и весом детей или между уровнем IQ и школьной успеваемостью) либо между двумя различными выборками (например, при сравнении пар близнецов), и если эта связь существует, то сопровождается ли увеличение одного показателя возрастанием (положительная корреляция) или уменьшением (отрицательная корреляция) другого.
Корреляционный анализ – метод установления связи и измерения ее тесноты между наблюдениями, которые можно считать случайными и выбранными из совокупности, распределенной по многомерному нормальному закону. Корреляционной связью называется такая статистическая связь, при которой различным значениям одной переменной соответствуют разные средние значения другой. Основной особенностью корреляционного анализа следует признать то, что он устанавливает лишь факт наличия связи и степени ее тесноты, не вскрывая причин. В статистике теснота связи может определяться с помощью различных коэффициентов (Пирсона, коэффициента ассоциации и т.д.), чаще используется линейный коэффициент корреляции между факторами x и y:
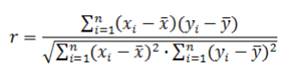
Значения коэффициента корреляции изменяются в интервале [-1; +1]. Значение r = –1 свидетельствует о наличии жестко детерминированной обратно пропорциональной связи между факторами; r =+1 соответствует жестко детерминированной связи с прямо пропорциональной зависимостью факторов. Другие значения коэффициента корреляции свидетельствуют о наличии стохастической связи, причем, чем ближе к единице, тем связь теснее. При ,
Роль химии в жизни человека: Химия как компонент культуры наполняет содержанием ряд фундаментальных представлений о.
Читайте также: