
Зачем применяется кодирование при обработке информации кратко
Обновлено: 05.07.2024
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

Индеец пингует
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
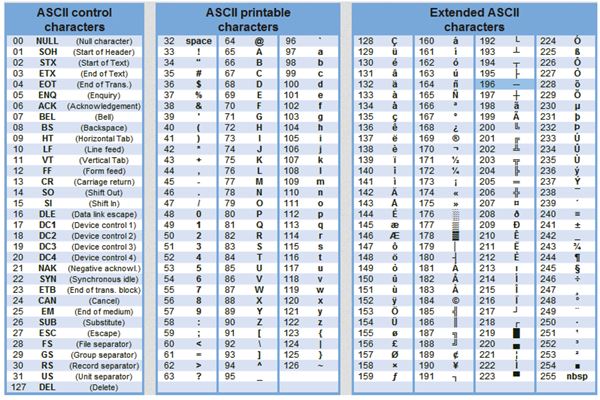
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.
Кодирование информации
В информатике большое число информационных процессов проходит с использованием кодирования данных. Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.

Это означает, что при кодировании текста каждому символу присваивается определенное значение в виде нулей и единиц – байта.
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид.
Стандарты кодирования текста
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста. В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.

ASCII
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.

Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
- изображения растровой графики;
- изображения векторной графики.
Растровая графика
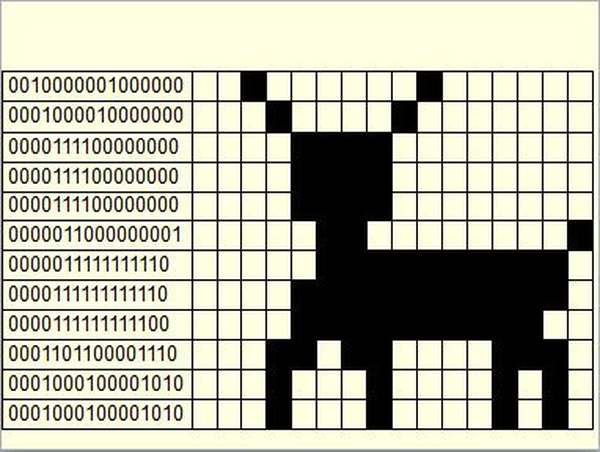
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет — 0, а белый — 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.

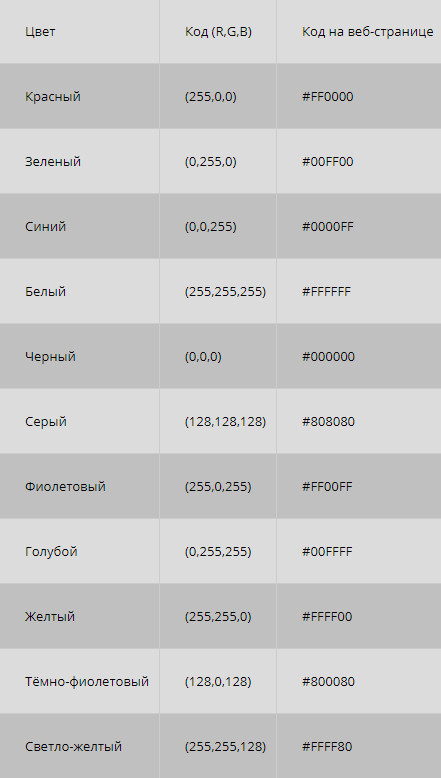
На практике, чаще применяют цветовую модель RGB, где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
I=a*b*i
- а - количество пикселей в ширину;
- b - количество пикселей в длину;
- I – размер одного пикселя в байтах.
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.

Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
- амплитуда колебаний – определяет громкость звука;
- частота колебания - определяет тональность звука.
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.

Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Стандарты кодирования видео
Как вы знаете, видеоряд состоит из быстро меняющихся фрагментов. Смена кадров происходит со скоростью в интервале 24-60 кадров в секунду.
Размер видеоряда в байтах определяется размером кадра (количеством пикселей на экран по высоте и ширине), количеством используемых цветов, а также количеством кадров в секунду. Но наряду с этим может присутствовать ещё и звуковая дорожка.
© 2013-2020 Информатика. Полезные материалы по информационным технологиям. Использование материалов без активной ссылки на сайт запрещено! Публикация в печати только с письменного разрешения администрации.
Ежедневно человек сталкивается с кодированием информации. Огромное количество данных из окружающего мира поступает к нему в форме разнообразных сигналов, звуков, вкусовых и тактильных ощущений. Вместе оно составляет своеобразный код, совокупность условных обозначений. Кодирование информации – это преобразование исходных данных с помощью определенного алгоритма.
План урока:
Примеры кодирования информации:
Информация проходит кодирование в целях:
Вслед за ним Ж. Бодо создал основополагающий в истории современной информатики метод бинарного кодирования информации, который заключается в применении всего двух различающихся электрических сигналов. Кодирование информации в компьютере также подразумевает использование двух чисел.
Кодирование информации в информатике, одна из базовых тем. Понимание для чего нужна процедура кодирования передаваемой информации, каким образом она осуществляется, поможет в изучении принципов работы компьютера.
Способы кодировки
Проанализируем разнообразные виды информации и особенности ее кодирования.
По принципу представления все информационные сведения можно классифицировать на следующие группы:
- графическая;
- аудиоинформация (звуковая);
- символьная (текстовая);
- числовая;
- видеоинформация.
Соответственно происходит и классификация информации по способу кодирования:
Самыми распространенными видами кодировок информации являются следующие:
- преобразование текста;
- графическая кодировка;
- кодирование числовых данных;
- перевод звука в бинарную последовательность чисел;
- видеокодирование.
Различают такие методы кодирования информации как:
Двоичный код
Самый широко используемый метод кодирования информации – двоичное кодирование. Кодирование данных двоичным кодом применяется во всех современных технологиях.
Двоичное кодирование информации применяется для различных данных:
- двоичное кодирование текстовой информации заключается в присвоении буквенным, цифровым и другим обозначениям определенного кода. Он записывается в компьютерной памяти цепочкой из нулей и единиц. Порядок кодирования алфавита в двоичный код с помощью стандарта ASCII является наглядным примером;
- вид используемой графики влияет на то, каким образом производится двоичное кодирование графической информации;
- двоичное кодирование звуковой информации происходит после дискретизации звуковой волны и присвоения каждому компоненту соответствующего бинарной цепочки чисел;
- кодирование двоичным кодом видеоматериалов сочетает принципы работы со звуком и растровыми изображениями.
Обработка графических изображений
Суть кодирования графической и звуковой информации заключается в преобразовании ее из аналогового вида в цифровой.
Кодирование графической информации – это процедура присвоения каждому компоненту изображения определенного кодового значения.
Способы кодирования графической информации подчиняются методам представления изображений (растрового или векторного):
- Принцип кодирования графической информации растровым способом заключается в присвоении бинарного шифра пикселям (точкам), формирующим изображение. Код содержит сведения о цветовых оттенках каждой точки. Примером служат снимки, сделанные на цифровом фотоаппарате.
- Векторная кодировка осуществляется благодаря использованию математических функций. Компонентам векторных изображений (точкам, прямым и другим геометрическим фигурам) присваивается двоичная последовательность, определяющая разнообразные параметры. Такая графика зачастую применяется в типографии.

Источник
Кодирование и обработка графической информации различного формата имеет как свои преимущества, так и недостатки.
Метод координат
Любые данные можно передать с помощью двоичных чисел, в том числе и графические изображение, представляющие собой совокупность точек. Чтобы установить соответствие чисел и точек в бинарном коде, используют метод координат.
Метод координат на плоскости основан на изучении свойств точки в системе координат с горизонтальной осью Ox и вертикальной осью Oy. Точка будет иметь 2 координаты.
Если через начало координат проходит 3 взаимно перпендикулярные оси X, Y и Z, то используется метод координат в пространстве. Положение точки в таком случае определяется тремя координатами.
Система координат в пространстве
Перевод чисел в бинарный код
Числовой способ кодирования информации, т.е. переход информационных данных в бинарную последовательность чисел широко распространен в современной компьютерной технике. Любая числовую, символьную, графическую, аудио- и видеоинформацию можно закодировать двоичными числами. Рассмотрим подробнее кодирование числовой информации.
Привычная человеку система счисления (основанная на цифрах от 0 до 9), которой мы активно пользуемся, появилась несколько сотен тысяч лет назад. Работа всей вычислительной техники организована на бинарной системе счисления. Алфавитом у нее минимальный – 0 и 1. Кодировка чисел совершается путем перехода из десятичной в двоичную систему счисления и выполнении вычислений непосредственно с бинарными числами.
Кодирование и обработка числовой информации обусловлено желаемым результатом работы с цифрами. Так, если число вводится в рамках текстового файла, то оно будет иметь код символа, взятого из используемого стандарта. Для математических вычислений числовые данные преобразуются совершенно другим способом.
Принципы кодирования числовой информации, представленной в виде целых или дробных чисел (положительных, отрицательных или равных 0) отличаются по своей сути. Самый простой способ перевести целое число из десятичной в двоичную систему счисления заключается в следующем:
- число нужно разделить на 2;
- если частное больше 1, то необходимо продолжить деление до того момента, пока результат будет равен 0 или 1;
- записать результат последней операции и остатки от деления в обратной последовательности;
- полученное число и будет являться искомым кодовым значением.
Одна из важнейших частей компьютерной работы – кодирование символьной информации. Все многообразие цифр, русских и латинских букв, знаков препинания, математических знаков и отдельных специальных обозначений относятся к символам. Cимвольный способ кодирования состоит в присвоении определенному знаку установленного шифра.
Рассмотрим подробнее самые распространенные стандарты ASCII и Unicode – то, что применяется для кодирования символьной информации во всем мире.
Фрагмент таблицы ASCII
Кодирование символьной и числовой информации принципиально отличается. Для ввода-вывода цифр на монитор или использовании их в текстовом файле происходит преобразование их согласно системе кодировки. В процессе арифметических действий число имеет совершенно другое бинарное значение, потому что оно переходит в двоичную систему счисления, где и совершаются все вычислительные действия.
Преобразование звука
Компьютерные технологии успешно внедряются в различные сферы деятельности, включая кодирование и обработку звуковой информации. С физической точки зрения, звук – это аналоговый сплошной сигнал. Процесс его перевода в ряд электрических импульсов называется кодированием звуковой информации.
Задачи, которые необходимо решить для успешной оцифровки сигнала:
- дискретизировать (разделить аудиоданные на элементарные участки путем измерения колебаний воздуха через одинаковые интервалы времени);
- оцифровать (присвоить каждому элементу числовой код).
Преобразование звука: а) аналоговый сигнал; б)дискретный сигнал.
Различают следующие методы кодирования звуковой информации:
Обработка текста
Текст – осмысленный порядок знаков. С использованием компьютера кодирование и обработка текстовой информации (набор, редактирование, обмен и сохранение письменного текста) значительно упростилось.
Кодирование текстовой информации – присвоение любому символу текста кода из кодировочной системы. Различают следующие стандарты кодировки:
- ASCII – первая международная система кодировки, содержащая коды на 256 знаков.
- Unicode – расширенный стандарт ASCII, превышающий ее размером в 256 раз.
- КОИ-8, СР1251, СР866, ISO – русские таблицы кодировки букв. При этом следует понимать, что документ, закодированный одним стандартом, не будет читаться в другом.
В задачах на кодирование текстовой информации часто встречаются следующие понятия:
- мощность алфавита;
- единицы измерения памяти (биты и байты).
Например, мощность алфавита ASCII составляет 256 символов. При этом один знак занимает 8 бит (или 1 байт) памяти, а Unicode – 35536 символов и 16 бит (или 2 байта) соответственно.
Читайте также: