
Проектирование базы данных кратко
Обновлено: 30.06.2024
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
-
отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность Citizen
Здесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):

Рис.2. Отношение сущностей Citizen и PassportData
Здесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):

Рис.3. Сущность Person
Таблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):

Рис.5. Сущность Parent
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):

Рис.6. Отношение сущностей Parent и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):

Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.2.2) в двух сущностях (таблицах):

Рис.8. Отношение сущностей Person и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:

Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):

Рис.10. Отношение сущностей Person и RealEstate
Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
А где же семь формальных правил?
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.

Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Подобная модель лежит в основе базы данных проекта Geecko.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Проектирование баз данных — процесс создания схемы базы данных и определения необходимых ограничений целостности.

Невозможно создать БД без подробного ее описания, также как и невозможно сделать какое-либо сложное изделие без чертежа и подробного описания технологий его изготовления. Другими словами, нужен проект. Проектом принято считать эскиз некоторого устройства, который в дальнейшем будет воплощен в реальность. Процесс проектирования БД представляет собой процесс переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. Конечной целью проектирования является построение конкретной БД. Очевидно, что процесс проектирования сложен и поэтому имеет смысл разделить его на логически завершенные части – этапы.
При проектировании таблиц рекомендуется руководствоваться следующими основными принципами:
- Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Когда определенная информация хранится только в одной таблице, то и изменять ее придется только в одном месте. Это делает работу более эффективной, а также исключает возможность несовпадения информации в разных таблицах. Например, в одной таблице должны содержаться адреса и телефоны клиентов.
- Каждая таблица должна содержать информацию только на одну тему. Сведения на каждую тему обрабатываются намного легче, если они содержатся в независимых друг от друга таблицах. Например, адреса и заказы клиентов лучше хранить в разных таблицах с тем, чтобы при удалении заказа информация о клиенте осталась в базе данных.
- Каждая таблица должна содержать необходимые поля. Каждое поле в таблице должно содержать отдельные сведения по теме таблицы. Например, в таблице с данными о клиенте могут содержаться поля с названием компании, адресом, городом, страной и номером телефона. При разработке полей для каждой таблицы необходимо помнить, что каждое поле должно быть связано с темой таблицы. Не рекомендуется включать в таблицу данные, которые являются результатом выражения. В таблице должна присутствовать вся необходимая информация. Информацию следует разбивать на наименьшие логические единицы (Например, поля "Имя" и "Фамилия", а не общее поле "Имя").

- База данных должна иметь первичный ключ. Это необходимо для того, чтобы СУБД могла связать данные из разных таблиц, например, данные о клиенте и его заказы.
Основные задачи проектирования баз данных:
- Обеспечение хранения в БД всей необходимой информации.
- Обеспечение возможности получения данных по всем необходимым запросам.
- Сокращение избыточности и дублирования данных.
- Обеспечение целостности базы данных.
Основные этапы проектирования баз данных:
Концептуальное (инфологическое) проектирование.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам.
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений. При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
Логическое (даталогическое) проектирование.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Логическая структура БД должна соответствовать логической модели предметной области и учитывать связь модели данных с поддерживаемой СУБД. Поэтому этап начинается с выбора модели данных, где важно учесть её простоту и наглядность.
Предпочтительнее, когда естественная структура данных совпадает с представляющей её моделью. Так, например, если в данные представлены в виде иерархической структуры, то и модель лучше выбирать иерархическую. Однако на практике такой выбор чаще определяется системой управления БД, а не моделью данных. Поэтому концептуальная модель фактически транслируется в такую модель данных, которая совместима с выбранной системой управления БД.
Здесь тоже находит отражение природа проектирования, которая допускает возможность (или необходимость) вернуться к концептуальной модели для её изменения в случае, если отражённые там взаимосвязи между объектами (или атрибуты объектов) не удастся реализовать средствами выбранной СУБД.
По завершению этапа должны быть сформированы схемы баз данных обоих уровней архитектуры (концептуального и внешнего), созданные на языке определения данных, поддерживаемых выбранной СУБД.
Схемы базы данных формируются с помощью одного из двух разнонаправленных подходов:
- либо с помощью восходящего подхода, когда работа идёт с нижних уровней определения атрибутов, сгруппированных в отношения, представляющие объекты, на основе существующих между атрибутами связей;
- либо с помощью обратного, нисходящего, подхода, применяемого при значительном (до сотен и тысяч) увеличении числа атрибутов.
Физическое проектирование.
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.

На следующем этапе физического проектирования БД логическая структура отображается в виде структуры хранения БД, то есть увязывается с такой физической средой хранения, где данные будут размещены максимально эффективно. Здесь детально расписывается схема данных с указанием всех типов, полей, размеров и ограничений. Помимо разработки индексов и таблиц, производится определение основных запросов.
Построение физической модели сопряжено с решением во многом противоречивых задач:
- задачи минимизации места хранения данных,
- задачи достижения целостности, безопасности и максимальной производительности.
Вторая задача вступает в конфликт с первой, поскольку, например:
- для эффективного функционирования транзакций нужно резервировать дисковое место под временные объекты,
- для увеличения скорости поиска нужно создавать индексы, число которых определяется числом всех возможных комбинаций участвующих в поиске полей,
- для восстановления данных будут создаваться резервные копии базы данных и вестись журнал всех изменений.
Всё это увеличивает размер базы данных, поэтому проектировщик ищет разумный баланс, при котором задачи решаются оптимально путём грамотного размещения данных в пространстве памяти, но не за счёт средств защиты базы дынных, куда входит как защита от несанкционированного доступа, так и защита от сбоев.
Для завершения создания физической модели проводят оценку её эксплуатационных характеристик (скорость поиска, эффективность выполнения запросов и расхода ресурсов, правильность операций). Иногда этот этап, как и этапы реализации базы данных, тестирования и оптимизации, а также сопровождения и эксплуатации, выносят за пределы непосредственного проектирования БД.
Выбор системы управления и программных средств БД.
От выбора системы управления БД зависит практическая реализация информационной системы. Наиболее значимыми критериями в процессе выбора становятся параметры:
- типа модели данных и её соответствие потребностям предметной области,
- запас возможностей в случае расширения информационной системы,
- характеристики производительности выбранной системы,
- эксплуатационная надёжность и удобство СУБД,
- инструментальная оснащённость, ориентированная на персонал администрирования данных,
- стоимость самой СУБД и дополнительного софта.
Ошибки в выборе СУБД практически наверняка впоследствии спровоцируют необходимость корректировать концептуальную и логическую модели.
Свидетельство и скидка на обучение каждому участнику
Зарегистрироваться 15–17 марта 2022 г.
Министерство образования и науки Российской Федерации
Федеральное государственное бюджетное образовательное
учреждение высшего образования
ИРКУТСКИЙ НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Факультет среднего профессионального образования
ОП.07 ОСНОВЫ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
КРАТКИЙ КУРС ЛЕКЦИЙ
09.02.04 Информационные системы (по отраслям)
Техник по информационным системам
Борисова Марина Валентиновна, преподаватель

Иркутск 2015 г.
Цель данного пособия оказать помощь в самостоятельной подготовке студентов изучающих основы проектирования баз данных, и способствовать формированию системного представления относительно основных теоретико-методологических вопросов.
Содержание конспекта лекций позволит более точно и правильно сформировать понимание представленных тем. Кроме того, работа с конспектом лекций определяет круг основных понятий по данному вопросу, что позволяет более качественно их освоить и быть более успешными в подготовке к промежуточной аттестации.
Основные понятия теории баз данных
История возникновения баз данных
История развития баз данных
Компьютеры были созданы для решения вычислительных задач, однако со временем они все чаще стали использоваться для построения систем обработки документов, а точнее, содержащейся в них информации. Такие системы обычно и называют информационными.
Информационные системы имеют следующие особенности:
для обеспечения их работы нужны сравнительно низкие вычислительные мощности
данные, которые они используют, имеют сложную структуру
необходимы средства сохранения данных между последовательными запусками системы, …
Другими словами, информационная система требует создания в памяти ЭВМ динамически обновляемой модели внешнего мира с использованием единого хранилища - базы данных (БД) .
Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации.
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными . В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в словаре базы данных .
Таким образом, система управления базой данных ( СУБД ) - важнейший компонент информационной системы. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
Основные функции СУБД:
управление данными во внешней памяти (на дисках);
управление данными в оперативной памяти;
журнализация изменений и восстановление базы данных после сбоев;
поддержание языков БД (язык определения данных, язык манипулирования данными).
История возникновения БД
В истории вычислительной техники можно проследить развитие двух основных областей ее использования.
Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик.
Вторая область — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах.
Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
надежное хранение информации в памяти компьютера;
выполнение специфических для данного приложения преобразований информации и вычислений;
предоставление пользователям удобного и легко осваиваемого интерфейса.
Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру.
Важным шагом в развитии именно информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным.
Пользователи видят файл как линейную последовательность записей и могут выполнить над ним ряд стандартных операций:
создать файл (требуемого типа и размера);
открыть ранее созданный файл;
прочитать из файла некоторую запись (текущую, следующую, предыдущую, первую, последнюю);
записать в файл на место текущей записи новую, добавить новую запись в конец файла.
В разных файловых системах эти операции могли несколько отличаться, но общий смысл их был именно таким.
Главное, что следует отметить, это то, что структура записи файла была известна только программе, которая с ним работала , система управления файлами не знала ее. И поэтому для того, чтобы извлечь некоторую информацию из файла, необходимо было точно знать структуру записи файла с точностью до бита. Каждая программа, работающая с файлом, должна была иметь у себя внутри структуру данных, соответствующую структуре этого файла. Поэтому при изменении структуры файла требовалось изменять структуру программы , а это требовало новой компиляции, то есть процесса перевода программы в исполняемые машинные коды. Такая ситуация характеризовалась как зависимость программ от данных. Для информационных систем характерным является наличие большого числа различных пользователей (программ), каждый из которых имеет свои специфические алгоритмы обработки информации, хранящейся в одних и тех же файлах. Изменение структуры файла, которое было необходимо для одной программы, требовало исправления и перекомпиляции и дополнительной отладки всех остальных программ, работающих с этим же файлом. Это было первым существенным недостатком файловых систем, который явился толчком к созданию новых систем хранения и управления информацией.
Следующей причиной стала необходимость обеспечения эффективной параллельной работы многих пользователей с одними и теми же файлами . В общем случае системы управления файлами обеспечивали режим многопользовательского доступа. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом. Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу.
В системах управления файлами обычно применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) среди прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции некоторым пользовательским процессом PR1 файл был уже открыт другим процессом PR2 в режиме изменения, то в зависимости от особенностей системы процессу PR1 либо сообщалось о невозможности открытия файла, либо он блокировался до тех пор, пока в процессе PR2 не выполнялась операция закрытия файла.
При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена.
Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к управлению информацией. Этот подход был реализован в рамках новых программных систем, названных впоследствии Системами Управления Базами Данных (СУБД), а сами хранилища информации, которые работали под управлением данных систем, назывались базами или банками данных (БД и БнД).
История развития БД
Концепция БД сложилась в конце 60-х годов прошлого столетия и с тех пор постоянно развивалась.
Первый этап сложился к началу 60-х годов прошлого века и характеризуется следующими признаками:
информация преимущественно хранится в последовательных файлах на магнитных лентах;
физическая структура данных строго соответствует логической;
в качестве архива хранятся несколько копий файлов;
файлы предназначены для единственной программы;
программист планирует не только логическую, но и физическую организацию данных;
при изменении физической или логической организации данных программа должна перерабатываться.
Второй этап относится к середине 60-х годов и имеет следующие особенности:
появились внешние устройства прямого доступа, позволившие осуществить произвольный доступ к записям (прямой, индексно-последовательный);
вошли в употребление процедуры поиска записи по ключевому полю (обычно одному);
стало возможным переносить файлы на другие внешние устройства без изменения прикладных программ, что обычно обеспечивалось средствами языка управления данными соответствующей операционной системы.
Третий этап начался с конца 60-х годов. Основным достижением можно считать осознание необходимости централизации данных для доступа к ним различных приложений. При этом уменьшается избыточность и противоречивость информации, приложения используют стандартные средства доступа к данным. На этом этапе возросла сложность организации данных, был реализован эффективный поиск записей по многим ключам.
Именно на этом этапе появились первые СУБД. Прежде всего развивались теория и практика построения иерархических и сетевых СУБД. В этих моделях связи данных описываются с помощью деревьев и графов общего вида.
Четвертый этап датируется второй половиной 70-х годов. На этом этапе были реализованы следующие основные характеристики СУБД:
логическая и физическая независимость данных;
удобство развития БД;
безопасность, секретность, целостность данных;
поиск информации по различным запросам;
языковые средства для администратора, прикладного программиста, пользователя-непрофессионала.
С начала 70-х годов после публикаций Э.Кодда начались активные исследования реляционной модели данных. Основу реляционной СУБД составляют таблицы. Вплоть до 80-х годов реляционные СУБД считались перспективными, но трудными для реализации.
Новый этап в развитии СУБД наступил при появлении персональных компьютеров. На этом этапе на передний план вышли такие особенности СУБД, как:
дружественность и удобство работы пользователя (развитые диалоги, меню, оконный интерфейс, контекстная помощь);
упрощение громоздких схем СУБД за счет частичной реализации ряда свойств;
почти полный переход на реляционные СУБД;
ориентация не только на программиста, но и на пользователя-непрофессионала;
наличие средств автоматизации программирования в виде генераторов форм, меню, отчетов, запросов.
Классификация БД
Классификация БД может быть произведена по различным признакам, среди которых выделяют:
По форме представления информации: фактографические и документальные.
По типу используемой модели данных: иерархические, сетевые, реляционные.
По типологии хранения данных: локальные (централизованные) и распределённые (удалённые) БД.
Классификация не является полной. Различные источники предоставляют разнообразную классификацию.
Вопросы для самоконтроля:
Дайте определения понятиям: информационная система, предметная область.
Что называется базой данных и каково ее место в ИС?
В чем различие между данными и метаданными?
Каково назначение систем управления базами данных?
Для чего используется словарь данных?
Назовите этапы развития БД.
Какую роль в развитии технологии БД сыграло появление ПК?
Каковы функции СУБД?
Технология "клиент – сервер"
Трехзвенная (многозвенная) архитектура "клиент – сервер"
Понятие базы данных изначально предполагало возможность решения многих задач несколькими пользователями. В связи с этим, важнейшей характеристикой современных СУБД является наличие многопользовательской технологии работы. Разная реализация таких технологий в разное время была связана как с основными свойствами вычислительной техники, так и с развитием программного обеспечения.
Централизованная архитектура
При использовании этой технологии база данных, СУБД и прикладная программа (приложение) располагаются на одном компьютере ( рисунок 1 ). Для такого способа организации не требуется поддержки сети и все сводится к автономной работе.

Рисунок 1 - Централизованная архитектура
Многопользовательская технология работы обеспечивалась либо режимом мультипрограммирования, либо режимом разделения времени.
Архитектура "файл-сервер"
Увеличение сложности задач, появление персональных компьютеров и локальных вычислительных сетей явились предпосылками появления новой архитектуры файл-сервер . Эта архитектура баз данных с сетевым доступом предполагает назначение одного из компьютеров сети в качестве выделенного сервера, на котором будут храниться файлы базы данных. В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных ( рисунок 2 ).

Рисунок 2 - Архитектура "файл-сервер"
Технология "клиент – сервер"
Использование технологии " клиент – сервер " предполагает наличие некоторого количества компьютеров, объединенных в сеть, один из которых выполняет особые управляющие функции (является сервером сети).
Так, архитектура " клиент – сервер " разделяет функции приложения пользователя (называемого клиентом) и сервера. Приложение-клиент формирует запрос к серверу, на котором расположена БД, на структурном языке запросов SQL (Structured Query Language), являющемся промышленным стандартом в мире реляционных БД. Удаленный сервер принимает запрос и переадресует его SQL-серверу БД.
SQL-сервер – специальная программа, управляющая удаленной базой данных. SQL-сервер обеспечивает интерпретацию запроса, его выполнение в базе данных, формирование результата выполнения запроса и выдачу его приложению-клиенту. При этом ресурсы клиентского компьютера не участвуют в физическом выполнении запроса; клиентский компьютер лишь отсылает запрос к серверной БД и получает результат, после чего интерпретирует его необходимым образом и представляет пользователю. Так как клиентскому приложению посылается результат выполнения запроса, по сети "путешествуют" только те данные, которые необходимы клиенту. В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там же, где хранятся данные (на сервере), нет необходимости в пересылке больших пакетов данных. Кроме того, SQL-сервер, если это возможно, оптимизирует полученный запрос таким образом, чтобы он был выполнен в минимальное время с наименьшими накладными расходами.
Архитектура системы представлена на рисунке 3 .

Рисунок 3 - Архитектура "клиент – сервер"
Трехзвенная (многозвенная) архитектура "клиент – сервер"
Трехзвенная (в некоторых случаях многозвенная ) архитектура (N-tier или multi-tier). представляет собой дальнейшее совершенствование технологии " клиент – сервер ". Рассмотрев архитектуру " клиент – сервер ", можно заключить, что она является 2-звенной: первое звено – клиентское приложение, второе звено – сервер БД + сама БД. В трехзвенной архитектуре вся бизнес-логика (деловая логика), ранее входившая в клиентские приложения, выделяется в отдельное звено, называемое сервером приложений. При этом клиентским приложениям остается лишь пользовательский интерфейс.
Схематически такую архитектуру можно представить, как показано на рисунке 4 .

Рисунок 4 - Представление многоуровневой архитектуры "клиент-сервер"
Вопросы для самоконтроля:
Назовите достоинства и недостатки существующих многопользовательских технологий с базами данных.

Рисунок 3 Этапы жизненного цикла БД этапы проектирования БД
Проектирования БД представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. В общем случае можно выделить следующие этапы проектирования;
1. Системный анализ и словесное описание информационных объектов предметной области.
2. Проектирование инфологической модели предметной области - частично формализованное описание объектов предметной области в терминах некоторой семантической модели, например, в терминах Е R -модели.
3. Даталогическое или логическое проектирование БД, то есть описание БД в терминах принятой даталогической модели данных,
4. .Физическое проектирование БД, то есть выбор эффективного размещения БД па внешних носителях для обеспечения наиболее эффективной работы приложения
Оценка проекта БД:
1) сокращение избыточности д-х,
2) уменьш-е затрат на многократн. обновление полей,
Этапы проектирования БД:
1. Концептуальное проектирование - сбор, анализ и редактирование требований к данным. Для этого осуществляются следующие мероприятия:
o обследование предметной области, изучение ее информационной структуры
o выявление всех фрагментов, каждый из которых характеризуется пользовательским представлением, информационными объектами и связями между ними, процессами над информационными объектами
o моделирование и интеграция всех представлений
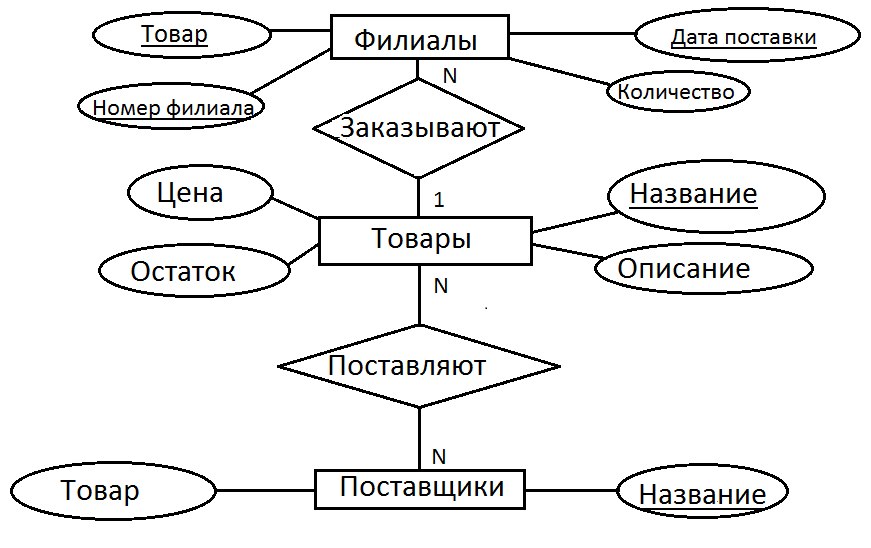
По окончании данного этапа получаем концептуальную модель, инвариантную к структуре базы данных. Часто она представляется в виде модели "сущность-связь".
2. Логическое проектирование - преобразование требований к данным в структуры данных. На выходе получаем СУБД-ориентированную структуру базы данных и спецификации прикладных программ. На этом этапе часто моделируют базы данных применительно к различным СУБД и проводят сравнительный анализ моделей.
3. Физическое проектирование - определение особенностей хранения данных, методов доступа и т.д.
Читайте также: