
Проблемы машинного перевода кратко
Обновлено: 08.07.2024
Эта история представляет собой обзор области машинного перевода. В этой истории представлено несколько цитируемых литературы и известных приложений, но я хотел бы призвать вас поделиться своим мнением в комментариях. Цель этой истории - обеспечить хорошее начало для новичка в этой области. Он охватывает три основных подхода машинного перевода, а также несколько проблем в этой области. Надеемся, что литература, упомянутая в рассказе, представляет историю проблемы, а также современные решения.
Машинный перевод (MT) - это задача перевода текста с исходного языка на его аналог на целевом языке. Есть много сложных аспектов MT: 1) большое разнообразие языков, алфавитов и грамматик; 2) задача по переводу последовательности (например, предложения) в последовательность для компьютера сложнее, чем работа только с числами; 3) нетодинправильный ответ (например, перевод с языка без местоимений, зависящих от пола,она такжеонаможно так же).
Машинный перевод - относительно старая задача. С 1970-х годов были проекты для достижения автоматического перевода. За эти годы появились три основных подхода:
- Машинный перевод на основе правил (RBMT): 1970-е-1990-е годы
- Статистический машинный перевод (SMT): 1990-е-2010-е
- Нейронный машинный перевод (NMT): 2014-

Система, основанная на правилах, требует знаний экспертов об источнике и целевом языке для разработки синтаксических, семантических и морфологических правил для достижения перевода.
Статья в википедииRBMT включает базовый пример основанного на правилах перевода с английского на немецкий. Для перевода требуется англо-немецкий словарь, набор правил для грамматики английского языка и набор правил для грамматики немецкого языка
Система RBMT содержит набор задач обработки естественного языка (NLP), включая токенизацию, тегирование части речи и так далее. Большинство из этих работ должны быть выполнены как на исходном, так и на целевом языке.
Примеры RBMT
Apertiumявляется программным обеспечением RBMT с открытым исходным кодом, выпущенным на условиях GNU General Public License. Он доступен на 35 языках и находится в стадии разработки. Первоначально он был разработан для языков, тесно связанных с испанским [4]. Изображение ниже является иллюстрацией конвейера Apertium.

GramTransэто сотрудничество компании, базирующейся в Дании, и компании, базирующейся в Норвегии, которая предлагает машинный перевод для скандинавских языков [5].
преимущества
- Не требуется двуязычный текст
- Домен-независимый
- Тотальный контроль (возможное новое правило для любой ситуации)
- Возможность повторного использования (существующие правила языков могут быть перенесены в сочетании с новыми языками)
Недостатки
- Требуются хорошие словари
- Правила, установленные вручную (требуется экспертиза)
- Чем больше правил, тем сложнее иметь дело с системой
Этот подход использует статистические модели, основанные на анализе двуязычных текстовых корпусов. Впервые он был представлен в 1955 году [6], но заинтересовался только после 1988 года, когда его начал использовать исследовательский центр IBM Watson [7, 8].
Идея статистического MT заключается в следующем:
Учитывая предложение T на целевом языке, мы ищем предложение S, из которого переводчик произвел T. Мы знаем, что наш шанс ошибки минимизирован, выбрав это предложение S, которое наиболее вероятно для данного T. Таким образом, мы хотим выбрать S так, чтобы как максимизировать Pr (S | T).
-Статистический подход к машинному переводу, 1990. [8]
Используя теорему Байеса, мы можем преобразовать эту задачу максимизации в произведение Pr (S) и Pr (T | S), где Pr (S) - это вероятность модели языка S (S - правильное предложение в этом месте) и Pr (T | S) - это вероятность перевода T с учетом S. Другими словами, мы ищем наиболее вероятный перевод с учетом того, насколько точен перевод кандидата и насколько хорошо он вписывается в контекст.

Следовательно, SMT требует три шага: 1) Языковая модель (каково правильное слово с учетом его контекста?); 2) Модель перевода (каков наилучший перевод данного слова?); 3) способ найти правильный порядок слов.

Нефакторный и факторный перевод - Фигуры из Моисея: Набор инструментов с открытым исходным кодом… [9]
Примеры SMT
-
(между 2006 и 2016 годами, когдаони объявили перейти на NMT) (в 2016 годуизменено на NMT) : Набор инструментов с открытым исходным кодом для статистического машинного перевода. [9]
преимущества
- Меньше ручной работы от лингвистов
- Один SMT подходит для нескольких языковых пар
- Меньше перевода из словаря: при правильной языковой модели перевод более свободный
Недостатки
Нейронный подход использует нейронные сети для достижения машинного перевода. По сравнению с предыдущими моделями NMT могут быть построены с одной сетью вместо конвейера отдельных задач.
В 2014 году были введены модели от последовательности к последовательности, открывающие новые возможности для нейронных сетей в НЛП. До появления моделей seq2seq нейронным сетям требовался способ преобразования входных последовательностей в готовые к работе числа (горячее кодирование, вложения). Благодаря seq2seq стала возможной тренировка сети с входными и выходными последовательностями [10, 11].

NMT появился быстро. После нескольких лет исследований эти модели превзошли SMT [12]. Благодаря улучшенным результатам многие компании-поставщики переводчиков изменили свои сети на нейронные модели, включая Google [13] и Microsoft.
Проблема с нейронными сетями возникает, если данные обучения несбалансированы, модель не может учиться на редких и частых выборках. В случае языков это общая проблема, так как, например, во всей Википедии много редких слов, используемых всего несколько раз. Тренировать модель, которая не склонна к частым словам (например: многократные вхождения на каждой странице Википедии), может быть сложной задачей. В недавней статье предлагается решение с использованием шага постобработки для перевода этих редких слов в словарь [14].
Недавно исследователи Facebook представили модель MT без присмотра, работающую как с SMT, так и с NMT, для которой требуются только большие одноязычные корпуса, а не двуязычные [15]. Основным узким местом предыдущих примеров было отсутствие большой базы данных с переводами для обучения. Эта модель показывает обещание решить эту проблему.
Примеры NMT
- Google Translate (с 2016 года)ссылка на языковую группу в Google AI
- Microsoft Translate (с 2016 года)ссылка на исследование MT в Microsoft
- Перевод в Фейсбуке:ссылка на НЛП в Фейсбуке AI Система нейронного машинного перевода с открытым исходным кодом. [16]
преимущества
- Сквозные модели (без конвейера конкретных задач)
Недостатки
- Требуется двуязычный корпус
- Проблема редких слов

В этой истории мы рассмотрели три подхода к проблеме машинного перевода. Многие важные публикации собраны вместе с важными приложениями. История раскрыла историю области и собрала литературу о современных моделях. Я надеюсь, что это хорошее начало для новичка в этой области.
Если вы думаете, что чего-то не хватает, можете поделиться им со мной!
[1] Тома, П. (1977, май).Систран как многоязычная система машинного перевода.ВМатериалы Третьего Европейского Конгресса по информационным системам и сетям, преодоления языкового барьера(стр. 569–581).
[2] Crego, J., Kim, J., Klein, G., Rebollo, A., Yang, K., Senellart, J., . & Enoue, S. (2016).Чистые нейронные системы машинного перевода Systran.Препринт arXiv arXiv: 1610.05540,
[4] Корби Белло, А. М., Форкада, М. Л., Ортис Рохас, С., Перес-Ортис, Дж. А., Рамирес Санчес, Г., Санчес-Мартинес, Ф.,… и Сарасола Габиола, К. (2005).Механизм машинного перевода с открытым исходным кодом для романских языков Испании.
[5] Бик, Экхард (2007),Dan2eng: машинный перевод датско-английского широкого охватаВ: Бенте Maegaard (ред.),Труды саммита машинного перевода XI, 10–14. Сентябрь 2007 г., копенгаген, дания, С. 37–43
[6] Уивер В. (1955).Перевод,Машинный перевод языков,14, 15–23.
[7] Браун П., Кокк Дж., Пьетра С.Д., Пьетра В.Д., Елинек Ф., Мерсер Р. и Русин П. (август 1988 г.).Статистический подход к языковому переводу ВМатериалы 12-й конференции по компьютерной лингвистике, том 1(стр. 71–76). Ассоциация компьютерной лингвистики.
[8] Браун, П. Ф., Кокк, Дж., Делла Пьетра, С. А., Делла Пьетра, В. Дж., Елинек, Ф., Лафферти, Дж. Д., . & Roossin, P. S. (1990).Статистический подход к машинному переводу.Компьютерная лингвистика,16(2), 79–85.
[9] Koehn, P., Hoang, H., Birch, A., Callison-Burch, C., Federico, M., Bertoldi, N.,… & Dyer, C. (2007, июнь).Моисей: Набор инструментов с открытым исходным кодом для статистического машинного перевода.ВМатериалы 45-го ежегодного собрания ассоциации по компьютерной лингвистике, сопутствующие объемные материалы демонстрационной и стендовой сессий(стр. 177–180).
[10] Sutskever, I., Vinyals, О. & Le, Q. V. (2014).Последовательность к обучению последовательности с нейронными сетями, ВДостижения в нейронных системах обработки информации(стр. 3104–3112).
[11] Чо, К., Ван Мерриенбоер, Б., Гулцехре, С., Богданау, Д., Бугарес, Ф., Швенк, Х. и Бенжио, Ю. (2014).Изучение фраз с использованием кодера-декодера RNN для статистического машинного перевода.Препринт arXiv arXiv: 1406.1078,
[14] Луонг, М. Т., Сутскевер, И., Ле, В. В., Виньяльс, О. и Заремба, В. (2014).Решение проблемы редких слов в нейронном машинном переводе.Препринт arXiv arXiv: 1410.8206,
3. Модификации лингвистических концепций перевода в свете современной антрополингвистики.
3.1. Теория закономерных соответствий Я.И. Рецкера.
3.2. Ситуационная теория В.Г. Гака.
3.4. Россия: синтетический и аналитический перевод.
4. Литературоведческие теории перевода.
Американское переводоведение в 80-е годы ХХ века.
Американское переводоведение 80-х годов характеризуется все более широким подходом к переводческой пробематике. Если в предшествующий период многие работы выполнялись в своеобразной теоретической изоляции, без учета опыта переводов других стран (в первую очередь, европейских), то теперь переводоведы США все чаще опираются на труды зарубежных авторов, вступают с ними в дискуссию, дают оценку их теорий.
В трактовке переводческой эквивалентности С. Басснетт-Макгайр резко расходится с Ю. Найдой. Положительно оценивая классификации типов эквивалентности, предложенные А. Поповичем (лексическая, парадигматическая, стилистическая и текстовая эквивалентность) и
А. Нойбертом (синтаксическая, семантическая и парадигматическая эквивалентность), она решительно отвергает концепцию динамической эквивалентности. Разбирая один из приводимых им примеров, когда библейское “ to greet with a holy kiss ” было передано в переводе “ to give one another a hearty handshake all around ”, С. Басснетт-Макгайр решительно утверждает, что это плохой перевод. По ее мнению, целесообразно различать эквивалентность семантики и эквивалентность социальных функций. Подводя итоги дискуссии об эквивалентности, С. Басснетт-Макгайр приходит к выводу, что она представляет собой не тождество, а диалектическое отношение между знакаи и структурами в текстах и вокруг них.
Проблемы современного машинного перевода.
По мнению академика Ю.В. Рождественского центральной системой внутреннего интеллекта является система машинного перевода
(Рождественский Ю.В. «Введение в культуроведение.-М.: ЧеРо, 1996.-287с.).
Качество современного машинного перевода не высоко, однако актуальность автоматизации перевода продолжает оставаться высокой вследствие того, что
• Перевод с одного языка на другой - единственный способ преодоления языковых барьеров, реальный в современных условиях возрастающей международной коммуникации;
• Растут и расширяются возможности современных информационных технологий, в то время как пропускная способность человека-переводчика остаётся неизменной.

Задача разработки систем машинного перевода неразрывно связана с моделированием того, как перевод производит человек. В связи с этим последнее время активно изучаются возможности перевода на основе человеко - компьютерного взаимодействия, а системы машинного перевода используются при обучении алгоритмам перевод профессиональных переводчиков. Г.В. Порозинская отмечает, что в некоторых университетах, например в Московском педагогическом университете, Ужгородском университете и др., осознали необходимость разработки специальных программ подготовки переводчиков при помощи систем машинного перевода. В МГУ создана специальная лаборатория по обучению студентов работе с переводческими пакетами.
В других странах, в частности в США, подобными проблемами занимаются многие университеты. Так, программа подготовки переводчиков, разработанная в Питтсбурге, включает несколько направлений:
• овладение навыками постредактирования переводов, выполненных при помощи систем МП;
• Подготовка, координирование и контроль над работой студентов, использующих системы МП;
• Обучение методу пополнения лексических словарей, глоссариев и терминологических банков данных переводческих пакетов программ.
Автор книги рассматривает зарождение концепции машинного перевода, первые его алгоритмы, анализирует результаты, достигнутые на пути моделирования перевода с помощью языка- посредника и описывает наиболее известные современные действующие системы машинного перевода. Потребность перевода с многих языков на многие - велика, однако действующих практических систем МП, основанных на концепции языка-посредника, в настоящее время нет, а те их них, которые разрабатывались для Европейского экономического сообщества, такие как ЕВРОТРА или система DZT использованием эсперанто, в настоящее время не финансируются, поскольку достигнутые после многих лет работы результаты не оправдали доверия и надежд инвесторов.
ЛИНГВИСТИЧЕСКИЕ ТЕОРИИ ПЕРЕВОДА (ОКОНЧАНИЕ). ЛИТЕРАТУРОВЕДЧЕСКИЕ ТЕОРИИ ПЕРЕВОДА
1. Американское переводоведение в 80-е годы ХХ века.
2. Проблемы современного машинного перевода.
3. Модификации лингвистических концепций перевода в свете современной антрополингвистики.
3.1. Теория закономерных соответствий Я.И. Рецкера.
3.2. Ситуационная теория В.Г. Гака.
3.4. Россия: синтетический и аналитический перевод.
4. Литературоведческие теории перевода.
Американское переводоведение в 80-е годы ХХ века.
Американское переводоведение 80-х годов характеризуется все более широким подходом к переводческой пробематике. Если в предшествующий период многие работы выполнялись в своеобразной теоретической изоляции, без учета опыта переводов других стран (в первую очередь, европейских), то теперь переводоведы США все чаще опираются на труды зарубежных авторов, вступают с ними в дискуссию, дают оценку их теорий.
В трактовке переводческой эквивалентности С. Басснетт-Макгайр резко расходится с Ю. Найдой. Положительно оценивая классификации типов эквивалентности, предложенные А. Поповичем (лексическая, парадигматическая, стилистическая и текстовая эквивалентность) и
А. Нойбертом (синтаксическая, семантическая и парадигматическая эквивалентность), она решительно отвергает концепцию динамической эквивалентности. Разбирая один из приводимых им примеров, когда библейское “ to greet with a holy kiss ” было передано в переводе “ to give one another a hearty handshake all around ”, С. Басснетт-Макгайр решительно утверждает, что это плохой перевод. По ее мнению, целесообразно различать эквивалентность семантики и эквивалентность социальных функций. Подводя итоги дискуссии об эквивалентности, С. Басснетт-Макгайр приходит к выводу, что она представляет собой не тождество, а диалектическое отношение между знакаи и структурами в текстах и вокруг них.
Проблемы современного машинного перевода.
По мнению академика Ю.В. Рождественского центральной системой внутреннего интеллекта является система машинного перевода
(Рождественский Ю.В. «Введение в культуроведение.-М.: ЧеРо, 1996.-287с.).
Качество современного машинного перевода не высоко, однако актуальность автоматизации перевода продолжает оставаться высокой вследствие того, что
• Перевод с одного языка на другой - единственный способ преодоления языковых барьеров, реальный в современных условиях возрастающей международной коммуникации;
• Растут и расширяются возможности современных информационных технологий, в то время как пропускная способность человека-переводчика остаётся неизменной.
Задача разработки систем машинного перевода неразрывно связана с моделированием того, как перевод производит человек. В связи с этим последнее время активно изучаются возможности перевода на основе человеко - компьютерного взаимодействия, а системы машинного перевода используются при обучении алгоритмам перевод профессиональных переводчиков. Г.В. Порозинская отмечает, что в некоторых университетах, например в Московском педагогическом университете, Ужгородском университете и др., осознали необходимость разработки специальных программ подготовки переводчиков при помощи систем машинного перевода. В МГУ создана специальная лаборатория по обучению студентов работе с переводческими пакетами.
В других странах, в частности в США, подобными проблемами занимаются многие университеты. Так, программа подготовки переводчиков, разработанная в Питтсбурге, включает несколько направлений:
• овладение навыками постредактирования переводов, выполненных при помощи систем МП;
• Подготовка, координирование и контроль над работой студентов, использующих системы МП;
• Обучение методу пополнения лексических словарей, глоссариев и терминологических банков данных переводческих пакетов программ.
Автор книги рассматривает зарождение концепции машинного перевода, первые его алгоритмы, анализирует результаты, достигнутые на пути моделирования перевода с помощью языка- посредника и описывает наиболее известные современные действующие системы машинного перевода. Потребность перевода с многих языков на многие - велика, однако действующих практических систем МП, основанных на концепции языка-посредника, в настоящее время нет, а те их них, которые разрабатывались для Европейского экономического сообщества, такие как ЕВРОТРА или система DZT использованием эсперанто, в настоящее время не финансируются, поскольку достигнутые после многих лет работы результаты не оправдали доверия и надежд инвесторов.

В XXI веке существует тенденция стабильного развития в мире цифровых технологий. Вместе с тем, нарастающая глобализация мировой экономики и укрепление международных отношений направляет все большее количество компаний, которые заинтересованы в успешном сотрудничестве с иностранными бизнесменами, фирмами и корпорациями, увеличивать профессионализм в интернациональных коммуникациях и деловом общении. Таким образом, немалая ответственность ложится на такую сферу деятельности как перевод, т. к. этот вид коммуникативного акта, подразумевающий интерпретацию смысла с одного языка на другой, несомненно, является атрибутом построения бизнеса на мировом рынке. Кроме того, политическую, культурную, социальную сферы жизни человека на уровне общения всего человечества действительно сложно представить без участия квалифицированного переводчика.
Чтобы рассмотреть взаимодействия переводчика и технических ресурсов, для начала стоит выделить два вида перевода, которые существуют на сегодняшний день:
- автоматизированный (machine-assisted translation (MAT)). В данном случае программа помогает переводчику осуществлять перевод. В свою очередь, автоматизированный перевод имеет определенные формы взаимодействия:
− частично автоматизированный перевод — при таком переводе переводчик использует электронные словари либо другие электронные ресурсы;
− системы с разделением труда — в таком случае компьютер настроен на то, чтобы в исходном тексте переводить только фразы, которые имеют жёстко заданные структуры (делает это таким образом, чтобы не требовались дальнейшие поправки и исправления в тексте), а всё, не включенное в структуру перевода, выдает человеку;
− предредактирование — тип редактирования, при котором переводчик подготавливает текст к обработке специализированной программой, в таком случае происходит упрощение текста за счет удаления возможных отрывков с неоднозначным прочтением, после чего осуществляется программная обработка;
− интерредактирование — тип редактирования, при котором переводчик вносит свои корректировки в процессе работы программы, тем самым решая сложные задачи перевода;
− постредактирование — тип редактирования, при котором запрограммированная машина производит обработку исходного текста, после завершения переводчик редактирует текст, переведенный машиной, исправляя ошибки и недочеты;
− смешанный — тип редактирования, при котором процесс МП может включать в себя одновременно пред- и постредактирование. [2]
Стоит отметить, что на сегодняшний день результаты работы МП далеки от совершенства, и необходима профессиональная корректировка ряда обнаруженных погрешностей в переведенном тексте. [3] Анализы готового текста на лексическую целостность показали, что вычислительные машины успешно справляются с простыми частями речи и устойчивыми выражениями, но допускают частые ошибки при переводе падежей, речевых оборотов, логико-смысловых акцентов в предложении и построении самих предложений. Это объясняется различной интерпретацией падежей на примере русского и английского языков: в русском — через окончание, в английском — через предлоги. [4] В таком случае несложная грамматическая структура китайского языка, а именно отсутствие как таковых окончаний у слов, казалось бы, должна упростить задачу МП, но порядок слов в предложении и огромное количество омонимичных единиц в языке, всё так же оставляет пробелы и недоработки в попытках создания совершенного текста с помощью только одного МП.
В таком случае можно заверить, что готовый текст, который был переведен с помощью МП, почти всегда требует дополнительных доработок. Поэтому адекватность и компетентность результатов работы с помощью электронных систем стоит оценивать не только качеством самого МП, но и, конечно, качеством дальнейшего редактирования. В данном случае уместно будет описать ещё одну классификацию, в которой рассматриваются стратегии постредактирования текста, переведенным машиной:
− использование МП только как подсказки в терминологии;
− использование МП как грамматического или лексического подстрочника с подбором синонимичных конструкций и выражений;
− чтение МП и корректировка вызывающих сомнения фрагментов с обращением к первичному тексту;
− чтение МП и исправление видимых погрешностей и ошибок без обращения к первичному тексту. [1]
В полной мере проанализировав варианты перевода текста и его редактирования, закономерной вещью будет являться рассмотрение более конкретных инструментов перевода, благодаря которым переводчик выполняет свою работу. Известные разработчики на рынке цифровых технологий не оставляют без внимания такую важную для международного общения сферу перевода. Многие корпорации, такие как Google иMicrosoft, заявили о себе как в письменном МП, так и в устном, выпустив мобильные приложения, которые позволяют переводить и воспроизводить слова, фразы, предложения и целые фрагменты, придерживаясь канонов грамматики и фонетики. [5] Ниже приведена классификация различных электронных ресурсов и информационных платформ, существующих на данный момент:
− СМП (системы машинного перевода), выполняющие полностью автоматизированный перевод;
− системы с функцией Translation Memory, которые предоставляют возможность для работы в системах автоматизированного перевода (SDL Trados, IBM Translation Manager, Atril Deja Vu X, Wordfast, Star Transit, Omega T и т. д.); [6]
− переводчики онлайн, которые осуществляют перевод текста прямо в окне браузера (Яндекс, Google);
− словари онлайн (PROMT, ABBYY Lingvo, Мультитран, БКРС (для китайского языка); [7]
− машинный перевод с контролем языка на основе мощных баз знаний (менеджер докачки файлов RegetDelux, специальная программа поиска неструктурированных текстов TextAnalyst); [8]
Подводя итог ко всему вышесказанному, стоит отметить, что уже сегодня машинный перевод в сочетании с дальнейшим редактированием текста становится достаточно конкурентно способной переводческой работой на основании стратегических направленностей и рекомендаций, разработанных специалистами на данном поприще. Нельзя не отметить постоянный, инновационный прогресс в сфере компьютерных технологий и растущее осознание необходимости их использования. Таким образом, профессиональные переводчики осваивают полезные и продуктивные плоды постоянного развития информационных систем, и эффективность от такого взаимодействия человека и машины в быстро меняющемся мире перевода будет только возрастать. Стоит также сказать, что отмеченные программы перевода, которые успешно используются переводчиками, до сих пор не могут разрешить самую сложную задачу процесса перевода: выбор контекстуально-необходимого варианта, который обусловлен многими причинами. Качество переводимого текста зависит от стиля и тематики первичного текста, а также синтаксической, грамматической и лексической родственности языков, между которыми производится перевод. Чем более формализован стиль исходного документа, тем качественнее перевод, поэтому наиболее высокие результаты МП отмечены при интерпретации текстов технического и официально-делового стилей. Такие изъяны ещё долго будут откладывать триумф технических инноваций на переводческом поприще, по этой же причине и переводчик должен обладать высокой квалификацией и профессионализмом, чтобы осуществлять перевод должным образом.
Основные термины (генерируются автоматически): автоматизированный перевод, машинный перевод, тип редактирования, первичный текст, переводчик, текст, ABBYY, готовый текст, исходный текст, китайский язык.
Искусственные нейронные сети, обученные на больших данных, действительно повысили качество машинного перевода настолько, что это видно невооруженным взглядом. Если поискать в интернете скриншоты с курьезами Google-переводчика и протестировать их сегодня, разница налицо.


Как работает машинный перевод?
- С начала 2000-х и до 2015-2016 гг. в массовых переводчиках вроде Google Translate использовался статистический машинный перевод по фразам (phrase-based).
- Статистический переводчик рубил текст на слова и цепочки слов, после чего использовал статистику переводов фраз с языка на язык. Несмотря на огромное количество дополнительных ухищрений, это был негибкий подход, который порождал огромное количество ошибок и курьезов.
- С приходом нейросетей машинные переводчики перешли на них. Нейросеть тоже обучается на готовых переводах, но делает это гораздо гибче. Ей не нужно заранее выделять в тексте фиксированные фразы: нейросетевые алгоритмы сами постепенно выучивают на больших объемах данных оптимальные разбиения текста на части и запоминают закономерности перевода. Благодаря этому и подскочило качество работы машинных переводчиков.
Что не так с нейронным машинным переводом?
НМП имеет множество недостатков, которые совсем не похожи на проблемы человеческих переводов. Недостатки нейронных переводчиков можно поделить на 3 категории: достоверность, память и здравый смысл.
- Достоверность: Вероятно, наибольшее беспокойство вызывает то, что НМП может оказаться недостоверным, вызывающе ошибочным и совершенно непонятным. Системы НМП не гарантируют точность перевода и часто пропускают отрицания, отдельные слова или целые фразы.
- Память: Для системы НМП также характерна потеря кратковременной памяти. Системы заточены на перевод одного предложения. В результате они забывают информацию, полученную из предыдущих предложений. Получается хуже, чем развлечение, принятое на вечеринках, в котором каждый участник пишет следующую строчку истории, видя при этом только предыдущую.
- Здравый смысл: Системы НМП не обладают здравым смыслом в человеческом понимании — то есть внешним контекстом и знаниями о мире. Умение различать, какие контексты подходят для определенных переводов, важно для нашего понимания ситуаций, но эти контексты часто трудно охватить полностью.
Расскажем об этих недостатках подробнее.
Достоверность: нейросеть, да ты гонишь!
Системы НМП не вооружены методами определения достоверности фактов в тексте перевода. Хуже того, такая недостоверность непредсказуема и непоследовательна, что затрудняет ее автоматическое выявление и исправление. Например, системы НМП могут путать отрицания и опускать целые отрывки информации. Каковы последствия таких ошибок?
А вот нейросеть разворачивает важнейшую строчку в знаменитом стихотворении Пушкина на 180 градусов: дай бог превращается в god forbid, т.е. не дай бог.
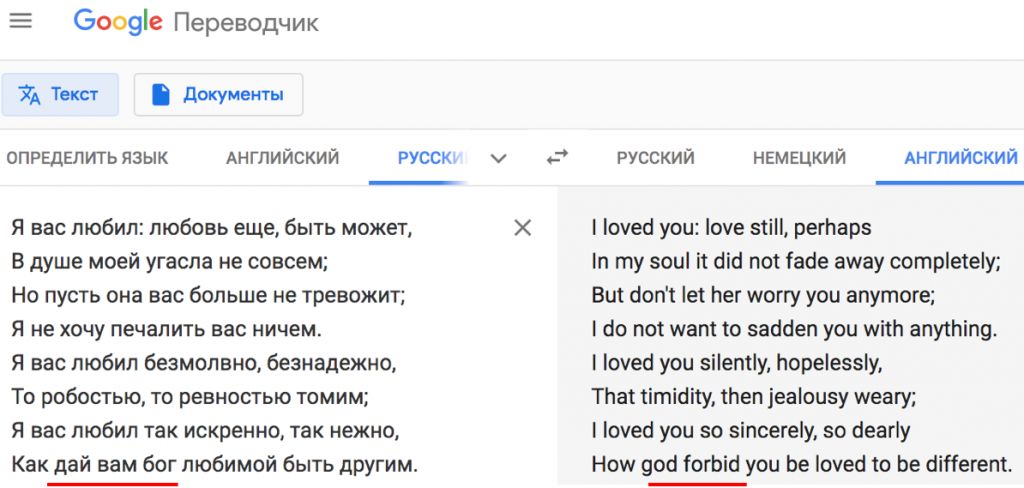
Одним из главных препятствий на пути широкого внедрения НМП является отсутствие доверия к такой системе. Почему эти системы неточны? Давайте подробно рассмотрим две основные причины и их признаки.
Проблема достоверности № 1: Искаженные данные, искаженные переводы

Хотя первоначальный малайский текст не содержал никакой гендерной информации, в переводе на английский язык предполагается, что медсестра-женщина, а программист-мужчина. Система НМТ предположила такой вариант, поскольку в данных для машинного обучения было больше примеров медсестер-женщин и больше примеров программистов-мужчин.
Проблема достоверности № 2: Попробуйте что-то новое и получите чепуху.
Системы НМП иногда выдают абсурдные вещи. И нам не совсем понятна логика этого безумного абсурда. Вот пример:
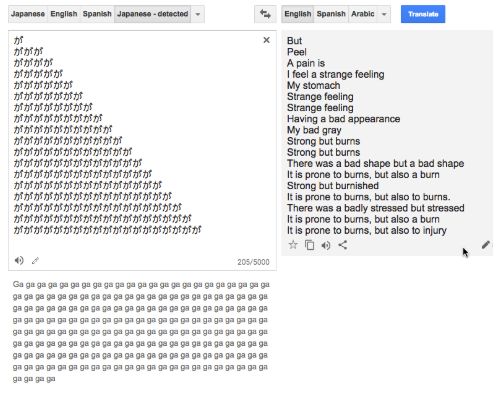
Разное число повторений этого знака японского алфавита выдает совершенно случайные фразы.
В целом системы НМП плохо работают при переводе исходных текстов, которые сильно отличаются от данных, использованных для машинного обучения. Такое явление ограничивает их способность распространяться на новые области и новые стили формулировки. Нейросети порождают языкоподобную чушь, когда сталкиваются с чем-то новым.
Память
Системы НМП имеют еще один заметный дефект: они сильно заточены на перевод отдельных предложений. Нейросети в современных переводчиках плохо помнят, что было до того предложения, которое они переводят.
К сожалению, нет. Система не может использовать правильные местоимения, даже если в предыдущем предложении говорится, что программист — женщина!
Почему системы НМП обучаются переводить по одному предложению, а не весь документ сразу? Причины технические. Во-первых, нейронной системе трудно читать длинный документ, компактно хранить всю эту информацию и эффективно ее запоминать. Во-вторых, этим системах нужно больше времени при большом объеме исходных данных.
Неспособность использовать более широкий контекст является основным препятствием для успеха НМП. Почти любой перевод требует понимания нескольких предложений, но в некоторых случаях, таких как перевод истории, это имеет решающее значение. Рассказывание историй — такая же человеческая деятельность, как и любая другая, требующая сочетание творчества, интеллекта и коммуникативных навыков, которые отличают нас от животных. Если системы перевода ИИ не могут переводить текст связно, не говоря уже о том, чтобы делать это красиво, то можем ли мы действительно сказать, что они обладают человеческим уровнем перевода?
Здравый смысл
Системы НМП не обладают здравым смыслом: знаниями или контекстом о мире, которые помогли бы помочь правильно перевести текст.
Для эффективного перевода системе НМП необходимы общие знания о мире. Однако эти знания трудно кодировать в полном объеме и нелегко извлечь из объемов данных. Нам нужны механизмы для включения здравого смысла и знаний о мире в нейронные сети.
Какой перевод можно назвать хорошим? Сложность оценки систем НМП
Как мы оцениваем качество системы машинного перевода? В настоящее время наиболее распространенным способом является использование оценки BLEU. Чтобы вычислить оценку по алгоритму оценки качества текста BLEU, мы берем переводы, произведенные системой MП, и сравниваем их с предложениями, переведенными людьми. Если перевод, написанный машиной содержат много слов и фраз, общих с переводами, выполненными людьми, то система получает более высокий балл BLEU.
Оценка BLEU является полезной жесткой мерой качества перевода, особенно для систем с низкой производительностью. Однако исследователи обнаружили, что оценка BLEU часто не сходится с оценками людей по качеству перевода. Это означает, что хотя показатель BLEU и может помочь нам определить, какая из систем лучше всего работает, обычно этого недостаточно для честной оценки самых эффективных систем.
Просить людей оценивать перевод напрямую — лучше, чем использовать BLEU. Но несмотря у оценивания качества МП человеком тоже есть недостатки.
Человеческая оценка не является автоматической, и поэтому она дорогостоящая и медленная — требует времени и знаний. Почти все исследования машинного перевода используют автоматические метрики, такие как BLEU, вместо более точной оценки человеком.
Человеческая оценка не всегда последовательна. Трудно добиться согласия между специалистами по оценке, особенно если они не являются двуязычными переводчиками, а просто сравнивают предложения на своем родном языке.
Двигаясь вперед, важно быть в курсе ограничений оценок НМП, сравнивая эту систему с переводчиками-людьми.
Мы работаем над этим… Как выглядит будущее?
НМП стремительно развивается и прогрессирует каждый месяц. Разработчики начинают осознавать проблемы, изложенные выше: достоверность, искажение данных, отсутствие смысла в полученном тексте перевода, память, здравый смысл и метрики оценок. Например, Google призвал исследователей к борьбе с искажениями фактов в НМП, выпустив новый набор метрик оценки специально для решения этой проблемы.
В течение прошлого года НМП также достиг заметных улучшений в эффективности и производительности. Это связано с внедрением новых систем, которым больше не требуется последовательно обрабатывать данные, например, слева направо или справа налево. Эти системы обрабатывают исходные предложения за раз, что позволяет легко находить соответствия в данных для машинного обучения. Таким образом, мы можем обучиться на большему объему данных за то же время и, в конечном итоге, выполнять более эффективные переводы. Среди таких успешных систем можно выделить Google Transformer и нейронные сети Salesforce’s Quasi-Recurrent.
Между тем, можно ожидать ускорение распространения новых исследований. Гарвардский OpenNMT — реализация нейронного машинного перевода с открытым исходным кодом в LuaTorch, PyTorch и Tensorflow — быстро объединяет новые методы исследований, и теперь другие легко могут брать за основу лучшие системы. Многие утверждают, что новая коммерческая система deepL, основанная бывшим исследователем Google, обходит по качеству Google Переводчика. Microsoft Переводчик продолжает предлагать новые функции в своей многоязычной поддержке предприятия. Машинный перевод развивается стремительно, и от наблюдения за его эволюцией сложно оторваться.
Подробнее узнать о том, как оценить качество машинного перевода с помощью метрики BLEU, можно тут.

Машинный перевод – этоперевод с одного языка на другой, который осуществляется с помощью компьютера. Эта проблема активно разрабатывается с 60-х годов 20 века, когда был проведен первый эксперимент по машинному переводу в США в 1954 году.
Программы машинного перевода стали появляться в России и в Японии в 1955 году, а первая конференция по машинному переводу проходит в Лондоне в 1956 году. Исследователи продолжали работать в этой сфере, и уже в 1962 году в США была создана Ассоциация машинного перевода и компьютерной лингвистики. В 1964 году Национальная академия наук сформировала комитет (ALPAC) для оценки прогресса в области компьютерной лингвистики в целом и машинного перевода в частности.
В отчете ALPAC говорится, что машинный перевод не может конкурировать с качеством перевода, выполненным человеком. В результате было выдвинуто предложение о том, чтобы прекратить финансирование исследований в области машинного перевода. Но они продолжились. Были запущены различные компании MT, включая Trados (1984). В 1991 году исследователи Харьковского университета создали программу машинного перевода с языковых пар русский-английский и немецкий-украинский.
Использование машинного перевода в Интернете началось с Systran, одной из старейших компаний по машинному переводу, которая предлагала бесплатный перевод небольших текстов (1996 г.).
В 2007 году была создана программа машинного перевода Моисей, механизм статистического машинного перевода, который можно использовать для обучения статистическим моделям перевода текста с исходного языка на целевой язык, служба перевода текста или SMS (для мобильных телефонов) в Японии (2008 г.) и мобильный телефон со встроенной функцией преобразования речи на одном языке в речь для английского языка, японского и китайского (2009 г.).
В последние годы технологии машинного перевода претерпели значительные положительные изменения благодаря исследованиям Google по нейронному машинному переводу, которые прогнозируют оптимистичное будущее этой отрасли. [5]
Система машинного перевода состоит из двуязычных словарей, в которых присутствует вся необходимая грамматическая информация в сфере морфологии, синтаксиса и семантики. Их цель заключается в обеспечении передачи трансформационных, эквивалентных и вариантных переводческих соответствий. Более того, переводчик может воспользоваться отдельными системами машинного перевода, которые имеют такую функцию, как перевод в пределах трех и более языков. В настоящее время такие программы экспериментальные. [1. С.5-15]
Суть машинного перевода состоит в том, что переводчик прикрепляет в программе текст на одном языке, в то время как компьютер обрабатывает его и в течение нескольких секунд выдает готовый текст на другом языке. Проблема заключается в недостаточной совершенности таких программ. Они не способны выполнить машинный перевод текста с обширной тематикой, определив при этом все значения слов в определенном контексте корректно.
Стоит отметить, что переводчики-профессионалы неодобрительно относятся к программам, осуществляющим машинный перевод. Они уверены, что такие системы вытеснят их из их профессиональной среды и что адекватно и грамотно перевести определенный текст только с помощью компьютерной программы машинного перевода невозможно. Убеждение в том, что машинный перевод не может конкурировать с переводом человека, – верное, несмотря на то, что разработчики программ машинного перевода производят огромную работу, чтобы компьютер мог в будущем облегчить жизнь человеку.
Логично, что машинному переводу целесообразно подвергать тексты определенного вида. Чаще всего это научно-технические тексты, которые имеют вид спецификаций, инвентарных списков, стандартизированных описаний. [2. С.23] Однако системы машинного перевода малопригодны для перевода статей, реклам, художественных текстов, где требуется творческий подход и воображение.
Общеизвестный факт, что машинный перевод требует от переводчика последующего редактирования текста перевода. Некоторые исследователи предлагают свои варианты, которые будут способствовать оптимизации этого процесса. [3] Переводчики в ходе редактирования изучили внимательно направления. Это исследование показало, что в основном переводчики делают стилистические правки. Неразумно, что от переводчиков требуется выполнение перевода без стилистических погрешностей, в то время как предполагается, что программы, выполняющие машинный перевод, выдадут такие же результаты высокого качества. Например, такие тексты как различные инструкции или руководства пользователя могут содержать дословный перевод в разумных количествах при условии, что информация, переданная данным способом, будет грамматически верна и понятна.).
Список используемых ресурсов:
Васильев А. Компьютер на месте переводчика. // Подводная лодка.1998. № 6.
Марчук Ю.Н. Проблемы машинного перевода. М.: Наука, 1983.
Читайте также: