
Представление символьной информации кратко
Обновлено: 08.07.2024
Для представления текстовой (символьной) информации в компьютере используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т.к. 2 8 = 256. Но 8 бит = 1 байту, следовательно, двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Решение. Слово состоит из 14 букв. Каждая буква является символом компьютерного алфавита и поэтому занимает 1 байт памяти. Слово займет 14 байт = 112 бит памяти, т.к. 1 байт = 8 бит.
Таблица кодировки символов: таблица, в которой устанавливается соответствие между символами и их порядковыми номерами в компьютерном алфавите.
Для разных типов ЭВМ используются различные таблицы кодировки. С распространением персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки под названием ASCII (American Standard Code for Information Interchange) — Американский стандартный код для информационного обмена.
Стандартными в этой таблице являются только первые 128 символов, т.е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная с 128 (двоичный код 10000000) и заканчивая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов (например, символы ≥, ≤ или ±). В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
В приведенных ниже таблицах приведены стандартная и альтернативная части кода ASCII (управляющие коды — от 00 до 31, в данную таблицу не включены). В них в первой колонке — десятичный номер символа, во второй колонке — сам символ, в третьей — двоичный код.
Презентация на тему: " 11 Представление символьной и графической информации в ЭВМ Лекция 7." — Транскрипт:
1 11 Представление символьной и графической информации в ЭВМ Лекция 7.
2 2 Представление символьной информации Символьная информация представляет собой набор букв, цифр, знаков препинания, математических и других символов. Совокупность всех символов, используемых в ЭВМ, представляет ее алфавит. Каждому символу соответствует свой код. Код символа в памяти ЭВМ хранится в виде двоичного числа.
4 4 Кодирование в АSCI I F – код ASCII; F европейские латинские; FF кириллица. СимволКод 16 Пробел 40 ! 21 А В 42 Кодирование в в UNICODE
5 5 Кодирование графической информации Экран дисплейного монитора представляется как набор отдельных точек -пикселей (pixels elements). Число пикселей отражается парой чисел, первое из которых показывает количество пикселей в одной строке, а второе - число строк (например, 320 х 200). Каждому пикселю ставится в соответствие фиксированное количество битов (атрибутов пикселя) в некоторой области памяти, которая называется видеопамятью. Атрибуты пикселя определяют цвет и яркость каждой точки изображения на экране монитора дисплея.
6 6 Монохромное изображение Если для атрибутов пикселя отводится один бит, то графика является двухцветной, например, черно-белой (нулю соответствует черный цвет пикселя, а единице белый цвет пикселя). Если каждый пиксель представляется п битами, то имеем возможность представить на экране одновременно 2 n оттенков. В дисплеях с монохромным монитором значение атрибута пикселя управляет яркостью точки на экране.
7 7 Цветное изображение В дисплеях с цветным монитором значение атрибута пикселя управляет интенсивностью трех составляющих, яркостями трех цветовых компонент изображения пикселя. При этом используется разделение цвета на RGB - компоненты красную, зеленую и синюю. Если каждая компонента имеет N градаций, то общее количество цветовых оттенков составляет N x N x N, при этом в число цветовых оттенков включаются белый, черный и градации серого цвета.
8 8 Цветное изображение R G B R Красный G Зеленый B Синий R+GЖелтый G+BГолубой R+B Пурпурный R+G+BБелый
9 9 Видеопамять В процессе формирования изображения обеспечивается периодическое считывание видеопамяти и преобразование значений атрибутов пикселей в последовательность сигналов, управляющих яркостью точек, отвечающих за RGB – компоненты каждого пикселя монитора. В видиопамяти может размещаться несколько страниц дисплея. Переход от воспроизведения одной страницы к воспроизведению другой страницы производится практически мгновенно.
10 10 Определение объема видеопамяти Необходимый объем видеопамяти P можно определить по формуле: P = m n b s / 8 (байт) где m количество пикселей в строке экрана; n количество строк пикселей; b количество двоичных разрядов, используемых для кодирования цвета одного пикселя; s количество страниц видеопамяти.
11 11 Представление звуковой информации Звуковая информация в компьютере представляется двумя способами: -как набор выборок звукового сигнала (оцифрованный звук); -как набор команд для синтеза звука с помощью музыкальных инструментов.
12 12 Дискретизация и квантование Рис.. Преобразование звукового сигнала в цифровую форму 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 t2 t3 t 4 t5 t6 t7 t8 t9 t10 t11 t12 t Дискретизация – это запоминание значения сигнала через определенные интервалы времени. Квантование – это выполнение аналого-цифрового преобразования с каждым полученным при дискретизации значением.
13 13 Квантование сигнала где U – величина преобразуемого значения, U – наименьшее возможное значение, отличное от нуля (величина кванта). При выполнении преобразования дробная часть значения N отбрасывается.
15 15 Объем памяти при хранения звукового сигнала где f – частота дискретизации (Гц, 1/с); t – интервал дискретизации (с); n – разрядность квантованных значений в двоичной форме (бит); k – режим воспроизведения (1 – стерео, 2 – моно); t – время воспроизведения (мин).
16 16 Пример определения объема памяти Определить объем данных в звуковом файле, воспроизводимом 10 мин с частотой выборок в секунду и 8 битовыми значениями выборки по одному (моно) и двум каналам (стерео).
17 17 Определение объема памяти для монозвучания = байт 12.6 Мб. = Определение объема памяти для стереозвучания = байт 25.2 Мб. = 18 18 Способ с использованием синтезаторов музыкальных инструментов Хранится последовательность событий (нажатие клавиш музыкантом) вместе с синхронизирующей информацией, которая обеспечивают требуемое звучание инструментов при воспроизведении музыкального произведения.
19 19 Хранение видеоинформации Видеофайл представляет собой последовательность кадров изображения (видеопоток) и звуковых данных (аудиопоток), которые должны воспроизводиться через определенные промежутки времени. где t – время воспроизведения файла (с); R V – скорость воспроизведения данных видеопотока (Гц, 1/с); S V – размер дискретизованной величины для видеопотока (байт); R A – скорость воспроизведения данных аудиопотока (Гц, 1/с); S A – размер дискретизованной величины для аудиопотока (байт). Объем памяти:
20 20 Пример определения объема видеоинформации Определим объем видеофайла, содержащего информацию, воспроизводимую 10 мин при значениях R V = 30 Гц, S V = байт, R A = Гц, S A = 8 байт. Q = байтов Мб.
Для представления целых чисел в компьютере существуют два представления: беззнаковое (для неотрицательных чисел) и знаковое.
В беззнаковом целом все разряды используются для двоичной записи числа. Соответственно, в n-разрядной сетке можно представить числа от 0 до 2 n -1. (Для 1-байтного беззнакового целого диапазон значений будет от 0 до 255; для 2-байтного — от 0 до 65535).
Если нужно представлять не только положительные, но и отрицательные значения, обычно используют дополнительный код. Он имеет следующие особенности:
Для положительных чисел дополнительный код совпадает с прямым (т.е. фактически его двоичной записью).
Для отрицательных — 2 n -|m|, где m — кодируемое число, n — количество разрядов в сетке.
Для получения дополнительного кода отрицательного числа следует сделать следующее:
Пример работы с числами в дополнительном коде
7210 = 10010002. Запись в восьмиразрядной сетке: 01001000.
Таким образом получаем запись в дополнительном коде: 11010010.
Сложим полученные числа:
Перенос из старшего разряда выходит за разрядную сетку и просто отбрасывается: 00011010.
Полученное число переведем в десятичную систему счисления:
Действительно, 72 - 46 = 26.
Числа с плавающей точкой
Для представления вещественных (действительных) чисел в современных компьютерах принят способ представления с плавающей точкой (запятой). Этот способ представления опирается на нормализованную (ее еще называют экспоненциальной) запись действительных чисел.
Нормализованная запись отличного от нуля действительного числа — это запись вида a = m * P q , где q — целое число, а m — правильная P-ичная дробь, у которой первая цифра после запятой не равна нулю, то есть
1250000=0,125 ⋅ 10 7 ;
0,123456789 = 0,123456789 ⋅ 10 0 ;
0,000076 = 0,76 ⋅ 10 -4 ;
1000,00012 = 0,100000012 ⋅ 2 4 . (порядок записан в десятичной системе)
Для хранения чисел с плавающей точкой в компьютерах обычно отводится 4, 8 или 10 байт.
Чем больше разрядов отводится под запись мантиссы, тем выше точность представления числа.
Чем больше разрядов занимает порядок, тем шире диапазон от наименьшего до наибольшего представимого числа.
Найти в Интернет более подробную информацию о кодировании чисел
Текст — это последовательность символов (букв, цифр, знаков препинания, математических знаков и т.д.). Как и любая другая информация, в компьютере текст представляется двоичным кодом. Для этого каждому символу ставится в соответствие некоторое положительное число, двоичная запись которого и будет записана в память компьютера. Соответствие между символом и его кодом определяется кодовой таблицей.
Современные кодовые таблицы ведут начало от американского стандартного кода обмена информацией ASCII (American Standard Code for Information Interchange). Он был семибитным и, соответственно, позволял представить 2 7 =128 различных символов. Таблица включала буквы латинского алфавита, цифры, основные знаки и управляющие символы (перевод строки, возврат каретки, табуляция и др.).
Во многих случаях для одного и того же языка было создано несколько кодировок. Например, для кодирования русскоязычных текстов достаточно широко использовалось (и до сих пор в некоторых случаях используются) пять кодировок:
Основные недостатки восьмибитных кодировок:
- Множественные варианты кодировок для одного и того же языка и, как следствие, проблемы с переносом текстов между компьютерами, использующими разные варианты.
- Невозможность использования в одном тексте (без дополнительных программных ухищрений) разных систем письма (за исключением сочетаний базового латинского алфавита с каким-либо иным алфавитным письмом).
- Невозможность использования для языков с иероглифической системой письма.
Первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 2 16 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+0410). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе.
Существует также UTF-32, в которой для записи любого символа используется 4 байта. Из-за очень неэкономного расхода памяти (в 2-4 раза больше, чем UTF-8, и почти вдвое больше, чем UTF-16) на практике она используется достаточно редко.
В Интернет наибольшее распространение получила система кодирования UTF-8, в MS Windows преимущественно используют UTF-16, в Unix-подобных ОС (включая Linux и Mac OS X) — в основном UTF-8.
И для одного, и для другого вида информации существуют два способа представления: либо искусственно разбить на малые элементы, либо описать правила формирования.
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
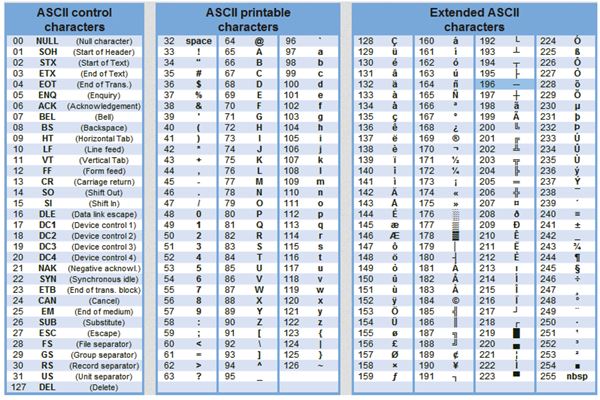
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
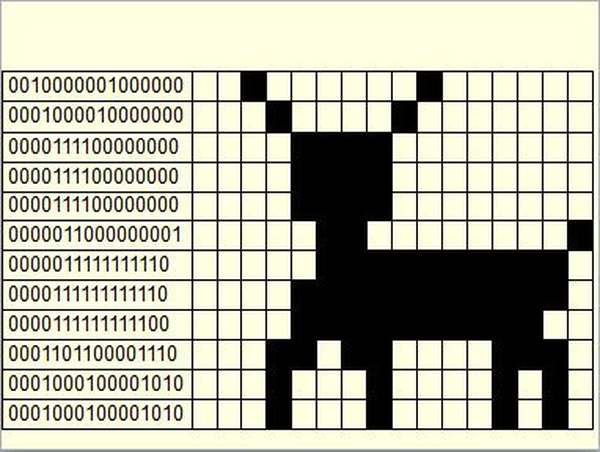
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
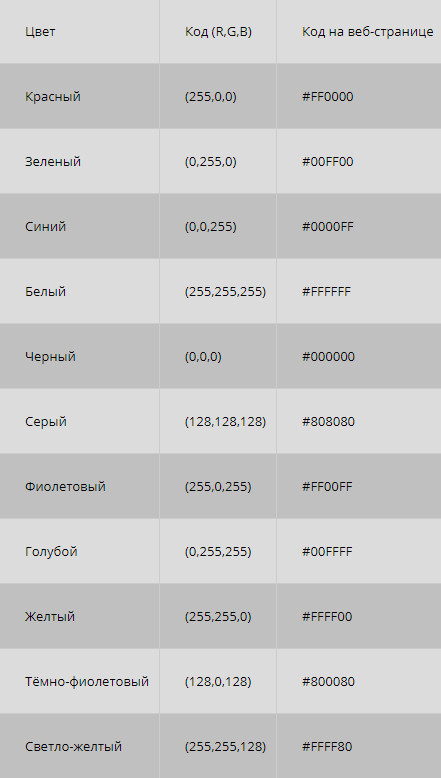
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.
Читайте также: