
Модели статистического прогнозирования кратко
Обновлено: 04.07.2024
1. Модели статистического прогнозирования (11класс)
Рассмотрим способ нахождения зависимости частоты заболеваемости
жителей города бронхиальной астмой от качества воздуха.
0011 0010 1010 1101 0001 0100 1011
Качество воздуха
в городе(чем хуже воздух, тем больше
больных астмой)
Опеределим
характер
зависимости
1
Частота легочных
заболеваний
Качественное
заключение. Его не
достаточно для того
чтобы управлять уровнем
загрязнённости воздуха
2
4
Нужно установить, какие именно примеси сильнее
всего влияют на здоровье людей, как связана
концентрация этих примесей в воздухе с числом
заболеваний. Такую зависимость можно
установить только экспериментальным путём:
посредством сбора многочисленных данных, их
анализа и обобщения.
3. Статистика- наука о сборе, измерении и анализе массовых количественных данных
Статистика- наука о сборе, измерении и
анализе массовых количественных
0011 0010 1010 1101 0001 0100 1011
данных
Виды статистики:
• медицинская статистика
• математический аппарат статистики разрабатывает наука
под названием математическая статистика
• экономическая статистика
• социальная статистика …
1
2
4
Зависимости устанавливаются экспериментальным путем:
-сбор данных;
- анализ;
- обобщение.
4. Рассмотрим пример из области медицинской статистики: Известно, что наиболее сильное влияние на бронхиально - легочные
заболевания оказывает угарный газ –оксид углерода. Специалисты по
медицинской статистике проводят сбор данных.
Сведения о средней концентрации угарного газа в атмосфере (C) и о
заболеваемости
астмой
(число
0011 0010
1010 1101 0001
0100
1011 хронических больных на 1000 жителей
(P) можно свести в таблицу и представить в виде точечной
диаграммы.
1
2
4
5. 2 варианта построения графической зависимости по экспериментальным данным
0011 0010 1010 1101 0001 0100 1011
1
2
4
Основные требования к искомой функции:
- она должна быть достаточно простой для использования ее в дальнейших
вычислениях;
-график функции должен проходить вблизи экспериментальных точек так, чтобы
отклонения этих точек о графика были минимальны и равномерны.
Полученную таким образом функцию называют в статистике регрессионной
моделью.
6. Получение регрессивной модели происходит в два этапа:
1) подбор вида функции:
y = ax + b - линейная функция;
0011 0010 1010
1101 0001 0100 1011
y = ax2 + bx
+ c - квадратичная функция (полиномиальная);
y=a ln(x) +b - логарифмическая функция;
y = aebx- экспоненциальная функция;
y = axb - степенная функция.
Во всех этих формулах х -аргумент, у- значение функции, a,b,c,dпараметры функции, ln(x) –натуральный логарифм, e –константа,
основание логарифма.
2) вычисление параметров функции:
1
2
4
метод наименьших квадратов (МНК) - сумма квадратов отклонений y-
координат всех экспериментальных точек от y-координат графика функции
должна быть минимальной.
Метод наименьших квадратов (МНК) был предложен в
XVIII веке немецким учёным математиком К.Гауссом.
0011 0010 1010 1101 0001 0100 1011
1
2
4
8. Метод наименьших квадрантов
y=ax+b – линейная функция;
0011
0010 1010 1101 0001 0100 1011
y=ax2+bx+c – квадратичная функция;
y=a ln(x)+b – логарифмическая функция;
y=aebx – экспоненциальная функция;
y=axb – степенная функция;
y=ax3+bx2+cx+d – полином 3 степени.
y=46,361x-99,881
R2=0,8384
График
регрессивной
модели
называется
ТРЕНДОМ
(англ. “trend”) –
общее
направление
или тенденция
y=3.4302e0,7555x
R2=0,9716
1
2
4
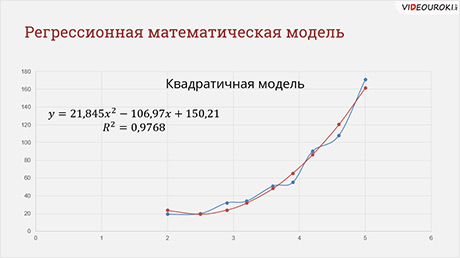
y=21,845x2-106,97x+150,21
R2=0,9788
9. Графики функций, построенные по МНК, - тренды
0011 0010 1010 1101 0001 0100 1011
1
2
4
Обратим внимание на подписи, присутствующие на графиках.
Во-первых, это записанные в явном виде искомые функции –регрессивные модели.
На графиках присутствует ещё одна величина, полученная в результате построения
трендов. Она обозначена как R2. В статистике эта величина называется
Коэффициентом детерминированности, который всегда заключён в диапазоне
от 0до 1.
Коэффициент детерминированности
2 – коэффициент детерминированности
R
0011 0010 1010 1101 0001 0100 1011
(определяет, насколько удачной является
полученная регрессионная модель). Если он равен
1, то функция точно проходит через табличные
значения, если 0, то выбранный вид регрессивной
модели предельно неудачен.
1
2
Чем R2 ближе к 1, тем удачнее регрессивная
модель.
4
11. Алгоритм построения регрессионной модели по МНК с помощью MS Excel (линейный тренд)
Построение регрессионной модели по МНК
с помощью MS Excel 2007 (линейный тренд)
0011 0010 1010 1101 0001 0100 1011
1
2
4
13. Практическая работа 3.1 Получение регрессионных моделей в MS Excel
0011 0010 1010 1101 0001 0100 1011
Цель работы: освоение способов построения по
экспериментальным данным регрессионной
модели и графического тренда средствами
табличного процессора MS Excel.
1
2
4
Семакин И.Г. Практикум. Информатика и ИКТ 11 кл., стр.209
Имея регрессивную модель , легко прогнозировать, производя расчёты с
помощью электронных таблиц
0011 0010 1010 1101 0001 0100 1011
1
2
4
15. Имея регрессивную модель , легко прогнозировать, производя расчёты с помощью электронных таблиц
0011 0010 1010 1101 0001 0100 1011
Табличный процессор даёт возможность
производить экстраполяцию графическим
способом, продолжая тренд за пределы
экспериментальных данных. Как это
выглядит при использовании
квадратичного тренда для С=7 показано на
графике.
1
2
4
16. ПРОГНОЗИРОВАНИЕ ПО РЕГРЕССИВНОЙ МОДЕЛИ Существует два способа прогнозирования по регрессивной модели:
0011 0010 1010 1101 0001 0100 1011
• Восстановление значений – прогноз в пределах
экспериментальных значений независимой
переменной.
1
2
4
• Экстраполяция – прогнозирование за пределами
экспериментальных данных
17. Ограничения при экстраполяции !
Применимость всякой регрессионной модели
ограничена,
особенно
за
пределами
экспериментальной области т.к. экстраполяция
строится на гипотезе.
0011 0010 1010 1101 0001 0100 1011
1
2
4
Вывод: применять экстраполяцию можно только
в областях данных,
близких к
экспериментальной.
18. Практическая работа 3.2 Прогнозирование в MS Excel
0011 0010 1010 1101 0001 0100 1011
Цель работы: освоение приемов прогнозирования
количественных характеристик системы по
регрессионной модели путем восстановления значений
и экстраполяции
1
Семакин И.Г. Практикум. Информатика и ИКТ 11 кл., стр.211
2
4
20. Используемая литература
• И.Г.Семакин и др. Информатика 11. Практикум, М.:
0011 0010 1010 1101 0001 0100 1011
Бином. Лаборатория знаний, 2014
• И.Г.Семакин и др. Информатика 11. Базовый уровень,
М.: Бином. Лаборатория знаний, 2014
1
2
4
Обычно в работах как отечественных, так и англоязычных авторы не задаются вопросом классификации методов и моделей прогнозирования, а просто их перечисляют. Но мне кажется, что на сегодняшний день данная область так разрослась и расширилась, что пусть самая общая, но классификация необходима. Ниже представлен мой собственный вариант общей классификации.
В чем разница между методом и моделью прогнозирования?
Метод прогнозирования представляет собой последовательность действий, которые нужно совершить для получения модели прогнозирования. По аналогии с кулинарией метод есть последовательность действий, согласно которой готовится блюдо — то есть сделается прогноз.
Модель прогнозирования есть функциональное представление, адекватно описывающее исследуемый процесс и являющееся основой для получения его будущих значений. В той же кулинарной аналогии модель есть список ингредиентов и их соотношение, необходимый для нашего блюда — прогноза.
Совокупность метода и модели образуют полный рецепт!
В настоящее время принято использовать английские аббревиатуры названий как моделей, так и методов. Например, существует знаменитая модель прогнозирования авторегрессия проинтегрированного скользящего среднего с учетом внешнего фактора (auto regression integrated moving average extended, ARIMAX). Эту модель и соответствующий ей метод обычно называют ARIMAX, а иногда моделью (методом) Бокса-Дженкинса по имени авторов.
Сначала классифицируем методы

Если мы вспомним нашу кулинарную аналогию, то и там можно разделить все рецепты на формализованные, то есть записанные по количеству ингредиентов и способу приготовления, и интуитивные, то есть нигде не записанные и получаемые из опыта кулинара. Когда мы не пользуемся рецептом? Когда блюдо очень просто: пожарить картошку или сварить пельмени — тут рецепт не нужен. Когда еще мы не пользуемся рецептом? Когда желаем изобрести что-то новенькое!
Интуитивные методы прогнозирования имеют дело с суждениями и оценками экспертов. На сегодняшний день они часто применяются в маркетинге, экономике, политике, так как система, поведение которой необходимо спрогнозировать, или очень сложна и не поддается математическому описанию, или очень проста и в таком описании не нуждается. Подробности о такого рода методах можно глянуть в [2].
Формализованные методы — описанные в литературе методы прогнозирования, в результате которых строят модели прогнозирования, то есть определяют такую математическую зависимость, которая позволяет вычислить будущее значение процесса, то есть сделать прогноз.
На этом общая классификация методов прогнозирования на мой взгляд может быть закончена.
Далее сделаем общую классификация моделей
Здесь необходимо переходить к классификации моделей прогнозирования. На первом этапе модели следует разделить на две группы: модели предметной области и модели временных рядов.

Модели предметной области — такие математические модели прогнозирования, для построения которых используют законы предметной области. Например, модель, на которой делают прогноз погоды, содержит уравнения динамики жидкостей и термодинамики. Прогноз развития популяции делается на модели, построенной на дифференциальном уравнении. Прогноз уровня сахара крови человека, больного диабетом, делается на основании системы дифференциальных уравнений. Словом, в таких моделях используются зависимости, свойственные конкретной предметной области. Такого рода моделям свойственен индивидуальный подход в разработке.
Модели временных рядов — математические модели прогнозирования, которые стремятся найти зависимость будущего значения от прошлого внутри самого процесса и на этой зависимости вычислить прогноз. Эти модели универсальны для различных предметных областей, то есть их общий вид не меняется в зависимости от природы временного ряда. Мы можем использовать нейронные сети для прогнозирования температуры воздуха, а после аналогичную модель на нейронных сетях применить для прогноза биржевых индексов. Это обобщенные модели, как кипяток, в которые если бросить продукт, то он сварится вне зависимости от его природы.
Классифицируем модели временных рядов
Мне кажется, что составить общую классификацию моделей предметной области не представляется возможным: сколько областей, столько и моделей! Однако модели временных рядов легко поддаются простому делению [3]. Модели временных рядов можно разделить на две группы: статистические и структурные.

- регрессионные модели (линейная регрессия, нелинейная регрессия);
- авторегрессионные модели (ARIMAX, GARCH, ARDLM);
- модель экспоненциального сглаживания;
- модель по выборке максимального подобия;
- и т.д.
- нейросетевые модели;
- модели на базе цепей Маркова;
- модели на базе классификационно-регрессионных деревьев;
- и т.д.
Для обоих групп я указала основные, то есть наиболее распространенные и подробно описанные модели прогнозирования. Однако на сегодняшний день моделей прогнозирования временных рядов имеется уже громадное количество и для построения прогнозов, например, стали использовать SVM (support vector machine) модели, GA (genetic algorithm) модели и многие другие.
Общая классификация
Таким образом мы получили следующую классификацию моделей и методов прогнозирования.

- Тихонов Э.Е. Прогнозирование в условиях рынка. Невинномысск, 2006. 221 с.
- Armstrong J.S. Forecasting for Marketing // Quantitative Methods in Marketing. London: International Thompson Business Press, 1999. P. 92 – 119.
- Jingfei Yang M. Sc. Power System Short-term Load Forecasting: Thesis for Ph.d degree. Germany, Darmstadt, Elektrotechnik und Informationstechnik der Technischen Universitat, 2006. 139 p.
UPD. 15.11.2016.
Господа, дошло до маразма! Недавно мне прислали на рецензию статью для ВАКовского издания со ссылкой на эту запись. Обращаю внимание, что ни в дипломах, ни в статьях, ни тем более в диссертациях ссылаться на блог нельзя! Если хотите ссылку, то используйте эту: Чучуева И.А. МОДЕЛЬ ПРОГНОЗИРОВАНИЯ ВРЕМЕННЫХ РЯДОВ ПО ВЫБОРКЕ МАКСИМАЛЬНОГО ПОДОБИЯ, диссертация… канд. тех. наук / Московский государственный технический университет им. Н.Э. Баумана. Москва, 2012.

Урок начинается с того, что учащиеся делают прогноз по уже построенной статистической модели. Из урока можно узнать, что называется восстановлением значения и для чего используется экстраполяция.
В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.
Получите невероятные возможности



Конспект урока "Моделирование статистического прогнозирования. Прогнозирование по регрессионной модели"
На сегодняшнем уроке мы с вами будем учиться прогнозировать по построенной статистической модели. А также выясним, что называется восстановлением значения и для чего используется экстраполяция.
Но прежде, чем приступить к изучению нового материала, давайте повторим некоторые важные моменты нашего прошлого урока.
На прошлом занятии мы с вами говорили о моделировании статистического прогнозирования и научились получать математическую модель по медицинским статистическим данным.
Для того чтобы получить формулу мы сначала по данным, полученным математическими статистами построили диаграмму. Затем подбирали к диаграмме вид функции. Для этого мы рассматривали стандартные функции.
Как вы помните, Полученную таким образом функцию в статистике называют регрессионной моделью.
То есть регрессионная модель – это функция, описывающая зависимость между количественными характеристиками сложных систем.
Затем, после выбора подходящих функций мы подбирали коэффициенты для них. Причём так, чтобы полученный график функции располагался как можно ближе к экспериментальным точкам. Здесь мы применяли метод наименьших квадратов.
По данному методу искомая функция должна быть построена так, чтобы сумма квадратов отклонений игрек-координат всех экспериментальных точек от игрек-координат графика функции была минимальной.
И, таким образом, получили график регрессионной модели, который называется трендом.
В статистике используется величина Эр в квадрате, которая называется коэффициентом детерминированности, он показывает, насколько удачной является полученная регрессионная модель.
Но для чего мы выполняли все эти построения и вычисления? Для чего нужны такие модели? Ответ на эти и другие вопросы мы получим сегодня на уроке.
Итак, мы получили регрессионную математическую модель по медицинским статистическим данным.
Как вы помните, модель — это объект-заменитель, который в определённых условиях может заменять объект-оригинал. Модель воспроизводит интересующие нас свойства и характеристики оригинала.
То есть наша модель воспроизводит интересующие нас свойства и характеристики, иначе говоря, теперь мы можем прогнозировать процесс путём вычислений.
По данной модели мы можем оценить уровень заболеваемости астмой не только для тех значений концентрации угарного газа, которые были получены экспериментально, но и для других значений.
Построение таких моделей очень важно с практической точки зрения. Если, например, в одном из городов планируется строительство тепловой электростанции, которая является основным источником загрязнения атмосферы, то можно рассчитать вероятную концентрацию угарного газа в воздухе и, соответственно, сделать прогноз на то, как это строительство отразится на здоровье людей.
Есть два способа прогнозирования по регрессионной модели.
Первый способ - восстановление значения.
Если прогноз рассчитывается в пределах экспериментальных значений независимой переменной (у нас независимая переменная – это концентрация угарного газа C), то такой прогноз называется восстановлением значения.
Второй способ - экстраполяция.
Если прогноз рассчитывается за пределами экспериментальных данных. Такой прогноз называется экстраполяцией.
Регрессионную модель просто строить, а затем прогнозировать по ней, с помощью электронных таблиц, например, Microsoft Excel.
На прошлом уроке мы выяснили, что наиболее подходящей является квадратичная зависимость.
Давайте построим электронную таблицу прогнозирования по регрессионной модели первым способом, то есть восстановление значения. Значения независимой переменной будем брать в пределах экспериментальных значений, в нашем случает от двух до пяти.
Итак, в ячейку А1 введём - Концентрация угарного газа (миллиграмм на метр кубический), в ячейку Б1 - Число больных астмой на одну тысячу жителей.
В ячейку А2 будем вводить значения концентрации угарного газа в промежутке от двух до пяти.
В ячейку Б2 вводим формулу для расчёта числа больных астмой на тысячу жителей. Итак, на прошлом уроке мы получили математическую формулу модели: игрек равно 21 целая 845 тысячных икс в квадрате минус 106 целых 97 сотых икс плюс 150 целых 21 сотая.
Протестируем нашу модель. Введём в ячейку А2 значение концентрации угарного газа равное трём. В ячейке Б2 отобразится результат вычислений. Число больных астмой будет равно двадцати пяти целым девятистам пяти тысячным жителя.
Однако считать число людей, даже среднее в дробных величинах нет смысла. Поэтому, нажимаем правой кнопкой мыши на ячейку Б2 и в раскрывшемся меню выберем формат ячеек. В раскрывшемся меню выберем числовые форматы – числовой и в окошке число десятичных знаков, поставим ноль.
Теперь число больных астмой будет равно 26 жителей.
Прогнозирование вторым способом – экстраполяционным производится подобным образом.
Введём в ячейку А2 значение концентрации угарного газа равное шести. В ячейке Б2 отобразится результат - 295 жителей.
Также с помощью табличного процессора Excel можно выполнять экстраполяцию графически. Для этого нужно продолжить тренд, или график регрессионной модели, за пределы экспериментальных данных.
Но бывают случаи, когда экстраполяция может оказаться неправдивой.
Применение всякой регрессионной модели ограничено, особенно за пределами экспериментальной области. В нашем примере при экстраполяции не следует далеко уходить от величины 5 миллиграмм на метр кубический.
Квадратичная модель в данном примере в области малых значений концентрации, близких к 0, вообще не годится.
Ведём в нашу таблицу значение концентрации угарного газа 0, получим 150 человек больных астмой, т. е. больше, чем при четырёх миллиграммах на метр кубический. Конечно, это неправда. В области малых значений С лучше работает экспоненциальная модель. Кстати, это довольно типичная ситуация: разным областям данных могут лучше соответствовать разные модели.
А теперь давайте вспомним всё, что мы сегодня изучили на уроке.
По полученной регрессионной модели можно прогнозировать процесс путём вычислений.
Есть два способа прогнозирования по регрессионной модели.
Первый способ. Если прогноз рассчитывается в пределах экспериментальных значений независимой переменной. Такой прогноз называется восстановлением значения.
Второй способ. Если прогноз рассчитывается за пределами экспериментальных данных. Такой прогноз называется экстраполяцией.
Регрессионную модель просто строить, а затем прогнозировать по ней, с помощью электронных таблиц.
Виды статистики Медицинская Экономическая Социальная Математическая и др.
С, мг/м 3 Р, бол./тыс. 2 19 2,5 20 2,9 32 3,2 34 3,6 51 3,9 55 4,2 90 4,6 108 5 171 Табличное и графическое представление статистических данных
Два варианта построения графической зависимости по экспериментальным данным
Метод наименьших квадрантов Этапы получения регрессивной функции: y=ax+b – линейная функция; y=ax 2 +bx+c – квадратичная функция; y=a ln(x)+b – логарифмическая функция; y=ae bx – экспоненциальная функция; y=ax b – степенная функция; y=ax 3 +bx 2 +cx+d – полином 3 степени. ТРЕНД (англ. “trend” ) – общее направление или тенденция y=46,361x-99,881 R 2 =0,8384 y=3.4302e 0,7555x R 2 = 0, 9716 y=21,845x 2 -106,97x+150,21 R 2 =0,9788
Три функции построенные по МНК y=46,361x-99,881 – линейная функция y=3.4302e 0,7555x - экспоненциальная функция y=21,845x 2 -106,97x+150,21 – квадратичная функция R 2 – коэффициент детерменированности (определяет, насколько удачной является полученная регрессионная модель)
Метод наименьших квадрантов Этапы получения регрессивной функции: y=ax+b – линейная функция; y=ax 2 +bx+c – квадратичная функция; y=a ln(x)+b – логарифмическая функция; y=ae bx – экспоненциальная функция; y=ax b – степенная функция; y=ax 3 +bx 2 +cx+d – полином 3 степени. ТРЕНД (англ. “trend” ) – общее направление или тенденция y=46,361x-99,881 R 2 =0,8384 y=3.4302e 0,7555x R 2 = 0, 9716 y=21,845x 2 -106,97x+150,21 R 2 =0,9788
Прогнозирование по регрессионной модели
Прогнозирование с помощью электронных таблиц y=21,845x 2 -106,97x+150,21 R 2 =0,9788
По теме: методические разработки, презентации и конспекты

презентация по теме "Статистические величины"
Данная презентация может быть использована на уроках алгебры в 7 классе по теме "Статистические характеристики". Материал урока представлен в виде исследлвания, что способствует его прочному усвоению.
Конспект и презентация урока алгебры в 8 классе по теме:" Наглядное представление статистической информации"
В ходе урока учащиеся повторят построение круговых и столбчатых диаграмм, а также построение кусочно-линейной функции. Знакомятся спонятиями "гистограмма", "диаграмма рассеивания" и "полиго.

Презентация к уроку "Статистические характеристики"
Дополнительный материал к уроку "Среднее арифметическое, мода, размах".
Презентация по теме: "Статистические характеристики".
Средним арифметическим ряда чисел называется частное от деления суммы этих чисел на число слагаемых.Размахом ряда чисел называется разность между наибольшим и наименьшим из этих чисел.Модой ряда назыв.
Цикл презентаций к урокам в 6 классе (8 презентаций)
Презентации к урокам: Искусство - память человека; Обобщающий урок первой четверти; В начале был ритм; О чем рассказывает музыкальный ритм; Жанр - оперетта, мюзикл; Диалог метра и ритма; От адажио к п.

Урок №1Тема: Компьютерные презентации, их назначение и классификация.Цели урока:· помочь учащимся получить представление о мультимедиа, познакомить.
Читайте также: