
Инструменты информационного поиска кратко
Обновлено: 02.07.2024
Аннотация: Понятие информационного поиска появилось только в середине прошлого века. Оно объединило такие, казалось бы, разные виды деятельности, как составление библиотечных каталогов и библиографических указателей, организация библиотек и справочно-информационного обслуживания, архивное дело, создание словарей, справочников, энциклопедий, вспомогательных указателей к монографиям и сборникам.
Предыстория и сущность
В основе этого понятия лежит представление о том, что поиск необходимой информации в любом собрании документов практически невозможен путем прочтения или даже беглого просмотра текстов всех документов данного собрания. Поэтому уже с незапамятных времен для поиска информации применяют ряд логических процедур, которые в совокупности и составляют процесс информационного поиска. Прочтение полного текста документа заменили просмотром заглавий, аннотаций, рефератов. Однако и эта процедура в многотысячных собраниях документов оказалась слишком трудоемкой. Документы пришлось систематизировать по содержанию, которое условно стали обозначать индексами, т. е. буквами и/или цифрами. Систематизация по разделам наук (классам) - один из самых первых способов раскрытия содержания научно-технических документов, моделирующий работу человеческого сознания и восходящий к глубокой древности.
По мере увеличения количества письменных и печатных документов и объема наших знаний о мире их классификация усложнялась. Эти классификации получили название иерархических. Многотомные схемы классификации конца прошлого - начала нашего века насчитывали десятки тысяч классов, подклассов, отдельных рубрик. Специалистам смежных областей знания и особенно массовому читателю библиотек стало трудно ориентироваться в схемах классификации и определять в их иерархии место той рубрики, по которой необходимо получать информацию.
Да и сами рубрики, которые строго ориентированы на узкие разделы наук, подвергающихся непрерывному процессу дифференциации, перестали удовлетворять специалистов-практиков, которым нужна была все более комплексная, предметная информация . Это привело к созданию в 70-х годах XIX в. предметной или, точнее, алфавитно-предметной классификации. На долгие годы она стала господствующей при составлении энциклопедий, вспомогательных указателей к трудам, систематически излагающим проблему или раздел науки, а в США, где она была создана, - при организации каталогов.
Стремительный рост объемов литературы значительно усложнил также задачу идентификации каждого произведения печати. Библиотеки первыми столкнулись с необходимостью создать инструмент, при помощи которого можно было бы быстро и надежно устанавливать наличие определенного произведения в их фондах. Таким инструментом стал в XIX в. авторский, именной указатель (алфавитный каталог, по библиотечной терминологии), который однозначно идентифицировал произведение по фамилиям лиц, принимавших участие в его создании или же связанных с его содержанием. Таким образом, до середины ХХ в. возможности содержательного поиска информации по справочникам или документов, содержащих нужную информацию, в библиотеках ограничивались тремя способами: систематическим, предметным и алфавитным.
Традиционной технологией реализации этих способов были списки, перечни книг и статей, содержавших необходимую информацию. С 70-х годов XIX в. эти сведения стали записываться на дискретных носителях - библиотечных карточках из плотного картона формата 75х125 мм (размер сложенной пополам американской почтовой карточки). Следует отдать должное этой традиционной технологии. Она успешно обеспечивала культурный прогресс на протяжении целого столетия вплоть до нынешнего этапа научно-технической революции, позволила накапливать и использовать многомиллионные собрания документов, обслуживать тематические потребности ученых и специалистов в необходимой им информации. На ней и сегодня еще в значительной степени зиждется деятельность всей мировой библиотечной системы - этого краеугольного камня человеческой культуры, важными составными частями которой является наука и техника.
Однако недостаточность, ограниченность этой технологии стала все более остро ощущаться уже в первой четверти ХХ в. В науке первыми почувствовали это химики из-за быстрого роста числа синтезируемых ими веществ. Обычные методы оповещения - библиографические указатели, библиотечные каталоги, справочники - начали значительно отставать по времени от успехов исследователей и перестали охватывать их результаты в полном объеме. Революции в физике и электронике, характеризующие середину прошлого столетия, усугубили трудности информационной коммуникации.
Процедуры и понятия
Научное сообщество осознало необходимость организационного оформления информационной деятельности, которая в течение нескольких десятилетий подспудно созревала в недрах науки и техники. Большая наука индустриального типа, пришедшая на смену "малой" науке университетского типа, выдвинула задачу создания систем научно-технической информации. Именно в это время, в конце 40-х - начале 50-х гг. прошлого века были сформулированы понятия информационного поиска, информационно-поисковой системы, информационно-поискового языка, была выдвинута задача механизации, а затем и автоматизации информационного поиска.
К этому времени стало ясно, что информационный поиск - это совокупность логических процедур, в результате которых в ответ на информационный запрос выдается либо необходимая информация , либо документы, в которых она может содержаться, либо библиографические адреса этих документов. В первом случае поиск получил название фактографического, во втором - документального, в третьем - библиографического. Эти процедуры сводятся к следующему.
Каждый вновь появляющийся документ подвергается анализу, в результате которого определяется его смысловое содержание. Затем это абстрактное представление о содержании (считается, что оно должно совпадать с авторским) выражается на некотором информационно-поисковом языке, т. е. синтезируется в виде библиографического описания и индекса.
Индекс образуется путем мысленного сопоставления основного смыслового содержания с потенциальными запросами потребителей информации. Эти запросы как бы зафиксированы в схемах классификации и обозначены индексами. Сама процедура выражения основного смыслового содержания документов и информационных запросов на информационно-поисковом языке получила название индексирования и составляет существенную часть аналитико-синтетической обработки документов. Информационный поиск , таким образом, заключается в замене содержательного прочтения полного текста документов формальным сличением (сравнением на соответствие) их поисковых образов с запросами на языке индексов.
Понятно, что такая замена значительно упрощает и убыстряет нахождение нужной информации, делает возможной автоматизацию процедуры сравнения. Но за это приходится платить неполнотой и неточностью поиска. Описанные выше логические процедуры допускают субъективизм осуществляющих их лиц, а используемые информационно-поисковые языки несовершенны и не способны адекватно передавать содержание документов и смысл запросов. Следовательно, информационные потери и шум - неизбежные условия информационного поиска. Когда говорят, что поиск осуществлен со 100-процентной полнотой, имеют в виду, что информационного поиска не производилось, а был осуществлен полный перебор всех текстов (современная технология в некоторых случаях предоставляет такую возможность).
Информационный поиск реализуется при помощи информационно-поисковой системы, которая в абстрактном виде должна состоять из информационно-поискового языка, правил перевода на этот язык и критерия смыслового соответствия, определяющего объем выдачи документов или информации (критерий выдачи). Конкретная система включает также средства реализации (перечень, картотека, механический селектор, компьютер ), информационный массив и обслуживающий персонал.
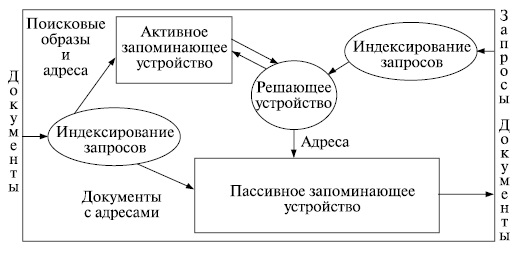
Функционирование простейшей документальной информационно-поисковой системы можно проследить по ее блок-схеме на рис. 3.1. В системе имеется два входа (для документов и запросов) и один выход (для выдачи документов по запросам). На входах имеются преобразователи для индексирования документов и запросов. Поисковые образы документов вместе с адресами их хранения (номерами) направляются в активное запоминающее устройство (ЗУакт), а сами документы - в пассивное (ЗУпас). Индексы каждого запроса сравниваются с индексами всех документов в решающем устройстве (РУ), которое в случае их соответствия (полного или предусмотренного критерием выдачи) дает в хранилище (ЗУпас) команду на выдачу документа. Это хранилище составляет как бы второй контур системы (сами документы), которого нет у библиографических (одноконтурных) систем.
Даже названия элементов на блок-схеме говорят о компьютерной реализации информационно-поисковой системы. Однако блок-схема верно обрисовывает работу любой системы, включая и наиболее традиционные. Это легко видеть на примере библиотеки. Преобразователи на входах соответствуют отделам обработки и справочно-библиографическому, ЗУакт - каталогам, ЗУпас - фондам. Нет в библиотеке только РУ - оно моделируется интеллектом читателя, который (хотя часто он и не осознает этого) вырабатывает собственный критерий выдачи и собственную стратегию поиска.
Не случайно именно эта интеллектуальная часть функционирования информационно-поисковой системы представила наибольшие трудности для автоматизации, именно она больше всего сдерживала развитие этих систем. Камнем преткновения явились, прежде всего, традиционные информационно-поисковые языки, ограничивающие возможности содержательного поиска информации. Расхожее мнение о том, что эти языки трудно поддаются автоматизации, неверно. Но они рассчитаны на ручную реализацию, и поэтому использование их в компьютерах удорожает поиск , ограничивает число пользователей и не дает никаких выигрышей, т. е. не снимает ограничений, присущих этим языкам.
А ограничения эти стали особенно ощутимыми на нынешнем этапе научно-технической революции. Прежде всего, традиционная технология поиска рассчитана на стабильный, медленно меняющийся состав запросов. В схемах классификации и перечнях предметных рубрик уже заранее как бы скоординированы все понятия, по которым можно извлекать информацию из документов и затем производить по ним поиск (такие языки поэтому и получили название предкоординатных). Это приводит к тому, что при возникновении новой проблемы или направления исследований, по которым имеется полученная прежде информация , система не обеспечивает ее поиска. Ведь эта тематика раньше не была сформулирована и не нашла места в схемах классификации и списках предметных рубрик , а значит, и индексирование по ней не производилось.
Другими словами, традиционная технология поиска не позволяет искать информацию по любому, заранее не предвиденному сочетанию признаков. При этом субъективизм индексатора при извлечении основного содержания документа увеличивает информационный шум и потери, предопределенные характером традиционных поисковых языков. Нельзя не отметить также, что основанные на них системы ручного поиска, даже фактографические, не предназначены для манипулирования полученными из них данными. Они не имеют логического аппарата для содержательной переработки этих данных. Подобная задача всегда решалась самими потребителями без помощи информационных систем.
В Интернете размещены миллионы сайтов, причем наряду с современной актуальной информацией имеется много устаревших ресурсов, немало мусора и недобросовестной рекламы — сайтов, которые рекламируют себя только для того, чтобы повысить собственный рейтинг. Интернет — это наиболее демократичный источник информации, где нет единоличного управления и почти нет цензуры. Каждый может разместить в Сети собственный ресурс и высказать свое мнение. В результате мало кто озабочен тем, чтобы избежать дублирования информации или следовать стандартам, принятым на сайте соседа.
Не зря бытует мнение, что в Сети есть все, но найти там что-либо практически невозможно. Впрочем, противоположная точка зрения, взятая на вооружение поисковой системой Яндекс, гласит, что найти в Интернете можно все. Видимо, для того чтобы находить, нужно уметь искать. В настоящей статье представлен обзор инструментов поиска в сети Интернет, объясняется механизм работы поисковых систем, даются практические рекомендации по оптимизации поиска.
Инструменты поиска
ля поиска в Интернете предназначены различные инструменты: поисковые машины (поисковики), индексированные каталоги (рубрикаторы), рейтинги и топы, метапоисковые системы и тематические списки ссылок, онлайновые энциклопедии и справочники (рис. 1). При этом для поиска разного рода информации наиболее эффективными оказываются различные инструменты. Рассмотрим каждую категорию по отдельности.
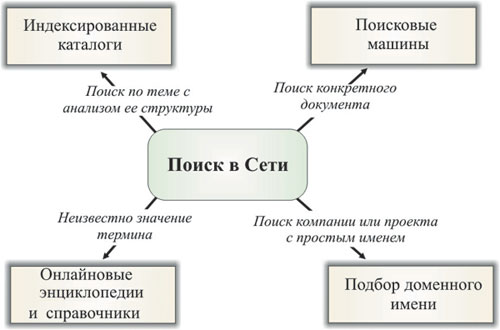
Рис. 1. Для каждого типа информации следует выбирать соответствующий инструмент поиска
Индексированные каталоги
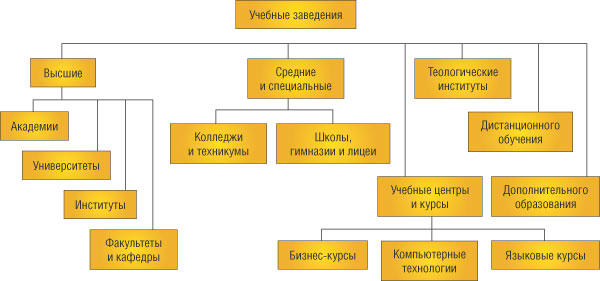
Рис. 2. Классификатор образовательных ресурсов дает наглядное представление о типах учебных заведений в системе образования
Помимо каталогов в Сети существуют рейтинги. От каталога рейтинг отличается тем, что в нем описание ресурсов делают непосредственно их владельцы, а в каталоге — авторы, то есть редакторы каталога.
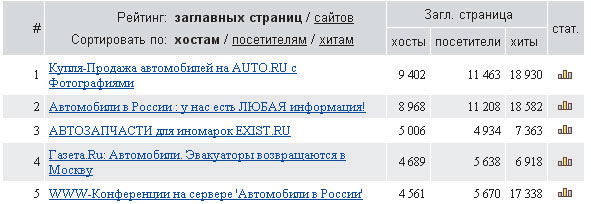
Рис. 3. Пример ранжирования ссылок в рейтинге Rambler Top 100
Тематические коллекции ссылок
Тематические коллекции ссылок — это списки, составленные группой профессионалов или коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним-единственным специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Поисковые машины
Прежде чем рассказать, как функционируют поисковые машины, следует ввести ряд терминов. Если бы компьютер был высокоинтеллектуальной системой, которой можно было бы легко объяснить, что вы ищете, то он выдавал бы вам два-три документа — именно те, которые вам нужны. Но это, к сожалению, не так, и в ответ на запрос вы обычно получаете длинный список документов, многие из которых не имеют никакого отношения к тому, о чем вы спрашивали. Такие документы называются нерелевантными (от англ. relevant подходящий, относящийся к делу). Таким образом, релевантный документ это документ, содержащий искомую информацию. Очевидно, что от умения грамотно делать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантны (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска 100%.
Таким образом, качество поиска определяется двумя параметрами: точностью и полнотой поиска. Стоит отметить, что они взаимозависимы, причем увеличение полноты снижает точность, и наоборот.
Поиск слова
Система позволяет находить:
- все формы слова для русского, английского, польского и других языков; в том числе все формы неизвестных Яндексу слов (отсутствующих в базовом словаре языка) при помощи автоматического моделирования их словоизменения;
- только заданную точную словоформу;
- только формы, производные от заданной формы.
Поиск нескольких слов
Поиск нескольких слов может происходить при:
Поиск в социальной сети
Под поиском в социальной сети понимается учет внетекстовых критериев в поиске, ранжировании и индексировании:
Дополнительные поисковые возможности
К таким возможностям относятся следующие:
Как работает поисковая машина
Поисковая машина состоит из двух частей: робота и поискового механизма. База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в существенно меньшей степени — владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (паука, червяка), который обходит все предписанные серверы и формирует базу данных, существует программа, определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности.
Следует отметить, что поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, понятно, ограничены. Несмотря на то что база данных поисковой машины постоянно обновляется за счет опроса узловых адресов в Сети, внутренние ресурсы поисковой машины и ресурсы Сети несопоставимы, и поэтому вероятность того, что машина даст устаревший адрес или не найдет нужный ресурс, всегда больше нуля. При этом проблема состоит не только в ограниченности внутренних ресурсов, но и в том, что скорость робота ограничена. Увеличение внутренних ресурсов поисковой машины не решает проблемы в силу того, что скорость обхода конечна. При этом нельзя сказать, что поисковая машина внутри имеет копию определенной части исходных ресурсов Интернета, разложенных по каталогу. Полностью информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть — так называемый индексированный список (индекс), который гораздо компактнее текста документов.
Для построения индекса исходные данные преобразуются таким образом, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список, можно провести параллель с его бумажным аналогом — так называемым конкордансом, то есть словарем, в котором в алфавитном порядке перечислены слова, употребляемые определенным писателем, а также указаны ссылки на них и частота их употребления в произведениях писателя.
Очевидно, что поиск ключевых слов с подобным словарем (индексом) гораздо эффективнее, чем поиск по книге. Отыскать нужное слово в конкордансе и посмотреть по ссылкам, где оно употребляется, намного проще, нежели перелистывать книгу в надежде наткнуться на это слово.
Построение индекса
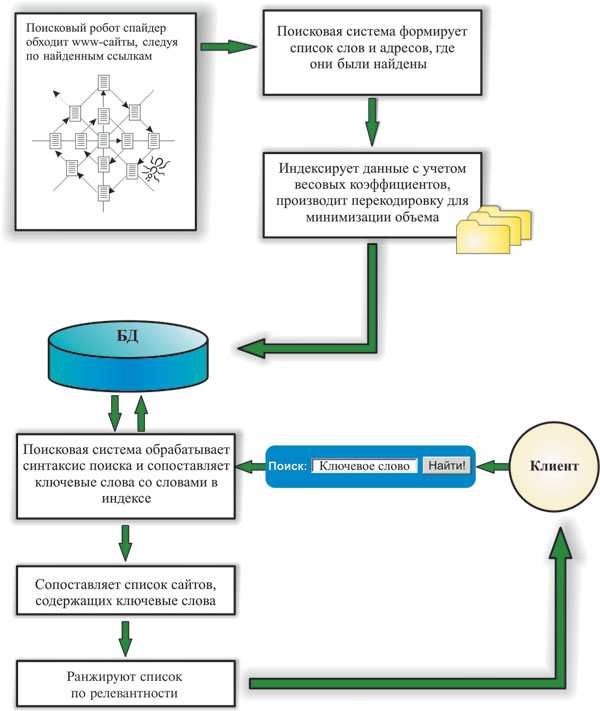
Рис. 4. Роботы-пауки просматривают информационное наполнение Web-страниц и создают индексированную базу поиска по ключевым словам, а затем по запросу пользователя выдают ранжированный по релевантности список сайтов
Поиск по индексу
Поиск по индексу заключается в том, что пользователь формирует запрос и передает его поисковой машине. В случае когда у пользователя имеется несколько ключевых слов, весьма полезно использование булевых операторов.
Наиболее часто используемые булевы операторы:
После того как пользователь передал запрос поисковой системе, она обрабатывает синтаксис запроса и сравнивает ключевые слова со словами в индексе. После этого составляется список сайтов, отвечающих запросу, они ранжируются по релевантности и формируется результат поиска, который и выдается пользователю.
Метапоисковые системы
Интернет развивается стремительными темпами — каждый день появляются сотни тысяч новых документов. Рост количества документов происходит быстрее, чем поисковые системы успевают их проиндексировать. Отсюда следует неутешительный вывод, что даже если в Сети и есть то, что вы ищете, вовсе не обязательно, что об этом знает поисковая машина, к которой вы обратились. Поисковых систем в мире сотни, и велика вероятность, что нужный вам документ не попал в ваш поисковик, но проиндексирован другой поисковой системой. Поэтому существуют службы, позволяющие транслировать ваш запрос сразу в несколько поисковых систем, — это метапоисковые системы. Однако пользоваться ими во всех случаях не следует. Если документов по теме много, то метапоиск не нужен и, возможно, даже вреден, поскольку смешивает разные логики ранжирования. Но если документов по теме мало, то метапоиск может быть полезен именно благодаря тому, что объединяет большое число поисковиков. Весьма удобной является отечественная программа ДИСКо Искатель, о которой стоит рассказать подробнее.
ДИСКо Искатель
ДИСКо Искатель (рис. 5) это метапоисковая система, инструмент для поиска информации на нескольких поисковых серверах одновременно. Главной особенностью этой программы является возможность запоминать как параметры поиска, так и его результаты и использовать их впоследствии.
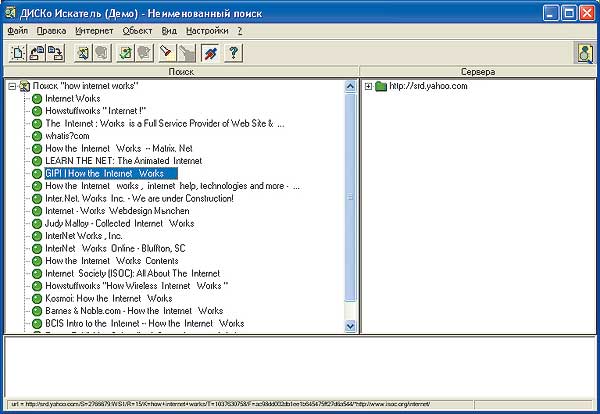
Рис. 5. Метапоисковая система ДИСКо Искатель
Двойным щелчком на любую ссылку вы можете вызвать свой Интернет-браузер для просмотра этой страницы. Выбрав любое подмножество страниц, можно потребовать создать HTML-страницы со ссылками на все эти страницы. ДИСКо Искатель запускает одновременно несколько соединений со всеми указанными поисковыми серверами, что существенно ускоряет время поиска. Оперативная информация о соединениях выводится в окно соединения. Вы можете сохранить параметры и результаты поиска в файле с расширением dio, чтобы в следующий раз снова запустить этот же поиск или внимательнее просмотреть его результаты.
Есть два способа экспорта подмножества страниц из дерева поиска: в закладки (избранное) Интернет-проводника и в HTML-страницу для последующего вызова ее из браузера.
Онлайновые энциклопедии и справочники
Очень часто нужно найти не документ, содержащий то или иное ключевое слово, а именно толкование искомого слова. Можно, конечно, поискать незнакомый вам термин с помощью поисковой машины, но в этом случае вы рискуете получить целый ряд статей, в которых этот термин используется, и при этом так и не узнать, что же он все-таки обозначает. В данном случае лучше обратиться к онлайновым энциклопедиям.
Будущее поисковых систем
Рис. 6. Поисковая система AskJeeves
Анализ социальных сетей разновидность структурного подхода, концентрирующего внимание на анализе возникающих в ходе социального взаимодействия связей (сетей), рассматриваемых в качестве структурных образований. Поведение личности или группы объясняется как производное от социальных сетей, элементами которых оно выступает. Метод получил широкое распространение при изучении процессов коммуникации в различных социальных группах. Всемирная паутина ярчайший пример социальной сети.
Булева модель, булевая, двоичная (boolean) — модель поиска, опирающаяся на операции пересечения, объединения и вычитания множеств.
Дубликаты (duplicates) разные документы с идентичным, с точки зрения пользователя, содержанием; приблизительные дубликаты, почти дубликаты (near duplicates), в отличие от точных дубликатов, содержат незначительные отличия.
Единица поиска текст, в пределах которого проверяется логическая комбинация.
Конкорданс словарь, в котором в алфавитном порядке перечислены слова, употребляемые писателем, а также указаны их адрес и частота употребления.
Индекс цитирования (citation index) число упоминаний (цитирований) научной статьи, в традиционной библиографии рассчитывается за промежуток времени, например за год.
Индексирование, индексация (indexing) процесс составления или приписывания индекса (указателя) служебной структуры данных, необходимой для последующего поиска.
Поиск похожих документов (similar document search) — задача информационного поиска, в которой в качестве запроса выступает сам документ и необходимо найти документы, максимально напоминающие данный.
Полнота, охват (recall) доля релевантного материала, заключенного в ответе поисковой системы, по отношению ко всему релевантному материалу в коллекции.
Релевантность (relevance, relevancy) соответствие документа запросу.
Словоизменение (inflection) образование определенной грамматической формы слова, обычно обязательной в определенном контексте.
Стоп-слова (stop-words) союзы, предлоги и другие частотные слова, которые поисковая система исключила из процесса индексирования и поиска для повышения своей производительности и/или точности поиска.
Точность (precision) доля релевантного материала в ответе поисковой системы.
Хиты количество заходов на сайт за определенный промежуток времени.
Хосты количество уникальных посетителей в единицу времени.
В настоящее время рост информационных ресурсов Интернета происходит высокими темпами. Всемирная сеть напоминает читальный зал библиотеки, где хранятся гигантские объемы текстовых, графических, мультимедийных, архивных и прочих файлов. Этот зал невозможно обойти полностью. Здесь все ежечасно меняется, тело разнообразных документов возрастает каждую секунду. Найти необходимую информацию становится все труднее. Различные печатные справочники устаревают еще до их выхода в свет. Единственным надежным способом поиска информации является использование специальных поисковых систем, которые постоянно отслеживают изменения информации в сети.
Используемые в сети Интернет ресурсы чаще всего размещаются на страницах WWW-серверов (или Web-серверов), в файловых архивах (FTP-архивах) и в информационно-справочной системе Gopher.
Выделяют две группы поисковых инструментов: 1) поисковые системы и 2) поисковые службы.
ИПС (информационно-поисковая система) –это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
В Internet можно выделить следующие поисковые инструменты для WWW: поисковые системы, метапоисковые системы (поисковые службы) и программы ускоренного поиска (поисковые агенты).
Рис.13. Средства поиска в WWW
В зависимости от того, кто создает базы данных, в которых осуществляется поиск необходимой пользователю информации, различают поисковые системыпервого и второго рода. В поисковых системах первого рода базы данных создаются людьми, в поисковых системах второго рода этот процесс осуществляет компьютер.
По ключевым словам можно осуществлять поиск следующей информации:
1) некоторого текста или его части;
2) фактических данных (например, массу солнца или имя президента страны);
3) картин, рисунков, кинофильмов и т.д. по их названиям;
4) технической информации (например, сведения о скорости некоторого автомобиля);
5) биографий людей (писателей, художников и т.п.).

Зарубежные поисковые машины:
- Российские поисковые машины:
Большинство поисковых систем являются одним из компонентов многофункциональных Web-сайтов Internet – так называемых порталов.
Портал– многофункциональный Web-узел Internet, предлагающий разнообразные услуги: поиск информации, бесплатная электронная почта и т.д.
Последнее время во всемирной паутине стали появляться системы, автоматически осуществляющие поиск сразу в двух индексах (индексе каталога и индексе поисковой машины). Подобные системы позволяют использовать преимущества поисковых серверов обоих типов и называются каталогами-машинами.
Поиск информации с помощью различных поисковых инструментов может осуществляться путем формирования простых и сложных запросов. Простой запрос представляет собой слово или словосочетание, которое иногда берется в кавычки. Сложный запрос формируется из слов или словосочетаний, соединяемых операторами типа AND, OR, NOT, NEAR или математическими символами, например "*", "+", "-", "~". Иногда для тех же целей используются специальные термины domain, host, link tide и др.
Размещение информационных ресурсов.
Средства поиска информационных ресурсов.
В настоящее время рост информационных ресурсов Интернета происходит высокими темпами. Всемирная сеть напоминает читальный зал библиотеки, где хранятся гигантские объемы текстовых, графических, мультимедийных, архивных и прочих файлов. Этот зал невозможно обойти полностью. Здесь все ежечасно меняется, тело разнообразных документов возрастает каждую секунду. Найти необходимую информацию становится все труднее. Различные печатные справочники устаревают еще до их выхода в свет. Единственным надежным способом поиска информации является использование специальных поисковых систем, которые постоянно отслеживают изменения информации в сети.
Используемые в сети Интернет ресурсы чаще всего размещаются на страницах WWW-серверов (или Web-серверов), в файловых архивах (FTP-архивах) и в информационно-справочной системе Gopher.
Выделяют две группы поисковых инструментов: 1) поисковые системы и 2) поисковые службы.
ИПС (информационно-поисковая система) –это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
В Internet можно выделить следующие поисковые инструменты для WWW: поисковые системы, метапоисковые системы (поисковые службы) и программы ускоренного поиска (поисковые агенты).
Рис.13. Средства поиска в WWW
В зависимости от того, кто создает базы данных, в которых осуществляется поиск необходимой пользователю информации, различают поисковые системыпервого и второго рода. В поисковых системах первого рода базы данных создаются людьми, в поисковых системах второго рода этот процесс осуществляет компьютер.
По ключевым словам можно осуществлять поиск следующей информации:
1) некоторого текста или его части;
2) фактических данных (например, массу солнца или имя президента страны);
3) картин, рисунков, кинофильмов и т.д. по их названиям;
4) технической информации (например, сведения о скорости некоторого автомобиля);
5) биографий людей (писателей, художников и т.п.).
Зарубежные поисковые машины:
- Российские поисковые машины:
Большинство поисковых систем являются одним из компонентов многофункциональных Web-сайтов Internet – так называемых порталов.
Портал– многофункциональный Web-узел Internet, предлагающий разнообразные услуги: поиск информации, бесплатная электронная почта и т.д.
Последнее время во всемирной паутине стали появляться системы, автоматически осуществляющие поиск сразу в двух индексах (индексе каталога и индексе поисковой машины). Подобные системы позволяют использовать преимущества поисковых серверов обоих типов и называются каталогами-машинами.
Поиск информации с помощью различных поисковых инструментов может осуществляться путем формирования простых и сложных запросов. Простой запрос представляет собой слово или словосочетание, которое иногда берется в кавычки. Сложный запрос формируется из слов или словосочетаний, соединяемых операторами типа AND, OR, NOT, NEAR или математическими символами, например "*", "+", "-", "~". Иногда для тех же целей используются специальные термины domain, host, link tide и др.

Конспект учеников по теме Информатики "".
Поиск информации. Поисковые системы
Код ОГЭ по информатике: 2.4.1. Компьютерные энциклопедии и справочники; информация в компьютерных сетях, некомпьютерных источниках информации. Компьютерные и некомпьютерные каталоги, поисковые машины, формулирование запросов
Поиск информации (информационный поиск) — это информационный процесс, цель которого — получение информации из информационного объекта или из хранилища информационных объектов. Поиск информации является разновидностью процесса обработки информации. Для ускорения информационного поиска создают и используют информационно-поисковые системы.
Информационно-поисковая система (ИПС) — система, выполняющая функции хранения больших объёмов информации, быстрого поиска требуемой информации и её вывода в удобном для человека виде.
Информационно-поисковые системы позволяют добавлять, удалять и изменять хранимую информацию. Существуют информационно-поисковые системы двух видов:
- документальные (в результате поиска выдаётся документ);
- справочные (в результате поиска информация предъявляется или сообщается).
Справочные ИПС, в свою очередь, делятся на:
- фактографические (в результате поиска предъявляется искомая информация, факт);
- адресные (в результате поиска предъявляется адрес, где информация хранится).
Документальные и фактографические ИПС. Документальными ИПС являются книжные фонды, открытые для доступа в читальных залах библиотек или в магазинах. Однотипные информационные объекты (книги) стоят на стеллажах чаще всего в порядке отраслей знаний (философия, математика, физика и т. п.). Читатель (покупатель), проходя вдоль стеллажей, ищет сначала названия отраслей знаний, а затем книги в разделах.
В словарях однотипные информационные объекты (слова и связанные с ними описания) расположены в алфавитном порядке, что существенно ускоряет поиск нужного слова или словосочетания. В энциклопедиях в аналогичном порядке расположены другие однотипные информационные объекты — статьи с описанием понятий. По такому же принципу организованы алфавитные книжки для записи телефонов и адресов, а также список учеников класса в классном журнале.
В другом порядке — хронологическом — организованы фактографические ИПС, которые называются расписаниями. Имеются в виду расписания занятий, расписания движения поездов, самолётов и т. п.
Адресные ИПС в документах. Адресные ИПС распространены гораздо шире документальных и фактографических. Каждый бумажный документ, исключая словари и энциклопедии, имеет собственную адресную ИПС в виде оглавления (содержания). В оглавлении записаны названия разделов документа и указаны их адреса — номера страниц, на которых эти названия находятся.
Поиск информации в документе состоит из трёх этапов:
- поиск в оглавлении подходящего названия раздела с адресом (номером страницы);
- поиск в документе страницы по адресу (номеру);
- поиск информации в разделе.
Адресные ИПС в хранилищах информационных объектов. В хранилищах бумажных документов (библиотеках, архивах) создаются адресные ИПС, которые называются каталогами.
Традиционные каталоги содержат бумажные карточки с описаниями документов и их адресов в хранилище (номер хранилища, номер стеллажа и т. д.). Адрес документа в хранилище называется шифром. Аналогичным образом организуется хранение и адресация звуко-, кино- и видеозаписей.
Поиск информации в хранилище информационных объектов состоит также из трёх этапов:
- поиск в каталоге карточки подходящего информационного объекта с адресом (шифром);
- поиск в хранилище информационного объекта по адресу (шифру);
- поиск информации в информационном объекте.
Оценка результатов поиска информации. Поиск информации в информационных объектах или в хранилищах информационных объектов редко бывает однократным. Результат поиска всегда оценивается с точки зрения полноты требуемой информации. Если информации недостаточно, поиск других источников информации проводят снова и снова, пока результат не станет удовлетворительным.
Поиск внутри компьютера
Для запуска процесса поиска в поле поиска вводят символы из имени файла или его содержимого. В области просмотра появляется список файлов и папок, которые отвечают запросу. В строке каждого файла указан реальный путь к нему.
Список с результатами поиска анализируется пользователем самостоятельно. Одно можно сказать точно: если файл на самом деле находится в компьютере, то его имя непременно окажется в списке результатов поиска.
Чтобы просмотреть файл в содержащей его папке, по строке файла щёлкают левой, потом правой клавишей мыши, а затем в контекстном меню щёлкают по пункту Расположение файла. В области просмотра открывается папка, содержащая файл.
Поиск в Интернете
Существует несколько сайтов, которые представляют в Интернете поисковые системы (поисковые машины), в том числе русскоязычные:
Поисковые системы представляют собой адресные информационно-поисковые системы. Они обычно включают два компонента:
- базу рефератов электронных документов, которые размещены на серверах Интернета, вместе с гиперссылками на эти документы;
- поисковый механизм, который позволяет автоматически по запросу найти информацию в этой базе данных (базе рефератов).
Процедура поиска информации. Для проведения автоматического поиска вводят текстовый запрос в поле поиска поисковой системы.

По умолчанию поисковые системы настроены на поиск в Интернете веб-страниц, которые содержат ключевые слова. Иногда требуется сузить область поиска, чтобы, например, найти новостную страницу или страницу-словарь, либо изменить объект поиска, чтобы, например, найти картинку, музыку, видео.

Для выбора объекта и области поиска поисковые системы в Интернете предлагают меню. После ввода данных щёлкают по кнопке Найти (или аналогичной). Через некоторое время окно браузера обновляется и в нём появляются результаты поиска в виде списка гиперссылок на документы. Этот список может содержать тысячи гиперссылок. По первой двадцатке списка всегда видно, точным ли был запрос. Иногда запрос следует уточнить и запустить поисковую систему ещё раз. В любом случае для получения ответа достаточно просмотреть первую сотню документов, обращаясь к ним с помощью гиперссылок из списка.
Поисковые каталоги. Многие поисковые системы на своих веб-страницах имеют поисковые каталоги, которые построены в виде меню, пунктами которого являются разделы каталога. Принцип построения поисковых каталогов аналогичен принципу построения дерева папок в компьютере. Выбор пункта каталога открывает новое меню, в котором также делают выбор. И так до тех пор, пока на экран не будет выведен список ссылок, входящих в конечный пункт каталога. В процессе поиска следует только правильно определяться с выбором пунктов каталога.
Сохранение информации из Интернета. Просмотр веб-страниц может сопровождаться сохранением информации с этих страниц.
Именно так в Интернете можно собрать информацию для подготовки реферата практически на любую тему.
Читайте также: