
Иерархическая база данных это в информатике кратко
Обновлено: 05.07.2024
СУБД используют различные модели баз данных . Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Модели баз данных — иерархическая база данных
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
Иерархическая база данных — пример
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Сетевая модель базы данных
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I . Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
Реляционная модель базы данных
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц ( отношений ) , состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle , Sybase , DB2 , Ingres , Informix и MS-SQL Server .
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Сравниваем три модели баз данных
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел .
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел .
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект .
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
- Избыточность данных.
- Низкая производительность.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, оставляйте ваши отзывы по текущей теме статьи. За комментарии, отклики, дизлайки, лайки, подписки низкий вам поклон!
Пожалуйста, оставьте ваши комментарии по текущей теме материала. Мы очень благодарим вас за ваши комментарии, лайки, отклики, подписки, дизлайки!
Дайте знать, что вы думаете по данной теме материала в комментариях. Мы очень благодарим вас за ваши комментарии, отклики, подписки, лайки, дизлайки!
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Содержание
Примеры
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневой директории, в которой имеется иерархия поддиректорий и файлов.
Иерархическая модель данных
Первые системы управления базами данных использовали иерархическую модель данных, и во времени их появление предшествует появлению сетевой модели.
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный гpaф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием ее в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Иерархическая модель базы данных — что это такое в информатике
Иерархическая модель базы данных — это древовидная структура, состоящая из данных или объектов разных уровней.
Преимуществами модели являются:
- простота концепции;
- независимость данных;
- целостность данных;
- безопасность базы;
- облегченный доступ к информации.
Среди несовершенств выделяют:
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
- недостаток структурной зависимости;
- сложность управления СУБД;
- сложность реализации СУБД;
- ограничение стандартизации.
Работа с иерархическими базами данных требует значительных ресурсов основной и дисковой памяти вычислительной машины. А это заметно понижает скорость считывания параметров, обработки информации.
Основные понятия, принцип построения
Между объектами иерархической базы присутствуют связи. Каждый из них может включать в себя объекты низшего уровня, быть зависимым от стоящего выше.
Если из двух объектов один расположен ближе к корню, его называют предком. Если дальше — потомком. Потомок всегда имеет только одного предка. А у предка может быть несколько потомков. При этом потомки одного уровня, имеющие единого предка, именуются близнецами или братьями.
Структурная часть
Основными элементами, информационными единицами выступают:
- поле — наименьшая из доступных пользователю неделимая единица;
- сегмент, для которого определяют экземпляр и тип.
Экземпляр — это образование из определенных значений полей данных. Тип — поименованная совокупность составляющих сегмент типов полей.
Управляющая часть
Для рассматриваемой модели разработаны языковые средства описания данных и манипулирования ими. База описывается набором операторов, определяющих структуру хранения и логику построения. При этом вариант создания связей между физическими записями определяется способом доступа, который может быть:
- индексным;
- индексно-прямым;
- прямым;
- последовательным;
- индексно-последовательным.
Описание должно содержать имя БД, способ доступа, уточнение типа сегмента в соответствии с иерархией.
Каждая база имеет один корневой сегмент. А система может включать несколько физических баз.
Операций манипулирования данными в рассматриваемой модели немного. Это поиск данных, их модификация и поиск с возможностью модификации. Но, несмотря на сравнительно небольшой набор, его вполне достаточно для корректного и эффективного управления.
Характерные особенности, какие операции можно производить
В качестве примера операций по поиску данных можно привести такие задачи, как:
- найти определенное дерево;
- совершить переход от одного дерева к другому;
- найти нужный экземпляр сегмента;
- совершить переход между сегментами в рамках одного дерева;
- совершить такой же переход посредством обхода иерархии.
Типичные операторы модификации:
- добавить новый экземпляр сегмента в определенную позицию;
- удалить текущий экземпляр;
- обновить текущий экземпляр.
Примеры поиска данных с возможностью модификации:
- найти и зафиксировать для изменения единственный экземпляр сегмента;
- найти и зафиксировать для изменения следующий экземпляр.
Особенной характеристикой иерархической базы данных является то, что она оптимизирована на чтение, а не запись. Система быстро производит поиск, выбор и представление информации пользователю, но не позволяет оперативно обновлять и заменять ее.
В сравнении с базами, построенными на основе цикла, иерархическая структура более функциональна: одна циклическая база хранит только один неизменный набор данных.
Применение иерархической структуры данных на практике
Широко известными иерархическими базами данных считаются:
- Mark IV MultiAccess Retrieval System;
- InterSystems Caché;
- IMS.
К этой же категории принадлежит System 2000 от американской частной компании SAS Institute.
Если отойти от информатики, то практическое применение можно обнаружить в биологии, географии, анатомии. По принципу нисходящей ветвящейся структуры организована классификация живых организмов, выстроены объекты гидросферы, отображены разветвления нервов и кровеносных сосудов.
Прямым аналогом, отображающим свойства и основы построения иерархических баз данных, является генеалогическое дерево.
Иерархическая база данных. Иерархическая модель данных
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
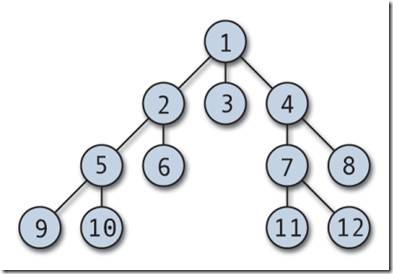
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.

Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
Еще записи о создании сайтов и их продвижении, базах данных, IT-технология и сетевых протоколах
Возможно, эти записи вам покажутся интересными
Выберете удобный для себя способ, чтобы оставить комментарий
This article has 6 comments
Привет! Спасибо, очень интересно! А не знаешь, пример иерархической базы данных это какая СУБД? И где можно скачать иерархическую СУБД?
Привет! Где скачать иерархическую СУБД или сетевую СУБД я не знаю, возможно есть где-нибудь на торрентах, возможно на оффициальных сайтах той или иной иерархической или сетевой СУБД. В качестве примера иерархической системы управления базами данных (пример иерархической СУБД, иерархической модели данных) можно привести СУБД от IBM — ISM (Information Managment System) примерно такой же вопрос был в публикации виды и типы баз данных.
Как ни странно, иерархические базы данных до сих пор используются, даже в повседневной жизни любого компьютерного юзвера, который даже об этом не подозревает. Мне, например, по работе частенько приходится работать с такими базами данных, к сожалению, именно по этому типу БД информации крайне мало сейчас, в основном, в довольно специализированной литературе и с использование через чур умных терминов.
Пожлуйста, не отправляйте в Google, я там уже искала и ничего не нашла! Как можно преобразовать данные из иерархической базы данных в представление сетевых баз данных? И наоборот: данные сетевой модели данных в иерархическую модель данных?
Для начала было бы неплохо узнать какая у вас иерархическая СУБД и какую используете сетевую СУБД, чтобы дать какой-то совет. Уверен, что уже готовые решения есть. В самом простом случае можно записывать данные в файл, которые берутся из иерархической базы данных, а затем из этого файла записывать данные в сетевую базу данных, конечно, с использованием какого-нибудь языка программирования.
Иерархическая СУБД (ИСУБД) - система управления базами данных, использующих в своей основе древовидную структуру.
Каталог СУБД-решений и проектов доступен на TAdviser.
Содержание
Подробности
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор существуют базы, которые поддерживаются этой СУБД. Иерархические модели имеют древовидную структуру, где каждому узлу соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту соответствует один входной и несколько выходных сегментов. Каждый элемент структуры лежит на единственном иерархическом пути, начинающемся от корневого. Иерархические базы данных наиболее пригодны для моделирования структур, по своей природе являющихся иерархическими. В качестве примеров можно привести воинские подразделения или сложные механизмы, состоящие из более простых узлов, которые в свою очередь тоже можно подвергнуть декомпозиции. Тем не менее существует значительное количество организаций, не сводящихся к простой иерархии. В этой модели запрос, направленный вниз по иерархии, прост, однако запрос, направленный вверх по иерархии, более сложен. К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархической базой данных является файловая система, состоящая из корневой директории, в которой имеется древовидная структура поддиректорий и файлов.
Иерархическая БД
Графически такую структуру можно изобразить в виде дерева, состоящего из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможно, чтобы объект-предок не имел потомков или имел их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
Читайте также: