
Двоичное кодирование 7 класс информатика кратко
Обновлено: 02.07.2024
Свидетельство и скидка на обучение каждому участнику
Зарегистрироваться 15–17 марта 2022 г.
Информатика 7 класс Дата _____________
личностные – представления о языке, его роли в передаче собственных мыслей и общении с другими людьми, навыки концентрации внимания.
Решаемые учебные задачи:
1) расширение и систематизация представлений учащихся о знаках и знаковых системах; систематизация представлений о языке как знаковой системе; установление общего и различий в естественных и формальных языках; систематизация знаний о формах представления информации;
2) рассмотрение сущности процесса дискретизации информации; систематизация представлений о двоичном кодировании; рассмотрение общей схемы перевода символов произвольного алфавита в двоичный код; выявление взаимосвязи между разрядностью двоичного кода и возможным количеством кодовых комбинаций; обоснование универсальности двоичного кодирования; знакомство с равномерными и неравномерными двоичными кодами.
I. Организационный момент .
II. Актуализация знаний уч-ся. Опрос домашнего задания.
III. Изложение новой темы.
Преобразование информации из непрерывной формы в дискретну ю
Сегодня мы рассмотрим более подробно, как информацию можно преобразовать из одной формы в другую: из непрерывной в дискретную и наоборот.
Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации из непрерывной формы (это голос учителя, учитель диктует текст монотонно, не прерываясь) в дискретную (это записи учеников – ученики записывают отдельные предложения).
Информация, представленная в дискретной форме, т.е. частями, значительно проще для передачи, хранения или автоматической обработки. Поэтому в компьютерной технике большое внимание уделяется методам преобразования информации из непрерывной формы в дискретную.
Процесс преобразования информации из непрерывной формы представления в дискретную называется дискретизацией информация.
Рассмотрим суть процесса дискретизации информации на более подробном примере.
На метеорологических станциях имеются самопишущие приборы для непрерывной записи атмосферного давления. Результатом их работы являются барограммы, т.е. кривые линии, показывающие, как изменялось давление в течение каких-то промежутков времени. Вот одна из таких кривых, вычерченная прибором в течение пяти часов проведения наблюдений.
На основании этой информации можно построить таблицу показания прибора в начале измерений и на конец каждого часа наблюдений.(См.рис 1.9 по учебнику)
Такая таблица даёт не полную картину того, как изменялось давление за время наблюдений: например, на ней не указано самое большое значение давления. Но если занести в таблицу все значения давления, например, наблюдаемые каждые 10-20 минут, то новая таблица будет давать более полное представление о том, как изменялось давление.
Таким образом, информацию, представленную в непрерывной форме в виде барограммы, преобразовали в дискретную форму в виде таблицы с некоторой потерей точности.
Рассмотрим еще один пример. Врач снимает кардиограмму больному при помощи специального прибора. Из прибора выходит длинная лента с непрерывной информацией в виде остроконечных кривых линий. Затем врач, анализируя эту кардиограмму, составляет уже полный анализ работы сердца больного человека в виде таблицы или описания, это информация уже будет в дискретной форме, т.к. описывается состояние больного по периодам в определённые промежутки времени.
Далее, изучая информатику, мы познакомимся со способами дискретного представления звуковой и графической информации.
Двоичное кодирование
Рассмотрим, как в общем случае можно представить информацию в дискретной форме.
Для того, чтобы представить информацию в дискретной форме необходимо выразить ее с помощью символов какого-нибудь естественного или формального языка.
Таких языков тысячи и каждый из них имеет свой алфавит.
Алфавит – это конечный набор отличных друг от друга символов или знаков, которые используются для представления информации. Мощность алфавита — это количество входящих в него символов или знаков.
В русском алфавите 33 буквы или знака, это его мощность; в десятичной системе счисления 10 знаков или цифр, это её мощность; в двоичной системе счисления только 2 знака, значит её мощность только два знака – 0 и 1.
Алфавит, содержащий два символа, называется двоичным алфавитом. Представление информации с помощью двоичного алфавита называют двоичным кодированием. Закодировав таким способом информацию, получаем её двоичный код. Возьмём в качестве символов двоичного алфавита цифры 0 и 1.
Сначала присвоим каждому символу любого алфавита порядковый номер. Номер представим с помощью двоичного алфавита. Полученный двоичный код можно считать кодом исходного символа.
Рассмотрим, как использовать двоичный код, если мощность исходного алфавита больше двух?
Для кодирования символа этого алфавита потребуется уже не один, а несколько двоичных символов. Значит, порядковому номеру каждого символа исходного алфавита будет поставлена в соответствие цепочка или последовательность из нескольких двоичных символов.
Двоичные символы (0,1) берутся в заданном алфавитном порядке и размещаются слева направо. Двоичные коды или цепочки символов читаются сверху вниз. Все цепочки или кодовые комбинации из двух двоичных символов представляют четыре различных символа любого алфавита.
Следовательно, цепочки из трёх двоичных символов получаются дополнением двухразрядных двоичных кодов справа символом 0 или 1.
В итоге кодовых комбинаций из трёх двоичных символов получается 8 - вдвое больше, чем из двух двоичных символов.
Соответственно, четырёхразрядный двоичный код позволяет получить 16 кодовых комбинаций, пятиразрядный — 32 комбинации, шестиразрядный — 64 и т. д.
Длину двоичной цепочки — количество символов в двоичном коде — называют разрядностью двоичного кода.
Количество кодовых комбинаций представляет собой не что иное как произведение некоторого количества одинаковых множителей, равного разрядности двоичного кода.
Как это можно представить в общем виде?
Если количество кодовых комбинаций обозначить буквой N, а разрядность двоичного кода - буквой i , то выявленная закономерность в общем виде это будет выглядеть так:

В математике такие произведения записывают в виде формулы.

(Количество кодовых комбинаций равно 2 в i-й степени)
Универсальность двоичного кодирования
Чтобы убедиться в универсальности двоичного кодирования решим задачу.
Вождь племени Мульти поручил своему министру разработать двоичный код и перевести в него всю важную информацию. Какой разрядности потребуется двоичный код, если алфавит, используемый племенем Мульти, содержит 16 символов?
Так как алфавит племени Мульти состоит из 16 символов, то и кодовых комбинаций им нужно 16.
В этом случае длина или разрядность двоичного кода определяется из соотношения.
Чтобы выписать все кодовые комбинации из четырёх 0 и 1, воспользуемся схемой.
Так выглядят все кодовые операции для информации племени Мульти
(0000, 0001, 0010, 0011, 0100, 0101, 0110, 0111, 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111).
Информация, представленная в непрерывной форме, может быть выражена с помощью символов некоторого естественного или формального языка.
Символы любого алфавита могут быть преобразованы в двоичный код.
Таким образом, с помощью двоичного кода может быть представлена любая информация на естественных и формальных языках, а также изображения и звуки. Это и означает универсальность двоичного кодирования.
В качестве главного достоинства двоичного кодирования будет простота технической реализации. Недостаток двоичного кодирования - большая длина получаемого кода.
Равномерные и неравномерные коды
Все ранее приведенные примеры – это примеры равномерных двоичных кодов. В их кодовых комбинациях содержится одинаковое число символов.
Неравномерные коды содержат разное число символов. Примером неравномерного кода может служить азбука Морзе, в которой для каждой буквы и цифры определена последовательность коротких и длинных сигналов.
Так, букве А соответствует один короткий и один длинный сигнал, а букве И - два коротких сигнала
IV. Закрепление темы.
V. Индивидуальная работа. Практическая работа на ПК.
VI. Итоги урока. Домашнее задание. §1.5. стр 37 – 44, ответить на вопросы.
Сегодня каждый из нас не представляет жизнь без компьютера. Компьютер — это устройство, которое может работать с разными видами данных (текстовыми, графическими, звуковыми). Чтобы эти данные компьютер мог сохранить, обработать, передать, они должны быть представлены в цифровом виде. Данные в компьютере хранятся, обрабатываются, передаются в двоичном коде.
Двоичный код — это строка символов, состоящих из \(0\) и \(1\).
Как и каждый язык (формальный или естественный), двоичный код имеет свой алфавит и мощность алфавита.
Алфавит, который состоит из двух символов, называется двоичным алфавитом.
Дискретизация информации – процесс преобразования информации из непрерывной формы представления в дискретную. Чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка.
Алфавит языка – конечный набор отличных друг от друга символов, используемых для представления информации. Мощность алфавита – это количество входящих в него символов.
Алфавит, содержащий два символа, называется двоичным алфавитом. Представление информации с помощью двоичного алфавита называют двоичным кодированием. Двоичное кодирование универсально, так как с его помощью может быть представлена любая информация.
Основная литература:
1. Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения
Кодирование информации
Для решения своих задач человеку часто приходится преобразовывать имеющуюся информацию из одной формы представления в другую. Например, при чтении вслух происходит преобразование информации из дискретной (текстовой) формы в непрерывную (звук). Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации из непрерывной формы (голос учителя) в дискретную (записи учеников).
Информация, представленная в дискретной форме, значительно проще для передачи, хранения или автоматической обработки. Поэтому в компьютерной технике большое внимание уделяется методам преобразования информации из непрерывной формы в дискретную.
Дискретизация информации – процесс преобразования информации из непрерывной формы представления в дискретную.
Рассмотрим суть процесса дискретизации информации на примере.
На метеорологических станциях имеются самопишущие приборы для непрерывной записи атмосферного давления. Результатом их работы являются барограммы – кривые, показывающие, как изменялось давление в течение длительных промежутков времени. Одна из таких кривых, вычерченная прибором в течение семи часов проведения наблюдений, показана на рисунке 1.
На основании полученной информации можно построить таблицу, содержащую показания прибора в начале измерений и на конец каждого часа наблюдений.

Полученная таблица даёт не совсем полную картину того, как изменялось давление за время наблюдений: например, не указано самое большое значение давления, имевшее место в течение четвёртого часа наблюдений. Но если занести в таблицу значения давления, наблюдаемые каждые полчаса или 15 минут, то новая таблица будет давать более полное представление о том, как изменялось давление.
Таким образом, информацию, представленную в непрерывной форме (барограмму, кривую), мы с некоторой потерей точности преобразовали в дискретную форму (таблицу).
В дальнейшем вы познакомитесь со способами дискретного представления звуковой и графической информации.
Двоичное кодирование
В общем случае, чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка. Таких языков тысячи. Каждый язык имеет свой алфавит.
Алфавит – конечный набор отличных друг от друга символов (знаков), используемых для представления информации. Мощность алфавита – это количество входящих в него символов (знаков).
Алфавит, содержащий два символа, называется двоичным алфавитом (рис. 3). Представление информации с помощью двоичного алфавита называют двоичным кодированием. Закодировав таким способом информацию, мы получим её двоичный код.
Рассмотрим в качестве символов двоичного алфавита цифры 0 и 1. Покажем, что любой алфавит можно заменить двоичным алфавитом. Прежде всего, присвоим каждому символу рассматриваемого алфавита порядковый номер. Номер представим с помощью двоичного алфавита. Полученный двоичный код будем считать кодом исходного символа.

Если мощность исходного алфавита больше двух, то для кодирования символа этого алфавита потребуется не один, а несколько двоичных символов. Другими словами, порядковому номеру каждого символа исходного алфавита будет поставлена в соответствие цепочка (последовательность) из нескольких двоичных символов. Правило получения двоичных кодов для символов алфавита мощностью больше двух можно представить схемой на рисунке.

Двоичные символы (0,1) здесь берутся в заданном алфавитном порядке и размещаются слева направо. Двоичные коды (цепочки символов) читаются сверху вниз. Все цепочки (кодовые комбинации) из двух двоичных символов позволяют представить четыре различных символа произвольного алфавита:

Цепочки из трёх двоичных символов получаются дополнением двухразрядных двоичных кодов справа символом 0 или 1. В итоге кодовых комбинаций из трёх двоичных символов получается 8 – вдвое больше, чем из двух двоичных символов:

Соответственно, четырёхразрядный двоичный код позволяет получить 16 кодовых комбинаций, пятиразрядный – 32, шестиразрядный – 64 и т. д.
Длину двоичной цепочки – количество символов в двоичном коде – называют разрядностью двоичного кода.
Обратите внимание, что:
32 = 2 ∙ 2 ∙ 2 ∙ 2 ∙ 2 и т. д.
Здесь количество кодовых комбинаций представляет собой произведение некоторого количества одинаковых множителей, равного разрядности двоичного кода.
Если количество кодовых комбинаций обозначить буквой N, а разрядность двоичного кода – буквой i, то выявленная закономерность в общем виде будет записана так:

В математике такие произведения записывают в виде:
Задача. Вождь племени Мульти поручил своему министру разработать двоичный код и перевести в него всю важную информацию. Двоичный код какой разрядности потребуется, если алфавит, используемый племенем Мульти, содержит 16 символов? Выпишите все кодовые комбинации.
Решение. Так как алфавит племени Мульти состоит из 16 символов, то и кодовых комбинаций им нужно 16. В этом случае длина (разрядность) двоичного кода определяется из соотношения: 16 = 2 i . Отсюда i = 4.
Чтобы выписать все кодовые комбинации из четырёх 0 и 1, воспользуемся схемой на рис. 1.13: 0000, 0001, 0010, 0011, 0100, 0101, 0110, 0111, 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111.
Универсальность двоичного кодирования
В начале нашей беседы вы узнали, что информация, представленная в непрерывной форме, может быть выражена с помощью символов некоторого естественного или формального языка. В свою очередь, символы произвольного алфавита могут быть преобразованы в двоичный код. Таким образом, с помощью двоичного кода может быть представлена любая информация на естественных и формальных языках, а также изображения и звуки (рис. 6). Это и означает универсальность двоичного кодирования.

Простота технической реализации – главное достоинство двоичного кодирования. Недостаток двоичного кодирования – большая длина получаемого кода.
Равномерные и неравномерные коды
Различают равномерные и неравномерные коды. Равномерные коды в кодовых комбинациях содержат одинаковое число символов, неравномерные – разное.
Выше мы рассмотрели равномерные двоичные коды.
Разбор решения заданий тренировочного модуля
№1.Тип задания: ввод с клавиатуры пропущенных элементов в тексте
Переведите десятичное число 273 в двоичную систему счисления.
Воспользуемся алгоритмом перевода целых чисел из системы с основанием p в систему с основанием q:
1. Основание новой системы счисления выразить цифрами исходной системы счисления и все последующие действия производить в исходной системе счисления.
2. Последовательно выполнять деление данного числа и получаемых целых частных на основание новой системы счисления до тех пор, пока не получим частное, меньшее делителя.
3. Полученные остатки, являющиеся цифрами числа в новой системе счисления, привести в соответствие с алфавитом новой системы счисления.
4. Составить число в новой системе счисления, записывая его, начиная с последнего остатка.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Двоичный алфавит состоит из двух цифр 0 и 1.
Цифровые ЭВМ (персональные компьютеры относятся к классу цифровых) используют двоичное кодирование любой информации. В основном это объясняется тем, что построить техническое устройство, безошибочно различающее 2 разных состояния сигнала, технически оказалось проще, чем то, которое бы безошибочно различало 5 или 10 различных состояний.
К недостаткам двоичного кодирования относят очень длинные записи двоичных кодов, что затрудняет работу с ними.
ДВОИЧНОЕ КОДИРОВАНИЕ СИМВОЛЬНОЙ (ТЕКСТОВОЙ) ИНФОРМАЦИИ
Основная операция, производимая над отдельными символами текста - сравнение символов.
При сравнении символов наиболее важными аспектами являются уникальность кода для каждого символа и длина этого кода, а сам выбор принципа кодирования практически не имеет значения.
Для кодирования текстов используются различные таблицы перекодировки. Важно, чтобы при кодировании и декодировании одного и того же текста использовалась одна и та же таблица.
Таблица перекодировки - таблица, содержащая упорядоченный некоторым образом перечень кодируемых символов, в соответствии с которой происходит преобразование символа в его двоичный код и обратно.
Наиболее популярные таблицы перекодировки: ДКОИ-8, ASCII, CP1251, Unicode.
Исторически сложилось, что в качестве длины кода для кодирования символов было выбрано 8 бит или 1 байт. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Различных комбинаций из 0 и 1 при длине кода 8 бит может быть 28 = 256, поэтому с помощью одной таблицы перекодировки можно закодировать не более 256 символов. При длине кода в 2 байта (16 бит) можно закодировать 65536 символов.
В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события):
т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.
Получите невероятные возможности



Конспект урока "Универсальное двоичное кодирование. Равномерные и неравномерные коды."
На прошлом уроке мы узнали:
· Для удобства хранения и передачи информации её часто переводят из непрерывной формы в дискретную. Такой процесс называется дискретизацией.
· В процессе дискретизации информация записывается на одном из языков.
· Алфавитом языка называются все существующие символы, которые используются для представления информации на этом языке.
· Алфавит характеризуется своей мощностью, это количество символов, которые в него входят.
· Двоичный алфавит состоит из двух символов. Запись информации с помощью такого алфавита называется двоичным кодированием.
· Двоичный код – это код информации, получившийся в результате её двоичного кодирования.
· Любой алфавит можно привести к двоичному.
· Двоичное кодирование звука.
· Двоичное кодирование изображения.
· Равномерный и неравномерный коды.
Начнём с изображения. Вполне логично, что любое изображение можно разделить на некоторые участки, каждый из которых имеет свой цвет. Именно так происходит при представлении изображений на компьютере. Изображение разбивается на маленькие фрагменты, которые можно назвать точками. Каждое изображение имеет своё разрешение. Оно состоит из двух цифр, которые разделяются крестиком или двоеточием. Число слева, означает, на сколько точек делится изображение по горизонтали, а справа – на сколько по вертикали. Таким образом изображение на компьютере представляется в виде последовательности точек, каждая из которых имеет свой цвет. То есть изображение на компьютере можно представить, последовательно записав цвета всех точек, которые в него входят.

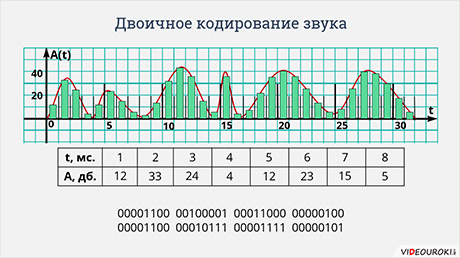
Немного иначе происходит двоичное кодирование звука. Позже из курса физики вы узнаете, что любой звук можно представить в виде непрерывной волны. Эту волну можно описать, зависимостью её амплитуды, то есть громкости звука от времени. Такую зависимость легко изобразить в виде графика. Чтобы представить звук в виде дискретных сигналов, время, в течение которого продолжается звук, делится на равные небольшие промежутки. И на каждом из промежутков заново определяется амплитуда волны, то есть громкость звука.

То, есть звук можно представить в виде списка чисел, каждое из которых означает амплитуду волны, в течение небольшого промежутка времени. Эти числа можно представить в виде двоичных кодов с одинаковым количеством разрядов. Таким образом звук на компьютере представляется в виде списка двоичных кодов одинаковой разрядности, каждый из которых обозначает амплитуду звуковой волны на некотором небольшом промежутке времени.



Снова ищем минимальные частоты появления. Возьмём две правые частоты и объединим их. Их сумма равна 6.

Теперь объединим две левые частоты. Их сумма равна 8.


Теперь двигаясь, сверху вниз присвоим ветвям дерева значения 0 и 1. Ветви, с большей частотой будем присваивать 1, а ветви с меньшей частотой – 0. Так левой ветви верхнего узла присвоим 1, а правой – 0.

Затем рассмотрим левый узел. Там две частоты равны. Поэтому левой ветви присвоим 0, а правой – 1.

Рассмотрим узел, частота которого равна 6. Частота появления пробела меньше суммарной частоты правой ветви. Поэтому левой ветви присвоим 0, а правой ветви – 1.

По такому же принципу пронумеруем оставшиеся ветви дерева.


Важно запомнить:
· Универсальность двоичного кодирования означает, что его можно применять для кодирования информации на любом формальном или неформальном языке, а также изображений и звука.
· Все коды можно разделить на равномерные и неравномерные, где равномерный код состоит из комбинаций равной длины, а неравномерный код состоит из комбинаций разной длины.
· Использование неравномерного кодирования позволяет сократить длину кода.
Читайте также: