
Биг дата это кратко
Обновлено: 05.07.2024
Если углубиться в смысл профессии аналитика или разработчика, то под big data поднимают набор методов и инструментов для хранения и обработки данных и решения задач.
Зачастую аналитик занимается неструктурированными (неорганизованными) данными, которым нужно придать форму с помощью алгоритмов, библиотек и Python. Разработчику же желательно давать ТЗ по структурированным данным, так получится быстрее решить какую-то бизнес-задачу.
Под понятием Big Data могут скрываться очень разные данные, в зависимости от сферы, направления компании, специфики конкретного специалиста. Например, данные по:
- погоде со всего мира, конкретной страны,
- трафику на дорогах,
- интересах или тратах клиентов банка или сети магазинов,
- приборам на электростанциях,
- продолжительности поездок клиентов на такси, маршрутам,
- и так далее.
Каждый раз, когда мы открываем приложение, ищем информацию в интернете или просто меняем местоположение с мобильным в кармане, генерируются big data. В результате появляется огромный объем информации – это становится большой ценностью для многих компаний. Таким образом, big data – это данные, отличающиеся: - разнообразием (variety), - большими объемами (volume), -. Читать далее
Дословно, Big Data – это большие данные. Если говорить более профессиональным языком, то это набор специальных методов и инструментов, которые используются для хранения и обработки огромных объемов данных для решения конкретных задач. Причем данные могут быть как структурированными, так и неструктурированными (неорганизованными, неоднородными).
Я считаю данный ответ сомнительным.
Прочла книги Юваля Ноя Харари и узнала о новой религии - датаизм. Датаисты верят в алгоритмы и отвечают на вопросы, на которые традиционная наука не даёт ответа. Харари полагает, что на смену веры в Бога и Человека пришла новая религия - верящая в алгоритмы - Big Data. Удачи нам всем и мудрости!
Это новая религия. Удастся ли датаизму, пришедшему на смену гуманизму, упрочить свои позиции или лет через двадцать обнаружится, что организмы и не алгоритмы вовсе. Датаизм это порождение биологии и информатики. Эта религия не чтит ни богов, ни людей, а поклоняется данным. Датаисты “скептически относятся к человеческим знаниям и мудрости и предпочитают полагаться. Читать далее
Это может быть тысячи программ каждая с своими данными задача объединить эти данные чтобы это не было хаосом а получилась одна конкретная !!
Бизнес-анализ данных компании, поиск точек роста. Анализ продаж и клиентской базы. · 4 июл 2021 · ceo-bi.club
Big Data - это достаточно молодой термин, который появился в лексиконе ИТ-рынка в начале 2000х годов.
Это скорее набор описательных характеристик подходов и методов обработки массивов данных из разных источников систем с помощью средств автоматизации алгоритмов обработки данных и вычислений на их основе.
К Big Data можно отнести такие разделы, как:
получение данных (разработка скриптов подключений)
загрузку, очистку, трансформацию и хранение (базы данных)
нахождение взаимосвязей между данными (инжиниринг данных, хранилище данных)
математические и статистические вычисления на основе данных (скрипты машинного обучения для обработки данных, построение моделей данных для последующих расчетов)
визуализация данных (построение визуальных отчетов из моделей данных для бизнес-пользователей)
проведение анализа данных для выявления зависимостей, отклонений или аномалий (бизнес-анализ на очищенных данных)
Ключевое отличие в том, что все эти характеристики прежде всего говорят о наличие высокопроизводительных мощностей (серверное оборудование) и штата специалистов (инженер баз данных, инженер данных, аналитики и т.п.) и широкой сети источников данных (погода в определенных регионах и количество посетителей торгового зала).
При это важно понимать, что задолго до этого термина 1960х годах появилось понятие Business Intelligence, описывающие подход к работе с корпоративной информацией и данными. Именно в нем и заключается ответ на вторую часть Вашего вопроса. Да, каждая компания самостоятельно выбирает свой путь развития работы с данными, системы и источники. Но прежде всего нужно помнить о том, что данные придется между собой связывать. Поэтому изначально очень важно этот момент не упустить и в свободной форме, от руки, грубо говоря, нарисовать то, как данные должны использоваться. Проведя простой анализ: что есть сейчас и что должно стать завтра. Соответственно, чего сейчас не хватает, для использования завтра.
Рассказываем об основных терминах, методах и инструментах, которые используются при анализе больших данных.

Что такое большие данные?
Big Data – область, в которой рассматриваются различные способы анализа и систематического извлечения больших объемов данных. Она включает применение механических или алгоритмических процессов получения оперативной информации для решения сложных бизнес-задач. Специалисты по Big Data работают с неструктурированными данными, результаты анализа которых используются для поддержки принятия решений в бизнесе.
Как классифицируются большие данные?
Выделим три категории:
- Структурированные данные, имеющие связанную с ними структуру таблиц и отношений. Например, хранящаяся в СУБД информация, файлы CSV или таблицы Excel.
- Полуструктурированные (слабоструктурированные) данные не соответствуют строгой структуре таблиц и отношений, но имеют другие маркеры для отделения семантических элементов и обеспечения иерархической структуры записей и полей. Например, информация в электронных письмах и файлах журналов.
- Неструктурированные данные вообще не имеют никакой связанной с ними структуры, либо не организованы в установленном порядке. Обычно это текст на естественном языке, файлы изображений, аудиофайлы и видеофайлы.
Характеристики больших данных
Большие данные характеризуются четырьмя правилами (англ. 4 V’s of Big Data: Volume, Velocity, Variety, Veracity) :
- Объем: компании могут собирать огромное количество информации, размер которой становится критическим фактором в аналитике.
- Скорость, с которой генерируется информация. Практически все происходящее вокруг нас (поисковые запросы, социальные сети и т. д.) производит новые данные, многие из которых могут быть использованы в бизнес-решениях.
- Разнообразие: генерируемая информация неоднородна и может быть представлена в различных форматах, вроде видео, текста, таблиц, числовых последовательностей, показаний сенсоров и т. д. Понимание типа больших данных является ключевым фактором для раскрытия их ценности.
- Достоверность: достоверность относится к качеству анализируемых данных. С высокой степенью достоверности они содержат много записей, которые ценны для анализа и которые вносят значимый вклад в общие результаты. С другой стороны данные с низкой достоверностью содержат высокий процент бессмысленной информации, которая называется шумом.
Традиционный подход к хранению и обработке больших данных
При традиционном подходе данные, которые генерируются в организациях, подаются в систему ETL (от англ. Extract, Transform and Load) . Система ETL извлекает информацию, преобразовывает и загружает в базу данных. Как только этот процесс будет завершен, конечные пользователи смогут выполнять различные операции, вроде создание отчетов и запуска аналитических процедур.
По мере роста объема данных, становится сложнее ими управлять и тяжелее обрабатывать их с помощью традиционного подхода. К его основным недостаткам относятся:
- Дорогостоящая система, которая требует больших инвестиций при внедрении или модернизации, и которую малые и средние компании не смогут себе позволить.
- По мере роста объема данных масштабирование системы становится сложной задачей.
- Для обработки и извлечения ценной информации из данных требуется много времени, поскольку инфраструктура разработана и построена на основе устаревших вычислительных систем.
Термины
Облачные Вычисления
Облачные вычисления или облако можно определить, как интернет-модель вычислений, которая в значительной степени обеспечивает доступ к вычислительным ресурсам. Эти ресурсы включают в себя множество вещей, вроде прикладного программного обеспечение, вычислительных ресурсов, серверов, центров обработки данных и т. д.
Прогнозная Аналитика
Технология, которая учится на опыте (данных) предсказывать будущее поведение индивидов с помощью прогностических моделей. Они включают в себя характеристики (переменные) индивида в качестве входных данных и производит оценку в качестве выходных. Чем выше объясняющая способность модели, тем больше вероятность того, что индивид проявит предсказанное поведение.
Описательная Аналитика
Описательная аналитика обобщает данные, уделяя меньше внимания точным деталям каждой их части, вместо этого сосредотачиваясь на общем повествовании.
Базы данных
Данные нуждаются в кураторстве, в правильном хранении и обработке, чтобы они могли быть преобразованы в ценные знания. База данных – это механизм хранения, облегчающий такие преобразования.
Хранилище Данных
Хранилище данных определяется как архитектура, которая позволяет руководителям бизнеса систематически организовывать, понимать и использовать свои данные для принятия стратегических решений.
Бизнес-аналитика
Бизнес-аналитика (BI) – это набор инструментов, технологий и концепций, которые поддерживают бизнес, предоставляя исторические, текущие и прогнозные представления о его деятельности. BI включает в себя интерактивную аналитическую обработку (англ. OLAP, online analytical processing) , конкурентную разведку, бенчмаркинг, отчетность и другие подходы к управлению бизнесом.
Apache Hadoop
Apache Hadoop – это фреймворк с открытым исходным кодом для обработки больших объемов данных в кластерной среде. Он использует простую модель программирования MapReduce для надежных, масштабируемых и распределенных вычислений.
Apache Spark
Apache Spark – это мощный процессорный движок с открытым исходным кодом, основанный на скорости, простоте использования и сложной аналитике, с API-интерфейсами на Java, Scala, Python, R и SQL. Spark запускает программы в 100 раз быстрее, чем Apache Hadoop MapReduce в памяти, или в 10 раз быстрее на диске. Его можно использовать для создания приложений данных в виде библиотеки или для выполнения специального анализа в интерактивном режиме. Spark поддерживает стек библиотек, включая SQL, фреймы данных и наборы данных, MLlib для машинного обучения, GraphX для обработки графиков и потоковую передачу.
Интернет вещей
Интернет вещей (IoT) – это растущий источник больших данных. IoT – это концепция, позволяющая осуществлять интернет-коммуникацию между физическими объектами, датчиками и контроллерами.
Машинное Обучение
Машинное обучение может быть использовано для прогностического анализа и распознавания образов в больших данных. Машинное обучение является междисциплинарным по своей природе и использует методы из области компьютерных наук, статистики и искусственного интеллекта. Основными артефактами исследования машинного обучения являются алгоритмы, которые облегчают автоматическое улучшение на основе опыта и могут быть применены в таких разнообразных областях, как компьютерное зрение и интеллектуальный анализ данных.
Интеллектуальный Анализ Данных
Интеллектуальный анализ данных – это применение специфических алгоритмов для извлечения паттернов из данных. В интеллектуальном анализе акцент делается на применении алгоритмов в ходе которых машинное обучение используются в качестве инструмента для извлечения потенциально ценных паттернов, содержащихся в наборах данных.
Где применяются большие данные
Аналитика больших данных применяется в самых разных областях. Перечислим некоторые из них:
- Поставщикам медицинских услуг аналитика больших данных нужна для отслеживания и оптимизации потока пациентов, отслеживания использования оборудования и лекарств, организации информации о пациентах и т. д.
- Туристические компании применяют методы анализа больших данных для оптимизации опыта покупок по различным каналам. Они также изучают потребительские предпочтения и желания, находят корреляцию между текущими продажами и последующим просмотром, что позволяет оптимизировать конверсии.
- Игровая индустрия использует BigData, чтобы получить информацию о таких вещах, как симпатии, антипатии, отношения пользователей и т. д.
Если вы хотите освоить новую профессию или повысить квалификацию в сфере Big Data, стоит обратить внимание на курс факультета аналитики Big Data онлайн-университета GeekBrains . Программа включает основательную математическую подготовку, изучение языка Python и получение навыков практической работы с базами данных. Также изучаются Hadoop и Apache Spark – востребованные инструменты для работы с большими данными. Курс ориентирован на применение машинного обучения в бизнесе и построен по принципам практической работы над проектами с ведущими специалистами отрасли и личным помощником-куратором.

Экскурс в историю и статистику
Из статистических выкладок аналитических агентств в 2005 году мир оперировал 4-5 эксабайтами информации (4-5 миллиардов гигабайтов), через 5 лет объемы big data выросли до 0,19 зеттабайт (1 ЗБ = 1024 ЭБ). В 2012 году показатели возросли до 1,8 ЗБ, а в 2015 – до 7 ЗБ. Эксперты прогнозируют, что к 2020 году системы больших данных будут оперировать 42-45 зеттабайтов информации.
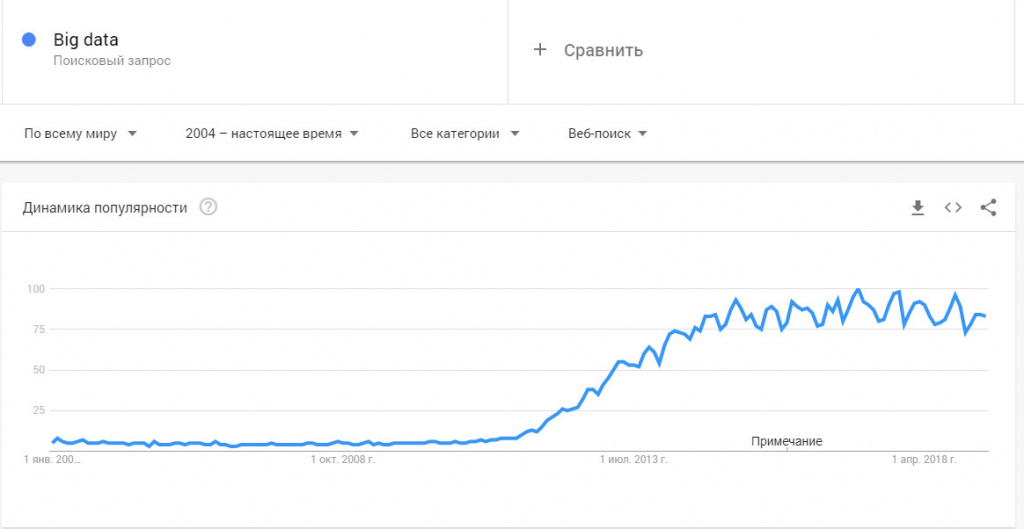
До 2011 года технологии больших данных рассматривались только в качестве научного анализа и практического выхода ни имели. Однако объемы данных росли по экспоненте и проблема огромных массивов неструктурированной и неоднородной информации стала актуальной уже в начале 2012 году. Всплеск интереса к big data хорошо виден в Google Trends.
К развитию нового направления подключились мастодонты цифрового бизнеса – Microsoft, IBM, Oracle, EMC и другие. С 2014 года большие данные изучают в университетах, внедряют в прикладные науки – инженерию, физику, социологию.
Как работает технология big data?

В современных системах рассматриваются два дополнительных фактора:

Современные аналитические агентства запускают миллионы подобных симуляций, когда тестируют идею, предположение или решают проблему. Процесс автоматизирован.
К источникам big data относят:
- интернет – блоги, соцсети, сайты, СМИ и различные форумы;
- корпоративную информацию – архивы, транзакции, базы данных;
- показания считывающих устройств – метеорологические приборы, датчики сотовой связи и другие.
Принципы работы с массивами данных включают три основных фактора:
- Расширяемость системы. Под ней понимают обычно горизонтальную масштабируемость носителей информации. То есть выросли объемы входящих данных – увеличились мощность и количество серверов для их хранения.
- Устойчивость к отказу. Повышать количество цифровых носителей, интеллектуальных машин соразмерно объемам данных можно до бесконечности. Но это не означает, что часть машин не будет выходить из строя, устаревать. Поэтому одним из факторов стабильной работы с большими данными является отказоустойчивость серверов.
- Локализация. Отдельные массивы информации хранятся и обрабатываются в пределах одного выделенного сервера, чтобы экономить время, ресурсы, расходы на передачу данных.
Для чего используют?
Чем больше мы знаем о конкретном предмете или явлении, тем точнее постигаем суть и можем прогнозировать будущее. Снимая и обрабатывая потоки данных с датчиков, интернета, транзакционных операций, компании могут довольно точно предсказать спрос на продукцию, а службы чрезвычайных ситуаций предотвратить техногенные катастрофы. Приведем несколько примеров вне сферы бизнеса и маркетинга, как используются технологии больших данных:
- Здравоохранение. Больше знаний о болезнях, больше вариантов лечения, больше информации о лекарственных препаратах – всё это позволяет бороться с такими болезнями, которые 40-50 лет назад считались неизлечимыми.
- Предупреждение природных и техногенных катастроф. Максимально точный прогноз в этой сфере спасает тысячи жизней людей. Задача интеллектуальных машин собрать и обработать множество показаний датчиков и на их основе помочь людям определить дату и место возможного катаклизма.
- Правоохранительные органы. Большие данные используются для прогнозирования всплеска криминала в разных странах и принятия сдерживающих мер, там, где этого требует ситуация.
Методики анализа и обработки

К основным способам анализа больших массивов информации относят следующие:
Большие данные в бизнесе и маркетинге
Например, аукцион RTB в контекстной рекламе работают с big data, что позволяет эффективно рекламировать коммерческие предложения выделенной целевой аудитории, а не всем подряд.
Какие выгоды для бизнеса:
- Создание проектов, которые с высокой вероятностью станут востребованными у пользователей, покупателей.
- Изучение и анализ требований клиентов с существующим сервисом компании. На основе выкладки корректируется работа обслуживающего персонала.
- Выявление лояльности и неудовлетворенности клиентской базы за счет анализа разнообразной информации из блогов, соцсетей и других источников.
- Привлечение и удержание целевой аудитории благодаря аналитической работе с большими массивами информации.
Технологии используют в прогнозировании популярности продуктов, например, с помощью сервиса Google Trends и Яндекс. Вордстат (для России и СНГ).

Методики big data используют все крупные компании – IBM, Google, Facebook и финансовые корпорации – VISA, Master Card, а также министерства разных стран мира. Например, в Германии сократили выдачу пособий по безработице, высчитав, что часть граждан получают их без оснований. Так удалось вернуть в бюджет около 15 млрд. евро.
Недавний скандал с Facebook из-за утечки данных пользователей говорит о том, что объемы неструктурированной информации растут и даже мастодонты цифровой эры не всегда могут обеспечить их полную конфиденциальность.

Например, Master Card используют большие данные для предотвращения мошеннических операций со счетами клиентов. Так удается ежегодно спасти от кражи более 3 млрд. долларов США.
В игровой сфере big data позволяет проанализировать поведение игроков, выявить предпочтения активной аудитории и на основе этого прогнозировать уровень интереса к игре.

Сегодня бизнес знает о своих клиентах больше, чем мы сами знаем о себе – поэтому рекламные кампании Coca-Cola и других корпораций имеют оглушительный успех.
Перспективы развития
В 2019 году важность понимания и главное работы с массивами информации возросла в 4-5 раз по сравнению с началом десятилетия. С массовостью пришла интеграция big data в сферы малого и среднего бизнеса, стартапы:
- Облачные хранилища. Технологии хранения и работы с данными в онлайн-пространстве позволяет решить массу проблем малого и среднего бизнеса: дешевле купить облако, чем содержать дата-центр, персонал может работать удаленно, не нужен офис.
- Глубокое обучение, искусственный интеллект. Аналитические машины имитируют человеческий мозг, то есть используются искусственные нейронные сети. Обучение происходит самостоятельно на основе больших массивов информации.
- Dark Data – сбор и хранение не оцифрованных данных о компании, которые не имеют значимой роли для развития бизнеса, однако они нужны в техническом и законодательном планах.
- Блокчейн. Упрощение интернет-транзакций, снижение затрат на проведение этих операций.
- Системы самообслуживания – с 2016 года внедряются специальные платформы для малого и среднего бизнеса, где можно самостоятельно хранить и систематизировать данные.
Резюме
Мы изучили, что такое big data? Рассмотрели, как работает эта технология, для чего используются массивы информации. Познакомились с принципами и методиками работы с большими данными.

Сегодня расскажем , что такое Big Data (биг дата) , простыми словами, чтобы стало ясно раз и навсегда.
Big Data — это область IT-сферы, которая изучает, анализирует, обрабатывает и взаимодействует с большими объемами данных. Биг дата — это все инструменты, подходы, методы обработки всех известных типов больших данных.
Специалисты биг дата чаще всего работают с неструктурированными данными, обработка которых дает структурированные данные в табличном представлении, используемые далее по назначению.
Что это такое — Big Data (биг дата) , простыми словами
- когда среднесуточный объем данных переваливает за 100 Гб;
- когда поступаемый объем данных становится проблемным;
- когда с данными не справляется один компьютер;
- когда с данными не справляется один человек;
- когда данные невозможно обрабатывать в Excel из-за их объема;
- абсолютно любой размер данных;
- когда для данных нужно использовать больше одного инструмента;
- и др.
Классификация биг дата
- Структурированные биг дата, которые имеют четкую связь между собой и чаще всего представлены в виде таблиц.
- Слабоструктурированные биг дата не имеют табличного представления или четких взаимоотношений, но имеют определенные общие индикаторы для придания им слабой организованности.
- Неструктурированные Big Data вообще не имеют никаких общих взаимосвязей и представлены в неорганизованном порядке.
Как характеризуются биг дата
Основные термины, окружающие биг дата
- Облачные вычисления. Все мы з н аем , что такое облако. Так вот, данный термин подразумевает работу с биг дата в облаке , ч то в первую очередь облегчает доступ к обрабатываемым данным.
- Прогнозная аналитика. Это технология обрабатывания биг дата, при которой вырабатывается модель для реализации прогнозов каких-то событий.
- Описательная аналитика. Данный термин подразумевает технологию обрабатывания данных, при которой меньше всего внимания уделяется уточненным деталям и идет концентрация на общие свойства данных.
- База данных. Все данные должны где-то размещаться, чтобы с ними можно было взаимодействовать. База данных — это место сохранения данных.
- Хранилище данных. Из отзывов реальных людей можно увидеть оценить уровень обслуживания в определенном игровом казино Вулкан в Казахстане . Такие комментарии о казино дают необходимую информацию о качестве сервиса, честности правил или скорости выплат выигрышей. Эти отклики настоящих игроков помогут новым пользователям выбрать надежный и хороший игорный зал для азартных развлечений. Это структура хранения информации, при которой у руководителя компании есть возможность наблюдать и использовать эти данные самостоятельно в собственных целях.
- Бизнес-аналитика. Это набор различного инструментария, который используется для определения, аналитики и прогноза бизнес-деятельности.
- Apache Hadoop. Это фреймворк, который применяется для обработки биг дата.
- Apache Spark . Это целый движок для работы с биг дата, к которому можно подключить API-интерфейсы для взаимодействия с популярными языками программирования, применяющимися для работы с Big Data: Java, Scala, R, Python и др.
- Интернет вещей. Это технология , при которой осуществляется коммуникация между физическими устройствами: станками, датчиками, видеокамерами, индикаторами и т. д.
- Машинное обучение. Это технология обучения компьютеров, при которой активно использу ю тся биг дата.
- Интеллектуальный анализ данных. Это анализ биг дата, который осуществляется по каким-то заданным критериям для выборки определенной информации.
Заключение
Невзирая на размеры, биг дата — это всегда работа с большим объемом данных. Big Data — это способность использовать большие объемы данных для благих целей. Работа с биг дата имеет очень важное значение в современном мире, поэтому она задействована во многих сферах человеческой деятельности.
Специалисты по биг дата всегда были и будут востребованы хотя бы потому , что объемы данных растут в геометрической прогрессии изо дня в день.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Читайте также: