
Алгоритм рабочий набор кратко
Обновлено: 04.07.2024
Рабочий набор это концепция в Информатика который определяет объем памяти, который процесс требуется в заданный промежуток времени.
Содержание
Определение
Обоснование
Влияние выбора того, какие страницы хранить в основной памяти (в отличие от выгружен во вспомогательную память) важен: если в основной памяти хранится слишком много страниц процесса, то одновременно может быть готово меньше других процессов. Если в основной памяти хранится слишком мало страниц процесса, его ошибка страницы частота значительно увеличивается, и количество активных (не приостановленных) процессов, выполняемых в настоящее время в системе, приближается к нулю.
Часто сильно загружен компьютер поставил в очередь столько процессов, что, если бы всем процессам было разрешено запускаться для одного планирование отрезок времени, они будут ссылаться на большее количество страниц, чем имеется ОЗУ, в результате чего компьютер "трэш".
При замене некоторых процессов из памяти в результате процессы - даже процессы, которые были временно удалены из памяти - завершаются гораздо раньше, чем если бы компьютер попытался запустить их все сразу. Процессы также завершаются намного раньше, чем если бы компьютер выполнял только один процесс за раз до завершения, поскольку это позволяет другим процессам запускаться и прогрессировать в то время, когда один процесс ожидает на жестком диске или каком-либо другом глобальном ресурсе.
Другими словами, стратегия рабочего набора предотвращает взбучка при сохранении максимально возможной степени мультипрограммирования. Таким образом оптимизируется загрузка ЦП и пропускная способность.
Выполнение
Чтобы избежать накладных расходов на ведение списка последних k ссылочные страницы, рабочий набор часто реализуется путем отслеживания времени т последней ссылки и учитывая, что рабочий набор - это все страницы, на которые есть ссылки в течение определенного периода времени.
Рабочий набор не является алгоритм замены страницы, но алгоритмы замены страниц могут быть разработаны так, чтобы удалять только те страницы, которых нет в рабочем наборе для определенного процесса. Одним из примеров является модифицированная версия алгоритм часов называется WSClock.
Варианты
Рабочий набор можно разделить на код рабочий набор и данные рабочий набор. Это различие важно, когда код и данные разделены на соответствующем уровне иерархии памяти, как если бы либо рабочий набор не помещается на этом уровне иерархии, произойдет перебивка. Помимо кода и самих данных, в системах с виртуальная память, то карта памяти (из виртуальной памяти в физическую) записи страниц рабочего набора должны кэшироваться в резервный буфер перевода (TLB) для эффективного продвижения процесса. Это различие существует потому, что код и данные кэшируются небольшими блоками (строки кеша), а не целые страницы, но поиск адресов выполняется на уровне страницы. Таким образом, даже если рабочие наборы кода и данных помещаются в кэш, если рабочие наборы разделены по многим страницам, рабочий набор виртуальных адресов может не поместиться в TLB, вызывая перегрузку TLB.
Аналоги рабочего набора существуют и для других ограниченных ресурсов, в первую очередь процессы. Если набор процессов требует частого взаимодействия между несколькими процессами, тогда он имеет рабочий набор процесса это должно быть запланированный чтобы прогрессировать: [2]
параллельные программы имеют рабочий набор процесса это должно быть запланированный (запланировано для одновременного выполнения) для выполнения параллельной программы.
Если процессы не планируются одновременно - например, если есть два процесса, но только одно ядро, на котором они выполняются, - тогда процессы могут продвигаться только со скоростью одно взаимодействие за временной интервал.
При использовании замещения страниц в простейшей форме процессы начинают свою работу, не имея в памяти вообще никаких страниц. Как только центральный процессор пытается извлечь первую команду, он получает ошибку отсутствия страницы, заставляющую операционную систему ввести в память страницу, содержащую первую команду Обычно вскоре за этим следуют ошибки отсутствия страниц с глобальными переменными и стеком. Через некоторое время процесс располагает большинством необходимых ему страниц и приступает к работе, сталкиваясь с ошибками отсутствия страниц относительно редко. Эта стратегия называется замещением страниц по требованию (demand paging) поскольку страницы загружаются только по мере надобности, а не заранее.
Разумеется, нетрудно написать тестовую программу, систематически читающую все страницы в огромном адресном пространстве, вызывая при этом такое количество ошибок отсутствия страниц, что для их обработки не хватит памяти. К счастью, большинство процессов так не работают. Ими применяется локальность обращений, означающая, что в течение любой фазы выполнения процесс обращается только к относительно небольшой части своих страниц. К примеру, при каждом проходе многопроходного компилятора обращение идет только к части имеющихся страниц, причем всякий раз к другой части.
Набор страниц, использующихся процессом в данный момент, известен как рабочий набор (Denning, 1968а; Denning, 1980). Если в памяти находится весь рабочий набор, процесс будет работать, не вызывая многочисленных ошибок отсутствия страниц, пока не перейдет к другой фазе выполнения (например, к следующему проходу компилятора). Если объем доступной памяти слишком мал для размещения всего рабочего набора, процесс вызовет множество ошибок отсутствия страниц и будет работать медленно, поскольку выполнение команды занимает всего несколько наносекунд, а считывание страницы с диска обычно занимает 10 мс. Если он будет выполнять одну или две команды за 10 мс, то завершение его работы займет целую вечность. Про программу, вызывающую ошибку отсутствия страницы через каждые несколько команд, говорят, что она пробуксовывает (Denning, 19686).
В многозадачных системах процессы довольно часто сбрасываются на диск (то есть все их страницы удаляются из памяти), чтобы дать возможность другим процессам воспользоваться своей очередью доступа к центральному процессору. Возникает вопрос, что делать, когда процесс возобновляет свою работу. С технической точки зрения ничего делать не нужно. Процесс просто будет вызывать ошибки отсутствия страниц до тех пор, пока не будет загружен его рабочий набор. Проблема в том, что наличие 20, 100 или даже 1000 ошибок отсутствия страниц при каждой загрузке процесса замедляет работу, а также вызывает пустую трату значительной части рабочего времени центрального процессора, поскольку на обработку операционной системой одной ошибки отсутствия страницы затрачивается несколько миллисекунд процессорного времени.
Поэтому многие системы замещения страниц пытаются отслеживать рабочий набор каждого процесса и обеспечивать его присутствие в памяти, перед тем как позволить процессу возобновить работу. Такой подход называется моделью рабочего набора (Denning, 1970). Он был разработан для существенного сокращения количества ошибок отсутствия страниц. Загрузка страниц до того, как процессу будет позволено возобновить работу, называется также опережающей подкачкой страниц (prepaging). Следует заметить, что со временем рабочий набор изменяется.
Давно подмечено, что большинство программ неравномерно обращается к своему адресному пространству, их обращения склонны группироваться на небольшом количестве страниц. Обращение к памяти может быть извлечением команды, извлечением данных или сохранением данных. В любой момент времени t существует некий набор, состоящий из всех страниц, используемый в k самых последних обращений к памяти. Этот набор, w(k> t), и является рабочим набором. Так как все недавние обращения к памяти для k > 1 обязательно должны были обращаться ко всем страницам, использовавшимся для k = 1 обращения к памяти, то есть к последней и, возможно, еще к некоторым страницам, w(k> t) является монотонно неубывающей функцией от k. По мере роста значения k значение функции w(k, t) достигает своего предела, поскольку программа не может обращаться к количеству страниц, превышающему по объему имеющееся адресное пространство, а каждая отдельно взятая страница будет использоваться лишь немногими программами. На рис. 3.18 показано, что размер рабочего набора является функцией от k.

Тот факт, что большинство программ произвольно обращается к небольшому количеству страниц, но со временем этот набор медленно изменяется, объясняет начальный быстрый взлет кривой графика, а затем, при больших значениях &, замедление этого взлета. К примеру, программа, выполняющая цикл, при этом занимающая две страницы и использующая данные, расположенные на четырех страницах, может обращаться ко всем шести страницам каждые 1000 команд, но самые последние обращения к некоторым другим страницам могут состояться за миллион команд до этого, в процессе фазы инициализации. Благодаря такому асимптотическому поведению содержимое рабочего набора нечувствительно к выбранному значению k.
Иначе говоря, существует широкий диапазон значений &, для которого рабочий набор остается неизменным. Поскольку со временем рабочий набор изменяется медленно, появляется возможность выстроить разумные предположения о том, какие страницы понадобятся при возобновлении работы программы, основываясь на том, каков был ее рабочий набор при последней приостановке ее работы. Опережающая подкачка страниц как раз и заключается в загрузке этих страниц перед возобновлением процесса.
Для реализации модели рабочего набора необходимо, чтобы операционная система отслеживала, какие именно страницы входят в рабочий набор. При наличии такой информации тут же напрашивается и возможный алгоритм замещения страниц: при возникновении ошибки отсутствия страницы нужно выселить ту страницу, которая не относится к рабочему набору. Для реализации подобного алгоритма нам необходим четкий способ определения, какие именно страницы относятся к рабочему набору По определению рабочий набор — это набор страниц, используемых в k самых последних обращений (некоторые авторы используют термин k самых последних страничных обращений, но это дело вкуса). Для реализации любого алгоритма рабочего набора некоторые значения k должны быть выбраны заранее. Как только после каждого обращения к памяти будет выбрано некоторое значение, однозначно определяется и набор страниц, используемый при самых последних k обращениях к памяти.
Разумеется, имеющееся определение рабочего набора не означает наличия эффективного способа его вычисления в процессе выполнения программы. Можно представить себе регистр со сдвигом, имеющий длину k, в котором при каждом обращении к памяти его содержимое сдвигается влево на одну позицию и справа вставляется номер страницы, к которой было самое последнее обращение. Набор из всех k номеров страниц в регистре со сдвигом и будет представлять собой рабочий набор. Теоретически при возникновении ошибки отсутствия страницы содержимое регистра со сдвигом может быть считано и отсортировано. Затем могут быть удалены продублированные страницы. В результате должен получиться рабочий набор. Но обслуживание регистра со сдвигом и обработка его содержимого при возникновении ошибки отсутствия страницы окажется недопустимо затратным делом, поэтому эта технология никогда не используется.
Вместо нее используются различные приближения. Одно из часто используемых приближений сводится к отказу от идеи вычисления k обращений к памяти и использованию вместо этого времени выполнения. Например, вместо определения рабочего набора в качестве страниц, использовавшихся в течение предыдущих 10 миллионов обращений к памяти, мы можем определить его как набор страниц, используемых в течение последних 100 мс времени выполнения. На практике с таким определением работать гораздо лучше и проще. Следует заметить, что для каждого процесса вычисляется только его собственное время выполнения. Таким образом, если процесс запускается во время Т и получает 40 мс времени центрального процессора за время T + 100 мс, то для определения рабочего набора берется время 40 мс. Интервал времени центрального процессора, реально занимаемый процессом с момента его запуска, часто называют текущим виртуальным временем. При этом приближении рабочим набором процесса является набор страниц, к которым он обращался в течение последних х секунд виртуального времени.
Теперь взглянем на алгоритм замещения страниц, основанный на рабочем наборе. Основной замысел состоит в том, чтобы найти страницу, не принадлежащую рабочему набору, и удалить ее из памяти. На рис. 3.19 показана часть таблицы страниц, используемой в некой машине. Поскольку кандидатами на выселение рассматриваются только страницы, находящиеся в памяти, страницы, в ней отсутствующие, этим алгоритмом игнорируются. Каждая запись состоит (как минимум) из двух ключевых элементов информации: времени (приблизительного) последнего использования страницы и бита R (Referenced — бита обращения). Пустыми белыми прямоугольниками обозначены другие поля, не нужные для этого алгоритма, например номер страничного блока, биты защиты и бит изменения — М (Modified).
Рассмотрим работу алгоритма. Предполагается, что аппаратура, как это было рассмотрено ранее, устанавливает биты R и М. Также предполагается, что периодические прерывания от таймера запускают программу, очищающую бит обращения R. При каждой ошибке отсутствия страницы происходит сканирование таблицы страниц с целью найти страницу, пригодную для удаления.
При каждой обработке записи проверяется состояние бита R. Если его значение равно 1, текущее виртуальное время записывается в поле времени последнего использования таблицы страниц, показывая, что страница была использована при возникновении ошибки отсутствия страницы. Если обращение к странице происходит в течение текущего такта времени, становится понятным, что она принадлежит рабочему набору и не является кандидатом на удаление (предполагается, что τ охватывает несколько системных тактов).

Если значение R равно 0, значит, за текущий такт времени обращений к странице не было и она может быть кандидатом на удаление. Чтобы понять, должна ли она быть удалена или нет, вычисляется ее возраст (текущее виртуальное время за вычетом ее времени последнего использования), который сравнивается со значением τ. Если возраст превышает значение τ, то страница уже не относится к рабочему набору и заменяется новой страницей. Сканирование продолжается, и происходит обновление всех остальных записей.
Идеальный алгоритм заключается в том, что бы выгружать ту страницу, которая будет запрошена позже всех.
Но этот алгоритм не осуществим, т.к. нельзя знать какую страницу, когда запросят. Можно лишь набрать статистику использования.
7.1.1 Алгоритм NRU (Not Recently Used - не использовавшаяся в последнее время страница)
Используются биты обращения (R-Referenced) и изменения (M-Modified) в таблице страниц.
При обращении бит R выставляется в 1, через некоторое время ОС не переведет его в 0.
M переводится в 0, только после записи на диск.
Благодаря этим битам можно получить 4-ре класса страниц:
не было обращений и изменений (R=0, M=0)
не было обращений, было изменение (R=0, M=1)
было обращение, не было изменений (R=1, M=0)
было обращений и изменений (R=1, M=1)
7.1.2 Алгоритм FIFO (первая прибыла - первая выгружена)
Недостаток заключается в том, что наиболее часто запрашиваемая страница может быть выгружена.
7.1.3 Алгоритм "вторая попытка"
Подобен FIFO, но если R=1, то страница переводится в конец очереди, если R=0, то страница выгружается.
Алгоритм "вторая попытка"
В таком алгоритме часто используемая страница никогда не покинет память.
Но в этом алгоритме приходится часто перемещать страницы по списку.
7.1.4 Алгоритм "часы"
Чтобы избежать перемещения страниц по списку, можно использовать указатель, который перемещается по списку.
7.1.5 Алгоритм LRU (Least Recently Used - использовавшаяся реже всего)
Чтобы реализовать этот алгоритм, можно поддерживать список, в котором выстраивать страницы по количеству использования. Эта реализация очень дорога.
В таблице страниц добавляется запись - счетчик обращений к странице. Чем меньше значение счетчика, тем реже она использовалась.
7.1.6 Алгоритм "рабочий набор"
Замещение страниц по запросу - когда страницы загружаются по требованию, а не заранее, т.е. процесс прерывается и ждет загрузки страницы.
Буксование - когда каждую следующую страницу приходится процессу загружать в память.
Чтобы не происходило частых прерываний, желательно чтобы часто запрашиваемые страницы загружались заранее, а остальные подгружались по необходимости.
Рабочий набор - множество страниц (к), которое процесс использовал до момента времени (t). Т.е. можно записать функцию w(k,t).
Зависимость рабочего набора w(k,t) от количества запрошенных страниц
Т.е. рабочий набор выходит в насыщение, значение w(k,t) в режиме насыщения может служить для рабочего набора, который необходимо загружать до запуска процесса.
Алгоритм заключается в том, чтобы определить рабочий набор, найти и выгрузить страницу, которая не входит в рабочий набор.
Этот алгоритм можно реализовать, записывая, при каждом обращении к памяти, номер страницы в специальный сдвигающийся регистр, затем удалялись бы дублирующие страницы. Но это дорого.
В принципе можно использовать множество страниц, к которым обращался процесс за последние t секунд.
Текущее виртуальное время (Tv) - время работы процессора, которое реально использовал процесс.
Время последнего использования (Told) - текущее время при R=1, т.е. все страницы проверяются на R=1, и если да то текущее время записывается в это поле.
Теперь можно вычислить возраст страницы (не обновления) Tv-Told, и сравнить с t, если больше, то страница не входит в рабочий набор, и страницу можно выгружать.
Получается три варианта:
если R=1, то текущее время запоминается в поле время последнего использования
если R=0 и возраст > t, то страница удаляется
если R=0 и возраст = 7.1.7 Алгоритм WSClock
Алгоритм основан на алгоритме "часы", но использует рабочий набор.
Используются битов R и M, а также время последнего использования.
Работа алгоритма WSClock
Это достаточно реальный алгоритм, который используется на практике.
7.2 Распределение памяти
7.2.1 Политика распределения памяти
Алгоритмы замещения бывают:
Пример глобального и локального алгоритма
В целом глобальный алгоритм работает лучше.
Можно поровну распределять страничные блоки между процессами.
Такой подход справедлив, но не эффективен, т.к. процессы разные.
Можно распределять страничные блоки между процессами, в зависимости от размеров процесса
Размер процесса динамически меняется, поэтому определить размер динамически сложно.
Частота страничных прерываний - может служить показателем потребности процесса в страницах.
Чем больше частота, тем больше памяти необходимо процессу.
Зависимость частоты страничных прерываний от размеров памяти предоставленной процессу
Если частота стала ниже линии В, то памяти процессу предоставлено слишком много.
Если частота стала выше линии А, то памяти процессу предоставлено слишком мало.
Если всем процессам не хватает памяти (происходит пробуксовка), то производится выгрузка какого то процесса на диск.
7.2.2 Размеры страниц
Есть два крайних случая:
Маленькие страницы - улучшает распределение памяти, но увеличивает таблицу и частые переключения уменьшают производительность.
Большие страницы - наоборот.
7.2.3 Совместно используемые страницы
Отдельные пространства команд и данных
Пример разделения пространства команд и данных
Совместно используемые страницы
Два процесса могут содержать в таблицах страниц указатели на общие страницы. В случае разделения пространств команд и данных это легко реализуется. Эти данные используются в режиме чтения.
В UNIX, когда создается дочерний процесс, у родительского и дочернего процесса общее пространство данных, и только если один из процессов попытается изменить данные, происходит прерывание и создание копии этой страницы, если записи не происходит, то оба процесса продолжают работать с общей памятью. Это приводит к экономии памяти.
7.2.4 Политика очистки страниц
Лучше всегда держать в запасе свободные блоки, освобождая их заранее, чем при нехватке памяти, искать и освобождать их.
Страничный демон - программа, периодически проверяющая состояние памяти, если занято много блоков, то производит выборочную выгрузку страниц.
7.3 Особенности реализации в UNIX
В UNIX системах последовательность запуска процессов, следующая:
процесс 0 - это свопер
процесс 1 - это init
процесс 2 - это страничный демон
Страничный демон просыпается каждые 250мс, и проверяет количество свободных страничных блоков, если их меньше 1/4 памяти, то он начинает выгружать страницы на диск. Он использует модифицированный алгоритм часов, и он является глобальным (т.е. он не различает, какому процессу принадлежит страница).
Каждые несколько секунд свопер проверяет, есть ли на диске готовые процессы для загрузки в память для выполнения. При этом сам код программы в своп-файле не сохраняется, а подкачивается непосредственно из файла программы.
В LUNIX системе нет предварительной загрузки страниц и концепции рабочего набора.
Тексты программ и отображаемые файлы подгружаются прямо из файлов расположенных на диске.
Все остальное выгружается в раздел свопинга или файлы свопинга (их может быть от 0 до 8).
Алгоритм выгрузки страниц основан на страничном демоне (kswapd), он активизируется раз в секунда и проверяет достаточно ли свободных страниц. Демон может быть активизирован и принудительно, при не хватке памяти.
Демон состоит из трех процедур:
В первой используется алгоритм часов, она ищет редко используемые страницы страничного кэша и буферного кэша файловой системы.
Вторая процедура ищет совместно редко используемые страницы.
Третья ищет редко используемые страницы одиночных пользователей. Сначала сканируются страницы у того процесса, у которого их больше всего.
В LINUX есть еще один демон - bdflush. Он регулярно просыпается и проверяет, не превысило ли определенное значение количество измененных страниц, если да то он начинает их принудительно сохранять на диск.
7.4 Особенности реализации в Windows
В Windows системах сегментация (следующая лекция) не поддерживается. Поэтому каждому процессу выделяется виртуальное адресное пространство в 4 Гбайт (ограничение 32 разрядов). Нижние 2 Гбайт доступны для процесса, а верхние 2 Гбайт отображаются на память ядра. В Advanced server и Datacenter server процесс может использовать до 3 Гбайт.
Конфигурация виртуального адресного пространства Windows
Белым цветом выделены области приватных данных процесса.
Затемнены области, совместно используемые всеми процессами.
Области в 64 Кбайт в начале и в конце, используются для защиты виртуального адресного пространства процесса, при попытке чтения или записи в эти области будет вызвано прерывание.
Системные данные содержат указатели и таймеры, доступные на чтение другим процессам.
Отображение верхней части на память ядра, позволяет при переключении потока в режим ядра не менять карту памяти.
У страниц есть три состояния:
свободное - не используется
фиксированное - данные отображены в странице
зарезервированное - зарезервировано, но не занято данными (при создании потока)
Файлы свопинга может быть до 16, разделов свопинга нет. В файлах свопинга хранятся только изменяемые страницы.
Опережающая подкачка в Windows не используется.
В Windows используется понятие рабочий набор.
Страничный демон в Windows состоит из :
менеджера балансового множества - проверяет, достаточно ли свободных страниц.
менеджера рабочих наборов - который исследует рабочие наборы и освобождает страницы.
Рабочий набор- множество страниц (к), которое процесс использовал до момента времени (t). Т.е. можно записать функцию w(k,t).
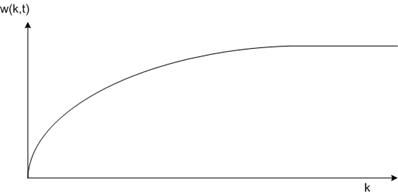
Рисунок 15. Зависимость рабочего набора w(k,t) от количества запрошенных страниц
Т.е. рабочий набор выходит в насыщение, значение w(k,t) в режиме насыщения может служить для рабочего набора, который необходимо загружать до запуска процесса.
Алгоритм заключается в том, чтобы определить рабочий набор, найти и выгрузить страницу, которая не входит в рабочий набор. Этот алгоритм можно реализовать, записывая, при каждом обращении к памяти, номер страницы в специальный сдвигающийся регистр, затем удалялись бы дублирующие страницы. Но это дорого. В принципе можно использовать множество страниц, к которым обращался процесс за последние t секунд.
Текущее виртуальное время (Tv) - время работы процессора, которое реально использовал процесс.
Время последнего использования (Told)- текущее время при R=1, т.е. все страницы проверяются на R=1, и если да то текущее время записывается в это поле.
Теперь можно вычислить возраст страницы (не обновления) Tv-Told,и сравнить с t, если больше, то страница не входит в рабочий набор, и страницу можно выгружать.
Получается три варианта:
· если R=1, то текущее время запоминается в поле время последнего использования
Когда необходимо заменить страницу, генерируется случайный номер страницы, чтобы заменить физическую страницу, соответствующую этой странице.
Замените самую раннюю страницу в памяти.
Механизм реализации FIFO состоит в том, чтобы использовать связанный список для связывания всех страниц в памяти в соответствии со временем ввода, а затем каждый раз заменять страницу в заголовке связанного списка.
Алгоритм второго шанса
При использовании FIFO для замены страницы вам необходимо проверить, была ли страница недавно посещена.
Если он не посещался, замените страницу.
Если страница была посещена недавно (путем проверки значения ее бита доступа), вместо замены страницы, повесьте страницу в конце связанного списка и введите страницу Установите время памяти на текущее время и очистите его бит доступа.
эквивалентно предоставлению странице памяти второй шанс.
Алгоритм часов

В алгоритме часов мы размещаем страницы в форме часов.
У часов есть булавка. Каждый раз, когда необходимо изменить страницу, мы начинаем проверку со страницы, на которую указывает игольчатый рычаг. Если бит доступа текущей страницы равен 0, то есть страница не посещалась с момента последней проверки, эта страница заменяется. Если текущая страница была посещена, очистите ее бит доступа и переместите указатель по часовой стрелке на следующую страницу. Мы повторяем эти шаги, пока не найдем страницу с битом доступа 0.
Алгоритм часов похож на алгоритм второго шанса, но он не тот же:
1. Структура данных отличается, вторая возможность использует связанный список, а алгоритм часов использует индекс (целочисленный указатель).
2. Алгоритм второго шанса должен использовать дополнительную память, а алгоритм часов может напрямую использовать таблицу страниц. И бит доступа таблицы страниц будет автоматически очищаться периодически, что делает детализацию временного разрешения алгоритма синхронизации выше, чем алгоритм второго шанса.
Оптимальный алгоритм замены
В недобросовестном алгоритме наиболее идеальным алгоритмом замены страницы является выбор страницы, к которой никогда не будет доступа для замены, если такой страницы нет, то, по крайней мере, выберите страницу, которая не будет посещаться дольше всего. Замена - это оптимальный алгоритм замены.
Фактически, оптимальный алгоритм замены - это алгоритм, который фактически не будет реализован.
Целью существования является определение эталона для оценки плюсов и минусов других алгоритмов.
Алгоритм NRU
Не использованный недавно (NRU) - для выбора страницы, к которой недавно не обращались, для ее замены.Во всех недавно неиспользованных страницах она делится в соответствии с комбинацией битов модификации и битов доступа каждой страницы.
| Тип страницы | Статус доступа к битам | Изменить статус бита |
|---|---|---|
| 1 | Не были посещены | Не был изменен |
| 2 | Не были посещены | модифицированный |
| 3 | Посетил | Не был изменен |
| 4 | Посетил | модифицированный |
Примечание: возможны 2 обстоятельства, система будет периодически очищать бит доступа, но не может очищать бит модификации.
Алгоритм NRU заключается в поиске заменяемых страниц в порядке этих 4 типов страниц.
Сначала он просматривает страницу памяти для первого типа страницы, и если это так, он берет первый тип найденной страницы в качестве замены.
Если нет, найдите на второй странице;
Если вы этого еще не сделали, посмотрите на третьей странице;
По аналогии, если все страницы были посещены и изменены, из него можно заменить только одну страницу.
Следовательно, алгоритм NRU всегда заканчивается.
Алгоритм LRU
Есть много способов реализовать этот алгоритм:
Используйте счетчик для записи
Самый простой способ - добавить поле счетчика к записи записи таблицы страниц. При однократном доступе к странице значение этого счетчика увеличивается на 1. Таким образом, когда необходимо заменить страницу, необходимо только найти страницу с наименьшим значением в поле счетчика и заменить ее.
Недостатки:
- Количество используемых счетчиков равно количеству виртуальных страниц, а стоимость места огромна.
- При выборе страниц для замены необходимо сравнивать значения счетчиков всех страниц, и затраты времени также очень велики.
Используйте связанные списки для достижения
Еще один простой способ реализации алгоритма LRU - использовать связанный список для связи всех страниц: последние использованные страницы находятся в начале связанного списка, а последние использованные страницы находятся в конце связанного списка. Обновляйте связанный список каждый раз, когда к странице обращаются, чтобы она удерживала последнюю использованную страницу в заголовке связанного списка.
Недостатки:
- Каждый доступ к памяти для обновления связанного списка очень неэффективен, потому что это обновление должно учитывать отношения между различными страницами.
Использовать матричную реализацию
Матричный метод заключается в использовании матрицы для записи частоты и времени использования страницы. Матрица имеет n × n измерений, где n - количество страниц, которые в данный момент находятся в памяти соответствующей программы. В начале начальное значение каждой строки и столбца матрицы равно 0.
Каждый раз, когда к странице обращаются, например, при обращении к k-й виртуальной странице, мы выполняем следующие операции:
- Установите все значения в k-й строке на 1.
- Установите значение k-го столбца в 0.

Каждый раз, когда необходимо заменить страницу, выбирайте страницу с наименьшим значением строки в матрице для замены. Здесь значение строки относится к значению, когда все 0 и 1 в строке связаны как двоичное число.
Например, предположим, что программа имеет 4 виртуальные страницы, а именно 0, 1, 2 и 3. Порядок доступа к виртуальным страницам программы: 0, 1, 2, 3, 2, 1, 0, 3, 2, 3. Когда доступ к странице продолжается, состояние матрицы изменяется, как показано на рисунке:
После первого шага мы гарантируем, что соответствующее значение строки страницы является одним из самых больших. Вторая операция устанавливает столбец, соответствующий странице, в 0, что гарантирует, что значение строки, соответствующее странице, является единственным максимумом.
Поскольку при каждом доступе к странице для определенного столбца устанавливается значение 0, чем длиннее страница, к которой не было доступа, тем больше число столбцов в соответствующем элементе строки устанавливается равным 0. Чем больше, то есть меньшее значение соответствующей строки обеспечит ее правильность.
Преимущества:
- Многие теории матриц используются для быстрого определения, какая матрица имеет наименьшее значение строки.
- Стоимость использования матрицы для реализации алгоритма LRU ниже, чем при использовании поля подсчета, потому что количество строк и столбцов этой матрицы не обязательно должно быть числом виртуальных страниц, но фактическим количеством страниц в памяти, поэтому оно намного меньше.
- Но матрица все еще слишком велика, потому что общий бит памяти равен квадрату количества страниц.
- Кроме того, если мы ограничим самое последнее время последними 9 посещениями, то страница 0 должна быть заменена. Поскольку за последние 9 посещений страницу 0 посещали только один раз, а другие страницы посещали 2 или более раз. Однако, согласно матричному методу, страница 1 заменяется. Поскольку каждый доступ к странице, операция набора матрицы охватывает предыдущую информацию, поэтому метод матрицы не может отражать накопление долговременного доступа.
Используйте сдвиговый регистр
Если страницу необходимо заменить в это время, значение в регистре сдвига, соответствующее третьей странице, является наименьшим, поэтому страница 3 будет заменена.
Преимущества:
- Точность не так хороша, как матричный метод. В некоторых конкретных случаях выбранная страница может быть не самой последней использованной страницей.
- Это достигается с помощью сдвигового регистра, который является дорогостоящим и требует большого количества регистров.
Алгоритм рабочего набора

Поскольку невозможно точно определить, какая страница используется в последнее время, нет необходимости тратить эти усилия и поддерживать только небольшое количество информации, так что выбранная нами страница замены вряд ли будет той страницей, которая будет использоваться снова немедленно. Этот небольшой объем информации является информацией рабочего набора.
Концепция рабочего набора основана на пространственно-временной локализации доступа к программам. То есть в течение определенного периода времени страницы, к которым обращается программа, будут ограничены набором страниц. Например, последние k посещений произошли на определенных m страницах, тогда m является рабочим набором, когда параметр равен k. Мы используем w (k, t) для обозначения количества страниц, вовлеченных в k посещений в момент времени t. Очевидно, что с увеличением k значение w (k, t) также увеличивается, но после того, как k возрастает до определенного значения, значение w (k, t) будет расти очень медленно или даже близко к стагнации и сохраняться в течение некоторого периода времени. Стабильность времени.
Из этого видно, что если программа имеет такое же количество страниц в памяти, что и размер ее рабочего набора, или превышает рабочий набор, программа не будет прерываться ошибками страниц в течение определенного периода времени. Если количество страниц в памяти меньше рабочего набора, частота прерываний сбоя страниц увеличится, и может произойти даже дрожание памяти.
Алгоритм рабочего набора реализован следующим образом:
Добавьте элемент информации в каждую запись таблицы страниц, чтобы записывать время последнего посещения страницы. Это время не обязательно должно быть реальным, если это виртуальное время, которое регулярно увеличивается. В то же время мы устанавливаем значение времени T. Если последнее посещение страницы предшествует текущему времени минус T, оно рассматривается как вне рабочего набора, в противном случае оно рассматривается как внутри рабочего набора.
Таким образом, каждый раз, когда требуется заменить страницу, все записи страницы сканируются и выполняются следующие операции:

- Если бит доступа к странице равен 1, последний раз доступа к странице устанавливается на текущее время, и бит доступа очищается.
- Если бит доступа к странице равен 0, проверьте, предшествует ли текущее время текущему времени минус T. а) Если это так, страница будет заменена, и алгоритм завершится.
b) Если нет, запишите минимальное значение последнего времени доступа для всех отсканированных страниц. Отсканируйте следующую страницу и повторите шаги 1 и 2
Если после сканирования всех страниц не найдено ни одной страницы, страница с самым старым последним временем доступа среди всех страниц будет заменена. Это также является причиной записи текущего минимального значения на шаге b.
Преимущества: - Преимущество алгоритма рабочего набора в том, что он прост в реализации, вам нужно только добавить виртуальное поле времени к каждой записи в таблице страниц. Поэтому его стоимость невелика.
- Этот временной домен не нужно изменять каждый раз, когда происходит доступ, но когда необходимо заменить страницу, алгоритм замены страницы изменяет его, поэтому временные затраты невелики.
- Каждый раз, когда страница сканируется для замены, может потребоваться сканирование всей таблицы страниц. И мы знаем, что не все страницы находятся в памяти, поэтому большую часть времени в процессе сканирования будет бесполезным.
- Поскольку его структура данных является линейной, она каждый раз сканируется в одном и том же порядке, что делает ее несправедливой по отношению к некоторым страницам. Это похоже на отбор отличных учеников. Если все выступают одинаково хорошо, то кандидаты определяются в соответствии с порядком чисел учеников. Студенты с меньшим числом учеников всегда будут страдать
Рабочий набор тактового алгоритма
Алгоритм рабочего набора часов, то есть принцип использования алгоритма рабочего набора, но порядок сканирования страниц организован в виде часов.
Таким образом, каждый раз, когда требуется заменить страницу, сканирование начинается со страницы, на которую указывает указатель, тем самым достигая более корректного состояния. Кроме того, страницы, организованные по часам, являются только страницами в памяти, а страницы вне памяти не помещаются в круг часов, что повышает эффективность реализации.
Ввиду своих временных и пространственных преимуществ алгоритм работы рабочего набора принят большинством коммерческих операционных систем.
Читайте также: