
Статистические методы обработки экспериментальных данных кратко
Обновлено: 02.07.2024
7.2. Первичная статистическая обработка данных.
Все методы количественной обработки принято подразделять на первичные и вторичные.
В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями.
К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных.
Меры центральной тенденции – это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода.
Выборочное среднее (М) – это результат деления суммы всех значений (Х) на их количество (N).
Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной.
Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки.
Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение.
Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных.
Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
Где d = |Х – М |, М – среднее выборки, Х – конкретное значение, N – число значений.
Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану.
Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М) не через их абсолютные величины, а через их возведение в квадрат:

Где d = |Х – М|, М – среднее выборки, Х – конкретное значение, N – число значений.
Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:

Где d = |Х– М|, М – среднее выборки, Х– конкретное значение, N – число значений.
МД, D и ? применимы для интервальных и пропорционных данных. Для порядковых данных в качестве меры изменчивости обычно берут полуквартильное отклонение (Q), именуемое еще полуквартильным коэффициентом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале, то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Qv Вторые 25 % распределения – второй квартиль, а соответствующая точка на шкале – Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями:
При симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
В этом разделе приведены часто используемые термины, необходимые для понимания изложенного материала.
Числовые характеристики выборки – обобщенные показатели, позволяющие:
- дать количественную оценку эмпирическим распределениям;
- сравнивать выборки между собой.
Статистической гипотезой (гипотезой) называется утверждение относительно истинных значений параметров исследуемой генеральной совокупности.
Нулевая гипотеза (Но) – предположение о том, что между параметрами генеральных совокупностей разница равна нулю и различия между ними носят не систематический, а случайный характер.
Альтернативная гипотеза (Н1) – гипотеза, противоположная нулевой.
Уровень значимости — вероятность отклонения нулевой гипотезы, когда она верна или другими словами вероятность ошибки.
Критерий — метод проверки статистических гипотез.
Критерий хи-квадрат, критерий лямбда Колмогорова–Смирнова – критерии согласия, часто используемые для проверки гипотезы о нормальности распределения.
t – критерий Стьюдента – критерий, позволяющий оценить, насколько статистически существенно различаются средние арифметические двух выборок.
F – критерий Фишера – метод, позволяющий проверить гипотезу, что две независимые выборки получены из генеральных совокупностей X и Y с одинаковыми дисперсиями sx 2 и sY 2 .
Критерий Манна-Уитни — непарамтерический критерий проверки статистических гипотез. Применяется для независимых выборок.
Критерий Вилкоксона – непараметрический критерий проверки статистических гипотез. Применяется для связанных выборок.
Корреляционный анализ – метод статистической обработки результатов, сущность которого состоит в определении степени взаимосвязи между двумя случайными величинами X и Y.
Лекция 2. Числовые характеристики выборки
В своей статье, опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь “…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52.
После проведения эксперимента исследователь получает определенные результаты. Чтобы его результаты можно было сравнить с данными других исследователей, необходимо рассчитать числовые характеристики выборки. Наибольшее практическое значение имеют характеристики положения, рассеивания и асимметрии (табл.1).
Таблица 1 — Название и обозначение числовых характеристик выборки
Среднее арифметическое (М)
Размах вариации (R)
Коэффициент асимметрии (As)
Коэффициент эксцесса (Ex)
Стандартное отклонение (S)
Характеристики положения
Среднее арифметическое (М) – одна из основных характеристик выборки. Этот показатель характеризуется тем, что сумма отклонений от него выборочных значений (с учетом знака) равна нулю.
где: n – объем выборки, xi – варианты выборки.
Среднее арифметическое, вычисленное на основе выборочных данных, как правило, не совпадает с генеральным средним. Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности (m).
где: S — стандартное отклонение (см. далее).
В научных публикациях очень часто окончательный результат приводится в следующем виде: М±m. В качестве примера приведем фрагмент таблицы из публикации Г.Г.Лапшиной (табл. 2).
Таблица 2 — Антропометрический и функциональный статусы студенток, n= 83 (по: Г.Г.Лапшиной, 1989)
Медианой (Me) – называется такое значение признака, когда одна половина значений экспериментальных данных меньше ее, а вторая половина — больше.
Мода (Мо) – представляет собой значение признака, встречающееся в выборке наиболее часто.
Характеристики вариативности
Средние значения не дают полной информации о варьирующем признаке, поэтому наряду со средними значениями вычисляют характеристики вариации.-
Размах вариации (R) вычисляется как разность между максимальным и минимальным значением признака: R= Xmax-Xmin.
Информативность этого показателя невелика, так как распределения результатов могут иметь одинаковый размах варьирования, а их форма будет очень отличаться.
Дисперсия (S 2 ) – средний квадрат отклонений значений признака от среднего арифметического (4):
Наиболее часто в публикациях приводится не дисперсия, а стандартное отклонение (S). Этот показатель также называется среднеквадратическим отклонением или СКО (5):
Во многих публикациях этот показатель обозначается s , однако мы рекомендуем применять обозначения, используемые в книге В.С. Иванова (1990): S – выборочное стандартное отклонение, сигма – стандартное отклонение генеральной совокупности. В качестве примера приведем фрагмент таблицы из статьи Л.Н. Жданова (1996).
Таблица 3 — Зависимость возраста достижения лучшего результата и количество необходимого для этого времени от возраста начала спортивной специализации у конькобежцев, дистанция 500 м, 225 спортсменов (по: Л.Н.Жданову, 1996).
Возраст начала спортивной специализации, лет
Возраст лучшего результата
Количество лет с начала специализации
Коэффициент вариации (V%). Чтобы сопоставить вариативность признаков, измеренных в различных единицах, используется относительный показатель (6), которы йназывается коэффициентов вариации.
Коэффициент вариации используют для оценки однородности выборки. Если V
Характеристики асимметрии
Коэффициент асимметрии (As) характеризует “скошенность“ эмпирического распределения.
Коэффициент эксцесса (Ex) определяет характер эмпирического распределения: остро- или плосковершинный.
Лекция 3. Закон нормального распределения
Корректное использование критериев проверки статистических гипотез предполагает знание закона распределения. Так, например, использование t – критерия Стьюдента и F-критерия Фишера требует нормального распределения экспериментальных данных. К сожалению, многие исследователи это не учитывают.
Большинство экспериментальных распределений, полученных при исследованиях в области физической культуры и спорта может быть описано с помощью нормального распределения. График плотности вероятности нормального распределения имеет следующий вид (рис. 1).

Рис. 1 Распределение роста женщин
На рис. 1 представлено распределение роста женщин с параметрами: мю (генеральное среднее) – 170 см, s = 5 см.
Нормальное распределение обладает следующими свойствами:
1. Нормальная кривая имеет колокообразную форму, симметричную относительно x = мю.
2. Точки перегиба отстоят от мю на ± сигма .
3. Нормальное распределение полностью определяется двумя параметрами: мю и сигма.
4. Медиана и мода совпадают и равны мю.
5. В интервал мю ± сигма попадают 68 % всех результатов.
В интервал мю ± 2 сигмы попадают 95% всех результатов.
В интервал мю ± 3 сигмы попадают 99 % всех результатов.
Чтобы проверить, соответствует ли распределение нормальному закону, существует много методов. Можно использовать свойства нормального распределения (равенство среднего, моды и медианы). Однако более точные результаты дают критерии согласия. В зависимости от объема выборки (n) следует использовать различные критерии:
если объем выборки небольшой (n = 10) – критерий Шапиро – Уилки;
если объем выборки более 40 — критерий хи-квадрат и критерий Колмогорова-Смирнова;
Лекция 4. Проверка статистических гипотез
Рассчитав числовые характеристики выборки, экспериментатор получает возможность сравнивать свои результаты с данными других исследователей или сравнить результаты, показанные контрольной и экспериментальной группой. Иногда задача работы состоит в том, чтобы сравнить результат, показанный группой спортсменов до и после эксперимента. В этом случае, чтобы дать ответ, существуют ли достоверные различия в результатах, нужно проверить статистические гипотезы, использовав для этого специальные методы — критерии значимости. Таким образом, критерий значимости — это метод проверки статистической гипотезы.
При использовании критериев значимости выдвигается нулевая гипотеза (Ho) — предположение о том, что в параметрах генеральных совокупностей из которых получены данные, представленные в выборках, разница равна нулю и различия между ними носят не систематический, а случайный характер. Противоположная гипотеза называется альтернативной (Н1).
Для проверки статистических гипотез применяются параметрические и непараметрические критерии. Параметрические критерии включают в формулу расчета параметры распределения, в нашем случае нормального. поэтому первым условием использования параметрических критериев является нормальное распределение результатов исследования. Вторым условием применения параметрических критериев является статистическая шкала, в которой представлены данные. Такими шкалами являются интервальная шкала и шкала отношений (данные, представлены в этих шкалах измеряются в кг, м, с и т.д). Непараметрические критерии (или ранговые критерии) построены по другому принципу и не требуют нормального распределения экспериментальных результатов. Кроме того, эти критерии можно применять к данным, представленным в порядковой шкале (баллы).
Параметрические критерии
К параметрическим критериям относят: критерий Стьюдента для независимых выборок и критерий Стьюдента для связанных выборок.
t–критерий Стьюдента для независимых выборок
Условия применения: обе выборки независимы и получены из генеральных совокупностей X и Y, имеющих нормальное распределение с параметрами μx , μy , σx σy .
Гипотеза: Ho: μx= μy (предполагается равенство средних арифметических генеральных совокупностей).
t – критерий Стьюдента рассчитывается по формуле (1):
Значение S x—y зависит от того, равны или не равны объемы выборки, а также их дисперсии.
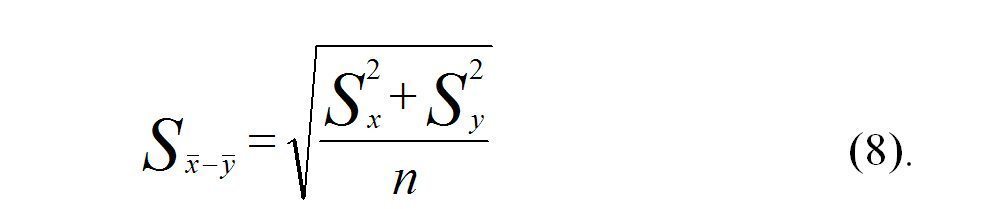
В случае равенства дисперсий и объемов выборок S x-y вычисляются по формуле (8)
t–критерий Стьюдента для связанных выборок (парные сравнения)
В практике педагогических исследований часто используются так называемые парные сравнения (до и после эксперимента). При парных сравнениях нельзя использовать рассмотренные выше методы для независимых выборок, поскольку это приведет к большим ошибкам. Для сравнения средних значений нужно использовать модификацию t – критерия Стьюдента для связанных выборок. Особенность расчета t – критерия в том, что гипотеза формулируется в отношении разностей сопряженных пар наблюдений.
Условия применения: di = xi – yi – разность связанных пар результатов измерения. Делается предположение о нормальном распределении этих разностей в генеральной совокупности с параметрами md , sd.
Значение t – критерия Стьюдента определяется по формуле (10):
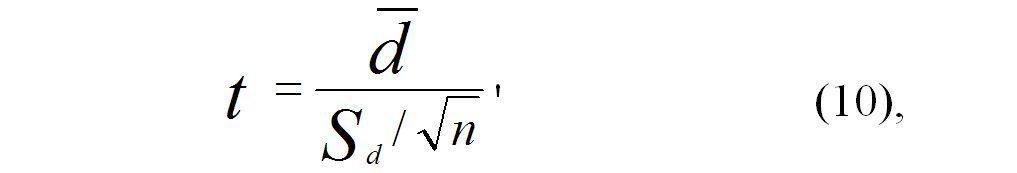
где: `d – среднее арифметическое разностей, Sd` стандартное отклонение.
Непараметрические критерии
Применение параметрических критериев (t – критерия Стьюдента) связано с целым рядом допущений. Например, сравнивая выборочные средние значения с помощью t – критерия Стьюдента, принимались следующие предположения: обе выборки являются случайными, то есть каждая из них получена в результате независимых измерений, обе выборки получены из генеральных совокупностей, имеющих нормальное распределение, дисперсии генеральных совокупностей равны между собой. На практике эти предположения строго никогда не выполняются, поэтому применение параметрических критериев всегда связано с опасностью ошибочных выводов, возникающих из-за нарушения принятых допущений. В последнее время в математической статистике интенсивно разрабатываются непараметрические методы, которые строятся так, чтобы их применение зависело от возможно меньшего числа допущений.
Параметрические критерии применимы только для сравнения выборочных данных, представляющих собой результаты измерений, выраженных в единицах метрических шкал (метры, килограммы, секунды и т.д.). Но в спортивных исследованиях часто приходится иметь дело с данными, выраженными в шкалах порядка, например, произвольная нумерация игроков в команде, места, занятые спортсменами в соревнованиях и т.д. Такие данные нельзя сравнивать с помощью параметрических критериев, а непараметрические критерии могут быть успешно применены и к данным этого типа.
Сравнение двух независимых выборок (критерий Манна-Уитни для независимых выборок)
Условие применения. Применение критерия Вилкоксона основано на единственном предположении: выборки получены из однотипных непрерывных распределений. При этом вид распределения генеральных совокупностей никак не оговаривается.
Гипотеза: Ho: Mex = Mey (предполагается равенство медиан двух генеральных совокупностей).
Сравнение двух связанных выборок (критерий Вилкоксона для связанных выборок)
Порядок использования t – критерия Стьюдента и W – критерия Вилкоксона следующий. При обработке выборочных данных рассчитывается фактическое значение критерия. Затем по табличным данным определяется его критическое значение. Если фактическое значение меньше, чем критическое на уровне значимости α=0,05, то различие считается статистически незначимым (р>0,05). Если вычисленное по выборке значение критерия превышает критические значения при a=0,05; a=0,01 или a=0,001, то различия считаются статистически значимыми. Это записывается следующим образом: p
Таблица 4 — Изменение высоты прыжка верх с места после силовых и скоростно-силовых тренировок в макроцикле (по: В.В.Марченко, Л.С.Дворкину, В.Н.Рогозяну, (1998).
Найди готовую курсовую работу выполненное домашнее задание решённую задачу готовую лабораторную работу написанный реферат подготовленный доклад готовую ВКР готовую диссертацию готовую НИР готовый отчёт по практике готовые ответы полные лекции полные семинары заполненную рабочую тетрадь подготовленную презентацию переведённый текст написанное изложение написанное сочинение готовую статью
Сделан в Word, графики в электронном виде с ссылками. Курсовая работа. Вариант 33. Гидравлический расчет гидросистемы стенда для испытания центробежных насосов.
(Материалы для самостоятельного изучения студентам психологам и социальным работникам)
Лекция № 2
Статистический анализ экспериментальных данных
1. Методы первичной статистической обработки результатов эксперимента
2. Методы вторичной статистической обработки результатов эксперимента
Краткое содержание
Рекомендуемые материалы
Методы первичной статистической обработки результатов эксперимента.
Общее представление о методах статистического анализа экспериментальных данных, назначение этих методов. Деление статистических методов на первичные и вторичные. Основные показатели, получаемые в результате первичной обработки экспериментальных данных. Вычисление средней арифметической. Определение дисперсии. Установление примерного распределения данных. Определение моды. Характеристика нормального распределения. Вычисление интервалов.
Методы вторичной статистической обработки результатов эксперимента.
Способы вторичной статистической обработки результатов исследования. Регрессионное исчисление. Сравнение средних величин разных выборок. Сравнение частотных распределений данных. Сравнение дисперсий двух выборок. Установление корреляционных зависимостей и их интерпретация. Понятие о факторном анализе как методе статистической обработки.
Способы табличного и графического представления результатов эксперимента.
Виды таблиц и их построение. Графическое представление экспериментальных данных. Гистограммы и их применение на практике.
МЕТОДЫ ПЕРВИЧНОЙ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ РЕЗУЛЬТАТОВ ЭКСПЕРИМЕНТА
Методами статистической обработки результатов эксперимента называются математические приемы, формулы, способы количественных расчетов, с помощью которых показатели, получаемые в ходе эксперимента, можно обобщать, приводить в систему, выявляя скрытые в них закономерности.
Речь идет о таких закономерностях статистического характера, которые существуют между изучаемыми в эксперименте переменными величинами.
1. Некоторые из методов математико-статистического анализа позволяют вычислять так называемые элементарные математические статистики, характеризующие выборочное распределение данных, например
*выборочное среднее,
*выборочная дисперсия,
*медиана и ряд других.
2. Иные методы математической статистики, например
дисперсионный анализ,
регрессионный анализ, позволяют судить о динамике изменения отдельных статистик выборки.
3. С помощью третьей группы методов, скажем,
*корреляционного анализа,
факторного анализа,
методов сравнения выборочныеа данных, можно достоверно судить о статистических связях,
существующих между переменными величинами, которые исследуют в данном эксперименте.
Все методы математико-статистического анализа условно делятся на первичные и вторичные 1 .
1 Приводимые здесь определения и высказывания не всегда являются достаточно строгими с точки зрения теории вероятностей и математической статистики как сложившихся областей современной математики. Это сделано для лучшего понимания данного текста студентами, не подготовленными в области математики:
Первичными называют методы, с помощью которых можно получить показатели, непосредственно отражающие результаты производимых в эксперименте измерений.
Соответственно под первичными статистическими показателями имеются в виду те, которые применяются в самих психодиагностических методиках и являются итогом начальной статистической обработки результатов психодиагностики.
Вторичными называются методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности.
К первичным методам статистической обработки относят, например,
*определение выборочной средней величины,
*выборочной дисперсии,
*выборочной моды и
*выборочной медианы.
В число вторичных методов обычно включают
*методы сравнения первичных статистик у двух или нескольких выборок.
Рассмотрим методы вычисления элементарных математических статистик, начав с выборочного среднего.
ВЫБОРОЧНОЕ СРЕДНЕЕ
Выборочное среднее значение как статистический показатель представляет собой среднюю оценку изучаемого в эксперименте психологического качества.
Эта оценка характеризует степень его развития в целом у той группы испытуемых, которая была подвергнута психодиагностическому обследованию. Сравнивая непосредственно средние значения двух или нескольких выборок, мы можем судить об относительной степени развития у людей, составляющих эти выборки, оцениваемого качества.
Выборочное среднее определяется при помощи следующей формулы:

хср —выборочная средняя величина или среднее арифметическое значение по выборке;
п — количество испытуемых в выборке или частных психодиагностических показателей, на основе которых вычисляется средняя величина;
xk — частные значения показателей у отдельных испытуемых. Всего таких показателей п, поэтому индекс k данной переменной принимает значения от 1 до п;
∑ — принятый в математике знак суммирования величин тех переменных, которые находятся справа от этого знака.

Выражение соответственно означает сумму всех х с индексом k от 1 до n.
Пример. Допустим, что в результате применения психодиагностической методики для оценки некоторого психологического свойства у десяти испытуемых мы получили следующие частные показатели степени развитости данного свойства у отдельных испытуемых: х1= 5, х2 = 4, х3 = 5, х4 = 6, х5 = 7, х6 = 3, х7 = 6, х8= 2, х9= 8, х10 = 4. Следовательно, п = 10, а индекс k меняет свои значения от 1 до 10 в приведенной выше формуле. Для данной выборки среднее значение 1 , вычисленное по этой формуле, будет равно:

В психодиагностике и в экспериментальных психолого-педагогических исследованиях среднее, как правило, не вычисляется с точностью, превышающей один знак после запятой, т.е. с большей, чем десятые доли единицы.
В психодиагностических обследованиях большая точность расчетов не требуется и не имеет смысла, если принять во внимание приблизительность тех оценок, которые в них получаются, и достаточность таких оценок для производства сравнительно точных расчетов.
Дисперсия как статистическая, величина характеризует, насколько частные значения отклоняются от средней величины в данной выборке.
Чем больше дисперсия, тем больше отклонения или разброс данных. Прежде чем представлять формулу для расчетов дисперсии, рассмотрим пример. Воспользуемся теми первичными данными, которые были приведены ранее и на основе которых вычислялась в предыдущем примере средняя величина. Мы видим, что все они разные и отличаются не только друг от друга, но и от средней величины. Меру их общего отличия от средней величины и характеризует дисперсия. Ее определяют для того, чтобы можно было отличать друг от друга величины, имеющие одинаковую среднюю, но разный разброс.
Представим себе другую, отличную от предыдущей выборку первичных значений, например такую: 5, 4, 5, 6, 5, 6, 5, 4, 5, 5. Легко убедиться в том, что ее средняя величина также равна 5,0. Но в данной выборке ее отдельные частные значения отличаются от средней гораздо меньше, чем в первой выборке. Выразим степень этого отличия при помощи дисперсии, которая определяется по следующей формуле:


где — выборочная дисперсия, или просто дисперсия;

— выражение, означающее, что для всех xk от первого до последнего в данной выборке необходимо вычислить разности между частными и средними значениями, возвести эти разности в квадрат и просуммировать;
п — количество испытуемых в выборке или первичных значений, по которым вычисляется дисперсия.
Определим дисперсии для двух приведенных выше выборок частных значений, обозначив эти дисперсии соответственно индексами 1 и 2:


Мы видим, что дисперсия по второй выборке (0,4) значительно меньше дисперсии по первой выборке (3,0). Если бы не было дисперсии, то мы не в состоянии были бы различить данные выборки.
ВЫБОРОЧНОЕ ОТКЛОНЕНИЕ
Иногда вместо дисперсии для выявления разброса частных данных относительно средней используют производную от дисперсии величину, называемую выборочное отклонение. Оно равно квадратному корню, извлекаемому из дисперсии, и обозначается тем же
Медианой называется значение изучаемого признака, которое делит выборку, упорядоченную по величине данного признака, пополам.
Справа и слева от медианы в упорядоченном ряду остается по одинаковому количеству признаков. Например, для выборки 2, 3,4, 4, 5, 6, 8, 7, 9 медианой будет значение 5, так как слева и справа от него остается по четыре показателя. Если ряд включает в себя четное число признаков, то медианой будет среднее, взятое как полусумма величин двух центральных значений ряда. Для следующего ряда 0, 1, 1, 2, 3, 4, 5, 5, 6, 7 медиана будет равна 3,5.
Знание медианы полезно для того, чтобы установить, является ли распределение частных значений изученного признака симметричным и приближающимся к так называемому нормальному распределению. Средняя и медиана для нормального распределения обычно совпадают или очень мало отличаются друг от друга.
Если выборочное распределение признаков нормально, то к нему можно применять методы вторичных статистических расчетов, основанные на нормальном распределении данных. В противном случае этого делать нельзя, так как в расчеты могут вкрасться серьезные ошибки.
Если в книге по математической статистике, где описывается тот или иной метод статистической обработки, имеются указания на то, что его можно применять только к нормальному или близкому к нему распределению признаков, то необходимо неукоснительно следовать этому правилу и полученное эмпирическое распределение признаков проверять на нормальность.
Если такого указания нет, то статистика применима к любому распределению признаков. Приблизительно судить о том, является или не является полученное распределение близким к нормальному, можно, построив график распределения данных, похожий на те, которые представлены на рис. 72. Если график оказывается более или менее симметричным, значит, к анализу данных можно применять статистики, предназначенные для нормального распределения. Во всяком случае, допустимая ошибка в расчетах в данном случае будет относительно небольшой.
Приблизительные картины симметричного и несимметричного распределений признаков показаны на рис. 72, где точками т1 и т2 на горизонтальной оси графика обозначены те величины признаков, которые соответствуют медианам, а х1 и х2 — те, которые соответствуют средним значениям.

Рис. 72. Графики симметричного и несимметричного распределения признаков: 1 – симметричное распределение (все относящиеся к нему элементарные статистики обозначены с помощь индекса 1); 11 – несимметричное распределение (его первичные статистики отмечены на графике индексом 2).
Мода еще одна элементарная математическая статистика и характеристика распределения опытных данных. Модой называют количественное значение исследуемого признака, наиболее часто встречающееся в выборке. На графиках, представленных на рис. 72, моде соответствуют самые верхние точки кривых, вернее, те значения этих точек, которые располагаются на горизонтальной оси.
Для симметричных распределений признаков, в том числе для нормального распределения, значения моды совпадают со значениям среднего и медианы. Для других типов распределений, несимметричных, это не характерно.
К примеру, в последовательности значений признаков 1, 2, 5, 2, 4, 2, 6, 7, 2 модой является значение 2, так как оно встречается чаще других значений — четыре раза.
Иногда исходных частных первичных данных, которые подлежат статистической обработке, бывает довольно много, и они требуют проведения огромного количества элементарных арифметических операций. Для того чтобы сократить их число и вместе с тем сохранить нужную точность расчетов, иногда прибегают к замене исходной выборки частных эмпирических данных на интервалы.
Интервалом называется группа упорядоченных по величине значений признака, заменяемая в процессе расчетов средним значением.
Пример. Представим следующий ряд частных признаков: О, 1, 1, 2, 2, 3, 3, 3, 4, 4, 5, 5, 5, 5, 6, 6, 6, 7, 7, 8, 8, 8, 9, 9, 9, 10, 10, 11, 11, 11. Этот ряд включает в себя 30 значений.
Разобьем представленный ряд на шесть подгрупп по пять признаков в каждом.
*Первая подгруппа включит в себя первые пять цифр,
Если Вам понравилась эта лекция, то понравится и эта - 9 Общественное потребление.
*вторая — следующие пять и т.д.
Вычислим средние значения для каждой из пяти образованных подгрупп чисел. Они соответственно будут равны 1,2; 3,4; 5,2; 6,8; 8,6; 10,6.
Таким образом, нам удалось свести исходный ряд, включающий тридцать значений, к ряду, содержащему всего шесть значений и представленному средними величинами. Это и будет интервальный ряд, а проведенная процедура — разделением исходного ряда на интервалы.
Теперь все статистические расчеты мы можем производить не с исходным рядом признаков, а с полученным интервальным рядом, и результаты в равной степени будут относиться к исходному ряду. Однако число производимых в ходе расчетов элементарных арифметических операций будет гораздо меньше, чем количество тех операций, которые с этой же целью пришлось бы проделать в отношении исходного ряда признаков.
На практике, составляя интервальный ряд, рекомендуется руководствоваться следующим правилом: если в исходном ряду признаков больше чем тридцать, то этот ряд целесообразно разделить на пять-шесть интервалов и в дальнейшем работать только с ними.
Для проверки сказанного проведем пробное вычисление среднего значения по приведенному выше ряду, составляющему тридцать чисел, и по ряду, включающему только интервальные средние значения. Полученные цифры с точностью до двух знаков после запятой будут соответственно равны 5,97 и 5,97, т.е. являются одинаковыми.
Свидетельство и скидка на обучение каждому участнику
Зарегистрироваться 15–17 марта 2022 г.
Тема 5. Статистические методы обработки данных 1. Методы получения данных (числовой информации).
Исследователь получает знания об объекте изучения не только путем сбора информации, но и ее обработкой. Обработка информации включает в себя различные методы, такие как: статистическая группировка; построение рядов распределения; создание статистических таблиц; графическая интерпретация эмпирических зависимостей; нахождение средних величин; определение мер изменчивости и др.
Данные методы реализуемы, если мы необходимую информацию получим в виде чисел. Это возможно, если исследователь использует измерительные шкалы.
1. Методы получения данных (числовой информации) Числовую информацию (данные) получают путем измерения. Как нам известно, измерение – это сравнение какой-либо физической величины объекта познания с эталонной единицей этой величины.
Измерение является признаком научной деятельности, поскольку любое исследование становится научным только тогда, когда в нём происходят измерения.
Назначение измерения состоит в том, чтобы выразить свойства объекта в количественных характеристиках, перевести их в языковую форму и сделать основой математического, графического или логического описания.
Измерение производится с помощью шкал. Шкалой называется числовая система, с помощью которой каждому объекту ставиться в соответствие некоторое число. Приписываемые объектам числа называются шкальными значениями.
Рассмотрим, как применяется измерение при ответах респондентов на закрытые вопросы.
Ответы на вопросы должны иметь такой вид, чтобы можно было бы применить для их обработки математико-статистические методы. Для этого используют шкалы и кодировку.
Это число называется шкальным значением.
Шкала - это определенный упорядоченный числовой ряд. Респондент по шкале может выбрать цифру, число, которое соответствует его мнению относительно интенсивности протекания того или иного социального процесса. Пример 1: "Как часто вы ходите в библиотеку?"
Очень часто
Довольно часто
Довольно редко
Практически не хожу в библиотеку
При измерении социальной информации чаще всего используются следующие шкалы.
Шкала наименований или номинальная шкала–это шкала, которая используется только для того, чтобы различать объекты, устанавливать отношение равенства или неравенства между ними. Демонстрирует наличие или отсутствие признака.
Приведенный ряд наименований не упорядочен, но имеет единое основание - причины увольнения с работы.
Таким образом, шкала наименований используется для описания принадлежности объектов к определенным классам. В данной шкале отсутствуют понятия масштаба и начала отсчета.
При использовании номинальных шкал невозможно установить никаких математических отношений между ответом и изучаемой переменной.
Порядковая шкала (ранговая шкала) способ измерения информации, основанный на возможности сопоставления степени выраженности единиц наблюдения.
В исследованиях такие шкалы используют для выяснения интенсивности оценок суждений, свойств, степени согласия или несогласия с предложенными утверждениями.
Примером применения порядковой шкалы является выставление оценок по результатам сдачи экзамена в учебном заведении (5; 4; 3; 2).
Разновидностью порядковой шкалы является ранговая шкала, в которой единицы анализа (шкальные значения) полностью упорядочены с помощью присваивания им числовых рангов от менее значимых к более значимым.
Таким образом, порядковая шкала применяется для измерения упорядочивания объектов по одному или совокупности признаков. Числа в шкале определяют порядок следования объектов и не дают возможности выяснить, насколько или во сколько раз один объект предпочтительнее другого. В этой шкале отсутствуют понятия масштаба и начала отсчета.
Интервальная шкала (она же Шкала разностей)
Здесь происходит сравнение с эталоном. Построение такой шкалы позволяет большую часть свойств существующих числовых систем приписывать числам, полученным на основе субъективных оценок.
Для данной шкалы допустимым является линейное преобразование. Это позволяет приводить результаты тестирования к общим шкалам и осуществлять, таким образом, сравнение показателей.
Пример: шкала Цельсия.
Начало отсчёта произвольно, единица измерения задана. Допустимые преобразования — сдвиги. Пример: измерение времени.
2.1. Меры центральной тенденции
Наиболее часто в статистике используют три меры центральной тенденции распределения: мода, среднее арифметическое и медиана.
Мода — это наиболее часто встречающееся значение в ряду данных. Например, в массиве модой будет являться значение 5. Обозначается следующим образом: Мо=5. Если выборка содержит две моды, то распределение называется бимодальным. Таким примером может служить массив (Mo 1 =5, Мо2=3). Если все значения выборки встречаются одинаково часто, то моды у распределения нет.
Бимодальное или полимодальное (содержащее более двух мод) распределение может рассматриваться как признак неоднородности выборки.
Среднее арифметическое значение — это отношение суммы всех значений данных к числу слагаемых. Среднее арифметическое часто обозначается как М ср или x (с чертой сверху), число слагаемых — буквой п , а индивидуальные значения показателя — символом х i .
Среднее арифметическое рассчитывается по формулам, представленным ниже.
x (х 1 х 2 . х п )
x 1 n x i . п i 1
В качестве примера можно рассмотреть массив
12, 13, 14, 17, 19, 19, 20, 20>: М ср =(8 + 9 + 11 + 2 ∗ 12 + 13 + 14 + 17 + 2 ∗ 19 + 2 ∗ 20)/12 = 14,5.
Медиана разбивает упорядоченный статистический ряд на две равные части. Для определения медианы необходимо сначала упорядочить данные.
Например, для определения значения медианы в массиве необходимо этот массив упорядочить (произвести сортировку по возрастанию): 13, 15, 17, 19, 19, 20>. Медиана будет равна 13, обозначается следующим образом: Me = 13.
Если количество данных в выборке четное, то медиана равна среднему арифметическому показателю между двумя центральными значениями.
Например, если добавить в последнюю выборку значение 20 и упорядоченный массив примет следующий вид: , то медиана будет равна 14. В подобном случае медиана не может соответствовать ни одному из значений выборки.
Медиана может принимать и дробные значения.
Например, если мы в последнем примере 15 (одно из двух центральных значений) заменим на 14, то массив примет вид (8, 9, 11, 12, 12, 13, 14, 17, 19, 19, 20, 20> и медиана будет равна 13,5.
В табл. 1 приводятся данные о возможности использования тех или иных мер центральной тенденции в зависимости от типа измерительных шкал.
Выбор меры центральной тенденции в зависимости от типа измерительной шкалы
Меры центральной тенденции
Номинальная
Интервальная
Мода, медиана, среднее
Мода, медиана, среднее
2.1. Меры изменчивости
К мерам изменчивости переменной относятся следующие характеристики: размах, дисперсия, среднее квадратическое (стандартное) отклонение и среднее линейное отклонение
Размах измеряет на числовой шкале расстояние, в пределах которого изменяются оценки. Поскольку существуют несколько иные определения размаха, то надо разграничить два его типа: включающий и исключающий.
Размах – это разность максимального и минимального значений в статистическом ряду.
Например, размах значений 1, 2, 3, 5, 8 равен 8 – 1 = 7. Значения: –0,2; 0,4; 0,8; 1,6 имеют размах, равный 1,6 – (–0,2) = 1,8.
Размах представляет собой меру рассеяния, разброса, неоднородности или изменчивости. Эта величина возрастает с ростом рассеяния и уменьшением однородности. Заметим, что, так же как и для моды и медианы, в ходе вычисления этой меры не учитывается каждое отдельное значение. Теперь мы сталкиваемся с другой мерой, при вычислении которой, как и для среднего, используется каждая оценка. Такая мера изменчивости называется дисперсией (обозначается D, σ или s 2
x ) и имеет вид
n (x i x ) 2
s x 2 i 1 . n 1
Ценность дисперсии заключается в том, что, являясь мерой варьирования числовых значений признака вокруг его среднего значения, она измеряет внутреннюю изменчивость значений признака, зависящую от разностей между наблюдениями. Преимущество дисперсии перед другими показателями вариации состоит также и в том, что она разлагается на составные компоненты, позволяя тем самым оценивать влияние различных факторов на величину учитываемого признака.
Мерой изменчивости, тесно связанной с дисперсией, является стандартное отклонение. Среднее квадратическое или стандартное отклонение, обозначаемое sx (или x ), определяется как положительное значение квадратного корня из дисперсии. Для определения sx надо сначала найти s x 2 , а затем вычислить квадратный корень из s x 2 :
n x i x 2
s x i 1 .
Стандартное отклонение часто является полезной мерой вариации, так как для многих распределений мы приблизительно знаем, какой процент данных лежит внутри одного, двух, трех и более стандартных отклонений среднего. Например, мы можем
знать, что 70% значений лежит между x s x и x s x .
Еще одна мера изменчивости — среднее отклонение — вычисляется легче, чем стандартное отклонение, но используется реже. Отклонение каждого значения от среднего обозначается как
х i x . Совокупность всех n отклонений характеризует изменчивость в исходных данных. Однако, сумма положительных и отрицательных отклонений вовсе не является мерой общей изменчивости в группе данных, ибо она всегда точно равна нулю.
Если рассматривать отклонения как расстояния от x без учета знака, то сумма этих расстояний будет характеризовать изменчивость данных.
Читайте также:
- Назовите основные стоянки мезолита и неолита на территории мордовии кратко
- Социальное образование это кратко
- Создание благоприятного психологического климата во время переговоров кратко
- Инвазивные и неинвазивные методы исследования в акушерстве кратко
- Положение о рабочей программе воспитателя в школе интернате