
Система машинного перевода кратко
Обновлено: 30.06.2024
С возникновением письменности люди получили мощный инструмент для сохранения знаний и для коммуникации. Первые письмена, дошедшие до нас на стенах храмов и гробниц, повествуют о деяниях царей и полководцев, происшедших много веков назад. Кроме того, люди записывали результаты хозяйственной деятельности, для того чтобы успешно торговать, собирать налоги и т.д.
Чтобы облегчить письменное общение между народами были созданы первые словари. Один из таких словарей был написан шумерскими жрецами на глиняных табличках. Каждая табличка была поделена на две равные части. С одной стороны записывалось шумерское слово, а с другой — аналогичное по значению слово на другом языке, иногда с кратким пояснением. С тех времен до наших дней структура словарей практически не изменилась.
С появлением персонального компьютера стали создаваться электронные словари, облегчившие поиск нужного слова и предложившие множество новых полезных функций (озвучивание слова, поиск синонимов и т.д.).
Технология машинного перевода постепенно совершенствовалась. И если качество и скорость перевода первых систем оставляли желать лучшего, то теперь компьютер действительно может связно переводить текст с одного языка на другой. А более современные системы с приемлемым качеством переводят 1 страницу текста за 1 секунду.
Кому и зачем нужен машинный перевод
В последнее время активно обсуждаются возможности и перспективы технологий машинного перевода (MП). В дискуссиях принимают участие как профессиональные переводчики, так и производители систем МП. Попробуем оценить возможности МП, опираясь на опыт применения реальных систем.
Справедливости ради следует отметить, что в обозримом будущем машинная технология не сможет полностью заменить переводчика-человека. По качеству перевода программы МП не смогут состязаться с человеком. Однако с помощью подобных программ можно существенно повысить эффективность труда переводчика.
Основываясь на формальном описании языков, программа анализирует текст на одном языке, а затем синтезирует фразу на другом. Алгоритмы анализа и синтеза, как правило, довольно сложны и управляются словарной информацией, приписанной лексическим единицам в словарях системы как для языка исходного текста, так и для языка его перевода.
Помимо этого системы МП могут быть использованы для решения задач профессионального перевода и значительно повысить эффективность работ. Сравним оба способа — традиционный и машинный. Традиционный перевод обычно включает несколько этапов: перевод, редакторская правка, верстка, корректура. При этом в целях ускорения перевод, как правило, выполняют несколько переводчиков. Вследствие этого возникает проблема единой терминологии и единого стиля перевода, что увеличивает затраты на редакторскую правку. Кроме того, значительные усилия приходится тратить на переверстку документа.
Что дает применение систем МП и где оно наиболее целесообразно? Системы МП, используя для перевода общую словарную базу, в значительной степени минимизируют затраты на поддержание единой терминологии, а следовательно, на редакторскую правку. При этом технический редактор получает от системы МП перевод, выполненный в едином стиле. Таким образом, использование систем машинного перевода наиболее эффективно для организации технологического процесса по переводу больших массивов однотипных документов в сжатые сроки с обеспечением единства терминологии и стиля по всему массиву документов.
Для оценки эффективности использования систем МП компания ПРОМТ предоставила свою систему PROMT 2000 Translation Office центру переводов ЛОНИИС. Эксперимент показал, что использование МП позволяет сократить суммарное время выполнения проекта примерно в 2 раза.
Следует отметить и ряд ограничений на использование систем МП. Не имеет смысла переводить с помощью программы-переводчика художественные тексты, пословицы и поговорки. Небольшие по объему тексты различной тематики также лучше переводить традиционным способом.
Русские системы машинного перевода
PROMT Translation Office 2000
PROMT Translation Office 2000 (далее — PROMT) ценой 300 долл. — это набор профессиональных инструментов, обеспечивающий перевод с основных европейских языков на русский и обратно. С его помощью можно не только переводить, но и редактировать перевод и работать со словарями всех языковых направлений одновременно.
В PROMT входят следующие коллекции словарей:
Для обеспечения высокого качества перевода в системе PROMT предусмотрена возможность настройки на перевод конкретного текста — посредством подключения специализированных предметных словарей, поставляемых отдельно, а также создания собственных пользовательских словарей. Удобным средством настройки системы является также возможность выбора тематики документа: какие словари подключать, какие слова оставить без перевода и как обрабатывать специальные конструкции типа электронного адреса, даты и времени.
Система PROMT включает следующие модули:
Перевод документа в системе PROMT
При первом запуске PROMT (рис. 1) в меню и на панелях инструментов отображаются основные команды и кнопки. При работе с PROMT кнопки, часто или недавно используемые, хранятся в личных настройках и отображаются в меню и на панелях инструментов. Можно настраивать или создавать новые панели инструментов, добавляя, изменяя структуру и удаляя кнопки и меню. Кроме того, можно отображать, перемещать и скрывать панели инструментов.
Окно PROMT-документа содержит исходный текст и его перевод, а также информационную панель, отображающую список используемых при переводе словарей, списки незнакомых и зарезервированных слов (рис. 3).
Меткой отмечен текущий абзац исходного текста и перевод этого абзаца (текущим из них является тот, в котором в данный момент установлен курсор).
Все документы, с которыми работает программа PROMT, появляются в окнах документов. Одновременно могут быть открыты несколько документов — каждый в своем окне (рис. 4, 5).
Выполненный перевод можно уточнить, воспользовавшись электронными словарями, разработанными другими фирмами (если они, конечно, установлены на вашем компьютере). Могут быть использованы электронные словари:
При переводе система PROMT не использует электронные словари других производителей. Поэтому, если какого-либо слова нет в словарях системы PROMT или вас не устраивает перевод какого-либо слова или словосочетания, можно вызвать электронный словарь и воспользоваться им как справочным.
Для перевода HTML-документов в комплект поставки входит браузер WebView.
Последовательность действий при выполнении перевода
- Откройте файл с исходным текстом или создайте новый документ (новый текст можно набрать непосредственно в окне PROMT).
- Проверьте разбивку текста на абзацы (после перевода форматирование по абзацам сохранится).
- Проверьте орфографию и отредактируйте исходный текст, если это необходимо.
- Выберите шаблон тематики, подходящий для перевода данного текста (шаблон тематики для данного направления перевода — это набор словарей и список зарезервированных слов; он устанавливается для повышения качества перевода).
- Уточните тематику документа, настроив ее компоненты:
- подключите словари, которые будут использоваться при переводе текста. Если не подключен ни один словарь, при переводе будет использоваться только общелексический генеральный словарь;
- зарезервируйте слова, которые в тексте перевода должны оставаться на языке исходного текста;
- подключите препроцессор, если хотите отменить перевод некоторых конструкций, например адресов электронной почты, имен файлов, а также выбрать форму представления даты и времени в тексте перевода;
- отметьте абзацы, не требующие перевода.
- Переведите текст (сразу весь документ или по абзацам).
- Введите незнакомые слова в свой пользовательский словарь, если хотите, чтобы они в дальнейшем переводились.
- Воспользуйтесь электронным словарем для уточнения значений слов.
- Сохраните результаты перевода.
Системные требования
Минимальная конфигурация компьютера:
- IBM PC-совместимый компьютер с процессором P166 или выше;
- 32 Мбайт оперативной памяти;
- примерно 160 Мбайт на жестком диске (для системы со всеми компонентами);
- видеоадаптер SVGA или лучшего разрешения;
- устройство для чтения компакт-дисков CD-ROM (для инсталляции);
- мышь или совместимое устройство;
- ОС: Windows 98 (русская версия или панъевропейская с поддержкой русского языка и русскими региональными установками), или Windows NT 4.0 SP3 (или выше) с поддержкой русского языка и русскими региональными установками, или Windows 2000 Professional (с поддержкой русского языка и русскими региональными установками);
- Microsoft Internet Explorer 5.x (входит в поставку).
Рекомендуемая конфигурация компьютера:
- IBM PC-совместимый компьютер с процессором PII-300 или выше;
- 64 Мбайт оперативной памяти
Сократ Персональный 4.0
Вид главного окна программы показан на рис. 6.
Для того чтобы воспользоваться словарем (рис. 7), достаточно щелкнуть мышью на соответствующей закладке. Кроме того, окно словаря может быть вызвано при помощи горячих клавиш.
С помощью словаря вы можете получить перевод искомого слова следующими способами:
- набрать слово в поле ввода, расположенном в верхнем правом окне словаря. Перемещение по словарной базе осуществляется по мере ввода букв, до тех пор пока не будет получено максимально возможное совпадение;
- вставить слово в поле ввода из буфера обмена. В этом случае будет осуществлен быстрый переход к слову, максимально совпадающему с введенным;
- выбрать ранее переведенное слово из окна истории поля ввода, после чего будет осуществлен быстрый переход к тому слову, которое имеет максимально возможное совпадение с введенным;
- выделить слово в другом приложении и, удерживая клавишу Shift, щелкнуть по выделению правой кнопкой мыши. Во всплывающем окне появится перевод выделенного слова;
- использовать сочетание горячих клавиш, предварительно поместив необходимое слово в буфер обмена.
Перевод содержимого справки
Если в окне справки был выделен какой-либо фрагмент, то будет переведен только он.
Перевод слов или текста из других приложений
Для того чтобы получить перевод текста из другого приложения (например, текстового редактора), необходимо выделить подлежащий переводу текст и, удерживая клавишу Shift, щелкнуть по выделению правой кнопкой мыши. Появится всплывающее окно, содержащее перевод выделенного фрагмента.
Для того чтобы получить перевод слова из другого приложения, необходимо выделить интересующее вас слово и, удерживая клавишу Shift, щелкнуть по выделению правой кнопкой мыши. Появившееся всплывающее окно будет содержать перевод выделенного слова.
Системные требования
Минимальная конфигурация компьютера:
- IBM PC-совместимый компьютер с процессором Pentium 90 или выше;
- Операционная система Windows 98/Me или Windows NT/2000;
- 32 Мбайт оперативной памяти;
- 16 Мбайт свободного места на жестком диске.
Словари
Каждая из названных компаний выпустила уже не первую версию своей системы, однако по функциональным возможностям словари разных производителей почти одинаковы. Основным различием является количество словарных статей (слов) в словарях и количество словарей.
Lingvo 7.0
Lingvo 7.0 — это мощный профессиональный словарь, очень удобный для пользователя. Нажмите горячую клавишу в любом Windows-приложении — и на экране появится самый полный перевод слова из всех словарей, подключенных к системе. Грамматические комментарии на любое слово, озвучивание наиболее важных слов, проверка правильности написания, возможность создания собственных словарей — всё это предлагает ABBYY Lingvo 7.0 (рис. 9). Lingvo 7.0 содержит более 1,2 млн. слов и словосочетаний в 18 общих и специализированных словарях.
При переводе с русского языка на английский выделение сочетаний и грамматических конструкций не представляет труда, и если данных сочетаний нет в словаре, можно сразу же обратиться к функции полнотекстового поиска. Результаты поиска позволяют оценить, как переводится интересующее вас выражение в реальных примерах.
Основные особенности Lingvo:
Системные требования
Минимальная конфигурация компьютера:
- IBM PC-совместимый компьютер с процессором Pentium 133 или выше;
- операционная система Windows 95/98/Mе, Windows 2000/Windows NT 4.0 (SP3 или выше);
- 16 Mбайт оперативной памяти для Windows 95/98/Mе, 32 Mбайт оперативной памяти для Windows 2000/Windows NT 4.0;
- от 85 до 265 Мбайт свободного пространства на жестком диске;
- дисковод 3.5” и CD-ROM-устройство, мышь;
- Microsoft Internet Explorer 5.0 и выше (дистрибутив ABBYY Lingvo 7.0 включает в себя Microsoft Internet Explorer 5.5 — при его установке потребуется дополнительно от 27 до 80 Мбайт);
- звуковая плата, совместимая с операционной системой; наушники или колонки (рекомендуется).
Контекст 4.0
Появилась новая функция быстрого набора (Fast Typing). При вводе слова пользователь получает подсказки близких слов из текущего словаря с учетом уже введенных символов (рис. 15). Далее пользователь может выбрать из списка или продолжить набор самостоятельно.
Для совместной работы словарей на разных языках наряду с автоматическим определением добавлена функция выбора языка (рис. 16).
Системные требования
Минимальная конфигурация компьютера:
- IBM PC-совместимый компьютер с процессором Pentium 133 или выше;
- операционная система Windows 95/98/Me, Windows 2000/Windows NT 4.0 (SP3 или выше);
- 16 Мбайт оперативной памяти для Windows 95/98/Me, 32 Мбайт оперативной памяти для Windows 2000/Windows NT 4.0;
- от 20 Мбайт свободного пространства на жестком диске;
- дисковод CD-ROM, мышь;
- звуковая плата, совместимая с операционной системой, наушники или колонки (рекомендуется).
МультиЛекс 3.5
Рабочая область по вертикали разделена на две части: панель заголовков статей (левая) и панель текста словарной статьи (правая). Границу между панелями можно передвигать вправо-влево.
Левая панель содержит список заголовков статей того словаря, который показывается в панели словарей при помощи пиктограммы в виде открытой книги (используется для просмотра заголовков словарных статей). Правая панель всегда показывает словарную статью, соответствующую заголовку, выделенному в правой панели. Словарная статья начинается с заголовка, за которым следует его транскрипция. Далее указывается часть речи, даются возможные переводы, пояснения, примеры.
Панель словарей позволяет выбрать нужный словарь. Каждому словарю соответствует своя пиктограмма, принимающая три различных состояния: закрытая книга, полуоткрытая книга или открытая книга. Форма значков показывает, какой из словарей сейчас открыт и в каких словарях в результате последнего поиска было что-либо найдено.
Если значок словаря изображает открытую книгу (блокнот) — данный словарь сейчас открыт, полуоткрытую книгу (блокнот) — данный словарь сейчас не открыт, но в нем содержится информация, соответствующая вашему запросу, а если пиктограмма изображает закрытую книгу (блокнот) — данный словарь закрыт и нужной вам информации в нем нет.
Версия 3.5 обладает рядом достоинств, которые вы не найдете в предыдущей версии:
Системные требования
Минимальная конфигурация компьютера:
- IBM PC-совместимый компьютер с процессором 486 или выше;
- операционная система Windows 95/98/Mе, Windows 2000/Windows NT 4.0 (SP3 или выше);
- 8 Мбайт оперативной памяти;
- от 15 Мбайт свободного пространства на жестком диске;
- дисковод CD-ROM, мышь;
- звуковая плата, совместимая с операционной системой, наушники или колонки (рекомендуется).
Резюме
В заключение несколько слов о личном опыте использования систем машинного перевода и словарями.
Три года назад я использовал систему машинного перевода для подготовки отчета западному работодателю. Несколько человек, которые занимались офшорным программированием, писали программу навигационного приемника. К сожалению, мало кто из группы владел английским настолько, чтобы описать результаты своей работы на языке заказчика. В связи с этим возникла необходимость перевода отчетов, составленных на русском языке. Именно тогда мне в голову пришла идея опробовать систему машинного перевода Stylus (первые версии систем компании ПРОМТ назывались именно так). Эта попытка оказалась очень удачной: я перевел 140-страничный документ раза в три быстрее, чем планировал. Конечно, перевод, выполненный программой, был не идеален. Мне пришлось много и долго его редактировать. Но выигрыш налицо.
С того времени при переводе текстов объемом более 10 страниц я всегда пользуюсь системами машинного перевода.
Эту историю я рассказал своему другу-предпринимателю. Тогда он начинал торговать обувью и налаживал связи с немецкими поставщиками. Он также купил подобную систему и до сих пор успешно переписывается с немцами по электронной почте (ни английского, ни немецкого он не знает). Написав письмо по-русски, он переводит его на немецкий и отсылает, а полученный ответ переводит на русский. И все довольны. В итоге мой друг на днях открывает уже пятый обувной магазин в Москве.
С электронными словарями я ознакомился еще раньше, когда у меня возникла необходимость читать зарубежные книги и журналы по техническим дисциплинам со специфической лексикой. Технические электронные словари, словари по телекоммуникациям и информатике позволили мне сохранить много времени и сил. Спасибо Lingvo!
Надеемся, что мой рассказ о новых системах машинного перевода и словарях поможет вам эффективно организовать свою работу и в конечном итоге добиться успеха.
МАШИННЫЙ ПЕРЕВОД, выполняемое на компьютере действие по преобразованию текста на одном естественном языке в эквивалентный по содержанию текст на другом языке, а также результат такого действия. Современный машинный, или автоматический перевод осуществляется с помощью человека: пред-редактора, который тем или иным образом предварительно обрабатывает подлежащий переводу текст, интер-редактора, который участвует в процессе перевода, или пост-редактора, который исправляет ошибки и недочеты в переведенном машиной тексте.
Для осуществления машинного перевода в компьютер вводится специальная программа, реализующая алгоритм перевода, под которым понимается последовательность однозначно и строго определенных действий над текстом для нахождения переводных соответствий в данной паре языков L1 – L2 при заданном направлении перевода (с одного конкретного языка на другой). Система машинного перевода включает в себя двуязычные словари, снабженные необходимой грамматической информацией (морфологической, синтаксической и семантической) для обеспечения передачи эквивалентных, вариантных и трансформационных переводных соответствий, а также алгоритмические средства грамматического анализа, реализующие какую-либо из принятых для автоматической переработки текста формальных грамматик. Имеются также отдельные системы машинного перевода, рассчитанные на перевод в рамках трех и более языков, но они в настоящее время являются экспериментальными.
Наиболее распространенной является следующая последовательность формальных операций, обеспечивающих анализ и синтез в системе машинного перевода:
1. На первом этапе осуществляется ввод текста и поиск входных словоформ (слов в конкретной грамматической форме, например дательного падежа множественного числа) во входном словаре (словаре языка, с которого производится перевод) с сопутствующим морфологическим анализом, в ходе которого устанавливается принадлежность данной словоформы к определенной лексеме (слову как единице словаря). В процессе анализа из формы слова могут быть получены также сведения, относящиеся к другим уровням организации языковой системы.
2. Следующий этап включает в себя перевод идиоматических словосочетаний, фразеологических единств или штампов данной предметной области (например, при англо-русском переводе обороты типа in case of, in accordance with получают единый цифровой эквивалент и исключаются из дальнейшего грамматического анализа); определение основных грамматических (морфологических, синтаксических, семантических и лексических) характеристик элементов входного текста (например, числа существительных, времени глагола, синтаксических функций словоформ в данном тексте и пр.), производимое в рамках входного языка; разрешение омографии (конверсионной омонимии словоформ – скажем, англ. round может быть существительным, прилагательным, наречием, глаголом или же предлогом); лексический анализ и перевод лексем. Обычно на этом этапе однозначные слова отделяются от многозначных (имеющих более одного переводного эквивалента в выходном языке), после чего однозначные слова переводятся по спискам эквивалентов, а для перевода многозначных слов используются так называемые контекстологические словари, словарные статьи которых представляют собой алгоритмы запроса к контексту на наличие/отсутствие контекстных определителей значения.
3. Окончательный грамматический анализ, в ходе которого доопределяется необходимая грамматическая информация с учетом данных выходного языка (например, при русских существительных типа сани, ножницы глагол должен стоять в форме множественного числа, при том что в оригинале может быть и единственное число).
4. Синтез выходных словоформ и предложения в целом на выходном языке.
В зависимости от особенностей морфологии, синтаксиса и семантики конкретной языковой пары, а также направления перевода общий алгоритм перевода может включать и другие этапы, а также модификации названных этапов или порядка их следования, но вариации такого рода в современных системах, как правило, незначительны. Анализ и синтез могут производиться как пофразно, так и для всего текста, введенного в память компьютера; в последнем случае алгоритм перевода предусматривает определение так называемых анафорических связей (такова, например, связь местоимения с замещаемым им существительным – скажем, местоимения им со словом местоимения в самом этом пояснении в скобках).
Действующие системы машинного перевода ориентированы на конкретные пары языков (например, французский и русский или японский и английский) и используют, как правило, переводные соответствия либо на поверхностном уровне, либо на некотором промежуточном уровне между входным и выходным языком. Качество машинного перевода зависит от объема словаря, объема информации, приписываемой лексическим единицам, от тщательности составления и проверки работы алгоритмов анализа и синтеза, от эффективности программного обеспечения. Современные аппаратные и программные средства допускают использование словарей большого объема, содержащих подробную грамматическую информацию. Информация может быть представлена как в декларативной (описательной), так и в процедурной (учитывающей потребности алгоритма) форме.
Теоретической основой начального (конец 1940-х – начало 1950-х годов) периода работ по машинному переводу был взгляд на язык как кодовую систему. Пионерами МП были математики и инженеры. Описания их первых опытов, связанных с использованием только что появившихся ЭВМ для решения криптографических задач, были опубликованы в США в конце 1940-х годов. Датой рождения машинного перевода как исследовательской области обычно считают март 1947; именно тогда специалист по криптографии Уоррен Уивер в своем письме Норберту Винеру впервые поставил задачу машинного перевода, сравнив ее с задачей дешифровки.
Тот же Уивер после ряда дискуссий составил в 1949 меморандум, в котором теоретически обосновал принципиальную возможность создания систем машинного перевода. Вскоре началось финансирование исследований; в 1952 состоялась первая конференция по машинному переводу, организованная логиком и математиком Й.Бар-Хиллелом.
В 1954 общественности были предъявлены первые результаты: фирма IBM совместно с Джорджтаунским университетом (США) успешно осуществили первый эксперимент (вошедший в историю под названием Джорджтаунского), в ходе которого система, использовавшая словарь из 250 слов и грамматику из 6 синтаксических правил, осуществила перевод 49 заранее отобранных предложений. В том же 1954 первый эксперимент по машинному переводу был осуществлен в СССР И.К.Бельской (лингвистическая часть) и Д.Ю.Пановым (программная часть) в Институте точной механики и вычислительной техники Академии наук СССР, а первый промышленно пригодный алгоритм машинного перевода и система машинного перевода с английского языка на русский на универсальной вычислительной машине были разработаны коллективом под руководством Ю.А.Моторина. После этого работы начались во многих информационных институтах, научных и учебных организациях страны.
Идея машинного перевода стимулировала развитие исследований в теоретическом и прикладном языкознании во всем мире. Появились теории формальных грамматик, большое внимание стало уделяться моделированию языка и отдельных его аспектов, языковой и мыслительной деятельности, вопросам языковой формы и количественных распределений лингвистических явлений. Возникли новые направления лингвистической науки – вычислительная, математическая, инженерная, статистическая, алгоритмическая лингвистика и ряд других отраслей прикладного и теоретического языкознания. В течение 1950-х годов в учебных центрах многих стран мира были открыты отделения прикладной лингвистики и машинного перевода. Так, в СССР такие отделения были созданы в Москве (МГУ им. М.В.Ломоносова, МГПИИЯ им. М.Тореза – ныне МГЛУ), в Минском МГПИИЯ, в Ереване, Махачкале, Ленинградском университете, в университетах Киева, Харькова, Новосибирска, ряда других городов. Исследования и разработки по машинному переводу развернулись также во Франции, Англии, США, Канаде, Италии, Германии, Японии, Нидерландах, Болгарии, Венгрии и других странах, а также в международных организациях, где велик объем переводов с различных языков. В настоящее время исследования по МП ведутся и в таких странах, как Малайзия, Саудовская Аравия, Иран и др.
Новый подъем исследований в области МП начался в 1970-х годах и был связан с серьезными достижениями в области компьютерного моделирования интеллектуальной деятельности. Соответствующая область исследований, возникшая несколько позже МП (датой ее рождения обычно считают 1956), получила название искусственного интеллекта, а создание систем машинного перевода было осмыслено в 1970-е годы как одна из частных задач этого нового исследовательского направления.
Можно выделить два основных стимула к развитию работ по машинному переводу в современном мире. Первый – собственно научный; он определяется комплексностью и сложностью компьютерного моделирования перевода. Как вид языковой деятельности перевод затрагивает все уровни языка – от распознавания графем (и фонем при переводе устной речи) до передачи смысла высказывания и текста. Кроме того, для перевода характерна обратная связь и возможность сразу проверить теоретическую гипотезу об устройстве тех или иных языковых уровней и эффективности предлагаемых алгоритмов. Эта характеристическая черта перевода вообще и машинного перевода в частности привлекает внимание теоретиков, в результате чего продолжают возникать все новые теории автоматизации перевода и формализации языковых данных и процессов.
Второй стимул – социальный, и обусловлен он возрастающей ролью самой практики перевода в современном мире как необходимого условия обеспечения межъязыковой коммуникации, объем которой возрастает с каждым годом. Другие способы преодоления языковых барьеров на пути коммуникации – разработка или принятие единого языка, а также изучение иностранных языков – не могут сравниться с переводом по эффективности. С этой точки зрения можно утверждать, что альтернативы переводу нет, так что разработка качественных и высокопроизводительных систем машинного перевода способствует разрешению важнейших социально-коммуникативных задач.
В ходе развития идей и создания промышленных систем машинного перевода были разработаны способы автоматического морфологического анализа для основных европейских языков, методы автоматического обнаружения синтаксических структур, сформулированы требования к семантическим компонентам систем. В рамках эффективного международного сотрудничества и обмена терминологией созданы большие автоматические словари с разнообразной лексической информацией, банки терминологических данных по разным тематическим областям (например, словарь ЕВРОДИКАТОМ и ряд других словарей, тематика которых определялась тем обстоятельством, что практический машинный перевод чаще всего имеет дело с научными и техническими текстами). Результаты работ по МП способствовали началу и развитию исследований и разработок в области автоматизации информационного поиска, логического анализа естественно-языковых текстов, экспертных систем, способов представления знаний в вычислительных системах и т.д.
За рубежом эксплуатируется целый ряд систем машинного перевода. Наиболее известной из их числа является система SYSTRAN, разработанная и поддерживаемая компанией SYSTRAN Software Inc. и используемая службой машинного перевода при комиссии Европейского союза. Данная служба, объем переводов в которой составляет около 2,5 млн. страниц в год, использует систему SYSTRAN для перевода с английского на немецкий, французский, испанский, греческий и итальянский языки, а также с французского на английский, испанский и итальянский. В практической эксплуатации находится ряд практических систем исследовательского центра Гренобля (Франция), систему CULT (Гонконг, ныне КНР) и ряд других. На рынке коммерческого машинного перевода предлагаются системы таких фирм, как Logos Corp., Globalinc Inc., Toshiba Corp., CompuServe и др., в том числе и санкт-петербургская компания ПроМТ, выпустившая под названием PROMT 98 усовершенствованную версию популярной системы Stylus.
Проблематика машинного перевода находит свое отражение в регулярно проводимых международных конференциях по вычислительной лингвистике COLING, а также на международных конференциях по машинному переводу MT SUMMIT.
Эффективность работы современной системы МП в решающей степени зависит от ее удачной настройки на конкретный подъязык (или микроподъязык) естественного языка, на определенную лексику и ограниченный набор грамматических средств, характерных для текстов данной предметной области, а также на определенные типы документов. Учение о подъязыках с точки зрения машинного перевода было впервые сформулировано Н.Д.Андреевым (Ленинградский университет) в 1967, хотя представления о языковых регистрах, стилях, жанрах письменного текста и т.п. были хорошо известны и в традиционной лингвистике. Подъязык, с точки зрения МП, определяется в первую очередь некоторым исходным набором текстов, в рамках которого определяется входной и выходной словари, степень распространения и характер лексической неоднозначности лексем, характер и распространенность синтаксических конструкций, способы их перевода в данной языковой паре и пр. Большую роль играют параллельные тексты и словари-конкордансы, с помощью которых можно достаточно эффективно изучить и использовать в составлении алгоритмов лексическую сочетаемость и дистрибуцию (распределение) языковых элементов в речи (дискурсе, тексте). Статистические характеристики подъязыков помогают упорядочить структуру соответствующих алгоритмов анализа и синтеза. Выходной словарь, ориентированный на потребности синтеза и передачи основных видов соответствий в конкретной языковой паре, обеспечивает приемлемый выходной текст. В любом из современных видов машинного перевода необходимо участие человека-редактора, удобство работы которого обеспечивается качеством и надежностью соответствующего программного обеспечения.
Эта история представляет собой обзор области машинного перевода. В этой истории представлено несколько цитируемых литературы и известных приложений, но я хотел бы призвать вас поделиться своим мнением в комментариях. Цель этой истории - обеспечить хорошее начало для новичка в этой области. Он охватывает три основных подхода машинного перевода, а также несколько проблем в этой области. Надеемся, что литература, упомянутая в рассказе, представляет историю проблемы, а также современные решения.
Машинный перевод (MT) - это задача перевода текста с исходного языка на его аналог на целевом языке. Есть много сложных аспектов MT: 1) большое разнообразие языков, алфавитов и грамматик; 2) задача по переводу последовательности (например, предложения) в последовательность для компьютера сложнее, чем работа только с числами; 3) нетодинправильный ответ (например, перевод с языка без местоимений, зависящих от пола,она такжеонаможно так же).
Машинный перевод - относительно старая задача. С 1970-х годов были проекты для достижения автоматического перевода. За эти годы появились три основных подхода:
- Машинный перевод на основе правил (RBMT): 1970-е-1990-е годы
- Статистический машинный перевод (SMT): 1990-е-2010-е
- Нейронный машинный перевод (NMT): 2014-

Система, основанная на правилах, требует знаний экспертов об источнике и целевом языке для разработки синтаксических, семантических и морфологических правил для достижения перевода.
Статья в википедииRBMT включает базовый пример основанного на правилах перевода с английского на немецкий. Для перевода требуется англо-немецкий словарь, набор правил для грамматики английского языка и набор правил для грамматики немецкого языка
Система RBMT содержит набор задач обработки естественного языка (NLP), включая токенизацию, тегирование части речи и так далее. Большинство из этих работ должны быть выполнены как на исходном, так и на целевом языке.
Примеры RBMT
Apertiumявляется программным обеспечением RBMT с открытым исходным кодом, выпущенным на условиях GNU General Public License. Он доступен на 35 языках и находится в стадии разработки. Первоначально он был разработан для языков, тесно связанных с испанским [4]. Изображение ниже является иллюстрацией конвейера Apertium.

GramTransэто сотрудничество компании, базирующейся в Дании, и компании, базирующейся в Норвегии, которая предлагает машинный перевод для скандинавских языков [5].
преимущества
- Не требуется двуязычный текст
- Домен-независимый
- Тотальный контроль (возможное новое правило для любой ситуации)
- Возможность повторного использования (существующие правила языков могут быть перенесены в сочетании с новыми языками)
Недостатки
- Требуются хорошие словари
- Правила, установленные вручную (требуется экспертиза)
- Чем больше правил, тем сложнее иметь дело с системой
Этот подход использует статистические модели, основанные на анализе двуязычных текстовых корпусов. Впервые он был представлен в 1955 году [6], но заинтересовался только после 1988 года, когда его начал использовать исследовательский центр IBM Watson [7, 8].
Идея статистического MT заключается в следующем:
Учитывая предложение T на целевом языке, мы ищем предложение S, из которого переводчик произвел T. Мы знаем, что наш шанс ошибки минимизирован, выбрав это предложение S, которое наиболее вероятно для данного T. Таким образом, мы хотим выбрать S так, чтобы как максимизировать Pr (S | T).
-Статистический подход к машинному переводу, 1990. [8]
Используя теорему Байеса, мы можем преобразовать эту задачу максимизации в произведение Pr (S) и Pr (T | S), где Pr (S) - это вероятность модели языка S (S - правильное предложение в этом месте) и Pr (T | S) - это вероятность перевода T с учетом S. Другими словами, мы ищем наиболее вероятный перевод с учетом того, насколько точен перевод кандидата и насколько хорошо он вписывается в контекст.

Следовательно, SMT требует три шага: 1) Языковая модель (каково правильное слово с учетом его контекста?); 2) Модель перевода (каков наилучший перевод данного слова?); 3) способ найти правильный порядок слов.

Нефакторный и факторный перевод - Фигуры из Моисея: Набор инструментов с открытым исходным кодом… [9]
Примеры SMT
-
(между 2006 и 2016 годами, когдаони объявили перейти на NMT) (в 2016 годуизменено на NMT) : Набор инструментов с открытым исходным кодом для статистического машинного перевода. [9]
преимущества
- Меньше ручной работы от лингвистов
- Один SMT подходит для нескольких языковых пар
- Меньше перевода из словаря: при правильной языковой модели перевод более свободный
Недостатки
Нейронный подход использует нейронные сети для достижения машинного перевода. По сравнению с предыдущими моделями NMT могут быть построены с одной сетью вместо конвейера отдельных задач.
В 2014 году были введены модели от последовательности к последовательности, открывающие новые возможности для нейронных сетей в НЛП. До появления моделей seq2seq нейронным сетям требовался способ преобразования входных последовательностей в готовые к работе числа (горячее кодирование, вложения). Благодаря seq2seq стала возможной тренировка сети с входными и выходными последовательностями [10, 11].

NMT появился быстро. После нескольких лет исследований эти модели превзошли SMT [12]. Благодаря улучшенным результатам многие компании-поставщики переводчиков изменили свои сети на нейронные модели, включая Google [13] и Microsoft.
Проблема с нейронными сетями возникает, если данные обучения несбалансированы, модель не может учиться на редких и частых выборках. В случае языков это общая проблема, так как, например, во всей Википедии много редких слов, используемых всего несколько раз. Тренировать модель, которая не склонна к частым словам (например: многократные вхождения на каждой странице Википедии), может быть сложной задачей. В недавней статье предлагается решение с использованием шага постобработки для перевода этих редких слов в словарь [14].
Недавно исследователи Facebook представили модель MT без присмотра, работающую как с SMT, так и с NMT, для которой требуются только большие одноязычные корпуса, а не двуязычные [15]. Основным узким местом предыдущих примеров было отсутствие большой базы данных с переводами для обучения. Эта модель показывает обещание решить эту проблему.
Примеры NMT
- Google Translate (с 2016 года)ссылка на языковую группу в Google AI
- Microsoft Translate (с 2016 года)ссылка на исследование MT в Microsoft
- Перевод в Фейсбуке:ссылка на НЛП в Фейсбуке AI Система нейронного машинного перевода с открытым исходным кодом. [16]
преимущества
- Сквозные модели (без конвейера конкретных задач)
Недостатки
- Требуется двуязычный корпус
- Проблема редких слов

В этой истории мы рассмотрели три подхода к проблеме машинного перевода. Многие важные публикации собраны вместе с важными приложениями. История раскрыла историю области и собрала литературу о современных моделях. Я надеюсь, что это хорошее начало для новичка в этой области.
Если вы думаете, что чего-то не хватает, можете поделиться им со мной!
[1] Тома, П. (1977, май).Систран как многоязычная система машинного перевода.ВМатериалы Третьего Европейского Конгресса по информационным системам и сетям, преодоления языкового барьера(стр. 569–581).
[2] Crego, J., Kim, J., Klein, G., Rebollo, A., Yang, K., Senellart, J., . & Enoue, S. (2016).Чистые нейронные системы машинного перевода Systran.Препринт arXiv arXiv: 1610.05540,
[4] Корби Белло, А. М., Форкада, М. Л., Ортис Рохас, С., Перес-Ортис, Дж. А., Рамирес Санчес, Г., Санчес-Мартинес, Ф.,… и Сарасола Габиола, К. (2005).Механизм машинного перевода с открытым исходным кодом для романских языков Испании.
[5] Бик, Экхард (2007),Dan2eng: машинный перевод датско-английского широкого охватаВ: Бенте Maegaard (ред.),Труды саммита машинного перевода XI, 10–14. Сентябрь 2007 г., копенгаген, дания, С. 37–43
[6] Уивер В. (1955).Перевод,Машинный перевод языков,14, 15–23.
[7] Браун П., Кокк Дж., Пьетра С.Д., Пьетра В.Д., Елинек Ф., Мерсер Р. и Русин П. (август 1988 г.).Статистический подход к языковому переводу ВМатериалы 12-й конференции по компьютерной лингвистике, том 1(стр. 71–76). Ассоциация компьютерной лингвистики.
[8] Браун, П. Ф., Кокк, Дж., Делла Пьетра, С. А., Делла Пьетра, В. Дж., Елинек, Ф., Лафферти, Дж. Д., . & Roossin, P. S. (1990).Статистический подход к машинному переводу.Компьютерная лингвистика,16(2), 79–85.
[9] Koehn, P., Hoang, H., Birch, A., Callison-Burch, C., Federico, M., Bertoldi, N.,… & Dyer, C. (2007, июнь).Моисей: Набор инструментов с открытым исходным кодом для статистического машинного перевода.ВМатериалы 45-го ежегодного собрания ассоциации по компьютерной лингвистике, сопутствующие объемные материалы демонстрационной и стендовой сессий(стр. 177–180).
[10] Sutskever, I., Vinyals, О. & Le, Q. V. (2014).Последовательность к обучению последовательности с нейронными сетями, ВДостижения в нейронных системах обработки информации(стр. 3104–3112).
[11] Чо, К., Ван Мерриенбоер, Б., Гулцехре, С., Богданау, Д., Бугарес, Ф., Швенк, Х. и Бенжио, Ю. (2014).Изучение фраз с использованием кодера-декодера RNN для статистического машинного перевода.Препринт arXiv arXiv: 1406.1078,
[14] Луонг, М. Т., Сутскевер, И., Ле, В. В., Виньяльс, О. и Заремба, В. (2014).Решение проблемы редких слов в нейронном машинном переводе.Препринт arXiv arXiv: 1410.8206,

В этой публикации нашего цикла step-by-step статей мы объясним, как работает нейронный машинный перевод и сравним его с другими методами: технологией перевода на базе правил и технологией фреймового перевода (PBMT, наиболее популярным подмножеством которого является статистический машинный перевод — SMT).
Давайте начнем с того, что рассмотрим методы работы всех трех технологий на различных этапах процесса перевода, а также методы, которые используются в каждом из случаев. Далее мы познакомимся с некоторыми примерами и сравним, что каждая из технологий делает для того, чтобы выдать максимально правильный перевод.
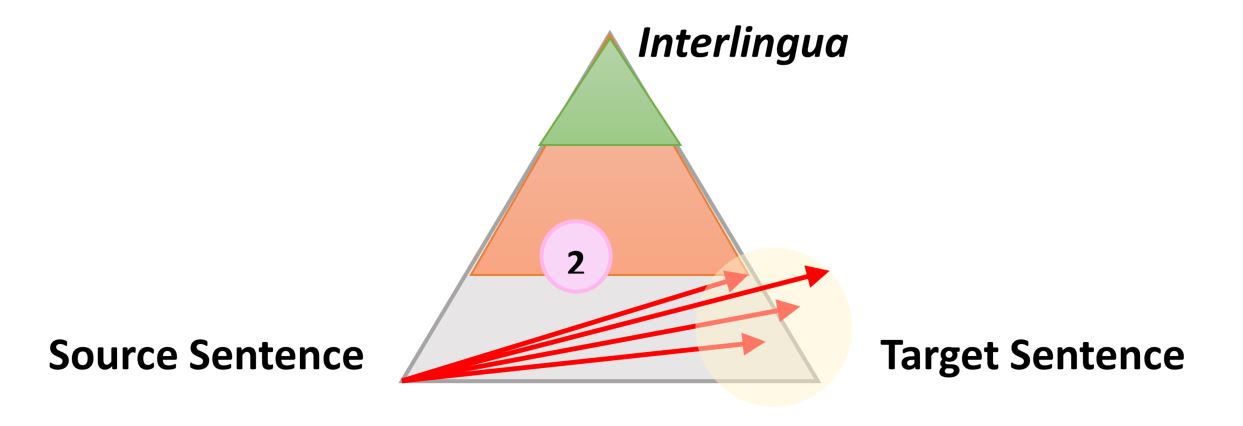
Очень простой, но все же полезной информацией о процессе любого типа автоматического перевода является следующий треугольник, который был сформулирован французским исследователем Бернардом Вокуа (Bernard Vauquois) в 1968 году:
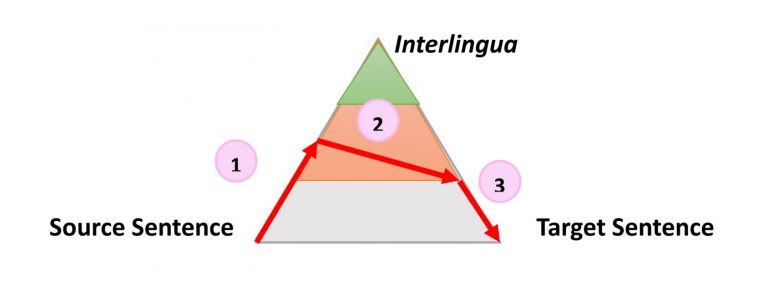
В этом треугольнике отображен процесс преобразования исходного предложения в целевое тремя разными путями.
Левая часть треугольника характеризует исходный язык, когда как правая — целевой. Разница в уровнях внутри треугольника представляет глубину процесса анализа исходного предложения, например синтаксического или семантического. Теперь мы знаем, что не можем отдельно проводить синтаксический или семантический анализ, но теория заключается в том, что мы можем углубиться на каждом из направлений. Первая красная стрелка обозначает анализ предложения на языке оригинала. Из данного нам предложения, которое является просто последовательностью слов, мы сможем получить представление о внутренней структуре и степени возможной глубины анализа.
Например, на одном уровне мы можем определить части речи каждого слова (существительное, глагол и т.д.), а на другом — взаимодействие между ними. Например, какое именно слово или фраза является подлежащим.
Машинный перевод на базе правил
Машинный перевод на базе правил является самым старым подходом и охватывает самые разные технологии. Однако, в основе всех их обычно лежат следующие постулаты:
- Процесс строго следует треугольнику Вокуа, анализ очень часто завышен, а процесс генерации сводится к минимальному;
- Все три этапа перевода используют базу данных правил и лексических элементов, на которые распространяются эти правила;
- Правила и лексические элементы заданы однозначно, но могут быть изменены лингвистом.
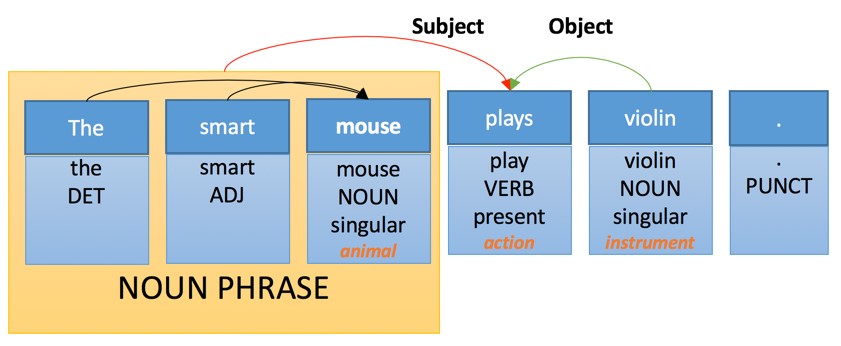
Тут мы видим несколько простых уровней анализа:

Применение этих правил приведет к следующей интерпретации на целевом языке перевода:
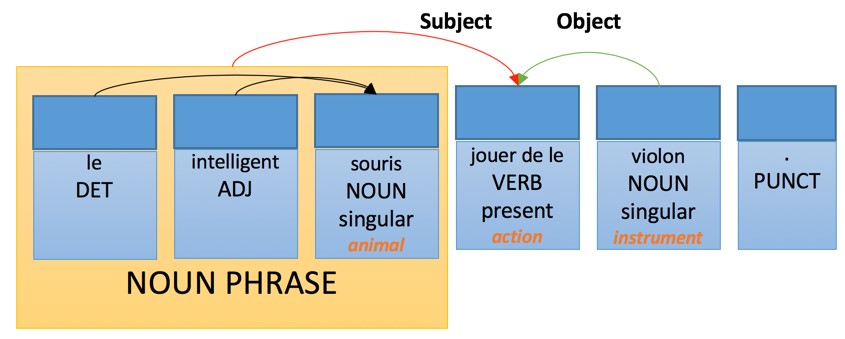
Тогда как правила генерации на французском будут иметь следующий вид:
- Прилагательное, выраженное словосочетанием, следует за существительным — с несколькими перечисленными исключениями.
- Определяющее слово согласованно по числу и роду с существительным, которое оно модифицирует.
- Прилагательное согласовано по числу и полу с существительным, которое оно модифицирует.
- Глагол согласован с подлежащим.
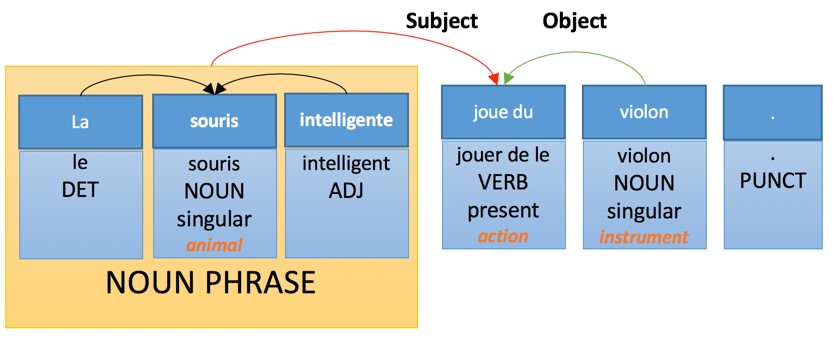
Машинный перевод на базе фраз
Выражаясь технически, машинный перевод на базе фраз не следует процессу, сформулированному Вокуа. Мало того, в процессе этого типа машинного перевода не проводится никакого анализа или генерации, но, что более важно, придаточная часть не является детерминированной. Это означает, что технология может генерировать несколько разных переводов одного и того же предложения из одного и того же источника, а суть подхода заключается в выборе наилучшего варианта.
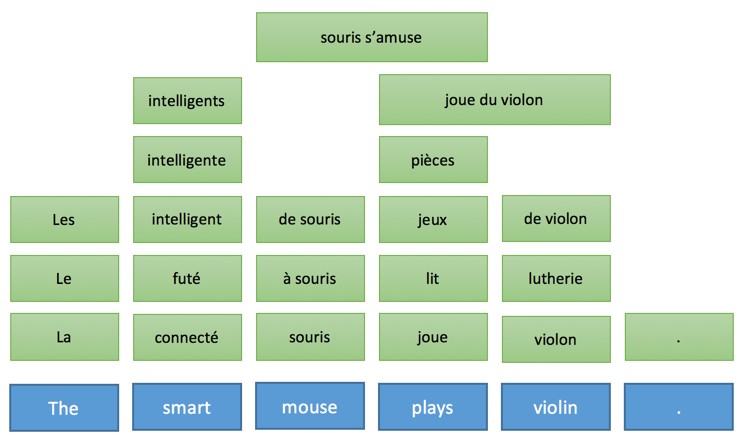
Эта модель перевода основана на трех базовых методах:
- Использование фразы-таблицы, которая дает варианты перевода и вероятность их употребления в этой последовательности на исходном языке.
- Таблица изменения порядка, которая указывает, как могут быть переставлены слова при переносе с исходного на целевой язык.
- Языковая модель, которая показывает вероятность для каждой возможной последовательности слов на целевом языке.
Далее из этой таблицы генерируются тысячи возможных вариантов перевода предложения, например:
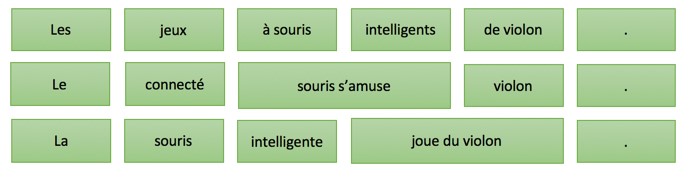
Однако благодаря интеллектуальным вычислениям вероятности и использованию более совершенных алгоритмов поиска, будет рассмотрен только наиболее вероятные варианты перевода, а лучший сохранится в качестве итогового.
В этом подходе целевая языковая модель крайне важна и мы можем получить представление о качестве результата, просто поискав в Интернете:

Поисковые алгоритмы интуитивно предпочитают использовать последовательности слов, которые являются наиболее вероятными переводами исходных с учетом таблицы изменения порядка. Это позволяет с высокой точностью генерировать правильную последовательность слов на целевом языке.
В этом подходе нет явного или неявного лингвистического или семантического анализа. Нам было предложено множество вариантов. Некоторые из них лучше, другие — хуже, но, на сколько нам известно, основные онлайн-сервисы перевода используют именно эту технологию.
Нейронный машинный перевод
Подход к организации нейронного машинного перевода кардинально отличается от предыдущего и, опираясь на треугольник Вокуа, его можно описать следующим образом:
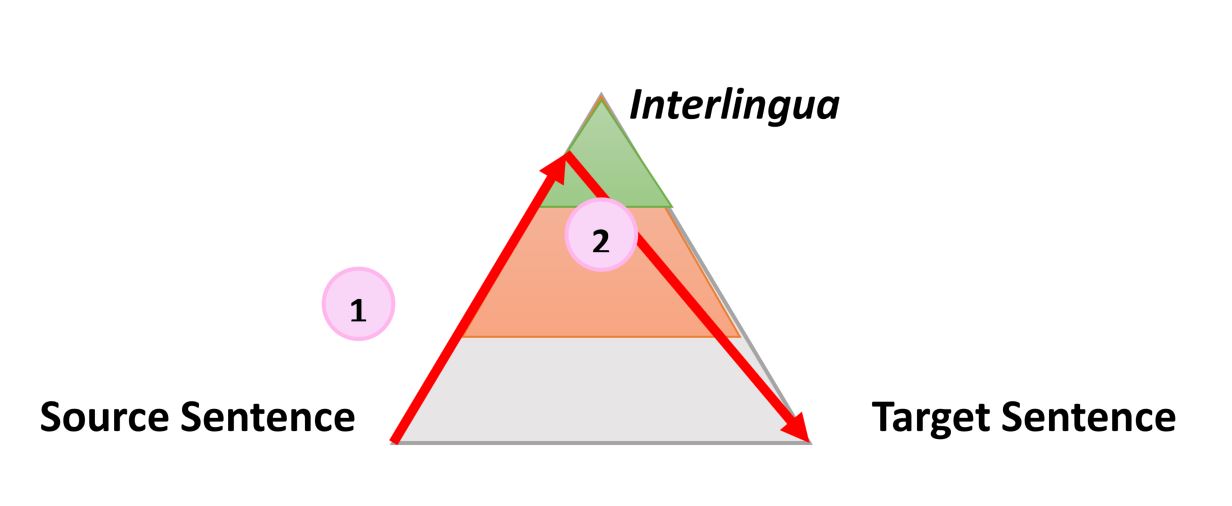
Нейронный машинный перевод имеет следующие особенности:
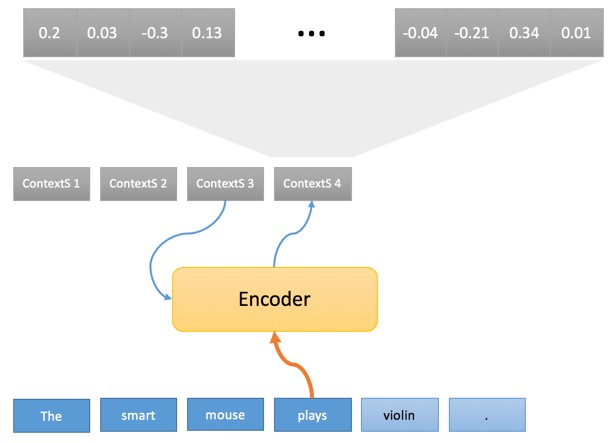
На самом деле это технический блок, как и в случае с основанной на правилах системой перевода, где каждое слово сначала сравнивается со словарем, первым шагом кодера является поиск каждого исходного слова внутри таблицы.
Предположим, что вам нужно вообразить разные объекты с вариациями по форме и цвету в двумерном пространстве. При этом объекты, находящиеся ближе всего друг к другу должны быть похожи. Ниже приведен пример:
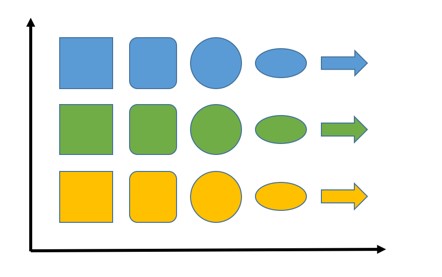
На оси абсцисс представлены фигуры и там мы стараемся поместить наиболее близкие по этому параметру объекты другой формы (нам нужно будет указать, что делает фигуры похожими, но в случае этого примера это кажется интуитивным). По оси ординат располагается цвет — зеленый между желтым и синим (расположено так, потому что зеленый является результатом смешения желтого и синего цветов, прим. пер.) Если бы у наших фигур были разные размеры, мы бы могли добавить этот третий параметр следующим образом:
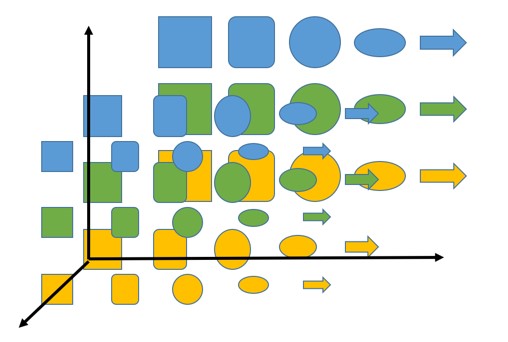
Если мы добавим больше цветов или фигур, мы также сможем увеличить и число измерений, чтобы любая точка могла представлять разные объекты и расстояние между ними, которое отражает степень их сходства.
Основная идея в том, что это работает и в случае размещения слов. Вместо фигур есть слова, пространство намного больше — например, мы используем 800 измерений, но идея заключается в том, что слова могут быть представлены в этих пространствах с теми же свойствами, что и фигуры.
Следовательно, слова, обладающие общими свойствами и признаками будут расположены близко друг к другу. Например, можно представить, что слова определенной части речи — это одно измерение, слова по признаку пола (если таковой имеется) — другое, может быть признак положительности или отрицательности значения и так далее.
Мы точно не знаем, как формируются эти вложения. В другой статье мы будем более подробно анализировать вложения, но сама идея также проста, как и организация фигур в пространстве.
Вернемся к процессу перевода. Второй шаг имеет следующий вид:
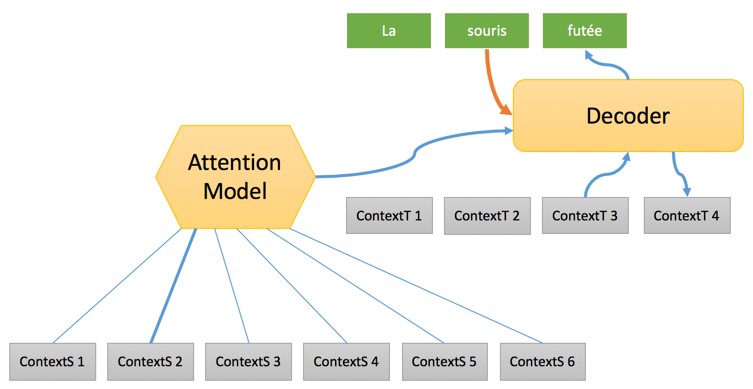
Весь процесс, несомненно, весьма загадочен и нам потребуется несколько публикаций, чтобы рассмотреть работу его отдельных частей. Главное, о чем следует помнить — это то, что операции процесса нейронного машинного перевода выстроены в той же последовательности, что и в случае машинного перевода на базе правил, однако характер операций и обработка объектов полностью отличается. И начинаются эти отличия с преобразования слов в векторы через их вложение в таблицы. Понимания этого момента достаточно для того, чтобы осознать, что происходит в следующих примерах.
Примеры перевода для сравнения
Давайте разберем некоторые примеры перевода и обсудим, как и почему некоторые из предложенных вариантов не работают в случае разных технологий. Мы выбрали несколько полисемических (т.е. многозначных, прим. пер.) глаголов английского языка и изучим их перевод на французский.

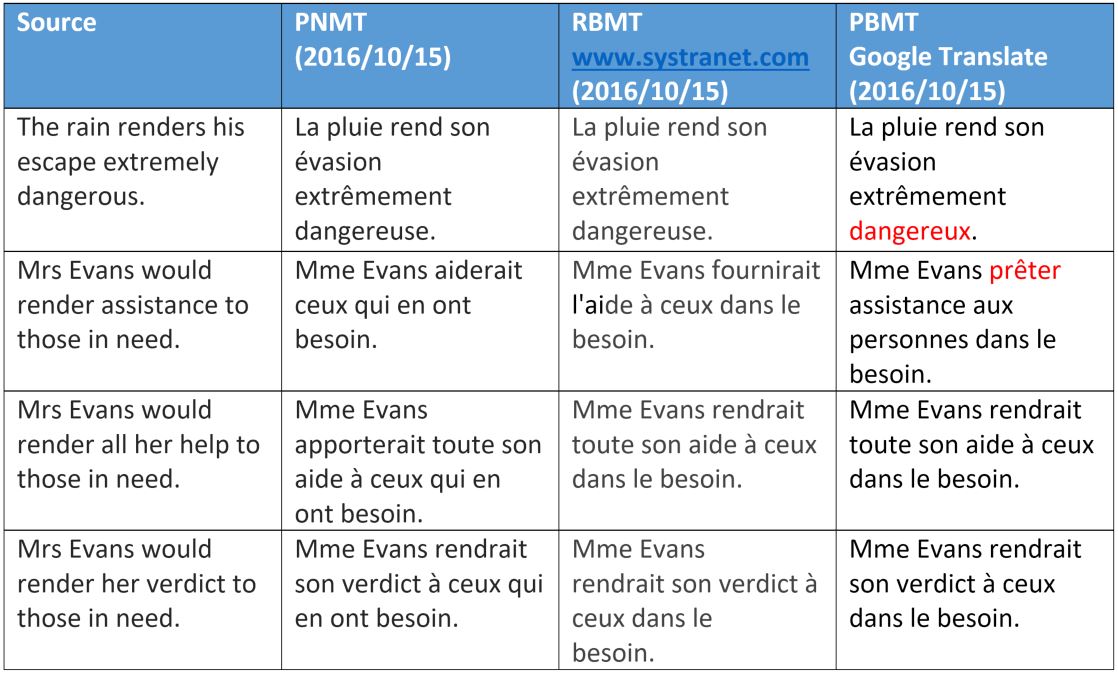

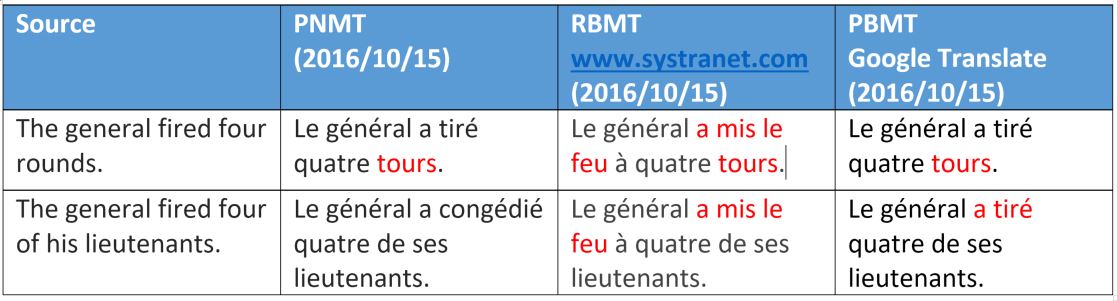
На этом примере опять видно, что нейронный машинный перевод имеет семантические различия с двумя другими способами (в основном они касаются одушевленности, обозначает слово человека или нет).

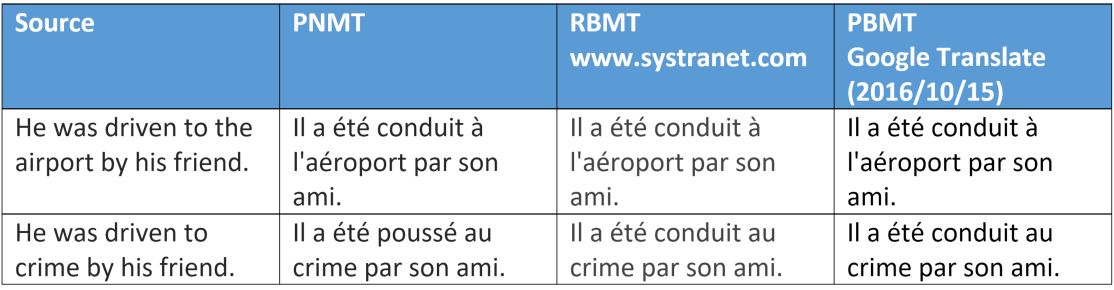
Выше еще один интересный пример того, как смысловые вариации глагола в ходе нейронного перевода взаимодействуют с объектом в случае однозначного употребления предлагаемого к переводу слова (crime или destination).
Переводчики работающие на базе слов и фраз так же не ошиблись, так как использовали те же глаголы, приемлемые в обоих контекстах.
Читайте также: