
Работа с элементарными базами данных кратко
Обновлено: 06.07.2024
База данных (БД) – это упорядоченная совокупность данных о конкретном объекте, хранящаяся во внешней памяти и организованная определенным способом. Либо можно сказать, что это организованная совокупность данных, предназначенная для длительного хранения во внешней памяти ЭВМ и постоянного применения. Различают несколько моделей (схем) БД. Как правило, СУБД входит в понятие баз данных как элемент сложной иерархической системы. Различают иерархические, реляционные, сетевые БД, распределенные и централизованные БД и т.д.
- по характеру хранимой информации: фактографические и документальные;
- по способу хранения данных: централизованные и распределенные;
- по структуре организации данных: реляционные (табличные БД), иерархические, сетевые БД.
Основное назначение БД хранение больших массивов данных, которыми можно манипулировать, используя встроенные возможности программной среды, такие как, редактирование данных, выборку данных по условию, созданию отчетов различной формы. База данных может быть отображена на экране в виде таблицы и в виде картотеки, вне зависимости от вида используемого формата.
Большинство баз данных используют в качестве основной информационной структуры табличный формат. Реляционная база данных представляет собой множество взаимосвязанных таблиц, каждая из которых содержит информацию об объектах определенного типа. Таблица имеет строки и столбцы, которые соответственно называются записью и полем записи. Именно поля определяют структуру базы.
Поля – это различные характеристики (иногда говорят – атрибуты) объекта.
Например: рассмотрим объект мебель. Основными свойствами объекта интересными для потребителя будут являться вид мебели, назначение, производитель, из чего выполнено изделие. Выделенные атрибуты и будут служить полями создаваемой базы. Каждое поле записи содержит одну характеристику объекта и имеет строго определенный тип данных (например, текстовая строка, число, дата и т.п.). Все записи имеют одни и те же поля, только в них содержаться разные значения атрибутов.
Обращение к базе данных и управление БД осуществляется с помощью Системы Управления Базой Данных (СУБД). Основные функции СУБД – это определение данных (описание структуры данных), обработка данных и управление данными.
- Интерфейс – среда пользователя для работы при помощи меню.
- Интерпретатор – алгоритмический язык программирования.
- Компилятор – преобразователь программ в автономные исполняемые файлы.
- Утилиты – средства программирования рутинных операций.
- добавлять в таблицу одну или несколько записей;
- удалять из таблицы одну или несколько записей;
- обновлять значения нескольких полей в одной или нескольких записях;
- находить одну или несколько записей, удовлетворяющих заданному условию.
Для выполнения этих операций используется механизм запросов. Результатом выполнения запросов является либо отобранное по определенным критериям множество записей, либо изменения в таблицах. Запросы к базе формируются на специально созданном языке. И самая важная функция СУБД – это управление данными. Под управлением данными обычно понимают защиту данных от несанкционированного доступа, поддержку многопользовательского режима работы с данными и обеспечение целостности и согласованности данных.
- проектирование базы данных (определение объекта и выделение атрибутов объекта в качестве полей базы данных);
- задание структуры базы данных (однотабличная БД или состоящая из нескольких связанных таблиц);
- ввод структуры данных с описанием типов данных вводимых в поля таблицы;
- непосредственный ввод данных в БД;
- редактирование данных;
- манипулирование данными (сортировка, выборка данных с использованием фильтрации и/или запросов).
Типы данных MS Access
| Тип данных | Использование |
| Текстовый | Алфавитно-цифровые данные (до 255 символов) |
| Memo | Алфавитно-цифровые данные – приложения, абзацы, текст (до 64 000 символов) |
| Числовой | Различные числовые данные (имеет несколько форматов: целое, длинное целое, с плавающей точкой) |
| Дата \ Время | Дата и время в одном из предлагаемых Access форматов |
| Денежный | Денежные суммы, хранящиеся с 8 знаками в десятичной части. В целой части каждые три разряда разделяются запятой. |
| Счетчик | Уникальное длинное целое, создаваемое Access для каждой новой записи |
| Логические | Логические данные, имеющие значения Истина или Ложь |
| Объект OLE | Картинки, диаграммы и другие объекты OLE из приложений Windows |
| Гиперссылка | В полях этого типа хранятся гиперссылки, которые представляют собой путь к файлу на жестком диске, либо адрес в сетях Internet или Intranet. |
Опишем сказанное на примере объекта “Страны Европы”. Важным для описания является название страны, её столица, площадь, население, языки, карта (флаг). Теперь подумаем, какие типы данных будут использованы.
| Имена полей | Типы данных |
| Страна | Текстовый |
| Столица | Текстовый |
| Площадь | Числовой |
| Население | Числовой |
| Языки | Memo |
| Карта | Объект OLE |
Структура базы данных будет такова:
Практическое задание
Заполнить созданную таблицу соответствующими данными (к уроку заранее подготовить документ, содержащий необходимые данные по каждой стране и папку с рисунками – картами каждой страны). Если нет карты страны, то можно заменить флагом или значимым символом страны.
- описывать структуры данных в конфигураторе,
- манипулировать данными с помощью объектов встроенного языка,
- составлять запросы к данным, используя язык запросов.
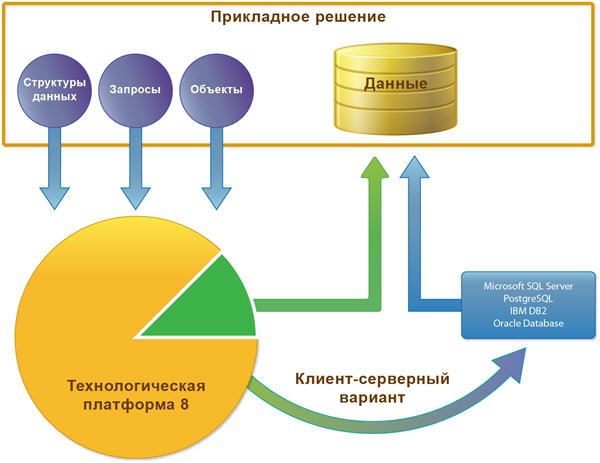
Общая система типов
Хранение ссылок на объекты
Характерной особенностью объектного манипулирования данными является то, что на каждый объект, как совокупность данных, существует уникальная ссылка, позволяющая однозначно идентифицировать этот объект в базе данных.
Эта ссылка также хранится в поле базы данных, вместе с остальными данными объекта. Кроме того, ссылка может быть использована как значение какого-либо поля другого объекта. Например, ссылка на объект справочника Контрагенты может быть использована как значение соответствующего реквизита документа Приходная накладная.
Составные типы

Такая возможность очень важна для экономических задач — например, в расходной накладной в качестве покупателя может быть указано либо юридическое лицо из справочника организаций, либо физическое лицо из справочника частных лиц. Соответственно, при проектировании базы данных разработчик может определить поле, которое будет хранить значение любого из этих типов.
Хранение любых данных как Хранилище значения
Для этого введен специальный тип данных — ХранилищеЗначения. Поля базы данных могут хранить значения такого типа, а встроенный язык содержит специальный одноименный объект, позволяющий преобразовывать значения других типов к специальному формату Хранилища значений.
Благодаря этому разработчик имеет возможность сохранять в базе данных значения, тип которых не может быть выбран в качестве типа поля базы данных, например, графические изображения.
Создание и обновление структур данных на основе метаданных
В процессе создания или модификации прикладного решения разработчик избавлен от необходимости каких-либо действий по непосредственному изменению структуры полей базы данных прикладного решения.
Разработчику достаточно путем визуального конструирования описать структуру используемых объектов прикладного решения, состав их реквизитов, табличных частей, форм и пр.
Все действия по созданию или изменению структуры таблиц базы данных платформа выполнит самостоятельно, на основании состава объектов прикладного решения и их характеристик.
Все, что требуется сделать разработчику — щелчком мыши добавить к справочнику табличную часть и задать два ее строковых реквизита: Имя и Родство. При сохранении или обновлении конфигурации платформа самостоятельно выполнит реорганизацию структуры базы данных, создаст необходимые таблицы и т.д.
Объектный / табличный доступ к данным
В объектной модели разработчик оперирует объектами встроенного языка. В этой модели обращения к объекту, например документу, происходят как к единому целому — он полностью загружается в память, вместе с вложенными таблицами, к которым можно обращаться средствами встроенного языка как к коллекциям записей и т.д.
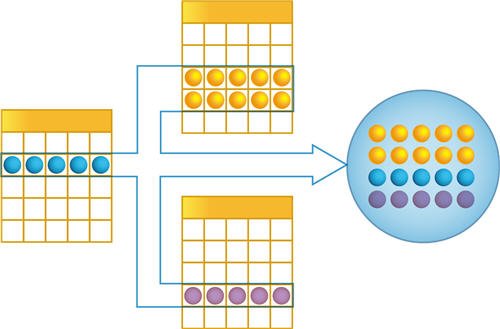
При манипулировании данными в объектной модели обеспечивается сохранение целостности объектов, кэширование объектов, вызов соответствующих обработчиков событий и т.д.
В табличной модели все множество объектов того или иного класса представляется как совокупность связанных между собой таблиц, к которым можно обращаться при помощи запросов — как к отдельной таблице, так и к нескольким таблицам во взаимосвязи:
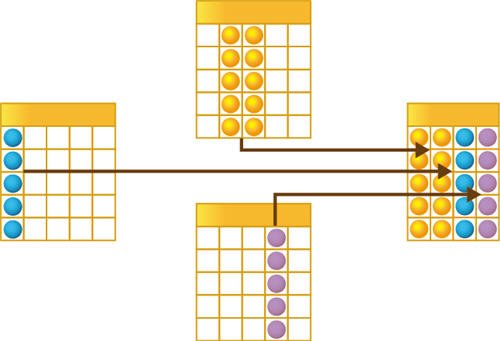
В этом случае разработчик получает доступ к данным сразу нескольких объектов, что очень удобно для анализа больших объемов данных, например, при создании отчетов. Однако в силу того, что данные, выбираемые таким способом, содержат не все, а лишь некоторые реквизиты анализируемых объектов, табличный способ доступа не позволяет изменять эти данные.
SQL – это язык структурированных запросов. СУРБД – система управления реляционными базами данных. Существуют следующие разновидности баз данных:
- Система управления файлами
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
- Гибридные
1) Иерархические – первые базы данных. Иерархическая база данных основана на древовидной структуре хранения информации и напоминает файловую систему компьютера. С точки зрения организации хранения информации, иерархическая база данных состоит из упорядоченного набора деревьев одного типа – каждая
запись в базе данных реализована в виде отношений предок-потомок. Основной недостаток иерархической структуры базы данных –невозможность реализовать отношения многие ко многим. Иерархические базы данных наиболее пригодны для моделирования структур, являющихся иерархическими по своей природе. Иерархия подразумевает только одного родителя.
2) Сетевые базы данных – являются расширением иерархических баз данных. Иерархические базы данных из-за большого количества недостатков просуществовали недолго и были заменены на сетевые базы данных.Сетевые базы данных представляют собой организацию данных в виде железнодорожных путей, где каждая крупная станция имеет связи с несколькими другими станциями. В сетевых базах данных имеется связь многие ко многим. Недостатком сетевых баз данных является сложность разработки больших приложений.
3) Реляционные базы данных – произвели настоящий прорыв в развитии теории баз данных. Основная задача реляционной модели была упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении
которых расположены данные.Особенности реляционной базы данных:
- Данные хранятся в таблицах, состоящих из столбцов и строк
- На пересечении каждого столбца и строки находится только одно значение
- У каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип.
- Столбцы располагаются в определенном порядке, который задается при создании таблицы, в отличие от строк, которые располагаются в произвольном порядке.
- В таблице может не быть ни одной строчки, но должен быть хотя бы один столбец.
- Запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов.
Первичные ключи
Строки в реляционной базе данных неупорядоченные. Для выбора в таблице конкретной строки создается один или несколько столбцов, значения которых во всех строках уникальны. Такой столбец называется первичным ключом.
Первичный ключ (primary key) – является уникальным значением в столбце. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).
Логический ключ – представляет собой значение, определяющее запись естественным образом.
Суррогатный ключ – представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
Нормализация базы данных
Нормализацией схемы базы данных – называется процедура, производимая над базой данных с целью удаления в ней избыточности.
Централизованная архитектура
При централизованной архитектуре и приложение, СУБД и база данных размещаются на одном центральном мэйнфрейме – базовой универсальной вычислительной машине. Пользователи подключаются к нему посредством терминалов. Терминал представлял собой клавиатуру, монитор и сетевую карту, посредством которой происходит обмен данных терминала с мэйнфреймом. Роль приложения состоит в принятии вводимых данных с пользовательского терминала по сети и передаче их на обработку СУБД с последующей передачей полученного от СУБД ответа на монитор терминала.
Архитектура клиент-сервер
В клиент-серверной архитектуре персональные компьютеры объединены в локальную сеть, в этой же сети находится и сервер баз данных, на котором содержатся общие для всех клиентом базы данные и СУБД. Вычислительные возможности сервера полностью сосредоточены на обслуживании СУБД.
Трехуровневая архитектура интернета
Трехуровневая модель позволяет отделить клиентское программное обеспечение от серверной части, а на серверной стороне отделить веб-сервер от сервера базы данных.
Несколько серверов, работающих над одной и той же задачей, функционируют надежнее и обходятся дешевле, чем один сервер высокой производительности.
Кластерная модель
Кластеры часто называют дешевыми супер ЭВМ. Ряд маломощных машин объединяют в локальную сеть. Специальное программное обеспечение распределяет вычисления между отдельными хостами сети. Выход из строя одного из хостов никак не отражается на работе все сети, а сам кластер легко расширяется за счет ввода дополнительных машин.
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Индексы
Индексы – основной способ ускорения работы баз данных. Чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит большое количество времени.
Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет очень быстро осуществлять поиск по такому столбцу, так, как заранее известно, где необходимо искать значение.
Добавление или удаление записи требует дополнительного времени на сортировку столбца, кроме того, создание копии увеличивает объем памяти, необходимый для размещения таблицы на жестком диске.
Существует несколько видов индексов:
- Первичный ключ – главный индекс таблицы. В таблице может быть только один первичный ключ, и все значения такого индекса должны отличаться друг от друга, являться уникальными в пределах одного столбца.
- Обычный индекс – таких индексов может быть несколько.
- Уникальный индекс – уникальных индексов также может быть несколько, на значения индекса не должны повторяться.
- Полнотекстовый индекс – специальный вид индекса для столбцов типа TEXT, позволяющий производить полнотекстовый поиск.
Типы и структура таблиц
СУБД MySQL поддерживает несколько видов таблиц, каждая из которых имеет свои возможности и ограничения.
MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
MERGE
Тип таблиц MERGE позволяет сгруппировать несколько таблиц типа MyISAM в одну. Такой тип таблиц применяется для снятия ограничения на объем таблиц MyISAM. Таблицы MyISAM, которые подвергаются объединению в одну таблицу MERGE, должны иметь одинаковую структуру, то есть, одинаковые столбцы и индексы, а также порядок их следования.
При создании таблицы типа MERGE будут образованы файлы структуры таблицы с расширением frm и файлы с расширением mrg. Файл mrgсодержит список индексных файлов, работа с которыми должна осуществляться как с единым файлом.
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
-
Индексы используются только в операциях сравнения совместимо с операторами = и , с другими операторами, такими как > или 2017-12-03 Программирование
Автор

Программист с образованием в области IT и опытом разработки на разных языках. Автор статей по программированию. Общий опыт работы в сфере IT и интернета более 5 лет.
ИНФОРМАТИКА- НАУКА, ИЗУЧАЮЩАЯ СПОСОБЫ АВТОМАТИЗИРОВАННОГО СОЗДАНИЯ, ХРАНЕНИЯ, ОБРАБОТКИ, ИСПОЛЬЗОВАНИЯ, ПЕРЕДАЧИ И ЗАЩИТЫ ИНФОРМАЦИИ.
ИНФОРМАЦИЯ – ЭТО НАБОР СИМВОЛОВ, ГРАФИЧЕСКИХ ОБРАЗОВ ИЛИ ЗВУКОВЫХ СИГНАЛОВ, НЕСУЩИХ ОПРЕДЕЛЕННУЮ СМЫСЛОВУЮ НАГРУЗКУ.
ЭЛЕКТРОННО-ВЫЧИСЛИТЕЛЬНАЯ МАШИНА (ЭВМ) ИЛИ КОМПЬЮТЕР (англ. computer- -вычислитель)-УСТРОЙСТВО ДЛЯ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИИ. Принципиальное отличие использования ЭВМ от всех других способов обработки информации заключается в способности выполнения определенных операций без непосредственного участия человека, но по заранее составленной им программе. Информация в современном мире приравнивается по своему значению для развития общества или страны к важнейшим ресурсам наряду с сырьем и энергией. Еще в 1971 году президент Академии наук США Ф.Хандлер говорил: "Наша экономика основана не на естественных ресурсах, а на умах и применении научного знания".
В развитых странах большинство работающих заняты не в сфере производства, а в той или иной степени занимаются обработкой информации. Поэтому философы называют нашу эпоху постиндустриальной. В 1983 году американский сенатор Г.Харт охарактеризовал этот процесс так: "Мы переходим от экономики, основанной на тяжелой промышленности, к экономике, которая все больше ориентируется на информацию, новейшую технику и технологию, средства связи и услуги.."
2. КРАТКАЯ ИСТОРИЯ РАЗВИТИЯ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ.
Вся история развития человеческого общества связана с накоплением и обменом информацией (наскальная живопись, письменность, библиотеки, почта, телефон, радио, счеты и механические арифмометры и др.). Коренной перелом в области технологии обработки информации начался после второй мировой войны.
В вычислительных машинах первого поколения основными элементами были электронные лампы. Эти машины занимали громадные залы, весили сотни тонн и расходовали сотни киловатт электроэнергии. Их быстродействие и надежность были низкими, а стоимость достигала 500-700 тысяч долларов.
Появление более мощных и дешевых ЭВМ второго поколения стало возможным благодаря изобретению в 1948 году полупроводниковых устройств- транзисторов. Главный недостаток машин первого и второго поколений заключался в том, что они собирались из большого числа компонент, соединяемых между собой. Точки соединения (пайки) являются самыми ненадежными местами в электронной технике, поэтому эти ЭВМ часто выходили из строя.
В ЭВМ третьего поколения (с середины 60-х годов ХХ века) стали использоваться интегральные микросхемы (чипы)- устройства, содержащие в себе тысячи транзисторов и других элементов, но изготовляемые как единое целое, без сварных или паяных соединений этих элементов между собой. Это привело не только к резкому увеличению надежности ЭВМ, но и к снижению размеров, энергопотребления и стоимости (до 50 тысяч долларов).
История ЭВМ четвертого поколения началась в 1970 году, когда ранее никому не известная американская фирма INTEL создала большую интегральную схему (БИС), содержащую в себе практически всю основную электронику компьютера. Цена одной такой схемы (микропроцессора) составляла всего несколько десятков долларов, что в итоге и привело к снижению цен на ЭВМ до уровня доступных широкому кругу пользователей.
СОВРЕМЕННЫЕ КОМПЬТЕРЫ- ЭТО ЭВМ ЧЕТВЕРТОГО ПОКОЛЕНИЯ, В КОТОРЫХ ИСПОЛЬЗУЮТСЯ БОЛЬШИЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ.
90-ые годы ХХ-го века ознаменовались бурным развитием компьютерных сетей, охватывающих весь мир. Именно к началу 90-ых количество подключенных к ним компьютеров достигло такого большого значения, что объем ресурсов доступных пользователям сетей привел к переходу ЭВМ в новое качество. Компьютеры стали инструментом для принципиально нового способа общения людей через сети, обеспечивающего практически неограниченный доступ к информации, находящейся на огромном множестве компьюторов во всем мире - "глобальной информационной среде обитания".
6.ПРЕДСТАВЛЕНИЕ ИНФОРМАЦИИ В КОМПЬЮТЕРЕ И ЕЕ ОБЪЕМ.
ЭТО СВЯЗАНО С ТЕМ, ЧТО ИНФОРМАЦИЮ, ПРЕДСТАВЛЕННУЮ В ТАКОМ ВИДЕ, ЛЕГКО ТЕХНИЧЕСКИ СМОДЕЛИРОВАТЬ, НАПРИМЕР, В ВИДЕ ЭЛЕКТРИЧЕСКИХ СИГНАЛОВ. Если в какой-то момент времени по проводнику идет ток, то по нему передается единица, если тока нет- ноль. Аналогично, если направление магнитного поля на каком-то участке поверхности магнитного диска одно- на этом участке записан ноль, другое- единица. Если определенный участок поверхности оптического диска отражает лазерный луч- на нем записан ноль, не отражает- единица.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО ИЗ ДВУХ СИМВОЛОВ-0 ИЛИ 1, НАЗЫВАЕТСЯ 1 БИТ (англ. binary digit- двоичная единица). 1 бит- минимально возможный объем информации. Он соответствует промежутку времени, в течение которого по проводнику передается или не передается электрический сигнал, участку поверхности магнитного диска, частицы которого намагничены в том или другом направлении, участку поверхности оптического диска, который отражает или не отражает лазерный луч, одному триггеру, находящемуся в одном из двух возможных состояний.
Итак, если у нас есть один бит, то с его помощью мы можем закодировать один из двух символов- либо 0, либо 1.
Если же есть 2 бита, то из них можно составить один из четырех вариантов кодов: 00 , 01 , 10 , 11 .
Если есть 3 бита- один из восьми: 000 , 001 , 010 , 100 , 110 , 101 , 011 , 111 .
1 бит- 2 варианта,
2 бита- 4 варианта,
3 бита- 8 вариантов;
Продолжая дальше, получим:
4 бита- 16 вариантов,
5 бит- 32 варианта,
6 бит- 64 варианта,
7 бит- 128 вариантов,
8 бит- 256 вариантов,
9 бит- 512 вариантов,
10 бит- 1024 варианта,
N бит - 2 в степени N вариантов.
В обычной жизни нам достаточно 150-160 стандартных символов (больших и маленьких русских и латинских букв, цифр, знаков препинания, арифметических действий и т.п.). Если каждому из них будет соответствовать свой код из нулей и единиц, то 7 бит для этого будет недостаточно (7 бит позволят закодировать только 128 различных символов), поэтому используют 8 бит.
ДЛЯ КОДИРОВАНИЯ ОДНОГО ПРИВЫЧНОГО ЧЕЛОВЕКУ СИМВОЛА В КОМПЬЮТЕРЕ ИСПОЛЬЗУЕТСЯ 8 БИТ, ЧТО ПОЗВОЛЯЕТ ЗАКОДИРОВАТЬ 256 РАЗЛИЧНЫХ СИМВОЛОВ.
СТАНДАРТНЫЙ НАБОР ИЗ 256 СИМВОЛОВ НАЗЫВАЕТСЯ ASCII ( произносится "аски", означает "Американский Стандартный Код для Обмена Информацией"- англ. American Standart Code for Information Interchange).
ОН ВКЛЮЧАЕТ В СЕБЯ БОЛЬШИЕ И МАЛЕНЬКИЕ РУССКИЕ И ЛАТИНСКИЕ БУКВЫ, ЦИФРЫ, ЗНАКИ ПРЕПИНАНИЯ И АРИФМЕТИЧЕСКИХ ДЕЙСТВИЙ И Т.П.
A - 01000001, B - 01000010, C - 01000011, D - 01000100, и т.д.
Таким образом, если человек создает текстовый файл и записывает его на диск, то на самом деле каждый введенный человеком символ хранится в памяти компьютера в виде набора из восьми нулей и единиц. При выводе этого текста на экран или на бумагу специальные схемы - знакогенераторы видеоадаптера (устройства, управляющего работой дисплея) или принтера образуют в соответствии с этими кодами изображения соответствующих символов.
Набор ASCII был разработан в США Американским Национальным Институтом Стандартов (ANSI), но может быть использован и в других странах, поскольку вторая половина из 256 стандартных символов, т.е. 128 символов, могут быть с помощью специальных программ заменены на другие, в частности на символы национального алфавита, в нашем случае - буквы кириллицы. Поэтому, например, передавать по электронной почте за границу тексты, содержащие русские буквы, бессмысленно. В англоязычных странах на экране дисплея вместо русской буквы Ь будет высвечиваться символ английского фунта стерлинга, вместо буквы р - греческая буква альфа, вместо буквы л - одна вторая и т.д.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО СИМВОЛА ASCII НАЗЫВАЕТСЯ 1 БАЙТ.
Очевидно что, поскольку под один стандартный ASCII-символ отводится 8 бит,
Остальные единицы объема информации являются производными от байта:
1 КИЛОБАЙТ = 1024 БАЙТА И СООТВЕТСТВУЕТ ПРИМЕРНО ПОЛОВИНЕ СТРАНИЦЫ ТЕКСТА,
1 МЕГАБАЙТ = 1024 КИЛОБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 500 СТРАНИЦАМ ТЕКСТА,
1 ГИГАБАЙТ = 1024 МЕГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ,
1 ТЕРАБАЙТ = 1024 ГИГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2000 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ.
Обратите внимание, что в информатике смысл приставок кило- , мега- и других в общепринятом смысле выполняется не точно, а приближенно, поскольку соответствует увеличению не в 1000, а в 1024 раза.
СКОРОСТЬ ПЕРЕДАЧИ ИНФОРМАЦИИ ПО ЛИНИЯМ СВЯЗИ ИЗМЕРЯЕТСЯ В БОДАХ.
1 БОД = 1 БИТ/СЕК.
В частности, если говорят, что пропускная способность какого-то устройства составляет 28 Килобод, то это значит, что с его помощью можно передать по линии связи около 28 тысяч нулей и единиц за одну секунду.
7. СЖАТИЕ ИНФОРМАЦИИ НА ДИСКЕ
ИНФОРМАЦИЮ НА ДИСКЕ МОЖНО ОБРАБОТАТЬ С ПОМОЩЬЮ СПЕЦИАЛЬНЫХ ПРОГРАММ ТАКИМ ОБРАЗОМ, ЧТОБЫ ОНА ЗАНИМАЛА МЕНЬШИЙ ОБЪЕМ.
Существуют различные методы сжатия информации. Некоторые из них ориентированы на сжатие текстовых файлов, другие - графических, и т.д. Однако во всех них используется общая идея, заключающаяся в замене повторяющихся последовательностей бит более короткими кодами. Например, в романе Л.Н.Толстого "Война и мир" несколько миллионов слов, но большинство из них повторяется не один раз, а некоторые- до нескольких тысяч раз. Если все слова пронумеровать, текст можно хранить в виде последовательности чисел - по одному на слово, причем если повторяются слова, то повторяются и числа. Поэтому, такой текст (особенно очень большой, поскольку в нем чаще будут повторяться одни и те же слова) будет занимать меньше места.
Сжатие информации используют, если объем носителя информации недостаточен для хранения требуемого объема информации или информацию надо послать по электронной почте
Программы, используемые при сжатии отдельных файлов называются архиваторами. Эти программы часто позволяют достичь степени сжатия информации в несколько раз.
Работу с базами данных SQL, как структурированный язык запросов, выполняет практически идеально. Более того, он считается основным инструментом для взаимодействия с реляционными БД, позволяющим проводить с ними самые разные манипуляции.
И пусть возраст SQL насчитывает уже несколько десятилетий, он до сих пор используется весьма широко. Создать без него нечто серьезное весьма затруднительно.
Особенности языка SQL
SQL является непроцедурным языком программирования, предназначенным в первую очередь для описания данных, их выборки из реляционных БД и последующей обработки. Таким образом, SQL оперирует исключительно базами данных, и использовать только его для создания полноценного приложения нельзя.
В этом случае потребуются инструменты других языков, поддерживающих встраивание SQL-команд. Именно по причине своей специфичности SQL считают вспомогательным средством, позволяющим обрабатывать данные. Этот язык на практике используется только совместно с другими языками.

Особенности языка SQL
В общем случае прикладные средства программирования подразумевают создание процедур. SQL такими возможностями не обладает. Здесь нельзя указать способы решения задач — задается лишь смысл каждой конкретной задачи. Иначе говоря, в работе с базами данных SQL важны результаты, а не процедуры, приводящие к этим результатам.
Этот специфический язык программирования обладает одним важным свойством — возможностью доступа к реляционным базам данных. Иногда все реляционные БД ошибочно приравниваются к СУБД с применением средств SQL. На самом деле эти понятия следует различать.
Понятие реляционной СУБД
Не углубляясь в детали, можно дать такое определение: реляционной называется СУБД, использующая реляционную модель управления.
Доктор Е. Ф. Кодд в 1970 году опубликовал свою работу, где впервые было дано понятие реляционной модели. В публикации описывался некий математический аппарат, структурирующий данные и оперирующий ими. Основная идея состояла в представлении любых данных в виде абстрактной модели.
В соответствии с предложенной концепцией отношение между объектами (relation) представляет собой некую таблицу с данными. При этом существуют атрибуты (или признаки) отношения, которые соответствуют столбцам рассматриваемой таблицы. Сами данные предстают в виде наборов этих признаков и формируют записи (кортежи). Последние в свою очередь соответствуют табличным строкам.
Значения атрибутов каждого кортежа входят в домены, представляющие собой определенные наборы данных и задающие пределы допустимых значений.
Ваш Путь в IT начинается здесь
Подробнее
Другое важное свойство отношений в СУБД — замкнутость операций. Оно заключается в том, что любая операция над отношением порождает новое отношение. Благодаря этому свойству программисты SQL получают предсказуемые результаты математических действий. Также становится возможным представление операций в виде абстрактных выражений, обладающих разными уровнями вложенности.
Популярные сервисы для работы с SQL
Как язык работы с базами данных, SQL предполагает обязательное наличие установленной БД с доступом для подключения и выполнения запросов.
С помощью данного сервиса все SQL-операции можно выполнять в облаке. Это достаточно серьезное преимущество, ведь программистам здесь нет необходимости устанавливать и настраивать СУБД на локальную машину. Достаточно лишь зарегистрироваться.

Основные команды SQL
Помимо трех основных команд (CREATE, UPDATE и DELETE), используются и несколько других. Перечислим их ниже с примерами для MySQL (поэтому везде после операторов стоит точка с запятой).
Итак, прежде всего создаем базу данных с текстовым наполнением.

Основные команды SQL
Далее необходимо скачать файлы DLL.sql и InsertStatements.sql, а затем установить на компьютер СУБД MySQL. После чего в командной строке нужно ввести mysql -u root -p для входа в консоль MySQL.
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Читайте также: