
Методы машинного обучения кратко
Обновлено: 30.06.2024
Сегодняшний искусственный интеллект (ИИ) намного превзошел шумиху в блокчейне и квантовых вычислениях. Это связано с тем, что огромные вычислительные ресурсы легко доступны обычному человеку. Разработчики теперь используют это при создании новых моделей машинного обучения и переподготовке существующих моделей для повышения производительности и результатов. Легкая доступность высокопроизводительных вычислений (HPC) привела к внезапному увеличению спроса на ИТ-специалистов, обладающих навыками машинного обучения.
В этом уроке вы подробно узнаете о —
В чем суть машинного обучения?
Какие существуют виды машинного обучения?
Какие существуют алгоритмы для разработки моделей машинного обучения?
Какие инструменты доступны для разработки этих моделей?
Каковы варианты выбора языка программирования?
Какие платформы поддерживают разработку и развертывание приложений машинного обучения?
Какие интегрированные среды разработки (интегрированная среда разработки) доступны?
Как быстро улучшить свои навыки в этой важной области?
Какие существуют виды машинного обучения?
Какие существуют алгоритмы для разработки моделей машинного обучения?
Какие инструменты доступны для разработки этих моделей?
Каковы варианты выбора языка программирования?
Какие платформы поддерживают разработку и развертывание приложений машинного обучения?
Какие интегрированные среды разработки (интегрированная среда разработки) доступны?
Как быстро улучшить свои навыки в этой важной области?
Когда вы отмечаете лицо на фотографии в Facebook, это искусственный интеллект, который работает за кулисами и идентифицирует лица на фотографии. В некоторых приложениях тегирование лиц теперь вездесуще, и в нем отображаются изображения с человеческими лицами. Почему только человеческие лица? Существует несколько приложений, которые обнаруживают такие объекты, как кошки, собаки, бутылки, автомобили и т. Д. На наших дорогах работают автономные автомобили, которые в режиме реального времени обнаруживают объекты для управления автомобилем. Когда вы путешествуете, вы используете Google Directions, чтобы изучать ситуации с трафиком в режиме реального времени и следовать лучшему пути, предложенному Google на тот момент. Это еще одна реализация метода обнаружения объектов в реальном времени.
Давайте рассмотрим пример приложения Google Translate, которое мы обычно используем при посещении зарубежных стран. Приложение Google для онлайн-перевода на вашем мобильном телефоне поможет вам общаться с местными людьми, которые говорят на иностранном для вас языке.
Есть несколько приложений ИИ, которые мы используем практически сегодня. Фактически, каждый из нас использует ИИ во многих частях нашей жизни, даже без нашего ведома. Сегодняшний ИИ может выполнять чрезвычайно сложные задания с большой точностью и скоростью. Давайте обсудим пример сложной задачи, чтобы понять, какие возможности ожидаются в приложении для искусственного интеллекта, которое вы разрабатываете сегодня для своих клиентов.
пример
Мы все используем Google Directions во время нашей поездки в любую точку города для ежедневных поездок на работу или даже для поездок по городу. Приложение Google Directions предлагает самый быстрый путь к месту назначения в данный момент. Следуя этому пути, мы заметили, что Google почти на 100% прав в своих предложениях, и мы экономим наше драгоценное время в поездке.
Вы можете вообразить сложность, связанную с разработкой такого рода приложений, учитывая, что существует множество путей к пункту назначения, и приложение должно оценивать ситуацию с дорожным движением на каждом возможном пути, чтобы дать вам оценку времени в пути для каждого такого пути. Кроме того, учтите тот факт, что Google Directions охватывает весь земной шар. Несомненно, под капотами таких приложений используется множество методов искусственного интеллекта и машинного обучения.
Учитывая постоянную потребность в разработке таких приложений, вы теперь поймете, почему внезапно возникает потребность в ИТ-специалистах с навыками искусственного интеллекта.
В нашей следующей главе мы узнаем, что нужно для разработки программ ИИ.
Путешествие ИИ началось в 1950-х годах, когда вычислительная мощность была незначительной по сравнению с сегодняшней. ИИ начал с прогнозов, сделанных машиной так, как статистик делает прогнозы, используя свой калькулятор. Таким образом, начальная разработка ИИ была основана главным образом на статистических методах.
В этой главе давайте обсудим подробно, что это за статистические методы.
Статистические методы
Некоторые из примеров статистических методов, которые использовались для разработки приложений ИИ в те дни и все еще применяются на практике, перечислены здесь —
- регрессия
- классификация
- Кластеризация
- Теории вероятностей
- Деревья решений
Здесь мы перечислили только некоторые основные методы, которых достаточно, чтобы вы начали изучать ИИ, не пугая вас обширностью, которую требует ИИ. Если вы разрабатываете приложения ИИ на основе ограниченных данных, вы будете использовать эти статистические методы.
Однако сегодня данных в изобилии. Анализ огромных данных, которыми мы располагаем, не очень помогает, поскольку у них есть свои собственные ограничения. Поэтому для решения многих сложных проблем разрабатываются более продвинутые методы, такие как глубокое обучение.
Продвигаясь вперед в этом руководстве, мы поймем, что такое машинное обучение и как оно используется для разработки таких сложных приложений ИИ.
Рассмотрим следующий рисунок, который показывает график цен на жилье в зависимости от его размера в кв. Футах.
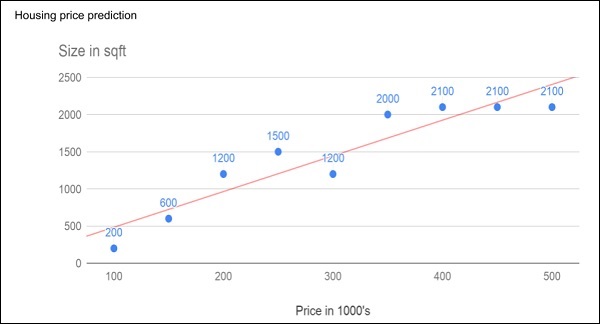
После построения различных точек данных на графике XY мы рисуем наиболее подходящую линию, чтобы сделать наши прогнозы для любого другого дома с учетом его размера. Вы передадите известные данные на машину и попросите найти линию наилучшего соответствия. Как только машина найдет наилучшую линию подгонки, вы проверите ее пригодность, введя известный размер дома, то есть значение Y на приведенной выше кривой. Теперь машина вернет приблизительное значение Х, то есть ожидаемую цену дома. Диаграмма может быть экстраполирована, чтобы узнать цену дома, который составляет 3000 кв. Футов или даже больше. Это называется регрессией в статистике. В частности, этот вид регрессии называется линейной регрессией, поскольку отношения между точками данных X & Y являются линейными.
Во многих случаях отношения между точками данных X & Y могут не быть прямой линией, и это может быть кривая со сложным уравнением. Ваша задача теперь состоит в том, чтобы найти наиболее подходящую кривую, которая может быть экстраполирована для прогнозирования будущих значений. Один такой сюжет приложения показан на рисунке ниже.
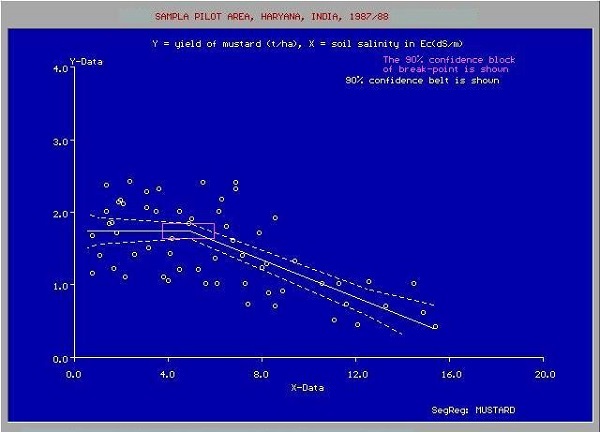
Вы будете использовать методы статистической оптимизации, чтобы найти здесь уравнение для наилучшей кривой соответствия. И это именно то, что такое машинное обучение. Вы используете известные методы оптимизации, чтобы найти лучшее решение вашей проблемы.
Далее давайте рассмотрим различные категории машинного обучения.
Машинное обучение широко классифицируется под следующими заголовками —
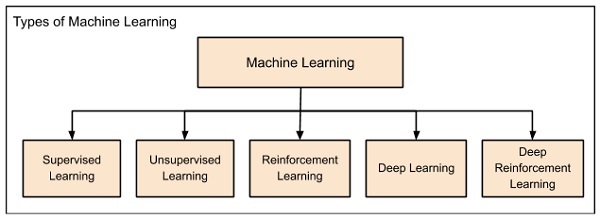
Машинное обучение развивалось слева направо, как показано на схеме выше.
Первоначально исследователи начали с контролируемого обучения. Это случай прогноза цен на жилье, который обсуждался ранее.
За этим последовало неконтролируемое обучение, когда машина обучалась самостоятельно без какого-либо надзора.
Ученые также обнаружили, что это может быть хорошей идеей, чтобы вознаградить машину, когда она выполняет работу ожидаемым образом, и наступило обучение по усилению.
Очень скоро данные, доступные в наши дни, стали настолько огромными, что разработанные до сих пор традиционные методы не смогли проанализировать большие данные и дать нам прогнозы.
Таким образом, пришло глубокое понимание, где человеческий мозг моделируется в искусственных нейронных сетях (ANN), созданных в наших двоичных компьютерах.
Теперь машина учится самостоятельно, используя высокую вычислительную мощность и огромные ресурсы памяти, доступные сегодня.
В настоящее время наблюдается, что глубокое обучение решило многие из ранее неразрешимых проблем.
В настоящее время эта техника получила дальнейшее развитие, поощряя сети Deep Learning в качестве наград, и, наконец, приходит Deep Reinforcement Learning.
Первоначально исследователи начали с контролируемого обучения. Это случай прогноза цен на жилье, который обсуждался ранее.
За этим последовало неконтролируемое обучение, когда машина обучалась самостоятельно без какого-либо надзора.
Ученые также обнаружили, что это может быть хорошей идеей, чтобы вознаградить машину, когда она выполняет работу ожидаемым образом, и наступило обучение по усилению.
Очень скоро данные, доступные в наши дни, стали настолько огромными, что разработанные до сих пор традиционные методы не смогли проанализировать большие данные и дать нам прогнозы.
Таким образом, пришло глубокое понимание, где человеческий мозг моделируется в искусственных нейронных сетях (ANN), созданных в наших двоичных компьютерах.
Теперь машина учится самостоятельно, используя высокую вычислительную мощность и огромные ресурсы памяти, доступные сегодня.
В настоящее время наблюдается, что глубокое обучение решило многие из ранее неразрешимых проблем.
В настоящее время эта техника получила дальнейшее развитие, поощряя сети Deep Learning в качестве наград, и, наконец, приходит Deep Reinforcement Learning.
Давайте теперь изучим каждую из этих категорий более подробно.
Контролируемое обучение
Обучение под присмотром аналогично обучению ребенка ходить. Вы будете держать ребенка за руку, показывать ему, как сделать шаг вперед, ходить на демонстрацию и так далее, пока ребенок не научится ходить самостоятельно.
регрессия
Аналогично, в случае контролируемого обучения вы даете конкретные известные примеры компьютеру. Вы говорите, что для данного значения признака x1 выход равен y1, для x2 это y2, для x3 это y3 и так далее. Основываясь на этих данных, вы позволяете компьютеру определить эмпирические отношения между x и y.
После того, как машина обучена таким образом с достаточным количеством точек данных, теперь вы бы попросили машину предсказать Y для данного X. Предполагая, что вы знаете реальное значение Y для данного X, вы сможете вывести правильный ли прогноз машины?
Таким образом, вы будете проверять, узнал ли машина, используя известные тестовые данные. Как только вы убедитесь, что машина может делать прогнозы с желаемым уровнем точности (скажем, от 80 до 90%), вы можете прекратить дальнейшую подготовку машины.
Теперь вы можете безопасно использовать машину для прогнозирования неизвестных точек данных или попросить машину прогнозировать Y для заданного X, для которого вы не знаете действительного значения Y. Это обучение относится к регрессии, о которой мы говорили ранее.
классификация
Вы также можете использовать методы машинного обучения для задач классификации. В задачах классификации вы классифицируете объекты сходной природы в одну группу. Например, в наборе из 100 студентов вы можете сгруппировать их в три группы в зависимости от их роста — короткая, средняя и длинная. Измеряя рост каждого ученика, вы поместите их в соответствующую группу.
Теперь, когда приходит новый студент, вы поместите его в соответствующую группу, измерив его рост. Следуя принципам регрессионного обучения, вы научите машину классифицировать ученика на основе его характеристики — роста. Когда машина узнает, как формируются группы, она сможет правильно классифицировать любого неизвестного нового ученика. Еще раз, вы должны использовать данные испытаний, чтобы убедиться, что машина изучила вашу технику классификации, прежде чем запускать разработанную модель в производство.
Обучение под наблюдением — это место, где ИИ действительно начал свое путешествие. Эта методика была успешно применена в нескольких случаях. Вы использовали эту модель во время распознавания рукописного текста на своем компьютере. Для контролируемого обучения было разработано несколько алгоритмов. Вы узнаете о них в следующих главах.
Обучение без учителя
На следующем рисунке показана граница между желтыми и красными точками, как это определено автоматическим обучением без присмотра. Вы можете ясно видеть, что машина будет в состоянии определить класс каждой из черных точек с довольно хорошей точностью.
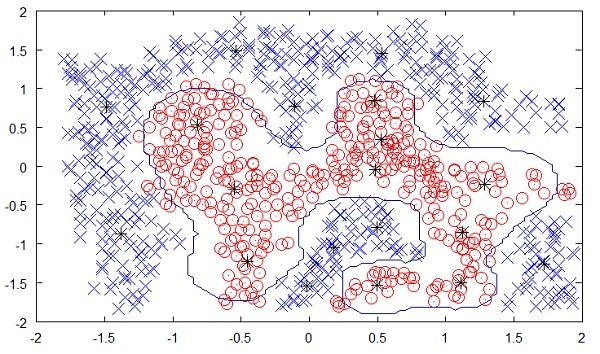
Обучение без присмотра показало большой успех во многих современных приложениях ИИ, таких как обнаружение лиц, обнаружение объектов и так далее.
Усиление обучения
Весь процесс может быть изображен на следующей диаграмме —
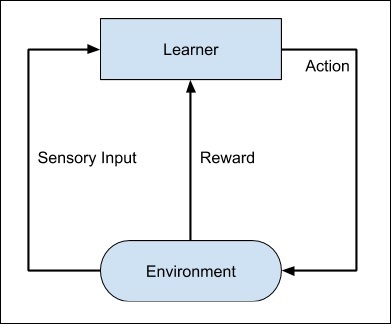
Этот метод машинного обучения отличается от контролируемого обучения тем, что вам не нужно снабжать помеченные пары ввода / вывода. Основное внимание уделяется поиску баланса между изучением новых решений и использованием изученных решений.
Глубокое обучение
Глубокое обучение — это модель, основанная на искусственных нейронных сетях (ANN), более конкретно, на сверточных нейронных сетях (CNN). Есть несколько архитектур, используемых в глубоком обучении, таких как глубокие нейронные сети, сети глубокого убеждения, рекуррентные нейронные сети и сверточные нейронные сети.
Эти сети успешно применяются для решения проблем компьютерного зрения, распознавания речи, обработки естественного языка, биоинформатики, разработки лекарств, анализа медицинских изображений и игр. Есть несколько других областей, в которых глубокое обучение активно применяется. Глубокое обучение требует огромной вычислительной мощности и огромных данных, которые обычно легко доступны в наши дни.
Мы поговорим о глубоком изучении более подробно в следующих главах.
Глубокое обучение
Глубокое обучение с подкреплением (DRL) сочетает в себе методы глубокого и подкрепляющего обучения. Алгоритмы обучения с подкреплением, такие как Q-learning, теперь сочетаются с глубоким обучением для создания мощной модели DRL. Техника была с большим успехом в области робототехники, видеоигр, финансов и здравоохранения. Многие ранее неразрешимые проблемы теперь решаются путем создания моделей DRL. В этой области ведется множество исследований, и отрасль очень активно этим занимается.
Пока у вас есть краткое введение в различные модели машинного обучения, а теперь давайте немного углубимся в различные алгоритмы, доступные в этих моделях.
Контролируемое обучение является одной из важных моделей обучения, связанных с обучением машин. В этой главе подробно говорится о том же.
Алгоритмы для контролируемого обучения
Есть несколько алгоритмов, доступных для контролируемого обучения. Некоторые из широко используемых алгоритмов контролируемого обучения, как показано ниже —
- k-Ближайшие соседи
- Деревья решений
- Наивный байесовский
- Логистическая регрессия
- Опорные векторные машины
По мере продвижения в этой главе давайте поговорим подробно о каждом из алгоритмов.
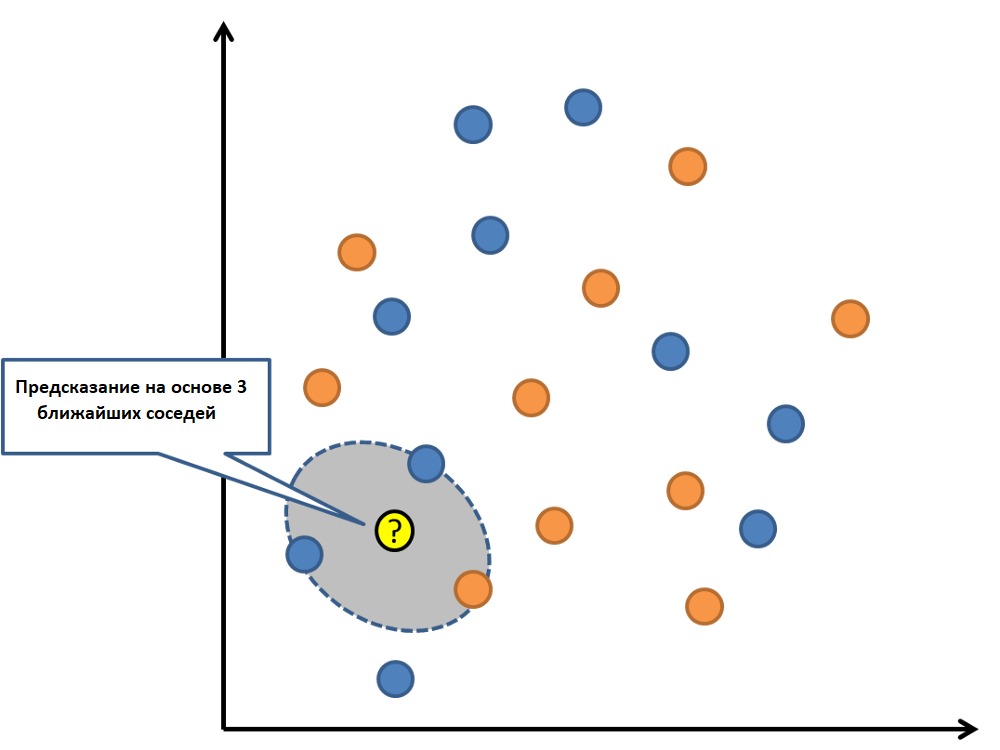
k-Ближайшие соседи
K-Ближайшие соседи, которые просто называются kNN, — это статистический метод, который можно использовать для решения задач классификации и регрессии. Давайте обсудим случай классификации неизвестного объекта с использованием kNN. Рассмотрим распределение объектов, как показано на рисунке ниже —
Например, нельзя сказать, что нейронные сети всегда работают лучше, чем деревья решений, и наоборот. На эффективность алгоритмов влияет множество факторов вроде размера и структуры набора данных.
По этой причине приходится пробовать много разных алгоритмов, проверяя эффективность каждого на тестовом наборе данных, и затем выбирать лучший вариант. Само собой, нужно выбирать среди алгоритмов, соответствующих вашей задаче. Если проводить аналогию, то при уборке дома вы, скорее всего, будете использовать пылесос, метлу или швабру, но никак не лопату.
Алгоритмы машинного обучения можно описать как обучение целевой функции f , которая наилучшим образом соотносит входные переменные X и выходную переменную Y : Y = f(X) .
Мы не знаем, что из себя представляет функция f . Ведь если бы знали, то использовали бы её напрямую, а не пытались обучить с помощью различных алгоритмов.
Наиболее распространённой задачей в машинном обучении является предсказание значений Y для новых значений X . Это называется прогностическим моделированием, и наша цель — сделать как можно более точное предсказание.
Представляем вашему вниманию краткий обзор топ-10 популярных алгоритмов, используемых в машинном обучении.
1. Линейная регрессия
Линейная регрессия — пожалуй, один из наиболее известных и понятных алгоритмов в статистике и машинном обучении.
Прогностическое моделирование в первую очередь касается минимизации ошибки модели или, другими словами, как можно более точного прогнозирования. Мы будем заимствовать алгоритмы из разных областей, включая статистику, и использовать их в этих целях.
Линейную регрессию можно представить в виде уравнения, которое описывает прямую, наиболее точно показывающую взаимосвязь между входными переменными X и выходными переменными Y . Для составления этого уравнения нужно найти определённые коэффициенты B для входных переменных.

Например: Y = B0 + B1 * X
Зная X , мы должны найти Y , и цель линейной регрессии заключается в поиске значений коэффициентов B0 и B1 .
Для оценки регрессионной модели используются различные методы вроде линейной алгебры или метода наименьших квадратов.
Линейная регрессия существует уже более 200 лет, и за это время её успели тщательно изучить. Так что вот пара практических правил: уберите похожие (коррелирующие) переменные и избавьтесь от шума в данных, если это возможно. Линейная регрессия — быстрый и простой алгоритм, который хорошо подходит в качестве первого алгоритма для изучения.
2 . Логистическая регрессия
Логистическая регрессия — ещё один алгоритм, пришедший в машинное обучение прямиком из статистики. Её хорошо использовать для задач бинарной классификации (это задачи, в которых на выходе мы получаем один из двух классов).
Логистическая регрессия похожа на линейную тем, что в ней тоже требуется найти значения коэффициентов для входных переменных. Разница заключается в том, что выходное значение преобразуется с помощью нелинейной или логистической функции.
Логистическая функция выглядит как большая буква S и преобразовывает любое значение в число в пределах от 0 до 1. Это весьма полезно, так как мы можем применить правило к выходу логистической функции для привязки к 0 и 1 (например, если результат функции меньше 0.5, то на выходе получаем 1) и предсказания класса.

Благодаря тому, как обучается модель, предсказания логистической регрессии можно использовать для отображения вероятности принадлежности образца к классу 0 или 1. Это полезно в тех случаях, когда нужно иметь больше обоснований для прогнозирования.
Как и в случае с линейной регрессией, логистическая регрессия выполняет свою задачу лучше, если убрать лишние и похожие переменные. Модель логистической регрессии быстро обучается и хорошо подходит для задач бинарной классификации.
3. Линейный дискриминантный анализ (LDA)
Логистическая регрессия используется, когда нужно отнести образец к одному из двух классов. Если классов больше, чем два, то лучше использовать алгоритм LDA (Linear discriminant analysis).
Представление LDA довольно простое. Оно состоит из статистических свойств данных, рассчитанных для каждого класса. Для каждой входной переменной это включает:
- Среднее значение для каждого класса;
- Дисперсию, рассчитанную по всем классам.
Предсказания производятся путём вычисления дискриминантного значения для каждого класса и выбора класса с наибольшим значением. Предполагается, что данные имеют нормальное распределение, поэтому перед началом работы рекомендуется удалить из данных аномальные значения. Это простой и эффективный алгоритм для задач классификации.
4. Деревья принятия решений
Дерево решений можно представить в виде двоичного дерева, знакомого многим по алгоритмам и структурам данных. Каждый узел представляет собой входную переменную и точку разделения для этой переменной (при условии, что переменная — число).
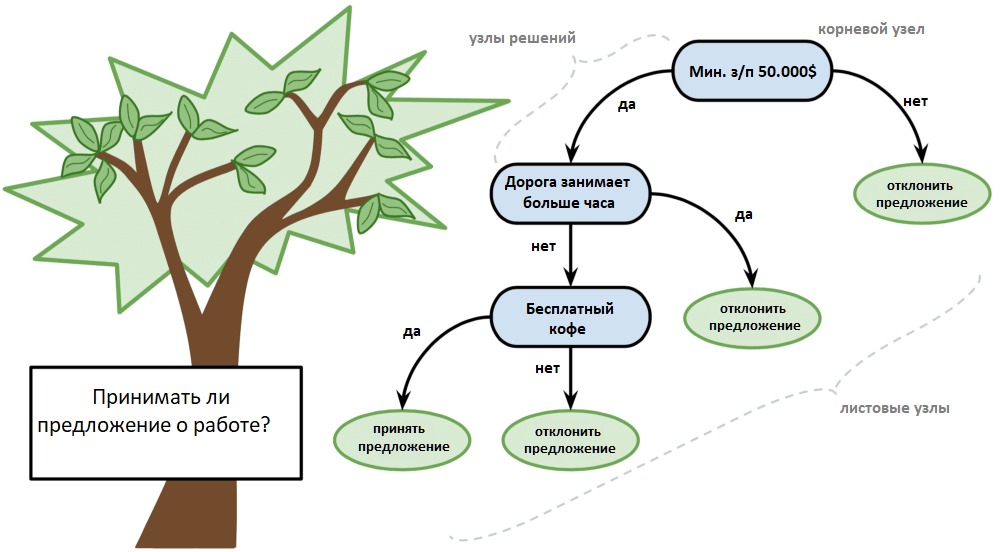
Листовые узлы — это выходная переменная, которая используется для предсказания. Предсказания производятся путём прохода по дереву к листовому узлу и вывода значения класса на этом узле.
Деревья быстро обучаются и делают предсказания. Кроме того, они точны для широкого круга задач и не требуют особой подготовки данных.
5 . Наивный Байесовский классификатор
Наивный Байес — простой, но удивительно эффективный алгоритм.
Модель состоит из двух типов вероятностей, которые рассчитываются с помощью тренировочных данных:
- Вероятность каждого класса.
- Условная вероятность для каждого класса при каждом значении x.
После расчёта вероятностной модели её можно использовать для предсказания с новыми данными при помощи теоремы Байеса. Если у вас вещественные данные, то, предполагая нормальное распределение, рассчитать эти вероятности не составляет особой сложности.
Наивный Байес называется наивным, потому что алгоритм предполагает, что каждая входная переменная независимая. Это сильное предположение, которое не соответствует реальным данным. Тем не менее данный алгоритм весьма эффективен для целого ряда сложных задач вроде классификации спама или распознавания рукописных цифр.
6. K-ближайших соседей (KNN)
К-ближайших соседей — очень простой и очень эффективный алгоритм. Модель KNN (K-nearest neighbors) представлена всем набором тренировочных данных. Довольно просто, не так ли?
Предсказание для новой точки делается путём поиска K ближайших соседей в наборе данных и суммирования выходной переменной для этих K экземпляров.
Вопрос лишь в том, как определить сходство между экземплярами данных. Если все признаки имеют один и тот же масштаб (например, сантиметры), то самый простой способ заключается в использовании евклидова расстояния — числа, которое можно рассчитать на основе различий с каждой входной переменной.
KNN может потребовать много памяти для хранения всех данных, но зато быстро сделает предсказание. Также обучающие данные можно обновлять, чтобы предсказания оставались точными с течением времени.
Идея ближайших соседей может плохо работать с многомерными данными (множество входных переменных), что негативно скажется на эффективности алгоритма при решении задачи. Это называется проклятием размерности. Иными словами, стоит использовать лишь наиболее важные для предсказания переменные.
7 . Сети векторного квантования (LVQ)
Недостаток KNN заключается в том, что нужно хранить весь тренировочный набор данных. Если KNN хорошо себя показал, то есть смысл попробовать алгоритм LVQ (Learning vector quantization), который лишён этого недостатка.
LVQ представляет собой набор кодовых векторов. Они выбираются в начале случайным образом и в течение определённого количества итераций адаптируются так, чтобы наилучшим образом обобщить весь набор данных. После обучения эти вектора могут использоваться для предсказания так же, как это делается в KNN. Алгоритм ищет ближайшего соседа (наиболее подходящий кодовый вектор) путём вычисления расстояния между каждым кодовым вектором и новым экземпляром данных. Затем для наиболее подходящего вектора в качестве предсказания возвращается класс (или число в случае регрессии). Лучшего результата можно достичь, если все данные будут находиться в одном диапазоне, например от 0 до 1.
8. Метод опорных векторов (SVM)
Метод опорных векторов, вероятно, один из наиболее популярных и обсуждаемых алгоритмов машинного обучения.
Гиперплоскость — это линия, разделяющая пространство входных переменных. В методе опорных векторов гиперплоскость выбирается так, чтобы наилучшим образом разделять точки в плоскости входных переменных по их классу: 0 или 1. В двумерной плоскости это можно представить как линию, которая полностью разделяет точки всех классов. Во время обучения алгоритм ищет коэффициенты, которые помогают лучше разделять классы гиперплоскостью.
Расстояние между гиперплоскостью и ближайшими точками данных называется разницей. Лучшая или оптимальная гиперплоскость, разделяющая два класса, — это линия с наибольшей разницей. Только эти точки имеют значение при определении гиперплоскости и при построении классификатора. Эти точки называются опорными векторами. Для определения значений коэффициентов, максимизирующих разницу, используются специальные алгоритмы оптимизации.
Метод опорных векторов, наверное, один из самых эффективных классических классификаторов, на который определённо стоит обратить внимание.
9 . Бэггинг и случайный лес
Случайный лес — очень популярный и эффективный алгоритм машинного обучения. Это разновидность ансамблевого алгоритма, называемого бэггингом.
Бутстрэп является эффективным статистическим методом для оценки какой-либо величины вроде среднего значения. Вы берёте множество подвыборок из ваших данных, считаете среднее значение для каждой, а затем усредняете результаты для получения лучшей оценки действительного среднего значения.
В бэггинге используется тот же подход, но для оценки всех статистических моделей чаще всего используются деревья решений. Тренировочные данные разбиваются на множество выборок, для каждой из которой создаётся модель. Когда нужно сделать предсказание, то его делает каждая модель, а затем предсказания усредняются, чтобы дать лучшую оценку выходному значению.
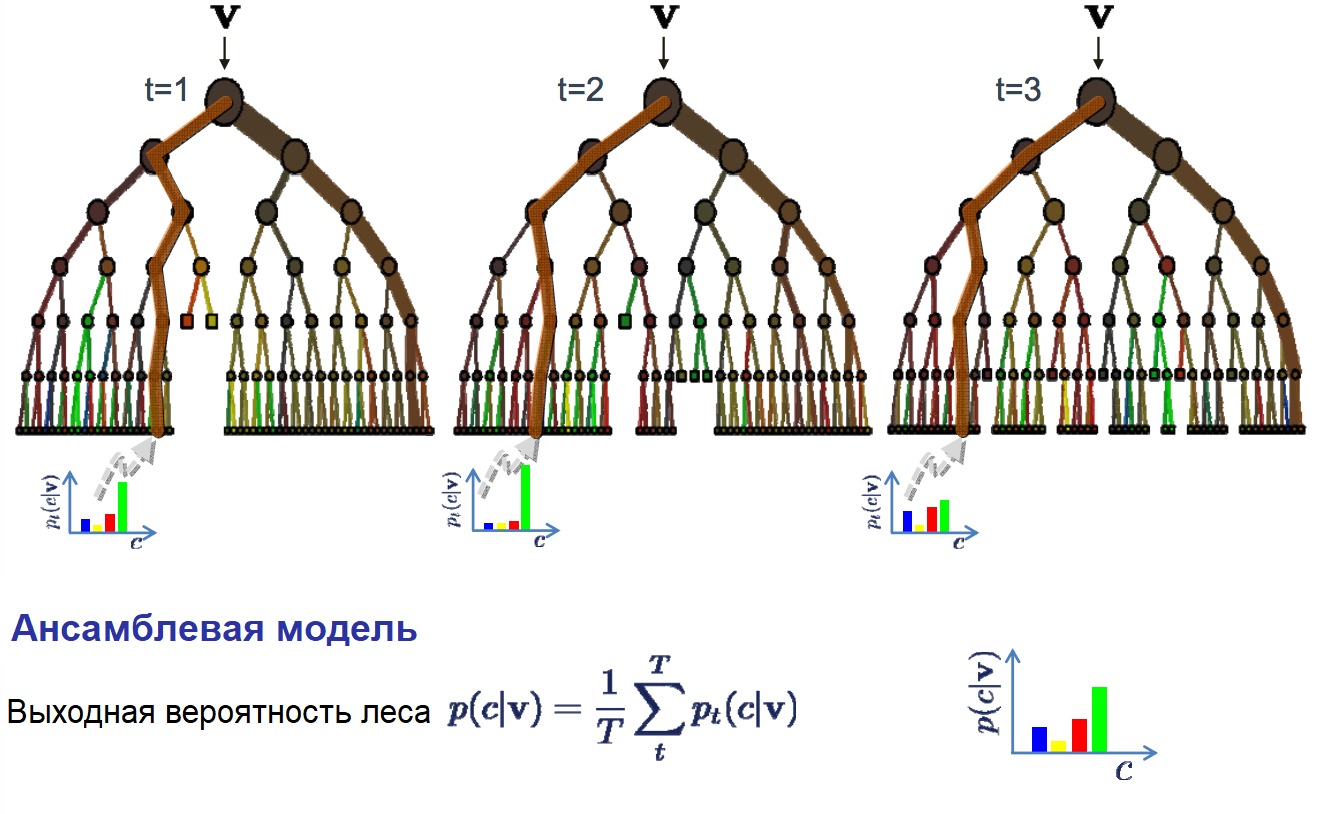
В алгоритме случайного леса для всех выборок из тренировочных данных строятся деревья решений. При построении деревьев для создания каждого узла выбираются случайные признаки. В отдельности полученные модели не очень точны, но при их объединении качество предсказания значительно улучшается.
Если алгоритм с высокой дисперсией, например, деревья решений, показывает хороший результат на ваших данных, то этот результат зачастую можно улучшить, применив бэггинг.
10 . Бустинг и AdaBoost
AdaBoost был первым действительно успешным алгоритмом бустинга, разработанным для бинарной классификации. Именно с него лучше всего начинать знакомство с бустингом. Современные методы вроде стохастического градиентного бустинга основываются на AdaBoost.
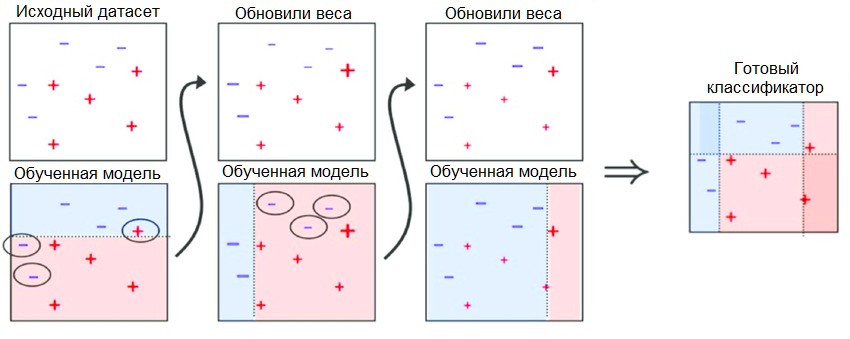
AdaBoost используют вместе с короткими деревьями решений. После создания первого дерева проверяется его эффективность на каждом тренировочном объекте, чтобы понять, сколько внимания должно уделить следующее дерево всем объектам. Тем данным, которые сложно предсказать, даётся больший вес, а тем, которые легко предсказать, — меньший. Модели создаются последовательно одна за другой, и каждая из них обновляет веса для следующего дерева. После построения всех деревьев делаются предсказания для новых данных, и эффективность каждого дерева определяется тем, насколько точным оно было на тренировочных данных.
Так как в этом алгоритме большое внимание уделяется исправлению ошибок моделей, важно, чтобы в данных отсутствовали аномалии.
Пара слов напоследок
- Размер, качество и характер данных;
- Доступное вычислительное время;
- Срочность задачи;
- Что вы хотите делать с данными.
Даже опытный data scientist не скажет, какой алгоритм будет работать лучше, прежде чем попробует несколько вариантов. Существует множество других алгоритмов машинного обучения, но приведённые выше — наиболее популярные. Если вы только знакомитесь с машинным обучением, то они будут хорошей отправной точкой.
Машинное обучение — это методы искусственного интеллекта, которые позволяют построить обучаемые модели для разных целей: например, автоматизации процессов, автоматического перевода текстов, распознавания изображений. Именно машинное обучение помогает ранжировать контент в лентах социальных сетей и создавать чат-ботов, которые общаются на естественном языке.
Типы машинного обучения
Выделяют два типа машинного обучения: дедуктивное и индуктивное.
Дедуктивное обучение (экспертные системы). В этом случае в задачах есть сформулированные и формализованные знания. Например, это может быть база данных, в которой указано, что если температура больше 30 градусов, то нужно включить кондиционер, а если на улице идет дождь — закрыть окна. Нужно вывести из них новое правило, которое можно применить к конкретному случаю. Экспертные системы чаще относят к ответвлению кибернетики — науки об управлении информацией в сложных системах, — чем к машинному обучению.
Индуктивное обучение подразделяется:
- на обучение с учителем. Пример задач: по предыдущему курсу валют предсказать курс на завтрашний день; отличить по изображениям кошек от собак (в этом случае изначально должна быть информация, на какой картинке и где изображены кошка и собака).
- Обучение без учителя. Пример задачи: разделить группу пользователей сайта на основе их интересов или демографических характеристик. Обычно нужно знать, сколько групп уже имеется в данных.
- Обучение с подкреплением (reinforcement learning). Пример: игра Super Mario, в которой компьютер (агент) взаимодействует со средой (уровень игры) и получает положительные или отрицательные очки.
- Активное обучение. Пример: подсказка слов на клавиатуре телефона.
Многие методы индуктивного обучения связаны с извлечением информации (information extraction). Например, создание для пользователя дополнительного признака на основе его транзакций, чтобы понять, потратил ли клиент в этом месяце больше, чем в предыдущем.
Освойте самую востребованную технологию искусственного интеллекта. Дополнительная скидка 5% по промокоду BLOG.
Основные методы машинного обучения
Обучение с учителем (supervised learning)
Для этого алгоритма обучения нужны данные, на основе которых будет строиться модель. К supervised learning относятся задачи классификации, прогнозирования и ранжирования и регрессии.
Например, на основе данных о продажах квартир в Москве можно создать алгоритм, который будет оценивать стоимость жилья, выставляемого на продажу. Для алгоритма нужны данные вида X, Y. Если предположить, что X — это таблица с параметрами домов, то Y — таблица со стоимостью каждого дома. Таким образом можно обучить модель предсказывать по параметрам дома его стоимость. Обычно это выражают в виде функции F(X) = Y.
Небольшая часть данных для алгоритма будет выглядеть так:
Благодаря этим данным алгоритм сможет определить цену квартиры в Москве.
Обучение без учителя (unsupervised learning)
При обучении без учителя задействуются неклассифицированные данные. Главное отличие от предыдущего пункта — это то, что тут нет Y, то есть имеется список домов, но неизвестна их стоимость. В этих данных нужно будет найти закономерности, а также создать их структуру. К формам обучения без учителя относят, например:
- кластеризацию — разбивку данных на похожие категории. Например, космические объекты объединяются в конкретные категории по схожим признакам: размеру, удаленности, типу;
- уменьшение размерности — снижение количества признаков наборов данных. Например, можно визуализировать данные о пользователях (их пол, возраст, платежеспособность, город и т.д.) на одном графике. Для этого какие-то признаки нужно убрать, а какие-то — трансформировать специальными методами.
Вернемся к примеру с продажей квартир. Бывает, что невозможно собрать полную информацию по каждому объекту. Тогда алгоритмы машинного обучения будут искать закономерности среди имеющихся вводных.
Так, можно создать алгоритм, автоматически определяющий разные рыночные сегменты. Тогда можно обнаружить, что покупатели недвижимости рядом с университетом выбирают маленькие квартиры, а владельцы коттеджей — дома с большой площадью.
Обучение с подкреплением (reinforcement learning)
В этом случае есть так называемый агент (A), который обычно моделируется нейронной сетью. Этот агент должен на каждом шаге взаимодействия со средой (E) предсказывать действие, позволяющее максимизировать награду, которую можно получить. Обучение с подкреплением больше всего похоже на то, как учатся дети: если ребенок дотронется до горячего чайника, он обожжется, получит негативную награду (или опыт) и в дальнейшем перестанет его трогать. Сейчас обучение с подкреплением активно используется для сборки кубика Рубика и в компьютерных играх.
Топ библиотек для машинного обучения
JavaScript
Dplyr
MLR
Caret
Python
SciPy
NumPy
Pandas
Keras
Skikit-learn
Data Science с нуля
Вы получите достаточную математическую подготовку и опыт программирования на Python, чтобы решать задачи машинного обучения.
Контент-маркетолог Мария Пушикова специально для блога Нетологии перевела статью Charles-Antoine Richard о том, что такое машинное обучение и какие методы машинного обучения существуют.
Совсем недавно мы обсуждали необходимость использования методов машинного обучения в бизнесе. Это подтолкнуло меня изучить основы методов машинного обучения, во время чего я сознал: большая имеющейся часть информации направлена на разработчиков или специалистов по Big Data.
Поэтому я решил, что читателям будет интересно прочесть объяснение методов машинного обучения от человека нетехнической специальности.
Машинное обучение — это…
Вот самое простое определение, которое я нашел:
Теперь давайте разложим все по полочкам, чтобы выстроить основы знаний в области машинного обучения.
…подраздел искусственного интеллекта (ИИ)
ИИ — это наука и технология по разработке мероприятий и методов, позволяющих компьютерам успешно выполнять задачи, которые обычно требуют интеллектуального осмысления человека. Машинное обучение — часть этого процесса: это методы и технологии, с помощью которых можно обучит компьютер выполнять поставленные задачи.
…способ решения практических задач
Методы машинного обучения все еще в развитии. Некоторые уже изучены и используются (рассмотрим дальше), но ожидается, что со временем их количество будет только расти. Идея в том, что совершенно разные методы используются для совершенно разных компьютеров, а различные бизнес-задачи требуют различных методов машинного обучения.
… способ увеличить эффективность компьютеров
Для решения компьютером задач с применением искусственного интеллекта нужны практика и автоматическая поднастройка. Модель машинного обучения нуждается в тренировке с использованием базы данных и в большинстве ситуаций — в подсказке человека.
…технология, основанная на опыте
ИИ нуждается в предоставлении опыта — иными словами, ему необходимы данные. Чем больше в систему ИИ поступает данных, тем точнее компьютер взаимодействует с ними, а также с теми данными, что получает в дальнейшем. Чем выше точность взаимодействия, тем успешнее будет выполнение поставленной задачи, и выше степень прогностической точности.
Простой пример:
- Выбираются входные данные и задаются условия ввода (например, банковские операции с использованием карт).
- Строится алгоритм машинного обучения и настраивается на конкретную задачу (например, выявлять мошеннические транзакции).
- Используемые в ходе обучения данные дополняются желаемой выходной информацией (например, эти транзакции — мошеннические, а эти нет).
Как работает машинное обучение
Машинное обучение часто называют волшебным или черным ящиком:
Давайте посмотрим на сам процесс обучения, чтобы лучше понять, как машинное обучение справляется с данными.
Машинное обучение основывается на данных. Первый шаг — убедиться, что имеющиеся данные верны и относятся именно к той задаче, которую вы пытаетесь решить. Оцените свои возможности для сбора данных, обдумайте их источник, необходимый формат и т. д.
Очистка
Данные зачастую формируются из различных источников, отображаются в различных форматах и языках. Соответственно, среди них могут оказаться нерелевантные или ненужные значения, которые потребуется удалить. И наоборот, каких-то данных может не хватать, и потребуется их добавить. От правильной подготовки базы данных прямым образом зависит и пригодность к использованию, и достоверность результатов.
Разделение
В зависимости от размера набора данных в некоторых случаях может потребоваться только небольшая их часть. Обычно это называется выборкой. Из выбранной части данные надо разделить на две группы: одна для использования алгоритмом, а другая для оценки его действий.
Обучение
Чтобы было проще, сосредоточимся на нейронных сетях.
Суть в том, что алгоритм использует часть данных, обрабатывает их, замеряет эффективность обработки и автоматически регулирует свои параметры (также называемый метод обратного распространения ошибки) до тех пор, пока не сможет последовательно производить желаемый результат с достаточной достоверностью.
Оценка
После того как алгоритм хорошо показал себя на учебных данных, его эффективность оценивается на данных, с которыми он еще не сталкивался. Дополнительная корректировка производится при необходимости. Этот процесс позволяет предотвратить переобучение — явление, при котором алгоритм хорошо работает только на учебных данных.
Оптимизация
Модель оптимизируется, чтобы при интеграции в приложение весить как можно меньше и как можно быстрее работать.
Какие существуют типы машинного обучения и чем они отличаются
Существует множество моделей для машинного обучения, но они, как правило, относятся к одному из трех типов:
- обучение с учителем (supervised learning);
- обучение без учителя, или самообучение (unsupervised learning);
- обучение с подкреплением (reinforcement learning).
В зависимости от выполняемой задачи, одни модели могут быть более подходящими и более эффективными, чем другие.
Обучение с учителем (supervised learning)
В этом типе корректный результат при обучении модели явно обозначается для каждого идентифицируемого элемента в наборе данных. Это означает, что при считывании данных у алгоритма уже есть правильный ответ. Поэтому вместо поисков ответа он стремится найти связи, чтобы в дальнейшем, при введении необозначенных данных, получались правильные классификация или прогноз.
В контексте классификации алгоритм обучения может, например, снабжаться историей транзакций по кредитным картам, каждая из которых помечена как безопасная или подозрительная. Он должен изучить отношения между этими двумя классификациями, чтобы затем суметь соответствующим образом маркировать новые операции в зависимости от параметров классификации (например, место покупки, время между операциями и т. д.).
В случае когда данные непрерывно связаны друг с другом, как, например, изменение курса акций во времени, регрессионный алгоритм обучения может использоваться для прогнозирования следующего значения в наборе данных.
Обучение без учителя (unsupervised learning)
Обучение с подкреплением
Этот тип обучения представляет собой смесь первых двух. Обычно он используется для решения более сложных задач и требует взаимодействия с окружающей средой. Данные предоставляются средой и позволяют алгоритму реагировать и учиться.
Логические игры также хорошо подходят для обучения с подкреплением, так как они традиционно содержат логическую цепочку решений: например, покер, нарды и го, в которую недавно выиграл AlphaGo от Google. Этот метод обучения также часто применяется в логистике, составлении графиков и тактическом планировании задач.
Для чего можно использовать машинное обучение
В бизнесе можно рассматривать три сферы применения машинного обучения: описательную, прогнозирующую и нормативную.
Описательное применение относится к записи и анализу статистических данных для расширения возможностей бизнес-аналитики. Руководители получают описание и максимально информативный анализ результатов и последствий прошлых действий и решений. Этот процесс в настоящее время обычен для большинства крупных компаний по всему миру — например, анализ продаж и рекламных проектов для определения их результатов и рентабельности.
Второе применение машинного обучения — прогнозирование. Сбор данных и их использование для прогнозирования конкретного результата позволяет повысить скорость реакции и быстрее принимать верные решения. Например, прогнозирование оттока клиентов может помочь его предотвратить. Сегодня этот процесс применяется в большинстве крупных компаний.
Третье и наиболее продвинутое применение машинного обучения внедряется уже существующими компаниями и совершенствуется усилиями недавно созданных. Простого прогнозирования результатов или поведения уже недостаточно для эффективного ведения бизнеса. Понимание причин, мотивов и окружающей ситуации — вот необходимое условие для принятия оптимального решения. Этот метод наиболее эффективен, если человек и машина объединяют усилия. Машинное обучение используется для поиска значимых зависимостей и прогнозирования результатов, а специалисты по данным интерпретируют результат, чтобы понять, почему такая связь существует. В результате становится возможным принимать более точные и верные решения.
Кроме того, я бы добавил еще одно применение машинного обучения, отличное от прогнозного: автоматизация процессов. Прочесть об этом можно здесь.
Вот несколько примеров задач, которые решает машинное обучение.
Логистика и производство
- В Rethink Robotics используют машинное обучение для обучения манипуляторов и увеличения скорости производства;
- В JaybridgeRobotics автоматизируют промышленные транспортные средства промышленного класса для более эффективной работы;
- В Nanotronics автоматизируют оптические микроскопы для улучшения результатов осмотра; и Amazon оптимизируют распределение ресурсов в соответствии с потребностями пользователей;
- Другие примеры: прогнозирование потребностей ERP/ERM; прогнозирование сбоев и улучшение техобслуживания, улучшение контроля качества и увеличение мощности производственной линии.
Продажи и маркетинг
-
прогнозирует, какой лид и в какое время наиболее склонен к покупке; помогает предвидеть возможности для продаж и автоматизировать задачи; автоматизирует планы продаж с помощью AI; предлагает пути повышения эффективности PR; предлагает кросс-канальное вовлечение;
- Другие примеры: прогнозирование стоимости жизненного цикла клиента, повышение точности сегментации клиентов, выявление клиентских моделей покупок, и оптимизация опыта пользователя в приложениях.
Кадры
-
помогает рекрутерам находить и отбирать кандидатов; помогает менеджерам в управлении талантами.
Финансы
-
and Sentient используют машинное обучение для улучшения процесса принятия инвестиционных решений; может помочь с текущими финансовыми решениями, заранее оповещая о социальных тенденциях и последних новостях;
- Другие примеры: выявление случаев мошенничества и прогнозирование цен на акции.
Здравоохранение
-
использует прогнозные модели для уменьшения времени производства лекарств; определяет подходящих пациентов для клинических испытаний;
- Другие примеры: более точная диагностика заболеваний, улучшение персонализированного ухода и оценка рисков для здоровья.
Больше примеров использования машинного обучения, искусственного интеллекта и других связанных с ними ресурсов вы найдете в списке, созданном Sam DeBrule.
Вместо заключения
Помните, что совместное использование разных систем и методик — ключ к успеху. ИИ и машинное обучение хоть и сложны, но увлекательны. Буду рад продолжить обсуждение стратегий разработки и проектирования с использованием больших данных вместе с вами. Комментируйте и задавайте вопросы.
Читайте также: