
Метод классификации это кратко
Обновлено: 01.07.2024
Классификация – фундаментальный метод познания действительности, делящий объект исследования на определенные классы посредством выделения существенных признаков на основе выявления их гомогенности (однородности) и гетерогенности (разнородности). Такое выделение позволяет изучить исследуемый объект более глубоко и вникнуть в его сущность путем определения состава, свойств, внутренних и внешних связей, путей использования объекта использования.
При проведении исследований выделяют.
• содержательные классификации: основу классификации составляют содержательные и особо важные классификационные признаки;
• искусственные классификации: классификационными признаками являются несущественные, вспомогательные признаки (например, классификация по алфавиту, цвету, формы и т. д.).
В исследованиях выделяют два вида классификации:
• деление общего: деление исследуемого объекта по определенному выделенному признаку на подклассы. Например, дома: жилые и нежилые, пятиэтажные и девятиэтажные и т. д.;
• разделение целого: из целого исследуемого объекта выделяются составные части по классификационному признаку, который должен отражать целостность исследуемого объекта. Например, дом состоит из фундамента, каркаса и крыши. В данном примере критерием классификации являются составные части, совокупность которых образует дом.
Выделяют разновидности классификации, следует назвать такие ее виды, как:
• декомпозиция – это вид классификации, предполагающий разделение единого целого на содержательные взаимосвязанные составные части. Например, система управления делится на подсистемы, которые делятся на компоненты, а те, в свою очередь, на элементы;
• стратификация – это вид классификации, предполагающий выделение слоев (страт) в системе управления Например, выделение внешней и внутренней среды организации.
При исследовании систем управления необходимо руководствоваться следующими классификационными принципами:
• единства классификационного критерия: осуществляя классификацию, нельзя менять критерий в рамках одной классификационной группы;
• соблюдения соразмерности деления исследуемого объекта: объем делимого объекта должен быть равен объему выделенных понятий;
• отнесения каждой однородной группы классифицируемого объекта только к одной видовой группе, выделенные понятия не могут одновременно относиться к двум классификационным группам;
• обеспечения классификационной полноты для каждой ступени классификации: не допускается деление одной части исследуемого объекта на классы, а другой – на подклассы.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
4.1. Классификация методов исследования
4.1. Классификация методов исследования Исследование – это вид деятельности человека, состоящий в распознавании проблем и ситуаций, определении их происхождения, выявлении свойств, содержания, закономерностей поведения и развития, установлении места этих проблем и
Лекция 9. Приемы научного исследования
Лекция 9. Приемы научного исследования Наиболее распространенными приемами исследования признаются анализ и синтез.Анализ – разложение исследуемого объекта на более простые составные части с целью последующего их самостоятельного изучения. Противоположным приемом,
Лекция 14. Методы исследования
Лекция 14. Методы исследования Метод исследования – это средство познания, способ проведения исследования для достижения определенного результата.Когда у организации возникают проблемы, она проводит исследование ситуации, повлекшей за собой данную проблему.Для
Лекция 16. Метод экспертных оценок
Лекция 16. Метод экспертных оценок Метод экспертных оценок – метод анализам обобщения суждений и предположений с помощью экспертов. Данный метод используют, когда рациональные математические методы малоэффективны при решении проблем. Производится интуитивно–
Лекция 17. Бизнес-план исследования
Лекция 17. Бизнес-план исследования Планирование – это одна из главных функций управления, которая представляет собой разработку этапов будущих действий с учетом возможных изменений, которые могут возникнуть в процессе реализации составленного плана. Разработанный
Лекция 18. Синектика как метод исследования систем управления
Лекция 21. Метод SWOT-анализа
Лекция 21. Метод SWOT-анализа Метод SWOT-анализа – метод, позволяющий получить общую картину развития организации при помощи изучения:• внутренней среды;• внешней среды организации.Данный метод состоит из анализа данных по внешней и внутренней среде и установления связей
Лекция 23. Эксперимент как частный метод исследования
Лекция 23. Эксперимент как частный метод исследования Эксперимент – метод исследования системы управления в определенных условиях ее функционирования, которые могут быть реальными или искусственно созданными исследователем, для получения необходимой информации.
Лекция 24. Наблюдение как частный метод исследования
Лекция 24. Наблюдение как частный метод исследования Наблюдение – метод исследования посредством сбора информации об исследуемом объекте, который осуществляется путем наблюдения за выбранным объектом исследования. При его проведении исследователь должен пользоваться
Лекция 25. Опрос как частный метод исследования
Лекция 25. Опрос как частный метод исследования Опрос – вопросно-ответный метод сбора информации об объекте исследования, которая собирается посредством обращения к опрашиваемым людям с определенными вопросами, которые содержат проблему исследования. В основе этого
Лекция 28. Метод анализа документов
Лекция 28. Метод анализа документов Метод анализа документов – метод сбора данных в ходе проведения исследований систем управления, основанный на применении информации, зафиксированной в письменной или печатной форме, на магнитной пленке, в электронном виде, в
МЕТОДЫ КЛАССИФИКАЦИИ - совокупность методов статистич. многомерного анализа. В зависимости от того, в какой области научн. знаний М.к. возникли и получили свое развитие, они наз. методами многомерной классификации, таксономии, кластерного анализа, группировки, автоматич. классификации. М.к. позволяют осуществить разбиение изучаемой совокупности объектов на отдельные группы, называемые классами, таксонами, кластерами. Разбиение производится так, что объекты, отнесенные к одному классу, считаются "похожими", близкими, однотипными, а к разным - "непохожими", далекими, разнотипными. В общем случае искомые классы определяются выполнением на них нек-рых эмпирич. закономерностей. Эти закономерности могут состоять в том, что классы определяются, напр., вполне определенными сочетаниями значений признаков; нек-рыми связями регрессионного характера между признаками; удовлетворением разбиения заданному критерию оптимальности и т. д. Объекты, подлежащие классификации, описываются совокупностью исходных признаков, на основе к-рых формируются классификационные (исходные для алгоритма) признаки. Последние могут не совпадать с исходными как по составу, так и по содержанию, т. к. могут быть получены из исходных посредством преобразования с целью взвешивания признаков, нормирования их значений, выбора среди них информационных и т. д. Эмпирич. закономерность может быть описана с помощью как классификационных, так и исходных признаков. М.к., как и др. методы, нельзя рассматривать в отрыве от тех задач, для решения к-рых они используются. М.к. применяются, как правило, в качестве инструмента анализа типологического (см.) соц. явлений с целью либо построения типологии объектов, либо проверки гипотезы существования предполагаемой типологии. В таких случаях возникновение и развитие этих методов обусловлено необходимостью достижения адекватности М.к. целям типологич. анализа. Первые алгоритмы М.к. возникли из геометрич. представления исходных (для алгоритма. данных: объекты - точки многомерного пространства классификационных признаков. "Похожесть" объектов - близость их расположения в этом пространстве; класс - сгущение объектов (близость - по значениям классификационных признаков) определенной конфигурации. М.к., основанные на геометрич. представлениях позволяют находить классы определенной конфигурации (оболочка сгущения точек). Дальнейшее развитие М.к. обусловлено необходимостью формализации различн. постановок задач построения типологии объектов адекватно их содержательным посылкам. Многообразие постановок задач порождает многообразие в формализации эмпирич. закономерностей (выполняемых на классах) и тем самым - существование различн. процедур классификации. Чтобы применить М.к., осуществить процедуру классификации, требуется задать критерий "похожести" объектов и алгоритм классификации. Искомые закономерности реализуются при задании как критерия "похожести", так и алгритма классификации. Критерий "похожести" в целом ряде методов (в т. ч. и основанных на геометрич. представлениях) задается в явном виде как мера близости (см.) между двумя объектами. В приведенных примерах в качестве меры близости использовалось евклидово расстояние. В социология. исследованиях используемые меры часто носят эвристич. характер. Важно уметь варьировать мерами близости, но не в любом алгоритме можно задавать требуемую меру. В нек-рых М.к. определенного вида мера близости уже заложена в самом алгоритме. Многие классификационные признаки носят номинальный характер. Как правило, в этом случае вся совокупность классфикационных признаков рассматривается на альтернативном уровне, исследователи пользуется соответствующими мерами. Критерий "похожести" может быть задан и исходя из того, что исследователя интересует не близость объектов по значениям классификационных признаков, а имеющая место нек-рая др. закономерность, напр. определенная связь между признаками в виде одинаковости регрессионной зависимости между всеми признаками сразу и целевым признаком (из числа неклассификационных). Алгоритм классификации - процедура, посредством к-рой на основе представлений о "похожести" объектов осуществляется разбиение объектов на классы, т. е. группы, на к-рых выполняется искомая закономерность (частично формализованная уже введением критерия "похожести объектов"). Практически любой алгоритм реализуется при определенных ограничениях, задаваемых в виде параметров М.к. Такими параметрами являются число классов, порог различимости объектов и классов и т. д. Каждый алгоритм классификации обладает рядом свойств. Наиболее важными для исследователя являются свойства, связанные с устойчивостью рез-тов классификации. Знание этих свойств облегчает выбор алгоритма и позволяет четче определить границы интерпретируемости рез-тов его применения. Таковыми свойствами являются следующие признаки. 1. Устойчивость алгоритма относительно переупорядочения объектов. Реализация М.к. предполагает нек-рую упорядоченность объектов с т. зр. порядка поступления на "вход" алгоритма (какой-то объект называется первым, какой-то - вторым и т. д.). В рез-те получаются классы, соответствующие этой упорядоченности. Меняя порядок и применяя алгоритм еще раз, получаем новый рез-т, к-рый может не совпадать с предыдущим. В случае совпадения считается, что алгоритм обладает свойством допустимости относительно переупорядоченности объектов. 2. Устойчивость алгоритма относительно дублирования классов означает, что если объекты нек-рого класса добавить (продублировать) к исходной совокупности объектов и повторить процедуру классификации, границы классов не изменятся. 3. Устойчивость относительно удаления классов. Это означает, что если объекты одного класса удалить из исходной совокупности и повторить классификацию, то границы классов не изменятся. 4. Устойчивость относительно дублирования объектов. Это свойство аналогично второму, с той лишь разницей, что вместо класса рассматривается объект. К числу важных относится и свойство, связанное с тем, что не всякая мера близости (задаваемая в явном виде) может быть использована в любом алгоритме. Это относится к тем алгоритмам, в к-рых, напр., несмотря на явную форму задания меры близости, сам алгоритм может быть реализован только при понимании близости как расстояния. Совокупность М.к. можно сгруппировать по различн. основаниям. Так, в зависимости от объема классифицируемой совокупности и от априорной информации о числе классов принято выделять три типа М.к.: иерархические, параллельные, последовательные. Это деление носит несколько условный характер. Суть иерархии, методов состоит в построении совокупности разбиений, каждое из к-рых получается из предыдущего посредством либо объединения двух и более классов (т. наз. агломеративные алгоритмы), либо разбиения классов (т. наз. дивизимные алгоритмы). В первом случае в качестве начального разбиения служит совокупность N одноэле-ментарных классов (N - число объектов), во втором - начальному разбиению подлежит один класс, состоящий из N элементов. Иерархич. методы (к ним относятся т. наз. методы ближайшего соседа, минимального внутриклассового разброса и т. д.) используются в основном для случая, когда число классов неизвестно и его определение не входит в условие классификационной задачи. Такого рода методы не рекомендуется применять для большого объема данных в силу специфики реализации этих алгоритмов. Параллельные и последовательные М.к. носят итерационный характер. Если первые из них используют параллельно (отсюда и название) все объекты исходной совокупности, то последние - только часть. Последовательные процедуры используются для анализа большого объема информации. В параллельных и последовательных процедурах число классов либо задано, либо подлежит определению. В этих процедурах реализуются различные принципы. Образование классов происходит, напр., по принципу определения мест (в пространстве признаков) наибольшей сгущенности (плотности, концентрации) точек; по принципу оптимизации т. наз. функционала качества разбиения и т. д. Введение функционала качества разбиения связано с возможностью получения разбиения, "лучшего" по нескольким параметрам. Напр., при заданном числе классов можно потребовать, чтобы объекты одного класса были более близки между собой, чем объекты разных классов. Разумеется, одновременно достичь этого невозможно. Поэтому вводится функционал качества разбиения как нек-рая функция, связывающая интересующие параметры, и отыскивается разбиение, на к-ром он принимает максимальное значение. Такого рода функционалов может быть много. Выбор одного из них обусловлен его адекватностью содержательным посылкам решаемой с помощью М.к. задачи. Напр., в качестве такого рода функционала служит сумма (по всем классам) внутригрупповых дисперсий классификационных признаков. Содержательной посылкой здесь является стремление к однородности объектов внутри класса с т. зр. "похожести" их по значениям классификационных признаков. М.к. различаются в зависимости от того, статистический или детерминистский подходы лежат в их основе (см. Анализ данных). Примерами первого являются т. наз. методы разделения смесей, модального анализа и т. д. Большинство М.к. относятся ко второму подходу. Среди них можно выделить две группы методов, ориентированные на следующие важные для социолога ситуации в характере исходных признаков: 1) признаки имеют различн. уровень измерения; 2) признаки играют в процессе классификации различн. роль: одни носят характер признаков-причин (X), другие - признаков-следствий (Y). В первом случае социологи либо переходят к дихотомич. признакам и пользуются методами, предназначенными для признаков количественного характера, либо применяют специальные методы, основанные на поиске классов, на к-рых искомые закономерности носят вид логич. функции. В качестве М.к. могут рассматриваться многие математич. методы: методы факторного анализа, если в роли признаков рассматриваются объекты; методы качественного регрессионного анализа, к-рые по своей сути являются М.к.; методы шкалирования многомерного и т. д. М.к. применяются для сжатия информации и для реализации методов типология, анализа соц. явлений. В первом случае, как правило, требуется разбиение на сравнительно небольшее число однородных групп и не стоит задача определения естественного расслоения исходных объектов, как во втором случае. Роль М.к. в типологии, анализе сводится к формализации этапа разбиения объектов на однородные группы. Как правило, в рамках одного-единственного метода невозможна такая формализация, адекватная содержательным посылкам решаемых задач. Рекомендуется последовательно-параллельное применение совокупности различн. методов. Такого рода стратегии комплексного использования методов основаны на выявлении различи. тенденций в структуре исходных данных. Примером такой стратегии является комплексное использование М.к. для проверки различ. гипотез о структуре расположения объектов в пространстве классификационных признаков (речь идет о М.к., основанных на геометрич. представлениях). В рамках этой стратегии первоначально проверяется гипотеза т. наз. компактности, соответственно для этих целей рекомендуются алгоритмы, позволяющие получить компактные классы. Тем самым определяется наличи сгущений точек посредством многократного повторения процедуры классификации при различн. значениях параметров алгоритма. Компактные классы могут иметь различ. конфигурацию. Напр., в двумерном пространстве они могут быть в виде кругов. Далее переходят к проверке гипотезы "связанности", чтобы убедиться в наличии (отсуствии) связи между отдельными компактными классами. При наличии такой связи наблюдается "цепочный эффект", и объекты одного класса могут оказаться более далекими (в смысле меры близости), чем объекты разных классов. Конфигурация классов в двумерном пространстве может иметь вид овала (метод "ближайшего соседа"), вид "облаков" (метод регрессионного характера). Проверка следующей гипотезы обусловлена тем, что в реальных задачах исходные данные плохо структурированы, т е сгущения, если они и имеются, сопровождаются "шумами". В таких ситуациях процедура классификации не дает "хорошие" (в смысле компактности и связанности) классы, резко отделенные друг от друга в признаковом пространстве. Тогда проверяется гипотеза о существовании областей с высокой концентрацией точек. В качестве М.к. для этих целей могут служить методы модального анализа, где класс - одномодальная совокупность точек, имеющая высокую концентрацию к центру. Центр является "модой", напр., это объект, вокруг к-рого находится самое большое количество точек. Проверка всех перечисленных гипотез дает представление о структуре взаимного расположения точек. При интерпретации рез-тов применения М.к. важным является выбор способов описания полученных классов. В качестве таковых могут рассматриваться, напр., распределения как классификационных, так и исходных признаков, а также показатели этих распределений. Основная цель интерпретации, как правило, - переход от формальной классификации к содержательной типологии. См. также: Группировка, Метод типологизации лингвистический, Анализ типологический.
Лит.: Зайгоруйко Н.Г., Заславская Т.И. Методы Распознавания образов в социальных исследованиях//Социология и математика. Новосибирск, 1970; Айвазян С.А., Бежаева З.И., Староверов О.В. Классификация многомерных наблюдений. М., 1977; Дюран Б., Оделл П. Кластерный анализ. М., 1977; Типология потребления. М., 1978; Саморегуляция и прогнозирование социального поведения личности. Л., 1979; Статистические методы анализа информации в социологических исследованиях. М., 1979; Социально-демографическое развитие села (региональный анализ) М., 1980; Классификация и кластер. М., 1980; Типология и классификация в социологических исследованиях. М., 1982; Рабочая книга социолога. М., 1983. Г.Г. Татарова.
Российская социологическая энциклопедия. — М.: НОРМА-ИНФРА-М . Г.В. Осипов . 1999 .
Полезное
Смотреть что такое "МЕТОДЫ КЛАССИФИКАЦИИ" в других словарях:
МЕТОДЫ КЛАССИФИКАЦИИ — – составная часть методов многомерного анализа. М. к. заключаются в разбиении совокупности объектов на отдельные классы так, что объекты, отнесенные к одному классу, считаются похожими, однотипными, близкими, а отнесенные к разным классам –… … Энциклопедический словарь по психологии и педагогике
Методы домарксистского литературоведения — I. Метод и мировоззрение. II. Проблемы историографии домарксистского литературоведения. III. Краткий обзор основных течений домарксистского литературоведения. 1. Филологическое изучение памятников слова. 2. Эстетический догматизм (Буало, Готтшед … Литературная энциклопедия
Методы электроаналитической химии — Содержание 1 Методы электроаналитической химии 2 Введение 3 Теоретическая часть … Википедия
Методы исследования понятий — группа психологических методов, направленных на изучение понятий. Содержание 1 Метод определения понятий 1.1 Результаты применения (на детях) … Википедия
Методы активного обучения — (МАО) совокупность педагогических действий и приёмов, направленных на организацию учебного процесса и создающего специальными средствами условия, мотивирующие обучающихся к самостоятельному, инициативному и творческому освоению учебного материала … Википедия
МЕТОДЫ СОЦИОЛОГИЧЕСКОГО ИССЛЕДОВАНИЯ — Подразделяются на методы сбора информации и методы её анализа. К числу первых относятся различные формы опроса (массовое анкетирование, интервью, экспертные опросы и т. д.), наблюдение, обработка документов. К числу методов анализа… … Философская энциклопедия
Методы изучения понятий — Методы исследования понятий группа психологических методов, направленных на изучение понятий. Содержание 1 Метод определения понятий 1.1 Результаты применения (на детях) … Википедия
Методы многомерного статистического анализа — Методы математической статистики, используемые для построения оптимальных планов сбора, систематизации и обработки многомерных статистических данных, направленные на выявление характера и структуры взаимосвязей между компонентами исследуемого… … Словарь социолингвистических терминов
методы многомерного статистического анализа — Методы математической статистики, нацеленные на построение оптимальных планов сбора, систематизации и обработки многомерных статистических данных. Выделяются три группы методов: 1) методы анализа многомерных распределений и их основных… … Словарь лингвистических терминов Т.В. Жеребило
Методы многомерного статистического анализа — Методы математической статистики, нацеленные на построение оптимальных планов сбора, систематизации и обработки многомерных статистических данных. Выделяются три группы методов: 1) методы анализа многомерных распределений и их основных… … Общее языкознание. Социолингвистика: Словарь-справочник
Классификация призвана решать две основные задачи: представлять в надёжном и удобном для обозрения и распознавания виде всю изучаемую область и заключать в себе максимально полную информацию о её объектах. Различают естественные и искусственные классификации в зависимости от существенности признака, который кладётся в её основу. Естественные классификации предполагают нахождение значимого критерия различения, искусственные могут быть в принципе построены на основании любого признака. Вариантом искусственных классификаций являются различные вспомогательные классификации типа алфавитных, технических и тому подобных указателей. Разные классификации по-разному справляются со своими задачами. Так, искусственная классификация, в которой группировка осуществляется на основании лишь отдельных, произвольно выбранных и удобно различимых свойств объектов, может решить только первую из указанных задач. В естественной классификации группировка происходит на основании комплекса свойств объектов, выражающих их природу, и таким образом объединяет их в естественные группы, а сами группы в единую систему. В такой классификации число свойств классифицируемых объектов, поставленных в соответствие с их положением в системе, является наибольшим по сравнению с любой другой группировкой этих объектов. Естественная классификация, в отличие от искусственной, основываясь на полноте понимания содержания классифицируемых объектов, является не просто описательно-распознавательной, а пояснительной, объясняющей причины общности свойств классификационных групп, равно как и характер отношений между группами. Известными примерами естественной классификации в науках (см. Наука) являются: периодическая система химических элементов, классификация кристаллов на основе фёдоровских групп преобразований, филогенетические систематики в биологии, генеалогическая и морфологическая классификации языков. В отличие от искусственной классификации, зачастую строящейся на прагматических основаниях, естественная классификация возникает на основе материала наблюдений и массива опытных данных той или иной области знания в результате синтеза эмпирических обобщений и теоретических представлений. В целом, естественная классификация всегда в той или иной степени является содержательно-обоснованной типологией (см. Типология), способной решать содержательные задачи и прогнозировать новые результаты.
Наряду с естественными и искусственными, различают теоретические и эмпирические классификации. Существуют и иные деления классификаций, например на общие и частные (специальные). Общие классификации содержат обзор всей области объектов определённого рода, группируют их на основании свойств, выражающих их природную общность самих по себе, и несут информацию о причине этой общности, то есть о некоторой естественной закономерности. Общие классификации имеют место в фундаментальных науках, главная задача которых состоит в объективном познании действительности через выявление доминирующих в ней законов. Тогда как частные, или специальные, классификации характерны, прежде всего, для прикладных, практических отраслей знания, целью которых является обеспечение деятельности. Предметная область частных, или специальных, классификаций более узкая, чем у общих классификаций. Они также исходят из объективных и зачастую немаловажных свойств классифицируемых объектов, но вся группировка в целом осуществляется здесь в целях удовлетворения определённых прагматических запросов. В целом, специальные классификации дополняют и расширяют то знание, которое дают общие классификации.
В логике (см. Логика) классификация является частным случаем деления — логической операции над понятиями. Деление — это распределение на группы тех предметов, которые мыслятся в исходном понятии. Получаемые в результате деления группы называются членами деления. Признак, по которому производится деление, именуется основанием деления. В каждом логическом делении имеются, таким образом, делимое понятие, основание деления и члены деления.
Классификации обычно представляются в форме деревьев или таблиц, которые в конечном итоге могут быть сведены к структуре древообразного иерархического порядка (см. Рис. № 1).
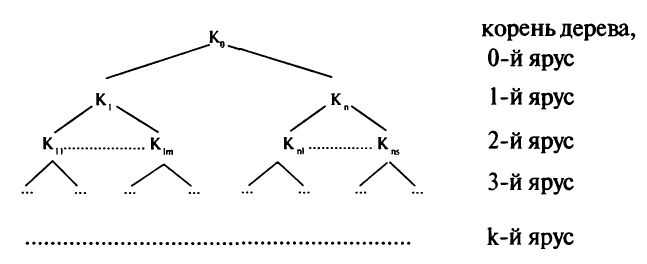 |
| Рис. № 1. Дерево классификации. |
Дерево классификации выглядит как множество точек (вершин), соединённых линиями (рёбрами). Каждая вершина представляет некоторый класс предметов (объёмов понятий), обладающих одинаковыми признаками. Эти классы называют таксонами (таксономическими единицами — см. Таксономия). Рёбра же показывают, на какие подвиды разбиваются данные таксоны. Вершина K0 называется корнем дерева. Она репрезентирует (представляет) исходное множество предметов. Таксоны группируются по ярусам. В каждом ярусе собраны таксоны, полученные в результате применения одинакового числа операций деления к исходному понятию. Те таксоны, которые в данной классификации уже далее не делятся на свои виды, называются концевыми таксонами. Предельной является такая классификация, все концевые таксоны которой представляют собой единичные понятия. Однако в зависимости от целей, которые преследуются при построении классификации, концевые таксоны могут и не быть единичными понятиями.
Логической основой построения различного рода классификаций является операция деления понятий, а потому при классифицировании предметов должны выполняться все правила деления, специфицированные относительно классификации. Так, требование, чтобы деление осуществлялось по одному основанию, сохраняется, но теперь разрешается, чтобы каждый акт деления осуществлялся по собственному основанию, отличному от оснований, которые использовались в других актах деления. Сохраняется и требование, чтобы члены деления исключали друг друга, но теперь это относится только к таксонам одного и того же яруса (ясно, что таксоны разных ярусов этому требованию удовлетворять не могут). Дополнительно вводится ещё одно требование — классификация должна быть соразмерной, то есть она должна быть непрерывной, без скачков (пропусков ярусов).
Всякая добротная классификация требует разработки соответствующей ей номенклатуры — системы однозначных наименований для всех классификационных групп. При этом номенклатура должна отличаться уникальностью, то есть каждое наименование должно быть единственным и отличным от других; универсальностью, то есть являть единый набор наименований, принятый всеми специалистами в противовес названиям тех же групп в обычных народных языках; стабильностью, исключающей произвольные изменения наименований, и вместе с тем гибкостью, допускающей неизбежные изменения названий в связи с изменениями в классификации. Проблема создания номенклатуры выступает как специальная научная задача, которая (как это имеет место, например, в биологии), может регламентироваться специальными международными кодексами. Примеры тщательно разработанных и совершенных номенклатур дают химия, ботаника, зоология.
Развитие науки показывает, что становление классификации проходит ряд этапов: от искусственных систем к выделению естественных групп и далее к установлению системы естественной классификации. Так, химические элементы первоначально группировались искусственным образом по отдельным физическим свойствам. Затем сходные элементы объединялись уже в естественные группы на основании многих и разнообразных чисто химических свойств. Открытие Д. И. Менделеевым периодической зависимости свойств химических элементов от их атомного веса позволило упорядочить сами группы в целостной системе естественной классификации. В дальнейшем система Менделеева, которая была глубоким, но всё же эмпирическим обобщением, подверглась теоретической обработке на основе учения о строении атома. Периодичность изменения свойств элементов в зависимости от их порядкового номера в системе была объяснена периодическим изменением числа электронов в наружном слое атомов. Искусственными были и первые группировки в биологии.
В XX веке задачи построения генетических и генеалогических классификаций, а также обращение к глубинным структурным началам как факторам, объясняющим эмпирические общности в химической, кристаллографической, минералогической классификациях, привлекли внимание к теоретическим аспектам классификации, а в последние десятилетия среди специалистов различных отраслей знания стал обсуждаться вопрос о создании теории классификации, долженствующей обеспечить эффективность классификационной работы в науке. При этом одни видели свою задачу в разработке частных теорий классификации, ориентированных на те или иные конкретные области естествознания, другие же задались целью построить общую теорию классификации, приложимую ко всем его областям. Задача первых вписывается в компетенцию тех конкретных наук, классификациями которых они занимаются, цель же вторых измеряется общеметодологическим масштабом (см. Методология) и представляет собой феномен методологии науки (см. Методология науки).
При изучении Data Science, я решил составить для себя конспект по основным приемам, используемым в анализе данных. В нем отражены названия методов, кратко описана суть и приведен код на Python для быстрого применения. Готовил конспект для себя, но подумал, что кому-то это также может быть полезно, например, перед собеседованием, в соревновании или при запуске нового проекта. Рассчитано на аудиторию, которая в целом знакома со всеми этими методами, но имеет необходимость освежить их в памяти. Статья под катом.
-Наивный байесовский классификатор. Формула расчета вероятности отнесения наблюдения к тому или иному классу:

Например, нужно рассчитать вероятность, что спортивный матч состоится при условии, что погода солнечная. Исходные данные и расчеты приведены в таблице ниже:

Можно посчитать по формуле (3/9) * (9/14) / (5/14) = 60%, или просто из здравого смысла 3/(2+3)=60%. Сильные стороны — легко интерпретировать результат, подходит для больших выборок и мультиклассовой классификации. Слабые стороны — не всегда выполняется предположение о независимости характеристик, характеристики должны составлять полную группу событий.
-Метод ближайших соседей. Классифицирует каждое наблюдение по степени похожести на остальные наблюдения. Алгоритм является непараметрическим (отсутствуют ограничения на данные, например, функция их распределения) и использует ленивое обучение (не применяются заранее обученные модели, все имеющиеся данные используются во время классификации).

Сильные стороны — легко интерпретировать результат, хорошо подходит для задач с малым количеством объясняющих переменных. Слабые стороны — невысокая точность по сравнению с другими методами. Требует значительных вычислительных мощностей при большом количестве объясняющих переменных и больших выборках.
-Метод опорных векторов (SVM). Каждый объект данных представляется как вектор (точка) в p-мерном пространстве. Задача — разделить точки гиперплоскостью. То есть, можно ли найти такую гиперплоскость, чтобы расстояние от неё до ближайшей точки было максимальным. Искомых гиперплоскостей может быть много, поэтому полагают, что максимизация зазора между классами способствует более уверенной классификации.
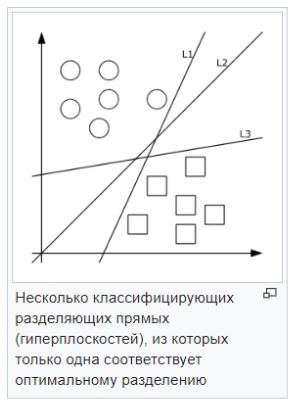
Сильные стороны — Эффективен при большом количестве гиперпараметров. Способен обрабатывать случаи, когда гиперпараметров больше, чем количество наблюдений. Существует возможность гибко настраивать разделяющую функцию. Слабые стороны — в случае, когда наблюдений меньше, чем объясняющих переменных, необходимо применять методы регуляризации, чтобы не переобучить модель. Также этот метод напрямую не дает вероятностных оценок.
-Деревья решений. Разделение данных на подвыборки по определенному условию в виде древовидной структуры. Математически разделение на классы происходит до тех пор, пока не найдутся все условия, определяющие класс максимально точно, т. е. когда в каждом классе отсутствуют представители другого класса. На практике используется ограниченное количество характеристик и слоев, а ветви всегда две.

Сильные стороны — возможно моделировать сложные процессы и легко их интерпретировать. Возможна мультиклассовая классификация. Слабые стороны — легко переобучить модель, если делать много слоев. Выбросы могут повлиять на точность, решение этих проблем — обрезать нижние уровни.
-Случайный лес/Ансамбль деревьев. Это много бустингов и деревьев решений объединенных вместе. Бустинг — случайная выборка из базовой выборки. За счет большого числа таких подвыборок (random patching) и построения на каждой своей модели увеличивается качество финальной модели за счет усреднения. Для оценки качества модели нужно применять oob-оценку.
Сильные стороны: нечувствительность к выбросам, малые требования к предобработке данных, к масштабированию, небольшая чувствительность к гиперпараметрам, разброс модели меньше, а значит она не склонна к переобучению. Так как построение деревьев независимое, то вычисления можно распараллелить. Слабые стороны — потребляет память и время, чтобы считать и хранить много деревьев. Не применять, когда признаков очень много (больше 100 000), в этом случае лучше — регрессии.
-Метод градиентного спуска. Итерационный алгоритм минимизации функции потерь (по умолчанию hinge loss function). Алгоритм также применяется в задачах прогнозирования.

Также есть версия стохастического градиентного спуска, который применяется при больших выборках. Его суть в том что он считает производную не по всей выборке, а по каждому наблюдению (online learning) (или по группе наблюдений mini-batch) и меняет веса. В итоге он приходит в тот же оптимум что и при обычном ГС. Существуют методы применения ГС для МНК, логит, тобит и других методов (доказательства).
Сильные стороны: высокая точность классификации и прогнозирования, подходит для мультиклассовой классификации. Слабые стороны — чувствительность к параметрам модели.
-Градиентный бустинг. Это ансамбли моделей. Строятся регрессии или деревья решений и минимизируется функция потерь, как в градиентном спуске. Используется, когда выборка помещается в память, есть смесь разных признаков.
Сильные стороны: высокая точность классификации и прогнозирования, подходит для мультиклассовой классификации, не чувствителен к выбросам, способен решать задачи ранжирования. Слабые стороны — требователен к ресурсам компьютера.
-Логистическая регрессия/logit. Используется для классификации от 0 до 1, доказывается методом максимального правдоподобия (log likelihood). ММП — это вероятность получить Y при заданных Х и найденных параметрах w.

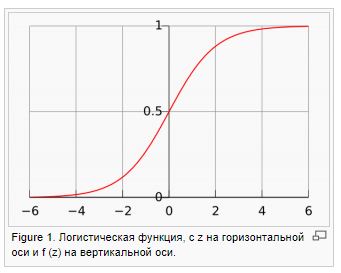
Сильные стороны: хорошо работает, когда гиперпараметры коррелируют с объясняющей переменной. Слабые стороны — подходит для бинарной классификации, слабо работает при эндогенности.
-Probit. Отличается от логит модели тем, что предполагает нормальность распределения гиперпараметров, в то время, как логит модель предполагает логистическое распределение.
-Tobit. Применяется, когда зависимая переменная ограничена и непрерывна.
Если упущен какой-либо важный метод, пожалуйста, напишите об этом в комментариях. Планируется выпуск статей по обучению без учителя, методам предобработки, методам оценки качества модели, интересным терминам и доказательствам. Спасибо за внимание.
Читайте также: