
Глубокое машинное обучение кратко
Обновлено: 02.07.2024
Всем привет. Уже в этом месяце в ОТУС стартует новый курс — "Математика для Data Science". В преддверии старта данного курса традиционно делимся с вами переводом интересного материала.

Аннотация. Глубокое обучение является передовой областью исследований машинного обучения (machine learning — ML). Оно представляет из себя нескольких скрытых слоев искусственных нейронных сетей. Методология глубокого обучения применяет нелинейные преобразования и модельные абстракции высокого уровня на больших базах данных. Последние достижения во внедрении архитектуры глубокого обучения в многочисленных областях уже внесли значительный вклад в развитие искусственного интеллекта. В этой статье представлено современное исследование о вкладе и новых применениях глубокого обучения. Следующий обзор в хронологическом порядке представляет, как и в каких наиболее значимых приложениях использовались алгоритмы глубокого обучения. Кроме того, представлены выгода и преимущества методологии глубокого обучения в ее многослойной иерархии и нелинейных операциях, которые сравниваются с более традиционными алгоритмами в обычных приложениях. Обзор последних достижений в области далее раскрывает общие концепции, постоянно растущие преимущества и популярность глубокого обучения.
В последнее время машинное обучение и интеллектуальный анализ данных попали в центр внимания и стали наиболее популярными темами среди исследовательского сообщества. Совокупность этих областей исследования анализируют множество возможностей характеризации баз данных [9]. На протяжении многих лет базы данных собирались в статистических целях. Статистические кривые могут описывать прошлое и настоящее, чтобы предсказывать будущие модели поведения. Тем не менее, в течение последних десятилетий для обработки этих данных использовались только классические методы и алгоритмы, тогда как оптимизация этих алгоритмов могла бы лечь в основу эффективного самообучения [19]. Улучшенный процесс принятия решений может быть реализован на основе существующих значений, нескольких критериев и расширенных методов статистики. Таким образом, одним из наиболее важных применений этой оптимизации является медицина, где симптомы, причины и медицинские решения создают большие базы данных, которые можно использовать для определения лучшего лечения [11].

Рис. 1. Исследования в области искусственного интеллекта (ИИ) Источник: [1].
Поскольку ML охватывает широкий спектр исследований, на данный момент уже разработано множество подходов. Кластеризация, байесовская сеть, глубокое обучение и анализ дерева решений — это только их часть. Следующий обзор в основном фокусируется на глубоком обучении, его основных понятиях, проверенных и современных применениях в различных областях. Кроме того, в нем представлены несколько рисунков, отражающих стремительный рост публикаций с исследованиями в области глубокого обучения за последние годы в научных базах данных.
Концепция глубокого обучения (Deep Learning — DL) впервые появилась в 2006 году как новая область исследований в машинном обучении. Вначале оно было известно как иерархическое обучение в [2], и как правило оно включало в себя множество областей исследований, связанных с распознаванием образов. Глубокое обучение в основном принимает в расчет два ключевых фактора: нелинейная обработка в нескольких слоях или стадиях и обучение под наблюдением или без него [4]. Нелинейная обработка в нескольких слоях относится к алгоритму, в котором текущий слой принимает в качестве входных данных выходные данные предыдущего слоя. Иерархия устанавливается между слоями, чтобы упорядочить важность данных, полезность которых следует установить. С другой стороны, контролируемое и неконтролируемое обучение связано с меткой классов целей: ее присутствие подразумевает контролируемую систему, а отсутствие — неконтролируемую.
Глубокое обучение подразумевает слои абстрактного анализа и иерархические методы. Тем не менее, оно может быть использовано в многочисленных реальных приложениях. Как пример, в цифровой обработке изображений; раскраска черно-белых изображений раньше выполнялась вручную пользователями, которым приходилось выбирать каждый цвет на основе своего собственного суждения. Применяя алгоритм глубокого обучения, раскраска может выполняться автоматически с помощью компьютера [10]. Точно так же звук может быть добавлен в видео с игрой на барабанах без звука с использованием рекуррентных нейронных сетей (Recurrent Neural Networks — RNN), которые являются частью методов глубокого обучения [18].
Глубокое обучение может быть представлено как метод улучшения результатов и оптимизации времени обработки в нескольких вычислительных процессах. В области обработки естественного языка методы глубокого обучения были применены для создания подписей к изображениям [20] и генерации рукописного текста [6]. Следующие применения детальнее классифицированы в таких областях как цифровая обработка изображений, медицина и биометрия.
3.1 Обработка изображений
До того, как глубокое обучение официально утвердилось в качестве нового исследовательского подхода, некоторые приложения были реализованы в рамках концепции распознавания образов посредством обработки слоев. В 2003 году был разработан интересный пример с применением фильтрации частиц и алгоритма распространения доверия (Bayesian – belief propagation). Основная концепция этого приложения полагает, что человек может распознавать лицо другого человека, наблюдая только половину изображения лица [14], поэтому компьютер может восстановить изображение лица из обрезанного изображения.
Позже в 2006 году жадный алгоритм и иерархия были объединены в приложение, способное обрабатывать рукописные цифры [7]. Недавние исследования применили глубокое обучение в качестве основного инструмента для цифровой обработки изображений. Например, применение сверточных нейронных сетей (Convolutional Neural Networks — CNN) для распознавания радужной оболочки может быть более эффективным, чем использование привычных датчиков. Эффективность CNN может достигать 99,35% точности [16].
Мобильное распознавание местоположения в настоящее время позволяет пользователю узнать определенный адрес на основе изображения. Алгоритм SSPDH (Supervised Semantics – Preserving Deep Hashing) оказался значительным улучшением по сравнению VHB (Visual Hash Bit) и SSFS (Space – Saliency Fingerprint Selection). Точность SSPDH аж на 70% эффективнее [15].
Наконец, еще одно замечательное применение в цифровой обработке изображений с использованием метода глубокого обучения — распознавание лиц. Google, Facebook и Microsoft имеют уникальные модели распознавания лиц с глубоким обучением [8]. В последнее время идентификация на основе изображения лица изменилась на автоматическое распознавание путем определения возраста и пола в качестве исходных параметров. Sighthound Inc., например, тестировали алгоритм глубокой сверточной нейронной сети, способный распознавать не только возраст и пол, но даже эмоции [3]. Кроме того, была разработана надежная система для точного определения возраста и пола человека по одному изображению путем применения архитектуры глубокого многозадачного обучения [21].
3.2 Медицина
Цифровая обработка изображений, несомненно, является важной частью исследовательских областей, где может применяться метод глубокого обучения. Таким же образом, недавно тестировались клинические приложения. Например, сравнение между малослойным обучением и глубоким обучением в нейронных сетях привело к лучшей эффективности в прогнозировании заболеваний. Изображение, полученное с помощью магнитно-резонансной томографии (МРТ) [22] из головного мозга человека, было обработано, чтобы предсказать возможную болезнь Альцгеймера [3]. Не смотря на быстрый успех этой процедуры, некоторые проблемы должны быть серьезно рассмотрены для будущих применений. Одними из ограничений являются тренировка и зависимость от высокого качества. Объем, качество и сложность данных являются сложными аспектами, однако интеграция разнородных типов данных является потенциальным аспектом архитектуры глубокого обучения [17, 23].
Оптическая когерентная томография (ОКТ) является еще одним примером, где методы глубокого обучения показывают весомые результаты. Традиционно изображения обрабатываются путем ручной разработки сверточных матриц [12]. К сожалению, отсутствие учебных наборов ограничивает метод глубокого обучения. Тем не менее, в течение нескольких лет внедрение улучшенных тренировочных наборов будет эффективно предсказывать патологии сетчатки и уменьшать стоимость технологии ОКТ [24].
3.3 Биометрия
В 2009 году было применено приложение для автоматического распознавания речи, чтобы уменьшить частоту телефонных ошибок (Phone Error Rate — PER) с использованием двух разных архитектур сетей глубокого доверия [18]. В 2012 году метод CNN [25] был применен в рамках гибридной нейронной сети — скрытой модели маркова (Hybrid Neural Network — Hidden Markov Model — NN — HMM). В результате был достигнут PER на уровне 20,07%. Полученный PER лучше по сравнению с ранее применяемым 3-слойным методом базовой линии нейронной сети [26]. Смартфоны и разрешение их камер были протестированы для распознавания радужной оболочки. При использовании мобильных телефонов, разработанных различными компаниями, точность распознавания радужной оболочки может достигать до 87% эффективности [22,28].
С точки зрения безопасности, особенно контроля доступа; глубокое обучение используется в сочетании с биометрическими характеристиками. DL был использован для ускорения разработки и оптимизации устройств распознавания лиц FaceSentinel. По словам этого производителя, их устройства могут расширить процесс идентификации с одного-к-одному до одного-к-многим за девять месяцев [27]. Это усовершенствование движка могло бы занять 10 человеко-лет без внедрения DL. Что ускорило производство и запуск оборудования. Эти устройства используются в лондонском аэропорту Хитроу, а также могут использоваться для учета рабочего времени и посещаемости, и в банковском секторе [3, 29].
Таблица 1 подытоживает несколько применений, реализованных в течение предыдущих лет относительно глубокого обучения. В основном упоминаются распознавание речи и обработка изображений. В этом обзоре рассматриваются только некоторые из большого списка применений.
Таблица 1. Применения глубокого обучения, 2003–2017 гг.

(Применение: 2003 — Иерархический байесовский вывод в зрительной коре; 2006 — Классификация цифр; 2006 — Глубокая сеть доверия для телефонного распознавания; 2012 — Распознавание речи из множественных источников; 2015 — Распознавание радужки глаза с помощью камер смартфонов; 2016 — Освоение игры Го глубокими нейронными сетями с поиском по дереву; 2017 — Модель сенсорного распознавания радужки).
4.1 Анализ публикаций за год
На рис. 1 приведено количество публикаций по глубокому обучению из базы данных ScienceDirect в год с 2006 по июнь 2017 года. Очевидно, что постепенное увеличение числа публикаций мог бы описать экспоненциальный рост.
На рис. 2 представлено общее количество публикаций по глубокому обучению в Springer в год с января 2006 года по июнь 2017 года. В 2016 году наблюдается внезапный рост публикаций, достигающий 706 публикаций, что доказывает, что глубокое обучение действительно в центре внимания современных исследований.
На рис. 3 показано количество публикаций на конференциях, в журналах и изданиях IEEE с января 2006 года по июнь 2017 года. Примечательно, что с 2015 года количество публикаций значительно увеличилось. Разница между 2016 и 2015 годами составляет более 200% прироста.

Рис. 1. Рост количества публикаций по глубокому обучению в базе данных Sciencedirect (январь 2006 г. — июнь 2017 г.)

Рис. 2. Рост количества публикаций по глубокому обучению из базы данных Springer. (январь 2006 г. — июнь 2017 г.)

Рис. 3. Рост публикаций в по глубокому обучению из базы данных IEEE. (январь 2006 г. — июнь 2017 г.)
Глубокое обучение — действительно быстро растущее применение машинного обучения. Многочисленные приложения, описанные выше, доказывают его стремительное развитие всего за несколько лет. Использование этих алгоритмов в разных областях показывает его универсальность. Анализ публикаций, выполненный в этом исследовании, ясно демонстрирует актуальность этой технологии и дает четкую иллюстрацию роста глубокого обучения и тенденций в отношении будущих исследований в этой области.
Кроме того, важно отметить, что иерархия уровней и контроль в обучении являются ключевыми факторами для разработки успешного приложения в отношении глубокого обучения. Иерархия важна для соответствующей классификации данных, в то время как контроль учитывает важность самой базы данных как части процесса. Основная ценность глубокого обучения заключается в оптимизации существующих приложений в машинном обучении благодаря инновационности иерархической обработки. Глубокое обучение может обеспечить эффективные результаты при цифровой обработке изображений и распознавании речи. Снижение процента ошибок (от 10 до 20%) явно подтверждает улучшение по сравнению с существующими и проверенными методами.
В нынешнюю эпоху и в будущем глубокое обучение может стать полезным инструментом безопасности благодаря сочетанию распознавания лиц и речи. Помимо этого, цифровая обработка изображений является областью исследований, которая может применяться в множестве других областей. По этой причине и доказав истинную оптимизацию, глубокое обучение является современным и интересным предметом развития искусственного интеллекта.
В этой статье сравнивается глубокое обучение и машинное обучение, а также описывается, как эти технологии соотносятся с более широким понятием искусственного интеллекта. Узнайте о решениях для глубокого обучения, которые можно создавать с помощью Машинного обучения Azure, предназначенных для обнаружения мошенничества, распознавания речи и лиц, анализа тональности и прогнозирования временных рядов.
Рекомендации по выбору алгоритмов для конкретных решений см. на странице Памятка по алгоритмам Машинного обучения.
Глубокое обучение, машинное обучение и искусственный интеллект

Рассмотрим следующие определения для понимания глубокого обучения в сравнении с машинным обучением и искусственным интеллектом.
Глубокое обучение — это разновидность машинного обучения на основе искусственных нейронных сетей. Процесс обучения называется глубоким, так как структура искусственных нейронных сетей состоит из нескольких входных, выходных и скрытых слоев. Каждый слой содержит единицы, преобразующие входные данные в сведения, которые следующий слой может использовать для определенной задачи прогнозирования. Благодаря этой структуре компьютер может обучаться с помощью собственной обработки данных.
Машинное обучение — это подмножество искусственного интеллекта, при котором используются методы (например, глубокое обучение), позволяющие компьютерам использовать опыт для совершенствования в решении задач. Процесс обучения основан на следующих действиях.
- Передача данные в алгоритм. (На этом шаге можно передать в модель дополнительные сведения, например, путем получения дополнительных данных).
- Эти данные используются для обучения модели.
- Тестирование и развертывание модели.
- Использование развернутой модели для автоматизированного решения задачи на основе прогнозирования. (Иными словами, вызовите и используйте развернутую модель для получения прогнозов, возвращаемых моделью).
Искусственный интеллект (ИИ) — это методика, которая позволяет компьютерам имитировать человеческий интеллект. Сюда же относится и машинное обучение.
С помощью приемов машинного обучения и глубокого обучения можно создавать компьютерные системы и приложения, которые выполняют задачи, обычно поручаемые людям. К этим задачам относятся распознавание изображений, распознавание речи и языковой перевод.
Методы глубокого обучения и машинного обучения
Теперь, когда получены общие сведения о машинном обучении и глубоком обучении, давайте сравним эти два метода. При машинном обучении алгоритму необходимо сообщить, как выполнять точный прогноз, используя дополнительные сведения (например, путем получения данных). В случае глубокого обучения алгоритм сможет обучиться, как создавать точный прогноз путем самостоятельной обработки данных с помощью структуры искусственных нейронных сетей.
В следующей таблице приведено более подробное сравнение этих двух методов.
| Все машинное обучение | Только глубокое обучение | |
|---|---|---|
| Количество точек данных | Для создания прогнозов можно использовать небольшие объемы данных. | Необходимо использовать большие объемы обучающих данных для создания прогнозов. |
| Зависимость от оборудования | Может работать на маломощных компьютерах. Не требуются крупные вычислительные мощности. | Зависит от высокопроизводительных компьютеров. При этом компьютер, по сути, выполняет большое количество операций перемножения матрицы. Графический процессор может эффективно оптимизировать эти операции. |
| Процесс конструирования признаков | Требует точного определения признаков и их создания пользователями. | Распознает признаки высокого уровня на основе данных и самостоятельно создает новые признаки. |
| Подход к обучению | Процесс обучения разбивается на мелкие шаги. Затем результаты выполнения каждого шага объединяются в единый блок выходных данных. | Задача решается методом сквозного анализа. |
| Время выполнения | Обучение занимает сравнительно мало времени — от нескольких секунд до нескольких часов. | Как правило, процесс обучения занимает много времени, поскольку алгоритм глубокого обучения включает много уровней. |
| Выходные данные | Выходными данными обычно является числовое значение, например оценка или классификация. | Выходные данные могут иметь несколько форматов, например текст, оценка или звук. |
Что собой представляет передача обучения?
Обучение моделей глубокого обучения часто требует большого количества обучающих данных, наличия ресурсов для высокопроизводительных вычислений (GPU, TPU) и временных затрат. В случаях, когда доступ к таким ресурсам отсутствует, можно попытаться упростить процесс обучения с помощью методики, известной как перенос обучения.
Перенос обучения — это метод, при котором знания, полученные в результате решения одной задачи, переносятся на другую задачу, связанную с первой.
Структура нейронных сетей такова, что первый набор слоев обычно содержит признаки более низкого уровня, а последний — признаки более высокого уровня, которые нас интересуют. Используя последние слои применительно к новой задаче или области рассмотрения, можно значительно сократить количество времени, данных и вычислительных ресурсов, необходимых для обучения новой модели. Например, у вас имеется модель, которая распознает легковые автомобили, можно переориентировать эту модель путем переноса обучения, чтобы начать распознавать грузовики, мотоциклы и другие виды транспортных средств.
Узнайте, как применить перенос обучения для классификации изображений с помощью платформы с открытым кодом в Машинном обучении Azure. Проведите обучение модели PyTorch глубокого обучения при помощью переноса обучения.
Варианты использования машинного обучения
Благодаря структуре искусственной нейронной сети глубокое обучение прекрасно справляется с поиском закономерностей в неструктурированных данных, таких как изображения, звук, видео и текст. По этой причине глубокое обучение ведет к быстрым преобразованиям в различных отраслях, включая здравоохранение, электроэнергетику, финансы и транспорт. Эти отрасли теперь реорганизуют традиционные бизнес-процессы.
Некоторые из наиболее распространенных применений глубокого обучения проводятся в следующих абзацах. При Машинном обучении Azure можно использовать модель, построенную с помощью платформы на базе открытого исходного кода, или построить модель с помощью предоставляемых средств.
Распознавание именованных сущностей
Распознавание именованных сущностей — это метод глубокого обучения, который воспринимает фрагмент текста в качестве входных данных и преобразует его в предварительно определенный класс. Эта новая информация может быть почтовым индексом, датой или кодом продукта. Затем эти сведения можно хранить в структурированной схеме для создания списка адресов или служить эталоном для подсистемы проверки кода.
Обнаружение объектов
Глубокое обучение зачастую применяется для обнаружения объектов. Обнаружение объектов состоит из двух частей: классификация изображения и его локализация. Классификация изображений распознает изображения объектов (например, автомобилей или людей). Локализация изображений дает конкретное местоположение этих объектов.
Обнаружение объектов уже используется в таких отраслях, как компьютерные игры, розничная торговля, туризм и автомобили с системой автоматического вождения.
Создание заголовка изображения
Как и при распознавании изображений, при создании заголовков изображений система должна создать заголовок, описывающий содержание конкретного изображения. Если у вас имеется технология, позволяющая обнаруживать и помечать объекты на фотографиях, следующим шагом станет преобразование этих меток в описательные предложения.
Как правило, приложения для создания описаний используют сначала сверточные нейронные сети, а затем рекуррентные нейронные сети для преобразования меток в связные предложения.
Машинный перевод
Машинный перевод воспринимает слова или предложения на одном языке и автоматически переводит их на другой язык. Машинный перевод существует уже давно, однако сейчас глубокое обучение позволяет получать впечатляющие результаты в двух конкретных областях: автоматический перевод текста (и перевод речи в текст), а также автоматическое преобразование изображений.
С помощью соответствующего преобразования данных нейронная сеть может понимать текст, звук и визуальные сигналы. Машинный перевод можно использовать для распознавания фрагментов звука в больших звуковых файлах и преобразовывать устную речь или изображения в текст.
Текстовая аналитика
Анализ текста, основанный на методах глубокого обучения, подразумевает анализ больших объемов текстовых данных (например, медицинских документов или денежных чеков), распознавание закономерностей и получение упорядоченной и систематизированной информации.
Компании используют глубокое обучение для анализа текста, чтобы обнаруживать торговлю инсайдерской информацией и обеспечивать соответствие требованиям законодательства. Еще один распространенный пример — мошенничество в области страхования: машинный анализ текста часто используется для анализа больших объемов документов, чтобы распознать случаи возможного мошенничества, выдаваемые за страховой случай.
Искусственные нейронные сети
Искусственные нейронные сети формируются с помощью слоев связанных узлов. В моделях глубокого обучения используются нейронные сети с большим количеством уровней.
В следующих разделах рассматриваются наиболее популярные типы искусственных нейронных сетей.
Нейронная сеть с передачей по очереди
Нейронная сеть с передачей по очереди — это наиболее простой тип искусственной нейронной сети. В сети с передачей по очереди информация перемещается только в одном направлении от входного уровня к выходному. Нейронные сети с передачей по очереди преобразуют входные данные, пропуская их через несколько скрытых слоев. Каждый слой состоит из набора нейронов и полностью соединен со всеми нейронами в предыдущем слое. Последний полностью соединенный слой (выходной слой) представляет собой вывод созданных прогнозов.
Рекуррентная нейронная сеть (RNN)
Рекуррентные нейронные сети — это широко используемые искусственные нейронные сети. Эти сети сохраняют выходные данные слоя и передают его обратно на входной слой, чтобы улучшить прогнозирование на выходе конкретного слоя. У рекуррентных нейронных сетей отличные возможности для обучения. Они широко используются для выполнения сложных задач, таких как прогнозирование временных рядов, обучение распознаванию рукописного ввода и распознавание естественной речи.
Сверточные нейронные сети (CNN)
Сверточная нейронная сеть — это особо эффективная искусственная нейронная сеть, имеющая уникальную архитектуру. Слои в ней организованы в трех измерениях: ширина, высота и глубина. Нейроны в одном слое соединяются не со всеми нейронами в следующем слое, а только с небольшой областью нейронов этого слоя. Окончательный результат сокращается до одного вектора оценки вероятности, упорядоченного по глубине в одном из измерений.
Сверточные нейронные сети используются в таких областях, как распознавание видео, распознавание изображений и в системах выработки рекомендаций.
Генеративно-состязательная сеть (GAN)
Генеративно-состязательные сети — это регенеративные модели, обученные для создания реалистичного содержимого, например изображений. Каждая такая сеть состоит из двух сетей, известных как генератор и дискриминатор. Обе сети обучаются одновременно. Во время обучения генератор использует случайные помехи для создания новых искусственных данных, которые похожи на реальные данные. Дискриминатор принимает выходные данные генератора в качестве входных данных и использует реальные данные, чтобы определить, является ли созданное содержимое реальным или искусственным. Каждая из сетей конкурирует друг с другом. Генератор пытается создать искусственное содержимое, которое не отличается от реального содержимого, в то время как дискриминатор пытается правильно классифицировать входные данные либо как реальные, либо как искусственные. Затем выходные данные используются для обновления веса обеих сетей, чтобы помочь им лучше достичь соответствующих целей.
Генеративно-состязательные сети используются для решения таких проблем, как преобразование изображений в изображения и прогресса возраста.
Преобразователи
Преобразователи — это архитектура модели, которая подходит для решения проблем, содержащих такие последовательности, как текст или данные временных рядов. Они состоят из слоев кодировщика и декодера. Кодировщик принимает входные данные и сопоставляет их с числовым представлением, содержащим определенные сведения, например контекст. Декодер использует информацию из кодировщика для получения выходных данных, например переведенного текста. Преобразователи отличаются от других архитектур, содержащих кодировщики и декодеры, своими вложенными слоями внимания. Внимание: метод концентрации на конкретных частях входных данных на основе важности их контекста относительно других входных данных в последовательности. Например, при суммировании новостных статей не все предложения важны для описания основной идеи. Если сосредоточиться на ключевых словах в статье, формирование сводных данных может быть сделано в одном предложении — в заголовке.
Преобразователи используются для решения проблем обработки естественного языка, таких как перевод, создание текста, ответы на вопросы и формирование сводных данных текста.
Вот некоторые известные примеры реализации преобразователей:
- Двунаправленные представления кодировщика из преобразователей (BERT)
- Генеративный предварительно обученный трансформатор 2 (GPT-2)
- Генеративный предварительно обученный трансформатор 3 (GPT-3)
Следующие шаги
В следующих статьях приведены дополнительные варианты использования моделей глубокого обучения с открытым кодом в Машинном обучении Azure.
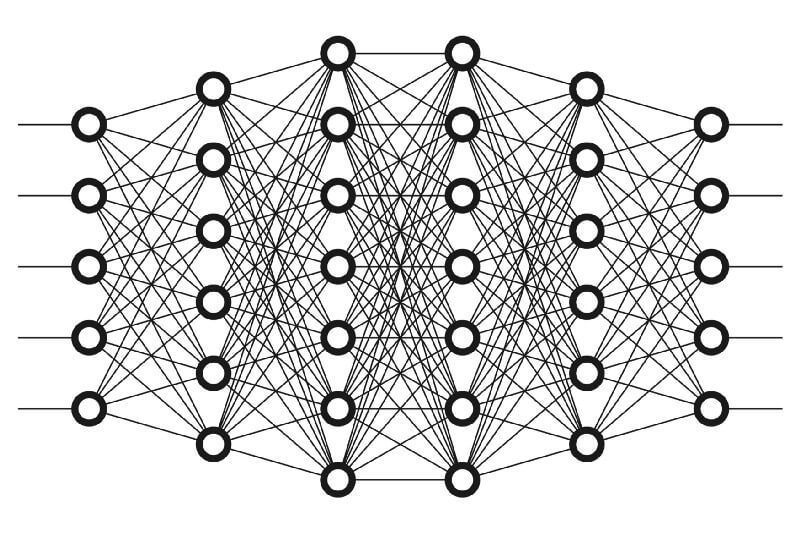
Искусственный интеллект — это модель человеческого интеллекта в компьютере.
В самом начале работы над ИИ учёные пытались смоделировать интеллект человека для решения конкретных задач, например, играть в игры. Они вводили огромное количество правил, которые компьютер должен был соблюдать. У компьютера был некоторый список возможных действий, и он принимал решения, отталкиваясь от этих правил.
Машинное обучение обозначает способность компьютера обучаться на основе массивных наборов данных, а не руководствуясь сложно закодированными правилами.
МО позволяет компьютерам учиться самостоятельно без помощи человека. Такой метод обучения возможен благодаря вычислительным мощностям современных компьютеров, которые способны быстро обрабатывать большие массивы данных.
Например, обученный с учителем ИИ, который предсказывает погоду. Такая система учится делать прогнозы на основе архивов метеорологических данных. Эти обучающие массивы включают как входные данные (атмосферное давление, влажность, скорость ветра), так и эталонные выходы (температура).
При обучении без учителя испытуемая система должна научиться логически обрабатывать данные без вмешательства экспериментаторов.
Примером такого вида обучения может быть ИИ, который предугадывает поведение пользователей онлайн-магазинов. Здесь система будет учиться не на предоставленных наборах данных с заданными стимулами и ожидаемыми ответами, а самостоятельно классифицировать входные данные и вычислять, какой тип пользователей с большей вероятностью купит тот или иной продукт.
Глубокое обучение — один из методов МО. Он позволяет научить ИИ предсказывать ответы на основе заданного набора стимулов. Для тренировки ИИ может применяться обучение и с учителем, и без учителя.
Как работает глубокое обучение можно рассмотреть на примере обученного с учителем сервиса, который рассчитывает стоимость авиабилетов. Система расчёта стоимости авиабилетов будет предсказывать цены на основе следующих входных данных:
- местонахождение аэропорта;
- планируемый пункт назначения;
- дата вылета;
- авиакомпания.
Нейронные сети

Нейроны сгруппированы в три слоя:
- входной слой;
- скрытый слой (их может быть несколько);
- выходной слой.
Выходной слой выводит полученный ответ — в данном случае, предполагаемую цену билета.


Тренировка нейросети
Тренировка ИИ — самая сложная часть глубокого обучения, потому что:
- требует обширных наборов данных;
- требует высоких вычислительных мощностей.
В примере с системой расчёта стоимости билетов необходимо найти архивы данных о стоимости билетов. А с учётом множества возможных комбинаций пунктов отправления и назначения, потребуется весьма немалый список цен на билеты.
Для тренировки ИИ в систему нужно ввести входные данные из массива, а потом сравнить её выходные данные с выходными данными из массива. Так как система ещё не обучена, её ответы будут содержать много ошибок.
Как уменьшить функцию потерь
Чтобы уменьшить функцию потерь, нужно по-другому расставить коэффициенты веса связей между нейронами. Менять в произвольном порядке, пока не будет достигнут нужный результат, достаточно неэффективно, и вместо этого используется метод градиентного спуска.
Градиентный спуск — метод, который позволяет находить минимальное значение функций, в данном случае — минимальное значение функции потерь. В этом методе вес понемногу изменяется после каждого прохождения набора данных через нейросеть. Подсчитав производную, или градиент, функции потерь при заданном распределении весов, можно вычислить, в какой точке находится наименьшее значение функции.

Существует много других типов нейронных сетей, например, свёрточные нейросети для машинного зрения и рекуррентные нейросети для обработки естественных языков. Технические аспекты глубокого обучения подробно освещают различные онлайн-курсы. Например, подобный курс недавно запустил Google.

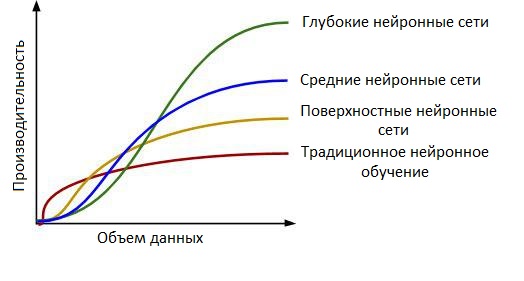
Глубокое обучение (англ. deep learning) — совокупность широкого семейства методов машинного обучения, основанных на имитации работы человеческого мозга в процессе обработки данных и создания паттернов, используемых для принятия решений [1] . Как правило, глубокое обучение предназначено для работы с большими объемами данных и использует сложные алгоритмы для обучения модели [2] . На больших датасетах глубокое обучение показывает более высокую точность результатов в сравнении с традиционным машинным обучением. Зависимость производительности (качества результатов) от объема данных представлена на рисунке ниже.
Несмотря на то, что данный раздел машинного обучения появился еще в 1980-х, до недавнего времени его применение было сильно ограничено из-за недостатка вычислительных мощностей существовавших компьютеров. Ситуация изменилась только в середине 2000-х.
На создание моделей глубокого обучения оказали влияние некоторые процессы и паттерны, происходящие в биологических нейронных системах. Несмотря на это, данные модели во многом отличаются от биологического мозга (и в структуре и в функциях), что делает невозможным использование теорем и доказательств, применяющихся в нейробиологии.
Содержание
- 1943 — Искусственный нейрон Маккаллока — Питтса [3] — узел искусственной нейронной сети, являющийся упрощённой моделью естественного нейрона;
- 1949 — Принцип обучения нейронов Хебба [4] — изначально наблюдаемая причинно-следственная связь между активациями пре- и постсинаптического нейрона имеет тенденцию к усилению;
- 1957 — Модель перцептрона предложена Фрэнком Розенблаттом [5] — математическая или компьютерная модель восприятия информации мозгом;
- 1960 — Дельта-правило обучения перцептрона [6] — метод обучения перцептрона по принципу градиентного спуска по поверхности ошибки;
- 1969 — Выход книги Марвина Минска и Сеймура Паперта "Перцептроны" [7] . В данной книге математически показаны ограничения перцептронов;
- 1974 — Метод обратного распространения ошибки впервые предложен А. И. Галушкиным и Дж. Вербосом [8] — метод вычисления градиента, который используется при обновлении весов многослойного перцептрона;
- 1980 — Первая свёрточная нейронная сеть предложена Кунихико Фукусимой [9] — специальная архитектура искусственных нейронных сетей использующая некоторые особенности зрительной коры;
- 1982 — Рекуррентные нейронные сети предложены Д. Хопфилдом — вид нейронных сетей, где связи между элементами образуют направленную последовательность;
- 1991 — Проблема "исчезающего" градиента была сформулирована С. Хочрейтом. Проблема "исчезающего" градиента заключается в быстрой потере информации с течением времени;
- 1997 — Долгая краткосрочная память предложена С. Хочрейтом и Ю. Шмидхубером [10] . В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными промежутками с неопределённой продолжительностью и границами;
- 1998 — Градиентный спуск для сверточных нейронных сетей предложен Я. Лекуном;
- 2006 — Публикации Г. Хинтона, С. Осиндера и Я. Теха об обучении сетей глубокого доверия. Данные публикации, а также их активное освещение в средствах массовой информации смогли привлечь внимание ученых и разработчиков со всего мира к глубоким сетям;
- 2012 — Предложение дропаута Г. Хинтоном, А. Крижевски и И. Шутковичем [11] . Дропаут (от англ. dropout) — метод регуляризации искусственных нейронных сетей, предназначен для предотвращения переобучения сети;
- 2012 — Нейронные сети побеждают в ImageNet Challenge [12] . Данное событие ознаменовало начало эры нейронных сетей и глубокого обучения;
- 2014 — Группа исследователей под руководством Зеппа Хохрейтера использовала глубокое обучение для определения токсичного воздействия лекарств и бытовых средств на окружающую среду. Данна работа была отмечена первым местом на соревновании "Tox21 Data Challenge" [13] ;
- 2016 — Программа для игры в го Google AlphaGo выиграла со счётом 4:1 у Ли Седоля, лучшего международного игрока в эту игру. AlphaGo, разработанная DeepMind, использует глубокое обучение с помощью многоуровневых нейронных сетей;
- 2018 — Глубокое обучение впервые используется для планирования лучевой терапии [14] .
В настоящее время глубокое обучение используется во многих сферах.
Глубокое обучение — это класс алгоритмов машинного обучения, который:
- Использует многослойную систему нелинейных фильтров для извлечения признаков с преобразованиями. Каждый последующий слой получает на входе выходные данные предыдущего слоя;
- Может сочетать алгоритмы обучения с учителем [на 28.01.19 не создан] (пример — классификация) и без учителя [на 28.01.19 не создан] (пример — анализ образца);
- Формирует в процессе обучения слои выявления признаков на нескольких уровнях представлений, которые соответствуют различным уровням абстракции; при этом признаки организованы иерархически — признаки более высокого уровня являются производными от признаков более низкого уровня;

- Распознавание речи [15] . Все основные коммерческие системы распознавания речи (например, Microsoft Cortana, Xbox, Skype Translator, Amazon Alexa, Google Now, Apple Siri, Baidu и iFlyTek) основаны на глубоком обучении;
- Компьютерное зрение [на 28.01.19 не создан] . На сегодняшний день системы распознавания образов основанные на глубоком обучении уже умеют давать более точные результаты, чем человеческий глаз [16] ;
- Обработка естественного языка [17] . Нейронные сети использовались для реализации языковых моделей еще с начала 2000-х годов. Изобретение LSTM помогло улучшить машинный перевод и языковое моделирование [18] ;
- Обнаружение новых лекарственных препаратов. К примеру, нейронная сеть AtomNet использовалась для прогнозирования новых биомолекул — кандидатов для лечения таких заболевания, как вирус Эбола и рассеянный склероз;
- Рекомендательные системы [19] . На сегодняшний день глубокое обучение применяется для изучения пользовательских предпочтений во многих доменах;
- Предсказание генномных онтологий в биоинформатике [20] .
Полный список возможных применений глубокого обучения [21] .
![]()
Transfer learning — это применение к решению задачи знаний, извлеченных нейронной сетью при решении другой задачи.
Глубокие нейронные сети требуют больших объемов данных для сходимости обучения. Поэтому часто встречается ситуация, когда для решаемой задачи недостаточно данных для того, чтобы хорошо натренировать все слои нейросети. Для решения этой проблемы и используется transfer learning [22] .
Чаще всего transfer learning выглядит следующим образом: к натренированной на определенную задачу нейросети добавляется еще несколько скрытый слоев, которые позволяют использовать уже полученные знания для решения более конкретной задачи. Например, знания, полученные при обучении распознаванию различных предметов, могут применяться при решении задачи распознавания еды.
- TensorFlow [23] ;
- Microsoft Cognitive Toolkit [24] ;
- Wolfram Mathematica [25] ;
- Keras [26] ;
- Deeplearning4j [27] ;
- Caffe [28] ;
- Torch/PyTorch [29] ;
- MXNet [30] ;
- Chainer [31] .
Сопоставление фреймворков, библиотек и отдельных программ для глубокого обучения [32] .
Читайте также: