
Обработка информации и алгоритмы 10 класс доклад
Обновлено: 04.07.2024
Теоретический материал для самостоятельного изучения:
В основе любой информационной деятельности лежат так называемые информационные процессы — совокупность последовательных действий (операций), производимых над информацией для получения какого-либо результата (достижения цели). Информационные процессы могут быть различными, но все их можно свести к трем основным: обработка информации, передача информации и хранение информации.
Обработка информации
Обработка информации — это целенаправленный процесс изменения формы ее представления или содержания.
Из курса информатики основной школы вам известно, что существует два различных типа обработки информации:
- обработка, связанная с получением новой информации (например, нахождение ответа при решении математической задачи; логические рассуждения и др.);
- обработка, связанная с изменением формы представления информации, не изменяющая ее содержания. К этому типу относятся:
— кодирование — переход от одной формы представления информации к другой, более удобной для восприятия, хранения, передачи или последующей обработки; один из вариантов кодирования — шифрование, цель которого — скрыть смысл информации от посторонних;
— структурирование — организация информации по некоторому правилу, связывающему ее в единое целое (например, сортировка);
— поиск и отбор информации, требуемой для решения некоторой задачи, из информационного массива (например, поиск в словаре).
Общая схема обработки информации может быть представлена следующим образом:

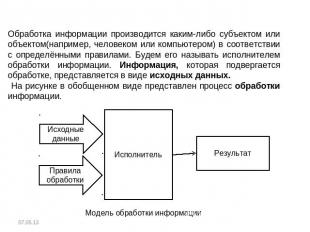
Исходные данные — это информация, которая подвергается обработке.
Правила — это информация процедурного типа. Они содержат сведения для исполнителя о том, какие действия требуется выполнить, чтобы решить задачу.
Исполнитель — тот объект, который осуществляет обработку. Это может быть человек или компьютер. При этом человек, как правило, является неформальным, творчески действующим исполнителем. Компьютер же способен работать только в строгом соответствии с правилами, т.е. является формальным исполнителем обработки информации.
Рассмотрим отдельные процессы обработки информации более подробно.
Кодирование информации
Кодирование информации — это обработка информации, заключающаяся в ее преобразовании в некоторую форму, удобную для хранения, передачи, обработки информации в дальнейшем.
Код — это система условных обозначений (кодовых слов), используемых для представления информации.
Кодовая таблица — это совокупность используемых кодовых слов и их значений.
Нам уже знакомы примеры равномерных двоичных кодов — пятиразрядный код Бодо и восьмиразрядный код ASCII.
Самый известный пример неравномерного кода — код Морзе. В этом коде все буквы и цифры кодируются в виде различных последовательностей точек и тире.

При использовании неравномерных кодов важно понимать, сколько различных кодовых слов они позволяют построить.
Пример 1. Имеющаяся информация должна быть закодирована в четырехбуквенном алфавите . Выясним, сколько существует различных последовательностей из 7 символов этого алфавита, которые содержат ровно пять букв А.
Нас интересует семибуквенная последовательность, т. е.

Если бы у нас не было условия, что в ней должны содержаться ровно пять букв А, то для первого символа было бы 4 варианта, для второго — тоже 4, и т. д.
Тогда мы получили бы: 4 · 4 · 4 · 4 · 4 · 4 · 4 = 16384 варианта.
Теперь вернемся к имеющемуся условию и заполним пять первых мест буквой А. Получим:

Так как на 6-м и 7-м местах могут стоять любые из трех оставшихся букв B, C, D, то всего существует 9 (3 · 3) вариантов последовательностей.
Но ведь буквы А могут находиться на любых пяти из семи имеющихся позиций. А сколько таких вариантов всего?
Префиксный код — код со словом переменной длины, обладающий тем свойством, что никакое его кодовое слово не может быть началом другого (более длинного) кодового слова.
- Код, состоящий из слов 0, 10 и 11, является префиксным.
- Код, состоящий из слов 0, 10, 11 и 100, не является префиксным.
Также достаточным условием однозначного декодирования неравномерного код является обратное условие Фано. В нем требуется, чтобы никакой код не был окончанием другого (более длинного) кода.
Пример 2. Двоичные коды для 5 букв латинского алфавита представлены в таблице:

Можно заметить, что для заданных кодов не выполняется прямое условие Фано:
B=01, E=011, и D=10, C=100.
А вот обратное условие Фано выполняется: никакое кодовое слово не является окончанием другого. Следовательно, имеющуюся строку нужно декодировать справа налево (с конца). Получим
01 10 100 011 000 = BDCEA
Для построения префиксных кодов удобно использовать бинарные деревья, в которых от каждого узла отходят только два ребра, помеченные цифрами 0 и 1.
Пример 3. Для кодирования некоторой последовательности, состоящей из букв А, Б, В и Г, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. При этом используются такие кодовые слова: А — 0, Б — 10, В — 110. Каким кодовым словом может быть закодирована буква Г? Если таких слов несколько, укажите кратчайшее из них.
Построим бинарное дерево:

Чтобы найти код символа, нужно пройти по стрелкам от корня дерева к нужному листу, выписывая метки стрелок, по которым мы переходим.
Определим положение букв А, Б и В на этом дереве, зная их коды. Получим:

Чтобы код был префиксным, ни один символ не должен лежать на пути от корня к другому символу. Уберем лишние стрелки:

На получившемся дереве можно определить подходящее расположение буквы Г и его код.
Поиск информации
Задача поиска обычно формулируется следующим образом. Имеется некоторое хранилище информации — информационный массив (телефонный справочник, словарь, расписание поездов, диск с файлами и др.). Требуется найти в нем информацию, удовлетворяющую определенным условиям поиска (телефон какой-то организации, перевод слова, время отправления поезда, нужную фотографию и т. д.). При этом, как правило, необходимо сократить время поиска, которое зависит от способа организации данных и используемого алгоритма поиска.
Алгоритм поиска, в свою очередь, также зависит от способа организации данных.
Если данные никак не упорядочены, то мы имеем дело с неструктурированным набором данных. Для осуществления поиска в таком наборе применяется метод последовательного перебора.
При последовательном переборе просматриваются все элементы подряд, начиная с первого. Поиск при этом завершается в двух случаях:
— искомый элемент найден;
— просмотрен весь набор данных, но искомого элемента среди них не нашлось.
— искомый элемент оказался первым среди просматриваемых. Тогда просмотр всего один;
Если же информация упорядочена, то мы имеем дело со структурой данных, в которой поиск осуществляется быстрее, можно построить оптимальный алгоритм.

Одним из оптимальных алгоритмов поиска в структурированном наборе данных может быть метод половинного деления.
Напомним, что при этом методе искомый элемент сначала сравнивается с центральным элементом последовательности. Если искомый элемент меньше центрального, то поиск продолжается аналогичным образом в левой части последовательности. Если больше, то — в правой. Если же значения искомого и центрального элемента совпадают, то поиск завершается.
Пример 4. В последовательности чисел 61 87 180 201 208 230 290 345 367 389 456 478 523 567 590 требуется найти число 180.
Процесс поиска представлен на схеме:

Передача информации
Передача информации — это процесс распространения информации от источника к приемнику через определенный канал связи.
На рисунке представлена схема модели процесса передачи информации по техническим каналам связи, предложенная Клодом Шенноном.

Работу такой схемы можно пояснить на примере записи речи человека с помощью микрофона на компьютер.
Источником информации является говорящий человек. Кодирующим устройством — микрофон, с помощью которого звуковые волны (речь) преобразуются в электрические сигналы. Канал связи — провода, соединяющие микрофон и компьютер. Декодирующее устройство — звуковая плата компьютера. Приемник информации — жесткий диск компьютера.
В современных технических системах связи борьба с шумом (защита от шума) осуществляется по следующим двум направлениям:
Но чрезмерная избыточность приводит к задержкам и удорожанию связи. Поэтому очень важно иметь алгоритмы получения оптимального кода, одновременно обеспечивающего минимальную избыточность передаваемой информации и максимальную достоверность принятой информации.
Важной характеристикой современных технических каналов передачи информации является их пропускная способность — максимально возможная скорость передачи информации, измеряемая в битах в секунду (бит/с). Пропускная способность канала связи зависит от свойств используемых носителей (электрический ток, радиоволны, свет). Так, каналы связи, использующие оптоволоконные кабели и радиосвязь, обладают пропускной способностью, в тысячи раз превышающей пропускную способность телефонных линий.
Современные технические каналы связи обладают, перед ранее известными, целым рядом достоинств:
— высокая пропускная способность, обеспечиваемая свойствами используемых носителей;
— надёжность, связанная с использованием параллельных каналов связи;
— помехозащищённость, основанная на автоматических системах проверки целостности переданной информации;
— универсальность используемого двоичного кода, позволяющего передавать любую информацию — текст, изображение, звук.
Объём переданной информации I вычисляется по формуле:
где v — пропускная способность канала (в битах в секунду), а t — время передачи.
Рассмотрим пример решения задачи, имеющей отношение к процессу передачи информации.
Пример 5. Документ объемом 10 Мбайт можно передать с одного компьютера на другой двумя способами.
А. Передать по каналу связи без использования архиватора.
Б. Сжать архиватором, передать архив по каналу связи, распаковать.
Какой способ быстрее и насколько, если:
— средняя скорость передачи данных по каналу связи составляет 2 18 бит/с;
— объем сжатого архиватором документа равен 25% от исходного объема;
— время, требуемое на сжатие документа — 5 секунд, на распаковку — 3 секунды?
Для решения данной задачи диаграмма Гантта не нужна; достаточно выполнить расчёты для каждого из имеющихся вариантов передачи информации.
Рассмотрим вариант А. Длительность передачи информации в этом случае составит:
Рассмотрим вариант Б. Длительность передачи информации в этом случае составит:
Итак, вариант Б быстрее на 232 с.
Хранение информации
Сохранить информацию — значит тем или иным способом зафиксировать её на некотором носителе.
Носитель информации — это материальная среда, используемая для записи и хранения информации.
Основным носителем информации для человека является его собственная память. По отношению к человеку все прочие виды носителей информации можно назвать внешними.
Основное свойство человеческой памяти — быстрота, оперативность воспроизведения хранящейся в ней информации. Но наша память не надёжна: человеку свойственно забывать информацию. Именно для более надёжного хранения информации человек использует внешние носители, организует внешние хранилища информации.
Виды внешних носителей менялись со временем: в древности это были камень, дерево, папирус, кожа и др. Долгие годы основным носителем информации была бумага. Развитие компьютерной техники привело к созданию магнитных (магнитная лента, гибкий магнитный диск, жёсткий магнитный диск), оптических (CD, DVD, BD) и других современных носителей информации.
В последние годы появились и получили широкое распространение всевозможные мобильные электронные (цифровые) устройства: планшетные компьютеры, смартфоны, устройства для чтения электронных книг, GPS-навигаторы и др. Появление таких устройств стало возможно, в том числе, благодаря разработке принципиально новых носителей информации, которые:
- Обладают большой информационной ёмкостью при небольших физических размерах.
- Характеризуются низким энергопотреблением при работе, обеспечивая наряду с этим высокие скорости записи и чтения данных.
- Энергонезависимы при хранении.
- Имеют долгий срок службы.
С точки зрения реализации на основе современных достижений вычислительной техники выделяют следующие виды обработки информации:
последовательная обработка, применяемая в традиционной фоннеймановской архитектуре ЭВМ, располагающей одним процессором;
параллельная обработка, применяемая при наличии нескольких процессоров в ЭВМ;
конвейерная обработка, связанная с использованием в архитектуре ЭВМ одних и тех же ресурсов для решения разных задач, Причем если эти задачи тождественны, то это последовательный конвейер, если задачи одинаковые -- векторный конвейер.
Принято относить существующие архитектуры ЭВМ с точки зрении обработки информации к одному из следующих классов.
Архитектуры с одиночными потоками команд и данных (SIMD). Особенностью данного класса является наличие одного (центрального) контроллера, управляющего рядом одинаковых процессоров. В зависимости от возможностей контроллера и процессорных элементов, числа процессоров, организации режима поиска и характеристик маршрутных и выравнивающих сетей выделяют:
матричные процессоры, используемые для решения векторных и матричных задач;
ассоциативные процессоры, применяемые для решения нечисловых задач и использующие память, в которой можно обращаться непосредственно к информации, хранящейся в ней;
процессорные ансамбли, применяемые для числовой и нечисловой обработки;
конвейерные и векторные процессоры.
Архитектуры с множественным потоком команд и одиночным потоком данных (MISD). К этому классу могут быть отнесены конвейерные процессоры.
Архитектуры с множественным потоком команд и множественным потоком данных (MIMD). К этому классу могут быть отнесены следующие конфигурации: мультипроцессорные системы, системы с мультобработкой, вычислительные системы из многих машин, вычислительные сети.
Основные процедуры обработки данных представлены на рисунке 4.
Рис. 4. Основные процедуры обработки данных
Создание данных, как процесс обработки, предусматривает их образование в результате выполнения некоторого алгоритма и дальнейшее использование для преобразований на более высоком уровне.
Модификация данных связана с отображением изменений в реальной предметной области, осуществляемых путем включения новых данных и удаления ненужных.
Контроль, безопасность и целостность направлены на адекватное отображение реального состояния предметной области в информационной модели и обеспечивают защиту информации от несанкционированного доступа (безопасность) и от сбоев и повреждений технических и программных средств.
Поддержка принятия решения является наиболее важным действием, выполняемым при обработке информации. Широкая альтернатива принимаемых решений приводит к необходимости использования разнообразных математических моделей.
Создание документов, сводок, отчетов заключается в преобразовании информации в формы, пригодные для чтения как человеком, так и компьютером. С этим действием связаны и такие операции, как обработка, считывание, сканирование и сортировка документов.
При преобразовании информации осуществляется ее перевод из одной формы представления или существования в другую, что определяется потребностями, возникающими в процессе реализации информационных технологий.
Реализация всех действий, выполняемых в процессе обработки информации, осуществляется с помощью разнообразных программных средств.
Наиболее распространенной областью применения технологической операции обработки информации является принятие решений.
К зависимости от степени информированности о состоянии управляемого процесса, полноты и точности моделей объекта и системы управления, взаимодействия с окружающей средой, процесс принятия решения протекает в различных условиях:
Принятие решений в условиях определенности. В этой задаче модели объекта и системы управления считаются заданными, а влияние внешней среды - несущественным. Поэтому между выбранной стратегией использования ресурсов и конечным результатом существует однозначная связь, откуда следует, что в условиях определенности достаточно использовать решающее правило для оценки полезности вариантов решений, принимая в качестве оптимального то, которое приводит к наибольшему эффекту. Если таких стратегий несколько, то все они считаются эквивалентными. Для поиска решений в условиях определенности используют методы математического программирования.
Принятие решений в условиях риска. В отличие от предыдущего случая для принятия решений в условиях риска необходимо учитывать влияние внешней среды, которое не поддается точному прогнозу, а известно только вероятностное распределение ее состояний. В этих условиях использование одной и той же стратегии может привести к различным исходам, вероятности появления которых считаются заданными или могут быть определены. Оценку и выбор стратегий проводят с помощью решающего правила, учитывающего вероятность достижения конечного результата.
Принятие решений в условиях многокритериальности. В любой из перечисленных выше задач многокритериальность возникает в случае наличия нескольких самостоятельных, не сводимых одна к другой целей. Наличие большого числа решений усложняет оценку и выбор оптимальной стратегии. Одним из возможных путей решения является использование методов моделирования.
Решение задач с помощью искусственного интеллекта заключается в сокращении перебора вариантов при поиске решения, при этом программы реализуют те же принципы, которыми пользуется в процессе мышления человек.
Экспертная система пользуется знаниями, которыми она обладает в своей узкой области, чтобы ограничить поиск на пути к решению задачи путем постепенного сужения круга вариантов.
Для решения задач в экспертных системах используют:
метод структурной индукции, основанный на построении дерева принятия решений для определения объектов из большого числа данных на входе;
метод эвристических правил, основанных на использовании опыта экспертов, а не на абстрактных правилах формальной логики;
метод машинной аналогии, основанный на представлении информации о сравниваемых объектах в удобном виде, например, в виде структур данных, называемых фреймами.
Процесс выработки решения на основе первичных данных, можно разбить на два этапа: выработка допустимых вариантов решений путем математической формализации с использованием разнообразных моделей и выбор оптимального решения на основе субъективных факторов.
Информационные потребности лиц, принимающих решение, во многих случаях ориентированы на интегральные технико-экономические показатели, которые могут быть получены в результате обработки первичных данных, отражающих текущую деятельность предприятия. Анализируя функциональные взаимосвязи между итоговыми и первичными данными, можно построить так называемую информационную схему, которая отражает процессы агрегирования информации. Первичные данные, как правило, чрезвычайно разнообразны, интенсивность их поступления высока, а общий объем на интересующем интервале велик. С другой стороны состав интегральных показателей относительно мал, а требуемый период их актуализации может быть значительно короче периода изменения первичных данных - аргументов.
Для поддержки принятия решений обязательным является наличие следующих компонент:
В настоящее время принято выделять два типа информационных систем поддержки принятия решений.
Системы поддержки принятия решений DSS (Decision Support System) осуществляют отбор и анализ данных по различным характеристикам и включают средства:
доступа к базам данных;
извлечения данных из разнородных источников;
моделирования правил и стратегии деловой деятельности;
деловой графики для представления результатов анализа;
искусственного интеллекта на уровне экспертных систем.
Системы оперативной аналитической обработки OLAP (OnLine Analysis Processing) для принятия решений используют следующие средства:
мощную многопроцессорную вычислительную технику в виде специальных OLAP-серверов;
специальные методы многомерного анализа;
специальные хранилища данных Data Warehouse.
Реализация процесса принятия решений заключается в построении информационных приложений. Выделим в информационном приложении типовые функциональные компоненты, достаточные для формирования любого приложения на основе БД.
PS (Presentation Services) - средства представления. Обеспечиваются устройствами, принимающими ввод от пользователя и отображающими то, что сообщает ему компонент логики представления PL, плюс соответствующая программная поддержка. Может быть текстовым терминалом или X-терминалом, а также персональным компьютером или рабочей станцией в режиме программной эмуляции терминала или Х-терминала.
PL (Presentation Logic) - логика представления. Управляет взаимодействием между пользователем и ЭВМ. Обрабатывает действия пользователя по выбору альтернативы меню, по нажатию кнопки или выбору элемента из списка.
DL (Data Logic) - логика управления данными. Операции с базой данных (SQL-операторы SELECT, UPDATE и INSERT), которые нужно выполнить для реализации прикладной логики управления данными.
DS (Data Services) - операции с базой данных. Действия СУБД, вызываемые для выполнения логики управления данными, такие как манипулирование данными, определения данных, фиксация или откат транзакций и т.п. СУБД обычно компилирует SQL-приложения.
FS (File Services) - файловые операции. Дисковые операции чтения и записи данных для СУБД и других компонент. Обычно являются функциями ОС.
Среди средств разработки информационных приложений можно выделить следующие основные группы;
По теме: методические разработки, презентации и конспекты
Обработка информации и алгоритмы. Автоматическая обработка информации
Презентация к уроку информатики для 10 класса.

Обработка информации. Получение новой информации. 5 класс.
Обработка информации - это процесс перехода от исходных данных к результату.Обработка информации бывает двух типов:1) обработка, связаная с получение новой информации:преобразование информации по зада.

Алгоритмы обработки информации. Алгоритмический этюд "Перевозчик"
Можно использовать для объяснения логической задачи "Переврозчик". Для 3-го класса. На внеурочных занятиях по информатике.
Алгоритмы обработки информации. Алгоритмический этюд "Конюх"
Можно исползоваать при объяснении темы "Алгоритмы обработки информации" в младшей школе на внеурочных занятиях. Для 3-го класса.
Алгоритмы обработки информации. Понятие "алгоритм"
Можно использовать на первом уроке темы "Алгоритмы обработки информации". Для 3-го класса. Внеурочная работа.

Цели урока:1. Обеспечить знание об основных видах обработки информации, понятия об алгоритмических машинах.2. Способствовать развитию познавательной дея.

№ слайда 2
Обработка информации производится каким-либо субъектом или объектом(например, человеком или компьютером) в соответствии с определёнными правилами. Будем его называть исполнителем обработки информации. Информация, которая подвергается обработке, представляется в виде исходных данных. На рисунке в обобщенном виде представлен процесс обработки информации.

№ слайда 3
Под обработкой информации в информатике понимают любое преобразование информации изодного вида в другой, производимое по строгим формальным правилам.

№ слайда 4
Примеры обработки информации Первый пример: ученик (исполнитель), решая задачу по математике, производит обработку информации. Исходные данные содержатся в условии задачи. Математические правила, описанные в учебнике, определяют последовательность вычислений. Результат — это полученный ответ. Второй пример: перевод текста с одного языка на другой - это пример обработки информации, при которой не меняется ее содержание, но изменяется форма представления — другой язык. Перевод осуществляет переводчик по определенным правилам, в определенной последовательности. Третий пример: работник библиотеки систематизирует картотеку книжного фонда. На каждую книгу заполняется карточка, на которой указываются все данные о книге: автор, название, год издания, объем и пр. Из карточек формируется каталог библиотеки, где все карточки располагаются в строгом порядке, например, в алфавитном каталоге карточки располагаются в алфавитном порядке фамилий авторов. Четвёртый пример: в телефонной книге вы ищете телефон нужной вам организации, например плавательного бассейна; или в том же библиотечном каталоге разыскиваете сведения о нужной вам книге. В обоих случаях исходными данными является информационный массив — телефонный справочник или каталог библиотеки, а также критерии поиска — название организации или фамилия автора и название книги.

№ слайда 5
Четыре вида обработки информации: получение новой информации, новых сведений;изменение формы представления информации;систематизация, структурирование данных;поиск информации.

№ слайда 6
Алгоритм - представляет собой конечную последовательность команд, посредством, выполнения которой машина решает задачу обработки информации.

№ слайда 7

№ слайда 8
Совокупность всех команд языка исполнителя называется системой команд исполнителя алгоритмов — СКИ.Алгоритм управления работой алгоритмической машины представляет собой конечную последовательность команд, посредством выполнения которой машина решает задачу обработки информации.

№ слайда 9
Алгоритм управления такой машиной должен обладать следующими свойствами: дискретностью (каждый шаг алгоритма выполняется отдельно от других);понятностью (в алгоритме используются только команды из СКИ);точностью (каждая команда определяет однозначное действие исполнителя);конечностью (за конечное число шагов алгоритма получается искомый результат).

№ слайда 11
Читайте также: