
Доклад на тему системы компьютерного перевода 7 класс информатика кратко
Обновлено: 01.05.2024
В многонациональном и мультиязычном мире существует проблема международной коммуникации. Людей, свободно говорящих на многих языках, меньше, чем людей, которым требуется перевод речи собеседника, научных текстов или видеоматериалов. Для разрешения подобных проблем появились системы компьютерного перевода.
Прообразы систем компьютерного перевода появились в начале 1930-х годов, работали такие системы по принципу словарей: на вход механизму подавались специально подготовленные наборы слов, которые переводились машиной, результат интерпретировался человеком, создававшим из него осмысленный текст.
Первые системы компьютерного перевода появились после второй мировой войны, содержали списки переводов слов и небольшой набор правил грамматики. В первой публичной демонстрации машинного перевода (1954 год, Джорджтаун) использовалась система, основанная на словаре из 250 записей, и всего на 6 правилах грамматики. Несмотря на позитивный настрой разработчиков, значительное финансирование и интерес со стороны средств массовой информации, переводчик был скорее игрушкой, качество перевода было невысоким. В последующие годы предпринимались многочисленные попытки улучшить качество перевода.
В 1980-х годах обрели широкое распространение микрокомпьютеры, на базе которых были созданы портативные компьютерные переводчики. Это подогрело интерес к системам компьютерного перевода со стороны промышленности и, как следствие, и мотивацию учёных. В это же время начали развиваться системы распознавания и генерации речи, что давало надежды на машинный перевод в режиме "on-air", во время разговора.
В настоящее время используется множество систем компьютерного перевода. К системам с заранее заданными правилами перевода добавляют статистические модели, самообучающиеся алгоритмы. Популярен подход с использованием нейронных сетей - алгоритмов, которые состоят из множества изменяющихся под действием обучения частей (нейронов), которые выдают ответ, интерпретируя сигналы, возвращаемые нейронами. Усложнения используемых алгоритмов позволяют получать результаты, приближенные к переводам переводчиков-людей.
Основные проблемы у компьютерных переводчиков возникают с неоднозначностью перевода. Много слов имеют разные значения, в языках существуют разные диалекты, в которых одинаковые на вид понятия могут иметь противоположные значения. Человек при переводе может догадаться, о чём идёт речь, компьютер же сам "додумать" ничего не может, поэтому использует то, что уже знает. При переводе технических текстов, инструкций или устойчивых выражений системы компьютерного перевода почти всех выбирают верные варианты, исходя из контекста. В случае художественных текстов задача усложняется, в том числе из-за того, что определённые метафоры в культуре одного народа могут не совпадать с традициями другого. Поэтому качество перевода художественных текстов как правило ниже, чем всех остальных.
Использование самообучающихся алгоритмов позволяет улучшить качество перевода за счёт анализа новых источников. Часто это бывает полезным, но эту систему можно использовать, чтобы ухудшить качество перевода, сделать его нелепым. В интернете можно найти много примеров из онлайн-переводчиков компаний Goоgle и Яндeкс, например, когда-то "Константин Хабенский" переводилось на английский как "Keira Knightley" - Кира Найтли. Скорее всего, это было сделано интернет-троллями, часто поправлявшими правильный вариант на неправильный, из-за чего изменились настройки алгоритма перевода.
Системы компьютерного перевода входят в большую группу алгоритмов, занимающихся обработкой естественного языка. Их развитие поможет людям как общаться между собой, получать информацию из иноязычных источников, так и научит компьютеры лучше понимать человека и его запросы, что повысит эффективность, простоту использования компьютера и увеличит возможные плюсы от такого взаимодействия.
На начальной стадии развития ЭВМ человеку было необходимо составлять программы на языке, понятном компьютеру, в машинных кодах.любая программа для процессора выглядела последовательность единиц и нулей.Как показала в дальнейшем такой язык громоздок и неудобен. При пользовании им легко допустить ошибку, записав не в той последовательности 1 или 0.при программировании в машинных кодах надо хорошо знать внутреннюю структуру ЭВМ. программы на данном языке - очень длинные последовательности единиц и нулей являются машинно зависимыми, т.е. для каждой ЭВМ необходимо было составлять свою программу, а так же программирование в машинных кодах требует от программиста много времени, труда, повышенного внимания.
В 1950 году начали применять мнемонический язык – язык assembly.Ассемблер - язык программирования низкого уровня.Язык ассемблера позволил представить машинный код в более удобной для человека форме: для обозначения команд и объектов , вместо двоичных кодов использовались буквы или сокращенные слова, которые отражали суть команды. Например, на языке ассемблера команда сложения двух чисел обозначается словом add, тогда как ее машинный код может быть таким: 000010.
Но сложность разработки в нём больших программных комплексов привела к появлению языков третьего поколения – языков высокого уровня.
середины 50-х гг. XX в. начали создавать первые языки программирования высокого уровня . Эти языки не были привязаны к определенному типу ЭВМ (машинонезависимы). Для каждого из них были разработаны собственные компиляторы.
Первый язык высокого уровня Фортран был создан в период с 1954 по 1957 года группой программистов под руководством Джона Бэкуса в корпорации IBM. Он предназначался для научных и технических расчетов.В конце 1953 Джон Бэкус предложил начать разработку эффективной альтернативы ассемблеру для программирования на ПК IBM 704. Уже к середине 1954 была закончена черновая спецификация языка Fortran.К 1960 году существовали версии Fortran для компьютеров IBM 709, 650, 1620, 7090.В 1963 существовало более 40 компиляторов для разных платформ.
Язык программирования ALGOL 58.Алгол был разработан в 1958 году на недельной конференции в ETH.Новая версия появилась в 1960 г., и ALGOL 60 (с небольшими изменениями, сделанными в 1962 г.) с 60-х и до начала 70-х гг. прошлого века был стандартом академического языка программирования. В Алголе появилось представление о программе не как о свободной последовательности команд, а как о блочной структуре, состоящей из чётко описанных и отделённых друг от друга частей. Основной блок программы на Алголе – это сама главная программа.
Язык программирования LISP.Язык Лисп был предложен Дж. Маккарти в работе в 1960 году и ориентирован на разработку программ для решения задач не численного характера.На протяжении почти сорокалетней истории его существования появился ряд диалектов этого языка: Common LISP, Mac LISP, Inter LISP, Standard LISP и др.Различия между ними не носят принципиального характера и в основном сводятся к несколько отличающемуся набору встроенных функций и некоторой разнице в форме записи программ. Поэтому программист, научившийся работать на одном из них, без труда сможет освоить и любой другой. Большим достоинством Лиспа является его функциональная направленность, т. е. программирование ведется с помощью функций.
Язык программирования COBOL.Кобол был разработан в 1959 году и предназначался для написания программ для разработки бизнес приложений, а так же для работы в экономической сфере.Создатели языка ставили своей целью сделать его машинонезависимым и максимально приближенным к естественному английскому языку. Обе цели были успешно достигнуты; программы на COBOL считаются понятными даже неспециалистам, поскольку тексты на этом языке программирования не нуждаются в каких-либо специальных комментариях. COBOL – язык очень старый и в свое время использовался крайне активно, поэтому существует множество реализаций и диалектов. Для языка был утвержден ряд стандартов: в 1968, 1974, 1985 и 2002 годах. Последний стандарт добавил в язык поддержку объектно–ориентированной парадигмы.
Технологическая революция привела к появлению термина "информационная эра" из-за того, что информационные системы стали частью нашей жизни и изменили ее коренным образом. Информационная эра также изменила способ ведения боевых действий, обеспечив командиров беспрецедентным количеством и качеством информации. Теперь командир может наблюдать за ходом ведения боевых действий, анализировать события и доводить информацию. Следует различать войну информационной эры и информационную войну. Война информационной эры использует информационную технологию как средство для успешного проведения боевых операций. Напротив, информационная война рассматривает информацию как отдельный объект или потенциальное оружие и как выгодную цель. Технологии информационной эры сделали возможной теоретическую возможность - прямое манипулирование информацией противника. Что такое информация? Информация появляется на основе событий окружающего мира. События должны быть восприняты каким-то образом и проинтерпретированы, чтобы стать информацией. Поэтому информация результат двух вещей - воспринятых событий(данных) и команд, требуемых для интерпретации данных и связывания с ними значения. Отметим, что это определение абсолютно не связано с технологией. Тем не менее, что мы можем делать с информацией и как быстро мы можем это делать, зависит от технологии. Поэтому введем понятие информационной функции - это любая деятельность, связанная с получением, передачей, хранением и трансформацией информации. Каковы военные информационные функции? Качество информации - показатель трудности ведения войны. Чем более качественной информацией владеет командир, тем большие него преимущества по сравнению с его врагом. Так в ВВС США анализ результатов разведки и прогноза погоды является основой для разработки полетного задания. Точная навигация увеличивает эффективность выполнения задания. Все вместе они являются видами военных информационных функций, которые увеличивают эффективность боевых операций. Поэтому дадим определение военным информационным функциям - это любые информационные функции, обеспечивающие или улучшающие решение войсками своих боевых задач. Что такое информационная война? На концептуальном уровне можно сказать, что государства стремятся приобрести информации, обеспечивающую выполнение их целей, воспользоваться ей и защитить ее. Эти использование и защита могут осуществляться в экономической, политической и военной сферах. Знание об информации, которой владеет противник, является средством, позволяющим усилить нашу мощь и понизить мощь врага или противостоять ей, а также защитить наши ценности, включая нашу информацию. Информационное оружие воздействует на информацию, которой владеет враг и его информационные функции. При этом наши информационные функции защищаются, что позволяет уменьшить его волю или возможности вести борьбу. Поэтом дадим определение информационной войне - это любое действие по использованию, разрушению, искажению вражеской информации и ее функций; защите нашей информации против подобных действий; и использованию наших собственных военных информационных функций. Это определение является основой для следующих утверждений. Информационная война - это любая атака против информационной функции, независимо от применяемых средств. Бомбардировка АТС - операция информационной войны.
Программирование,11 класс. Протабулируйте функцию на промежутке y=xcos2x на промежутке (-2:2) с шагом 0,2 и вычислите количест
Хэлп, по информатике Стилевое форматирование – это . Выберите один из 3 вариантов ответа: 1) форматирование (изменение) структ
Вычислите значение переменной Y после выполнения фрагмента программы int r=35\%10, y; if (r==0) y=r*10; if (r>0) y=r+10; if (
Документ объемом 20 Мбайт можно передать с одного компьютера на другой двумя способами: А) Сжать архиватором, передать архив по
В школе задали очередной реферат. Нужно подготовиться и найти материалы. Вы скачали файл, но вместо него запустилась какая-то ус
Здравствуйте ребят!Помогите решить задачку..Мне её надо написать в С++.Честно говоря хотя бы напишите мне "Дано" и как это решит
Проблема та-же но осталось всего 1 задание (остальные 4 сделал сам) прошу помощи вот само задание: Напишите программу которая в

В многонациональном и мультиязычном мире существует проблема международной коммуникации. Людей, свободно говорящих на многих языках, меньше, чем людей, которым требуется перевод речи собеседника, научных текстов или видеоматериалов. Для разрешения подобных проблем появились системы компьютерного перевода.
Прообразы систем компьютерного перевода появились в начале 1930-х годов, работали такие системы по принципу словарей: на вход механизму подавались специально подготовленные наборы слов, которые переводились машиной, результат интерпретировался человеком, создававшим из него осмысленный текст.
Первые системы компьютерного перевода появились после второй мировой войны, содержали списки переводов слов и небольшой набор правил грамматики. В первой публичной демонстрации машинного перевода (1954 год, Джорджтаун) использовалась система, основанная на словаре из 250 записей, и всего на 6 правилах грамматики. Несмотря на позитивный настрой разработчиков, значительное финансирование и интерес со стороны средств массовой информации, переводчик был скорее игрушкой, качество перевода было невысоким. В последующие годы предпринимались многочисленные попытки улучшить качество перевода.
В 1980-х годах обрели широкое распространение микрокомпьютеры, на базе которых были созданы портативные компьютерные переводчики. Это подогрело интерес к системам компьютерного перевода со стороны промышленности и, как следствие, и мотивацию учёных. В это же время начали развиваться системы распознавания и генерации речи, что давало надежды на машинный перевод в режиме "on-air", во время разговора.
В настоящее время используется множество систем компьютерного перевода. К системам с заранее заданными правилами перевода добавляют статистические модели, самообучающиеся алгоритмы. Популярен подход с использованием нейронных сетей - алгоритмов, которые состоят из множества изменяющихся под действием обучения частей (нейронов), которые выдают ответ, интерпретируя сигналы, возвращаемые нейронами. Усложнения используемых алгоритмов позволяют получать результаты, приближенные к переводам переводчиков-людей.
Основные проблемы у компьютерных переводчиков возникают с неоднозначностью перевода. Много слов имеют разные значения, в языках существуют разные диалекты, в которых одинаковые на вид понятия могут иметь противоположные значения. Человек при переводе может догадаться, о чём идёт речь, компьютер же сам "додумать" ничего не может, поэтому использует то, что уже знает. При переводе технических текстов, инструкций или устойчивых выражений системы компьютерного перевода почти всех выбирают верные варианты, исходя из контекста. В случае художественных текстов задача усложняется, в том числе из-за того, что определённые метафоры в культуре одного народа могут не совпадать с традициями другого. Поэтому качество перевода художественных текстов как правило ниже, чем всех остальных.
Использование самообучающихся алгоритмов позволяет улучшить качество перевода за счёт анализа новых источников. Часто это бывает полезным, но эту систему можно использовать, чтобы ухудшить качество перевода, сделать его нелепым. В интернете можно найти много примеров из онлайн-переводчиков компаний Goоgle и Яндeкс, например, когда-то "Константин Хабенский" переводилось на английский как "Keira Knightley" - Кира Найтли. Скорее всего, это было сделано интернет-троллями, часто поправлявшими правильный вариант на неправильный, из-за чего изменились настройки алгоритма перевода.
Системы компьютерного перевода входят в большую группу алгоритмов, занимающихся обработкой естественного языка. Их развитие поможет людям как общаться между собой, получать информацию из иноязычных источников, так и научит компьютеры лучше понимать человека и его запросы, что повысит эффективность, простоту использования компьютера и увеличит возможные плюсы от такого взаимодействия.

Информатика
Использование текстовых редакторов позволяет не только переводить информацию в набранный документ, но и проводить ряд действий для того, чтобы она выглядела привлекательнее и быстрее усваивалась читателями. Благодаря специальным приложениям стало возможным обрабатывать тексты автоматически, без уделения времени и выбора каждой команды. В информатике за 7 класс системы перевода и распознавания текста описаны как основные механизмы в работе с большими объёмами материала.
Системы перевода
Сначала программа-переводчик анализирует текст на родном языке и после этого переводит его на желаемый с использованием тех форм и правил, которые присущи нужному языку. Перевод занимает от нескольких секунд до минуты, а его качество зависит от используемых словарей, которые вписаны в основу программы.

Переводчик можно установить на персональный компьютер или на мобильный или использовать онлайн-версию. Второй вариант будет более подходящим в плане высокого качества, ведь классические переводчики, встроенные в поисковые системы, обладают большим словарным запасом и максимально приближаются к реальной речи. А также здесь имеется голосовой набор и возможность прослушать перевод на новый язык, чтобы уловить интонацию и стиль проговаривания фразы.
Отдельные предложения могут иметь платные опции или требовать много места на гаджете из-за постоянных обновлений. Такой вариант подойдёт для туристов или для любителей путешествий. Для стабильной работы и перевода лучше пользовать стандартными переводчиками в онлайн-системе. Что касается возможного объёма в системе перевода текста, то в гугл он может достичь 5 тысяч знаков и осуществить перевод со 103 языков мира. Эта система считается одной из наиболее популярных и широко используемых в мире.
Список преимуществ
В любой компьютерной программе можно найти как положительные, так и негативные качества. Всё зависит от технических возможностей и задания, которое необходимо выполнить. К преимуществам переводчиков специалисты относят следующие факторы:

- Большое разнообразие словарей по специальностям, что делает возможным перевод разных текстов и материалов.
- Возможность организовать быстрый поиск по любой теме. В программах-переводчиках возможности систем распознавания текстов зависят от типа программы, онлайн-версии постоянно обновляются и дополняются.
- Одновременно можно просматривать несколько вариантов перевода и выбирать для себя наиболее подходящий с нужными формами.
- Можно самостоятельно вписывать фразы и формировать свой словарь на нужном языке.
- Сочетание с текстовыми редакторами и возможность быстро переводить текст с формата поиска в вордовский документ.
Благодаря удобному интерфейсу, простоте и большому словарному запасу можно переводить тексты и работать с коррекцией в одном и том же переводчике. К плюсам программы можно отнести и компактность, переводчики могут устанавливаться как на компьютеры, так и на телефоны или другие мобильные гаджеты.

Современные технологии не стоят на месте, и благодаря работе компьютерщиков можно сравнить современные версии со старыми, более примитивными и несложными. Начиная с 2017 года, компания Google использует технологию, в основе которой находится применение нейросети. Это позволяет не только использовать более подходящие по смыслу фразы и создавать точный перевод, но и учитывать в процессе разные тонкости языков, подбирать подходящие варианты слов.
Машинный перевод и распознавание текста являются сложным автоматизированным процессом. который требует от пользователя только введения данных. Получить таким образом перевод из одного языка на другой достаточно просто, нужно только подобрать свой тип переводчика с нужным словарём.
Описание недостатков
Возможности распознавания текстов в программах-переводчиках постоянно улучшаются и расширяются, но при этом специалисты выделяют и ряд недостатков. К основным можно отнести следующие факторы:

- Ограниченный обзор, который зависит от размеров экрана.
- Большой словарь позволяет увидеть сразу много вариантов слова, но нужно самостоятельно выбирать ту форму, которая будет кстати. Для людей, которые недостаточно хорошо владеют иностранным языком, сделать это будет тяжело.
- Словари-переводчики не учитывают игру слов и возможных художественных приёмов, поэтому перевод будет больше механическим и сухим. Электронный вид текста после переводчика нужно исправлять и редактировать возможные ошибки в формах.
- Если фразы в словаре нет, то переводчик не переводит её.
- Из нескольких вариантов многозначного слова переводчик выбирает тот тип, что используется чаще всего, а это не всегда может подходить по смыслу в конкретный текст.
- Иногда в словарях предложено несколько вариантов одного слова, которые могут отличаться смыслом. Само же трактование не указывается, и поэтому выбрать из нескольких правильный ответ тяжело.
Описание специальных программ, особенности перевода текстов и краткое содержание предоставляемых возможностей позволяют сделать правильный выбор и установить нужный вариант для работы. К сожалению, осуществить адекватный перевод с помощью программы не получится, но заметно облегчить себе задачу вполне реально.
Распознавание текста
Информацию на компьютер можно вводить не только стандартным методом, с помощью клавиатуры, но и используя сканнер. Благодаря устройству можно перевести страницу из книги или журнала в электронный формат за некоторое время. Большим плюсом программы является то, что можно перевести не только текст, но и картинки, и сделать это как в чёрно-белом, так и в цветном формате.
Первоначально отсканированный текст воспринимается компьютером как картинка, нужна дополнительная работа и использование специальной программы, чтобы изображение превратилось в текст. Процесс распознавания несложный, но многоэтапный. Он состоит из таких пунктов:

- Программа начинает анализировать полученное изображение, выделяет в нём текстовые, графические и области таблицы.
- После этого строки в текстовых блоках начинают разбиваться на слова, а слова, в свою очередь, — на символы.
- Каждый символ сравнивается с имеющейся в базе буквой и подбирается наиболее подходящий тип.
- После окончания программа выдаёт обработанный текст пользователю в готовом виде.
Конечно, после сканирования документ нужно дополнительно перечитывать и исправлять ошибки, но это существенно экономит время в сравнении с простым набором текста. Благодаря программам распознавания можно обрабатывать и переводить в формат документа не только текстовые блоки, но и материалы в таблицах и схемах.

Популярной является программа Fine Reader, она позволяет быстро отсканировать картинку и перевести её в электронный вариант за короткий промежуток времени. Благодаря постоянному обновлению элементов программы, она совместима с разными моделями сканеров и быстро настраивается для работы. После сканирования результаты можно хранить в разных форматах приложений и в формате разметки гипертекста HTML. Большим преимуществом программы является возможность орфографической проверки, которая уже встроена в программу, и удобный интерфейс, что делает использование ещё проще.
Применение на практике программ с распознаванием и переводом текста заметно упрощает работу и позволяет почувствовать все преимущества современных возможностей. Текстовые редакторы, программы для установки постоянно обновляются и наполняются новыми функциями, благодаря чему работать с разными форматами намного проще и эффективнее. Нейросети, качественное оборудование, большие объёмы памяти помогают работать с разной информацией и хранить копии в доступных облачных хранилищах. Даже начинающим пользователям будет комфортно выполнять разные задачи и обрабатывать тексты благодаря простому функционалу и подсказкам онлайн.
Словари необходимы для перевода текстов с одного языка на другой. Первые словари были созданы около 5 тысяч лет назад в Шумере и представляли собой глиняные таблички, разделенные на две части. В одной части записывалось слово на шумерском языке, а в другой — аналогичное по значению слово на другом языке, иногда с краткими пояснениями.
Современные словари построены по такому же принципу. В настоящее время существуют тысячи словарей для перевода между сотнями языков (англо-русский, немецко-французский и т. д.), причем каждый из них может содержать десятки тысяч слов. В бумажном варианте словарь представляет собой толстую книгу объемом в сотни страниц, в которой поиск нужного слова — процесс достаточно трудоемкий.
прослушивания слов в исполнении дикторов, носителей языка;
• онлайновые компьютерные словари в Интернете обеспечивают выбор тематического словаря и направления перевода.
Системы компьютерного перевода.
Происходящая в настоящее время глобализация нашего мира приводит к необходимости обмена документами между людьми и организациями, находящимися в разных странах мира и говорящими на различных языках.
Онлайновые компьютерные переводчики в Интернете обеспечивают выбор тематического словаря и направления перевода. Они позволяют переводить любые тексты, набранные в окне перевода или скопированные из буфера обмена, Web-стракицы, включая гиперссылки, с сохранением исходного форматирования, а также электронные письма.
Современные системы компьютерного перевода позволяют с приемлемым качеством переводить техническую документацию, деловую переписку и другие специализированные тексты. Но на эти системы нельзя полностью полагаться. Они допускают смысловые и стилистические ошибки и неприменимы, например, для перевода художественных произведений, так как не способны адекватно переводить метафоры, аллегории и другие элементы художественного творчества человека и т. д.
Формы организации взаимодействия ЭВМ и человека при машинном переводе:
- С постредактированием: исходный текст перерабатывается машиной, а человек-редактор исправляет результат.
- С предредактированием: человек приспосабливает текст к обработке машиной (устраняет возможные неоднозначные прочтения, упрощает и размечает текст), после чего начинается программная обработка.
- С интерредактированием: человек вмешивается в работу системы перевода, разрешая трудные случаи.
- Смешанные системы (например, одновременно с пред- и постредактированием).
Компьютерные словари (примеры):
омпания ПРОМТ — лидер в разработке систем автоматического перевода — предлагает широкий спектр продуктов для разных языковых пар.


Pragma 3.0 работает со всеми популярными офисными пакетами (Microsoft Office, StarOffice, Lotus Notes), а также с почтовыми клиентами (Outlook Express, MS Outlook, Netscape, Eudora) и браузерами (Internet Explorer, Netscape, Mozilla).
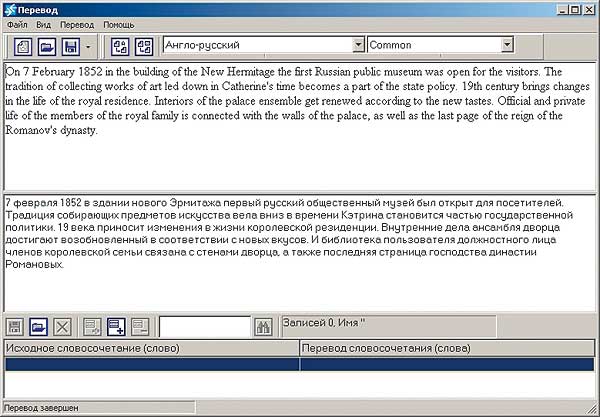
Retrans Vista предоставляет интерактивный режим перевода, при котором пользователь может выбрать из предлагаемых вариантов перевода слов и словосочетаний собственный вариант перевода, зарезервировать слово, которое не нужно переводить, объединить слова в словосочетание или предложение. Интерактивный режим представлен в двух формах — табличной и текстовой.
Словарь пользователя позволяет сохранять результаты перевода и использовать их в дальнейшей работе, что существенно облегчает труд переводчика и обеспечивает единообразие стиля и терминологии.
Перевод в Интернете дает возможность быстро понять смысл содержания страницы на английском языке, при этом формат страницы сохраняется.
Функция быстрого автоматического перевода обеспечивает скорость до 7200 слов в минуту.
В системе Retrans Vista реализована концепция фразеологического машинного перевода, основанная на переводе целостных понятий, выражаемых словами, словосочетаниями или предложениями. Поэтому система в первую очередь находит эквиваленты для максимально длинных фраз и словосочетаний, а если это не удается, переводит входящие в их состав более короткие словосочетания и отдельные слова.
ABBYY Lingvo имеет три версии:
• ABBYY Lingvo 9.0. Англо-русский — словарь для PC и Pocket PC, который содержит около 1 млн. 400 тыс. словарных статей в 22 словарях общей, разговорной и тематической лексики, русско-английский разговорник, лингвострановедческий словарь Великобритании и новый словарь разговорной лексики;
• ABBYY Lingvo 9.0. Многоязычный — электронный словарь для PC и Pocket PC, включающий более 3 млн. 500 тыс. словарных статей в 49 словарях (более 7 млн. 400 тыс. переводов) на пяти европейских языках (английский, немецкий, французский, испанский, итальянский), а также пять новых разговорников, содержащих по 500 наиболее употребительных фраз;
• ABBYY Lingvo 9.0. Популярный — многоязычная версия стоимостью 100 руб., которая содержит самую необходимую лексику на пяти языках (английском, немецком, французском, итальянском и испанском). Всего — более 370 тыс. словарных статей.
Основные достоинства англо-русской и многоязычной версии:
• самые полные словари, актуальная лексика;
• всесторонняя тематика, включающая такие тематические специализированные словари, как медицинский и компьютерный, а также справочник по грамматике английского языка;
• подробный перевод, многочисленные примеры словоупотребления;
• перевод слова из любой формы с учетом морфологии);
• говорящий словарь — 25 тыс. самых наиболее употребительных слов озвучены дикторами из Великобритании и Германии;
Читайте также: