
Доклад на тему алфавитный подход и содержательный подход различие
Обновлено: 02.07.2024
Пример 1. Предположим, что мы подбрасываем монету. Есть два равновероятных исхода – выпадет орел или решка. Узнав результат бросания монеты, Вы получаете 1 бит информации.
Можно обозначить (закодировать) возможные варианты:
| Равновероятные события | Их обозначение (код) |
| Решка | |
| Орёл |
Преобразование информации из одной формы представления в другую называют кодированием. Для кодирования используют определенную систему знаков – алфавит. Количество знаков в алфавите может быть различным. Самый короткий алфавит состоит из двух знаков. Если для кодирования информации используется только два знака - 0 и 1, то кодирование называют двоичным. Таблица, представленная выше, называется таблицей двоичной кодировки, а один бит информации, таким образом, представляет собой один двоичный знак.
Заметим теперь, что записать результаты многократного бросания монет можно по-разному:
· Орёл, решка, решка, орёл, решка, орёл, орёл .
· 1, 0, 0, 1, 0, 1, 1, .
Пример 2.На уроке информатики проводится тестовая работа, состоящая из трёх заданий. Составим таблицу двоичной кодировки возможных результатов выполнения работы одним из учеников:
| События | Двоичные коды |
| выполнено 0 заданий | |
| выполнено 1 задание | |
| выполнено 2 задания | |
| выполнено 3 задания |
Пример 3. Если увеличить количество заданий до семи, то таблица примет вид:
| События | Двоичные коды |
| выполнено 0 заданий | 000 |
| выполнено 1 задание | 001 |
| выполнено 2 задания | |
| выполнено 3 задания | 011 |
| выполнено 4 задания | |
| выполнено 5 заданий | 101 |
| выполнено 6 заданий | 110 |
| выполнено 7 заданий | 111 |
С увеличением количества событий в два раза увеличивается на 1 бит длина кода:
| Количество событий (N) | Длина кода (i) |
| N = 2 | i = 1 |
| N = 4 | i = 2 |
| N = 8 | i = 3 |
Нетрудно заметить, что величины N и iсвязаны формулой 2 i = N, если N выбирать из ряда 2,4,8,16,32,64…….. Для других значений N формула выглядит так: 2 i ≥ N. По ней мы можем рассчитать длину двоичного кода для любого количества событий. Неравенство можно решить подбором наименьшего значения i из ряда натуральных чисел. ( Двойка в формуле показывает, что используется двоичное кодирование. Если бы использовалось, например, троичное кодирование, нужно было бы писать три и т.д.)
Для записи текстовой (знаковой) информации всегда используется какой-либо язык (естественный или формальный). Всё множество используемых в языке символов называется алфавитом. Полное число символов алфавита называют его мощностью. При записи текста в каждой очередной позиции может появиться любой из N символов алфавита, т.е. может произойти N событий. Следовательно, каждый символ алфавита содержит iбит информации, где i определяется из неравенства: 2 i ≥ N. Тогда общее количество информации в тексте определяется формулой:

V = k * i , где V – количество информации в тексте; k – число знаков в тексте (включая знаки препинания и даже пробелы), i- количество бит, выделенных на кодирование одного знака.
Измерение информации: содержательный и алфавитный подходы. Единицы измерения информации.
Ответ:
Измерение информации: содержательный и алфавитный подходы
Пример 1. Предположим, что мы подбрасываем монету. Есть два равновероятных исхода – выпадет орел или решка. Узнав результат бросания монеты, Вы получаете 1 бит информации.
Можно обозначить (закодировать) возможные варианты:
| Равновероятные события | Их обозначение (код) |
| Решка | |
| Орёл |
Преобразование информации из одной формы представления в другую называют кодированием. Для кодирования используют определенную систему знаков – алфавит. Количество знаков в алфавите может быть различным. Самый короткий алфавит состоит из двух знаков. Если для кодирования информации используется только два знака - 0 и 1, то кодирование называют двоичным. Таблица, представленная выше, называется таблицей двоичной кодировки, а один бит информации, таким образом, представляет собой один двоичный знак.
Заметим теперь, что записать результаты многократного бросания монет можно по-разному:
· Орёл, решка, решка, орёл, решка, орёл, орёл .
· 1, 0, 0, 1, 0, 1, 1, .
Пример 2.На уроке информатики проводится тестовая работа, состоящая из трёх заданий. Составим таблицу двоичной кодировки возможных результатов выполнения работы одним из учеников:
| События | Двоичные коды |
| выполнено 0 заданий | |
| выполнено 1 задание | |
| выполнено 2 задания | |
| выполнено 3 задания |
Пример 3. Если увеличить количество заданий до семи, то таблица примет вид:
| События | Двоичные коды |
| выполнено 0 заданий | 000 |
| выполнено 1 задание | 001 |
| выполнено 2 задания | |
| выполнено 3 задания | 011 |
| выполнено 4 задания | |
| выполнено 5 заданий | 101 |
| выполнено 6 заданий | 110 |
| выполнено 7 заданий | 111 |
С увеличением количества событий в два раза увеличивается на 1 бит длина кода:
| Количество событий (N) | Длина кода (i) |
| N = 2 | i = 1 |
| N = 4 | i = 2 |
| N = 8 | i = 3 |
Нетрудно заметить, что величины N и iсвязаны формулой 2 i = N, если N выбирать из ряда 2,4,8,16,32,64…….. Для других значений N формула выглядит так: 2 i ≥ N. По ней мы можем рассчитать длину двоичного кода для любого количества событий. Неравенство можно решить подбором наименьшего значения i из ряда натуральных чисел. ( Двойка в формуле показывает, что используется двоичное кодирование. Если бы использовалось, например, троичное кодирование, нужно было бы писать три и т.д.)
Для записи текстовой (знаковой) информации всегда используется какой-либо язык (естественный или формальный). Всё множество используемых в языке символов называется алфавитом. Полное число символов алфавита называют его мощностью. При записи текста в каждой очередной позиции может появиться любой из N символов алфавита, т.е. может произойти N событий. Следовательно, каждый символ алфавита содержит iбит информации, где i определяется из неравенства: 2 i ≥ N. Тогда общее количество информации в тексте определяется формулой:
V = k * i , где V – количество информации в тексте; k – число знаков в тексте (включая знаки препинания и даже пробелы), i- количество бит, выделенных на кодирование одного знака.
Развитие компьютерной техники в новом информационном веке вызывает множество дополнительных вопросов, открывает новые возможности и знания. Но вместе с этим и возникает множество дилемм, которые необходимо разрешить. Так, например, изучая компьютерную технику, важно понимать, как она обрабатывает, запоминает и передает файлы, что такое кодирование данных и в каком формате осуществляется измерение информации. Но главным предметом обсуждения становится вопрос о том, какие существуют основные подходы к измерению информации. Примеры и пояснения каждого аспекта будут подробно описаны в данной статье.
Информация в компьютерной науке
Чтобы начинать разбираться в информационных подходах хранения данных, прежде необходимо узнать, что в компьютерной сфере представляет информация и что она показывает. Ведь если взять информатику как науку, то ее основным объектом изучения является именно информация. Само слово латинского происхождения и в переводе на наш язык означает "ознакомление", "объяснение", "сведение". Каждая наука использует разные определения данного понятия. В компьютерной сфере это все те сведения о различных явления и объектах, окружающих нас, которые уменьшают меру неопределенности и степень нашего незнания о них. Но, чтобы хранить все файлы, данные, символьные знаки в электронной вычислительной машине, необходимо знать алгоритм их перевода в бинарный вид и существующие единицы замера количества данных. Алфавитный подход к измерению информации показывает, как именно компьютерная машина преобразовывает символы в бинарный код ноликов и единичек.
Кодирование информации электронной вычислительной машиной
Компьютерная техника способна распознавать, обрабатывать, запоминать и передавать только информационные данные в двоичном коде. Но если это аудиозапись, текст, видео, графическое изображение, как машина способна разные типы данных преобразовывать в бинарный тип? И как они в таком виде хранятся в памяти? На эти вопросы ответы можно найти, если вы знаете алфавитный подход к определению количества информации, содержательный аспект и техническую суть кодирования.
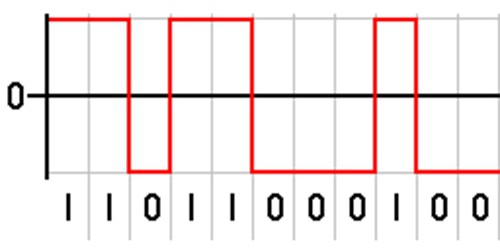
Кодирование информации состоит в том, чтобы зашифровать символы в бинарный код, состоящий из знаков "0" и "1". Это технически просто организовать. Сигнал есть, если стоит единица, ноль указывает на обратное. Некоторые задаются вопросом о том, почему компьютер не может, как и человеческий мозг, сохранять сложные числа, ведь они меньше по размеру. Но электронной вычислительной технике легче оперировать огромным бинарным кодом, нежели хранить в своей памяти сложные числа.
Системы исчисления в компьютерной сфере
Мы привыкли считать от 1 до 10, слагать, вычитать, умножать и делать различные операции над числами. Компьютер же способен оперировать только двумя числами. Но делает это за доли миллисекунд. Как компьютерной машиной производится кодирование и декодирование символов? Это достаточно простой алгоритм, который можно рассмотреть на примере. Алфавитный подход к измерению информации, единицы измерения данных мы рассмотрим немного позже, после того, как станет понятной суть кодирования и декодирования данных.
Существует множество компьютерных программ, которые наглядно осуществляют перевод систем исчисления или текстовой строки в двоичный код и обратно.
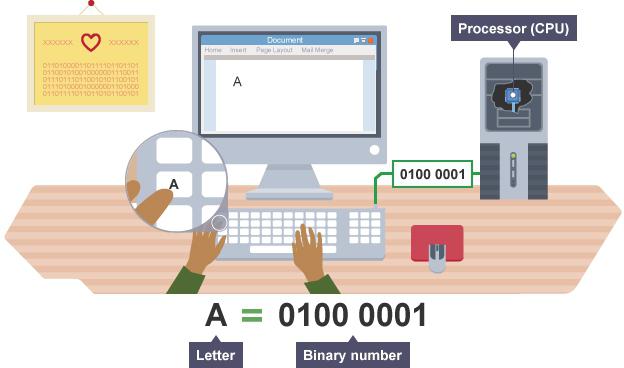
Мы же осуществим расчеты вручную. Кодирование информации производится обычным делением на 2. Итак, допустим, у нас есть десятичное число 217. Нам необходимо преобразовать его в двоичный код. Для этого делим его на число 2 до того момента, пока в остатке не получится ноль или единица.
- 217/2=108 с остатком 1. Отдельно выписываем остатки, именно они и будут создавать наш окончательный ответ.
- 108/2=54. Здесь остатком является число 0, так как 108 нацело делится. Не забываем помечать себе остатки. Ведь если потерять хоть одну цифру, изначальное число уже будет другим.
- 54/2=27, остаток 0.
- 27/2=13, записываем 1 в остаток. Наши числа из остатка создают бинарный код, который необходимо считывать в обратном порядке.
- 13/2=6. Здесь единица в остатке, выписываем ее.
- 6/2=3 с остатком 0. В конечном ответе цифр должно быть на одну больше, чем всех действий, произведенных вами.
- 3/2=1 с остатком 1. Записываем остаток и число 1, которое является окончательным делением.
Если оформлять ответ, начиная с цифры в первом действии, в результате получится 10011011, но это неверно. Бинарное число необходимо переписать в обратном порядке. Вот окончательный результат перевода числа: 11011001. Содержательный и алфавитный подход к измерению информации используют данные именно такого формата для хранения и передачи. Двоичный код записывается в кодовую таблицу и хранится там, пока не понадобится вывести его на экран монитора. Затем осуществляется перевод информации в привычный для нас вид, называемый декодированием.
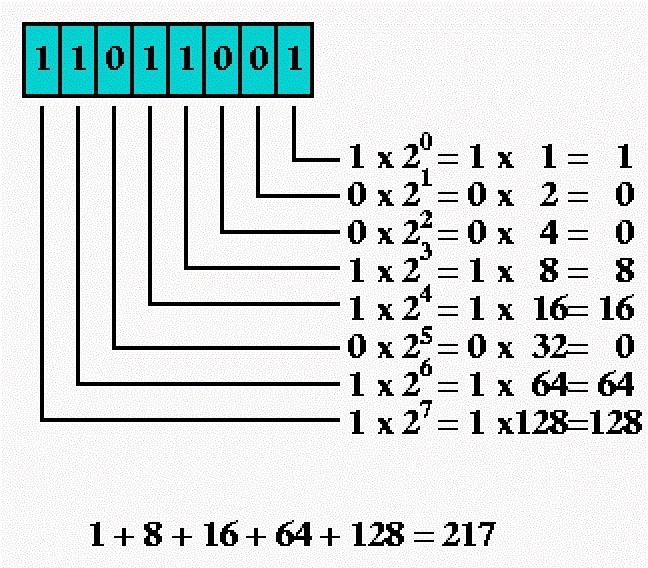
На картинке хорошо виден алгоритм перевода из бинарного вида в десятичный код. Он осуществляется по простой формуле. Первую цифру кода умножаем на 2 в степени 0, прибавляем к ней следующую цифру, умноженную на 2 в большей степени, и так далее. В результате, как видно из картинки, получаем то же число, что и изначальное при кодировании.
Алфавитный подход к измерению информации: суть, единицы
В компьютерной науке существует множество терминов, которыми все чаще оперируют в обиходе. Так, алфавит в информатике означает набор всех символов, включая скобки, пробел, знаки препинания, символы кириллицы, латиницы, которые являются ничем иным как текстовой составной частью. Здесь имеют место два определения, по которым и будет рассчитываться данная величина.
2. Но в некоторых случаях целесообразнее высчитать нужную нам величину, представив равновероятностное появление каждого символа. И тут будет использоваться другая формула расчета.
В этом и заключается алфавитный подход к измерению информации.

Равновероятностная встречаемость знаков в текстовом файле
Допустим, на экране монитора выведен текст. Перед нами стоит задача посчитать, какой объем памяти компьютера он занимает. Пусть текст состоит из 100 символов. Получается, что вероятность появления одной буквы, символа или знака будет составлять одну сотую часть всего объема. Если почитать книгу по теории вероятности, можно найти такую достаточно простую формулу, которая точно определит числовую величину шанса появления того или иного знака в любой позиции текста.
Наверное, доказательство формул и теорем не всем будет интересно, поэтому, учитывая формулы известных ученых, выводится расчетное выражение:
где i – это та величина, которую нам необходимо узнать, p – числовое значение возможности возникновения знака в текстовой позиции, N в большинстве случаев равняется 2, ведь компьютерная машина кодирует данные в бинарный код, состоящий из двух величин.
Алфавитный объемный подход к измерению информации предполагает, что вес одного символьного знака равняется 1 биту – минимальной единице измерения. По формуле можно определить, чему равняется байт, килобайт, мегабайт и др.
Разная вероятность встречаемости символов в тексте
Если предполагать, что знаки появляются с разной частотой (соответственно, и в любой позиции текста их вероятность появления различна), тогда можно сказать, что их информационный вес тоже разный. Необходимо вычислять по другой формуле измерение информации. Алфавитный подход тем и универсален, что предполагает как равную, так и разную возможность частоты встречаемости знака в тексте. Мы не будем затрагивать сложную формулу расчета данной величины с учетом различной вероятности встречаемости символа. Необходимо понимать, что такие буквы, как "ъ", "х", "ф", "ч", в русских словах встречаются гораздо реже. Поэтому возникает необходимость считать частоту появления по другой формуле. Проведя некоторые расчеты, ученые пришли к выводу, что информационный вес редко попадающихся символов гораздо больше, нежели вес букв, которые часто встречаются. Чтобы вычислить объем текста, необходимо учитывать величину повторений каждого символа и его информационный вес, а также размер алфавита.
Измерение информации: тонкости содержательного аспекта
События, встречаемые с равной вероятностью
Как и в случае, когда применяется объективный алфавитный подход к измерению информации, искомая формула при содержательном подходе рассчитывается с учетом уже известной закономерности, которую вывел ученый Хартли:
где i – это величина события, которую нам необходимо найти, а N – число событий, встречаемых с равновероятностной частотой. Величина i считается в минимальной единице исчисления – битах. Можно i выразить через логарифм.
Пример расчета равновероятностного события
Допустим, у нас на тарелке лежит 64 пельменя, в одном из которых спрятан сюрприз вместо мяса. Необходимо посчитать, сколько информации содержит событие, когда вытянули именно этот пельмень с сюрпризом, то есть осуществить измерение информации. Алфавитный подход такой же простой, как и объективный. В двух случаях использовалась бы одна и та же формула для расчета количественного объема информационных материалов. Подставляем известную формулу величины: 2 i =64=2 6 . Результат: i=6 бит.

Измерение информации с учетом различной вероятности появления события
Допустим, у нас есть некоторое событие с вероятностью появления p. Будем считать, что величина i, рассчитываемая в битах, - это число, характеризирующее тот факт, что событие произошло. Исходя из этого, можно утверждать, что величины можно рассчитать по существующей формуле: 2 i =1/p.
Отличия алфавитного и содержательного подходов к информационному измерению
Чем объемный подход отличается от содержательного? Ведь формулы расчета величин количества информации совершенно одни и те же. Разница в том, что алфавитный аспект можно использовать, если вы работаете с текстами, а содержательный позволяет решать любые задачи теории вероятности, высчитывать объем информации некого события с учетом его вероятного появления.
Выводы
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
§ 2. Подходы к измерению информации
Информатика. 10 класса. Босова Л.Л. Оглавление
Информация и её свойства
Информация и её свойства являются объектом исследования целого ряда научных дисциплин, таких как:
? теория информации (математическая теория систем передачи информации);
? кибернетика (наука об общих закономерностях процессов управления и передачи информации в машинах, живых организмах и обществе);
? информатика (изучение процессов сбора, преобразования, хранения, защиты, поиска и передачи всех видов информации и средств их автоматизированной обработки);
? семиотика (наука о знаках и знаковых системах);
? теория массовой коммуникации (исследование средств массовой информации и их влияния на общество) и др.
Рассмотрим более детально подходы к определению понятия информации, важные с позиций её измерения:
1) определение К. Шеннона, применяемое в математической теории информации;
2) определение А. Н. Колмогорова, применяемое в отраслях информатики, связанных с использованием компьютеров.
2.1. Содержательный подход к измерению информации

Информация — это снятая неопределённость. Величина неопределённости некоторого события — это количество возможных результатов (исходов) данного события.
Такой подход к измерению информации называют содержательным.
Итак, количество возможных результатов (исходов) события, состоящего в том, что книга поставлена в шкаф, равно восьми: 1, 2, 3, 4, 5, 6, 7 и 8.
Метод поиска, на каждом шаге которого отбрасывается половина вариантов, называется методом половинного деления. Этот метод широко используется в компьютерных науках.

1) обойтись минимальным количеством вопросов;




1) Да — Да — Да — Да;
2) Нет — Нет — Нет — Нет;
3) Да — Нет — Да — Нет.
При N, равном целой степени двойки (2, 4, 8, 16, 32 и т. д.), это уравнение легко решается в уме. Решать такие уравнения при других N вы научитесь чуть позже, в курсе математики 11 класса.

2.2. Алфавитный подход к измерению информации
Однако при хранении и передаче информации с помощью технических устройств целесообразно отвлечься от её содержания и рассматривать информацию как последовательность символов (букв, цифр, кодов цвета точек изображения и т. д.) некоторого алфавита.
Информация — последовательность символов (букв, цифр, кодов цвета точек изображения и т. д.) некоторого алфавита.
Минимальная мощность алфавита (количество входящих в него символов), пригодного для кодирования информации, равна 2. Такой алфавит называется двоичным. Один символ двоичного алфавита несёт 1 бит информации.

Андрей Николаевич Колмогоров (1903-1987) — один из крупнейших математиков XX века. Им получены основополагающие результаты в математической логике, теории сложности алгоритмов, теории информации, теории множеств и ряде других областей математики и её приложений.
В отличие от определения количества информации по Колмогорову в определении информационного объёма не требуется, чтобы число двоичных символов было минимально возможным. При оптимальном кодировании понятия количества информации и информационного объёма совпадают.
Из курса информатики основной школы вы знаете, что двоичные коды бывают равномерные и неравномерные. Равномерные коды в кодовых комбинациях содержат одинаковое число символов, неравномерные — разное.
Первый равномерный двоичный код был изобретён французом Жаном Морисом Бодо в 1870 году. В коде Бодо используются сигналы двух видов, имеющие одинаковую длительность и абсолютную величину, но разную полярность. Длина кодов всех символов алфавита равна пяти (рис. 1.7).

Рис. 1.7. Фрагмент кодовой таблицы кода Бодо
Всего с помощью кода Бодо можно составить 2 5 = 32 комбинации.
Пример 5. Слово WORD, закодированное с помощью кода Бодо, будет выглядеть так:

Пример 6. Для двоичного представления текстов в компьютере чаще всего используется равномерный восьмиразрядный код. С его помощью можно закодировать алфавит из 256 символов (2 8 = 256). Фрагмент кодовой таблицы ASCII представлен на рисунке 1.8.

Рис. 1.8. Фрагмент кодовой таблицы ASCII
Слово WORD, закодированное с помощью таблицы ASCII:

Из курса информатики основной школы вам известно, что с помощью i-разрядного двоичного кода можно закодировать алфавит, мощность N которого определяется из соотношения:
2 i = N.
Иными словами, зная мощность используемого алфавита, всегда можно вычислить информационный вес символа — минимально возможное количество бит, требуемое для кодирования символов этого алфавита. При этом информационный вес символа должен быть выражен целым числом.
Соотношение для определения информационного веса символа алфавита можно получить и из следующих соображений.
1) определить мощность используемого алфавита N;
2) из соотношения 2 i = N определить i — информационный вес символа алфавита в битах (длину двоичного кода символа из используемого алфавита мощности N);
I = К * i,
где I — информационный вес символа в битах, связанный с мощностью используемого алфавита N соотношением:
2 i = N.
Пример 7. Для регистрации на некотором сайте пользователю надо придумать пароль, состоящий из 10 символов. В качестве символов можно использовать десятичные цифры и шесть первых букв латинского алфавита, причём буквы используются только заглавные. Пароли кодируются посимвольно. Все символы кодируются одинаковым и минимально возможным количеством бит. Для хранения сведений о каждом пользователе в системе отведено одинаковое и минимально возможное целое число байт.
Необходимо выяснить, какой объём памяти потребуется для хранения 100 паролей.

2.3. Единицы измерения информации
Итак, в двоичном коде один двоичный разряд несёт 1 бит информации. 8 бит образуют один байт. Помимо бита и байта, для измерения информации используются более крупные единицы:
1 Кбайт (килобайт) = 2 10 байт;
1 Мбайт (мегабайт) = 2 10 Кбайт = 2 20 байт;
1 Гбайт (гигабайт) = 2 10 Мбайт = 2 20 Кбайт = 2 30 байт;
1 Тбайт (терабайт) = 2 10 Гбайт = 2 20 Мбайт = 2 30 Кбайт = 2 40 байт;
1 Пбайт (петабайт) = 2 10 Тбайт = 2 20 Гбайт = 2 30 Мбайт = 2 40 Кбайт = 2 50 байт.
Это произошло потому, что 2 10 = 1024 ? 1000 = 10 3 . Поэтому 1024 байта и стали называть килобайтом, 2 10 килобайта стали называть мегабайтом и т. д.
Чтобы избежать путаницы с различным использованием одних и тех же приставок, в 1999 г. Международная электротехническая комиссия ввела новый стандарт наименования двоичных приставок. Согласно этому стандарту, 1 килобайт равняется 1000 байт, а величина 1024 байта получила новое название — 1 кибибайт (Кибайт).
Пример 8. При регистрации в компьютерной системе каждому пользователю выдаётся пароль длиной в 12 символов, образованный из десятичных цифр и первых шести букв английского алфавита, причём буквы могут использоваться как строчные, так и прописные — соответствующие символы считаются разными. Пароли кодируются посимвольно. Все символы кодируются одинаковым и минимально возможным количеством бит. Для хранения сведений о каждом пользователе в системе отведено одинаковое и минимально возможное целое число байт.
Кроме собственно пароля для каждого пользователя в системе хранятся дополнительные сведения, для которых отведено 12 байт. На какое максимальное количество пользователей рассчитана система, если для хранения сведений о пользователях в ней отведено 200 Кбайт?
Прежде всего, выясним мощность алфавита, используемого для записи паролей: N — 6 (буквы прописные) + 6 (буквы строчные) + 10 (десятичные цифры) = 22 символа.
Для кодирования одного из 22 символов требуется 5 бит памяти (4 бита позволят закодировать всего 2 4 = 16 символов, 5 бит позволят закодировать уже 2 5 = 32 символа); 5 — минимально возможное количество бит для кодирования 22 разных символов алфавита, используемого для записи паролей.
Для хранения всех 12 символов пароля требуется 12 • 5 = 60 бит. Из условия следует, что пароль должен занимать целое число байт; т. к. 60 не кратно восьми, возьмём ближайшее большее значение, которое кратно восьми: 64 = 8 • 8. Таким образом, один пароль занимает 8 байт.
Информация о пользователе занимает 20 байт, т. к. содержит не только пароль (8 байт), но и дополнительные сведения (12 байт).


САМОЕ ГЛАВНОЕ
I = K * i, где i — информационный вес символа в битах, связанный с мощностью используемого алфавита N соотношением 2 i = N. Единицы измерения информации:
1 Кбайт (килобайт) = 2 10 байт;
1 Мбайт (мегабайт) = 2 10 Кбайт = 2 20 байт;
1 Гбайт (гигабайт) = 2 10 Мбайт = 2 20 Кбайт = 2 30 байт;
1 Тбайт (терабайт) = 2 10 Гбайт = 2 20 Мбайт = 2 30 Кбайт = 2 40 байт;
1 Пбайт (петабайт) = 2 10 Тбайт = 2 20 Гбайт = 2 30 Мбайт = 2 40 Кбайт = 2 50 байт.
Вопросы и задания
1. Что такое неопределённость знания о результате какого-либо события? Приведите пример.
2. В чём состоит суть содержательного подхода к определению количества информации? Что такое бит с точки зрения содержательного подхода?
3. Паролем для приложения служит трёхзначное число в шестнадцатеричной системе счисления. Возможные варианты пароля:

Ответ на какой вопрос (см. ниже) содержит 1 бит информации?
1) Это число записано в двоичной системе счисления?
2) Это число записано в четверичной системе счисления?
3) Это число может быть записано в восьмеричной системе счисления?
4) Это число может быть записано в десятичной системе счисления?
5) Это число может быть записано в шестнадцатеричной системе счисления?
4. При угадывании целого числа в некотором диапазоне было получено 5 бит информации. Каковы наибольшее и наименьшее числа этого диапазона?
5. Какое максимальное количество вопросов достаточно задать вашему собеседнику, чтобы точно определить день и месяц его рождения?
6. В чём состоит суть алфавитного подхода к измерению информации? Что такое бит с точки зрения алфавитного подхода?
8. Какие единицы используются для измерения объёма информации, хранящейся на компьютере?
13. При регистрации в компьютерной системе каждому пользователю выдаётся пароль, состоящий из 6 символов и содержащий только символы из шестибуквенного набора А, В, С, D, Е, F. Для хранения сведений о каждом пользователе отведено одинаковое и минимально возможное целое число байт. При этом используют посимвольное кодирование паролей и все символы кодируются одинаковым и минимально возможным количеством бит. Кроме собственно пароля для каждого пользователя в системе хранятся дополнительные сведения, занимающие 15 байт. Определите объём памяти в байтах, необходимый для хранения сведений о 120 пользователях.

Понятие информации – одно из фундаментальных в современной науке.
Наряду с такими понятиями, как вещество , энергия , пространство и время , оно составляет основу современной научной картины мира.
Информация – от латинского informatio – сведения, разъяснения, изложение.
Под информацией понимают:

Возникло от слова INFORMATIO – разъяснение, изложение.
Под словом ИНФОРМАЦИЯ понимаем:
Сведения, обмениваемые между людьми, человеком и автоматом, автоматом и автоматом, обмен сигналами в растительном и животном мире, передача признаков от клетки к клетке, от организма к организму.

Процесс, происходящий при установлении связи между источником (генератором) и её получателем (приемником), называется информационным процессом.

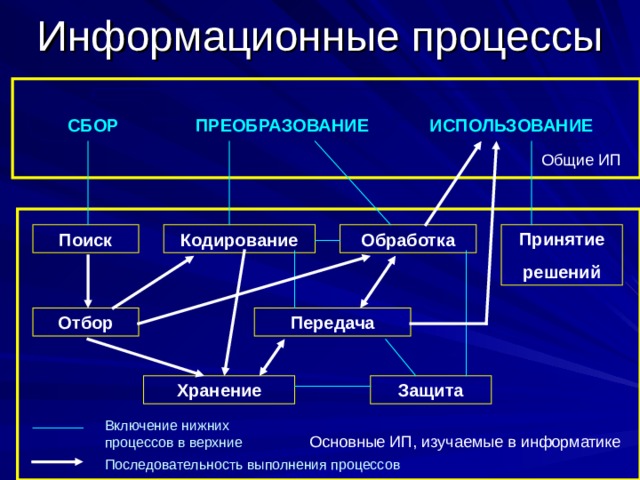
ПРЕОБРАЗОВАНИЕ
ИСПОЛЬЗОВАНИЕ
Кодирование
Включение нижних процессов в верхние
Основные ИП, изучаемые в информатике
Последовательность выполнения процессов

Поиск и систематизация информации
Сбор информации состоит из процессов поиска и отбора (систематизации) информации.
Сбор информации всегда осуществляется с определенной целью , которая во многом определяет выбор методов поиска и критерии отбора найденной информации
Методы поиска информации:
Поиск информации всегда сопровождается её отбором .
Отбор информации предполагает оценку найденной информации по
и выбор только информации, полезной для решения поставленной задачи.
Для ускорения процесса получения наиболее полной информации по интересующему вопросу в хранилищах информации составляют каталоги .
Подлинный переворот в службе хранения, отбора информации произвели автоматизированные информационно-поисковые системы (ИПС ), позволившие сэкономить время и усилия и существенно сократить пространство хранилищ.

Хранение информации необходимо для распространения её во времени.
Хранилище информации зависит от её носителя (книга – библиотека, картина – музей, фотография – альбом).
Носителем информации может быть:
Основные хранилища информации:
- для человека – память, в том числе генетическая;
- для общества – библиотеки, видеотеки, фонотеки, архивы, патентные бюро, медиатеки и т.п.
Компьютерные хранилища : базы и банки данных, информационно-поисковые системы (ИПС), электронные энциклопедии, медиатекии и т.п.
Информация, предназначенная для хранения и передачи, как правило, представлена в форме документа.
Под документом понимается информация на любом материальном носителе , предназначенная для распространения в пространстве и времени.
Хранение очень больших объёмов информации оправдано только при условии, если поиск нужной информации можно осуществить достаточно быстро, а сведения получить в доступной форме.
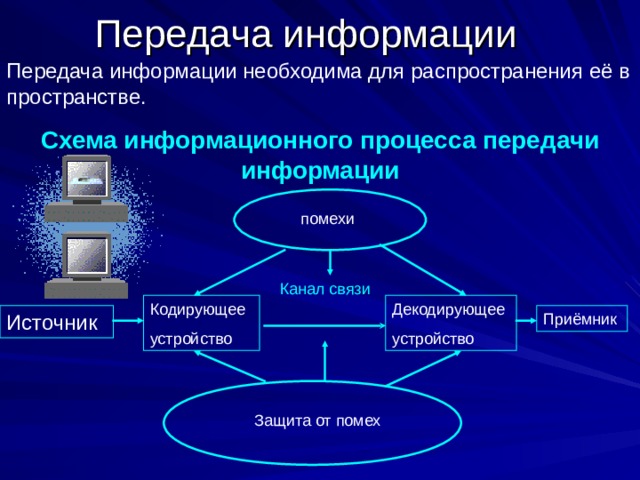
Передача информации необходима для распространения её в пространстве.
Схема информационного процесса передачи информации
Защита от помех

- упорядоченная совокупность взаимосвязанных элементов (устройств), необходимых для генерации, переработки, передачи и приема информации.
Виды социальной информации
по способу восприятия
по степени значимости
- визуальная
- аудиальная
- обонятельная
- тактильная
- вкусовая
по форме представления
- знания, умения
- прогнозы, планы
- чувства, интуиция
- опыт, наследственная память
- текстовая
- числовая
- графическая
- звуковая
- научная;
- производственная;
- техническая;
- управленческая
Общественная
Полнота Неполнота (недостаточность), а также
Актуальность Неактуальность (устаревание
(своевременность) или преждевременность )

знаний о некотором
знаний в два раза,
несет 1 бит
Равновероятность означает, что ни одно событие не имеет преимущества перед другими
N= 32 N = 2 i
i = ? 32 = 2 i
Ответ: 5 бит

позволяет определить количество информации, заключенной в тексте.
Полный набор символов, используемый для кодирования текста, называется алфавитом или азбукой
Полное количество символов в алфавите называется мощностью (размером) алфавита .
Если допустить, что все символы алфавита встречаются в тексте с равной частотой (равновероятно), то количество информации, которое несёт каждый символ , вычисляется по формуле:
2 i = N , где N - мощность алфавита;
i -информационная ёмкость (вес) одного символа алфавита.

Компьютерный алфавит состоит из 256 символов. Какое количество информации несёт один символ этого алфавита?
N= 256 N = 2 i
i = ? 256 = 2 i
Ответ: 8 бит

Единицы измерения информации
8 бит = 1 байт
1 Кбайт (килобайт) = 2 10 байт = 1024 байт
1 Мбайт (мегабайт) = 2 10 Кбайт =
1024 Кбайт=1024х1024=1048576 байт
1 Гбайт (гигабайт) = 2 10 Мбайт = 1024 Мбайт

Как измерить объём информации в тексте из k символов
V i = k . i
Где V i – информационный объём текста;
i – информационный вес одного символа;
k – количество символов в тексте
Читайте также: