
В чем заключается принцип последовательного кодирования кратко
Обновлено: 07.07.2024
Если внимательно рассмотреть ASCII таблицу кодов, то можно заметить, что все буквы кодируются последовательно за исключением буквы "ё".
Поэтому в пределах ВСЕГО алфавита принцип не соблюдается, но в пределах большей его части соблюдается.
Мы постоянно добавляем новый функционал в основной интерфейс проекта. К сожалению, старые браузеры не в состоянии качественно работать с современными программными продуктами. Для корректной работы используйте последние версии браузеров Chrome, Mozilla Firefox, Opera, Microsoft Edge или установите браузер Atom.
1. В чем преимущества хранения текстов в файлах по сравнению с бумажным способом хранения?
Имея компьютер, можно создавать тексты, не тратя на это лишнее время и бумагу. Не нужно зачеркивать и перписывать заново.
Файлы компактно размещены, их можно удалить, если они не нужны, и помесить на их место другие файлы.
С помощью компьютера легко скопировать файлы в любом количестве на другие носители.
Файл c текстом можно быстро переслать другому человеку по электронной почте.
2. Что такое таблица кодировки? Какие таблицы кодировки вы знаете?
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки. ASCII, ANSI, СР1251, UNICODE.
3. В чем заключается принцип последовательного кодирования?
Это означает, что в таблице кодировки буквы располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений.
4. Сколько места в памяти компьютера занимает код одного символа, если используется таблица кодировки ASCII?
2 8 = 256
8 битов = 1 байт
1 символ = 1 байт
5. Сколько места в памяти компьютера занимает код одного символа, если используется таблица кодировки UNICODE?
6. Что такое гипертекст? Какие возможности предоставляет гипертекст пользователю?
Гипертекст — это текст, организованный так, что его можно просматривать в последовательности смысловых связей между его отдельными фрагментами. Такие связи называются гиперсвязями (гиперссылками). Гипертекст предоставляет возможность перемещаться по смысловым связям в тексте.
7. Познакомьтесь с кодовой страницей, используемой в школьных компьютерах. Выясните, соблюдается ли принцип последовательного кодирования алфавита из русских букв (их называют кириллицей).
8. Закодируйте короткую фразу на русском языке. Обменяйтесь с соседом по парте полученными кодами и декодируйте тексты друг друга.
Я люблю информатику
11010000 10101111 100000 11010000 10111011 11010001 10001110 11010000 10110001 11010000 10111011 11010001 10001110 100000 11010000 10111000 11010000 10111101 11010001 10000100 11010000 10111110 11010001 10000000 11010000 10111100 11010000 10110000 11010001 10000010 11010000 10111000 11010000 10111010 11010001 10000011
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
Что такое принцип последовательного кодирования алфавитов? Приведите примеры алгоритмов, где он может быть использован.
Ответ
В любой кодовой таблице выполняется принцип последовательного кодирования латинского (английского) алфавита и алфавита десятичной системы счисления.
Это важное обстоятельство, которое часто учитывается в программах обработки символьной информации.
При выполнении операций отношений, применительно к символьным величинам, учитываются коды этих величин. Чем больше значение кода, тем символ считается больше. Истинными являются следующие отношения: ‘А’ с ‘В’, ‘Z’ > ‘Y’, ‘а’ > ‘А’. Значение символьной переменной С является прописной (заглавной) латинской буквой, если истинно логическое выражение:
Среди всего разнообразия информации, обрабатываемой на компьютере, значительную часть составляют числовая, текстовая, графическая и аудиоинформация. Познакомимся с некоторыми способами кодирования этих типов информации в ЭВМ.
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2 k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
- перевести число N в двоичную систему счисления;
- полученный результат дополнить слева незначащими нулями до k разрядов.
Пример. Получить внутреннее представление целого числа 1607 в 2-х байтовой ячейке.
Переведем число в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке будет следующим: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
- получить внутреннее представление положительного числа N;
- обратный код этого числа заменой 0 на 1 и 1 на 0;
- полученному числу прибавить 1.
Пример. Получим внутреннее представление целого отрицательного числа -1607. Воспользуемся результатом предыдущего примера и запишем внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Инвертированием получим обратный код : 1111 1001 1011 1000. Добавим единицу: 1111 1001 1011 1001 - это и есть внутреннее двоичное представление числа -1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p .
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12.345 = 0.0012345 x 10 4 = 1234.5 x 10 -2 = 0.12345 x 10 2
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию: 0.1p мантисса меньше 1 и первая значащая цифра - не ноль (p - основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12.345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере - это 2.
Кодирование текста
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 2 8 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов. О кодировании символов русского алфавита рассказывается в главе "Обработка документов".
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части - растровую и векторную графику .
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element ). Код пиксела содержит информацию о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится - не светится), а для его кодирования достаточно одного бита памяти: 1 - белый, 0 - черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 - черный, 10 - зеленый, 01 - красный, 11 - коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов - красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов - К и количество битов для их кодировки - N связаны между собой простой формулой: 2 N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения - линия, прямоугольник, окружность или фрагмент текста - располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Подробнее о графических форматах рассказывается в разделе "Графика на компьютере".
Кодирование звука
Из курса физики вам известно, что звук - это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой - аналоговый - сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера . Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его - аналого-цифровым преобразователем (АЦП).
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь - ЦАП ), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки - нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке . В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI .
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI -редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
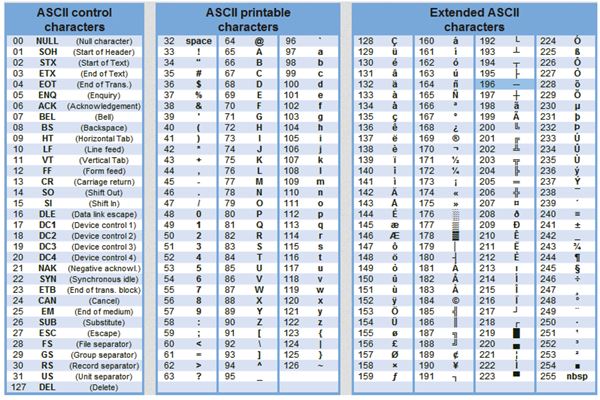
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
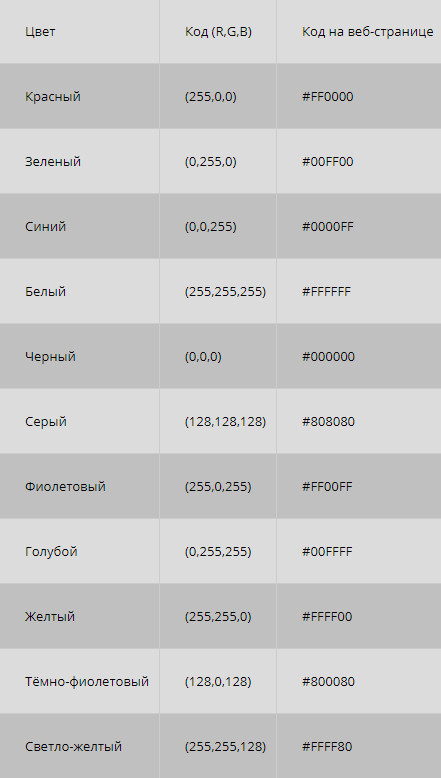
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.
Читайте также:
- Как выучиться на воспитателя детского сада
- Анализ результатов деятельности подразделения кратко
- Как река печора изменяется в разные времена года кратко
- Для чего необходимо различать сильную и слабую позицию звука кратко
- Какие чувства вызывают у вас образы главных героев прокомментируйте мнение искусствоведов кратко