
Регрессионный анализ кратко и понятно
Обновлено: 02.07.2024
Регрессио́нный (линейный) анализ — статистический метод исследования влияния одной или нескольких независимых переменных на зависимую переменную . Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных (см. Ложная корреляция), а не причинно-следственные отношения.
Содержание
Цели регрессионного анализа
- Определение степени детерминированностивариации критериальной (зависимой) переменной предикторами (независимыми переменными)
- Предсказание значения зависимой переменной с помощью независимой(-ых)
- Определение вклада отдельных независимых переменных в вариацию зависимой
Регрессионный анализ нельзя использовать для определения наличия связи между переменными, поскольку наличие такой связи и есть предпосылка для применения анализа.
Математическое определение регрессии
Строго регрессионную зависимость можно определить следующим образом. Пусть , — случайные величины с заданным совместным распределением вероятностей. Если для каждого набора значений определено условное математическое ожидание

(уравнение регрессии в общем виде),
то функция называется регрессией величины Y по величинам , а её график — линией регрессии по , или уравнением регрессии.
Зависимость от проявляется в изменении средних значений Y при изменении . Хотя при каждом фиксированном наборе значений величина остаётся случайной величиной с определённым рассеянием.
Для выяснения вопроса, насколько точно регрессионный анализ оценивает изменение Y при изменении , используется средняя величина дисперсии Y при разных наборах значений (фактически речь идет о мере рассеяния зависимой переменной вокруг линии регрессии).
Метод наименьших квадратов (расчёт коэффициентов)
На практике линия регрессии чаще всего ищется в виде линейной функции (линейная регрессия), наилучшим образом приближающей искомую кривую. Делается это с помощью метода наименьших квадратов, когда минимизируется сумма квадратов отклонений реально наблюдаемых " width="" height="" />
от их оценок " width="" height="" />
(имеются в виду оценки с помощью прямой линии, претендующей на то, чтобы представлять искомую регрессионную зависимость):


(M — объём выборки). Этот подход основан на том известном факте, что фигурирующая в приведённом выражении сумма принимает минимальное значение именно для того случая, когда .
Для решения задачи регрессионного анализа методом наименьших квадратов вводится понятие функции невязки:

Условие минимума функции невязки:

Полученная система является системой линейных уравнений с неизвестными
Если представить свободные члены левой части уравнений матрицей

а коэффициенты при неизвестных в правой части матрицей


то получаем матричное уравнение: , которое легко решается методом Гаусса. Полученная матрица будет матрицей, содержащей коэффициенты уравнения линии регрессии:

Для получения наилучших оценок необходимо выполнение предпосылок МНК (условий Гаусса−Маркова). В англоязычной литературе такие оценки называются BLUE (Best Linear Unbiased Estimators) − наилучшие линейные несмещенные оценки.
Интерпретация параметров регрессии
Параметры являются частными коэффициентами корреляции; интерпретируется как доля дисперсии Y, объяснённая , при закреплении влияния остальных предикторов, то есть измеряет индивидуальный вклад в объяснение Y. В случае коррелирующих предикторов возникает проблема неопределённости в оценках, которые становятся зависимыми от порядка включения предикторов в модель. В таких случаях необходимо применение методов анализа корреляционного и пошагового регрессионного анализа.
Говоря о нелинейных моделях регрессионного анализа, важно обращать внимание на то, идет ли речь о нелинейности по независимым переменным (с формальной точки зрения легко сводящейся к линейной регрессии), или о нелинейности по оцениваемым параметрам (вызывающей серьёзные вычислительные трудности). При нелинейности первого вида с содержательной точки зрения важно выделять появление в модели членов вида , , свидетельствующее о наличии взаимодействий между признаками , и т. д (см. Мультиколлинеарность).
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения называется регрессией y по x .
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция такая, что сумма квадратов разностей минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений вокруг регрессии является дисперсия.
- k — число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x .
Линейная регрессия
Уравнения линейной регрессии можно записать в виде
В матричном виде это выгладит
- y — зависимая переменная;
- x — независимая переменная;
- β — коэффициенты, которые необходимо найти с помощью МНК;
- ε — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;

Случайная величина может быть интерпретирована как сумма из двух слагаемых:
- — полная дисперсия (TSS).
- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
Еще одно ключевое понятие — коэффициент корреляции R 2 .
Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая εi обладает одинаковой и конечной дисперсией σ 2 и не коррелирует с другой εi. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.

Неоднородность дисперсии
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.

Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ≤ d ≤ 4). Если автокорреляции нет, то значения критерия d≈2, при позитивной автокорреляции d≈0, при отрицательной — d≈4.
- Неоднородность дисперсии — Тест Уайта, , при нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
В этой формуле — коэффициент взаимной детерминации между и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма ln .
- Таким же способом возможно решить проблему неоднородной дисперсии, с помощью ln , или sqrt преобразований зависимой переменной, либо же используя взвешенный МНК.
- Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
Теперь собственно сама модель, используем функцию lm .
В первой строке мы задаем параметры линейной регрессии. Строка points ~. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points ~ reads , набор переменных — points ~ reads + comm .
Перейдем теперь к расшифровке полученных результатов.
- Intercept — Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, или intercept .
- R-squared — Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.
- Adjusted R-squared — Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
- F-statistic — Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.
- t value — Критерий, основанный на t распределении Стьюдента . Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что при t > 2 фактор является значимым для модели.
- p value — Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значение p value ниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми , F-статистика выросла, так же как и скорректированный коэффициент детерминации .
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
В статистическом моделировании регрессионный анализ представляет собой исследования, применяемые с целью оценки взаимосвязи между переменными. Этот математический метод включает в себя множество других методов для моделирования и анализа нескольких переменных, когда основное внимание уделяется взаимосвязи между зависимой переменной и одной или несколькими независимыми. Говоря более конкретно, регрессионный анализ помогает понять, как меняется типичное значение зависимой переменной, если одна из независимых переменных изменяется, в то время как другие независимые переменные остаются фиксированными.

Во всех случаях целевая оценка является функцией независимых переменных и называется функцией регрессии. В регрессионном анализе также представляет интерес характеристика изменения зависимой переменной как функции регрессии, которая может быть описана с помощью распределения вероятностей.
Задачи регрессионного анализа
Данный статистический метод исследования широко используется для прогнозирования, где его использование имеет существенное преимущество, но иногда это может приводить к иллюзии или ложным отношениям, поэтому рекомендуется аккуратно его использовать в указанном вопросе, поскольку, например, корреляция не означает причинно-следственной связи.
Разработано большое число методов для проведения регрессионного анализа, такие как линейная и обычная регрессии по методу наименьших квадратов, которые являются параметрическими. Их суть в том, что функция регрессии определяется в терминах конечного числа неизвестных параметров, которые оцениваются из данных. Непараметрическая регрессия позволяет ее функции лежать в определенном наборе функций, которые могут быть бесконечномерными.
Как статистический метод исследования, регрессионный анализ на практике зависит от формы процесса генерации данных и от того, как он относится к регрессионному подходу. Так как истинная форма процесса данных, генерирующих, как правило, неизвестное число, регрессионный анализ данных часто зависит в некоторой степени от предположений об этом процессе. Эти предположения иногда проверяемы, если имеется достаточное количество доступных данных. Регрессионные модели часто бывают полезны даже тогда, когда предположения умеренно нарушены, хотя они не могут работать с максимальной эффективностью.
В более узком смысле регрессия может относиться конкретно к оценке непрерывных переменных отклика, в отличие от дискретных переменных отклика, используемых в классификации. Случай непрерывной выходной переменной также называют метрической регрессией, чтобы отличить его от связанных с этим проблем.
История
Самая ранняя форма регрессии - это всем известный метод наименьших квадратов. Он был опубликован Лежандром в 1805 году и Гауссом в 1809. Лежандр и Гаусс применили метод к задаче определения из астрономических наблюдений орбиты тел вокруг Солнца (в основном кометы, но позже и вновь открытые малые планеты). Гаусс опубликовал дальнейшее развитие теории наименьших квадратов в 1821 году, включая вариант теоремы Гаусса-Маркова.


Методы регрессионного анализа продолжают оставаться областью активных исследований. В последние десятилетия новые методы были разработаны для надежной регрессии; регрессии с участием коррелирующих откликов; методы регрессии, вмещающие различные типы недостающих данных; непараметрической регрессии; байесовские методов регрессии; регрессии, в которых переменные прогнозирующих измеряются с ошибкой; регрессии с большей частью предикторов, чем наблюдений, а также причинно-следственных умозаключений с регрессией.
Регрессионные модели
Модели регрессионного анализа включают следующие переменные:
- Неизвестные параметры, обозначенные как бета, которые могут представлять собой скаляр или вектор.
- Независимые переменные, X.
- Зависимые переменные, Y.
В различных областях науки, где осуществляется применение регрессионного анализа, используются различные термины вместо зависимых и независимых переменных, но во всех случаях регрессионная модель относит Y к функции X и β.
Приближение обычно оформляется в виде E (Y | X) = F (X, β). Для проведения регрессионного анализа должен быть определен вид функции f. Реже она основана на знаниях о взаимосвязи между Y и X, которые не полагаются на данные. Если такое знание недоступно, то выбрана гибкая или удобная форма F.
Зависимая переменная Y
Предположим теперь, что вектор неизвестных параметров β имеет длину k. Для выполнения регрессионного анализа пользователь должен предоставить информацию о зависимой переменной Y:
- Если наблюдаются точки N данных вида (Y, X), где N точки к данным. В этом случае имеется достаточно информации в данных, чтобы оценить уникальное значение для β, которое наилучшим образом соответствует данным, и модель регрессии, когда применение к данным можно рассматривать как переопределенную систему в β.
В последнем случае регрессионный анализ предоставляет инструменты для:
- Поиска решения для неизвестных параметров β, которые будут, например, минимизировать расстояние между измеренным и предсказанным значением Y.
- При определенных статистических предположениях, регрессионный анализ использует избыток информации для предоставления статистической информации о неизвестных параметрах β и предсказанные значения зависимой переменной Y.
Необходимое количество независимых измерений
Рассмотрим модель регрессии, которая имеет три неизвестных параметра: β0, β1 и β2. Предположим, что экспериментатор выполняет 10 измерений в одном и том же значении независимой переменной вектора X. В этом случае регрессионный анализ не дает уникальный набор значений. Лучшее, что можно сделать, оценить среднее значение и стандартное отклонение зависимой переменной Y. Аналогичным образом измеряя два различных значениях X, можно получить достаточно данных для регрессии с двумя неизвестными, но не для трех и более неизвестных.

Если измерения экспериментатора проводились при трех различных значениях независимой переменной вектора X, то регрессионный анализ обеспечит уникальный набор оценок для трех неизвестных параметров в β.
В случае общей линейной регрессии приведенное выше утверждение эквивалентно требованию, что матрица X Т X обратима.
Статистические допущения
Когда число измерений N больше, чем число неизвестных параметров k и погрешности измерений εi, то, как правило, распространяется затем избыток информации, содержащейся в измерениях, и используется для статистических прогнозов относительно неизвестных параметров. Этот избыток информации называется степенью свободы регрессии.
Основополагающие допущения
Классические предположения для регрессионного анализа включают в себя:
- Выборка является представителем прогнозирования логического вывода.
- Ошибка является случайной величиной со средним значением нуля, который является условным на объясняющих переменных.
- Независимые переменные измеряются без ошибок.
- В качестве независимых переменных (предикторов) они линейно независимы, то есть не представляется возможным выразить любой предсказатель в виде линейной комбинации остальных.
- Ошибки являются некоррелированными, то есть ковариационная матрица ошибок диагоналей и каждый ненулевой элемент являются дисперсией ошибки.
- Дисперсия ошибки постоянна по наблюдениям (гомоскедастичности). Если нет, то можно использовать метод взвешенных наименьших квадратов или другие методы.
Эти достаточные условия для оценки наименьших квадратов обладают требуемыми свойствами, в частности эти предположения означают, что оценки параметров будут объективными, последовательными и эффективными, в особенности при их учете в классе линейных оценок. Важно отметить, что фактические данные редко удовлетворяют условиям. То есть метод используется, даже если предположения не верны. Вариация из предположений иногда может быть использована в качестве меры, показывающей, насколько эта модель является полезной. Многие из этих допущений могут быть смягчены в более продвинутых методах. Отчеты статистического анализа, как правило, включают в себя анализ тестов по данным выборки и методологии для полезности модели.
Кроме того, переменные в некоторых случаях ссылаются на значения, измеренные в точечных местах. Там могут быть пространственные тенденции и пространственные автокорреляции в переменных, нарушающие статистические предположения. Географическая взвешенная регрессия - единственный метод, который имеет дело с такими данными.
Линейный регрессионный анализ
В линейной регрессии особенностью является то, что зависимая переменная, которой является Yi, представляет собой линейную комбинацию параметров. Например, в простой линейной регрессии для моделирования n-точек используется одна независимая переменная, xi, и два параметра, β0 и β1.
При множественной линейной регрессии существует несколько независимых переменных или их функций.
При случайной выборке из популяции ее параметры позволяют получить образец модели линейной регрессии.
В данном аспекте популярнейшим является метод наименьших квадратов. С помощью него получают оценки параметров, которые минимизируют сумму квадратов остатков. Такого рода минимизация (что характерно именно линейной регрессии) этой функции приводит к набору нормальных уравнений и набору линейных уравнений с параметрами, которые решаются с получением оценок параметров.
При дальнейшем предположении, что ошибка популяции обычно распространяется, исследователь может использовать эти оценки стандартных ошибок для создания доверительных интервалов и проведения проверки гипотез о ее параметрах.
Нелинейный регрессионный анализ
Пример, когда функция не является линейной относительно параметров, указывает на то, что сумма квадратов должна быть сведена к минимуму с помощью итерационной процедуры. Это вносит много осложнений, которые определяют различия между линейными и нелинейными методами наименьших квадратов. Следовательно, и результаты регрессионного анализа при использовании нелинейного метода порой непредсказуемы.
Расчет мощности и объема выборки
Здесь, как правило, нет согласованных методов, касающихся числа наблюдений по сравнению с числом независимых переменных в модели. Первое правило было предложено Доброй и Хардином и выглядит как N = t^n, где N является размер выборки, n - число независимых переменных, а t есть числом наблюдений, необходимых для достижения желаемой точности, если модель имела только одну независимую переменную. Например, исследователь строит модель линейной регрессии с использованием набора данных, который содержит 1000 пациентов (N). Если исследователь решает, что необходимо пять наблюдений, чтобы точно определить прямую (м), то максимальное число независимых переменных, которые модель может поддерживать, равно 4.
Другие методы
Несмотря на то что параметры регрессионной модели, как правило, оцениваются с использованием метода наименьших квадратов, существуют и другие методы, которые используются гораздо реже. К примеру, это следующие методы:
- Байесовские методы (например, байесовский метод линейной регрессии).
- Процентная регрессия, использующаяся для ситуаций, когда снижение процентных ошибок считается более целесообразным.
- Наименьшие абсолютные отклонения, что является более устойчивым в присутствии выбросов, приводящих к квантильной регрессии.
- Непараметрическая регрессия, требующая большого количества наблюдений и вычислений.
- Расстояние метрики обучения, которая изучается в поисках значимого расстояния метрики в заданном входном пространстве.
Программное обеспечение
Все основные статистические пакеты программного обеспечения выполняются с помощью наименьших квадратов регрессионного анализа. Простая линейная регрессия и множественный регрессионный анализ могут быть использованы в некоторых приложениях электронных таблиц, а также на некоторых калькуляторах. Хотя многие статистические пакеты программного обеспечения могут выполнять различные типы непараметрической и надежной регрессии, эти методы менее стандартизированы; различные программные пакеты реализуют различные методы. Специализированное регрессионное программное обеспечение было разработано для использования в таких областях как анализ обследования и нейровизуализации.

Научитесь выстраивать процессы для роста бизнеса и увеличения прибыли.
Зависимую переменную в бизнесе называют предиктором (характеристика, за изменением которой наблюдают). Это может быть уровень продаж, риски, ценообразование, производительность и так далее. Независимые переменные — те, которые могут объяснять поведение выше приведенных факторов (время года, покупательная способность населения, место продаж и многое другое).
Регрессионный анализ включает несколько моделей. Наиболее распространенные из них: линейная, мультилинейная (или множественная линейная) и нелинейная.

Как видно из названий, модели отличаются типом зависимости переменных: линейная описывается линейной функцией; мультилинейная также представляет линейную функцию, но в нее входит больше параметров (независимых переменных); нелинейная модель — та, в которой экспериментальные данные характеризуются функцией, являющейся нелинейной (показательной, логарифмической, тригонометрической и так далее).
Чаще всего используются простые линейные и мультилинейные модели.
Рассмотрим поподробнее принципы построения и адаптации результатов метода.
Предположения линейной модели
Линейный регрессионный анализ основан на шести фундаментальных предположениях:
- Переменные показывают линейную зависимость;
- Независимая переменная не случайна;
- Значение невязки (ошибки) равно нулю;
- Значение невязки постоянно для всех наблюдений;
- Значение невязки не коррелирует по всем наблюдениям;
- Остаточные значения подчиняются нормальному распределению.
Построение простой линейной регрессии
Простая линейная модель выражается с помощью следующего уравнения:
Y = a + bX
- Y — зависимая переменная
- X — независимая переменная (объясняющая)
- а – свободный член (сдвиг по оси OY)
- b – угловой коэффициент. Он указывает на поведение кривой (убывает или возрастает, угол между с осью)
a и b называют коэффициентами линейной регрессии. В их нахождении и заключается основная задача.

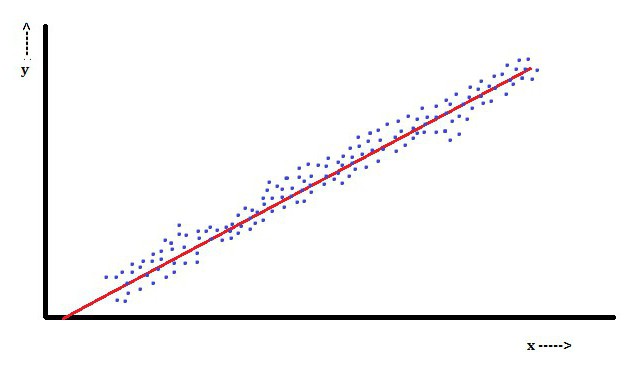
Рис.1. Линия линейной регрессии
Если в нашей задаче присутствуют несколько факторов: x1, x2, x3, от которых, мы полагаем, зависит y, то нужно использовать множественную регрессию, описываемую уравнением:

Рис.2. Множественная регрессия
Существует много способов определить коэффициенты a и b. Но самым простым и надежным является метод наименьших квадратов (можно научно доказать, что это лучший способ).
Идея метода: мы имеем значения y – числовой ряд или набор данных. Необходимо построить функцию регрессии Y=a + bX так, чтобы выражение (Y – y) 2 было минимальным. (Y – y) 2 – ошибка, которую мы хотим минимизировать. Минимизируется функционал благодаря подбору коэффициентов a и b.

Рис. 3. Линия линейной регрессии.
Пунктиром изображено расстояние y – Y для каждой точки.
Ключевым фактором применения любой статистической модели является правильное понимание предметной области и ее бизнес-приложения.
Линейная регрессия — это довольно простой, но мощный инструмент, который может существенно облегчить работу аналитика при изучении поведения потребителей; факторов, влияющих на производительность и окупаемость; улучшит понимание бизнес процессов в целом.
Примеры использования линейной регрессии
Прогнозирование показателей
Данную модель можно использовать для обнаружения тенденций и составления прогнозов. Предположим, продажи компании росли на протяжении двух лет. Путем проведения линейного анализа данных о ежемесячных продажах компания могла бы спрогнозировать продажи в будущие месяцы.
Оценка эффективности маркетинга
Прелесть линейной регрессии в том, что она позволяет улавливать отдельные воздействия каждой маркетинговой кампании, а также контролировать факторы, которые могут повлиять на продажи.
В реальных сценариях обычно существует несколько рекламных кампаний, которые проводятся в один и тот же период времени. Предположим, что две кампании запускаются на телевидении и радио параллельно. Построенная модель может уловить как изолированное, так и комбинированное влияние одновременного показа этой рекламы.
Оценка риска
Модель линейной регрессии хорошо работает для расчета рисков в сфере финансов или страхования. К примеру, компания по страхованию автомобилей может построить линейную регрессию, чтобы составить таблицу выплат по страховке, используя отношение прогнозируемых исков к заявленной страховой стоимости. Основными факторами в такой ситуации являются характеристики автомобиля, данные о водителе или демографическая информация. Результаты такого анализа помогут в принятии важных деловых решений.
Обнаружение важных факторов
В индустрии кредитования финансовая компания заинтересована в минимизации рисков. Поэтому ей важно понять пять основных факторов, вызывающих неплатежеспособность клиента. На основе результатов регрессионного анализа компания могла бы выявить эти факторы и определить варианты EMI (Equated Monthly Installment – фиксированный платеж, произведенный заемщиком кредитору в течение оговоренного срока), чтобы минимизировать дефолт среди сомнительных клиентов.
Ценообразование активов
Вывод
Несмотря на то, что линейная регрессия имеет довольно жесткие ограничения, поскольку она может работать только тогда, когда зависимая переменная имеет непрерывный характер и имеется линейная зависимость между переменными, модель является самым известным методом анализа и прогнозирования.
Читайте также: