
Кластерный анализ презентация кратко
Обновлено: 05.07.2024
Вы можете изучить и скачать доклад-презентацию на тему КЛАСТЕРНЫЙ АНАЛИЗ. Презентация на заданную тему содержит 35 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас - поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!





























КЛАСТЕРНЫЙ АНАЛИЗ Кластерный анализ – это совокупность методов, позволяющих классифицировать многомерные наблюдения. Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году, включает в себя более 100 различных алгоритмов. В отличие от задач классификации, кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных (интервальным данным, частотам, бинарным данным). При этом необходимо помнить, что переменные должны измеряться в сравнимых шкалах. Кластерный анализ позволяет сокращать размерность данных, делать ее наглядной.
ЗАДАЧИ КЛАСТЕРНОГО АНАЛИЗА Задачи кластерного анализа можно объединить в следующие группы: 1. Разработка типологии или классификации. 2. Исследование полезных концептуальных схем группирования объектов. 3. Представление гипотез на основе исследования данных. 4. Проверка гипотез или исследований для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных. Как правило, при практическом использовании кластерного анализа одновременно решается несколько из указанных задач.
СХОЖЕСТЬ КЛАСТЕРОВ СХОЖЕСТЬ КЛАСТЕРОВ Критерием для определения схожести и различия кластеров является расстояние между точками на диаграмме рассеивания. Это сходство можно "измерить", оно равно расстоянию между точками на графике. Способов определения меры расстояния между кластерами, называемой еще мерой близости, существует несколько. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда известны их координаты X и Y: Примечание: чтобы узнать расстояние между двумя точками, надо взять разницу их координат по каждой оси, возвести ее в квадрат, сложить полученные значения для всех осей и извлечь квадратный корень из суммы.
Математические характеристики кластера Математические характеристики кластера Кластер имеет следующие математические характеристики: Центр кластера - это среднее геометрическое место точек в пространстве переменных. Дисперсия кластера - это мера рассеяния точек в пространстве относительно центра кластера:
Среднеквадратичное отклонение (СКО) объектов относительно центра кластера: Среднеквадратичное отклонение (СКО) объектов относительно центра кластера: Радиус кластера - максимальное расстояние точек от центра кластера: Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам.
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным. Неоднозначность данной задачи может быть устранена экспертом или аналитиком
Работа кластерного анализа опирается на два предположения: Работа кластерного анализа опирается на два предположения: Первое предположение - рассматриваемые признаки объекта в принципе допускают желательное разбиение совокупности объектов на кластеры. Второе предположение - правильность выбора масштаба или единиц измерения признаков.
Методы кластерного анализа Методы кластерного анализа Методы кластерного анализа можно разделить на две группы: • иерархические; • неиерархические. Каждая из групп включает множество подходов и алгоритмов. Используя различные методы кластерного анализа, аналитик может получить различные решения для одних и тех же данных. Это считается нормальным явлением. Рассмотрим иерархические и неиерархические методы подробно.
Иерархические методы кластерного анализа Иерархические методы кластерного анализа Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении больших кластеров на меньшие. Иерархические агломеративные методы (Agglomerative Nesting, AGNES) Эта группа методов характеризуется последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров. В начале работы алгоритма все объекты являются отдельными кластерами. На первом шаге наиболее похожие объекты объединяются в кластер. На последующих шагах объединение продолжается до тех пор, пока все объекты не будут составлять один кластер.
Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA) Эти методы являются логической противоположностью агломеративным методам. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп. Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA) Эти методы являются логической противоположностью агломеративным методам. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп. Программная реализация алгоритмов кластерного анализа широко представлена в различных инструментах Data Mining, которые позволяют решать задачи достаточно большой размерности. Например, агломеративные методы реализованы в пакете SPSS, дивизимные методы - в пакете Statgraf.
Иерархические методы кластеризации различаются правилами построения кластеров. В качестве правил выступают критерии, которые используются при решении вопроса о "схожести" объектов при их объединении в группу (агломеративные методы) либо разделения на группы (дивизимные методы).
Меры сходства кластеров Для вычисления расстояния между объектами используются различные меры сходства (меры подобия), называемые также метриками или функциями расстояний. Евклидово расстояние, это наиболее популярная мера сходства. Квадрат евклидова расстояния. Для придания больших весов более отдаленным друг от друга объектам можем воспользоваться квадратом евклидова расстояния путем возведения в квадрат стандартного евклидова расстояния. Манхэттенское расстояние (расстояние городских кварталов), также называемое "хэмминговым" или "сити-блок" расстоянием.
Манхэттенское расстояние (расстояние городских кварталов), также называемое "хэмминговым" или "сити-блок" расстоянием. Манхэттенское расстояние (расстояние городских кварталов), также называемое "хэмминговым" или "сити-блок" расстоянием. Это расстояние рассчитывается как среднее разностей по координатам. В большинстве случаев эта мера расстояния приводит к результатам, подобным расчетам расстояния евклида. Однако, для этой меры влияние отдельных выбросов меньше, чем при использовании евклидова расстояния, поскольку здесь координаты не возводятся в квадрат. Расстояние Чебышева. Это расстояние стоит использовать, когда необходимо определить два объекта как "различные", если они отличаются по какому-то одному измерению. Процент несогласия. Это расстояние вычисляется, если данные являются категориальными.
Методы объединения или связи Когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Возникает следующий вопрос - как определить расстояния между кластерами? Существуют различные правила, называемые методами объединения или связи для двух кластеров. Метод ближнего соседа или одиночная связь. Здесь расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Этот метод позволяет выделять кластеры сколь угодно сложной формы при условии, что различные части таких кластеров соединены цепочками близких друг к другу элементов. В результате работы этого метода кластеры представляются длинными "цепочками" или "волокнистыми" кластерами, "сцепленными вместе" только отдельными элементами, которые случайно оказались ближе остальных друг к другу.
Метод наиболее удаленных соседей или полная связь Здесь расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. "наиболее удаленными соседями"). Метод хорошо использовать, когда объекты действительно происходят из различных "рощ". Если же кластеры имеют в некотором роде удлиненную форму или их естественный тип является "цепочечным", то этот метод не следует использовать.
Метод Варда (Ward's method). В качестве расстояния между кластерами берется прирост суммы квадратов расстояний объектов до центров кластеров, получаемый в результате их объединения (Ward, 1963). В отличие от других методов кластерного анализа для оценки расстояний между кластерами, здесь используются методы дисперсионного анализа. На каждом шаге алгоритма объединяются такие два кластера, которые приводят к минимальному увеличению целевой функции, т.е. внутригрупповой суммы квадратов. Этот метод направлен на объединение близко расположенных кластеров и "стремится" создавать кластеры малого размера.
Метод невзвешенного попарного среднего Метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages, UPGMA (Sneath, Sokal, 1973)). В качестве расстояния между двумя кластерами берется среднее расстояние между всеми парами объектов в них. Этот метод следует использовать, если объекты действительно происходят из различных "рощ", в случаях присутствия кластеров "цепочного" типа, при предположении неравных размеров кластеров.
Метод взвешенного попарного среднего (метод взвешенного попарного арифметического среднего - weighted pair-group method using arithmetic averages, WPGM A (Sneath, Sokal, 1973)). Этот метод похож на метод невзвешенного попарного среднего, разница состоит лишь в том, что здесь в качестве весового коэффициента используется размер кластера (число объектов, содержащихся в кластере). Этот метод рекомендуется использовать именно при наличии предположения о кластерах разных размеров. Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average (Sneath and Sokal, 1973)). В качестве расстояния между двумя кластерами в этом методе берется расстояние между их центрами тяжести.
Взвешенный центроидный метод Mетод взвешенного попарного центроидного усреднения -weighted pair-group method using the centroid average, WPGMC (Sneath, Sokal 1973)). Этот метод похож на предыдущий, разница состоит в том, что для учета разницы между размерами кластеров (числе объектов в них), используются веса. Этот метод предпочтительно использовать в случаях, если имеются предположения относительно существенных отличий в размерах кластеров.
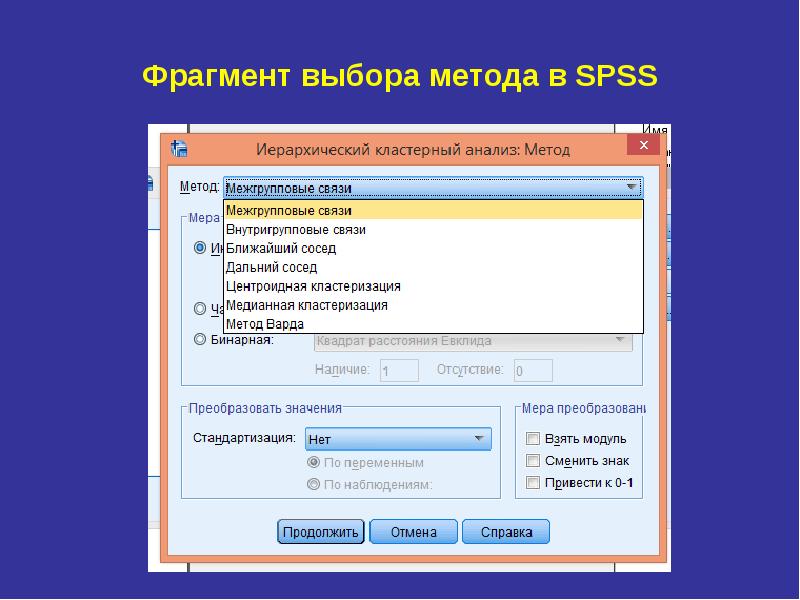
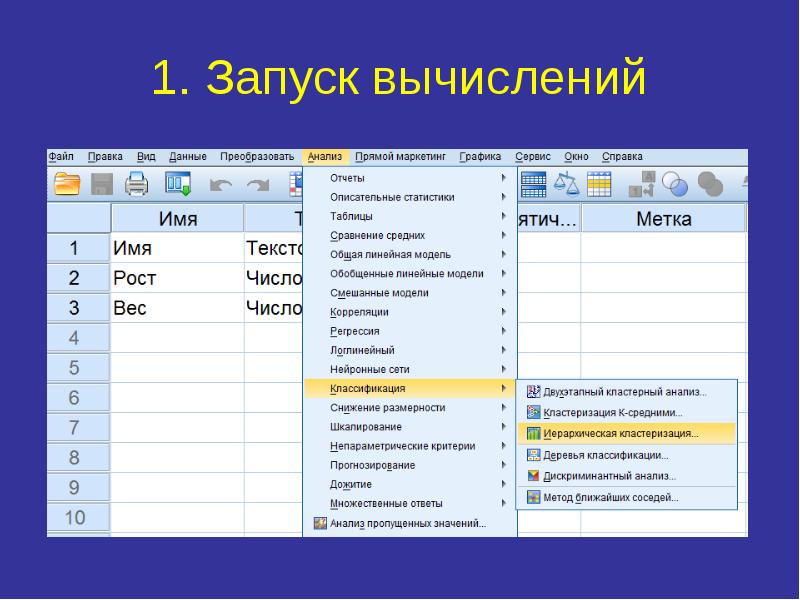
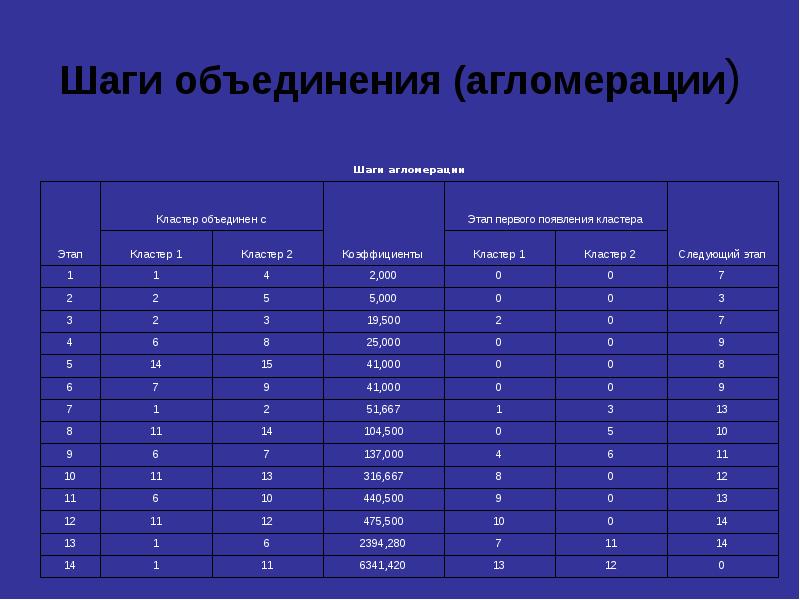
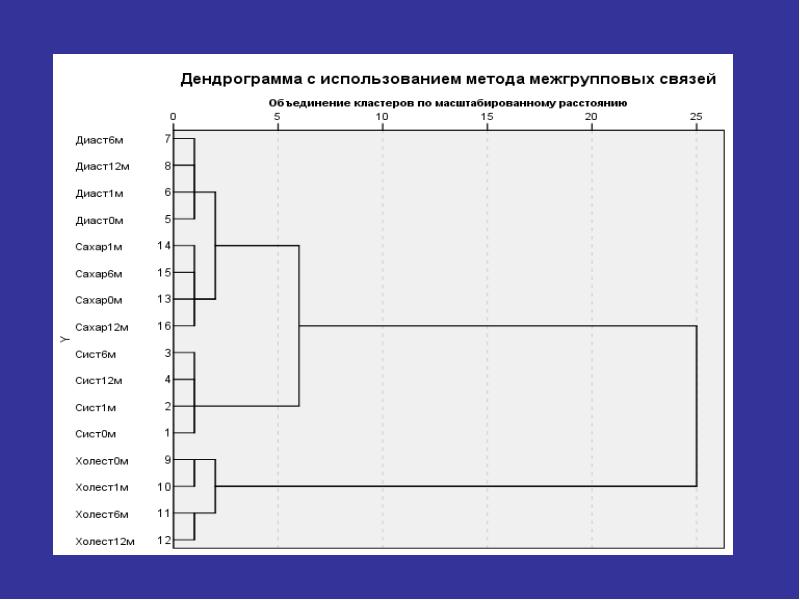
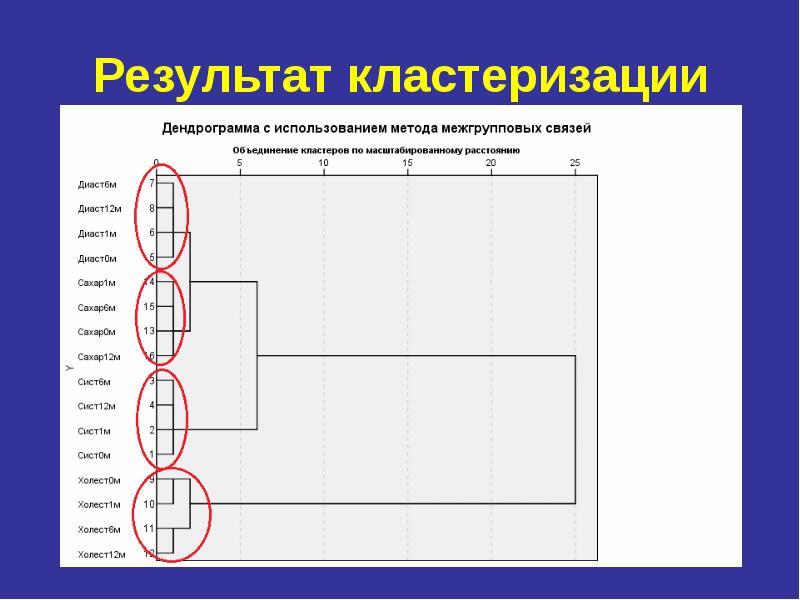
Иерархический кластерный анализ в SPSS Рассмотрим процедуру иерархического кластерного анализа в пакете SPSS (SPSS). Процедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), так и переменных (столбцов). Можно считать, что в последнем случае роль объектов играют переменные, а роль переменных - столбцы. В этом методе реализуется иерархический агломеративный алгоритм, смысл которого заключается в следующем. Перед началом кластеризации все объекты считаются отдельными кластерами, в ходе алгоритма они объединяются. Вначале выбирается пара ближайших кластеров, которые объединяются в один кластер.
В результате количество кластеров становится равным N-1. Процедура повторяется, пока все классы не объединятся. На любом этапе объединение можно прервать, получив нужное число кластеров. Таким образом, результат работы алгоритма агрегирования зависит от способов вычисления расстояния между объектами и определения близости между кластерами. Для определения расстояния между парой кластеров могут быть сформулированы различные подходы. С учетом этого в SPSS предусмотрены следующие методы: В результате количество кластеров становится равным N-1. Процедура повторяется, пока все классы не объединятся. На любом этапе объединение можно прервать, получив нужное число кластеров. Таким образом, результат работы алгоритма агрегирования зависит от способов вычисления расстояния между объектами и определения близости между кластерами. Для определения расстояния между парой кластеров могут быть сформулированы различные подходы. С учетом этого в SPSS предусмотрены следующие методы:
Определение количества кластеров Определение количества кластеров Существует проблема определения числа кластеров. Иногда можно априорно определить это число. Однако в большинстве случаев число кластеров определяется в процессе агломерации/разделения множества объектов. Процессу группировки объектов в иерархическом кластерном анализе соответствует постепенное возрастание коэффициента, называемого критерием Е. Скачкообразное увеличение значения критерия Е можно определить как характеристику числа кластеров, которые действительно существуют в исследуемом наборе данных. Таким образом, этот способ сводится к определению скачкообразного увеличения некоторого коэффициента, который характеризует переход от сильно связанного к слабо связанному состоянию объектов.
Свидетельство и скидка на обучение каждому участнику
Зарегистрироваться 15–17 марта 2022 г.

Описание презентации по отдельным слайдам:
Кластерный анализ
Минск 2003

Литература
1.Факторный, дискриминантный и кластерный анализ: Пер. с англ. / Дж.-О.Ким, Ч.У.Мюллер, У.Р.Клекка и др.; Под ред. И.С.Енюкова. – М.: Финансы и статистика, 1989.
2. Бююль А., Цефель П. SPSS: искусство обработки информации. – СПб.: ДиаСофт, 2001.

Предназначение кластерного анализа
Построение эмпирической классификации
Кластерный анализ позволяет разбить выборку на группы схожих объектов, называемых кластерами. Члены одной группы (кластера) должны обладать схожими проявлениями переменных, а члены разных групп – различными.

Стратегия кластерного анализа
1. Выбор переменных и их предварительные преобразования
2. Определение меры сходства (подобия) между объектами
3. Выбор метода кластеризации
4. Определение числа кластеров и обоснование кластерного решения

Важнейшие семейства кластерных методов
1. Иерархические методы
1.1. Аггломеративные *
1.2. Дивизимные
2. Итеративные методы
2.1. Метод К средних *
2.2. Метод "восхождения на холм"
3. Факторные методы *
4. Нейросетевые методы
* Реализованы в SPSS

Пример: классификация людей по скорости реакции
на свет и звук

1. Выбор переменных
время реакции на свет
время реакции на звук
2. Выбор меры сходства
Евклидово расстояние

3. Выбор метода кластеризации
аггломеративный
метод одиночной связи
(метод "ближайшего соседа")






Методы объединения или связи
На первом шаге, когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Однако когда связываются вместе несколько объектов, возникает вопрос, как следует определить расстояния между кластерами?
Другими словами, необходимо правило объединения или связи для двух кластеров. Здесь имеются различные возможности.

Методы объединения кластеров
1. Метод одиночной связи
2. Метод полной связи
3. Метод средней связи
3.1. Невзвешенный
3.2. Взвешенный (внутригрупповой)
4. Центроидный метод
4.1. Невзвешенный
4.2. Взвешенный (медианый)
5. Метод Уорда

Меры подобия в SPSS
Евклидова дистанция. Наиболее простой и легко интерпретируемый путь. Следует помнить, что на расстояния могут сильно влиять различия между осями, по координатам которых вычисляются эти расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово расстояние (или квадрат евклидова расстояния), вычисляемое по координатам, сильно изменится, и, как следствие, результаты кластерного анализа могут сильно отличаться от предыдущих. При этом следует использовать z-стандартизацию.

Квадрат евклидова расстояния. Иногда стандартное евклидово расстояние возводят в квадрат, чтобы придать большие веса более отдаленным друг от друга объектам.
Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два объекта как "различные", если они различаются по какой-либо одной координате (т.е. каким-либо одним признаком).
Процент несогласия. Эта мера используется в тех случаях, когда данные являются категориальными.






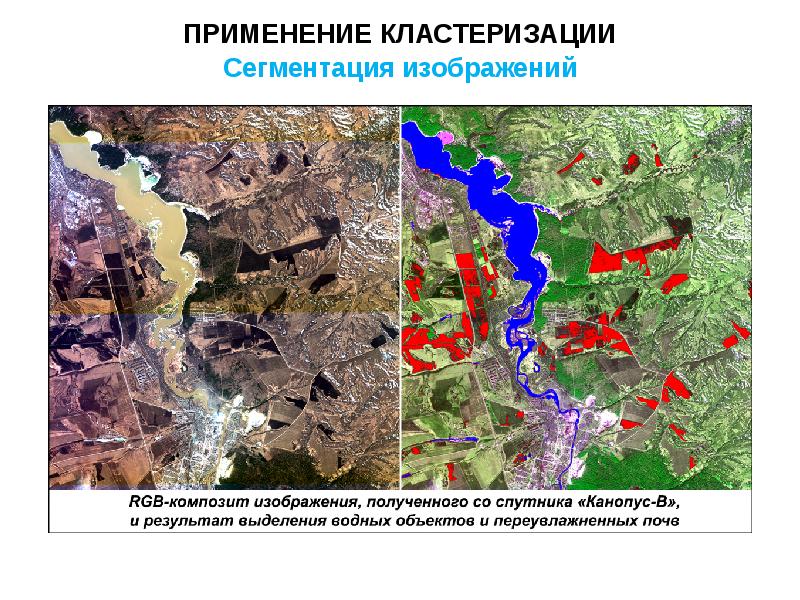






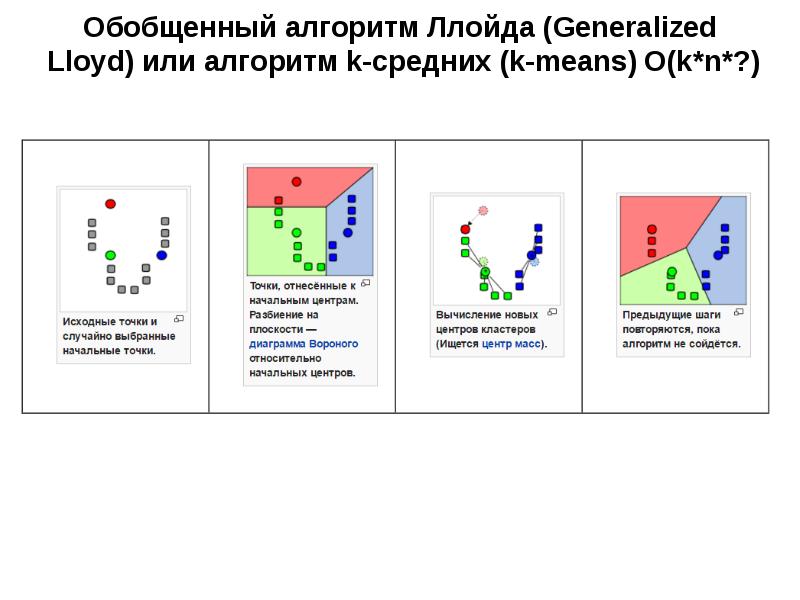

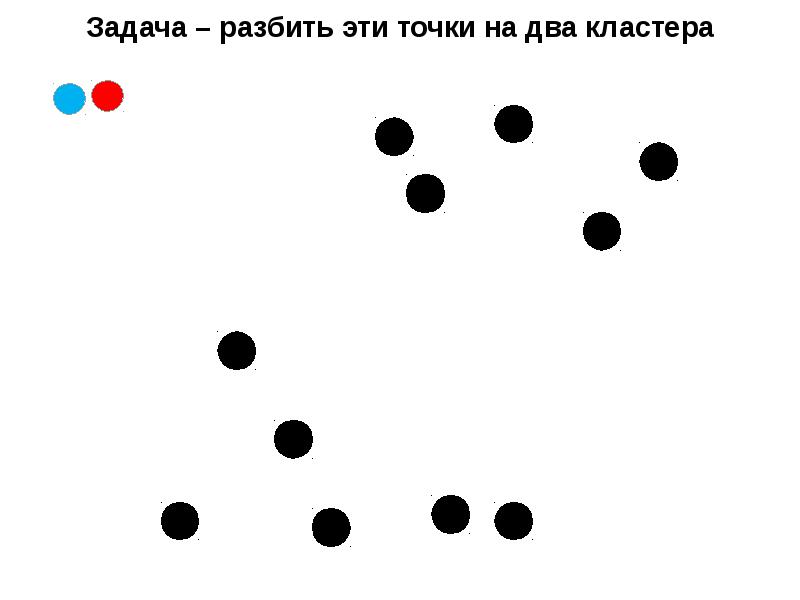

Слайд 1
Слайд 2
ПОНЯТИЕ КЛАСТЕРИЗАЦИИ Во многих прикладных задачах измерять степень сходства объектов существенно проще, чем формировать признаковые описания. Например, гораздо легче сравнить две фотографии и сказать, что они принадлежат одному человеку, чем понять, на основании каких признаков они схожи. Задача классификации объектов на основе их сходства друг с другом, когда принадлежность обучающих объектов каким-либо классам не задаётся, называется задачей кластеризации. Кластеризация – это процесс автоматического разбиения некоторого множества элементов на группы на основе степени их схожести (кластеры). Кластерный анализ (cluster analysis) — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Слайд 4
Слайд 5
Слайд 6
Слайд 7
Слайд 8
Слайд 9
Слайд 10
Слайд 12
ОБЩИЙ АЛГОРИТМ КЛАСТЕРИЗАЦИИ Выбор меры близости; Выбор алгоритма кластеризации; Представление полученных результатов;
Слайд 13
МЕРЫ БЛИЗОСТИ Коэффициент сходства (также мера сходства, индекс сходства) — безразмерный показатель, применяемый для количественного определения степени сходства объектов.
Слайд 14
Слайд 15
Слайд 16
Слайд 17
Слайд 18
Слайд 19
Слайды и текст этой презентации

Постановка задачи группировки данных
Задача состоит в том ,чтобы на основании данных , находящихся в множестве Х разбить их на m групп таким образом , чтобы
Такое разбиение должно отвечать некоторому критерию сходства, т.е. элементы из одного класса отвечают критерию сходства, а элементы из разных классов- нет.
Имеется некоторая целевая функция, которая определяет правило, по которому мы относим элементы к тому или иному классу. Предполагается, что каждый элемент относится строго к одному классу- это детерминированная постановка задачи.
Кластеризация может быть и нечетной. Может быть вероятностная постановка задачи кластеризации.
Существует задача разделения смесей, когда по совместной выборке необходимо оценить характеристики классов.
Мы будем рассматривать кластерный анализ в детерминированном смысле.
Задача классификации может решаться очень успешно, если вначале провести кластеризацию.

Задача кластеризации:
1)Изучение данных
2)Использование кластеров для более правильного решения задачи классификации.
На чем базируется задача кластеризации:
Результат кластеризации зависит от критерия, по которому будет проходить кластеризация. Большинство методов основано на понятии расстояния между объектами.
Сумма квадратов отклонения:
Внутригрупповые квадраты отклонения (критерий- это минимум внутригруппового отклонения)
w1=0
w2=0
w3=0
w=w1+w2+w3=0
Все метрические методы основаны функции расстояния между объектами.

При рассмотрении задачи кластеризации применяются различные функции расстояния.

Свойство расстояния Махланобиса:
заданы
это расстояние обладает свойством инвариантности по отношению к линейному преобразованию.
(Нужно доказать свойство инвариантности. Выписать формулы
и т.д.)
Если имеется m объектов, то можно определить матрицу расстояний между этими объектами для каждой пары xi и xj
Условно обозначим

Некоторые алгоритмы работают на основе таких матриц.
Мера сходства определяется следующим образом:
и обладают следующими свойствами:

Если то rij определяется немного не так.
Меру сходства очень просто построить из меры расстояния:
Фактически это обратная функция
Может быть мера сходства для бинарных объектов , которая определяется следующим образом:
-число совпадений единиц (если все совпадают, то Sij =1,если нет, то Sij =0)
nij -число совпадений нулей

Что такое расстояние между кластерами:
1) Расстояние на основе ближайшего соседа – это расстояние, которое определяется минимальным расстоянием между элементами рассматриваемых кластеров.

Расстояние по принципу дальнего соседа(т.е. рассматриваются наиболее удаленные точки между объектами)
Расстояние между центрами тяжести (или между математическими ожиданиями)
средний вектор.
Расстояние по принципу средней связи.

Критерии качества разбиения на классы
Критерий суммы квадратов ошибок: ni –элементов в Xi:
Мы можем ввести функцию разброса:
Здесь можно минимизировать только положение mi.
Этот критерий хорошо работает, когда предполагается, что кластеры хорошо разнесены.

Есть критерий, основанный на матрице рассеивания: матрица рассеивания определяется следующим образом:
Где Si -матрица рассеяния внутри группы, Sw – суммарная матрица рассеяния внутри группы.
Есть понятия расстояния между группами:
где -общее среднее, ST – общее рассеивание
На данной базе рассматривают следующие критерии:
Еще один критерий основан на минимизации определителя матрицы рассеивания (данный критерий эквивалентен линейным преобразованиям):

Основные типы кластерных процедур. Основные задачи кластерного анализа
Задачи могут быть классифицированы по объему выборки .
1) Малые выборки (10-100 объектов)
2) Большие выборки (100-1000 и больше объектов)
Задачи кластеризации с точки зрения априорной информации:
1) Число кластеров априорно задано
2)Число кластеров априорно не задано и их нужно определить
3)Число кластеров априорно не задано, но не требуется их точно определять в процессе обработки информации
Имеются следующие виды процедур:
1)Иерархические. Они отличаются большим объемом вычислений.
2)Параллельные процедуры. На каждом шагу анализируется вся выборка.
3)Процедуры последовательного типа: на каждом шагу анализируется один элемент выборки. Цель-минимизация некоторого функционала разбиения.

Все задачи сводятся к минимизации следующего функционала:
Пусть мы делаем все переборы
N-количество элементов
Пример: N=500 c=5, тогда полных переборов: М

Построение последовательной процедуры итеративной оптимизации
Пусть есть 2 кластера хi и хj
передвигаем эту выборку в xj (физически она остается на месте в пространстве, но относится уже к хj)
Критерий качества:

Теперь передвигаем из I->J. Что поменяется в этом случае?
Когда передвинули i->j , то

После преобразования результат получился следующим:
Нам надо , а это будет тогда, когда
Базовая процедура кластеризации (базовая минимальная квадратичная ошибка)
1) выбирается некоторое первоначальное разделение по группам .
x1,x2,…xc Пусть с известно.
Вычисляем I и средние m1,m2,…mc .
Цикл:
2) выбрать следующую выборку кандидата на передвижение
3) если Ni =1 , то перейти к следующему, иначе вычислить:
4) Передвинуть x в ХК ,если для всех I
5) Вновь вычислить I =

Следующий:
6) если I не изменилось после N попыток – остановка;
иначе перейти к Цикл
N- число выборок
Это типичная последовательная процедура.

Параллельная процедура. Базовые изоданные
Основан на классификации данных по принципу min d , можно задать любое расстояние, Евклидово, Махланобиуса и т.д.
Каждый группа описывается средним:
Отличия к группе определяются как:

Описание процедуры: Базовые изоданные
1. Выбираем некоторые начальные значения для средних
2. Классифицируем n-выборок, разбивая их на классы по ближайшим соседям
3. Вновь вычисляем среднее как среднее значение выборок в своем классе.
4. Если какое-либо среднее изменило значение, переходим в Цикл, иначе остановка
5. остановка.

Алгоритм К - внутригрупповых средних (это базовые и заданные)
Этот алгоритм минимизирует сумму квадратов расстояний всех точек, входящих в кластерную область, до центра кластера структура алгоритма состоит из к-шагов.
Шаг 1. Выбираем К исходных центров кластеров
Этот выбор производится произвольно и обычно в качестве исходных центров кластеров используем первые к- результатов выборки из заданного множества образов.
Шаг 2. На к-том шаге итерации заданное множество образов распределяется по к- кластерам по правилу мин расстояния:
для всех i=1,2… к: , Sj(k) - множество образов, входящих в кластер с центром zj(k)
В случае равенства решения принимается произвольным образом

Шаг 3. На основе результатов шага 2 принимаются новые центры кластеров
zj(k+1), j=1,2,…k. Исходя из условия, что сумма квадратов расстояний между всеми образами принадлежит множеству Sj(k) и новым центрам кластера д.б. минимально,
таким образом, новый центр кластера выбирается так, чтобы минимизировать показатель качества
центр zj(k+1), обеспечивающий минимизацию показателя качества, является, в сущности, выборочным средним, определенным по множеству Sj(k). Как
Nj- число выборочных образов, входящих в множество Sj(k)

Иерархические процедуры группировки
Здесь количество групп С не определено четко, оно меняется от N (число выборок) до 1.
Основаны на построении деревьев, описывающих взаимосвязи между кластерами.

Имеется N выборок. В начале полагается, что С=N
x1, x2, x3, … xN
* * * … *
Используем матрицу взаимных расстояний, т.к. каждый кластер состоит из 1-го элемента
Ищутся классы, ближайшие по данной ветке. Получаем следующее разбиение S(2), которой соответствует расстояние и так далее:
Но на каком-то этапе можем получить довольно устойчивую кластеризацию.

Базовую процедуру кластеризации можно сформулировать следующим образом:
С- количество кластеров
1) Пусть , N - количество элементов выборок
цикл:
2) Если , то остановка
- заданное количество кластеров, текущее количество кластеров
3) Найти ближайшую пару кластеров xi , xj
4) Объединяем xi и xj и уничтожаем хi . Положить -1
5) Переход к циклу.
Аналогично можно осуществлять эту процедуру и снизу.
Читайте также:
- Бог и дьявол бальмонт анализ стихотворения кратко
- Замолкни муза мести и печали анализ стихотворения кратко
- План суицидального поведения в школе 2019 2020 по профилактике
- Нужен ли детский сад если мама не работает
- Какие происшествия в жизни земли связаны с космическими стихиями 5 класс география кратко