
Какие требования должны соблюдать при профессиональном поиске информации в интернет кратко
Обновлено: 05.07.2024
Вряд ли среди интернет-пользователей найдутся люди, никогда не использовавшие крупные универсальные поисковые машины. Названия Google, Яндекс и пары-тройки других больших машин на слуху у всех. Они замечательно справляются с повседневными задачами интернет-поиска, и зачастую пользователи даже не пытаются искать им замену. В то же время количество поисковых интернет-машин в наше время исчисляется тысячами. Причины такого разнообразия альтернативных машин имеют различные корни. Одни проекты пытаются напрямую конкурировать с лидерами глобального рынка за счет тщательной работы с национальными интернет-ресурсами. Другие предлагают возможности составления запроса, отсутствующие у известных поисковиков. Значительное количество альтернативных машин специализируются на поиске по определенной тематической области или определенному типу контента, достигая в решении этих задач впечатляющих результатов. Как бы то ни было, включение таких поисковиков в собственный пользовательский арсенал средств интернет-поиска может заметно повысить его качество. Здесь, правда, существует один нюанс: надо знать о таких машинах и уметь пользоваться их возможностями.
Для того чтобы интернет-поиск был успешным, должны быть выполнены два условия: запросы должны быть хорошо сформулированы и задавать их нужно в подходящих местах. Другими словами, от пользователя требуется, с одной стороны, умение переводить свои поисковые интересы на язык поискового запроса, а с другой – хорошее знание поисковых систем, доступных инструментов поиска, их достоинств и недостатков, что позволит выбирать в каждом конкретном случае наиболее подходящие средства поиска.
В настоящее время не существует какого-либо одного ресурса, удовлетворяющего всем требованиям к интернет-поиску. Поэтому при серьезном подходе к поиску неизбежно приходится задействовать разные инструменты, используя каждый в наиболее подходящем случае.
Доступных средств поиска немало. Их можно объединить в несколько групп, каждая из которых обладает определенными достоинствами и недостатками. Главы нашей книги посвящены основным группам современных поисковых интернет-систем.
Прежде чем начинать рассказ о конкретных продуктах, имеет смысл разобраться с классификацией современных средств интернет-поиска, а также определиться с терминами, которые постоянно встречаются на страницах нашей книги.
Основные средства интернет-поиска можно разделить на следующие основные группы:
• локальные программы для поиска в интернете.
Наиболее популярным средством поиска являются поисковые машины – так называемые интернет-поисковики (Search Engines). Тройка лидеров в общемировом масштабе достаточно стабильна – это Google, Yahoo! и Bing. Во многих странах к этому перечню добавляются собственные локальные поисковики, оптимизированные для работы с местным контентом. С их помощью теоретически можно найти любое конкретное слово на страницах многих миллионов сайтов.
Несмотря на многие различия, все интернет-поисковики работают по схожим принципам и с технической точки зрения состоят из похожих подсистем.
Первая структурная часть поисковика – специальные программы, применяемые для автоматического поиска и последующего индексирования веб-страниц. Такие программы обычно называют пауками, или ботами. Они просматривают код веб-страниц, находят расположенные на них ссылки и тем самым обнаруживают новые веб-страницы. Есть и альтернативный способ включения сайта в индекс. Многие поисковики предлагают владельцам ресурсов возможность самостоятельно добавить сайт в свою базу. Как бы то ни было, затем веб-страницы скачиваются, анализируются и индексируются. В них выделяются структурные элементы, находятся ключевые слова, определяются их связи с остальными сайтами и веб-страницами. Производятся и другие операции, результатом выполнения которых становится формирование индексной базы поисковика. Эта база – второй главный элемент любого поисковика. Сейчас не существует какой-либо одной абсолютно полной индексной базы, которая содержала бы сведения обо всем контенте интернета. Поскольку разные поисковики используют разные программы поиска веб-страниц и строят свой индекс с помощью разных алгоритмов, индексные базы поисковиков могут существенно различаться. Некоторые сайты оказываются проиндексированными несколькими поисковиками, однако всегда остается определенный процент ресурсов, включенных в базу только какого-либо одного поисковика. Наличие у каждого поисковика такой оригинальной и непересекающейся части индекса позволяет сделать важное практическое заключение: если вы пользуетесь только одним поисковиком, пусть даже самым крупным, вы обязательно потеряете некоторый процент полезных ссылок.
Заметим, что формирование индексных баз – весьма ресурсоемкая задача. Многие поисковые проекты не утруждают себя сбором собственных баз, предпочитая использовать базы одного или нескольких сторонних поисковиков. Это позволяет сосредоточиться на разработке оригинальных пользовательских интерфейсов и дополнительных инструментов, иногда превосходящих по возможностям соответствующие средства владельцев баз. Следующая часть интернет-поисковика – собственно программы поиска и сортировки результатов. Эти программы решают две основные задачи: сначала находят в базе страницы и файлы, соответствующие поступившему запросу, а затем сортируют полученный массив данных в соответствии с различными критериями. От эффективности их работы во многом зависит успех в достижении целей поиска.
Последний элемент интернет-поисковика – пользовательский интерфейс. Кроме обычных для любых сайтов требований к эстетике и удобству, к интерфейсам поисковиков предъявляется еще одно важное требование: они должны предлагать различные инструменты составления и уточнения запросов, а также сортировки и фильтрации результатов. Преимущества поисковых машин – великолепный охват источников, сравнительно быстрое обновление содержимого базы и хороший выбор дополнительных функций. Главный инструмент работы с поисковиками – это запрос. Для успешного поиска неплохо изучить основные правила составления запросов, а также языки поисковых запросов конкретных поисковиков.
Для интернет-поиска используются также специальные приложения, устанавливаемые на локальном компьютере. Это могут быть как простые программы, так и довольно сложные комплексы поиска и анализа данных. Наиболее распространены поисковые плагины для браузеров, панели для браузеров, предназначенные для работы с каким-либо конкретным поисковым сервисом, и метапоисковые пакеты с возможностями анализа результатов.
Веб-каталоги – это ресурсы, в которых сайты распределяются по тематическим категориям. Если с поисковиками пользователь работает только посредством запросов, то в каталоге есть возможность просматривать тематические разделы целиком.
Второе принципиальное отличие каталогов от автоматических поисковиков – это то, что в их наполнении, как правило, непосредственно участвуют люди, которые просматривают ресурсы и относят сайт к той либо иной категории.
Веб-каталоги принято делить на универсальные и тематические. Универсальные стараются охватить максимум тем. В них можно найти все, что угодно: от сайтов о поэзии до компьютерных ресурсов. Другими словами, широта поиска у них максимальная. Тематические же каталоги специализируются на определенной тематике, обеспечивая за счет сокращения широты охвата ресурсов максимальную глубину поиска.
Второе дыхание веб-каталоги получили в эпоху Web 2.0. Над их пополнением на многочисленных социальных проектах трудятся сами посетители, а не специальная команда каталогизаторов. За счет привлечения труда многочисленных пользователей удается значительно расширить базы проектов. Такие ресурсы являются ценным источником информации и предлагают массу интересных дополнительных инструментов поиска.
Недостатки веб-каталогов известны. В первую очередь, это медленное пополнение базы, поскольку включение сайта в каталог предполагает участие человека. В отношении оперативности веб-каталог – не соперник поисковикам. Кроме того, веб-каталоги существенно уступают поисковикам по размерам баз. Соперничать с автоматическими системами в количестве охваченных ресурсов – задача для них безнадежная. Еще один недостаток современных каталогов – отсутствие единой классификации ресурсов и четких критериев отнесения их к той или иной категории. Иногда создается впечатление, что разработчики веб-каталогов намеренно игнорируют уже существующие классификационные языки поиска.
Говоря о интернет-поиске, нельзя обойти вниманием ряд терминов, которые тесно связаны с этой сферой и часто используются для описания и оценки поисковиков.
Достаточно часто можно встретить такие понятия, как глобальный и локальный интернет-поиск. При локальном интернет-поиске учитывается географическое местоположение пользователя и предпочтение отдается результатам, так или иначе связанным с конкретной страной или местностью. При глобальном поиске эта информация не учитывается, и поиск ведется во всех доступных ресурсах.
При составлении запроса на интернет-поисковиках действуют различные режимы поиска. К типовым режимам поиска, которые встречаются на большинстве интернет-машин, можно отнести простой и расширенный поиск. Простой поиск позволяет в одном запросе указать только один поисковый признак. Расширенный поиск дает возможность составить запрос из нескольких условий, связав их логическими операторами.
Для уточнения поисковых запросов используются различные фильтры. Фильтрами далее мы будем называть те или иные вспомогательные средства составления запроса, которые не относятся к содержательной стороне условий запроса, а ограничивают результаты поиска каким-либо формальным признаком. Так, например, применяя при поиске фильтр типа файла, пользователь не сообщает системе сведений, относящихся к теме своего запроса, а просто ограничивает полученные результаты определенным типом файлов, указанным в условии своего запроса.
Мы будем рады узнать ваше мнение!
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Введение
Введение Области применения трехмерного компьютерного моделирования необычайно широки. Кого-то интересует создание персонажей, кто-то мечтает построить виртуальный город, кто-то работает в игровой индустрии, а кто-то занимается наружной рекламой. Трехмерное
10.0. Введение
10.0. Введение Потоки (streams) являются одной из самых мощных (и сложных) компонент стандартной библиотеки С++. Их применение при простом, неформатированном вводе-выводе в целом не представляет трудностей, однако ситуация усложняется, если необходимо изменить формат с помощью
11.0. Введение
11.0. Введение Язык программирования C++ хорошо подходит для решения научных и математических задач из-за своей гибкости, выразительности и эффективности. Одно из самых больших преимуществ применения C++ для выполнения численных расчетов связано с тем, что он помогает
12.0. Введение
12.0. Введение В данной главе даются рецепты написания многопоточных программ на C++ с использованием библиотеки Boost Threads, автором которой является Вильям Кемпф (William Kempf). Boost — это набор переносимых, высокопроизводительных библиотек с открытым исходным кодом, неоднократно
13.0. Введение
13.0. Введение В данной главе приводятся решения некоторых задач, которые обычно возникают при интернационализации программ С++. Обеспечение возможности работы программы в различных регионах (это обычно называется локализацией), как правило, требует решения двух задач:
14.0. Введение
14.0. Введение Язык XML играет важную роль во многих областях, в том числе при хранении и поиске информации, в издательском деле и при передаче данных по сетям; в данной главе мы научимся работать с XML в С++. Поскольку эта книга больше посвящена С++, чем XML, я полагаю, вы уже имеете
15.0. Введение
15.0. Введение В этой главе рассматриваются некоторые аспекты C++, которые плохо вписываются в тематику любой другой главы: указатели функций и членов, константные переменные и функции- члены, независимые операторы (т.е. не члены класса) и несколько других
Введение
Введение По своей популярности пакет офисных приложений Microsoft Office может сравниться, пожалуй, лишь с операционной системой Windows. Его активно используют школьники и студенты, бухгалтеры и топ-менеджеры, ИТ-специалисты и писатели, руководители и офисные сотрудники. Сегодня
Введение
Введение В своей первой книге, "Delphi. Только практика", автор рассматривал примеры различных интересных программ. Эта книга является продолжением первой книги. Продолжением, поскольку исходные коды программ, которые рассматриваются в первой и второй книге, не повторяются.
Введение
Введение MySQL – это система управления базами данных (СУБД) с открытым кодом. Это высокопроизводительная и масштабируемая СУБД с множеством программных интерфейсов. Она обладает огромными функциональными возможностями и подходит для решения самых разных задач.Данная
Введение
Введение Я помню время, много лет тому назад, когда я предложил издательству Apress книгу, посвященную еще не выпущенному на тот момент пакету инструментальных средств разработки под названием Next Generation Windows Services (NGWS - сервисы Windows следующего поколения). Вы, наверное, знаете,
Введение
Введение Трудно представить себе компьютер, на котором не установлен Microsoft Office. Этот пакет включает программы, с помощью которых решаются многие повседневные задачи студентов, бухгалтеров, инженеров, менеджеров. Можно было бы перечислить еще огромное количество
Введение
Введение Вы уже знакомы с STL. Вы умеете создавать контейнеры, перебирать их содержимое, добавлять и удалять элементы, а также использовать общие алгоритмы — такие, как find и sort. Но вы никак не можете отделаться от впечатления, что используете лишь малую часть возможностей
Введение
Введение Это не совсем книга. Просто по ходу работы и изучения пакета у меня накопилось немало заметок, которые я в конце концов собрал воедино и опубликовал с оглавлением и под единым названием.Данные заметки относятся к версиям 4 и 5 пакета MySQL. По ходу текста особо
Введение
Введение Правильно организованное делопроизводство – залог удачного бизнеса, поэтому эффективности этой составляющей всегда уделялось большое внимание. С появлением компьютерных технологий в делопроизводстве произошла настоящая революция. Работать с документами
Введение
Введение Если вы никогда раньше не работали в Photoshop, но мечтаете научиться его использовать, считайте, что вам повезло – первый шаг к этому вы уже сделали, купив данную книгу. Если же вы все-таки боитесь того, что вам никогда не разобраться со всеми этими кнопками, панелями
За последние годы развития Интернет-технологий в мире и в России произошло немало положительных перемен. Формирование позитивного общественного мнения о роли Сети, расширение ее технических возможностей и географии подключения пользователей стимулировали стремительный рост информационной базы Интернета и, как следствие, становление новых и развитие старых поисковых сервисов. Тем не менее эти события явились лишь фоном, на котором произошел главный перелом — в сознании руководителей среднего и высшего звена как коммерческих организаций, так и государственных учреждений. Стало понятно, что своевременное получение информации из Сети способно приносить авторитет, деньги и стабильное положение ее потребителям. Автору этой статьи в течение нескольких лет приходилось читать и поддерживать на современном уровне курс по поиску информации в Интернете. Судьба предоставила ему уникальную возможность: немало учебного времени пришлось провести с десятками людей, для которых решение поисковых задач стало профессиональной деятельностью. Общение с ними, безусловно, обогатило личный опыт автора и в какой-то мере уполномочило говорить о самой проблеме от их имени.
Черты, присущие профессиональному поиску
- контроль полноты охвата ресурсов;
- контроль достоверности информации, полученной из Сети;
- высокая скорость проведения поиска.
Так, если вы выступаете в роли заказчика, то вправе потребовать от поисковика помимо собственно результатов еще и некоторых гарантий по указанным выше пунктам. Такие гарантии, безусловно, может дать лишь человек, неплохо осведомленный о тонкостях распределения и движения информационных потоков в Интернете.
Целью настоящей и последующих публикаций станет обсуждение тех возможностей, которыми располагает поисковик, чтобы добиться оптимальных показателей полноты, достоверности и скорости выполнения поисковых работ. Попробуем теперь более предметно обозначить существующие проблемы.
Контроль достоверности информации, полученной из Сети в результате поиска, разумеется, может производиться разными средствами. Кратко остановимся здесь на возможностях, которые предоставляет сама Сеть. Так, традиционными способами проверки являются локализация источников информации, альтернативных данному; сверка фактического материала, установление частоты его использования другими источниками; выяснение статуса документа и рейтинга узла, на котором он находится, средствами поисковых систем; получение информации о компетентности и статусе автора материала с помощью специальных поисковых сервисов; анализ отдельных элементов организации узла с целью оценки квалификации поддерживающих его специалистов и другие.
Скорость проведения поиска в Сети, если не принимать во внимание технические характеристики подключения пользователя, в основном зависит от двух факторов: грамотного планирования поисковой процедуры и навыков работы с ресурсом выбранного типа. Под составлением плана поисковых работ понимается выбор поисковых сервисов и инструментов, отвечающих специфике задачи и, что крайне важно, последовательности их применения в зависимости от ожидаемой результативности. После получения доступа к соответствующему ресурсу на передний край выдвигается умение быстро разобраться в его структуре и способах навигации. Моторика выполнения действий, умелое совмещение поисковых средств и возможностей обработки информации локальной клиентской программы и сервера являются необходимыми для поисковика навыками.
Материал данной статьи будет посвящен в основном вопросу полноты проводимого поиска.
Контроль полноты охвата ресурсов. Типы ресурсов Интернета
Большинство пользователей, пришедших в Интернет за последние пару лет, отождествляют его со Всемирной паутиной (www). И дело даже не в том, что им ничего не известно о существовании в мультипротокольной среде Сети других типов ресурсов. Как правило, эти сведения воспринимаются ими скорее как признак эрудиции, чем как практически полезная вещь. Действительно, информационный объем Web-пространства удовлетворяет многих пользователей. Однако как только поиск ставится на профессиональную основу и заставляет нести ответственность за выполненную работу, контроль за полнотой охвата ресурсов выдвигается на передний план. Можете ли вы гарантировать, что эксперт, выполнивший поисковые работы после вас, не обнаружит в Сети ничего реально значимого по заданному вопросу, что уже находилось там на момент ваших действий? Автору известен случай, когда сведения, в нужный момент найденные в группах новостей телеконференций, до какой-то степени изменили судьбу целой компании, на порядок увеличив доход от планировавшейся накануне сделки.
Так или иначе, сегодня информация в Интернете оказывается доступной из источников разного типа. Планировать поиск без полного представления об их спектре и особенностях функционирования невозможно. Перечень основных типов ресурсов, который можно использовать как карту при планировании поисковой процедуры, приведен на рис. 1. Фактически вопрос ставится более широко — об основных способах представления, передачи и обработки информации в Сети.
Особенности доступа к ресурсам указанного типа обсуждаются во многих руководствах. Полезный материал на этот счет содержится также в КомпьютерПресс №2’99. Ограничимся здесь краткой характеристикой каждого типа, акцентируя внимание на той нагрузке, которую может нести на себе ресурс при проведении поиска в Сети.
Электронная почта и почтовые роботы. Адрес электронной почты отдельного лица или организации традиционно используется для идентификации владельца. В коммуникационных ресурсах Сети — онлайновых средствах коммуникации пользователей и системе телеконференций — он нередко оказывается необходимым атрибутом каждого участника. Специальная URL-схема mailto позволяет вставлять в Web-страницу гиперссылку на Е-mail, автоматически открывающую почтового клиента. В этом виде она широко применяется в Паутине. Сами адреса при этом свободно индексируются поисковыми системами и доступны для поиска через поисковые машины общего назначения. AltaVista, например, показывает, что адреса электронной почты встречаются почти на 100 миллионах Web-страниц из 150 миллионов проиндексированных ею документов.
Адреса Е-mail активно накапливаются и в специальных системах поиска людей и организаций, о которых пойдет речь ниже. Серьезное неудобство для поиска по E-mail составляет то, что при получении адреса допускается регистрация пользователя под псевдонимом. Эта практика особенно широко распространена на серверах, предоставляющих бесплатные почтовые ящики.
Глобальная система телеконференций Usenet, региональные и специализированные телеконференции. Система построена по принципу электронных досок объявлений, когда пользователь может разместить свою информацию в одной из тематических групп новостей. Затем эта информация передается пользователям, которые подписаны на данную группу. Полное число групп новостей Usenet превышает 20 тысяч, и сведения о них можно найти, например, на Yahoo. Все они одновременно не поддерживаются ни одним сервером, так что труднее бывает отыскать не название соответствующей группы, а сервер телеконференций, с которого ее можно загрузить. Usenet — ключевое слово именно для глобальной системы телеконференций. Региональные и специализированные системы также имеют распространение. Ресурс наиболее значим для быстрого накопления информации по узкому вопросу, а при поиске — чаще для получения частной, неофициальной информации.
Еще несколько слов о чат-серверах. Как правило, некоторый их перечень уже зашит в используемую клиентскую программу, как, например, в программе Microsoft NetMeeting.
В регистрационных списках чатов обычно присутствуют сведения о месте проживания участников, и они редко указываются неверно. Автора этой статьи чат-ресурсы даже в своем анонимном варианте не раз привлекали тем, что позволяли получить информацию из первых рук от представителей конкретного государства, региона и города планеты.
FTP-архивы — это в первую очередь источники программного обеспечения, успешно конкурирующие с Web-узлами, которые специализируются на продаже и представлении коллекций программ. В отличие от Web-узлов на них гораздо чаще можно столкнуться с нарушением авторских прав в виде пиратских копий программ и отдельных материалов, продаваемых на других узлах за деньги. Как следствие теневых сторон FTP-сервиса — опасность заражения вирусом из непроверенного источника. Поиски какой же информации стоит начинать с поисковой системы FTP? Универсальный ответ прост: поскольку ключевым словом при оформлении запроса является текст, входящий в название файла или каталога на FTP-сервере, то наибольшего успеха можно добиться при поиске информации, которая, будучи оформлена в виде файла, либо уже имеет определенное кем-либо имя, либо существует реальная возможность его угадать. Известных автору случаев делового применения FTP-поиска немало. Один из них следующий. Поисковик, разыскивающий один из американских стандартов ASTM по материаловедению, с помощью поисковой системы HotBot быстро локализовал головной Web-сервер. Там ему удалось выяснить точное название стандарта. Полное описание стандарта предоставлялось за плату, а краткая аннотация — бесплатно. По техническим причинам аннотация на сервере была недоступна. Человек принял решение исследовать FTP-архивы с помощью поисковой системы и использовать алфавитно-цифровую последовательность, кодирующую название материала. Вскоре была найдена версия стандарта, близкая к полной, что исчерпало проблему. Достоверность информации вызвала у поисковика некоторые сомнения, однако была легко установлена специалистами.
Каталоги ресурсов — глобальные, локальные, специализированные (в среде WWW) — представляют собой размещаемые в Сети базы данных с адресами ресурсов и самым разным масштабом накопленной информации и охватом тематики. Обычно они имеют иерархическую структуру, перемещаясь по которой можно локализовать нужный объект. Скорость накопления информации такими системами оказывается сравнительно низкой, поскольку в классификации ресурсов предполагается непосредственное участие человека. Для поисковика получение информации о ресурсе из известного каталога всегда является некоторой гарантией достоверности. При решении более или менее стандартной поисковой задачи именно каталог, а не поисковая машина, оказывается стартовой площадкой для начала поиска.
Баннерные системы (в среде WWW) предполагают различные варианты размещения специальных объектов — баннеров, обычно небольших графических изображений с рекламной целью на Web-узле, принимающем рекламу. Баннеры отсылают пользователя по гиперссылке на сервер рекламодателя и зачастую могут не иметь вообще никакого отношения к основному содержимому страницы. Баннеры не используются напрямую при проведении поиска, но являются неплохими индикаторами состояния информационного рынка Сети.
Активные информационные каналы (в среде WWW) представляют собой специализированные Web-серверы, предназначенные для поступления данных прямо на рабочее место пользователя. Ресурсы этого типа принято связывать с push-технологией (технология проталкивания информации). Фактически активный Web-канал является информационным источником периодически обновляемых данных. Можно как подписаться на канал, так и остановить подписку, что многим напоминает работу со списками рассылки. Методика поддержки каналов основными на сегодняшний день браузерами Netscape Communicator и Internet Explorer оказывается различной. С информацией каналов после ее обновления можно позднее ознакомиться в автономном режиме. Сама технология не получила ожидаемого широкого распространения и в контексте проблемы поиска не играет заметной роли.
Ресурсы Интернета через призму поисковых сервисов
Среди пользователей Интернета легко выделить две категории. С одной стороны — это разработчики ресурсов в самом широком смысле этого слова: от технического персонала до авторов-журналистов, поставляющих информацию в Сеть. С другой стороны — активные потребители информационного потока. Деятельность по поиску информации становится неотъемлемой надстройкой потребительской сферы.
Стремление разработчиков осмыслить интересы потребителя выглядит более чем естественно. Однако эффективные подходы к решению поисковых задач кроются как раз в обратном проникновении — детальном осмыслении поисковиком интересов, намерений и технических решений, культивируемых разработчиком. В этом смысле при рассмотрении основных типов ресурсов Сети мы стремились упомянуть и те, которые пока привлекательны в большей степени для поставщиков информации. Роль некоторых из них для задач поиска на первый взгляд не кажется существенной, но такое положение может измениться.
История развития Интернет-технологий показывает, что состояние поисковых сервисов, обслуживающих информационный ресурс определенного типа, напрямую связано с фазой его жизненного цикла (см. рис. 3).
Кратко поясним основные элементы схемы жизненного цикла. Каталогизация как оформление и укрупнение коллекций ссылок на ресурсы данного типа следует немедленно за становлением ресурса. Сервис автоматического индексирования начинает обычно формироваться лишь в случае достижения информационной массой ресурса некоторого критического объема. После этого наступает фаза конкуренции идентичных поисковых сервисов — каталогов и индексов, обслуживающих ресурс. Канонизация фактически приостанавливает этот процесс, отдавая пальму первенства одному или нескольким поисковым системам. Заключительная стадия — угасание ресурса — характеризуется активной утечкой информационной массы в поле функционирования ресурсов другого типа вплоть до полного исчезновения.
Этой статьей мы начинаем небольшую серию публикаций, связанных с вопросом поиска информации в Интернете. Интерес к нему не ослабевает на протяжении всего времени существования Сети. Однако наш угол зрения на проблему будет несколько нетрадиционным - речь пойдет о профессиональном поиске. Хотелось бы избежать пафосного звучания слова "профессиональный". Оно лишь подчеркивает тот факт, что люди, для которых поиск информации стал частью служебных обязанностей, сталкиваются с проблемами, не свойственными эпизодическому, "любительскому" поиску. Их естественным желанием становится преодолеть эти проблемы и выработать новые результативные подходы к решению поисковых задач.
За последние годы развития Интернет-технологий в мире и в России произошло немало положительных перемен. Формирование позитивного общественного мнения о полезности Сети, расширение ее технических возможностей и географии подключения пользователей стимулировали стремительный рост информационной базы Интернета и, как следствие, становление новых и развитие старых поисковых сервисов. Тем не менее эти события явились лишь фоном, на котором произошел главный перелом - в сознании руководителей среднего и высшего звена как коммерческих организаций, так и государственных учреждений. Стало понятно, что своевременное получение информации из Сети способно приносить авторитет, деньги и стабильность положения ее потребителям. Автору этой статьи, которому в течение нескольких лет приходилось читать и поддерживать на современном уровне курс по поиску информации в Интернете, судьба предоставила уникальную возможность. Немало учебного времени ему пришлось провести с десятками людей, для которых решение поисковых задач стало профессиональной деятельностью. Общение с ними, безусловно, обогатило личный опыт автора, и до какой-то степени уполномочило говорить о самой проблеме от их имени.
Черты, присущие профессиональному поиску
- контроль полноты охвата ресурсов;
- контроль достоверности информации, полученной из Сети;
- высокая скорость проведения поиска;
Так, если вы выступаете в роли заказчика, то вправе потребовать от поисковика помимо собственно результатов, еще и некоторых гарантий по указанным выше пунктам. Такие гарантии, безусловно, может дать лишь человек, неплохо осведомленный о тонкостях распределения и движения информационных потоков в Интернете.
Целью настоящей и ближайших публикаций станет обсуждение тех возможностей, которыми располагает поисковик, чтобы добиться оптимальных показателей по полноте, достоверности и скорости выполнения поисковых работ. Попробуем теперь более предметно обозначить существующие проблемы
Контроль полноты охвата ресурсов является закономерным требованием, если вы решаете задачу, противоположную той, что звучит как "найти хоть что-нибудь".
Полномасштабный сбор информации из Интернета по какому-либо вопросу во многих случаях выводит поисковика за пределы широко освоенного Web-пространства, в лоно telnet-доступных баз данных, региональных телеконференций и других хранилищ информации. Знание всех основных существующих на сегодняшний день типов ресурсов Сети, понимание технической и тематической специфики их информационного наполнения и особенностей доступа становится необходимым условием успешного планирования и проведения поисковых работ.
Контроль достоверности информации, полученной из Сети в результате поиска, разумеется, может производиться разными средствами. Кратко остановимся здесь на возможностях, которые предоставляет сама Сеть. Так, традиционными способами проверки являются локализация источников информации, альтернативных данному; сверка фактического материала, установление частоты его использования другими источниками; выяснение статуса документа и рейтинга узла, на котором он находится средствами поисковых систем; получение информации о компетентности и статусе автора материала с помощью специальных поисковых сервисов; анализ отдельных элементов организации узла с целью оценки квалификации специалистов, его поддерживающих и другие.
Скорость проведения поиска в Сети, если не принимать во внимание технические характеристики подключения пользователя, зависит в основном от двух факторов. Это грамотное планирование поисковой процедуры и навыки работы с ресурсом выбранного типа. Под составлением плана поисковых работ понимается выбор поисковых сервисов и инструментов, отвечающих специфике задачи и, что крайне важно, последовательности их применения в зависимости от ожидаемой результативности. После получения доступа к соответствующему ресурсу на передний край выдвигается умение быстро разобраться в его структуре и способах навигации. Моторика выполнения действий, умелое совмещение поисковых средств и возможностей обработки информации локальной клиентской программы и сервера для поисковика являются необходимыми навыками.
Материал этой статьи будет посвящен в основном вопросу полноты проводимого поиска.
Контроль полноты охвата ресурсов. Типы ресурсов Интернет.
Так или иначе, сегодня информация в Интернете оказывается доступной из источников разного типа. Планировать поиск без полного представления об их спектре и особенностях функционирования невозможно. Перечень основных типов ресурсов, который можно использовать как карту при планировании поисковой процедуры, приведен на рис.1. Фактически вопрос ставится более широко - об основных способах представления, передачи и обработки информации в Сети.
- электронная почта и почтовые роботы;
- глобальная система телеконференций Usenet, региональные и специализированные телеконференции;
- списки рассылки;
- он-лайновые средства коммуникации пользователей;
- системы поиска людей и организаций;
- базы данных Hytelnet;
- система файловых архивов FTP, системы поиска в FTP-архивах глобального и регионального охвата;
- базы данных Gopher и поисковая система Veronica;
- гипертекстовая информационная система World Wide Web (WWW);
- каталоги ресурсов - глобальные, локальные, специализированные (в среде WWW);
- поисковые машины, или автоматические индексы - глобальные, локальные, специализированные (в среде WWW);
- баннерные системы (в среде WWW);
- активные информационные каналы (в среде WWW);
Рис.1. Основные информационные и коммуникационные ресурсы Интернета
Особенности доступа к ресурсам указанного типа обсуждаются во многих руководствах. Полезный материал на этот счет содержится также во втором номере журнала КомпьютерПресс за этот год. Ограничимся здесь краткой характеристикой каждого типа, акцентируя внимание на той нагрузке, которую может нести на себе ресурс при проведении поиска в Сети.
Электронная почта и почтовые роботы. Адрес электронной почты отдельного лица или организации традиционно используются для идентификации владельца. В коммуникационных ресурсах Сети - он-лайновых средствах коммуникации пользователей и системе телеконференций нередко он оказывается необходимым атрибутом каждого участника. Специальная URL-схема mailto позволяет вставлять в Web-страницу гиперссылку на е-mail, автоматически открывающую почтового клиента. В этом виде она широко применяется в Паутине. Сами адреса при этом свободно индексируются поисковыми системами и доступны для поиска через поисковые машины общего назначения. AltaVista, например, показывает, что адреса электронной почты встречаются почти на 100 миллионах Web-страниц из 150 миллионов заиндексированных ей документов.
Адреса е-mail активно накапливаются и в специальных системах поиска людей и организаций, о которых пойдет речь ниже. Серьезное неудобство для поиска по e-mail составляет то, что при получении адреса допускается регистрации пользователя под псевдонимом. Эта практика особенно широко распространена на серверах, предоствляющих бесплатные почтовые ящики.
Глобальная система телеконференций Usenet, региональные и специализированные телеконференции. Система построена по принципу электронных досок объявлений, когда пользователь может разместить свою информацию в одной из тематических групп новостей. Затем эта информация передается пользователям, которые подписаны на данную группу. Полное число групп новостей Usenet превышает 20 тысяч и сведения о них можно найти, например, на Yahoo. Все они одновременно не поддерживаются ни одним сервером, так что труднее бывает отыскать не название соответствующей группы, а сервер телеконференций, с которого ее можно загрузить. Usenet - ключевое слово именно для глобальной системы телеконференций. Региональные и специализированные системы также имеют распространение. Ресурс наиболее значим для быстрого накопления информации по узкому вопросу, а при поиске - чаще для получения частной, неофициальной информации.
Еще один поисковик столкнулся с проблемами, возникшими у офис-менеджера при конвертировании документов в текстовом процессоре Microsoft Word97. Автор посоветовал ему обратиться на сервер телеконференций msnews.microsoft.com компании Microsoft и задать при организации подписки поиск русскоязычной группы новостей по ключевому слову "word"в ее названии. Ответ на все вопросы был получен в течение двух дней.
Еще несколько слов о чат-серверах. Как правило, некоторый их перечень уже зашит в используемую клиентскую программу, как, например, в программе Microsoft NetMeeting.
В регистрационных списках чатов обычно присутсвуют сведения о месте проживания участников, и они редко указываются неверно. Автора этой статьи чат-ресурсы даже в своем анонимном варианте не раз привлекали тем, что позволяли получить информацию из первых рук от представителей конкретного государства, региона и города планеты.
Рис.2. Пример интерфейса, доступной по протоколу telnet базы данных библиотеки Glasgow University (UK).
Ftp-архивы - это в первую очередь источники программного обеспечения, успешно конкурирующие с Web-узлами, которые специализируются на продаже и представлении коллекций программ. В отличие от Web-узлов на них гораздо чаще можно столкнуться с нарушением авторских прав в виде пиратских копий программ и отдельных материалов, продаваемых на других узлах за деньги. Как следствие теневых сторон ftp-сервиса- опасность заражения вирусом из непроверенного источника. Поиски какой же информации стоит начинать с поисковой системы ftp? Универсальный ответ прост: поскольку ключевым словом при оформлении запроса является текст, входящий в название файла или каталога на ftp-сервере, то наибольшего успеха можно добиться в поиске информации, которая, будучи оформлена в виде файла, либо уже имеет определенное кем-либо имя, либо существует реальная возможность его угадать. Известных автору случаев делового применения ftp-поиска немало. Один из них следующий. Поисковик , разыскивающий один из американских стандартов ASTM по материаловедению с помощью поисковой системы HotBot быстро локализовал головной Web-сервер. Там ему удалось выяснить точное название стандарта. Полное описание стандарта предоставлялось за плату, а краткая аннотация - бесплатно. По техническим причинам аннотация на сервере была не доступна. Человек принял решение исследовать ftp-архивы с помощью поисковой системы и использовать алфавитно-цифровую последовательность, кодирующую название материала. Вскоре была найдена версия стандарта, близкая к полной, что исчерпало проблему. Достоверность информации вызывала у поисковика некоторые сомнения, однако была легко установлена специалистами.
Каталоги ресурсов - глобальные, локальные, специализированные (в среде WWW ); представляют собой размещаемые в Сети базы данных с адресами ресурсов и самым разным масштабом накопленной информации и охватом тематики. Обычно они имеют иерархическую структуру, перемещаясь по которой, можно локализовать нужный объект. Скорость накопления информации такими системами оказывается сравнительно низкой, поскольку в классификации ресурсов предполагается непосредственное участие человека. Для поисковика получение информации о ресурсе из известного каталога всегда является некоторой гарантией достоверности. При решении более или менее стандартной поисковой задачи именно каталог, а не поисковая машина оказываются стартовой площадкой для начала поиска.
Поисковые машины, или автоматические индексы - глобальные, локальные, специализированные (в среде WWW ) представляют собой мощные информационно-поисковые системы, размещаемые на серверах свободного доступа. Их специальные программы-роботы, или пауки, в автоматическом режиме непрерывно сканируют информацию Сети на основе заданных алгоритмов, проводя индексацию документов. В последующем на основе созданных индексных баз данных поисковые машины предоставляют пользователю доступ к распределенной на узлах Сети информации. Это реализуется через выполнение поисковых запросов в рамках соответсвующего интерфейса. Последние исследования возможностей поисковых машин, даже самых мощных из них, таких как AltaVista, или HotBot, показывают, что реальная полнота охвата ресурсов Всемирной Паутины отдельной такой системой не превышает 30%. Планирование поисковой процедуры в пространстве WWW является нетривиальным, и его,безусловно, следует рассмотреть отдельно.
Баннерные системы (в среде WWW ) предполагают различные варианты размещения специальных объектов - баннеров, обычно небольших графических изображений с рекламной целью на Web-узле , принимающем рекламу. Баннеры отсылают пользователя по гиперссылке на сервер рекламодателя и зачастую могут не иметь вообще никакого отношения к основному содержимому страницы. Баннеры не используются напрямую при проведении поиска, но являются неплохими индикаторами состояния информационного рынка Сети.
Активные информационные каналы (в среде WWW ) представляют собой специализированные Web-сервера, предназначенные для поступления данных прямо на рабочее место пользователя. Ресурсы этого типа принято связывать с push-технологией (технология проталкивания информации). Фактически активный Web-канал является информационным источником периодически обновляемых данных. Можно как подписаться на канал, так и остановить подписку, что многим напоминает работу со списками рассылки. Методика поддержки каналов основными на сегодняшний день браузерами Netscape Communicator и Internet Explorer оказывается различной. С информацией каналов после ее обновления можно позднее ознакомиться в автономном режиме. Сама технология не получила ожидаемого широкого распространения и в контексте проблемы поиска не играет заметной роли.
Ресурсы Интернета через призму поисковых сервисов.
Среди пользователей Интернета легко очертить две категории. С одной стороны - это разработчики ресурсов в самом широком смысле этого слова от технического персонала до авторов-журналистов, поставляющих информацию в Сеть. С другой стороны - активные потребители информационного потока. Деятельность по поиску информации становится неотъемлемой надстройкой потребительской сферы.
Стремление разработчиков осмыслить интересы потребителя выглядит более чем естественно. Однако эффективные подходы к решению поисковых задач кроются как раз в обратном проникновении - детальном осмыслении поисковиком интересов, намерений и технических решений, культивируемых разработчиком. В этом смысле при рассмотрении основных типов ресурсов Сети мы стремились упомянуть и те, которые пока привлекательны в большей степени для поставщиков информации. Роль некоторых из них для задач поиска не кажется, на первый взгляд, существенной, но такое положение может измениться.
История развития Интернет-технологий показывает, что состояние поисковых сервисов, обслуживающих информационный ресурс определенного типа, напрямую связано с фазой его жизненного цикла (см. рис. 3).
Рис.3. Связь жизненного цикла информационного ресурса Сети с динамикой развития сопутствующих поисковых сервисов.
Кратко поясним основные элементы схемы жизненного цикла. Каталогизация как оформление и укрупнение коллекций ссылок на ресурсы данного типа следует немедленно за становлением ресурса. Сервис автоматического индексирования начинает обычно формироваться лишь в случае достижения информационной массой ресурса некоторого критического объема. После этого течет фаза конкуренции идентичных поисковых сервисов - каталогов и индексов, обслуживающих ресурс. Канонизация фактически приостанавливает этот процесс, отдавая пальму первенства одному или нескольким поисковым системам. Заключительная стадия - угасания ресурса - характеризуется активной утечкой информационной массы в поле функционирования ресурсов другого типа вплоть до полного исчезновения.

Пример шаблона Блога Категории (Категория - FAQ/Общие вопросы)
ПРОФЕССИОНАЛЬНЫЙ ПОИСК ИНФОРМАЦИИ В ИНТЕРНЕТ
Поиск информации является одной из наиболее распространенных и одновременно наиболее сложных задач, с которыми приходится сталкиваться в Сети любому пользователю. Однако если для рядового члена сетевого сообщества знание методов эффективного информационного поиска является желательным, но далеко не обязательным качеством, то для профессионалов информационной деятельности умение быстро ориентироваться в ресурсах Интернет и находить требуемые источники относится к числу базовых квалификационных навыков.
Причина сложностей, возникающих при информационном поиске в Интернет, определяется двумя главными факторами. Во-первых, число источников в Сети чрезвычайно велико. В конце 2001 года самые приблизительные подсчеты указывали ориентировочную цифру в 7,5 миллиардов документов, расположенных на серверах по всему миру. Во-вторых, массив информации в Сети не только колоссален по объему, но еще и крайне динамичен. За те полминуты, что вы потратили на чтение первых строк этого раздела, в виртуальной вселенной появилось порядка сотни новых или измененных документов, десятки были перемещены на новые адреса, а единицы - навсегда прекратили свое существование. Интернет никогда "не спит", как никогда "не спит" наша планета, по которой непрерывно катится волна деловой активности человечества в точном соответствии со сменой часовых поясов.
В отличии от стабильного и контролируемого фонда документов в библиотеке, в Сети мы имеем дело с гигантским и непрерывно меняющимся информационным массивом, поиск данных в котором является весьма и весьма сложным процессом. Ситуация зачастую очень напоминает известную задачу поиска иголки в стоге сена, и порой сведения, представляющие огромную ценность, остаются невостребованными единственно по причине трудности их разыскания.
Навыками информационных разысканий в той или иной степени обладают большинство пользователей глобальных компьютерных сетей. И дилетанты, и профессионалы зачастую пользуются одними и теми же инструментами. Однако результаты разысканий и затраченное на них время различаются в очень значительной степени.
Задача данного раздела состоит в детальном ознакомлении с инструментами и методами информационного поиска и выработке устойчивых навыков профессионального поиска в Сети всех видов данных: от текстов в любых форматах, до видео и анимации.
Не прекращающееся ни на секунду обновление информационного массива Интернет в сочетании с одновременным ростом объема данных крайне усложняет учет имеющихся документов. Никакие списки серверов, которыми наполнены печатные руководства по работе в Интернет, не могут дать действительно точных сведений. В лучшем случае они в состоянии лишь помочь сделать первые шаги: сверхбыстрая смена ситуации в киберпространстве приводит к тому, что подобные перечни устаревают уже в момент своего выхода в свет, а поддерживать их в актуальном состоянии становится принципиально невозможно из-за стремительного роста новых и новых узлов.
Необходимость и важность проблемы информационного поиска привела к образованию в самом Интернет целой отрасли, задача которой заключается именно в оказании помощи пользователю в его навигации в киберпространстве. Составляют эту отрасль специальные поисковые службы или сервисы. Условно их можно разделить на справочники (directories) и поисковые системы (search engines).
Эти разновидности внешне очень похожи, поскольку каждый справочник, как правило, обладает собственной поисковой системой, а каждая поисковая система - собственным справочником. Однако принципы их работы базируются на абсолютно разных подходах и технологиях. При этом каждая разновидность поисковых сервисов применяется для решения определенного типа задач. Правильным выбором инструмента во многом определяется стратегия поисковой деятельности и, в конечном итоге, результат разысканий.
- объем;
- оперативность отражения новых или изменившихся ресурсов;
- логичность и последовательность иерархической схемы классификации;
- перекрестность структуры.
Объемом справочника определяется степень его надежности или "информационная прочность". От этого зависит уровень доверия, который пользователи питают к конкретному каталогу. Так как материалы в Интернет появляются, изменяются, а порой и бесследно исчезают ежедневно, важно то, насколько оперативно появляются ссылки на новые сайты и исправляются или удаляются ссылки на устаревшие ресурсы. В некоторых системах существует специальный механизм, периодически проверяющий доступность сайта и исключающий его из перечня при долгом "отсутствии" в Сети. Логичностью (научностью) применяемой схемы классификации определяется степень простоты, с которой пользователи могут находить требуемые сведения. Система же перекрестных ссылок позволяет выявлять информацию, используя разные подходы (например, территориальный или отраслевой). В этом случае схема классификации должна автоматически выводить пользователя на искомый объект, какой бы путь поиска не был выбран.
Возможности составления запроса для этого вида поисковых средств особой роли не играют, так как сложные разыскания, требующие большой детализации запроса, с помощью каталогов не проводятся.
- ориентация в незнакомой отрасли знания;
- разыскание крупных объектов, каковыми являются, к примеру, серверы целых организаций или значительных проектов;
- получение готового перечня ресурсов, имеющих размытый поисковый образ, например, клиник пластической хирургии, библиотек определенного типа, транспортных расписаний или сайтов различных политических партий.
Следует помнить, что, обращаясь к справочникам, мы изначально можем рассчитывать на получение лишь очень общих сведений по тематике, и никогда - детальных данных. Понять это помогает простой пример, когда от сервера крупной корпорации, например, "Газпром", содержащего тысячи страниц, в справочнике будет представлено лишь название и несколько строк аннотации. Другим примером является сравнение справочника ресурсов Интернет с систематическим каталогом библиотеки, в котором от книги (в данном случае целого сайта) остается лишь описание и аннотация.
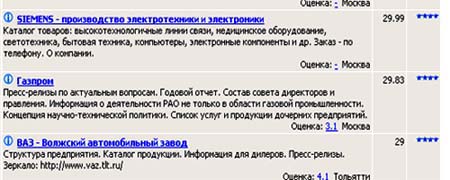
Описания ресурсов в одном из российских справочников
В основу работы поисковых систем (поисковых машин) заложены совершенно иные технологические принципы. Задача поисковых машин - обеспечивать детальное разыскание информации в электронной вселенной, что может быть достигнуто только за счет учета (индексирования) всего содержания максимально возможного числа web-страниц. В отличие от справочников, все они функционируют в автоматизированном режиме и имеют одинаковый принцип действия. Поисковые системы состоят из двух базовых компонентов. Первый компонент представляет собой программу-робот, задача которого путешествовать с сервера на сервер, находить там новые или изменившиеся документы и скачивать их на главный компьютер системы. При этом робот, просматривая содержимое документа, находит новые ссылки, как на другие документы данного сервера, так и на внешние сайты. Программа самостоятельно направляется по указанным ссылкам, находит новые документы и ссылки в них, после чего процесс повторяется вновь, напоминая хорошо известный в библиографии "метод снежного кома". Выявленные документы обрабатываются (индексируются) вторым компонентом поисковой системы. При этом, как правило, учитывается все содержание страницы, включая текст, иллюстрации, аудио- и видеофайлы и пр. Индексации подвергаются все слова в документе, что как раз и дает возможность использовать поисковые системы для детального поиска по самой узкой тематике. Образуемые гигантские индексные файлы, хранящие информацию о том, какое слово, сколько раз, в каком документе и на каком сервере употребляется, и составляют базу данных, к которой происходит обращение пользователей, вводящих в строку запроса сочетания ключевых слов.
Выдача результатов осуществляется с помощью специального модуля, который производит интеллектуальное ранжирование результатов. При этом берется в расчет местоположение термина в документе (название, заголовок, основной текст), частота его повторения, процентное соотношение искомого термина к остальному тексту страницы, а также число и авторитетность внешних ссылок на данную страницу с других сайтов.
- объем индексных файлов (число проиндексированных серверов и отдельных документов);
- степень оперативности обновления базы данных за счет включения сведений о новых материалах и удаления устаревших;
- возможности для составления запроса;
- интеллектуальность системы ранжирования результатов поиска;
- наличие дополнительных сервисных функций, облегчающих работу пользователя.
Первая величина, являющаяся ключевой, устанавливает широту охвата материала и определяется числом проиндексированных документов. Сейчас эта цифра для лидеров мирового сетевого поиска колеблется в пределах от 2 до 4 с лишним миллиардов.
Учитывая тот факт, что в среднем интернетовский адрес сохраняет актуальность до полугода, после чего документ или меняет местоположение или убирается с сервера, большое значение имеет уровень оперативности обновления данных, характеризующий степень соответствия индексного файла поисковой системы реальному местоположению документов на сайтах. В настоящее время этот параметр колеблется от двух недель до полутора месяцев.
Возможности поискового механизма выражать запрос максимально точно в значительной степени предопределяют долю релевантных документов в перечне полученных результатов. Каждая машина имеет свою собственную лексику, которая по-разному позволяет детализировать поисковое предписание.
Все поисковые машины обладают модулем ранжирования результатов поиска. Создание таких модулей - целая область программирования, в которой конкурируют сложнейшие алгоритмы, созданные разными компаниями. Перечень факторов, принимаемых во внимание при определении места документа в перечне ссылок, необычайно широк: от местоположения слова на странице до рейтинга (авторитета) страниц, имеющих ссылки на найденный документ.
Не последнюю роль играет и простота интерфейса, наличие дополнительных сервисных функций, как, например, возможность перевода текста документа на иностранный язык, способность выделять все документы с определенного сайта, сужение критериев в ходе поиска, нахождение документов "по образцу" и т.д.
Практически все всемирно известные справочники и поисковые системы в настоящее время превратились во внушительные информационные корпорации с многомиллионными доходами. Заработав авторитет наиболее посещаемых мест в Сети, они предоставляют свои страницы для размещения рекламной информации, доходы от которой и составляют основу их бюджета. Постепенно поисковые сервера превращаются в многофункциональные порталы, в которых поисковый сервис остается главной приманкой для пользователей, но далеко не единственной и даже не основной из предоставляемых услуг. Помимо разыскания информации, такие сервера обычно предоставляют пользователям бесплатную электронную почту, возможность бесплатно размещать собственные страницы, сведения о погоде, текущих новостях, биржевые котировки, карты местности и т.д.
Читайте также: