
Какие модели организации баз данных вы знаете кратко
Обновлено: 08.07.2024
1. Иерархический подход к организации баз данных.Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными – одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель.Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Во-первых, все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель – единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково – таблицами. Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элементмодели – реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления (полнота последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL.
Третий элементреляционной модели требует от реляционной модели поддержания некоторых ограничений целостности. Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор, называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель.Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты – текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных, не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. Несмотря на преимущества объектно-ориентированных систем – реализация сложных типов данных, связь с языками программирования и т.п. – на ближайшее время превосходство реляционных СУБД гарантировано.
1. Иерархический подход к организации баз данных.Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными – одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель.Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.

Во-первых, все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель – единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково – таблицами. Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элементмодели – реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления (полнота последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL.
Третий элементреляционной модели требует от реляционной модели поддержания некоторых ограничений целостности. Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор, называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель.Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты – текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных, не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. Несмотря на преимущества объектно-ориентированных систем – реализация сложных типов данных, связь с языками программирования и т.п. – на ближайшее время превосходство реляционных СУБД гарантировано.
Любые данные где-то хранятся. Будь это интернет вещей или пароли в *nix. Показываем схемы основных типов баз данных, чтобы наглядно представить различия между ними.

Типы баз данных, называемых также моделями БД или семействами БД, представляют собой шаблоны и структуры, используемые для организации данных в системе управления базами данных (СУБД). Выбор типа повлияет на то, какие операции сможет выполнять приложение, как будут представлены данные, на функции СУБД для разработки и рантайма.
Начнём с трёх типов БД, которые всё ещё могут встречаться в специализированных средах, но в основном заменены надежными и производительными альтернативами.
1. Простые структуры данных
Первый и простейший способ хранения данных – текстовые файлы. Метод применяется и сегодня для работы с небольшими объёмами информации. Для разделения полей используется специальный символ: запятая или точка с запятой в csv-файлах датасетов, двоеточие или пробел в *nix-подобных системах:
/etc/passwd в *nix системе
- ограничен тип и уровень сложности хранимой информации;
- трудно установить связи между компонентами данных;
- отсутствие функций параллелизма;
- практичны только для систем с небольшими требованиями к чтению и записи;
- используются для хранения конфигурационных данных;
- нет необходимости в стороннем программном обеспечении.
- /etc/passwd и /etc/fstab в *nix-системах
- csv-файлы
2. Иерархические базы данных

Пример построения иерархических связей
3. Сетевые базы данных
Сетевые базы данных расширяют функциональность иерархических: записи могут иметь более одного родителя. А значит, можно моделировать сложные отношения.

Пример связей в сетевой базе данных
- сетевые базы данных представляются не деревом, а общим графом
- ограничены теми же шаблонами доступа, что иерархические БД
4. SQL базы данных
Реляционные базы данных – старейший тип до сих пор широко используемых БД общего назначения. Данные и связи между данными организованы с помощью таблиц. Каждый столбец в таблице имеет имя и тип. Каждая строка представляет отдельную запись или элемент данных в таблице, который содержит значения для каждого из столбцов.

- поле в таблице, называемое внешним ключом, может содержать ссылки на столбцы в других таблицах, что позволяет их соединять;
- высокоорганизованная структура и гибкость делает реляционные БД мощными и адаптируемыми ко различным типам данных;
- для доступа к данным используется язык структурированных запросов (SQL);
- надёжный выбор для многих приложений.

- хранилища обеспечивают быстрый и малозатратный доступ;
- часто хранят данные конфигураций и информацию о состоянии данных, представленных словарями или хэшем;
- нет жёсткой схемы отношения между данными, поэтому в таких БД часто хранят одновременно различные типы данных;
- разработчик отвечает за определение схемы именования ключей и за то, чтобы значение имело соответствующий тип/формат.
6. Документная база данных

- база данных не предписывает опредёленный формат или схему;
- каждый документ может иметь свою внутреннюю структуру;
- документные БД являются хорошим выбором для быстрой разработки;
- в любой момент можно менять свойства данных, не изменяя структуру или сами данные.
7. Графовая база данных
Вместо сопоставления связей с таблицами и внешними ключами, графовые базы данных устанавливают связи, используя узлы, рёбра и свойства.

Графовые базы представляют данные в виде отдельных узлов, которые могут иметь любое количество связанных с ними свойств.
- выглядят аналогично сетевым;
- фокусируются на связях между элементами;
- явно отображает связи между типами данных;
- не требуют пошагового обхода для перемещения между элементами;
- нет ограничений в типах представляемых связей.
8. Колоночные базы данных
Колоночные базы данных (также нереляционные колоночные хранилища или базы данных с широкими столбцами) принадлежат к семейству NoSQL БД, но внешне похож на реляционные БД. Как и реляционные, колоночные БД хранят данные, используя строки и столбцы, но с иной связью между элементами.

- БД удобны при работе с приложениями, требующими высокой производительности;
- данные и метаданные записи доступны по одному идентификатору;
- гарантировано размещение всех данных из строки в одном кластере, что упрощает сегментацию и масштабирование данных.
9. Базы данных временных рядов
Базы данных временны́х рядов созданы для сбора и управления элементами, меняющимися с течением времени. Большинство таких БД организованы в структуры, которые записывают значения для одного элемента. Например, можно создать таблицу для отслеживания температуры процессора. Внутри каждое значение будет состоять из временной метки и показателя температуры. В таблице может быть несколько метрик.

- ориентированы на запись;
- предназначены для обработки постоянного потока входных данных;
- производительность зависит от количества отслеживаемых элементов, интервала опроса между записью новых значений и фактической полезной нагрузки данных.
NewSQL и многомодельные БД являются разными типами баз данных, но решают одну группу проблем, вызванных полярными подходами SQL или NoSQL-стратегии. Почему бы не объединить преимущества обеих групп?
10. NewSQL базы данных
NewSQL базы данных наследуют реляционную структуру и семантику, но построены с использованием более современных, масштабируемых конструкций. Цель – обеспечить большую масштабируемость, нежели реляционные БД, и более высокие гарантии согласованности, чем в NoSQL. Компромисс между согласованностью и доступностью является фундаментальной проблемой распределённых баз данных, описываемой теоремой CAP.
- возможность горизонтального масштабирования;
- высокая доступность;
- большая производительность и репликация;
- небольшой функционал и гибкость;
- немалое потребление ресурсов и необходимость специализированных знаний для работы с базой данных.
11. Многомодельные базы данных
Многомодельные базы данных – базы, объединяющие функциональные возможности нескольких видов БД. Преимущества такого подхода очевидны – одна и та же система может использовать различные представления для разных типов данных.
Совместное размещение данных из нескольких типов БД в одной системе позволяет выполнять новые операции, которые в противном случае были бы затруднены или невозможны. Например, многомодельные базы могут позволить юзерам получить доступ к данным, хранящимся в разных типах БД, и управлять ими в рамках одного запроса, а также поддерживают согласованность данных при выполнении операций, изменяющих информацию сразу в нескольких системах.
- помогают уменьшить нагрузку на СУБД;
- позволяют расширяться до новых моделей по мере изменения потребностей без внесения изменений в базовую инфраструктуру;
- обеспечивают непрерывный доступ и простое распределение данных;
- имеют линейную масштабируемость и просты для разработки.
Заключение
Изменение типов хранимых данных, требования к скорости и производительности привели и к продолжающемуся расширению типов баз данных. При этом каждый из них продолжает быть нужным в своей нише, где взаимосвязи между данными ассоциируются с определенной схемой строения базы данных.
1) Иерархическая — представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней, структура запись-потомок должна иметь в точности одного предка.

В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. Это была первая иерархически база данных благодаря которой определили ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных.
a. Серверы каталогов, такие, как LDAP и Active Directory (допускают чёткое представление в виде дерева)
2) Сетевая - являющаяся расширением иерархического подхода, сетевой структуре данных у потомка может иметься любое число предков.

3) Реляционная - данные в базе данных представляют собой набор отношений. Отношения (таблицы) отвечают определенным условиям целостности. Реляционная модель данных поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения

4) Объектная и объектно-ориентированная – Данные в таких базах представляют из себя объекты с определенными наборами свойств и методов и поведения. Отношения данных объектов строятся на основе обобщения свойств и методов и поведения различных объектов по отношению друг к другу.

2. Versant (разработка Versant Technologies) — использовалась в основном для разработки телекоммуникаций
3. POET (компания POET Software) — компактная объектная база данных. Которая поддерживает программные интерфейсы C++, Java, Visual Basic
Аннотация: В лекции рассматриваются модели организации баз данных, дается характеристика каждой модели. Описываются достоинства и недостатки существующих моделей баз данных. Даются определения атрибута, записи и отношений в различных моделях БД.
Цель лекции: Уяснить разницу между моделями организации БД . Ознакомиться с их достоинствами и недостатками. Понять, как организовываются связи в этих моделях, как применяются операции изменения в той или иной модели.
Различают три основные модели базы данных - это иерархическая, сетевая и реляционная. Эти модели отличаются между собой по способу установления связей между данными.
1. Иерархический подход к организации баз данных. Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными - одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Во-первых, все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель - единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково - таблицами. Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элемент модели - реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления ( полнота последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL .
Третий элемент реляционной модели требует от реляционной модели поддержания некоторых ограничений целостности . Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор , называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель. Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты - текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных , не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. Несмотря на преимущества объектно-ориентированных систем - реализация сложных типов данных , связь с языками программирования и т.п. - на ближайшее время превосходство реляционных СУБД гарантировано.
Рассмотрим более подробно эти модели данных далее.
Иерархическая модель базы данных
Иерархические базы данных - самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений "предок- потомок ". Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных - невозможность реализовать отношения " многие-ко-многим ", а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных . Иерархические базы данных графически могут быть представлены как перевернутое дерево , состоящее из объектов различных уровней. Верхний уровень ( корень дерева ) занимает один объект , второй - объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка ( объект , более близкий к корню) к потомку ( объект более низкого уровня), при этом объект -предок может не иметь потомков или иметь их несколько, тогда как объект - потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
Иерархической базой данных является Каталог папок Windows , с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол . На втором уровне находятся папки Мой компьютер , Мои документы, Сетевое окружение и Корзина , которые являются потомками папки Рабочий стол , а между собой является близнецами. В свою очередь , папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков ( Диск 3,5(А:), (С:), (D:), (Е:), (F:)) и системным папкам ( сканер , bluetooth и.т.д.) - на рис. 4.1.
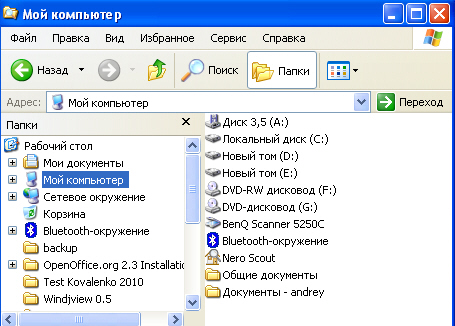
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись ( группа ), групповое отношение , база данных .
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами ( диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись .
Пример
Рассмотрим следующую модель данных предприятия (см. рис. 4.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) ( рис. 4.2 b).
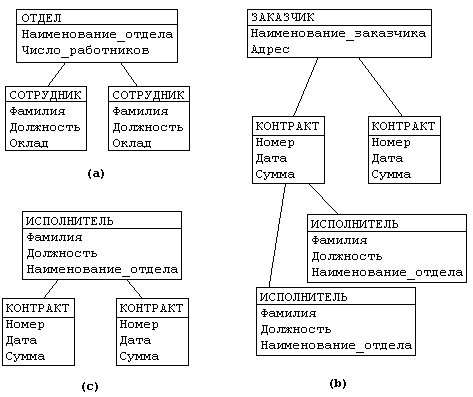
Из этого примера видны недостатки иерархических БД :
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних.
Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение , в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней ( рис. 4.2 c). Таким образом, мы опять вынуждены дублировать информацию.
Операции над данными, определенные в иерархической модели :
- Добавить в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- Изменить значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- Удалить некоторую запись и все подчиненные ей записи.
- Извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей.
- Извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева ).
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 10 тысяч руб.)
Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных ). Такой подход к манипулированию данных получил название "навигационного".
Ограничения целостности
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разные иерархии.
Читайте также: