
Какие алгоритмы сжатия вы знаете кратко опишите каждый
Обновлено: 31.05.2024
Аннотация: В лекции рассматриваются основные понятия и алгоритмы сжатия данных, приводятся примеры программной реализации алгоритма Хаффмана через префиксные коды и на основе кодовых деревьев.
Цель лекции: изучить основные виды и алгоритмы сжатия данных и научиться решать задачи сжатия данных по методу Хаффмана и с помощью кодовых деревьев.
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и насколько та или иная информация при этом сожмется. Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Шенон предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0,6 – 1,3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение .
Сжатие данных – это процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Сжатие данных можно разделить на два основных типа:
- Сжатие без потерь (полностью обратимое) – это метод сжатия данных, при котором ранее закодированная порция данных восстанавливается после их распаковки полностью без внесения изменений. Для каждого типа данных, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
- Сжатие с потерями – это метод сжатия данных, при котором для обеспечения максимальной степени сжатия исходного массива данных часть содержащихся в нем данных отбрасывается. Для текстовых, числовых и табличных данных использование программ, реализующих подобные методы сжатия, является неприемлемыми. В основном такие алгоритмы применяются для сжатия аудио- и видеоданных, статических изображений.
Алгоритм сжатия данных (алгоритм архивации) – это алгоритм , который устраняет избыточность записи данных.
Введем ряд определений, которые будут использоваться далее в изложении материала.
Алфавит кода – множество всех символов входного потока. При сжатии англоязычных текстов обычно используют множество из 128 ASCII кодов. При сжатии изображений множество значений пиксела может содержать 2, 16, 256 или другое количество элементов.
Кодовый символ – наименьшая единица данных, подлежащая сжатию. Обычно символ – это 1 байт , но он может быть битом, тритом , или чем-либо еще.
Кодовое слово – это последовательность кодовых символов из алфавита кода. Если все слова имеют одинаковую длину (число символов), то такой код называется равномерным (фиксированной длины), а если же допускаются слова разной длины, то – неравномерным (переменной длины).
Код – полное множество слов.
Токен – единица данных, записываемая в сжатый поток некоторым алгоритмом сжатия. Токен состоит из нескольких полей фиксированной или переменной длины.
Фраза – фрагмент данных, помещаемый в словарь для дальнейшего использования в сжатии.
Кодирование – процесс сжатия данных.
Декодирование – обратный кодированию процесс, при котором осуществляется восстановление данных.
Отношение сжатия – одна из наиболее часто используемых величин для обозначения эффективности метода сжатия.

Значение 0,6 означает, что данные занимают 60% от первоначального объема. Значения больше 1 означают, что выходной поток больше входного (отрицательное сжатие, или расширение).
Коэффициент сжатия – величина, обратная отношению сжатия.

Средняя длина кодового слова – это величина, которая вычисляется как взвешенная вероятностями сумма длин всех кодовых слов.
где – вероятности кодовых слов;
Существуют два основных способа проведения сжатия.
Статистические методы – методы сжатия, присваивающие коды переменной длины символам входного потока, причем более короткие коды присваиваются символам или группам символам, имеющим большую вероятность появления во входном потоке. Лучшие статистические методы применяют кодирование Хаффмана.
Словарное сжатие – это методы сжатия, хранящие фрагменты данных в "словаре" (некоторая структура данных ). Если строка новых данных, поступающих на вход, идентична какому-либо фрагменту, уже находящемуся в словаре, в выходной поток помещается указатель на этот фрагмент. Лучшие словарные методы применяют метод Зива-Лемпела.
Рассмотрим несколько известных алгоритмов сжатия данных более подробно.
Метод Хаффмана
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Хаффмановское кодирование (сжатие) – это широко используемый метод сжатия, присваивающий символам алфавита коды переменной длины, основываясь на вероятностях появления этих символов.
Идея алгоритма состоит в следующем: зная вероятности вхождения символов в исходный текст, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Таким образом, в этом методе при сжатии данных каждому символу присваивается оптимальный префиксный код , основанный на вероятности его появления в тексте.
Префиксный код – это код, в котором никакое кодовое слово не является префиксом любого другого кодового слова. Эти коды имеют переменную длину.
Оптимальный префиксный код – это префиксный код , имеющий минимальную среднюю длину.
Алгоритм Хаффмана можно разделить на два этапа.
- Определение вероятности появления символов в исходном тексте.
Первоначально необходимо прочитать исходный текст полностью и подсчитать вероятности появления символов в нем (иногда подсчитывают, сколько раз встречается каждый символ). Если при этом учитываются все 256 символов, то не будет разницы в сжатии текстового или файла иного формата.
Далее находятся два символа a и b с наименьшими вероятностями появления и заменяются одним фиктивным символом x , который имеет вероятность появления, равную сумме вероятностей появления символов a и b . Затем, используя эту процедуру рекурсивно, находится оптимальный префиксный код для меньшего множества символов (где символы a и b заменены одним символом x ). Код для исходного множества символов получается из кодов замещающих символов путем добавления 0 или 1 перед кодом замещающего символа, и эти два новых кода принимаются как коды заменяемых символов. Например, код символа a будет соответствовать коду x с добавленным нулем перед этим кодом, а для символа b перед кодом символа x будет добавлена единица.
Коды Хаффмана имеют уникальный префикс , что и позволяет однозначно их декодировать, несмотря на их переменную длину.
Пример 1. Программная реализация метода Хаффмана.
Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранения словаря). В настоящее время данный метод практически не применяется в чистом виде, обычно используется как один из этапов сжатия в более сложных схемах. Это единственный алгоритм , который не увеличивает размер исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
Говоря об алгоритмах сжатия, будем иметь в виду обратимые алгоритмы.
Алгоритм RLE (Run-Length Encoding) использует принцип выявления повторяющихся последовательностей. При сжатии записывается последовательность из двух повторяющихся величин: повторяемого значения и количества его повторений.
Алгоритм KWE (Keyword Encoding) предполагает использование словаря, в котором каждому слову соответствует двухбайтовый код. Эффективность сжатия увеличивается с ростом объема кодируемого текста.
Алгоритм Хафмана предполагает кодирование не байтами, а битовыми группами. В нем можно выделить три основные этапа.
1. Выявляется частота повторения каждого из встречающихся символов.
2. Чем чаще встречается символ, тем меньшим количеством битов он кодируется.
3. К закодированной последовательности прикладывается таблица соответствия.
Самораспаковывающийся архив получил название SFX-архив (SelF-eXtracting). Архивы такого типа в обычно создаются в форме .ЕХЕ-файла.
Архиваторы, служащие для сжатия и хранения информации, обеспечивают представление в едином архивном файле одного или нескольких файлов, каждый из которых может быть при необходимости извлечен в первоначальном виде. В оглавлении архивного файла для каждого содержащегося в нем файла хранится следующая информация:
Ø сведения о каталоге, в котором содержится файл;
Ø дата и время последней модификации файла;
Ø размер файла на диске и в архиве;
Ø код циклического контроля для каждого файла, используемый для проверки целостности архива.
Архиваторы имеют следующие функциональные возможности:
1. Уменьшение требуемого объема памяти для хранения файлов от 20% до 90% первоначального объема.
2. Обновление в архиве только тех файлов, которые изменялись со времени их последнего занесения в архив, т.е. программа-упаковщик сама следит за изменениями, внесенными пользователем в архивируемые файлы, и помещает в архив только новые и измененные файлы.
3. Объединение группы файлов с сохранением в архиве имен директорий с именами файлов, что позволяет при разархивации восстанавливать полную структуру директорий и файлов.
4. Написания комментариев к архиву и файлам в архиве.
5. Создание саморазархивируемых архивов, которые для извлечения файлов не требуют наличия самого архиватора.
6. Создание многотомных архивов– последовательности архивных файлов. Многотомные архивы предназначены для архивации больших комплексов файлов на дискеты.
Говоря об алгоритмах сжатия, будем иметь в виду обратимые алгоритмы.
Алгоритм RLE (Run-Length Encoding) использует принцип выявления повторяющихся последовательностей. При сжатии записывается последовательность из двух повторяющихся величин: повторяемого значения и количества его повторений.
Алгоритм KWE (Keyword Encoding) предполагает использование словаря, в котором каждому слову соответствует двухбайтовый код. Эффективность сжатия увеличивается с ростом объема кодируемого текста.
Алгоритм Хафмана предполагает кодирование не байтами, а битовыми группами. В нем можно выделить три основные этапа.
1. Выявляется частота повторения каждого из встречающихся символов.
2. Чем чаще встречается символ, тем меньшим количеством битов он кодируется.
3. К закодированной последовательности прикладывается таблица соответствия.
Самораспаковывающийся архив получил название SFX-архив (SelF-eXtracting). Архивы такого типа в обычно создаются в форме .ЕХЕ-файла.
Архиваторы, служащие для сжатия и хранения информации, обеспечивают представление в едином архивном файле одного или нескольких файлов, каждый из которых может быть при необходимости извлечен в первоначальном виде. В оглавлении архивного файла для каждого содержащегося в нем файла хранится следующая информация:
Ø сведения о каталоге, в котором содержится файл;
Ø дата и время последней модификации файла;
Ø размер файла на диске и в архиве;
Ø код циклического контроля для каждого файла, используемый для проверки целостности архива.
Архиваторы имеют следующие функциональные возможности:
1. Уменьшение требуемого объема памяти для хранения файлов от 20% до 90% первоначального объема.
2. Обновление в архиве только тех файлов, которые изменялись со времени их последнего занесения в архив, т.е. программа-упаковщик сама следит за изменениями, внесенными пользователем в архивируемые файлы, и помещает в архив только новые и измененные файлы.

3. Объединение группы файлов с сохранением в архиве имен директорий с именами файлов, что позволяет при разархивации восстанавливать полную структуру директорий и файлов.
4. Написания комментариев к архиву и файлам в архиве.
5. Создание саморазархивируемых архивов, которые для извлечения файлов не требуют наличия самого архиватора.
6. Создание многотомных архивов– последовательности архивных файлов. Многотомные архивы предназначены для архивации больших комплексов файлов на дискеты.
Для сжатия данных придумано множество техник. Большинство из них комбинируют несколько принципов сжатия для создания полноценного алгоритма. Даже хорошие принципы, будучи скомбинированы вместе, дают лучший результат. Большинство техник используют принцип энтропийного кодирования, но часто встречаются и другие – кодирование длин серий (Run-Length Encoding) и преобразование Барроуза-Уилера (Burrows-Wheeler Transform).
Кодирование длин серий (RLE)
Это очень простой алгоритм. Он заменяет серии из двух или более одинаковых символов числом, обозначающим длину серии, за которым идёт сам символ. Полезен для сильно избыточных данных, типа картинок с большим количеством одинаковых пикселей, или в комбинации с алгоритмами типа BWT.
На входе: AAABBCCCCDEEEEEEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
На выходе: 3A2B4C1D6E38A
Преобразование Барроуза-Уилера (BWT)
Алгоритм, придуманный в 1994 году, обратимо трансформирует блок данных так, чтобы максимизировать повторения одинаковых символов. Сам он не сжимает данные, но подготавливает их для более эффективного сжатия через RLE или другой алгоритм сжатия.
— создаём массив строк
— создаём все возможные преобразования входящей строки данных, каждое из которых сохраняем в массиве
— сортируем массив
— возвращаем последний столбец
Алгоритм лучше всего работает с большими данными со множеством повторяющихся символов. Пример работы на подходящем массиве данных (& обозначает конец файла)

Энтропийное кодирование
Алгоритм Шеннона — Фано
Одна из самых ранних техник (1949 год). Создаёт двоичное дерево для представления вероятностей появления каждого из символов. Затем они сортируются так, чтобы самые часто встречающиеся находились наверху дерева, и наоборот.

Кодирование Хаффмана
Это вариант энтропийного кодирования, работающий схожим с предыдущим алгоритмом методом, но двоичное дерево строится сверху вниз, для достижения оптимального результата.
1. Парсим ввод, считаем количество повторений символов
2. Определяем вероятность появления каждого символа
3. Сортируем список по вероятностям (самые частые вначале)
4. Создаём листы для каждого символа, и добавляем их в очередь
5. пока очередь состоит более, чем из одного символа:
— берём из очереди два листа с наименьшими вероятностями
— к коду первой прибавляем 0, к коду второй – 1
— создаём узел с вероятностью, равной сумме вероятностей двух нод
— первую ноду вешаем на левую сторону, вторую – на правую
— добавляем полученный узел в очередь
6. Последняя нода в очереди будет корнем двоичного дерева.
Арифметическое кодирование
Был разработан в 1979 году в IBM для использования в их мейнфреймах. Достигает очень хорошей степени сжатия, обычно большей, чем у Хаффмана, однако он сравнительно сложен по сравнению с предыдущими.
Вместо разбиения вероятностей по дереву, алгоритм преобразует входные данные в одно рациональное число от 0 до 1.
В общем алгоритм таков:
Если мы положим, что имеем дело с восьмибитными символами, то на входе у нас 8х8=64 бита, а на выходе – 15, то есть степень сжатия 24%.
Классификация алгоритмов

В данном случае результат получился длиннее входа, но обычно он конечно получается короче.
Модификация алгоритма LZ77, предложенная Майклом Роуде в 1981 году. В отличие от LZ77 работает за линейное время, однако требует большего объёма памяти. Обычно проигрывает LZ78 в сжатии.
DEFLATE
Придуман Филом Кацем в 1993 году, и используется в большинстве современных архиваторов. Является комбинацией LZ77 или LZSS с кодированием Хаффмана.
DEFLATE64
Патентованная вариация DEFLATE с увеличением словаря до 64 Кб. Сжимает лучше и быстрее, но не используется повсеместно, т.к. не является открытым.
Алгоритм Лемпеля-Зива-Сторера-Цимански был представлен в 1982 году. Улучшенная версия LZ77, которая просчитывает, не увеличит ли размер результата замена исходных данных кодированными.
До сих пор используется в популярных архиваторах, например RAR. Иногда – для сжатия данных при передаче по сети.
Разработан в 1987 году Тимоти Беллом, как вариант LZSS. Как и LZH, LZB уменьшает результирующий размер файлов, эффективно кодируя указатели. Достигается это путём постепенного увеличения размера указателей при увеличении размера скользящего окна. Сжатие получается выше, чем у LZSS и LZH, но скорость значительно меньше.
LZRW1
Алгоритм от Рона Вильямса 1991 года, где он впервые ввёл концепцию уменьшения смещения. Достигает высоких степеней сжатия при приличной скорости. Потом Вильямс сделал вариации LZRW1-A, 2, 3, 3-A, и 4
Вариант от Джеффа Бонвика (отсюда “JB”) от 1998 года, для использования в файловой системе Solaris Z File System (ZFS). Вариант алгоритма LZRW1, переработанный для высоких скоростей, как этого требует использование в файловой системе и скорость дисковых операций.
Lempel-Ziv-Stac, разработан в Stac Electronics в 1994 для использования в программах сжатия дисков. Модификация LZ77, различающая символы и пары длина-смещение, в дополнение к удалению следующего встреченного символа. Очень похож на LZSS.
Был разработан в 1995 году Дж. Форбсом и Т.Потаненом для Амиги. Форбс продал алгоритм компании Microsoft в 1996, и устроился туда работать над ним, в результате чего улучшенная его версия стала использоваться в файлах CAB, CHM, WIM и Xbox Live Avatars.
Разработан в 1996 Маркусом Оберхьюмером с прицелом на скорость сжатия и распаковки. Позволяет настраивать уровни компрессии, потребляет очень мало памяти. Похож на LZSS.
“Lempel-Ziv Markov chain Algorithm”, появился в 1998 году в архиваторе 7-zip, который демонстрировал сжатие лучше практически всех архиваторов. Алгоритм использует цепочку методов сжатия для достижения наилучшего результата. Вначале слегка изменённый LZ77, работающий на уровне битов (в отличие от обычного метода работы с байтами), парсит данные. Его вывод подвергается арифметическому кодированию. Затем могут быть применены другие алгоритмы. В результате получается наилучшая компрессия среди всех архиваторов.
LZMA2
Следующая версия LZMA, от 2009 года, использует многопоточность и чуть эффективнее хранит несжимаемые данные.
Статистический алгоритм Лемпеля-Зива
Концепция, созданная в 2001 году, предлагает проводить статистический анализ данных в комбинации с LZ77 для оптимизирования кодов, хранимых в словаре.
Алгоритмы с использованием словаря
Алгоритм 1978 года, авторы – Лемпель и Зив. Вместо использования скользящего окна для создания словаря, словарь составляется при парсинге данных из файла. Объём словаря обычно измеряется в нескольких мегабайтах. Отличия в вариантах этого алгоритма строятся на том, что делать, когда словарь заполнен.
При парсинге файла алгоритм добавляет каждый новый символ или их сочетание в словарь. Для каждого символа на входе создаётся словарная форма (индекс + неизвестный символ) на выходе. Если первый символ строки уже есть в словаре, ищем в словаре подстроки данной строки, и самая длинная используется для построения индекса. Данные, на которые указывает индекс, добавляются к последнему символу неизвестной подстроки. Если текущий символ не найден, индекс устанавливается в 0, показывая, что это вхождение одиночного символа в словарь. Записи формируют связанный список.

Лемпель-Зив-Велч, 1984 год. Самый популярный вариант LZ78, несмотря на запатентованность. Алгоритм избавляется от лишних символов на выходе и данные состоят только из указателей. Также он сохраняет все символы словаря перед сжатием и использует другие трюки, позволяющие улучшать сжатие – к примеру, кодирование последнего символа предыдущей фразы в качестве первого символа следующей. Используется в GIF, ранних версиях ZIP и других специальных приложениях. Очень быстр, но проигрывает в сжатии более новым алгоритмам.
Компрессия Лемпеля-Зива. Модификация LZW, использующаяся в утилитах UNIX. Следит за степенью сжатия, и как только она превышает заданный предел – словарь переделывается заново.
Лемпель-Зив-Тищер. Когда словарь заполняется, удаляет фразы, использовавшиеся реже всех, и заменяет их новыми. Не получил популярности.
Виктор Миллер и Марк Вегман, 1984 год. Действует, как LZT, но соединяет в словаре не похожие данные, а две последние фразы. В результате словарь растёт быстрее, и приходится чаще избавляться от редко используемых фраз. Также непопулярен.
Вариант LZW от 2006 года, работающий с сочетаниями символов, а не с отдельными символами. Успешно работает с наборами данных, в которых есть часто повторяющиеся сочетания символов, например XML. Обычно используется с препроцессором, разбивающим данные на сочетания.
1985 год, Матти Якобсон. Один из немногих вариантов LZ78, отличающихся от LZW. Сохраняет каждую уникальную строку в уже обработанных входных данных, и всем им назначает уникальные коды. При заполнении словаря из него удаляются единичные вхождения.
Алгоритмы, не использующие словарь
Предсказание по частичному совпадению – использует уже обработанные данные, чтобы предсказать, какой символ будет в последовательности следующим, таким образом уменьшая энтропию выходных данных. Обычно комбинируется с арифметическим кодировщиком или адаптивным кодированием Хаффмана. Вариация PPMd используется в RAR и 7-zip
bzip2
Реализация BWT с открытым исходным кодом. При простоте реализации достигает хорошего компромисса между скоростью и степенью сжатия, в связи с чем популярен в UNIX. Сначала данные обрабатываются при помощи RLE, затем BWT, потом данные особым образом сортируются, чтобы получить длинные последовательности одинаковых символов, после чего к ним снова применяется RLE. И, наконец, кодировщик Хаффмана завершает процесс.
Мэтт Махоуни, 2002 год. Улучшение PPM(d). Улучшает их при помощи интересной техники под названием „перемешивание контекста“ (context mixing). В этой технике несколько предсказательных алгоритмов комбинируются, чтобы улучшить предсказание следующего символа. Сейчас это один из самых многообещающих алгоритмов. С его первой реализации было создано уже два десятка вариантов, некоторые из которых ставят рекорды сжатия. Минус – маленькая скорость из-за необходимости использования нескольких моделей. Вариант под названием PAQ80 поддерживает 64 бита и показывает серьёзное улучшение в скорости работы (используется, в частности, в программе PeaZip для Windows).
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
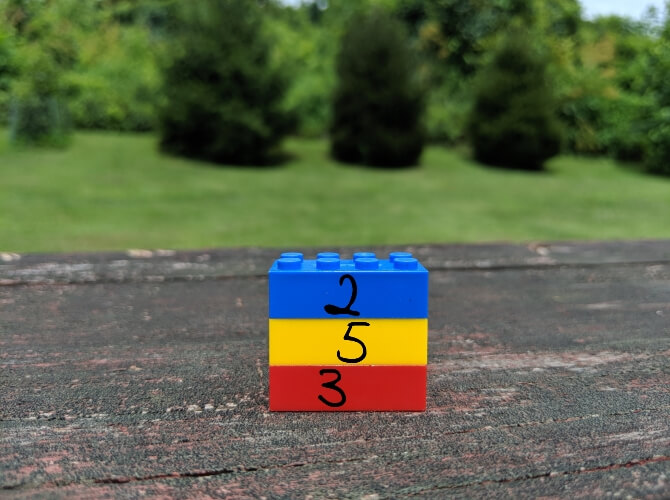
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
Информацию, которую можно сжимать может представляться в разных видах — текст, сигнал, файл. С точки зрения теории подразумевается, что инфромация исходит от источника и идет на вход компрессора в виде символа в рамках алфавита. Раньше процесс сжатия называли кодированием источника, так как удалялась избыточность на основе их предсказуемости с помощью другого представления информации. Сейчас сжатие делят на кодирование и моделирование.
Чем больше знает кодировщик о исходной информации, тем лучше он сможет их сжать. Чем лучшая модель исходных данных, тем лучше сработает кодировщик и тем больше будет коэффициент сжатия. Коэффициент сжатия показывает отношение длины сжатого текста к длине исходного. В криптологии исходный текст называется открытым, а сжатый — шифротекст.
Существует множество разных алгоритмов сжатия без потерь данных с статистическими и адаптивными моделями. Их все можно классифицировать по определенному признаку. Каждое семейство алгоритмов сжимает текст определенной структуры с определенным коэффициентом сжатия и быстродействия.
Одним из первых алгоритмов сжатия является RLE (Run Length Encoding) — алгоритм повторений и кодирования длин тиражей. Это самый простой и быстрый способ сжатия данных. Алгоритм отлично работает, если в тексте содержаться повторяющийся последовательности одного символа. На рис.1 видна схема.
Алгоритм сжатия на основе работ Шеннона
Источник генерирует разные символы с разной вероятностью, а значит, что одни символы появляются в тексте чаще других. Кодировщик должен кодировать символы так, что более частым символам соответствовал меньший по длине код, а более редким — более длинее. Согласно работам Шеннона, можно получить ожидаемую длину кода, взяв среднее значение вероятности появления каждого символа в тексте (формула энтропии текста):
где, Pi — вероятность появления i-го символа в тексте. Чтобы кодировщие был эффективным, ему нужно знать о исходном тексте. Для этого используется множество методов. Самый простой — подсчет частот, которые встречаются в тексте, и назначается ему определенная вероятность появления (ni / N), где ni — частота i-го символа, N — длина в символах всего текста.
Таблица вероятностей появления каждого символа основана на подсчете частот их встречаемости — модель первого приближения (первого порядка). Можно создавать таблицы более сложной зависимости, к примеру появления конкретного символа после другого и тд. После моделирования исходного текста, можно реализовать достаточно эффективный код.
Адекватно рассматривать модель оценки вероятности появления каждого символа. Вероятность символа определяется отрезком [0,1]. К примеру, если исходный текст состоит из символов — А, Б, В, Г. Буква А встречается 2 раза, Б — 3 раза, В — 1 раз, Г — 4 раза. Таблица вероятностей символов исходного текста показана в таблице 1.
| Символ | А | Б | В | Г |
| Вероятность | 0.2 | 0.3 | 0.1 | 0.4 |
Алгоритм сжатия на основе работ Хаффмана
Алгоритм сжатия основан на создании двоичного дерева с узловыми компонентами из символов исходного текста. Каждая ветвь имеет бит 0 или 1. Кодирование каждого символа реализуется проходом дерева по ветвям с корня, и до листочка где находится наш символ.
На примере исходного текста — АААБГВ, покажем работу дерева Хаффмана. Так как частота появления каждого символа разная, нужно составить таблицу частот символов.
| Символ | А | Б | В | Г |
| Частота появления | 3 | 1 | 1 | 1 |
Таблица нужна для создания дерева для построения кодов сжатия. Левые ветки дерева помечены битом 0, а правые — 1.(рис.2).
Символ А будет иметь код — 0. Символ Б — 10. Символ В — 110, Г — 111.
Алгоритм Хаффмана не работает с адаптивными моделями сжатия, так как каждый раз нужно перестраивать дерево, что существенно занимает время и ресурсы.
Читайте также: