
Как организована конвейерная работа процессора кратко
Обновлено: 05.07.2024
Разделение обработки компьютерной инструкции на последовательность независимых стадий с сохранением результатов в конце каждой стадии. Рассмотрение принципов работы тактового генератора. Определение преимуществ и недостатков бесконвейерной архитектуры.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 29.06.2017 |
| Размер файла | 176,6 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Конвейерный процессор
Выполнил Гущин Александр Сергеевич
студент группы 56-205А
Проверил Нечаев Валентин Иванович
Для объяснения этого понятия введем некоторые определения, поясняющие его смысл.
Конвемйер -- это способ организации вычислений, используемый в современных процессорах и контроллерах с целью ускорения выполнения инструкций (увеличения числа инструкций, выполняемых в единицу времени). Применительно к процессорам, является приемом, используемым при разработке компьютеров и других цифровых электронных устройств для увеличения их инструкционной пропускной способности (количеству инструкций, которые могут быть выполнены за определенный временной промежуток).
Идея заключается в разделении обработки компьютерной инструкции на последовательность независимых стадий(шагов) с сохранением результатов в конце каждой стадии. Это позволяет управляющим цепям процессора получать инструкции со скоростью самой медленной стадии обработки, однако при этом намного быстрее, чем при выполнении эксклюзивной полной обработки каждой инструкции от начала до конца.
Простой пятиуровневый конвейер в RISC-процессорах
На иллюстрации справа показан простой пятиуровневый конвейер в RISC-процессорах. Здесь:
· IF (англ. Instruction Fetch) -- получение инструкции,
· ID (англ. Instruction Decode) -- раскодирование инструкции,
· EX (англ. Execute) -- выполнение,
· MEM (англ. Memory access) -- доступ к памяти,
· WB (англ. Register write back) -- запись в регистр.
Вертикальная ось -- последовательные независимые инструкции, горизонтальная -- время. Зелёная колонка описывает состояние процессора в один момент времени, в ней самая ранняя, верхняя инструкция уже находится в состоянии записи в регистр, а самая последняя, нижняя инструкция -- только в процессе чтения.
Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Векторные операции обеспечивают идеальную возможность полной загрузки.
Например, простейший конвейер RISC-процессоров можно представить пятью стадиями с наборами триггеров между стадиями:
1. получение инструкции (англ. Instruction Fetch);
2. декодирование инструкции (англ. Instruction Decode) и чтение регистров (англ. Register fetch);
3. выполнение (англ. Execute);
4. доступ к памяти (англ. Memory access);
5. запись в регистр (англ. Register write back).
компьютерный архитектура тактовый конвейерный
Бесконвейерная архитектура значительно менее эффективна из-за меньшей загрузки функциональных модулей процессора в то время, пока один или небольшое число модулей выполняет свою функцию во время обработки инструкций. Конвейер не убирает полностью время простоя модулей в процессорах как таковое и не уменьшает время выполнения каждой конкретной инструкции, но заставляет модули процессора работать параллельно над разными инструкциями, увеличивая тем самым количество инструкций, выполняемых за единицу времени, а значит, и общую производительность программ.
Процессоры с конвейером внутри устроены так, что обработка инструкций разделена на последовательность стадий, предполагая одновременную обработку нескольких инструкций на разных стадиях. Результаты работы каждой из стадий передаются через ячейки памяти на следующую стадию, и так -- до тех пор, пока инструкция не будет выполнена. Подобная организация процессора, при некотором увеличении среднего времени выполнения каждой инструкции, тем не менее, обеспечивает значительный рост производительности за счёт высокой частоты завершения выполнения инструкций.
Преимущества и недостатки
1. Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
2. Некоторые комбинационные логические элементы, такие, как сумматоры или умножители, могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
1. Бесконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще, и он дешевле для изготовления.
2. Задержка инструкций в бесконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
3. У бесконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
Общий четырёхуровневых конвейер; цветные квадраты символизируют независимые друг от друга инструкции
Справа изображён общий конвейер с четырьмя стадиями работы:
1. Получение (англ. Fetch)
2. Раскодирование (англ. Decode)
3. Выполнение (англ. Execute)
4. Запись результата (англ. Write-back)
Верхняя серая область -- список инструкций, которые предстоит выполнить. Нижняя серая область -- список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
Четыре инструкции ожидают исполнения
· Зелёная инструкция забирается из памяти
· Зелёная инструкция раскодируется
· Фиолетовая инструкция забирается из памяти
· Зелёная инструкция выполняется (то есть исполняется то действие, которое она кодировала)
· Фиолетовая инструкция раскодируется
· Синяя инструкция забирается из памяти
· Итоги исполнения зелёной инструкции записываются в регистры или в память
· Фиолетовая инструкция выполняется
· Синяя инструкция раскодируется
· Красная инструкция забирается из памяти
· Зелёная инструкция завершилась
· Итоги исполнения фиолетовой инструкции записываются в регистры или в память
· Синяя инструкция выполняется
· Красная инструкция раскодируется
· Фиолетовая инструкция завершилась
· Результаты исполнения синей инструкции записываются в регистры или в память
· Красная инструкция выполняется
· Синяя инструкция завершилась
· Итоги исполнения красной инструкции записываются в регистры или в память
· Красная инструкция завершилась
Все инструкции были выполнены
Пузырек в третьем такте обработки задерживает исполнение
Очевидно, что наличие пузырька в конвейере даёт суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, показанной выше.
Исполнительные устройства должны выполнять какое-то действие на каждом такте. Пузырьки являются способом создания задержки при обработке инструкции без прекращения работы конвейера. При их выполнении не происходит полезной работы на стадиях выборки, декодирования, исполнения и записи результата. Они могут быть выражены при помощи инструкции.
Допустим, типичная инструкция для сложения двух чисел -- это СЛОЖИТЬ A, B, C. Эта инструкция суммирует значения, находящиеся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи вида
СЛОЖИТЬ R1, R2, R3
загрузить следующую инструкцию
Ячейки R1, R2 и R3 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (то есть копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней -- загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция, в принципе, начнется. В конвейерном процессоре все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому, когда первая инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, а третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объём (число) инструкций, которые могут быть выполнены одновременно, и таким образом уменьшает задержку между выполненными инструкциями -- увеличивая т. н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер.
Теоретический трёхуровневый конвейер:
Англ. название
Прочитать инструкцию из памяти
Записать результат в память и/или регистры
Псевдоассемблерный листинг, который нужно выполнить:
ЗАГРУЗИТЬ 40, A ; загрузить число 40 в A
КОПИРОВАТЬ A, B ; скопировать A в B
СЛОЖИТЬ 20, B ; добавить 20 к B
ЗАПИСАТЬ B, 0x0300 ; записать B в ячейку памяти 0x0300
Как это будет исполняться:
Инструкция ЗАГРУЗИТЬ читается из памяти.
Инструкция ЗАГРУЗИТЬ выполняется, инструкция КОПИРОВАТЬ читается из памяти.
Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (то есть число 40) записывается в регистр А. В это же время инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ.
Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления.
Множество схем включают в себя конвейеры в 7, 10 или даже 20 уровней (как, например, в процессоре Pentium 4). Поздние ядра Pentium 4 с кодовыми именами Prescott и Cedar Mill (и их Pentium D-производные) имеют 31-уровневый конвейер. Процессор Xelerator X10q имеет конвейер длиной более, чем в тысячу шагов [6] . Обратной стороной медали в данном случае является необходимость сбрасывать весь конвейер в случае, если ход программы изменился (например, по условному оператору). Эту проблему пытаются решатьпредсказатели переходов. Предсказание переходов само по себе может только усугубить ситуацию, если предсказание производится плохо. В некоторых областях применения, таких, как вычисления на суперкомпьютерах, программы специально пишутся так, чтобы как можно реже использовать условные операторы, поэтому очень длинные конвейеры весьма позитивно скажутся на общей скорости вычислений, так как длинные конвейеры проектируются так, чтобы уменьшить CPI (англ. clocks per instruction, количество тактов на инструкцию). Если ветвление происходит постоянно, перестановка машинных инструкций таким образом, чтобы те инструкции, которые, скорее всего, понадобятся, были размещены в конвейере, может значительно уменьшить потери скорости по сравнению с необходимостью каждый раз полностью сбрасывать конвейер.Некоторые программы могут использоваться для того, чтобы определять, как часто отдельные ветки исполняются на самом деле, используя технологию, известную как анализ покрытия кода (англ. code coverage analysis), хотя на практике подобный анализ является последней мерой при оптимизации.
Если процессор оснащён конвейером, код, читаемый из памяти, не выполняется сразу, а помещается в очередь (очередь предвыборки, prefetch input queue). Если код, содержащийся в памяти, будет изменён, код, содержащийся очереди конвейера, останется прежним. Также не изменятся инструкции, находящиеся в кэше инструкций. Стоит учитывать, что данная проблема характерна только для самомодифицирующихся программ и упаковщиков исполняемых файлов.
1. Raъl Rojas. The First Computers: History and Architectures. MIT Press, 2002. С. 249. 472 с. I SBN 0-262-68137-4.
2. Harvey G. Cragon. Memory Systems and Pipelined Processors. Jones and Bartlett Learning, 1996. С. 289. 575 с. ISBN 0-86720-474-5.
3. Статья по конвейерам (англ.) на ArsTechnica.
4. Архитектура процессора с противоточным конвейером (англ.).
Влияние длины конвейера. Исследование эффективности ALU и FPU процессоров разных поколений от TestLabs.kz.
Подобные документы
Структура процессора Pentium, суперскалярность, основные особенности архитектуры. Организация конвейера команд, правила объединения. Дополнительные режимы работы процессора. Источники аппаратных прерываний. Формат ММХ команды. Процессор Pentium 4, схемы.
лекция [4,0 M], добавлен 14.12.2013
Система компьютерной обработки данных для сбора, систематизации, статистической обработки, анализа результатов учебного процесса за четверть, полугодие, год. Модуль обработки данных о качестве обучения, итогов успеваемости и данных о движении учащихся.
реферат [22,5 K], добавлен 05.02.2011
Микропроцессоры с архитектурой Complex Instruction Set Computers. Развитие архитектуры IA-32 в семействе Pentium. Параллельные конвейеры обработки. Усовершенствованный блок вычисления с плавающей точкой. Технология динамического предсказания ветвлений.
презентация [220,4 K], добавлен 11.12.2013
Режимы компьютерной обработки данных. Централизованный, децентрализованный, распределенный и интегрированный способы обработки данных. Средства обработки информации. Типы ведения диалога, пользовательский интерфейс. Табличный процессор MS Excel.
курсовая работа [256,9 K], добавлен 25.04.2013
Сравнение результатов имитационного моделирования и аналитического расчета характеристик. Исследование узла коммутации пакетов данных, обработки пакетов в процессоре, буферизации и передачи по выходной линии. Определение коэффициента загрузки процессора.

Простой пятиуровневый конвейер в RISC-процессорах (IF (англ. Instruction Fetch ) — получение инструкции, ID (англ. Instruction Decode ) — раскодирование инструкции, EX (англ. Execute ) — выполнение, MEM (англ. Memory access ) — доступ к памяти, WB (англ. Register write back ) — запись в регистр. Вертикальная ось — это последовательные независимые инструкции, горизонтальная — время. Соответственно, в зеленой колонке, которая описывает состояние процессора в один момент времени, самая ранняя, верхняя инструкция уже находится в состоянии записи в регистр, а самая последняя, нижняя инструкция только в процессе чтения.
Конве́йер — это способ организации вычислений, используемый в современных процессорах и контроллерах с целью ускорения выполнения инструкций (увеличения числа инструкций, выполняемых в единицу времени). Применительно к процессорам, является приемом, используемым при разработке компьютеров и других цифровых электронных устройств для увеличения их инструкционной пропускной способности (количеству инструкций, которые могут быть выполнены за определенный временной промежуток).
Идея заключается в том, чтобы разделить обработку компьютерной инструкции на последовательности независимых шагов, с сохранением результатов в конце каждого шага. Это позволяет управляющим цепям компьютера получать инструкции со скоростью самого медленного шага обработки, но такое решение намного быстрее, чем выполнение всех этих шагов эксклюзивно для каждой инструкции.
Многие современные процессоры управляются таймером. Процессор внутри состоит из логики и памяти (триггеров). Когда приходит сигнал от таймера, триггеры приобретают своё новое значение и логике требуется отрезок времени для декодирования новых значений. Затем приходит следующий сигнал от таймера, триггеры снова принимают новые значения, и так далее. Разбивая логику на более мелкие части и вставляя триггеры между частями логики, время, необходимое логике для правильного вывода, уменьшается. В этом случае, интервал сработки таймера процессора может быть соответственно уменьшен. Например, конвейер RISC-процессоров разбит на 5 шагов, с набором триггеров между шагами:
- получение инструкции (англ.Instruction Fetch );
- раскодирование инструкции (англ.Instruction Decode ) и чтение регистров (англ.Register fetch );
- выполнение(англ.Execute );
- доступ к памяти (англ.Memory access );
- запись в регистр (англ.Register write back );
Неконвейерная архитектура неэффективна потому, что некоторые компоненты (модули) процессора простаивают, пока какой-то из модулей выполняет свою роль в цикле обработки инструкций. Конвейер не убирает полностью время простоя в процессорах как таковое, но заставляет модули процессора работать параллельно, за счет этого увеличивая общую производительность программ.
К сожалению, не все инструкции являются независимыми. В простом конвейере обработка инструкции может потребовать 5-ти этапов обработки. Для работы в полную мощность, этот конвейер должен выполнять 4 последовательные независимые инструкции, пока заканчивается обработка первой. Если же 4-х инструкций, которые не зависят от результата выполнения первой инструкции, нет, управляющая логика должна вставлять в конвейер ничего не делающую заглушку (англ. stall ) до тех пор, пока зависимость не будет разрешена. К счастью, такие техники, как форвардинг, значительно уменьшают количество случаев, где всё же необходимо вставлять заглушки (то есть заставлять процессор пробуксовывать). Хотя конвейеры в теории позволяют увеличить производительность по сравнению с бесконвейерным процессором в количество раз, равное количеству этапов (подразумевая, что частота таймера также масштабируется с количеством этапов), в реальности, большинство кода не позволяет идеального выполнения.
Содержание
Преимущества и недостатки
Конвейер помогает не во всех случаях. Существует несколько возможных минусов. Конвейер инструкций можно назвать "полностью конвейерным", если он может принимать новую инструкцию каждый машинный цикл (англ. en:clock cycle ). Иначе в конвейер должны быть вынужденно вставлены задержки, которые выравняют конвейер, при этом ухудшат его производительность.
Преимущества конвейера:
- Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
- Некоторые комбинационные логические элементы, такие как сумматоры (англ.adders ) или умножители (англ.multipliers ) могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
Недостатки конвейера:
- Беcконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически, каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще и он дешевле для изготовления.
- Задержка инструкций в беcконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
- У беcконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
Примеры
Общий конвейер

Справа изображен общий конвейер с четырьмя стадиями работы:
- Получение (англ.Fetch )
- Раскодирование (англ.Decode )
- Выполнение (англ.Execute )
- Запись результата (англ.Write-back )
Верхняя серая область — список инструкций, которые предстоит выполнить. Нижняя серая область — список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
Пузырек
Очевидно, что наличие пузырька в конвейере дает суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, продемонстрированной выше.
Пузырьки - это как заглушки, в которых не случается ничего полезного при их прочтении, раскодировании, исполнении и записи результата. Они могут быть выражены при помощи NOP.
Пример 1
Допустим, типичная инструкция для сложения двух чисел это СЛОЖИТЬ A, B, C , которая суммирует значения, которые находятся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи вида
Ячейки R1 и R2 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (т.е. копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней - загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре, только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция в принципе начнется. В конвейерном процессоре, все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому когда эта инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, и третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объем (число) инструкций, которые могут быть выполнены одновременно и таким образом уменьшает задержку между выполненными инструкциями — увеличивая т.н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер. Процессоры Intel Pentium 4 имеют 20-тиуровневый конвейер.
Пример 2
Чтобы лучше продемонстрировать идею, давайте посмотрим на теоретический трехуровневый конвейер:
| Шаг | Описание |
|---|---|
| Загрузка | Прочитать инструкцию из памяти |
| Исполнение | Исполнить инструкцию |
| Запись | Записать результат в память и/или регистры |
и на псевдоассемблерный листинг, который нужно выполнить:
Теперь как это всё будет исполняться:
| Загрузка | Исполнение | Запись |
|---|---|---|
| ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ читается из памяти.
| Загрузка | Исполнение | Запись |
|---|---|---|
| КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ выполняется, тогда как инструкция КОПИРОВАТЬ читается из памяти.
| Загрузка | Исполнение | Запись |
|---|---|---|
| СЛОЖИТЬ | КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (т.е. число 40) записывается в регистр А. В это же время, инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ.
| Загрузка | Исполнение | Запись |
|---|---|---|
| ЗАПИСАТЬ | СЛОЖИТЬ | СКОПИРОВАТЬ |
Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления.
Трудности
Из-за конвейера процессора, код, который загружает процессор, не будет исполнен мгновенно. Из-за этого, обновления в коде, которые находятся очень близко к текущему месту исполнения программы, могут пройти незамеченными из-за того, что код уже предзагружен в en:Prefetch Input Queue. Кэши инструкций (англ. en:Instruction cache ) еще больше усугубляют эту проблему. Стоит учитывать, что данная проблема присутствует только в самомодифицирующихся программах.
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Первым шагом на пути обеспечения параллельности уровня команд явилось создание конвейера команд. Идея конвейера команд была предложена в 1956 году С.А. Лебедевым. Команда подразделяется на несколько этапов, каждый из которых выполняется своей частью аппаратуры, причем, эти части могут работать параллельно. Если на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора в каждый такт появляется результат очередной команды. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Количество этапов, на которые конструкторы разбивают выполнение процессорной команды, может быть различным (в разных моделях процессоров х86 колеблется от 2 i8088 до 20 Pentium IV).
Конвейеризация — способ обеспечения параллельности выполнения команд
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды — IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров — ID;
- выполнение операции / вычисление эффективного адреса памяти — EX;
- обращение к памяти — MEM;
- запоминание результата — WB.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунках показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и соответственно пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.

Блоки прохождения команды в процессоре
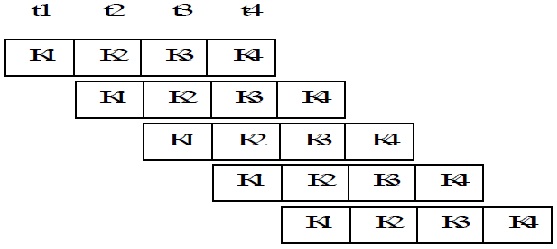
Пятиступенчатая схема конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие — образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд — естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд — разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (см. таблицу).
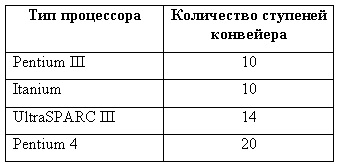
Суперконвейер
Издания, посвященные компьютерной тематике, читают люди далеко не глупые. Другое дело, что знать абсолютно все невозможно - это факт. Ну и, конечно, читать намного интереснее, если понимаешь, о чем хочет сказать в своем материале автор. Если пролистать "КВ", то практически в каждом номере вы найдете такие слова, как "конвейер", "FPU", "южный мост", "RAMDAC", "Z-Buffer", "теневая маска" и т.д., и т.п. А вот объяснить смысл многих слов и выражений, в таком изобилии встречающихся в газете, может далеко не каждый читатель. Эти размышления и привели к написанию цикла небольших статей, в которых будет рассказываться о том многом, что может таить в себе понятие "современный компьютер". Ну а о чем речь пойдет сегодня, думаю, понятно из заголовка.
Как известно, сущность работы процессора заключается в выполнении программы, хранящейся в памяти. Программа представляет собой набор команд (инструкций) и данных. Считывая эти команды, процессор выполняет определенные действия. Проблема в том, что процесс обработки команды не может быть выполнен за одну стадию. В самом деле, как минимум, команду нужно извлечь из памяти, затем ее выполнить и снова сохранить (кроме названных, в процессе обработки команды присутствуют и другие, не менее важные этапы).
В "ранних" процессорах обработка следующей команды не могла быть начата до завершения всех этапов обработки над предыдущей. Это существенно тормозило работу процессора - на каждую инструкцию уходило более 10 тактов процессорного ядра. Инженеры не могли с этим мириться, поэтому обработку команд они поставили, в буквальном смысле, на конвейер - как только команда проходила один из этапов, сразу же на ее место становилась следующая, чтобы пройти аналогичный этап, и т.д.
Первые конвейеры, обладателями которых стали 486-е компьютеры, были пятиступенчатыми. В современных процессорах этапы стандартного пятиступенчатого конвейера делят еще на более мелкие части (например, у Pentium II конвейер имеет 10 ступеней, у Pentium 4 - 20). С увеличением числа ступеней в конвейере на каждый шаг приходится меньше работы, а, следовательно, и меньше аппаратной логики. Упрощение логики, в свою очередь, позволяет повысить рабочую частоту процессора. Именно этот факт позволил Pentium 4 достичь таких высоких рабочих частот. Добавлю, что наличие более 5 ступеней в конвейере носит название "суперконвейеризация".
Начиная с 5-го поколения, в процессорах появился двойной конвейер - U (основной) и V (дополнительный). Основной конвейер выполняет все команды, а дополнительный - ряд наиболее распространенных инструкций. При этом становится возможным выполнять, в среднем, более одной команды за такт. Процессор, имеющий в своем составе два и более конвейера, называется суперскалярным. Введение нескольких конвейеров значительно повышает производительность процессора без увеличения частоты.
Установка конвейеров в процессорах вызвала появление еще одного очень важного модуля - блока предсказания переходов. О том, зачем он понадобился и как бы без него было "нехорошо", мы поговорим в следующий раз.
Читайте также: