
Как называется документ для школьного кодирования
Обновлено: 05.07.2024
Кодирование – это процесс преобразования данных из исходной формы представления в коды.
Код – это набор условных символов для представления информации.
К целям использования кодирования относятся:
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
- компактное хранение, удобство при обработке и передаче информации через автоматические устройства с программным обеспечением;
- удобство при обмене данными между субъектами;
- четкое отображение информации;
- распознавание объектов и субъектов;
- шифровка конфиденциальной информации.
Виды кодирования информации, какие бывают способы изменения вида
Перевести в систему кодов можно текст, цвета, графическое изображение, числа, звук, видео и т.д.
Кодирование текстовой информации
Выделяют 3 основных вида кодирования текста:
- графический – текст переводится в рисунки;
- символьный – преобразование происходит с помощью знаков алфавита, в котором представлен исходный текст;
- числовой – текст кодируется в числа.
Поскольку вся информация представлена в памяти компьютера в двоичной системе, для работы с текстом в ЭВМ используют числовой способ кодирования.
Изначально кодирование символов осуществлялось по 7-битному стандарту. В этой системе вычислительная машина записывала в свою память 128 разных состояний. Каждому из них соответствовала определенная буква, знак или символ.
Двоичное кодирование предполагает, что каждый знак соответствует уникальному двоичному коду. В стандартном коде информационного обмена ASCII регламентируется присвоение символу такой последовательности. Первые 33 кода – это операции, такие как пробел, ввод и т.п. Коды 33 – 127 соответствуют буквам латинского алфавита, цифрам, арифметическим символам и знакам препинания. Коды 128 – 255 – это буквы национального алфавита.
Неудобство существования разных кодовых языков состоит в том, что они не адаптированы. Следовательно, текст, созданный в одном стандарте, не будет отображаться в другой кодовой системе. Разработчики нашли решение этой проблемы и предусмотрели автоматическую перекодировку текстовой информации при работе с разными кодовыми стандартами.
Кодирование цвета
Основой всех цветов являются красный, зеленый и синий. На этом свойстве базируется одна из моделей представления цветового разнообразия, названная по первым буквам данных цветов RGB (red, green, blue). Этот стандарт использует всего 3 байта, по одному на каждый цвет. При единице цвет включен, при нуле – выключен. Из трех базовых цветов можно составить 8 двоичных кодов , значит, 8 разных цветов: красный, зеленый синий, желтый, белый, голубой, лиловый, черный.
Для управления яркостью вводят еще один бит, и получается модель IRGB (от английского Intensity – интенсивность). При этом образуются 8 дополнительных кодов, соответственно, цветовая гамма расширяется до 16 оттенков. Добавляются серый, ярко-синий, ярко-зеленый, ярко-голубой, ярко-красный, ярко-лиловый, ярко-желтый, ярко-белый.
Создание более богатой палитры осуществляется в 6-битной системе, называемой RrGgBb. Код 00 означает, что цвет выключен, 01 – это слабый цвет, 10 – обычный оттенок и 11 – интенсивный. В этом случае можно закодировать 64 цвета. Несмотря на это, на экране параллельно могут отражаться до 16 оттенков, поскольку кодирование в кадровом буфере происходит в 4-битной системе. Представление цвета в RrGgBb применяется на видеоадаптерах EGA.
В принтерах используется иная цветовая модель – CMYK. Она базируется на голубом, фиолетовом, желтом и черном цветах (Cyan, Magenta, Yellow, Key color – обозначение черного цвета). Так как эти тона получены при вычитании из белого основных цветов, модель называется субстрактивной.
Выбор такой цветовой модели для полиграфии объясняется техническим удобством. Так как печать производится на бумаге, нужно учитывать свойство поверхности отражать. В этом случае проще считать, сколько света отразилось, чем поглотилось.
Кодирование графической информации
Представление графической информации в компьютерах подразделяется на два формата:
- растровая графика;
- векторная графика.
Растровый формат можно назвать точечным. Расположенные строго по строкам и столбцам точки имеют отдельные координаты нахождения на дисплее, цвет и уровень интенсивности. Качество изображения напрямую зависит от количества точек – чем их больше, тем картинка качественнее. Растровый способ кодирования подходит для фотографий.
Векторная графика опирается на закодированные геометрические фигуры. В числовой формат приведены размеры объектов, координаты вершин, толщина контуров цвет заливки. Векторное кодирование удобно применять при создании рекламной продукции.
Кодирование числовой информации
Числа в памяти вычислительных машин хранятся в двоичной системе счисления. Выделяют два способа представления чисел:
- форма с фиксированной точкой – для целых чисел;
- форма с плавающей точкой – для действительных чисел.
Целочисленные значения в компьютере представлены с фиксированной запятой.
Целое положительное число переводят в двоичную систему счисления. К полученному коду приписывают 2 нуля слева. Крайний разряд слева в положительном числе равен 0.
Целое отрицательное число преобразуется следующим образом. Число без минуса переводят в двоичную систему, дополняют его нулями слева. Образовавшийся код переводят в обратный, заменяя нули единицами, а единицы – нулями. К полученной комбинации чисел прибавляют 1.
Порядок кодирования действительного или вещественного числа выглядит следующим образом. Число десятичной системы счисления переводят в двоичную. Определяют так называемую мантиссу числа: перемещают запятую в нужную сторону, чтобы слева не было ни одной единицы. Далее определяют значение порядка – количество знаков, на которое перемещена запятая для определения мантиссы.
Кодирование звуковой информации
Звук – это волны с постоянно меняющейся частотой и интенсивностью, вызванные колебанием частиц. Человек распознает звук благодаря меняющемуся давлению акустической волны на препятствия. Громкость звука зависит от акустики звуковой волны, а тон – от частоты.
При оцифровке непрерывная акустическая волна временно превращается в прерывистую. Дискретная форма представляет собой короткие отрезки с неизменным сигналом.
Частота дискретизации – количество измерений громкости в секунду.
Глубина кодирования звука – количество данных, необходимое для преобразования прерывистых уровней громкости звукового сигнала.
От частоты дискретизации глубины кодирования звука зависит точность воспроизведения оригинального звука. Чем выше эти показатели, тем корректнее представление звуковой информации.
Кодирование видеозаписи
Видеофайл состоит из звукового элемента и графического изображения, поэтому эти составляющие подвергаются раздельной кодировке.
Принципы преобразования звука видеозаписи в двоичную систему аналогичны с кодированием обычной звуковой информации.
Последовательность кодирования графики также схожа с переводом обычного изображения в двоичный код. В случае с видео шифруется лишь первый кадр. Последующие изображения преобразуются относительно предыдущей картинки посредством записи изменений.
По завершении процесса кодирования звуковой дорожки и графики получается двоичный код для хранения в памяти ПК и других электронных носителях. Синхронность воспроизведения видеозаписи осуществляется путем разделения этих операций.
Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернете, создавать и обрабатывать графические изображения и и.д
Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года.
Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила - законы записи этих кодов, т.е. уметь кодировать.
Код - набор условных обозначений для представления информации.
Кодирование - процесс представления информации в виде кода.
Для общения друг с другом мы используем код - русский язык. При разговоре этот код передается звуками, при письме - буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Способ кодирования (форма представления) информации зависит от цели, ради которой осуществляется кодирование. Такими целями могут быть сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. п.
Чаще всего применяют следующие способы кодирования информации:
1) графический - с помощью рисунков или значков;
2) числовой - с помощью чисел:
3) символьный с помощью символов того же алфавита, что и исходный текст.
Переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки, также называют кодированием .
Действия по восстановлению первоначальной формы представления информации принято называть декодированием . Для декодирования надо знать код.
Кодирование текстовой информации
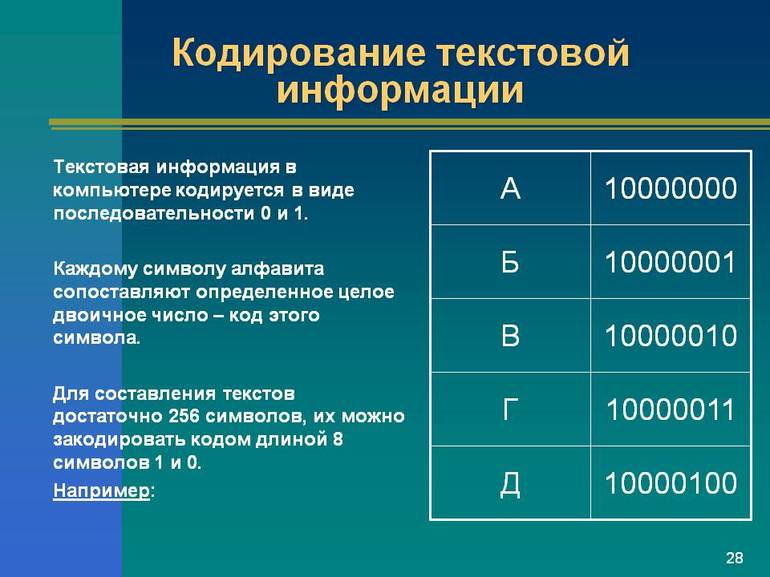
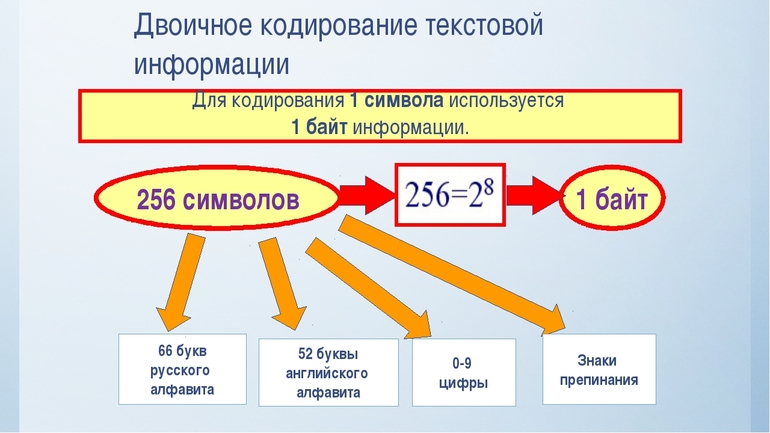
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute). В системе ASCII закреплены две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы. В настоящее время существует много различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Mac, ISO),поэтому тексты, созданные в одной кодировке , могут не правильно отображаться в другой.
Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей). Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”. Тогда для его кодирования достаточно 1 бита:
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов:
00 – черный 10 – зеленый
01 – красный 11 – коричневый
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Из трех цветов можно получить восемь комбинаций:
1 1 0 Коричневый
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

Индеец пингует
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Персональные компьютеры предназначены для воспроизведения видеофильмов и музыки, организации речевых конференций, обработки графических изображений, арифметических подсчётов. Для предоставления данных в альтернативном варианте проводится кодирование информации путём составления специальной модели явления либо объекта. Процесс осуществляется с помощью специальных символов.
- Трактовка понятий
- Двоичная методика
- Текстовое значение
- Растровое изображение
- Звуки и их разрядность
- Машинные команды

Трактовка понятий
Запись 251299 может нести следующие смысловые нагрузки:
- массу;
- длину;
- расстояние между объектами;
- телефонный номер.
Восприятие сигналов светофора — основная цель, для чего нужна процедура кодирования передаваемой информации при переходе через дорогу. В этом случае зашифровка сводится к применению совокупности символов по правилам дорожного движения. В различных отраслях культуры, науки, техники разработаны специфические формы записи данных:
- устно;
- письменно;
- сигналами;
- жестами.
В школе рассматриваемая тема изучается в 5 классе. К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
В процессе развития технологий учёные разработали несколько способов и видов кодирования информации. В конце XIX века американец Морзе Сэмюель разработал уникальную систему шифрования. В её основе находятся 3 символа:
- длинный сигнал либо тире;
- короткий сигнал (точка);
- отсутствие сигнала (пауза).
Последний знак применяется для равномерного разделения букв. В вычислительных технологиях применяется система двоичного кодирования (ДК): 0 и 1. На английском языке используется выражение binary digit либо сокращённо bit (бит).
Через 1 бит можно выразить:
- да либо нет;
- белое или чёрное;
- ложь либо истина.
Чтобы зашифровать действительные числа, изучается специальный формат, в котором предусмотрена плавающая запятая. Для предметного опознания проводится декодирование. Процесс совершается индивидом с учётом анализа полученной информации.
Текстовое значение

Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111. На примере человек различает символы с учётом их начертания, а вычислительная техника — кода. В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Первоосновной считается стандарт ASCII. Он разработан Национальным институтом ANSI. Система основана на 2-х таблицах шифрования:
- базовая (символы 0−127);
- условная расширенная (128−255).
Знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальной кодировки применяются показатели 128−255. За всю историю существования русского языка использовались следующие кодовые таблицы:
Текст, зашифрованный по одной системе, может неверно поясняться в другой.
Растровое изображение
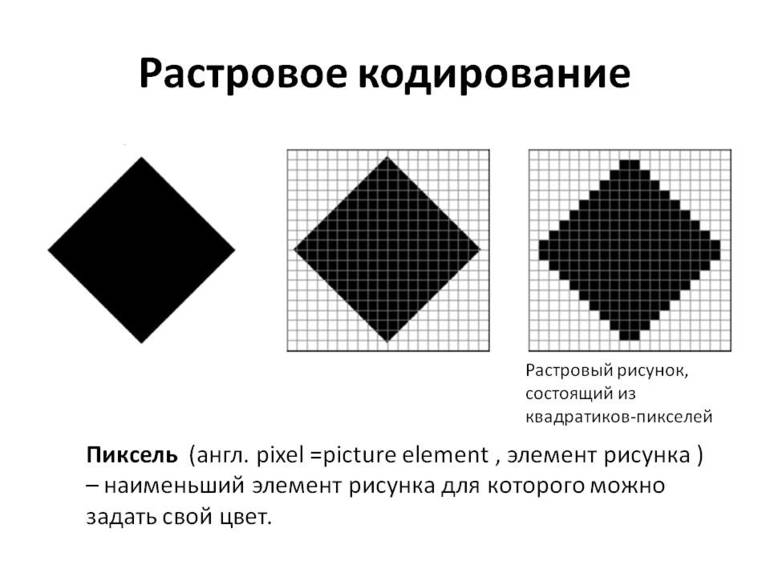
Графические данные на мониторе представляются в качестве растрового изображения. Для его формирования применяется конкретное количество строк из пикселей (точек). Для каждого пикселя характерен знаковый код, в котором хранится информация об оттенке пикселя.
Чтобы получить чёрно-белое фото, требуется 2 состояния: чёрный (0) и белый (1). Так как для восстановления полной картинки используется несколько красок, поэтому одного бита на пиксель недостаточно. Для передачи фото из 4-х оттенков, понадобится 2 бита на 1 пиксель.
Формирование цветного изображения на мониторе осуществляется путём смешивания 3-х основных цветов: синего, красного и зелёного. Из этих оттенков получается 8 комбинаций. Кодировка изображения из восьми цветов проводится с помощью трёх битов памяти на 1 пиксель. Чтобы получить разноцветную картинку, увеличивается число нужных вариантов сочетаний оттенков.
Для палитры из 16 цветов понадобится 4-разрядная кодировка пикселя. На три бита базовых оттенков приходится 1 бит интенсивности. Он отвечает за яркость всех цветов одновременно. Для определения объёма растрового изображения потребуется умножить число точек на аналогичный показатель, характерный для одной точки.
Чтобы представить графическую информацию, применяется векторное изображение. Оно представлено в виде соответствующего объекта, состоящего из стандартных отрезков и дуг. Их положение определяется путём нахождения координат точек, длины радиуса. У каждой линии есть свой тип:
- пунктирная;
- сплошная;
- штрихпунктирная.
Чтобы закодировать данные о векторной картинке, применяются обычные буквенно-цифровые символы и специальные программы. Качество фото определяется разрешением монитора: количество точек, из которых получается картинка. Чем выше показатель, тем больше количество точек в строке, тем лучше качество фото.
Звуки и их разрядность
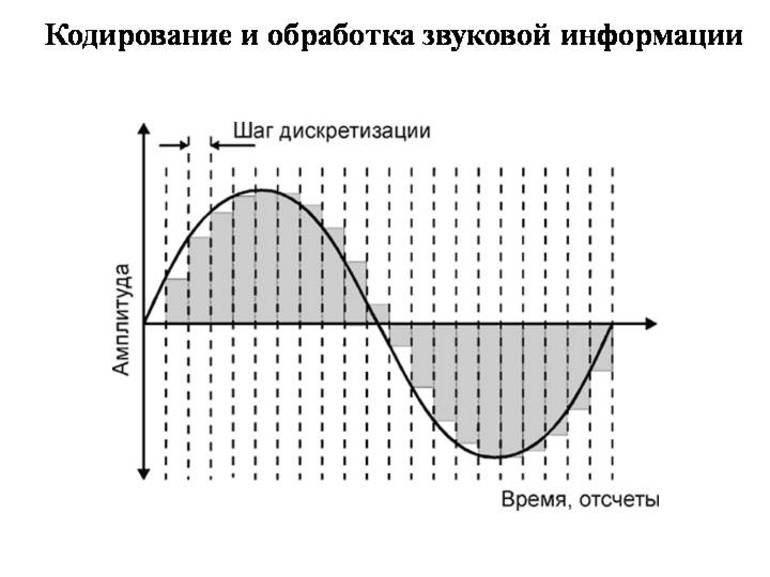
C 90-х годов компьютеры работают со звуковой информацией. В каждой вычислительной машине предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Чем больше последний показатель, тем он громче для человеческого восприятия. Чем будет больше частота, тем выше тон.
Современное программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность электроимпульсов. Для шифровки последних явлений используются двоичная форма и аудиоадаптер либо звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс наблюдается при вводе звуков и обратном их преобразовании.
В задачи аудиоадаптера входят:
- измерение амплитуды электрического тока с конкретным периодом;
- данные заносятся в регистр, а затем в оперативную память.

Качество звука определяется следующими понятиями: дискретизация и разрядность. Первый термин связан с количеством измерений входящих сигналов за одну секунду. Показатель измеряется в герцах (Гц). Для одного измерения за секунду характерна частота в 1 Гц. Под разрядностью подразумевается число бит в регистре звуковой платы. Величина определяет точность измерения входящих сигналов.
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК). Они содержат в себе некоторую информацию:
- Местонахождение операнд.
- Хранилище для результатов операций.
- Выбор следующей команды.
У каждого процессора МК со стандартным форматом и строгой фиксированной длиной сама команда состоит из адреса и кода операции. Последний показатель описывает действия процессора. По адресной части определяется, где была произведена операция. С учётом её структуры она классифицируется на моно- и мультиадресные части. Длина кода зависит от числа действий, которые входят в систему компьютера.
Читайте также: