
Языки искусственного интеллекта сообщение
Обновлено: 05.05.2024
Это прежде всего Лисп (LISP) и Пролог (Prolog) [8] – наиболее распространенные языки, предназначенные для решения задач искусственного интеллекта. Есть и менее распространенные языки искусственного интеллекта, например РЕФАЛ, разработанный в России. Универсальность этих языков меньшая, нежели традиционных языков, но ее потерю языки искусственного интеллекта компенсируют богатыми возможностями по работе с символьными и логическими данными, что крайне важно для задач искусственного интеллекта. На основе языков искусственного интеллекта создаются специализированные компьютеры (например, Лисп-машины), предназначенные для решения задач искусственного интеллекта. Недостаток этих языков – неприменимость для создания гибридных экспертных систем.
Специальный программный инструментарий
В эту группу программных средств искусственного интеллекта входят специальные инструментарии общего назначения. Как правило, это библиотеки и надстройки над языком искусственного интеллекта Лисп: КЕЕ (Knowledge Engineering Environment), FRL (Frame Representation Language), KRL (Knowledge Represantation Language), ARTS и др. [1,4,7,8,10], позволяющие пользователям работать с заготовками экспертных систем на более высоком уровне, нежели это возможно в обычных языках искусственного интеллекта.
"Оболочки"
Под "оболочками" (shells) понимают "пустые" версии существующих экспертных систем, т.е. готовые экспертные системы без базы знаний. Примером такой оболочки может служить EMYCIN (Empty MYCIN – пустой MYCIN) [8], которая представляет собой незаполненную экспертную систему MYCIN. Достоинство оболочек в том, что они вообще не требуют работы программистов для создания готовой экспертной системы. Требуется только специалист(ы) в предметной области для заполнения базы знаний. Однако если некоторая предметная область плохо укладывается в модель, используемую в некоторой оболочке, заполнить базу знаний в этом случае весьма не просто.
ТЕХНОЛОГИЯ РАЗРАБОТКИ ЭКСПЕРТНЫХ СИСТЕМ
1. Этапы разработки
2. Этап 1: выбор подходящей проблемы
3. Этап 2: разработка прототипной системы
4. Этап 3: развитие прототипа до промышленной ЭС
5. Этап 4: оценка системы
6. Этап 5: стыковка системы
7. Этап 6: поддержка системы
ЭТАПЫ РАЗРАБОТКИ
Разработка программных комплексов экспертных систем как за рубежом, так и в нашей стране находится на уровне скорее искусства, чем науки. Это связано с тем, что долгое время системы искусственного интеллекта внедрялись в основном во время фазы проектирования, а чаще всего разрабатывалось несколько прототипных версий программ, прежде чем был получен конечный продукт. Такой подход действует хорошо в исследовательских условиях, однако в коммерческих условиях он является слишком дорогим, чтобы оправдать коммерчески жизненный продукт.
Процесс разработки промышленной экспертной системы, опираясь на традиционные технологии [4,8,10], можно разделить на шесть более или менее независимых этапов (рис. 16.7), практически не зависимых от предметной области.
Рис. 16.7.Этапы разработки ЭС
Последовательность этапов дана для общего представления о создании идеального проекта. Конечно, последовательность эта не вполне фиксированная. В действительности каждый последующий этап разработки ЭС приносит новые идеи, которые могут повлиять на предыдущие решения и даже привести к их переработке. Именно поэтому многие специалисты по информатике весьма критично относятся к методологии экспертных систем. Они считают, что расходы на разработку таких систем очень большие, время разработки слишком длительное, а полученные в результате программы ложатся тяжелым бременем на вычислительные ресурсы.
В целом за разработку экспертных систем целесообразно браться организации, где накоплен опыт по автоматизации рутинных процедур обработки информации, например:
1. информационный поиск;
2. сложные расчеты;
4. обработка текстов.
Решение таких задач, во-первых, подготавливает высококвалифицированных специалистов по информатике, необходимых для создания интеллектуальных систем, во-вторых, позволяет отделить от экспертных систем неэкспертные задачи.
ЭТАП 1: ВЫБОР ПОДХОДЯЩЕЙ ПРОБЛЕМЫ
Этот этап включает деятельность, предшествующую решению начать разрабатывать конкретную ЭС. Он включает:
1. определение проблемной области и задачи;
2. нахождение эксперта, желающего сотрудничать при решении проблемы, и назначение коллектива разработчиков;
3. определение предварительного подхода к решению проблемы;
4. анализ расходов и прибыли от разработки;
5. подготовку подробного плана разработки.
Правильный выбор проблемы представляет, наверное, самую критическую часть разработки в целом. Если выбрать неподходящую проблему, можно очень быстро увязнуть в "болоте" проектирования задач, которые никто не знает, как решать. Неподходящая проблема может также привести к созданию экспертной системы, которая стоит намного больше, чем экономит. Дело будет обстоять еще хуже, если разработать систему, которая работает, но не приемлема для пользователей. Даже если разработка выполняется самой организацией для собственных целей, эта фаза является подходящим моментом для получения рекомендаций извне, чтобы гарантировать удачно выбранный и осуществимый с технической точки зрения первоначальный проект.

При выборе области применения следует учитывать, что если знание, необходимое для решения задач, постоянное, четко формулируемое и связано с вычислительной обработкой, то обычные алгоритмические программы, по всей вероятности, будут самым целесообразным способом решения проблем в этой области.
Экспертная система ни в коем случае не устранит потребность в реляционных базах данных, статистическом программном обеспечении, электронных таблицах и системах текстовой обработки. Но если результативность задачи зависит от знания, которое является субъективным, изменяющимся, символьным или вытекающим частично из соображений здравого смысла, тогда область может обоснованно выступать претендентом на экспертную систему.
Приведем некоторые факты, свидетельствующие о необходимости разработки и внедрения экспертных систем:
1. нехватка специалистов, расходующих значительное время для оказания помощи другим;
2. потребность в многочисленном коллективе специалистов, поскольку ни один из них не обладает достаточным знанием;
3. сниженная производительность, поскольку задача требует полного анализа сложного набора условий, а обычный специалист не в состоянии просмотреть (за отведенное время) все эти условия;
4. большое расхождение между решениями самых хороших и самых плохих исполнителей;
5. наличие конкурентов, имеющих преимущество в том, что они лучше справляются с поставленной задачей.
Подходящие задачи имеют следующие характеристики:
1. являются узкоспециализированными;
2. не зависят в значительной степени от общечеловеческих знаний или соображений здравого смысла;
3. не являются для эксперта ни слишком легкими, ни слишком сложными (время, необходимое эксперту для решения проблемы, может составлять от трех часов до трех недель);
4. условия исполнения задачи определяются самим пользователем системы;
5. имеет результаты, которые можно оценить.
Обычно экспертные системы разрабатываются путем получения специфических знаний от эксперта и ввода их в систему. Некоторые системы могут содержать стратегии одного индивида. Следовательно, найти подходящего эксперта – это ключевой шаг в создании экспертных систем.
В процессе разработки и последующего расширения системы инженер по знаниям и эксперт обычно работают вместе. Инженер по знаниям помогает эксперту структурировать знания, определять и формализовать понятия и правила, необходимые для решения проблемы.
Во время первоначальных бесед они решают, будет ли их сотрудничество успешным. Это немаловажно, поскольку обе стороны будут работать вместе по меньшей мере в течение одного года. Кроме них в коллектив разработчиков целесообразно включить потенциальных пользователей и профессиональных программистов.
Предварительный подход к программной реализации задачи определяется исходя из характеристик задачи и ресурсов, выделенных на ее решение. Инженер по знаниям выдвигает обычно несколько вариантов, связанных с использованием имеющихся на рынке программных средств. Окончательный выбор возможен лишь на этапе разработки прототипа.
После того как задача определена, необходимо подсчитать расходы и прибыли от разработки экспертной системы. В расходы включаются затраты на оплату труда коллектива разработчиков. В дополнительные расходы включают стоимость приобретаемого программного инструментария, с помощью которого разрабатывается экспертная система.
Прибыль возможна за счет снижения цены продукции, повышения производительности труда, расширения номенклатуры продукции или услуг или даже разработки новых видов продукции или услуг в этой области. Соответствующие расходы и прибыли от системы определяются относительно времени, в течение которого возвращаются средства, вложенные в разработку. На современном этапе большая часть фирм, развивающих крупные экспертные системы, предпочли разрабатывать дорогостоящие проекты, приносящие значительные прибыли.
Наметились тенденции разработки менее дорогостоящих систем, хотя и с более длительным сроком возвращаемости вложенных в них средств, так как программные средства разработки экспертных систем непрерывно совершенствуются.
После того как инженер по знаниям убедился, что:
1. данная задача может быть решена с помощью экспертной системы;
2. экспертную систему можно создать предлагаемыми на рынке средствами;
3. имеется подходящий эксперт;
4. предложенные критерии производительности являются разумными;
5. затраты и срок их возвращаемости приемлемы для заказчика, он составляет план разработки.
План определяет шаги процесса разработки и необходимые затраты, а также ожидаемые результаты.
ЭТАП 2: РАЗРАБОТКА ПРОТОТИПНОЙ СИСТЕМЫ
Понятие прототипной системы
Прототипная система является усеченной версией экспертной системы, спроектированной для проверки правильности кодирования фактов, связей и стратегий рассуждения эксперта. Она также дает возможность инженеру по знаниям привлечь эксперта к активному участию в разработке экспертной системы и, следовательно, к принятию им обязательства приложить все усилия для создания системы в полном объеме.
Объем прототипа – несколько десятков правил, фреймов или примеров. На рис. 16.8 изображены шесть стадий разработки прототипа и минимальный коллектив разработчиков, занятых на каждой из стадий (пять стадий заимствованы из [10]). Приведем краткую характеристику каждой из стадий, хотя эта схема представляет грубое приближение к сложному итеративному процессу.
Рис. 16.8.Стадии разработки прототипа ЭС
Хотя любое теоретическое разделение бывает часто условным, осознание коллективом разработчиков четких задач каждой стадии представляется целесообразным. Роли разработчиков (эксперт, программист, пользователь и аналитик) являются постоянными на протяжении всей разработки. Совмещение ролей нежелательно.
Сроки приведены условно, так как зависят от квалификации специалистов и особенностей задачи.
Идентификация проблемы
Уточняется задача, планируется ход разработки прототипа экспертной системы, определяются:
1. необходимые ресурсы (время, люди, ЭВМ и т.д.);
2. источники знаний (книги, дополнительные эксперты, методики);
3. имеющиеся аналогичные экспертные системы;
4. цели (распространение опыта, автоматизация рутинных действий и др.);
5. классы решаемых задач и т.д.
Идентификация проблемы– знакомство и обучение коллектива разработчиков, а также создание неформальной формулировки проблемы.
Средняя продолжительность 1 - 2 недели.
Извлечение знаний
Происходит перенос компетентности экспертов на инженеров по знаниям с использованием различных методов:
1. анализ текстов;
3. экспертные игры;
7. наблюдение и другие.
Извлечение знаний– получение инженером по знаниям наиболее полного представления о предметной области и способах принятия решения в ней.
Этой статьей я начинаю серию публикаций, посвященных проблеме программирования искусственного интеллекта. Цель этого цикла - показать, каким образом (в смысле общих принципов) осуществляется программирование искусственного интеллекта.
Само понятие "искусственный интеллект" возникло где-то на заре вычислительной техники. Несмотря на почтенный возраст, термин этот не имеет точного определения и всегда понимался в интуитивном смысле. Обычно говорят, что к области искусственного интеллекта относятся те задачи, которые до сих пор человек решает лучше, чем компьютер. Таким образом, круг решаемых в рамках искусственного интеллекта проблем постоянно динамически изменяется. Например, еще несколько лет назад обучение ЭВМ игре в шахматы являлось прерогативой AI (от английского Artifical Intelligence - искусственный интеллект), но сегодня все больше специалистов считает, что игра в шахматы уже не является проблемой искусственного интеллекта. Сегодня главными проблемами, решаемыми в рамках AI, являются примерно следующие: построение экспертных систем, решение задач поиска, в которых полный перебор вариантов теоретически невозможен (в том числе - программирование игр), моделирование биологических форм, распознавание образов. Фундаментальные принципы решения всех этих задач были заложены еще в начале семидесятых, но, в связи с тем, что задачи AI очень ресурсоемки, настоящее развитие они получили только в наши дни.
Для решения задач AI еще в начале семидесятых годов были созданы два специфических языка программирования - Пролог (Prolog) и Лисп (LISP). Современный разработчик искусственного интеллекта должен свободно владеть каждым из них. Далее остановимся на самых характерных их особенностях.
Исторически Лисп более старый язык. Концепция, которую он представляет, называется функциональным программированием, она является прямым продолжением обычного алгоритмического подхода. Лисп-программа представляет собой функцию, результат вычисления которой - это результат работы программы, а аргументы, чаще всего - другие вызовы функций. В связи с объективными причинами в Лиспе принята бесскобочная запись при вызове функций, вызов любой функции осуществляется при помощи списка, первым элементом которого является название функции, а все остальные элементы представляют аргументы. Например, сложение двух чисел A и B может выглядеть так : (add A B), сложение трех чисел - так : (add A (add B C)). Самой важной особенностью Лиспа является то, что запись вида (add A B) может представлять из себя не только список, как вызов функции, но и список, как элемент данных, содержащий в себе три компоненты - add, A и B. Решение о том, следует ли использовать список как данные, или его необходимо интерпретировать, в рамках Лиспа может приниматься самой программой. Таким образом, программа получает возможность модифицировать собственный код, что чрезвычайно важно для приложений AI.
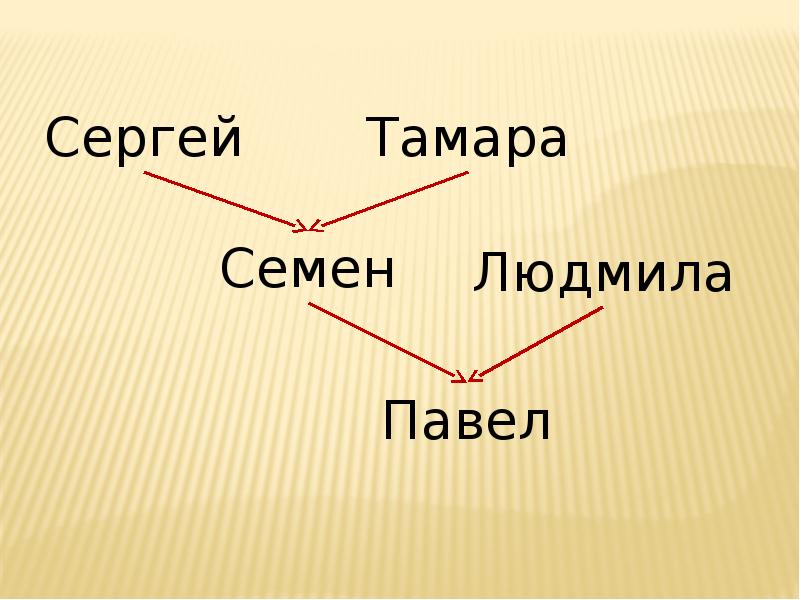
Пролог для меня более интересен, чем Лисп, поскольку использует подход к программированию, принципиально отличный от алгоритмического и называемый целевым или декларативным программированием. При алгоритмическом программировании мы задаем последовательность действий, которые должна выполнять программа, т.е. описываем, КАК она должна работать. При декларативном программировании мы описываем, ЧТО программа должна делать, а то, как будут осуществлены эти действия - дело Пролог-системы. Рассмотрим типичнейшую Пролог-задачу - определение, в каких родственных отношениях находятся те или иные люди. В качестве исходных выберем отношение родитель(X,Y), обозначающее, что X является родителем Y, и отношения мужчина(X) и женщина (X), обозначающие принадлежность лица к одному из полов. Тогда исходные данные для программы могут выглядеть примерно так.
мужчина(Сергей). женщина(Тамара). мужчина(Семен). женщина (Людмила). мужчина(Павел).
родитель(Сергей, Семен). родитель(Тамара, Семен). родитель(Семен, Павел).
Как можно видеть, это - небольшая база данных, естественно представляющая генеалогическое дерево. Каждое из выражений в ней является утверждением, в Прологе такие утверждения называют фактами. База может быть легко расширена.
Теперь введем выражение дед(X,Y), обозначающее, является ли X дедом Y. Мы используем два Прологовских символа - запятая в следующей записи обозначает логическое и, а символ :- обозначает если.
дед(X,Y):- родитель(X,Z), родитель(Z,Y),мужчина(X).
Эта условная запись является таким же элементом базы данных, как и факты, в Прологе такие элементы принято называть правилами.
На самом деле та Пролог-программа, которую мы написали, умеет делать очень многое (это наверняка удивит тех, кто до сих пор был знаком только с алгоритмическим программированием). После запуска ее на выполнение Пролог-система выдаст запрос на ввод вопроса. Для начала введем дед(X,Павел) (по-русски этот вопрос звучит так: "Кто дед Павла?"), система выдаст X=Сергей. Теперь спросим дед(Тамара, Павел) ("Является ли Тамара дедом Павла?"). Получим ответ no (нет). Можно спросить родитель(X,_) (так, как на Прологе _ обозначает, что значение этого элемента отношения для нас не важно, то данная запись по-русски звучит, как "Кто является чьим-либо родителем?"). Получим X=Сергей, X=Тамара, X=Семен, X=Людмила. Этим круг вопросов, которые можно задать нашей программе, далеко не исчерпывается.
Как видим, в задачах, связанных с заданием отношений между объектами, Пролог гораздо мощнее алгоритмических языков типа Паскаля или Си. Если добавить к этому, что база данных Пролога (содержащая факты и правила) может динамически изменяться во время выполнения самой же программой или пользователем, становится ясно, насколько полезен Пролог для разработки в области искусственного интеллекта.
Если читателя заинтересовали Лисп и Пролог, он может изучить их самостоятельно - языки очень просты. Я же в последующих публикациях не буду останавливаться на лингвистических проблемах, стараясь уделить внимание только фундаментальным методам программирования в области AI.
Вы можете изучить и скачать доклад-презентацию на тему Языки искусственного интеллекта. Презентация на заданную тему содержит 13 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас - поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!












Алан Тьюринг , основатель информатики, был одним из первых, кто принимал развитие искусственного интеллекта (ИИ) всерьез и знал, что в один прекрасный день машины смогут думать так же, как люди. Он предложил простой тест: если человек во время беседы не сможет отличить машину от человека, значит, машина достигла уровня интеллекта человека. Другими словами, если она может думать, как человек, значит, она может обрабатывать язык, как человек. Алан Тьюринг , основатель информатики, был одним из первых, кто принимал развитие искусственного интеллекта (ИИ) всерьез и знал, что в один прекрасный день машины смогут думать так же, как люди. Он предложил простой тест: если человек во время беседы не сможет отличить машину от человека, значит, машина достигла уровня интеллекта человека. Другими словами, если она может думать, как человек, значит, она может обрабатывать язык, как человек.
С появлением Siri компании Google и Cortana надеялись, что эра, о которой говорил Тьюринг, наступила, но пока обе программы способны распознавать и отвечать лишь на простые вопросы С появлением Siri компании Google и Cortana надеялись, что эра, о которой говорил Тьюринг, наступила, но пока обе программы способны распознавать и отвечать лишь на простые вопросы
Главными проблемами, решаемыми в рамках ИИ, являются: Главными проблемами, решаемыми в рамках ИИ, являются: построение экспертных систем, решение задач поиска, в которых полный перебор вариантов теоретически невозможен (в том числе - программирование игр), моделирование биологических форм, распознавание образов
Типы ии Искусственный интеллект узкой направленности Общий искусственный интеллект Искусственный суперинтеллект
Одним из самых ярких примеров обработки естественного языка является функция спонтанного перевода, запущенная Microsoft в Skype Одним из самых ярких примеров обработки естественного языка является функция спонтанного перевода, запущенная Microsoft в Skype
Языки программирования ии В начале семидесятых годов были созданы два специфических языка программирования – Пролог (Prolog) и Лисп (LISP).
Язык программирования LISP LISP был придуман Джоном Маккарти в 1958 году для решения задач нечислового характера. Долгое время LISP использовался исключительно узким кругом специалистов по искусственному интеллекту. Но, начиная с 80-х годов прошлого века, LISP начал набирать обороты и сейчас активно используется, например, в AutoCad и Emacs.
Пример программы на LISP Давайте напишем программу сложения: 2 + 3 Исходный код: (+ 2 3) После нажатия Enter выведется ответ: 5. Или пример посложнее: (2 + 2) * (11 - 1) Код: ( * ( + 2 2) ( - 11 1)) Вывод: 40
Язык программирования Пролог Этот язык логического программирования предназначен для представления и использования знаний о некоторой предметной области. Программы на этом языке состоят из некоторого множества отношений, а ее выполнение сводится к выводу нового отношения на основе заданных. В Прологе реализован декларативный подход, при котором достаточно описать задачу с помощью правил и утверждений относительно заданных объектов. Если это описание является достаточно точным, то ЭВМ может самостоятельно найти требуемое решение.
Пример программы на Prolog В качестве исходных выберем отношение родитель(X,Y), обозначающее, что X является родителем Y, и отношения мужчина(X) и женщина (X), обозначающие принадлежность лица к одному из полов. Тогда исходные данные для программы могут выглядеть примерно так. мужчина(Сергей). женщина(Тамара). мужчина(Семен). женщина (Людмила). мужчина(Павел). родитель(Сергей, Семен). родитель(Тамара, Семен). родитель(Семен, Павел). родитель(Людмила, Павел)
Теперь введем выражение дед(X,Y), обозначающее, является ли X дедом Y. Мы используем два Прологовских символа – запятая в следующей записи обозначает логическое И, а символ :- обозначает ЕСЛИ. Теперь введем выражение дед(X,Y), обозначающее, является ли X дедом Y. Мы используем два Прологовских символа – запятая в следующей записи обозначает логическое И, а символ :- обозначает ЕСЛИ. дед(X,Y):- родитель(X,Z),родитель(Z,Y),мужчина(X). После запуска ее на выполнение Пролог-система выдаст запрос на ввод вопроса. Для начала введем дед(X,Павел) (по-русски этот вопрос звучит так: "Кто дед Павла?"), система выдаст X=Сергей. Теперь спросим дед(Тамара, Павел) ("Является ли Тамара дедом Павла?"). Получим ответ no (нет).
Искусственный интеллект - это отрасль инженерии, которая, по сути, стремится сделать компьютеры способными мыслить разумно, так же, как думают разумные люди. ИИ начался в 1950-х годах, и с тех пор было сделано много разработок.
Искусственный интеллект революционизирует технологию, и он используется в различных секторах, таких как здравоохранение, бизнес, туристическая индустрия, социальные сети, образование и т. д.
Вот основные языки, наиболее часто используемые для создания проектов искусственного интеллекта:
Python занимает первое место в списке всех языков разработки AI из-за своей простоты. Синтаксисы, принадлежащие Python, очень просты и могут быть легко изучены. Поэтому многие алгоритмы искусственного интеллекта могут быть легко реализованы. Python занимает немного времени разработки по сравнению с другими языками, такими как Java, C ++ или Ruby. Python поддерживает объектно-ориентированные, функциональные стили и процедуры программирования. Есть много библиотек Python, которые облегчают наши задачи. Например: Numpy - это библиотека для python, которая помогает нам решать многие научные вычисления. Также есть Pybrain, который использует машинное обучение на Python.
R является одним из наиболее эффективных языков и сред для анализа и обработки данных в статистических целях. Используя R, мы можем легко создать хорошо спроектированный график качества математических символов и формул, где это уместно. Помимо общего языка, R имеет множество пакетов, таких как RODBC, Gmodels, Class и Tm, используемых в области машинного обучения. Эти пакеты облегчают реализацию алгоритмов машинного обучения для решения проблем, связанных с бизнесом.
Lisp - один из старейших языков и наиболее подходящий для развития ИИ. Он был изобретен Джоном Маккарти, отцом искусственного интеллекта в 1958 году. Он обладает способностью эффективно обрабатывать символическую информацию. Его цикл разработки позволяет проводить интерактивную оценку выражений и перекомпиляцию функций или файлов во время выполнения программы. За прошедшие годы благодаря достигнутому прогрессу многие из этих функций перешли на многие другие языки, что сказалось на уникальности Lisp.
Этот язык находится рядом с Lips'om, когда мы говорим о разработке в области ИИ. Предоставленные функции включают эффективное сопоставление моделей, структурирование дерева и автоматический откат. Все эти функции обеспечивают удивительно мощную и гибкую среду программирования. Пролог широко используется для работы над медицинскими проектами и для разработки экспертных систем искусственного интеллекта.
Java также можно считать хорошим выбором для развития искусственного интеллекта. Искусственный интеллект во многом связан с алгоритмами поиска, искусственными нейронными сетями и генетическим программированием. Java предлагает множество преимуществ: простота использования, простота отладки, пакетные сервисы, упрощенная работа с большими проектами, графическое представление данных и лучшее взаимодействие с пользователем. Он также включает в себя Swing и SWT (стандартный набор инструментов для виджетов). Эти инструменты делают графику и интерфейсы привлекательными и сложными.

Знать понемногу обо всё иногда (по крайней мере, для новичков, пытающихся сориентироваться в популярных технических направлениях) бывает полезнее, чем знать много о чём-то одном.
Многие люди думают, что немного знакомы с ИИ. Но эта область настолько молода и растёт так быстро, что прорывы совершаются чуть ли не каждый день. В этой научной области предстоит открыть настолько многое, что специалисты из других областей могут быстро влиться в исследования ИИ и достичь значимых результатов.
Эта статья — как раз для них. Я поставил себе целью создать короткий справочный материал, который позволит технически образованным людям быстро разобраться с терминологией и средствами, используемыми для разработки ИИ. Я надеюсь, что этот материал окажется полезным большинству интересующихся ИИ людей, не являющихся специалистами в этой области.
Введение
Искусственный интеллект (ИИ), машинное обучение и нейронные сети — термины, используемые для описания мощных технологий, базирующихся на машинном обучении, способных решить множество задач из реального мира.
В то время, как размышление, принятие решений и т.п. сравнительно со способностями человеческого мозга у машин далеки от идеала (не идеальны они, разумеется, и у людей), в недавнее время было сделано несколько важных открытий в области технологий ИИ и связанных с ними алгоритмов. Важную роль играет увеличивающееся количество доступных для обучения ИИ больших выборок разнообразных данных.
Область ИИ пересекается со многими другими областями, включая математику, статистику, теорию вероятностей, физику, обработку сигналов, машинное обучение, компьютерное зрение, психологию, лингвистику и науку о мозге. Вопросы, связанные с социальной ответственностью и этикой создания ИИ притягивают интересующихся людей, занимающихся философией.
Мотивация развития технологий ИИ состоит в том, что задачи, зависящие от множества переменных факторов, требуют очень сложных решений, которые трудны к пониманию и сложно алгоритмизируются вручную.

Обзор
Интеллект — способность воспринимать информацию и сохранять её в качестве знания для построения адаптивного поведения в среде или контексте
Это определение интеллекта из (англоязычной) Википедии может быть применено как к органическому мозгу, так и к машине. Наличие интеллекта не предполагает наличие сознания. Это — распространённое заблуждение, принесённое в мир писателями научной фантастики.
Обработка естественного языка и распознавание речи стали первыми примерами коммерческого использования машинного обучения. Вслед за ними появились задачи другие задачи автоматизации распознавания (текст, аудио, изображения, видео, лица и т.д.). Круг приложений этих технологий постоянно растёт и включает в себя беспилотные средства передвижения, медицинскую диагностику, компьютерные игры, поисковые движки, спам-фильтры, борьбу с преступностью, маркетинг, управление роботами, компьютерное зрение, перевозки, распознавание музыки и многое другое.
Как работает наш мозг

Но на этом всё не заканчивается. Каждый нейрон применяет функцию, или преобразование, к взвешенным входным сигналам перед тем, как проверить, достигнут ли порог его активации. Преобразование входного сигнала может быть линейным или нелинейным.
Изначально входные сигналы приходят из разнообразных источников: наших органов чувств, средств внутреннего отслеживания функционирования организма (уровня кислорода в крови, содержимого желудка и т.д.) и других. Один нейрон может получать сотни тысяч входных сигналов перед принятием решения о том, как следует реагировать.
Мышление (или обработка информации) и полученные в результате его инструкции, передаваемые нашим мышцам и другим органам являются результатом преобразования и передачи входных сигналов между нейронами из различных слоёв нейронной сети. Но нейронные сети в мозгу могут меняться и обновляться, включая изменения алгоритма взвешивания сигналов, передаваемых между нейронами. Это связано с обучением и накоплением опыта.
Эта модель человеческого мозга использовалась в качестве шаблона для воспроизведения возможностей мозга в компьютерной симуляции — искуственной нейронной сети.
Искусственные Нейронные Сети (ИНС)
Искусственные Нейронные Сети — это математические модели, созданные по аналогии с биологическими нейронными сетями. ИНС способны моделировать и обрабатывать нелинейные отношения между входными и выходными сигналами. Адаптивное взвешивание сигналов между искусственными нейронами достигается благодаря обучающемуся алгоритму, считывающему наблюдаемые данные и пытающемуся улучшить результаты их обработки.

Для улучшения работы ИНС применяются различные техники оптимизации. Оптимизация считается успешной, если ИНС может решать поставленную задачу за время, не превышающее установленные рамки (временные рамки, разумеется, варьируются от задачи к задаче).
ИНС моделируется с использованием нескольких слоёв нейронов. Структура этих слоёв называется архитектурой модели. Нейроны представляют собой отдельные вычислительные единицы, способные получать входные данные и применять к ним некоторую математическую функцию для определения того, стоит ли передавать эти данные дальше.
В простой трёхслойной модели первый слой является слоем ввода, за ним следует скрытый слой, а за ним — слой вывода. Каждый слой содержит не менее одного нейрона.
Архитектура, настройка и выбор алгоритмов обработки данных являются основными составляющими построения ИНС. Все эти компоненты определяют производительность и эффективность работы модели.
Модели часто характеризуются так называемой функцией активации. Она используется для преобразования взвешенных входных данных нейрона в его выходные данные (если нейрон решает передавать данные дальше, это называется его активацией). Существует множество различных преобразований, которые могут быть использованы в качестве функций активации.

Глубокое обучение
Обучение без учителя (unsupervised learning) — область, в которой методики глубокого обучения отлично себя показывают. Правильно настроенная ИНС способна автоматически определить основные черты входных данных (будь то текст, изображения или другие данные) и получить полезный результат их обработки. Без глубокого обучения поиск важной информации зачастую ложится на плечи программиста, разрабатывающего систему их обработки. Модель глубокого обучения же самостоятельно способна найти способ обработки данных, позволяющий извлекать из них полезную информацию. Когда система проходит обучение (то есть, находит тот самый способ извлекать из входных данных полезную информацию), требования к вычислительной мощности, памяти и энергии для поддержания работы модели сокращаются.
Глубокое обучение применяется для решения широкого круга задач и считается одной из инновационных ИИ-технологий. Существуют также другие виды обучения, такие как обучение с учителем (supervised learning) и обучение с частичным привлечением учителя(semi-supervised learning), которые отличаются введением дополнительного контроля человека за промежуточными результатами обучения нейронной сети обработке данных (помогающего определить, в правильном ли направлении движется система).
Заключение
Читайте также: