
Выберите нужный вариант закодированное сообщение получилось короче при использовании кода
Обновлено: 06.05.2024

Задание 4 № 1123
Закодируем последовательность букв: ГБАВАВГ — 0111101000100011. Теперь разобьём это представление на тройки справа налево и переведём полученный набор чисел сначала в десятичный код, затем в восьмеричный (в данном случае они совпадают):
0 111 101 000 100 011 — 7 5 0 4 3 (дописав к первому нулю два нуля, получим, что это 0, так как он стоит в начале кода, его можно отбросить).
Задание 4 № 1129
Закодируем последовательность букв: БАБВГВ — 10 00 10 010 101 010. Теперь разобьём это представление на четвёрки справа налево и переведём полученный набор чисел сначала в десятичный код, затем в шестнадцатеричный:
100 0100 1010 1010 (дописав к первой единицы нуль слева, получим, что это число 0100) —
4 4 10 10 — 44AA.
Задание 4 № 1130
Закодируем последовательность букв: АБГВГБ — 101101100101111. Теперь разобьём это представление на четверки справа налево и переведём полученный набор чисел сначала в десятичный код, затем в шестнадцатеричный:
101 1011 0010 1111 (дописав к первому числу нуль слева, получим, что это число 0101) — 5 11 2 15 — 5B2F.
Задание 4 № 1124
Закодируем последовательность букв: ВАГБААГВ — 1101001110100110. Теперь разобьём это представление на тройки справа налево и переведём полученный набор чисел сначала в десятичный код, затем в восьмеричный (в данном случае они совпадают):
1 101 001 110 100 110 для самой левой цифры 1 допишем два нуля слева, тогда получим
001 101 001 110 100 110— 1 5 1 6 4 6.
Задание 4 № 10379
Какова наименьшая возможная суммарная длина всех кодовых слов? Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование.
Перечислим возможные коды в порядке возрастания длины. Стоит сразу сказать, что любой код, начинающийся с 0, не подходит, так как код А - 0, поэтому смотрим только на те, что начинаются с 1.
1 - нельзя, Б, В начинаются с 1.
10 - нельзя из-за Б.
11 - нельзя из-за В.
111 - можно использовать, пусть это будет код Д.
100 - также можно использовать, но если мы его возьмём, то не будет больше кодов, которые можно будет взять, так как все коды, начинающиеся с 0, уже нельзя брать, а все коды, начинающиеся с 1 и имеющие длину больше трёх, начинаются с одной из этих строк: 100, 101, 110, 111.
Рассмотрели все коды с длинами от 1 до 3, поэтому теперь достаточно взять любые два подходящие кода длины 4. Например, 1000 и 1001.
В сумме длина кодов 1 + 3 + 3 + 3 + 4 + 4 = 18.
Задание 4 № 10406
Какова наименьшая возможная суммарная длина всех кодовых слов? Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование.
Перечислим возможные коды в порядке возрастания длины. Стоит сразу сказать, что любой код, начинающийся с 1, не подходит, так как код А - 1, поэтому смотрим только на те, что начинаются с 0.
0 - нельзя, Б, В начинаются с 0.
01 - нельзя из-за Б.
00 - нельзя из-за В.
000 - можно использовать, пусть это будет код Д.
011 - также можно использовать, но если мы его возьмём, то не будет больше кодов, которые можно будет взять, так как все коды, начинающиеся с 1, уже нельзя брать, а все коды, начинающиеся с 0 и имеющие длину больше трёх, начинаются с одной из этих строк: 011, 010, 001, 000.
Рассмотрели все коды с длинами от 1 до 3, поэтому теперь достаточно взять любые два подходящие кода длины 4. Например, 0111 и 0110.
В сумме длина кодов 1 + 3 + 3 + 3 + 4 + 4 = 18.
Задания Д8 № 6179
И — 000000, Г — 001110, Л — 110110.
Можно ли использовать одно из таких слов: 111110, 111000, 000110?
4) нет, не подходит ни одно из указанных выше слов
Проанализируем каждый вариант кодового слова. Первое слово: 111110 отличается от буквы Л только в одной позиции. Второе слово: 111000 отличается от любой буквы И, Г или Л не менее чем в трёх позициях. Третье слово: 000110 отличается от буквы Г только в одной позиции. Таким образом, в качестве кодового слова для буквы А можно использовать слово 111000.
Правильный ответ указан под номером 2.
Задания Д8 № 6224
П — 111111, А — 110001, Р — 001001.
Можно ли использовать одно из таких слов: 000001, 111001, 000111?
4) нет, не подходит ни одно из указанных выше слов
Проанализируем каждый вариант кодового слова. Первое слово: 000001 отличается от буквы А только в двух позициях. Второе слово: 111001 отличается от буквы А только в одной позиции. Третье слово: 000111 отличается от любой буквы П, А или Р не менее чем в трёх позициях. Таким образом, в качестве кодового слова для буквы К можно использовать слово 000111.
Правильный ответ указан под номером 3.
Задания Д8 № 8089
а) ни одно кодовое слово не является началом другого (это нужно, чтобы код допускал однозначное декодирование);
Какой код из приведённых ниже следует выбрать для кодирования букв А, Б, В и Г?
1) А:0, Б:10, В:110, Г:111
2) А:0, Б:10, В:01, Г:11
3) А:1, Б:01, В:011, Г:001
4) А:00, Б:01, В:10, Г:11
2 и 3 не подходят, так как в них встречаются пары кодов, один из которых является началом другого.
Задания Д8 № 5203
П — 11111, О — 11000, Р — 00100, Т — 00011.
Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях.
11011 11100 00011 11000 01110
00111 11100 11110 11000 00000
Задания Д8 № 5235
П — 00000, О — 00111, Р — 11011, Т — 11100.
Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях.
11011 10111 11101 00111 10001
10000 10111 11101 00111 00001
Задания Д8 № 4927
Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трех позициях.
4) не подходит ни одно из указанных выше слов
Пользуясь правилом "любые два слова из набора отличаются не менее чем в трех позициях" проверим все возможные варианты.
Число 11111 отличается от кодового слова 00111 только в двух позициях.
Число 11100 отличается от кодового слова 00000 — в трех позициях, от 00111 — в четырех позициях, 11011 — в трех позициях.
Правильный вариант ответа второй.
Задания Д8 № 4968
Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трех позициях.
4) не подходит ни одно из указанных слов
Пользуясь правилом "любые два слова из набора отличаются не менее чем в трех позициях" проверим все возможные варианты.
Число 00000 отличается от кодового слова 11000 только в двух позициях.
Число 11100 отличается от кодового слова 00100 только в двух позициях.
Число 00011 отличается от кодового слова 11111 в трех позициях, от 11000 — в четырех позициях, от 00100 — в трех позициях.
Правильный вариант ответа третий.
Задания Д8 № 5047
А — 0, И — 00, К — 10, О — 110, Т — 111.
Среди приведённых ниже слов укажите такое, код которого можно декодировать только одним способом. Если таких слов несколько, укажите первое по алфавиту.
Закодируем каждое слово.
Слово КАА можно декодировать как КИ
Слово ИКОТА можно декодировать как ААКОТА
Слово КОТ никак нельзя декодировать по-другому.
Следовательно, ответ 3.
Верно ли я понимаю, что код в условии противоречит правилу Фано — код A (0) является началом кода И (00)?
Условие Фано действительно не соблюдается.
Задания Д8 № 5079
А — 0, И — 00, К — 10, О — 110, Т — 111.
Среди приведённых ниже слов укажите такое, код которого можно декодировать только одним способом. Если таких слов несколько, укажите первое по алфавиту.
Закодируем каждое слово.
Слово КИОТ можно декодировать как КAA.
Слово ТААК можно декодировать как TИ.
Слово КООТ никак нельзя декодировать по-другому.
Следовательно, ответ 2.
Задание 4 № 18617
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Буква Т повторяется в слове АТТЕСТАТ чаще всего, поэтому закодируем её кодовым словом 0. Следующую букву невозможно закодировать кодовым словом длиной 2, так как будет невозможно закодировать другие буквы так, чтобы выполнялось условие Фано. Букву А закодируем кодовым словом длиной 3, например, 111. Буквы Е и В закодируем кодовыми словами 1100 и 1101. Таким образом, в слове АТТЕСТАТ буква Т кодируется кодовым словом длиной 1, буквы А и С кодируются кодовыми словами длиной 3 и буква Е кодируется кодовым словом длиной 4, тогда количество двоичных знаков, которые потребуются для кодирования слова АТТЕСТАТ, равно 4 · 1 + 2 · 3 + 3 + 4 = 17.

Внимание! Все тесты в этом разделе разработаны пользователями сайта для собственного использования. Администрация сайта не проверяет возможные ошибки, которые могут встретиться в тестах.
Список вопросов теста
Вопрос 1
Вопрос 2
Вопрос 3
Вопрос 4
Вопрос 5
Сколько символов можно закодировать с помощью двоичного кода, используя кодовые слова различной длины — от 1 до 5 знаков?
Вопрос 6
Вопрос 7
Вопрос 8
Разведчик передал в штаб радиограмму, в которой встречаются только буквы Т, А, У, Ж, Х. Каждая буква закодирована с помощью азбуки Морзе. Разделителей между кодами букв нет. Запишите в ответе переданную последовательность букв.
Вопрос 9
Разведчик передал в штаб радиограмму, в которой встречаются только буквы А, Д, Ж, Л, Т. Каждая буква закодирована с помощью азбуки Морзе. Разделителей между кодами букв нет. Запишите в ответе переданную последовательность букв.

Задания для учащихся 11 классов. Материалы для подготовки к ЕГЭ по информатике.
Передача информации. Выбор кода
1. Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0, для буквы К — кодовое слово 10. Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
Найдём наиболее короткие представления для всех букв. Кодовые слова 01 и 00 использовать нельзя, поскольку тогда нарушается условие Фано. Используем, например, для буквы Л кодовое слово 11. Тогда для четвёртой буквы нельзя подобрать кодовое слово, не нарушая условие Фано. Следовательно, для оставшихся двух букв нужно использовать трёхзначные кодовые слова. Закодируем буквы Л и М кодовыми словами 110 и 111. Тогда суммарная длина всех четырёх кодовых слов равна 1 + 2 + 3 + 3 = 9.
2. Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: А — 1; Б — 0100; В — 000; Г — 011; Д — 0101. Требуется сократить для одной из букв длину кодового слова так, чтобы код по-прежнему можно было декодировать однозначно. Коды остальных букв меняться не должны. Каким из указанных способов это можно сделать?
1) для буквы Г — 11
2) для буквы В — 00
3) для буквы Г — 01
4) это невозможно
Для однозначного декодирования получившееся в результате сокращения кодовое слово не должно быть началом никакого другого. Первый вариант ответа не подходит, поскольку код буквы А является началом кода буквы Г. Второй вариант ответа подходит. Третий вариант ответа не подходит, т. к. в таком случае код буквы Г является началом кода буквы Д.
Правильный ответ указан под номером: 2.
3. Для кодирования некоторой последовательности, состоящей из букв И, К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0, для буквы К – кодовое слово 10. Какова наименьшая возможная суммарная длина всех пяти кодовых слов?
Нельзя использовать кодовые слова, которые начинаются с 0 или с 10. 11 также не можем использовать, поскольку тогда мы больше не сможем взять никакое другое кодовое слово, а нам их нужно пять. Поэтому берём трёхзначное 110. 111 опять же не можем использовать, потому что понадобиться ещё одно кодовое слово, а вместе с этим не останется больше свободных. Теперь осталось взять всего два слова и это будут 1110 и 1111. Итого имеем 0, 10, 110, 1110 и 1111 — 14 символов.
4. Для кодирования некоторой последовательности, состоящей из букв И, К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Л использовали кодовое слово 1, для буквы М – кодовое слово 01. Какова наименьшая возможная суммарная длина всех пяти кодовых слов?
Условие Фано — никакое кодовое слово не может быть началом другого кодового слова. Так как уже имеется кодовое слово 1, то никакое другое не может начинаться с 1. Только с 0. Также не может начинаться с 01, поскольку у нас уже есть 01. То есть любое новое кодовое слово будет начинаться с 00. Но это не может быть 00, так как иначе мы не сможем взять больше ни одного кодового слова, поскольку все более длинные слова начинаются либо с 1, либо с 00, либо с 01. Мы можем взять либо 000, либо 001. Но не оба сразу, поскольку опять же в таком случае мы больше не сможем взять ни одного нового кода. Тогда возьмём 001. И так как нам осталось всего два кода, то можем взять 0000 и 0001. Итого имеем: 1, 01, 001, 0000, 0001. Всего 14 символов.
Укажите кратчайшее кодовое слово для буквы С, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Буква С не может кодироваться строкой, которая начинается с 0, поскольку О имеет код 0.
Буква С не может кодироваться как 1, так как кодирование буквы Т начинается с 1.
Буква С не может кодироваться как 10, так как кодирование буквы П начинается с 10.
Буква С не может кодироваться как 11, так как кодирование буквы Т начинается с 11.
Буква С может кодироваться как 101 − это наименьшее возможное значение.
A – 1, B – 010, C – 000.
Укажите кратчайшее кодовое слово для буквы E, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Буква E не может кодироваться как 0, так как кодирование буквы B начинается с 0.
Буква E не может кодироваться как 1, так как это кодирование буквы А.
Буква E не может кодироваться как 10 и 11 − так как кодирование буквы А — 1.
Буква E не может кодироваться как 01 и 00 — так как кодирование буквы B начинается с 01, а кодирование буквы C с 00. Буква E может кодироваться как 001 — это наименьшее возможное значение.
любые два слова из набора отличаются не менее чем в трёх позициях.
Код Т начинается с 1 и заканчивается на 0. Код С также начинается с 1 и заканчивается на 0. Поэтому для того, чтобы коды отличались не менее чем в трёх позициях, нужно, чтобы в остальных позициях все цифры были разные. И раз у С в середине 100, то у Т должно быть 011. Итого получили код 10110.
любые два слова из набора отличаются не менее чем в трёх позициях.
Код А начинается с 1 и заканчивается на 0. Код Г также начинается с 1 и заканчивается на 0. Поэтому для того, чтобы коды отличались не менее чем в трёх позициях, нужно, чтобы в остальных позициях все цифры были разные. И раз у Г в середине 011, то А Т должно быть 100. Итого получили код 11000.
Какова наименьшая возможная суммарная длина всех кодовых слов? Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование.
Перечислим возможные коды в порядке возрастания длины. Стоит сразу сказать, что любой код, начинающийся с 0, не подходит, так как код А - 0, поэтому смотрим только на те, что начинаются с 1.
1 - нельзя, Б, В начинаются с 1.
10 - нельзя из-за Б.
11 - нельзя из-за В.
111 - можно использовать, пусть это будет код Д.
100 - также можно использовать, но если мы его возьмём, то не будет больше кодов, которые можно будет взять, так как все коды, начинающиеся с 0, уже нельзя брать, а все коды, начинающиеся с 1 и имеющие длину больше трёх, начинаются с одной из этих строк: 100, 101, 110, 111.
Рассмотрели все коды с длинами от 1 до 3, поэтому теперь достаточно взять любые два подходящие кода длины 4. Например, 1000 и 1001.
В сумме длина кодов 1 + 3 + 3 + 3 + 4 + 4 = 18.
Какова наименьшая возможная суммарная длина всех кодовых слов? Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование.
Перечислим возможные коды в порядке возрастания длины. Стоит сразу сказать, что любой код, начинающийся с 1, не подходит, так как код А - 1, поэтому смотрим только на те, что начинаются с 0.
0 - нельзя, Б, В начинаются с 0.
01 - нельзя из-за Б.
00 - нельзя из-за В.
000 - можно использовать, пусть это будет код Д.
011 - также можно использовать, но если мы его возьмём, то не будет больше кодов, которые можно будет взять, так как все коды, начинающиеся с 1, уже нельзя брать, а все коды, начинающиеся с 0 и имеющие длину больше трёх, начинаются с одной из этих строк: 011, 010, 001, 000.
Рассмотрели все коды с длинами от 1 до 3, поэтому теперь достаточно взять любые два подходящие кода длины 4. Например, 0111 и 0110.
В сумме длина кодов 1 + 3 + 3 + 3 + 4 + 4 = 18.
11. Для кодирования некоторой последовательности, состоящей из букв А, Б, В и Г, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В используются такие кодовые слова: А — 000, Б — 1, В — 011.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Код не может начинаться с 1, так как Б − 1.
0 не подойдёт, так как А и В начинаются с 0.
Двоичные коды 00 или 01 не подходят, поскольку А и В — 000 и 011.
010 и 001 подойдут, так как не конфликтуют ни с каким другим уже имеющимся кодом, из них 001 меньше.
12. Для кодирования некоторой последовательности, состоящей из букв А, Б, В и Г, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В используются такие кодовые слова: А — 010, Б — 1, В — 011.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Код не может начинаться с 1, так как Б − 1.
0 не подойдёт, так как А и В начинаются с 0.
00 же не включает в себя никакой из кодов и также не является подстрокой какого-либо кода, поэтому подойдёт.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Рассмотрим варианты для буквы Г, начиная с самого короткого.
1) Г=1: код буквы Г является началом кода буквы Б — 110, поэтому этот вариант не подходит.
2) Если код Г=01, то условие Фано нарушается, поскольку тогда код буквы А является началом кода буквы Г.
3) Если код Г=101, то условие Фано не нарушается. Данное кодовое слово является кратчайшим для буквы Г.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование.
Заметим, что для алфавита из трёх букв, код с наименьшей суммарной длиной кодовых слов, удовлетворяющий условию Фано имел бы длину 1 + 2 + 2 = 5. Для алфавита из четырёх букв: 1 + 2 + 3 + 3 = 9. Аналогично можно получить минимальную длину суммарную длину кодовых слов для алфавита, содержащего произвольное число символов.
Удостоверимся, что, используя кодовые слова, приведённые в условии можно построить код, удовлетворяющий условию Фано и имеющий наименьшую суммарную длину. Будем использовать для буквы D кодовое слово 1000, для буквы E кодовое слово 10010, для буквы F 10011.
Суммарная длина такого кода 1 + 2 + 3 + 4 + 5 + 5 = 20.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование.
Для нахождения кодовых слов будем использовать двоичное дерево, в котором от каждого узла отходит две ветви, соответствующие выбору следующей цифры кода. Буквы будем размещать на конечных узлах дерева — листьях. Условие Фано выполняется, поскольку при проходе от корня дерева к букве в середине пути не встречается других букв.
Пример дерева, обеспечивающего минимальную сумму длин всех шести кодов изображено на рисунке.

Суммарная длина такого кода 1 + 2 + 3 + 4 + 5 + 5 = 20.
16. Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы А использовали кодовое слово 0; для буквы Б – кодовое слово 10. Какова наименьшая возможная сумма длин всех шести кодовых слов?
Для нахождения кодовых слов будем использовать двоичное дерево, в котором от каждого узла отходит две ветви, соответствующие выбору следующей цифры кода. Буквы будем размещать на конечных узлах дерева — листьях. Условие Фано выполняется, поскольку при проходе от корня дерева к букве в середине пути не встречается других букв.
Пример дерева, обеспечивающего минимальную сумму длин всех шести кодов изображено на рисунке.

Суммарная длина такого кода 1 + 2 + 4 + 4 + 4 + 4 = 19.
17. Для кодирования растрового рисунка, напечатанного с использованием шести красок, применили неравномерный двоичный код. Для кодирования цветов используются кодовые слова.

procedure preob(var a,b,n:integer; var se:string);
begin
repeat
b:=a mod n;
a:=a div n;
str(b,se);
s+=se;
until (a end.
Пример ввода:
Домашняя работа на завтра.
2
Пример вывода:
11000100-11101110-11101100-11100000-11111000-11101101-11111111-11111111-100000-11110000-11100000-11100001-11101110-11110010-11100000-100000-11101101-11100000-100000-11100111-11100000-11100010-11110010-11110000-11100000-101110-
1. Основные понятия
Закодировать текст – значит сопоставить ему другой текст. Кодирование применяется при передаче данных – для того, чтобы зашифровать текст от посторонних, чтобы сделать передачу данных более надежной, потому что канал передачи данных может передавать только ограниченный набор символов (например, – только два символа, 0 и 1) и по другим причинам.
При кодировании заранее определяют алфавит, в котором записаны исходные тексты (исходный алфавит) и алфавит, в котором записаны закодированные тексты (коды), этот алфавит называется кодовым алфавитом. В качестве кодового алфавита часто используют двоичный алфавит, состоящий из двух символов (битов) 0 и 1. Слова в двоичном алфавите иногда называют битовыми последовательностями.
2. Побуквенное кодирование
Пример 1. Исходный алфавит – алфавит русских букв, строчные и прописные буквы не различаются. Размер алфавита – 33 символа.
Кодовый алфавит – алфавит десятичных цифр. Размер алфавита – 10 символов.
Применяется побуквенное кодирование по следующему правилу: буква кодируется ее номером в алфавите: код буквы А – 1; буквы Я – 33 и т.д.
Тогда код слова АББА – это 1221.
Внимание: Последовательность 1221 может означать не только АББА, но и КУ (К – 12-я буква в алфавите, а У – 21-я буква). Про такой код говорят, что он НЕ допускает однозначного декодирования
Пример 2. Исходный и кодовый алфавиты – те же, что в примере 1. Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А – 01, код Б – 02 и т.д.
В этом случае кодом текста АББА будет 01020201. И расшифровать этот код можно только одним способом. Для расшифровки достаточно разбить кодовый текст 01020201 на двойки: 01 02 02 01 и для каждой двойки определить соответствующую ей букву.
Такой способ кодирования называется равномерным. Равномерное кодирование всегда допускает однозначное декодирование.
Далее рассматривается только побуквенное кодирование
3. Неравномерное кодирование
Равномерное кодирование удобно для декодирования. Однако часто применяют и неравномерные коды, т.е. коды с различной длиной кодовых слов. Это полезно, когда в исходном тексте разные буквы встречаются с разной частотой. Тогда часто встречающиеся символы стоит кодировать более короткими словами, а редкие – более длинными. Из примера 1 видно, что (в отличие от равномерных кодов!) не все неравномерные коды допускают однозначное декодирование.
Есть простое условие, при выполнении которого неравномерный код допускает однозначное декодирование.
Код называется префиксным, если в нем нет ни одного кодового слова, которое было бы началом (по-научному, – префиксом) другого кодового слова.
Код из примера 1 – НЕ префиксный, так как, например, код буквы А (т.е. кодовое слово 1) – префикс кода буквы К (т.е. кодового слова 12, префикс выделен жирным шрифтом).
Код из примера 2 (и любой другой равномерный код) – префиксный: никакое слово не может быть началом слова той же длины.
Пример 3. Пусть исходный алфавит включает 9 символов: А, Л, М, О, П, Р, У, Ы, -. Кодовый алфавит – двоичный. Кодовые слова:
Кодовые слова выписаны в алфавитном порядке. Видно, что ни одно из них не является началом другого. Это можно проиллюстрировать рисунком
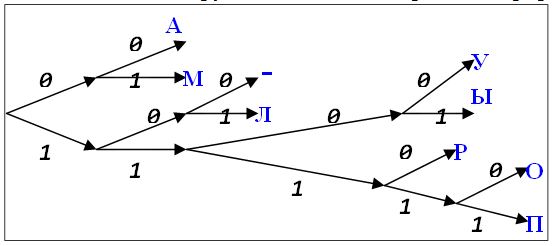
На рисунке изображено бинарное дерево. Его корень расположен слева. Из каждого внутреннего узла выходит два ребра. Верхнее ребро имеет пометку 0, нижнее – пометку 1. Таким образом, каждому узлу соответствует слово в двоичном алфавите. Если слово X является началом (префиксом) слова Y, то узел, соответствующий слову X, находится на пути из корня в узел, соответствующий слову Y. Наши кодовые слова находятся в листьях дерева. Поэтому ни одно из них не является началом другого.
Теорема (условие Фано). Любой префиксный код (а не только равномерный) допускает однозначное декодирование.
Разбор примера (вместо доказательства). Рассмотрим закодированный текст, полученный с помощью кода из примера 3:
Будем его декодировать таким способом. Двигаемся слева направо, пока не обнаружим код какой-то буквы. 0 – не кодовое слово, а 01 – код буквы М.
0100010010001110110100100111000011100
Далее таким же образом находим следующее кодовое слово 00 – код буквы А.
Доведите расшифровку текста до конца самостоятельно. Убедитесь, что он расшифровывается (декодируется) однозначно.
Замечание. В расшифрованном тексте 14 букв. Т.к. в алфавите 9 букв, то при равномерном двоичном кодировании пришлось бы использовать кодовые слова длины 4. Таким образом, при равномерном кодировании закодированный текст имел бы длину 56 символов – в полтора раза больше, чем в нашем примере (у нас 37 символов).
4. Как все это повторять. Задачи на понимание
Знание приведенного выше материала достаточно для решения задачи 5 из демо-варианта и близких к ней (см. здесь). Повторять (учить) этот материал стоит в том порядке, в котором он изложен. При этом нужно решать простые задачи – до тех пор, пока не будет достигнуто полное понимание. Ниже приведены возможные типы таких задач. Опытные учителя легко придумают (или подберут) конкретные задачи таких типов. Если будут вопросы – пишите.
1) Понятие побуквенного кодирования.
Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Закодировать заданный текст в алфавите Ф. Коды могут быть с использованием разных кодовых алфавитов, равномерные и неравномерные.
2) Префиксные неравномерные коды.
2.1) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Построить дерево кода (см. рис.1) и убедиться, что код – префиксный.
2.2) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Декодировать (анализом слева направо) данный текст в кодовом алфавите.
2.3) Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Определить, является ли данный код префиксным, или нет. В качестве примеров полезно приводить:
2.4) Решать задачи для самостоятельного решения, например, отсюда
Читайте также: