
Сообщение rpo что это
Обновлено: 04.07.2024
Показатели точки восстановления (RPO — Recovery Point Objective) и времени восстановления (RTO — Recovery Time Objective) позволяют организации узнать, какой объем данных она может потерять и как долго её сервисы могут быть недоступны — это ключевые элементы плана резервного копирования и плана аварийного восстановления.
Важно рассмотреть каждый показатель, их роль, способы их вычисления и финансовые последствия, а также способы их включения в различные планы обеспечения устойчивости.
Что такое RTO?
Показатель времени восстановления (RTO) определяет количество времени с момента наступления разрушительного события до момента, когда затронутые ресурсы должны быть полностью работоспособны и готовы поддерживать цели организации.
Когда ресурс выходит из строя, может потребоваться несколько действий, например, замена поврежденных компонентов, перепрограммирование и тестирование, прежде чем ресурс будет снова введен в эксплуатацию и начнется обычный режим работы. Существует обратная зависимость между временем восстановления и затратами, необходимыми для поддержки восстановления. В частности, чем короче RTO по времени, тем больше затраты на восстановление, и наоборот. Поэтому очень важно, чтобы при определении значений RTO участвовали руководители бизнес-подразделений. Они могут захотеть, например, чтобы целевое время восстановления составляло 30 минут, но затраты на достижение этой цели могут оказаться непомерно высокими.

Что такое RPO?
Показатель точки восстановления (RPO) особенно важен, когда речь идет о резервном копировании и восстановлении данных. Организациям — например, банкам, компаниям выпускающим кредитные карты — которые проводят много операций в течение дня, вероятно, потребуется более частое резервное копирование, почти в режиме реального времени, чтобы иметь в наличии самые актуальные критические данные для своих конкретных нужд, доступные для будущих операций. Это означает, что данные не должны сильно устареть с момента последнего резервного копирования, то есть данные должны быть как можно более актуальными. В этом и есть суть RPO, чтобы резервные копии данных были как можно более актуальными.
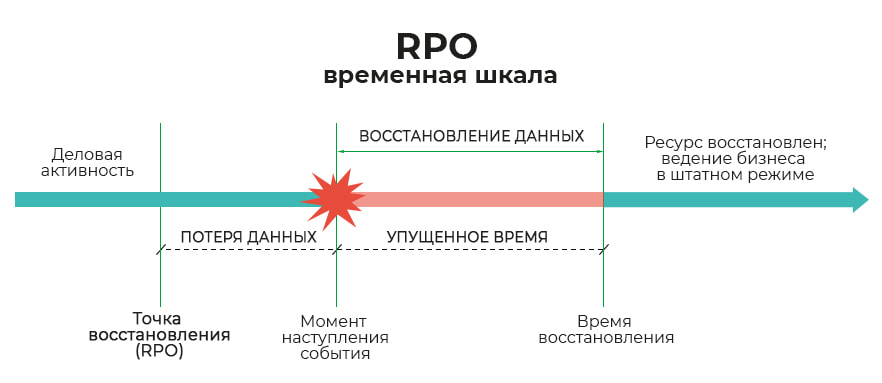
И здесь мы видим обратную зависимость между значением RPO и затратами на его достижение. Очень короткое RPO, например, от 10 до 30 секунд, означает, что резервное копирование данных должно выполняться очень часто, что требует использования высокоскоростных технологий резервного копирования, таких как зеркалирование или репликация данных, особенно если резервные копии хранятся вне площадки в облаке или другом месте. Добавьте к этому пропускную способность сети, необходимую для передачи больших объемов данных, и затраты могут быть значительными для достижения требуемой доступности данных.
Основные сходства и различия
Оба показателя являются важными элементами, используемыми в планах резервного копирования и восстановления данных. В идеале оба показателя должны быть ключевыми элементами резервного копирования и восстановления, чтобы обеспечить доступность критически важных данных и систем в случае необходимости, особенно после разрушительного события.
Кроме случаев их использования в планах восстановления, на практике они совершенно разные. RTO назначаются после наступления события. RPO используются до наступления события. Впрочем, когда эти два показателя связаны между собой, короткий RTO обычно требует столь же короткого RPO, особенно если речь идет о защите данных. Если мы рассматриваем только резервное копирование и восстановление систем, значения RTO может быть достаточно для определения того, как будет происходить восстановление. Однако если восстанавливаемая система также работает с критическими данными, то обе метрики должны быть согласованы.
Расчет RPO и RTO
Анализ воздействия на бизнес проводится для определения соответствующих значений RTO и RPO. Анализ рисков выявляет критически важные бизнес-процессы и определяет технологии, людей и объекты, необходимые для обеспечения непрерывности бизнеса. Он также может определить финансовые последствия — например, потерю доходов, наложение штрафов — вызванные сбоем.
На основе данных, полученных от руководителей бизнес-подразделений и высшего руководства, определяются числовые значения, которые представляют собой наилучшие сценарии восстановления после сбоев с точки зрения бизнеса. В настоящее время для расчета значений RTO/RPO не существует математических формул. Это исключительно числовые значения времени. Например, RTO для файлов транзакций с менее критическими данными может составлять 24 часа, а также может поддерживать использование оборудования для хранения резервных копий на магнитной ленте.
Как упоминалось ранее, по мере уменьшения численных значений RTO/RPO, затраты на достижение этих показателей, скорее всего, возрастут. Единственный способ определить истинную стоимость — это сначала определить желаемые значения RTO/RPO, а затем провести исследование, чтобы определить, что необходимо для достижения этих показателей, если произойдет сбой. Затем может потребоваться проинформировать руководителей бизнес-подразделений и высшее руководство о дополнительных инвестициях.
Именно здесь могут возникнуть потенциальные конфликты, поскольку если руководство не хочет тратить дополнительные средства для достижения указанных им желаемых показателей, оно должно понимать, что такое решение может повлечь за собой дополнительные риски в случае возникновения сбоев. В идеале, руководство должно быть осведомлено о потенциальных финансовых проблемах и других последствиях события — например, ущерб репутации — до того, как оно примет решение.
РПО – это оригинальный цифровой код, который состоит из 14 цифр и предназначается для отслеживания любой разновидности почтового отделения. Сокращенно подобный термин обозначает вид регистрируемого отправления. Также другими словами все это принято называть и специальным почтовым идентификатором.
Что обозначает РПО на современной почте?
РПО используется клиентами современной почты для отслеживания месторасположения собственного почтового отправления. Код используется только для внутренних разновидностей посылок. Он назначается каждому без исключения отправителю при непосредственном отправлении собственной посылке. Дополнительно он в обязательном порядке обозначается и в соответствующем чеке.
При отслеживании бандероли код вводится без пробелов и всевозможных скобок. А вот в ситуации, когда речь идет именно о международной разновидности почтового отправления, тогда в коде присутствуют не только цифры, но и соответственно, наиболее разнообразные буквенные символы. В этой ситуации, буквы рекомендуется вводить только на латинице. Дополнительно там не должны присутствовать всевозможные пробелы, а вот сами буквы должны быть только заглавными.

Вот пример текста из квитанции где расположен наш номер:
- Прием
- Внутренняя почта
- Население, Наличные рубли
- Ценная посылка
- Квитанция № 51226
- 30802215511760
- Кому:Число 30802215511760 является нашим почтовым идентификатором.
Пример международного почтового идентификатора:
RA461352295RU. Буквы вводятся на латинице, причём только заглавные, без пробелов.
Зачем необходим идентификатор или код?
Почтовый идентификатор – один из самых полезных помощников в последнее время. Не так давно почта государства перешла на совершенно новые, а также международного варианта стандарты. Поэтому обслуживание многочисленных клиентов стало еще качественнее. Все это подразумевает под собой значительное улучшение качественности сервиса, а также автоматизацию, как и компьютеризацию огромнейшей численности действий.
В последнее время почта стала использовать и подобный достаточно новенький для многих граждан государства термин, как специальный идентификатор. Благодаря его применению имеется возможность не просто отследить полностью все существующие пункты, которые встречаются по пути конкретного отправления, но и непосредственно сохранять информацию в соответствующей базе.
Все это в определенной степени облегчает сам процесс поиска отправлений, которые неожиданно были утеряны. Дополнительно почтовый идентификатор способен помочь отправителю и в непосредственном своевременном получении любой бандероли. В определенной степени возможно и осуществление контроля за самим процессом доставки.
Где его можно обнаружить?
Внутригосударственный код представляется под видом 14 цифр. По такой разновидности номера каждый человек может определить то, где именно на данный момент находится конкретная посылка. Первоначальные 6 цифр здесь обозначает именно конкретный почтовый индекс.
В ситуации, когда отправителем даже был обозначен совершенно иной адрес, идентификатор позволяет без малейших проблем определить конкретный пункт, где была осуществлена отправка самой посылки. Подобна разновидность информации, в действительности часто бывает достаточно полезной. Первоначально это касается тех ситуаций, когда нужно срочно найти конкретного отправителя. Ведь иногда он может по определенным причинам просто скрываться от адресата.
В обязательном порядке здесь необходимо отметить и факт того, что аналогичного вида номера могут быть присвоены только тем посылкам, которые являются регистрируемыми. Естественно, первоначально сюда стоит отнести следующие варианты:
- Заказные бандероли.
- Заказные письма.
- Ценные бандероли.
- Письма с наличием объявленной ценности.
- EMS-отправление и посылки.
- Международные посылки.
- Мелкие пакеты и т.д.
Подобного вида отправления можно отследить в любой требующийся момент. Вследствие этого можно максимально точно узнать факт того, кому конкретно и когда было вручено определенное отправление. А вот обычному письму подобный код вообще не присваивается. Поэтому узнать какую-то информацию о нем, после непосредственной отправки, в дальнейшем просто невозможно.
Вышеобозначенную характеристику в обязательном порядке необходимо учитывать при непосредственной отправке какого-то достаточно важного письма. Естественно, все это касается и наиболее разнообразных значимых документов. Ведь при отправке подобного письма обычным вариантом, существует риск потери, как говорится навсегда.
Вне зависимости от того, что регистрирующиеся отправления могут обойтись в не слишком маленькую сумму, в определенных ситуациях все-таки стоит переплатить. Ведь здесь предлагается самая настоящая гарантийная доставка. С эти все понятно. Но, каким образом можно узнать этот самый код? В действительности, здесь нет ничего сложного. Его всегда можно посмотреть в собственной квитанции.
-
RPO (recovery point objective) – допустимая потеря данных. Любая информационная система должна обеспечивать (внутренними ли средствами, или сторонними) защиту своих данных от потери выше приемлемого уровня.

- Точкой-событием отмечается сбой в работе системы
- Левее этой точки (то есть в прошлое) отмечается целевое значение RPO
- Правее (то есть в будущем) отмечается целевое значение RTO
Ясно, что все системы в компании работают не просто так, а для различных нужд/целей. Сама же компания зарабатывает (и тратит) деньги. В случае сбоя системы компания, очевидно, деньги теряет. Показатели RTO и RPO – то, что говорит о приемлемых размерах этих потерь.
Поэтому в график вводится второе измерение – финансовое (вот они, деньги – $):

Из такого графика уже видно, что стоимость простоя сервиса растет со временем: чем дольше не работает система, тем больше денег теряет компания.
Тоже самое и со стоимостью потерь данных: чем больше мы их (в исторической перспективе) теряем, тем дороже такая потеря обойдется компании. И да, эти графики в живой природе не симметричны.
Как правило, эти стоимости меняются не линейно, что отражено на картинке. Чаще всего наступает момент, когда стоимость потери начинает резко возрастать – отсюда и те самые печальные истории, когда компании теряли так много от сбоя системы, что некоторые даже не смогли вернуться в бизнес.
Чтобы защититься от таких проблем, необходимо внедрить систему, которая будет обеспечивать защиту от потерь данных и восстановление после сбоев. Такие системы имеют свои стоимости, и, значит, их тоже можно отразить на графике (нарисуем их синим):

Как видно из графика, чем меньше показатели RPO и RTO при потере данных, чем меньшее время простоя сервиса обеспечивает решение по защите, тем дороже такая защита стоит.
Определим точки безубыточности решения по защите
И тут мы наблюдаем пересечение кривых на графике – я отметил эти точки зелеными стрелками. Это так называемые точки безубыточности для системы защиты и для защищаемой информационной системы. Отдаляясь от данной точки, мы получаем дорогую систему защиты, стоимость которой превышает стоимость потери/простоя, либо наоборот – дешевую систему защиты, но не обеспечивающую приемлемый уровень потерь.
Как кажется, вывод напрашивается сам собой: именно ориентируясь на точки безубыточности, и надо подбирать системы, которые обеспечат нам необходимую защиту.
К тому же, как правило, ищется решение по защите не одной конкретной информационной системы (ИС), а группы (или вообще всех) инфосистем компании (то есть всей инфраструктуры). При этом каждое такое решение, скорее всего, будет иметь свои графики зависимостей стоимости простоя/потери данных от времени.

Получается, что наши точки безубыточности – уже не точки, а области:
Если мы рассмотрим нашу инфраструктуру более пристально и начнем строить графики для каждой ИС, то мы увидим интересную тенденцию — системы группируются со схожими. Об этом ниже.
Рассматриваем различные классы решений
На схеме ниже видно, какой примерно класс решения в зависимости от целевых RTO/RPO рекомендуется выбирать.

Конечно, на картинке всё изображено достаточно схематично. На самом деле нет четких границ между типами решений, как и точных значений в виде точек.
Например, сейчас многие решения по резервному копированию используют технологию запуска сервиса из резервной копии. Время обеспечения доступности при использовании такой технологии — в среднем ~2-5 минут на одну ВМ. И такие показатели находятся в рамках RTO для реплик или даже кластеров.
Немного о кластерах
Кластеры, как и DR-решения (и вообще практически все решения по защите от потерь данных или восстановлению работоспособности) имеют свои значения по скорости восстановления данных и объемам данных, которые теряются. Потому они также связаны со своими показателями RTO/RPO.
Говоря, например, про HA-кластер (HA – High Availability), имеем в виду, что его RTO равно времени переключения. Допустим, MSCS для двух нод переключает СУБД за 30 секунд. Значит, целевое RTO, которое можно обеспечить этим видом кластера — от 30 секунд.
А если рассмотреть VMware HA, которое отработает за 2 минуты (с учетом старта виртуальной машины, ее гостевой ОС и приложений)? Значит, такое решение подходит для приложений с целевым значением RTO от 2 минут.
Где же потери для HA-кластера (и соответственно, обеспечение RPO), спросите вы? Когда сервис поднимается, есть вероятность небольших потерь данных. Например, если СУБД проверит состояние базы данных и может откатить своё состояние на некорректно проведенную транзакцию. Или если файловая система вернется к некорректно сохраненной версии файла, и т.д., и т.п.
Вывод: не всегда стоит строить одинаковые решения одно поверх другого, например, HA над HA. Это только излишне усложнит инфраструктуру, усложнит (и удорожает) поддержку работы таких систем.
К предыдущим примерам двух HA. Определите, какое реальное значение RTO необходимо обеспечить для приложения? Для значений больше 2 минут нет смысла стоить еще и HA-кластер для сервисов внутри ВМ.
Обратим внимание еще на ряд факторов:
-
Разные системы обеспечения доступности могут решать различные проблемы, закрывать различные риски (риск-менеджмент – отдельная тема). И даже разные кластеры могут закрывать различные потенциальные проблемы и также дополнять друг друга.
К примеру, резервное копирование почтового сервера не исключает, но дополняет использование кластера HA для почтовых серверов. Кластер защищает от выхода из строя физического сервера и обеспечивает быстрое переключение на резервный сервер. Но кластер не защищает от потери данных (нежелательного удаленных данных, невозможности запуска ВМ после сбоя оборудования и т.п.). Для этого необходимо применение резервного копирования.
Что при этом дает совместное использование VMware vSphere HA? Быстрое восстановление уровня защиты. Если просто выключился один сервер с одной нодой MS Exchange, то вначале отработает DAG, переключив сервисы на другую ноду, а затем HA VMware загрузит сбойный сервер на другом плече своего кластера. И система готова к работе. (Хотя в этом примере я бы рассматривал применение виртуализации не только для одной функции только кластера, но и для всех остальных преимуществ самой платформы).
Говорим и пишем правильно! Или еще раз про RTO и RPO
Хочу сделать на этом акцент, поскольку я сам периодически совершаю ошибку, потому и остерегаю от этого вас:
RTO и RPO – это целевые значения для информационных систем (ИС), максимальные рамки, в которые мы должны уложиться. И эти целевые значения нам, ИТ-специалистам, сообщает бизнес, точнее, бизнес-владельцы соответствующей ИС, но не наоборот.
То есть:
Нельзя сказать, что RTO функции Instant Recovery – 2 минуты.
Нельзя считать, что резервное копирование раз в сутки и есть RPO 24 часа.
Всё идет в обратную сторону, то есть от бизнеса, и конкретно для RTO будет озвучиваться так:
Для определенного сервиса, в случае сбоя обслуживающей этот сервис системы, необходимо обеспечить восстановление, не допустив простоя в работе этого сервиса более 5 минут (RTO – 5 минут). Значит, подойдет решение, которое позволит сделать систему доступной за срок менее 5 минут.
Для базы данных, в случае сбоя СУБД, нужно обеспечить восстановление с допустимой потерей данных сроком не более 24 часов от момента сбоя. Значит, подойдет решение, которое обеспечит гарантированное восстановление базы из точек восстановления, производимых чаще, чем 1 раз в сутки. При этом отмечу, что резервное копирование раз в час, создающее 24 точки восстановления, дает больше гарантий восстановления, чем копирование раз в сутки, делающее только 1 точку.
А вот и практический пример
Казалось бы, можно рассуждать так:
Но! При этом надо понимать еще несколько моментов:
- Нам, прежде всего, необходимо отследить момент возникновения сбоя.
- Определить последствия от сбоя: всё сломалось или что-то доступно.
- Желательно найти причины возникновения сбоя, или хотя бы локализовать (изолировать) проблему: если пожар – потушить его, прежде чем пытаться восстановить что-либо в ту же инфраструктуру; если вирус портит данные – отключить от сети зараженный сервер, а не кормить вирус восстановленным сервером.
- Далее определить способы реанимации (наиболее подходящую процедуру восстановления: перегрузить ВМ, дождаться переключения кластера на другую ноду, или восстановить из резервной копии).
- Принять решение по восстановлению и собственно запустить восстановление.
Поэтому рассуждаем дальше:
Как видим, в 5 минут мы вряд ли укладываемся.
Теперь подумаем, возможно, нужен HA-кластер со временем восстановления 2 минуты? Но и он не обеспечит нам защиту от всех типов сбоев: рестарт машины в BSoD вполне вероятен, диск ВМ — тоже точка отказа, и т.п. Следовательно нужна дополнительная защита. Значит, продолжаем наши рассуждения:
В итоге, ваш ответ бизнес-владельцу ИС будет таким:
Очень важно! Самый главный совет: после того, как вы согласовали с владельцем ИС конкретные целевые показатели, договорились – обязательно фиксируйте ваши договоренности с ним в письменном виде, подписывайте с ним соглашение об уровне обслуживания (SLA).
Мы восстановили работу сервиса, но при этом потеряли все его данные – это неприемлемо. Мы восстановили БД, но СУБД не запускается, прочитать данные не могут – это неприемлемо. Именно поэтому мы говорим о доступности и данных, и сервисов. Важны и RPO, и RTO – в совокупности они обеспечивают доступность и того, и другого.
Через 15 минут после сбоя восстановлен доступ к сервису с данными за весь предыдущий период работы (до 1 часа включительно) – это всё про общую доступность.
Вот такой вот дуализм ;) Вместе дуальная пара RTO и RPO является важным показателем в том самом соглашении об уровне обслуживания (Service Level Agreement, или SLA) для конкретной ИС в части обеспечения доступности её сервисов и данных в случае возникновения сбоя. А подписывается соответствующее соглашение, как я говорил выше, между владельцем ИС (заказчиком услуги), и вами, ИТ-отделом (поставщиком услуги).

Сокращенно РПО - это регистрируемое почтовое отправление или почтовый идентификатор, УФПС Почта России
Сервис предоставлен Почтой России. Сервис отслеживает все почтовые отправления, любых магазинов и направлений, переданных на доставку Почте России. Мы не являемся сотрудниками Почты России и не несем никакой ответственности за доставку отправлений Почтой России. Сервис предоставлен, для удобства наших покупателей, отслеживать свои заказы, переданные нами на доставку Почте России.
Читайте также: